Амазонка Redshift — это полностью управляемое облачное хранилище данных объемом в несколько петабайт, которое используется десятками тысяч клиентов для ежедневной обработки эксабайтов данных для выполнения своей аналитической рабочей нагрузки. Вы можете структурировать свои данные, измерять бизнес-процессы и быстро получать ценную информацию с помощью многомерной модели. Amazon Redshift предоставляет встроенные функции для ускорения процесса моделирования, организации и составления отчетов на основе многомерной модели.
В этом посте мы обсудим, как реализовать многомерную модель, в частности методология Кимбалла. Мы обсуждаем аспекты и факты реализации в рамках Amazon Redshift. Мы покажем, как выполнять извлечение, преобразование и загрузку (ELT) — процесс интеграции, направленный на получение необработанных данных из озера данных на промежуточный уровень для выполнения моделирования. В целом, пост даст вам четкое представление о том, как использовать многомерное моделирование в Amazon Redshift.
Обзор решения
Следующая диаграмма иллюстрирует архитектуру решения.

В следующих разделах мы сначала обсудим и продемонстрируем ключевые аспекты многомерной модели. После этого мы создаем витрину данных с помощью Amazon Redshift с многомерной моделью данных, включая таблицы измерений и фактов. Данные загружаются и размещаются с помощью КОПИЯ команда, данные в измерениях загружаются с помощью MERGE утверждение, и факты будут присоединены к измерениям, из которых получены идеи. Мы планируем загрузку измерений и фактов с помощью Редактор запросов Amazon Redshift версии 2. Наконец, мы используем Amazon QuickSight чтобы получить представление о смоделированных данных в виде панели инструментов QuickSight.
Для этого решения мы используем образец набора данных (нормализованный), предоставленный Amazon Redshift для продажи билетов на мероприятия. Для этого поста мы сузили набор данных для простоты и демонстрационных целей. В следующих таблицах приведены примеры данных по продажам билетов и местам проведения.


Согласно Методология размерного моделирования Кимбалла, есть четыре ключевых шага в разработке многомерной модели:
- Определите бизнес-процесс.
- Объявите зерно ваших данных.
- Определить и внедрить размеры.
- Выявляйте и применяйте факты.
Кроме того, мы добавляем пятый шаг в демонстрационных целях, который заключается в создании отчетов и анализе бизнес-событий.
Предпосылки
Для этого прохождения у вас должны быть следующие предпосылки:
Определить бизнес-процесс
Проще говоря, идентификация бизнес-процесса — это идентификация измеримого события, которое генерирует данные в организации. Обычно у компаний есть какая-то операционная исходная система, которая генерирует свои данные в необработанном формате. Это хорошая отправная точка для определения различных источников для бизнес-процесса.
Затем бизнес-процесс сохраняется как витрина данных в виде измерений и фактов. Глядя на наш образец набора данных, упомянутый ранее, мы можем ясно видеть, что бизнес-процесс — это продажи, сделанные для данного события.
Распространенной ошибкой является использование отделов компании в качестве бизнес-процесса. Данные (бизнес-процесс) должны быть интегрированы между различными отделами, в этом случае маркетинг может получить доступ к данным о продажах. Определение правильного бизнес-процесса имеет решающее значение — неправильное выполнение этого шага может повлиять на всю витрину данных (это может привести к дублированию зернистости и неправильным показателям в окончательных отчетах).
Объявите зерно ваших данных
Объявление зернистости — это акт уникальной идентификации записи в вашем источнике данных. Зернистость используется в таблице фактов для точного измерения данных и обеспечения возможности дальнейшего сведения. В нашем примере это может быть позиция в бизнес-процессе продаж.
В нашем случае продажа может быть однозначно идентифицирована путем просмотра времени транзакции, когда продажа имела место; это будет самый атомарный уровень.

