В современном мире клиенты управляют огромными объемами данных в своих Простой сервис хранения Amazon (Amazon S3), для которых требуются сложные конвейеры данных, чтобы постоянно понимать изменения в макете данных и делать их доступными для потребляющих систем. Клей AWS Поисковые роботы обеспечивают простой способ каталогизации данных в каталоге данных AWS Glue, который устраняет тяжелую работу, когда речь идет об управлении схемой и классификации данных. Сканеры AWS Glue извлекают схему данных и разделы из Amazon S3 для автоматического заполнения каталога данных, поддерживая актуальность метаданных.
Но при экспоненциальном росте данных с течением времени количество разделов в данной таблице может значительно возрасти. Поскольку службы аналитики, такие как Амазонка Афина запрашивать таблицу, содержащую миллионы секций, время, необходимое для извлечения секции, увеличивается, что может привести к увеличению времени выполнения запроса.
Сегодня поддержка сканера AWS Glue была расширена, чтобы автоматически добавлять индексы секций для вновь обнаруженных таблиц, чтобы оптимизировать обработку запросов к секционированному набору данных. Теперь, когда программа-обходчик создает новую таблицу каталога данных во время работы программы-обходчика, он также по умолчанию создает индекс секции с наибольшим перестановкой всех числовых и строковых столбцов секции в качестве ключей. Затем каталог данных создает индекс с возможностью поиска на основе этих ключей, что сокращает время, необходимое для извлечения и фильтрации метаданных разделов в таблицах с миллионами разделов. Создание индексов разделов приносит пользу аналитическим рабочим нагрузкам, выполняемым в Athena, Амазонка ЭМИ, Спектр красного смещения Амазонкии AWS Glue.
В этом посте мы опишем, как создавать индексы разделов с помощью сканера AWS Glue, и сравним повышение производительности запросов при доступе к просканированным данным с индексом разделов от Athena и без него.
Обзор решения
Мы используем AWS CloudFormation шаблон для создания наших ресурсов решения. На следующих шагах мы покажем, как настроить сканер AWS Glue для создания индекса разделов с помощью консоли AWS Glue или Интерфейс командной строки AWS (интерфейс командной строки AWS). Затем мы сравним улучшения производительности запросов с помощью Athena.
Предпосылки
Чтобы следить за этой публикацией, у вас должен быть доступ к Управление идентификацией и доступом AWS (IAM) для создания ресурсов с помощью AWS CloudFormation.
Настройте ресурсы решения
Шаблон CloudFormation генерирует следующие ресурсы:
- Роли и политики IAM
- База данных AWS Glue для хранения схемы
- Искатель AWS Glue указывает на сильно секционированный набор данных
- Рабочая группа Athena и корзина для хранения результатов запросов.
Выполните следующие шаги, чтобы настроить ресурсы решения:
- Войти в Консоль управления AWS в качестве администратора IAM.
- Выберите Стек запуска для развертывания шаблона CloudFormation:

- Что касается Имя базы данных, оставьте значение по умолчанию
blog_partition_index_crawlerdb.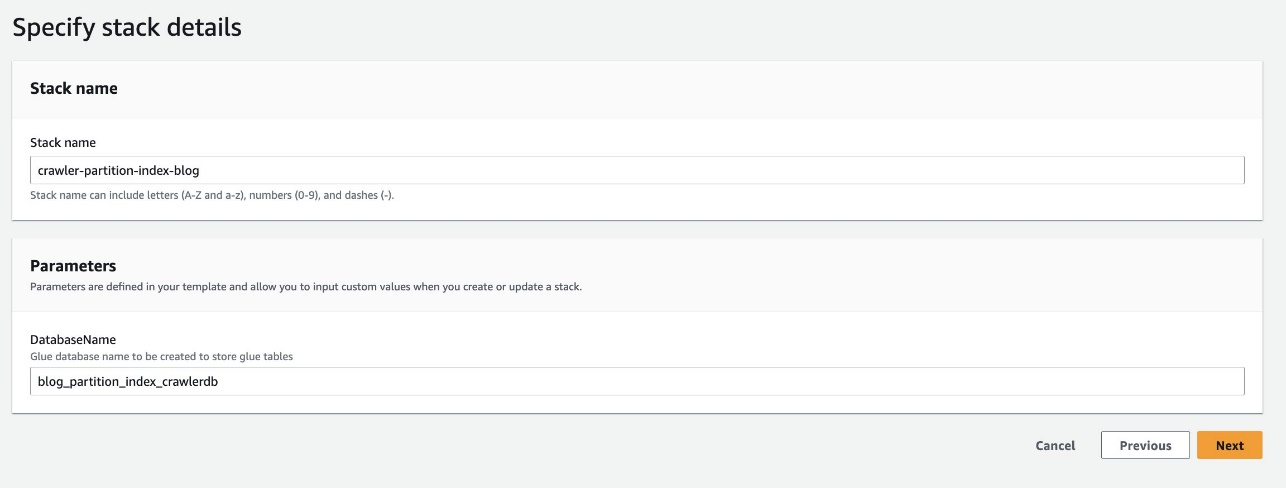
- Выберите Следующая.
