В этом посте мы демонстрируем тонкую настройку модели Llama 2 с использованием метода точной настройки с эффективным использованием параметров (PEFT) и развертываем точно настроенную модель на AWS Инферентия2, Мы используем АВС Нейрон комплект разработки программного обеспечения (SDK) для доступа к устройству AWS Inferentia2 и получения преимуществ от его высокой производительности. Затем мы используем большой контейнер вывода моделей на базе Глубокая библиотека Java (DJLServing) в качестве нашего решения для модельного обслуживания.
Обзор решения
Эффективная точная настройка Llama2 с использованием QLoRa
Семейство больших языковых моделей (LLM) Llama 2 представляет собой набор предварительно обученных и точно настроенных генеративных текстовых моделей с масштабом от 7 до 70 миллиардов параметров. Llama 2 был предварительно обучен на 2 триллионах токенов данных из общедоступных источников. Клиенты AWS иногда предпочитают точнее настраивать модели Llama 2, используя собственные данные клиентов, чтобы добиться более высокой производительности при выполнении последующих задач. Однако из-за большого количества параметров модели Llama 2 полная точная настройка может оказаться непомерно дорогой и трудоемкой. Подход с эффективной точной настройкой параметров (PEFT) может решить эту проблему путем точной настройки небольшого количества дополнительных параметров модели, одновременно замораживая большинство параметров предварительно обученной модели. Дополнительную информацию о PEFT можно прочитать здесь. после. В этом посте мы используем QLoRa для доводки модели Llama 2 7B.
Разверните точно настроенную модель на Inf2 с помощью Amazon SageMaker.
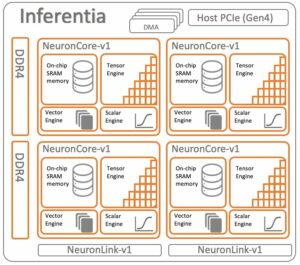
AWS Inferentia2 — это специально созданный ускоритель машинного обучения (ML), предназначенный для рабочих нагрузок вывода и обеспечивающий высокую производительность при снижении затрат до 40 % для рабочих нагрузок генеративного искусственного интеллекта и LLM по сравнению с другими экземплярами, оптимизированными для вывода, на AWS. В этом посте мы используем Amazon Elastic Compute Cloud (Amazon EC2) Экземпляр Inf2 с AWS Inferentia2, ускорителями Inferentia2 второго поколения, каждый из которых содержит два NeuronCores-v2. Каждый NeuronCore-v2 представляет собой независимый гетерогенный вычислительный блок с четырьмя основными ядрами: тензорными, векторными, скалярными и GPSIMD. Он включает в себя встроенную SRAM-память, управляемую программным обеспечением, для обеспечения максимальной локальности данных. Поскольку по Inf2 было опубликовано несколько блогов, читатель может обратиться к этому после и наш документации для получения дополнительной информации об Inf2.
Для развертывания моделей на Inf2 нам понадобится AWS Neuron SDK в качестве программного уровня, работающего поверх оборудования Inf2. AWS Neuron — это SDK, используемый для выполнения рабочих нагрузок глубокого обучения на AWS Inferentia и AWS Трениум основанные экземпляры. Он обеспечивает сквозной жизненный цикл разработки машинного обучения для создания новых моделей, обучения и оптимизации этих моделей, а также их развертывания для производства. AWS Neuron включает в себя глубокое обучение компилятор, время выполненияи инструменты которые изначально интегрированы с популярными фреймворками, такими как TensorFlow и PyTorch. В этом блоге мы будем использовать transformers-neuronx, который является частью AWS Neuron SDK для рабочих процессов вывода декодера преобразователя. Это поддерживает ряд популярных моделей, включая Llama 2.