Определить и внедрить размеры
Ваша таблица измерений описывает вашу таблицу фактов и ее атрибуты. При определении описательного контекста вашего бизнес-процесса вы сохраняете текст в отдельной таблице, помня о зернистости таблицы фактов. При присоединении таблицы измерений к таблице фактов должна быть только одна строка, связанная с таблицей фактов. В нашем примере мы используем следующую таблицу для разделения на таблицу измерений; эти поля описывают факты, которые мы будем измерять.
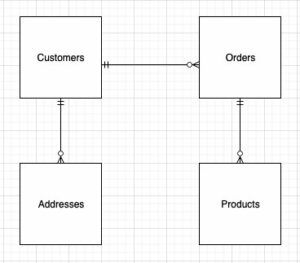
При проектировании структуры многомерной модели (схемы) можно либо создать звезда or снежинка схема. Структура должна быть тесно связана с бизнес-процессом; поэтому для нашего примера лучше всего подходит схема звезда. На следующем рисунке показана наша диаграмма отношений сущностей (ERD).

В следующих разделах мы подробно описываем шаги по реализации измерений.
Стадия исходных данных
Прежде чем мы сможем создать и загрузить таблицу измерений, нам нужны исходные данные. Поэтому мы помещаем исходные данные в промежуточную или временную таблицу. Это часто называют промежуточный слой, который является необработанной копией исходных данных. Для этого в Amazon Redshift мы используем Команда КОПИРОВАТЬ для загрузки данных из общедоступной корзины S3 размерного моделирования в amazon-redshift, расположенной на us-east-1 Область, край. Обратите внимание, что команда COPY использует Управление идентификацией и доступом AWS (IAM) роль с доступ к амазон S3. Роль должна быть связанный с кластером. Выполните следующие шаги, чтобы подготовить исходные данные:
- Создайте
venueисходная таблица:
- Загрузите данные о месте проведения:
- Создайте
salesисходная таблица:
- Загрузите данные источника продаж:
- Создайте
calendarтаблица:
- Загрузите данные календаря:
Создайте таблицу размеров
Разработка таблицы измерений может зависеть от ваших бизнес-требований — например, нужно ли отслеживать изменения данных с течением времени? Есть семь различных типов размеров. Для нашего примера мы используем Тип 1 потому что нам не нужно отслеживать исторические изменения. Подробнее о типе 2 см. Упростите загрузку данных в медленно изменяющиеся измерения типа 2 в Amazon Redshift.. Таблица измерений будет денормализована с помощью первичного ключа, суррогатного ключа и нескольких добавленных полей для указания изменений в таблице. См. следующий код:
Несколько замечаний по созданию таблицы измерений:
- Имена полей преобразуются в удобные для бизнеса имена.
- Наш первичный ключ
VenueID, который мы используем для уникальной идентификации места продажи. - Будут добавлены две дополнительные строки, указывающие, когда запись была вставлена и обновлена (для отслеживания изменений).
- Мы используем АВТОМАТИЧЕСКИЙ стиль распределения возложить на Amazon Redshift ответственность за выбор и корректировку стиля распространения
Другим важным фактором, который следует учитывать при моделировании размеров, является использование суррогатные ключи. Суррогатные ключи — это искусственные ключи, которые используются в многомерном моделировании для уникальной идентификации каждой записи в таблице измерений. Обычно они генерируются как последовательные целые числа и не имеют никакого значения в бизнес-сфере. Они предлагают несколько преимуществ, таких как обеспечение уникальности и повышение производительности соединений, поскольку они обычно меньше естественных ключей и, будучи суррогатными ключами, не меняются со временем. Это позволяет нам быть последовательными и легче соединять факты и измерения.
В Amazon Redshift суррогатные ключи обычно создаются с использованием ключевого слова IDENTITY. Например, предыдущий оператор CREATE создает таблицу измерений с VenueSkey суррогатный ключ. VenueSkey столбец автоматически заполняется уникальными значениями по мере добавления новых строк в таблицу. Затем этот столбец можно использовать для присоединения таблицы мест проведения к FactSaleTransactions таблице.