- Просмотрите подробности на последней странице и выберите Я признаю, что AWS CloudFormation может создавать ресурсы IAM.
- Выберите Создать стек.
- Когда стек будет готов, в консоли AWS CloudFormation перейдите к Выходы вкладка стека.
- Запишите значения
DatabaseNameиGlueCrawlerName.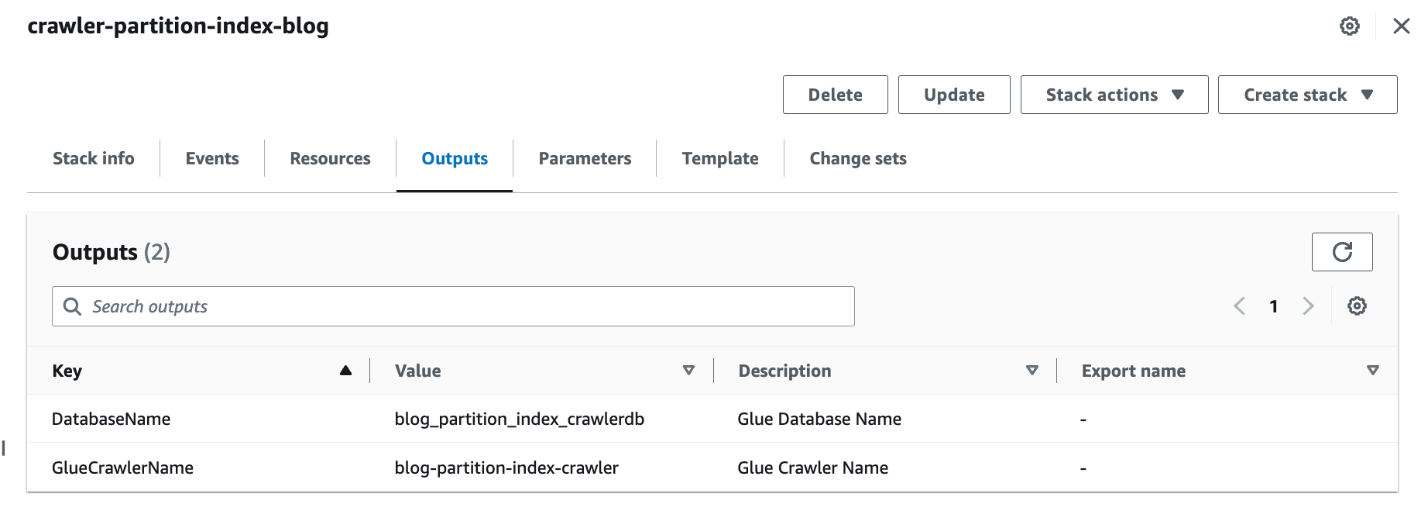
Некоторые ресурсы, развертываемые этим стеком, требуют затрат при использовании.
Отредактируйте и запустите сканер AWS Glue.
Чтобы настроить и запустить сканер AWS Glue, выполните следующие действия:
- На консоли AWS Glue выберите ползунки в навигационной панели.
- Найдите
crawler blog-partition-index-crawler, а затем выбрать Редактировать.
- В Установить выход и расписание в разделе Дополнительные параметры, наведите на Автоматически создавать индексы разделов.