Чтобы развернуть модели на Создатель мудреца Амазонкимы обычно используем контейнер, содержащий необходимые библиотеки, такие как Neuron SDK и transformers-neuronx а также компонент обслуживания модели. Amazon SageMaker поддерживает контейнеры для глубокого обучения (DLC) с популярными библиотеками с открытым исходным кодом для размещения больших моделей. В этом посте мы используем Контейнер вывода большой модели для нейрона. В этом контейнере есть все необходимое для развертывания модели Llama 2 на Inf2. Ресурсы для начала работы с LMI в Amazon SageMaker можно найти во многих наших существующих публикациях (блог 1, блог 2, блог 3) на эту тему. Короче говоря, вы можете запустить контейнер без написания дополнительного кода. Вы можете использовать обработчик по умолчанию для более удобного взаимодействия с пользователем и передайте одно из поддерживаемых названий моделей и любые настраиваемые параметры времени загрузки. Это компилирует и обслуживает LLM на экземпляре Inf2. Например, для развертывания OpenAssistant/llama2-13b-orca-8k-3319, вы можете предоставить следующую конфигурацию (как serving.properties файл). В serving.properties, мы указываем тип модели как llama2-13b-orca-8k-3319, размер пакета — 4, степень параллелизма тензора — 2, и все. Полный список настраиваемых параметров см. Все варианты конфигурации DJL.
Альтернативно вы можете написать свой собственный файл обработчика модели, как показано в этом документе. пример, но для этого требуется реализация методов загрузки модели и вывода, которые будут служить мостом между API-интерфейсами DJLServing.
Предпосылки
В следующем списке представлены предварительные условия для развертывания модели, описанной в этой записи блога. Вы можете реализовать либо из Консоль управления AWS или используя последнюю версию Интерфейс командной строки AWS (Интерфейс командной строки AWS).
Прохождение
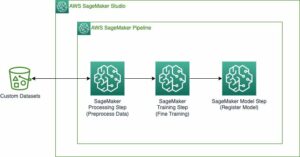
В следующем разделе мы рассмотрим код, разделенный на две части:
- Точная настройка модели Llama2-7b и загрузка артефактов модели в указанное расположение корзины Amazon S3.
- Разверните модель в Inferentia2 с помощью обслуживающего контейнера DJL, размещенного в Amazon SageMaker.
Полные примеры кода с инструкциями можно найти в этом GitHub репозиторий.
Часть 1. Точная настройка модели Llama2-7b с помощью PEFT.
Мы собираемся использовать недавно представленный в статье метод. QLoRA: настройка адаптера низкого ранга с учетом квантования для генерации языка Тим Деттмерс и др. QLoRA — это новый метод, позволяющий уменьшить объем памяти больших языковых моделей во время тонкой настройки без ущерба для производительности.
Примечание: Показанная ниже точная настройка модели llama2-7b была протестирована на Amazon. Блокнот SageMaker Studio с оптимизированным ядром Python 2.0 для графического процессора, используя мл.g5.2xбольшой тип экземпляра. В качестве наилучшей практики мы рекомендуем использовать Студия Amazon SageMaker Интегрированная среда разработки (IDE), запущенная в вашем собственном Виртуальное частное облако Amazon (Amazon VPC). Это позволяет вам контролировать, отслеживать и проверять сетевой трафик внутри и за пределами вашего VPC, используя стандартные возможности сети и безопасности AWS. Для получения дополнительной информации см. Обеспечение безопасности подключения к Amazon SageMaker Studio с помощью частного VPC.
Квантовать базовую модель
Сначала мы загружаем квантованную модель с 4-битным квантованием, используя Трансформеры Huggface библиотека следующим образом:
Загрузить набор обучающих данных
Затем мы загружаем набор данных, чтобы передать модель для этапа точной настройки, как показано ниже:
Прикрепите слой-адаптер
Здесь мы прикрепляем небольшой обучаемый слой адаптера, настроенный как ЛораКонфиг определяется в Обнимающем Лице пефт библиотека.
Обучить модель
Используя конфигурацию LoRA, показанную выше, мы настроим модель Llama2 вместе с гиперпараметрами. Фрагмент кода для обучения модели показан ниже:
Объединить вес модели
Точная настройка модели, выполненная выше, создала новую модель, содержащую обученные веса адаптера LoRA. В следующем фрагменте кода мы объединим адаптер с базовой моделью, чтобы можно было использовать точно настроенную модель для вывода.
Загрузите вес модели в Amazon S3.
На последнем этапе первой части мы сохраним веса объединенной модели в указанном месте Amazon S1. Вес модели будет использоваться контейнером обслуживания модели в Amazon SageMaker для размещения модели с использованием экземпляра Inferentia3.