Несколько советов по разработке суррогатных ключей:
- Используйте небольшой тип данных фиксированной ширины для суррогатного ключа. Это повысит производительность и уменьшит объем памяти.
- Используйте ключевое слово IDENTITY или создайте суррогатный ключ, используя последовательное значение или значение GUID. Это гарантирует, что суррогатный ключ уникален и не может быть изменен.
Загрузите тусклую таблицу, используя MERGE
Существует множество способов загрузить вашу тусклую таблицу. Необходимо учитывать определенные факторы, например производительность, объем данных и, возможно, время загрузки SLA. С MERGE оператор, мы выполняем upsert без необходимости указывать несколько команд вставки и обновления. Вы можете настроить MERGE заявление в хранимая процедура для заполнения данных. Затем вы планируете программный запуск хранимой процедуры с помощью редактора запросов, который мы продемонстрируем позже в этом посте. Следующий код создает хранимую процедуру с именем SalesMart.DimVenueLoad:
Несколько замечаний по загрузке измерений:
- Когда запись вставляется впервые, будут заполнены дата вставки и обновленная дата. При изменении каких-либо значений данные обновляются, и обновленная дата отражает дату, когда она была изменена. Вставленная дата остается.
- Поскольку данные будут использоваться бизнес-пользователями, нам необходимо заменить значения NULL, если таковые имеются, более подходящими для бизнеса значениями.
Выявить и реализовать факты
Теперь, когда мы объявили наше зерно событием продажи, имевшим место в определенное время, наша таблица фактов будет хранить числовые факты для нашего бизнес-процесса.
Мы определили следующие числовые факты для измерения:
- Количество проданных билетов за одну продажу
- Комиссия за продажу
Реализация факта
Существуют три типа таблиц фактов (таблица фактов транзакций, таблица фактов периодического снимка и таблица фактов накопительного снимка). Каждая из них служит разным представлениям о бизнес-процессе. В нашем примере мы используем таблицу фактов транзакций. Выполните следующие шаги:
- Создайте таблицу фактов
Добавляется вставленная дата со значением по умолчанию, указывающая, была ли загружена запись и когда. Вы можете использовать это при перезагрузке таблицы фактов, чтобы удалить уже загруженные данные, чтобы избежать дублирования.
Загрузка таблицы фактов состоит из простого оператора вставки, объединяющего связанные измерения. Мы присоединяемся из DimVenue была создана таблица, которая описывает наши факты. Это лучшая практика, но необязательно иметь календарная дата измерения, которые позволяют конечному пользователю перемещаться по таблице фактов. Данные могут загружаться либо при новой распродаже, либо ежедневно; здесь пригодится вставленная дата или дата загрузки.
Мы загружаем таблицу фактов с помощью хранимой процедуры и используем параметр даты.
- Создайте хранимую процедуру со следующим кодом. Чтобы сохранить ту же целостность данных, которую мы применяли при загрузке измерения, мы заменяем значения NULL, если они есть, более подходящими для бизнеса значениями:
- Загрузите данные, вызвав процедуру с помощью следующей команды:
Расписание загрузки данных
Теперь мы можем автоматизировать процесс моделирования, запланировав хранимые процедуры в Amazon Redshift Query Editor V2. Выполните следующие шаги:
- Сначала мы вызываем загрузку измерения, и после успешного выполнения загрузки измерения начинается загрузка факта:
Если загрузка измерения завершается неудачно, загрузка фактов не выполняется. Это обеспечивает согласованность данных, поскольку мы не хотим загружать таблицу фактов устаревшими измерениями.
- Чтобы запланировать загрузку, выберите Назначить в редакторе запросов V2.