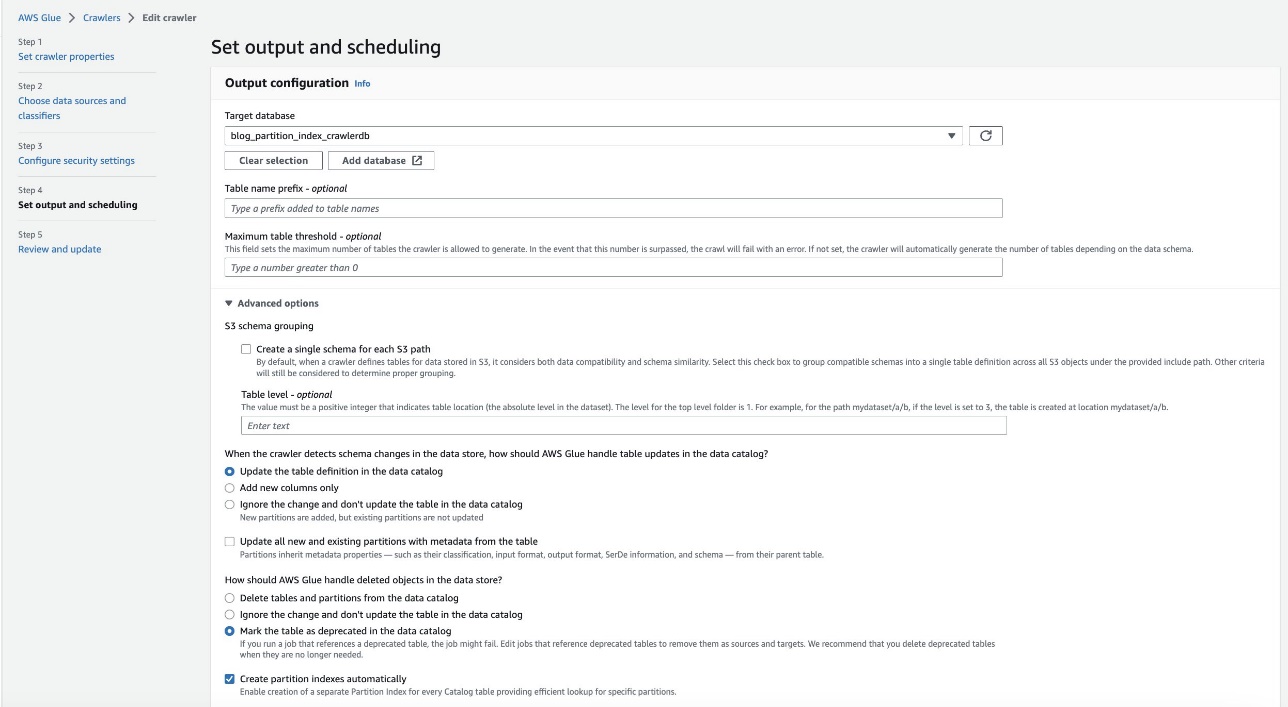
- Проверьте и обновите настройки сканера.
Кроме того, вы можете настроить свой сканер с помощью интерфейса командной строки AWS (укажите свою роль IAM и регион):
- Теперь запустите искатель и убедитесь, что запуск искателя завершен.
Это сильно секционированный набор данных, и его создание займет примерно 90 минут.
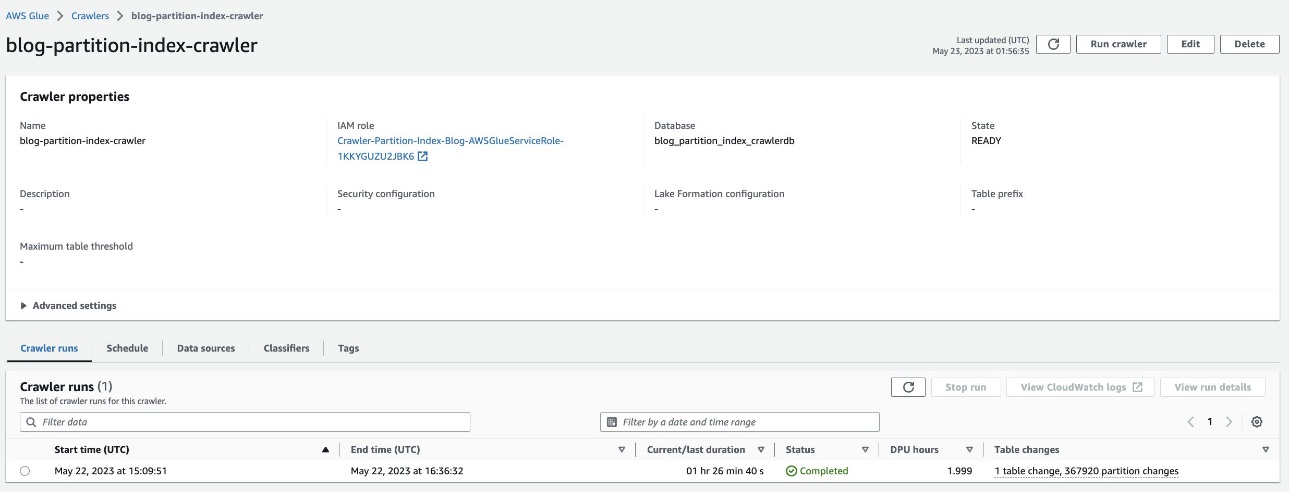
Проверьте секционированную таблицу
В базе данных AWS Glue blog_partition_index_crawlerdb, убедитесь, что таблица highly_partitioned_table создается.