Часть 2. Хост-модель QLoRA для вывода с помощью AWS Inf2 с использованием контейнера SageMaker LMI.
В этом разделе мы рассмотрим этапы развертывания точно настроенной модели QLoRA в среде хостинга Amazon SageMaker. Мы будем использовать DJL-сервировка контейнер от SageMaker DLC, который интегрируется с трансформеры-нейронкс библиотека для размещения этой модели. Эта установка облегчает загрузку моделей в ускорители AWS Inferentia2, распараллеливает модель на нескольких нейронных ядрах и обеспечивает обслуживание через конечные точки HTTP.
Подготовьте артефакты модели
DJL поддерживает множество библиотек оптимизации глубокого обучения, в том числе Глубокая скорость, БыстрееТрансформер и более. Для конкретных конфигураций модели мы предоставляем serving.properties с ключевыми параметрами, такими как tensor_parallel_degree и model_id определить параметры загрузки модели. model_id это может быть идентификатор модели Hugging Face или путь Amazon S3, где хранятся веса моделей. В нашем примере мы указываем местоположение нашей точно настроенной модели на Amazon S3. В следующем фрагменте кода показаны свойства, используемые для обслуживания модели:
Пожалуйста, обратитесь к этому документации для получения дополнительной информации о настраиваемых параметрах, доступных через serving.properties. Обратите внимание, что мы используем option.n_position=512 в этом блоге для более быстрой компиляции AWS Neuron. Если вы хотите попробовать большую длину входного токена, мы рекомендуем читателю заранее скомпилировать модель (см. Модель предварительной компиляции AOT в EC2). В противном случае вы можете столкнуться с ошибкой тайм-аута, если время компиляции слишком велико.
После serving.properties файл определен, мы упакуем его в tar.gz формате следующим образом:
Затем мы загрузим tar.gz в корзину Amazon S3:
Создайте конечную точку модели Amazon SageMaker.
Чтобы использовать экземпляр Inf2 для обслуживания, мы используем Amazon Контейнер SageMaker LMI с поддержкой DJL NeuronX. Пожалуйста, обратитесь к этому после для получения дополнительной информации об использовании контейнера DJL NeuronX для вывода. Следующий код показывает, как развернуть модель с помощью Amazon SageMaker Python SDK:
Конечная точка тестовой модели
После успешного развертывания модели мы можем проверить конечную точку, отправив образец запроса предиктору:
Пример вывода показан следующим образом:
В контексте анализа данных машинное обучение (МО) относится к статистическому методу, способному извлекать прогностическую силу из набора данных с возрастающей сложностью и точностью путем итеративного сужения области статистики.
Машинное обучение — это не новый статистический метод, а скорее комбинация существующих методов. Более того, он не предназначен для использования с конкретным набором данных или для получения конкретного результата. Скорее, он был разработан так, чтобы быть достаточно гибким, чтобы адаптироваться к любому набору данных и делать прогнозы относительно любого результата.
Убирать
Если вы решите, что больше не хотите, чтобы конечная точка SageMaker работала, вы можете удалить ее, используя AWS SDK для Python (boto3), AWS CLI или консоль Amazon SageMaker. Кроме того, вы также можете закройте ресурсы Amazon SageMaker Studio которые больше не нужны.
Заключение
В этом посте мы показали вам, как точно настроить модель Llama2-7b с помощью адаптера LoRA с 4-битным квантованием с использованием одного экземпляра графического процессора. Затем мы развернули модель на экземпляре Inf2, размещенном в Amazon SageMaker, с помощью обслуживающего контейнера DJL. Наконец, мы проверили конечную точку модели Amazon SageMaker с помощью прогноза генерации текста с помощью SageMaker Python SDK. Попробуйте, мы будем рады услышать ваши отзывы. Следите за обновлениями о дополнительных возможностях и новых инновациях AWS Inferentia.
Дополнительные примеры об AWS Neuron см. aws-нейрон-образцы.
Об авторах
 Вэй Тэ — старший специалист по архитектуре решений AI/ML в AWS. Он с энтузиазмом помогает клиентам продвигать их путь к AWS, уделяя особое внимание сервисам машинного обучения Amazon и решениям на основе машинного обучения. Вне работы он любит активный отдых на свежем воздухе, например, кемпинг, рыбалку и пешие походы со своей семьей.