По умолчанию программа-обходчик определяет индекс на основе наибольшей перестановки столбцов разделов допустимых типов столбцов в том же порядке столбцов разделов, которые могут быть либо числовыми, либо строковыми. Для таблицы, созданной сканером (highly_partitioned_table), у нас есть столбцы разделов year (Строка), month (Строка), day (строка) и hour (нить).
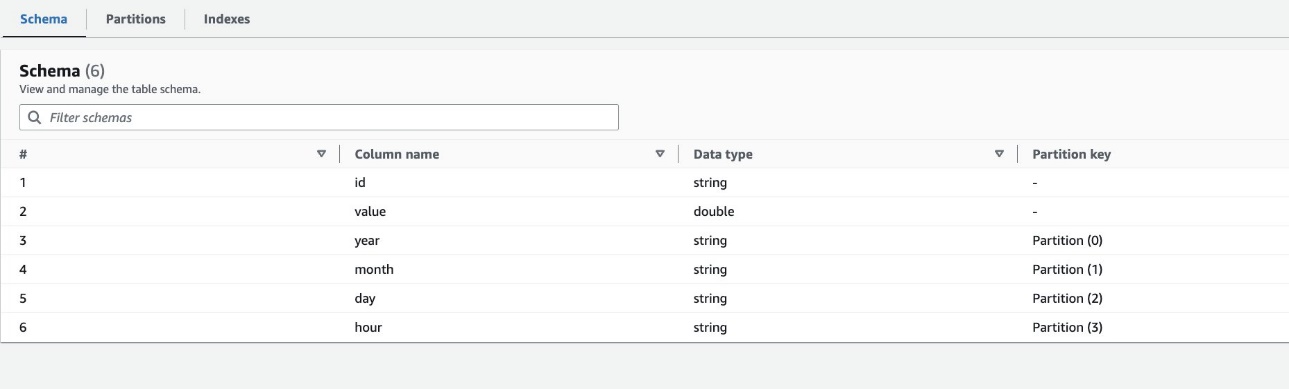
На основе этого определения сканер создал индекс по перестановке года, месяца, дня и часа. Искатель создал индексы с префиксом crawler_ в любом индексе раздела, созданном по умолчанию.
Проверьте то же самое, перейдя к таблице highly_partitioned_table на консоли AWS Glue и выбрав Индексы меню.
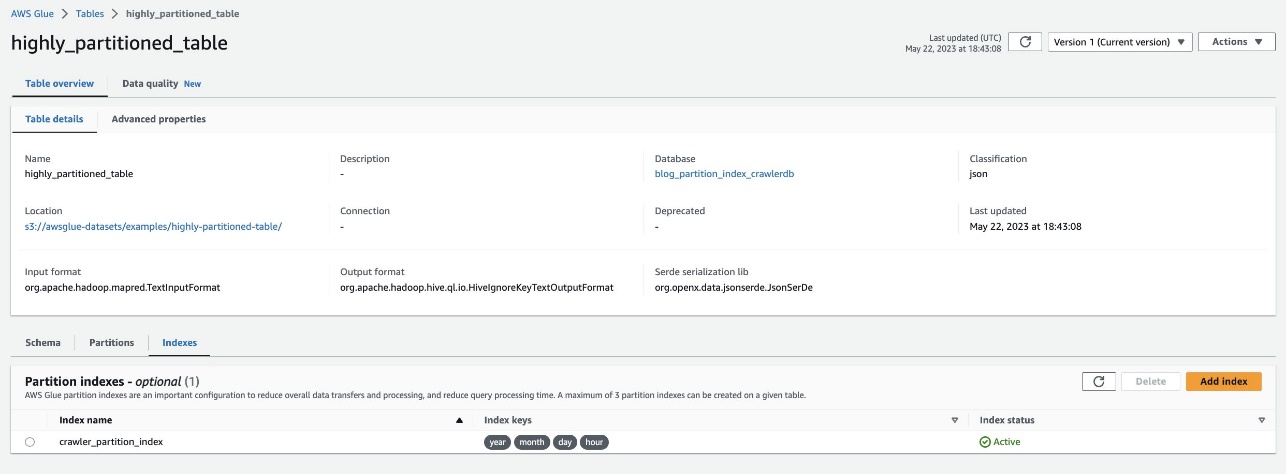
Искатель смог просканировать источник данных S3 и успешно заполнить индексы разделов для таблицы.
Сравните улучшения производительности запросов с помощью Athena.
Во-первых, мы запрашиваем таблицу в Athena без использования индекса раздела. Чтобы проверить таблицы с помощью Athena, выполните следующие шаги:
- На консоли Athena выберите
crawler-primary-workgroupкак рабочая группа Athena и выберите признавать.
- Выполните следующий запрос:
На следующем снимке экрана показано, что запрос занял примерно 32 секунды без включения фильтрации с использованием индекса раздела.
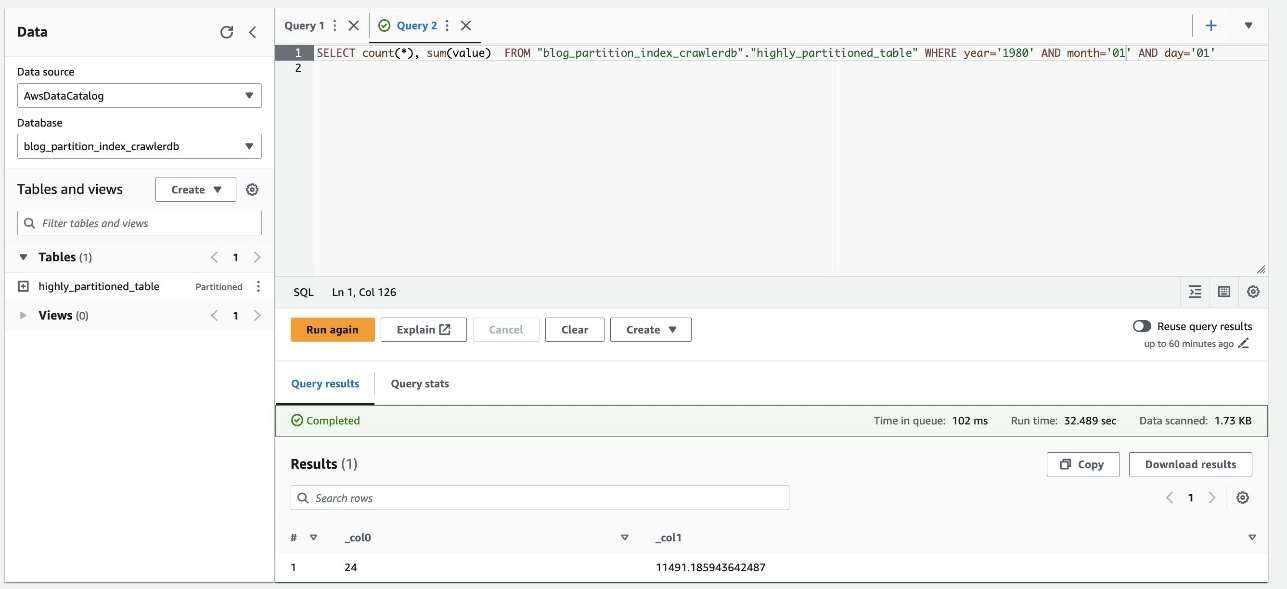
- Теперь мы включаем индекс раздела в запросе Athena:
- Запустите следующий запрос еще раз и обратите внимание на время выполнения:
На следующем снимке экрана показано, что запрос занял всего 700 миллисекунд, что намного быстрее при включенной фильтрации с использованием индекса раздела.