Вэй Тэ — старший специалист по архитектуре решений AI/ML в AWS. Он с энтузиазмом помогает клиентам продвигать их путь к AWS, уделяя особое внимание сервисам машинного обучения Amazon и решениям на основе машинного обучения. Вне работы он любит активный отдых на свежем воздухе, например, кемпинг, рыбалку и пешие походы со своей семьей.
 Цинвея Ли является специалистом по машинному обучению в Amazon Web Services. Он получил докторскую степень. в исследованиях операций после того, как он нарушил счет своего советника на исследовательский грант и не смог вручить обещанную Нобелевскую премию. В настоящее время он помогает клиентам в сфере финансовых услуг и страхования создавать решения для машинного обучения на AWS. В свободное время любит читать и преподавать.
Цинвея Ли является специалистом по машинному обучению в Amazon Web Services. Он получил докторскую степень. в исследованиях операций после того, как он нарушил счет своего советника на исследовательский грант и не смог вручить обещанную Нобелевскую премию. В настоящее время он помогает клиентам в сфере финансовых услуг и страхования создавать решения для машинного обучения на AWS. В свободное время любит читать и преподавать.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/fine-tune-llama-2-using-qlora-and-deploy-it-on-amazon-sagemaker-with-aws-inferentia2/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 10
- 100
- 11
- 15%
- 16
- 19
- 24
- 300
- 7
- 70
- 8
- a
- О нас
- выше
- ускоритель
- ускорители
- доступ
- Учетная запись
- точность
- Достигать
- через
- активно
- приспосабливать
- дополнительный
- Дополнительно
- адрес
- продвижение
- После
- впереди
- AI
- AI / ML
- AL
- позволяет
- вдоль
- Альфа
- причислены
- Amazon
- Амазонское машинное обучение
- Создатель мудреца Амазонки
- Студия Amazon SageMaker
- Amazon Web Services
- an
- анализ
- и
- любой
- API
- Применить
- подхода
- МЫ
- AS
- At
- прикреплять
- автоматический
- доступен
- AWS
- Вывод AWS
- мяч
- Использование темпера с изогнутым основанием
- основанный
- дозирующий
- BE
- было
- польза
- ЛУЧШЕЕ
- Лучшая
- между
- миллиард
- Блог
- блоги
- МОСТ
- Сломался
- строить
- но
- by
- кемпинг
- CAN
- возможности
- способный
- Выберите
- облако
- код
- лыжных шлемов
- сочетание
- полный
- сложность
- компонент
- Вычисление
- Конфигурация
- настроить
- связь
- Консоли
- Container
- содержит
- контекст
- контроль
- Цена
- может
- создали
- В настоящее время
- Клиенты
- данным
- анализ данных
- решать
- глубоко
- глубокое обучение
- По умолчанию
- определять
- определенный
- Степень
- доставить
- обеспечивает
- развертывание
- развернуть
- развертывание
- описано
- предназначенный
- Развитие
- устройство
- Docker
- вниз
- два
- в течение
- динамический
- Е & Т
- каждый
- или
- позволяет
- впритык
- Конечная точка
- конечные точки
- Двигатель
- Двигатели
- достаточно
- Окружающая среда
- ошибка
- и т.д
- Эфир (ETH)
- многое
- пример
- Примеры
- выполненный
- существующий
- дорогим
- опыт
- дополнительно
- Face
- облегчает
- Oшибка
- ложный
- семья
- быстрее
- Показывая
- Обратная связь
- Файл
- окончательный
- в заключение
- финансовый
- финансовая служба
- Во-первых,
- Рыбалка
- гибкого
- фокусировка
- следовать
- следует
- после
- следующим образом
- след
- Что касается
- формат
- найденный
- 4
- каркасы
- Замораживание
- от
- полный
- Более того
- поколение
- генеративный
- Генеративный ИИ
- получить
- Дайте
- Go
- будет
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- предоставлять
- Аппаратные средства
- he
- слышать
- помощь
- помогает
- здесь
- High
- высокая производительность
- пеший туризм
- его
- кашель
- состоялся
- хостинг
- Вилла / Бунгало
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- ID
- if
- изображение
- осуществлять
- Осуществляющий
- in
- включают
- включает в себя
- В том числе
- повышение
- независимые
- промышленность
- информация
- инновации
- вход
- затраты
- пример
- случаев
- инструкции
- страхование
- страховая индустрия
- интегрированный
- Интегрируется
- в
- выпустили
- IT
- итерация
- ЕГО
- Java
- путешествие
- JPG
- JSON
- Сохранить
- Основные
- комплект
- Комплект (SDK)
- язык
- большой
- больше
- последний
- запустили
- слой
- слоев
- изучение
- Длина
- уровень
- библиотеки
- Библиотека
- Жизненный цикл
- такое как
- нравится
- линия
- Список
- Лама
- загрузка
- погрузка
- расположение
- дольше
- любят
- ниже
- машина
- обучение с помощью машины
- Главная
- поддерживает
- сделать
- управление
- многих
- максимизации
- Память
- идти
- метод
- методы
- может быть
- ML
- модель
- Модели
- Модули
- монитор
- БОЛЕЕ
- самых
- много
- с разными
- имена
- в
- Необходимость
- сеть
- сетевой трафик
- сетей
- Новые
- нет
- нобелевская торговая точка
- Ничто
- в своих размышлениях
- номер
- of
- on
- ONE
- только
- открытый
- с открытым исходным кодом
- Операционный отдел
- оптимизация
- Оптимизировать
- оптимизированный
- Опция
- Опции
- or
- Другое
- в противном случае
- наши
- Результат
- На открытом воздухе
- контуры
- выходной
- внешнюю
- за
- собственный
- пакет
- бумага & картон
- Параллельные
- параметр
- параметры
- часть
- части
- pass
- страстный
- путь
- производительность
- выполнены
- план
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пожалуйста
- Популярное
- После
- Блог
- мощностью
- Питание
- практика
- Точность
- прогноз
- Predictions
- интеллектуального
- Predictor
- предпосылки
- частная
- приз
- вероятность
- Проблема
- процесс
- производит
- Производство
- обещанный
- свойства
- обеспечивать
- публично
- опубликованный
- Питон
- pytorch
- ассортимент
- ранжирование
- скорее
- Читать
- читатель
- Reading
- получила
- недавно
- рекомендовать
- уменьшить
- относиться
- понимается
- хранилище
- запросить
- Запросы
- обязательный
- требуется
- исследованиям
- Полезные ресурсы
- ответ
- ответы
- правую
- Run
- Бег
- пожертвовав
- sagemaker
- Сохранить
- Шкала
- масштабирование
- сфера
- SDK
- бесшовные
- Во-вторых
- Второе поколение
- Раздел
- безопасность
- посмотреть
- отправка
- старший
- Последовательность
- служить
- обслуживание
- Услуги
- выступающей
- набор
- установка
- установка
- несколько
- Короткое
- демонстрации
- показал
- показанный
- Шоу
- с
- одинарной
- Размер
- небольшой
- отрывок
- So
- Software
- разработка программного обеспечения
- комплект для разработки программного обеспечения
- Решение
- Решения
- иногда
- Источник
- Источники
- специалист
- конкретный
- указанный
- стандарт
- и политические лидеры
- статистический
- оставаться
- Шаг
- Шаги
- хранить
- студия
- Успешно
- такие
- поддержка
- Поддержанный
- Поддержка
- задачи
- Обучение
- техника
- снижения вреда
- tensorflow
- проверенный
- текст
- генерация текста
- который
- Ассоциация
- их
- Их
- тогда
- Эти
- этой
- Через
- Тим
- время
- в
- знак
- Лексемы
- слишком
- топ
- тема
- факел
- трафик
- Train
- специалистов
- Обучение
- трансформатор
- Триллион
- правда
- стараться
- два
- напишите
- Updates
- загружено
- URI
- URL
- использование
- используемый
- Информация о пользователе
- Пользовательский опыт
- через
- обычно
- VALIDATE
- подтверждено
- версия
- с помощью
- Виртуальный
- от
- прохождение
- хотеть
- законопроект
- we
- Web
- веб-сервисы
- вес
- ЧТО Ж
- Что
- Что такое
- , которые
- в то время как
- будете
- в
- без
- Работа
- работник
- Рабочие процессы
- записывать
- письмо
- являетесь
- ВАШЕ
- зефирнет