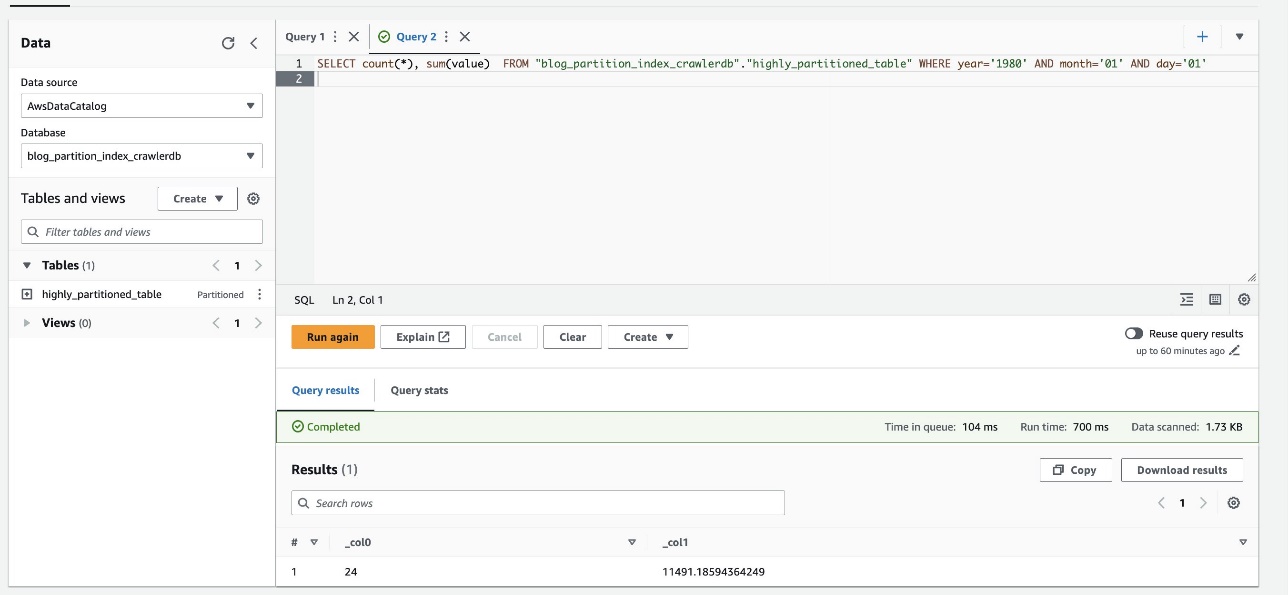
Убирать
Чтобы избежать нежелательных списаний с вашего аккаунта AWS, вы можете удалить ресурсы AWS:
- Войдите в консоль CloudFormation в качестве администратора IAM, используемого для создания стека CloudFormation.
- Удалите созданный вами стек CloudFormation.
Заключение
В этом посте мы объяснили, как настроить сканер AWS для создания индексов разделов, и сравнили производительность запросов при доступе к данным с помощью индексов из Athena.
Если в таблице нет индексов разделов, AWS Glue загружает все разделы таблицы, а затем фильтрует загруженные разделы, что приводит к неэффективному извлечению метаданных. Сервисы аналитики, такие как Redshift Spectrum, Amazon EMR и AWS Glue ETL Spark DataFrames, теперь могут использовать индексы для выборки разделов, что значительно повышает производительность запросов.
Дополнительные сведения об индексах разделов и производительности запросов в различных аналитических механизмах см. Повышение производительности запросов Amazon Athena с помощью индексов разделов каталога данных AWS Glue. и Повышение производительности запросов с помощью индексов разделов AWS Glue.
Особая благодарность всем, кто внес свой вклад в запуск этой функции сканера: Юханг Чен, Кайл Дуонг и Мита Гаваде.
Об авторах
 Шривидья Партхасарати является старшим архитектором больших данных в команде AWS Lake Formation. Ей нравится создавать решения для сетки данных и делиться ими с сообществом.
Шривидья Партхасарати является старшим архитектором больших данных в команде AWS Lake Formation. Ей нравится создавать решения для сетки данных и делиться ими с сообществом.
 Сандип Адванкар является старшим менеджером по техническим продуктам в AWS. Находясь в районе Калифорнийского залива, он работает с клиентами по всему миру, чтобы преобразовать деловые и технические требования в продукты, которые позволяют клиентам улучшить управление, защиту и доступ к данным.
Сандип Адванкар является старшим менеджером по техническим продуктам в AWS. Находясь в районе Калифорнийского залива, он работает с клиентами по всему миру, чтобы преобразовать деловые и технические требования в продукты, которые позволяют клиентам улучшить управление, защиту и доступ к данным.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ЭВМ Финанс. Единый интерфейс для децентрализованных финансов. Доступ здесь.
- Квантум Медиа Групп. ИК/PR усиление. Доступ здесь.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :имеет
- :является
- :куда
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- в состоянии
- доступ
- доступа
- Учетная запись
- признавать
- через
- Добавить
- Администратор
- снова
- Все
- вдоль
- причислены
- Amazon
- Амазонка Афина
- Амазонка ЭМИ
- Amazon Web Services
- суммы
- an
- Аналитические фармацевтические услуги
- аналитика
- и
- любой
- примерно
- МЫ
- ПЛОЩАДЬ
- около
- AS
- At
- автоматически
- доступен
- избежать
- AWS
- AWS CloudFormation
- Клей AWS
- Формирование озера AWS
- основанный
- залив
- , так как:
- было
- Преимущества
- большой
- Big Data
- Строительство
- бизнес
- by
- Калифорния
- CAN
- каталог
- Вызывать
- изменения
- расходы
- чен
- Выберите
- Выбирая
- классификация
- Column
- Колонки
- выходит
- сообщество
- сравнить
- сравненный
- полный
- Консоли
- непрерывно
- способствовало
- Расходы
- гусеничный
- Создайте
- создали
- создает
- Создающий
- создание
- Текущий
- Клиенты
- данным
- доступ к данным
- Озеро данных
- База данных
- день
- По умолчанию
- демонстрировать
- развертывание
- развертывает
- описывать
- подробнее
- определяет
- открытый
- вниз
- в течение
- эффективно
- или
- включить
- включен
- Двигатели
- Эфир (ETH)
- все члены
- расширенный
- объяснены
- экспоненциально
- извлечение
- извлечь данные
- быстрее
- Особенность
- фильтр
- фильтрация
- фильтры
- окончательный
- следовать
- после
- Что касается
- образование
- от
- генерирует
- данный
- земной шар
- Расти
- Рост
- Есть
- he
- тяжелый
- тяжелая атлетика
- очень
- держать
- час
- Как
- How To
- HTML
- HTTP
- HTTPS
- IAM
- Личность
- улучшать
- улучшение
- улучшение
- in
- Увеличение
- Увеличивает
- индекс
- Индексы
- неэффективное
- информация
- в
- IT
- JPG
- Сохранить
- хранение
- ключи
- озеро
- крупнейших
- запуск
- Планировка
- Подтяжка лица
- такое как
- линия
- грузы
- сделать
- управлять
- управление
- менеджер
- сетке
- Метаданные
- может быть
- миллионы
- минут
- Месяц
- БОЛЕЕ
- много
- должен
- Откройте
- навигационный
- Навигация
- необходимый
- Новые
- вновь
- нет
- сейчас
- номер
- of
- on
- только
- Оптимизировать
- or
- заказ
- наши
- выходной
- за
- страница
- хлеб
- путь
- производительность
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- После
- представить
- обработка
- Продукт
- Менеджер по продукции
- Продукция
- обеспечивать
- снижение
- область
- обязательный
- Требования
- требуется
- Полезные ресурсы
- в результате
- Итоги
- Роли
- роли
- Run
- Бег
- то же
- секунды
- Раздел
- безопасный
- старший
- Услуги
- набор
- настройки
- разделение
- она
- Шоу
- значительный
- существенно
- просто
- Решение
- Решения
- Источник
- Искриться
- Спектр
- стек
- Шаги
- диск
- магазин
- простой
- строка
- Успешно
- поддержка
- системы
- ТАБЛИЦЫ
- взять
- команда
- Технический
- шаблон
- благодаря
- который
- Ассоциация
- их
- Их
- тогда
- Эти
- они
- этой
- время
- в
- Сегодняшних
- приняли
- переведите
- правда
- напишите
- Типы
- под
- понимать
- нежелательный
- Обновление ПО
- использование
- используемый
- через
- использовать
- ценностное
- Наши ценности
- различный
- Огромная
- проверить
- версия
- законопроект
- Путь..
- we
- Web
- веб-сервисы
- когда
- который
- КТО
- будете
- без
- Рабочая группа
- работает
- Мир
- YAML
- год
- являетесь
- ВАШЕ
- зефирнет