- Мы планируем выполнение запроса каждый день в 5:00.
- При желании вы можете добавить уведомления об ошибках, включив Amazon Простая служба уведомлений (Amazon SNS) уведомления.

Создание отчетов и анализ данных в Amazon Quicksight
QuickSight — это служба бизнес-аналитики, которая упрощает предоставление информации. Будучи полностью управляемой службой, QuickSight позволяет легко создавать и публиковать интерактивные информационные панели, к которым затем можно получить доступ с любого устройства и которые можно встроить в ваши приложения, порталы и веб-сайты.
Мы используем нашу витрину данных для визуального представления фактов в виде информационной панели. Чтобы начать работу и настроить QuickSight, см. Создание набора данных с использованием базы данных, которая не обнаруживается автоматически.
После того как вы создадите источник данных в QuickSight, мы объединим смоделированные данные (витрину данных) на основе нашего суррогатного ключа. skey. Мы используем этот набор данных для визуализации витрины данных.

Наша конечная информационная панель будет содержать информацию о витрине данных и отвечать на важные бизнес-вопросы, такие как общая комиссия за место и даты с самыми высокими продажами. На следующем снимке экрана показан конечный продукт витрины данных.

Убирать
Чтобы избежать дополнительных расходов в будущем, удалите все ресурсы, созданные вами в рамках этой публикации.
Заключение
Теперь мы успешно внедрили витрину данных, используя нашу DimVenue, DimCalendarи FactSaleTransactions столы. Наш склад не укомплектован; поскольку мы можем расширять витрину данных большим количеством фактов и внедрять больше витрин, а по мере роста бизнес-процессов и требований со временем будет расти и хранилище данных. В этом посте мы подробно рассказали о понимании и реализации многомерного моделирования в Amazon Redshift.
Начните с вашего Амазонка Redshift габаритная модель сегодня.
Об авторах
 Бернард Верстер — опытный облачный инженер с многолетним опытом создания масштабируемых и эффективных моделей данных, определения стратегий интеграции данных и обеспечения управления данными и их безопасности. Он увлечен использованием данных для получения информации, а также согласования с бизнес-требованиями и целями.
Бернард Верстер — опытный облачный инженер с многолетним опытом создания масштабируемых и эффективных моделей данных, определения стратегий интеграции данных и обеспечения управления данными и их безопасности. Он увлечен использованием данных для получения информации, а также согласования с бизнес-требованиями и целями.
 Абхишек Пан является специалистом WWSO по SA-Analytics, работающим с клиентами AWS в государственном секторе Индии. Он взаимодействует с клиентами, чтобы определить стратегию, основанную на данных, проводит сеансы углубленного изучения вариантов использования аналитики и разрабатывает масштабируемые и производительные аналитические приложения. Он имеет 12-летний опыт работы и увлечен базами данных, аналитикой и AI/ML. Он заядлый путешественник и пытается запечатлеть мир через объектив своей камеры.
Абхишек Пан является специалистом WWSO по SA-Analytics, работающим с клиентами AWS в государственном секторе Индии. Он взаимодействует с клиентами, чтобы определить стратегию, основанную на данных, проводит сеансы углубленного изучения вариантов использования аналитики и разрабатывает масштабируемые и производительные аналитические приложения. Он имеет 12-летний опыт работы и увлечен базами данных, аналитикой и AI/ML. Он заядлый путешественник и пытается запечатлеть мир через объектив своей камеры.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Автомобили / электромобили, Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- Смещения блоков. Модернизация права собственности на экологические компенсации. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- О нас
- ускорять
- доступ
- Доступ
- точно
- через
- Действие (Act):
- Добавить
- добавленный
- дополнительный
- После
- AI / ML
- выравнивать
- выравнивание
- позволять
- позволяет
- уже
- am
- Amazon
- Amazon Web Services
- an
- анализ
- Аналитические фармацевтические услуги
- аналитика
- анализировать
- и
- ответ
- любой
- Приложения
- прикладной
- соответствующий
- архитектура
- МЫ
- искусственный
- AS
- аспекты
- связанный
- At
- Атрибуты
- автоматический
- автоматизировать
- автоматически
- избежать
- AWS
- b
- основанный
- BE
- , так как:
- начинать
- Преимущества
- ЛУЧШЕЕ
- встроенный
- бизнес
- бизнес-аналитика
- Бизнес-процесс
- деловые процессы
- но
- by
- Календарь
- призывают
- под названием
- вызова
- камера
- CAN
- захватить
- случаев
- случаев
- Вызывать
- определенный
- изменение
- менялась
- изменения
- изменения
- персонаж
- расходы
- Выберите
- Очистить
- явно
- тесно
- облако
- код
- Column
- выходит
- комиссии
- Общий
- Компании
- Компания
- полный
- Рассматривать
- последовательный
- состоит
- контекст
- исправить
- может
- Создайте
- создали
- создает
- Создающий
- создание
- критической
- Клиенты
- ежедневно
- приборная панель
- щитки
- данным
- Интеграция данных
- Озеро данных
- информационное хранилище
- управляемых данными
- Стратегия, основанная на данных
- База данных
- базы данных
- Время
- Финики
- Дата и время
- день
- глубоко
- глубокое погружение
- По умолчанию
- определяющий
- доставить
- демонстрировать
- ведомства
- Производный
- описывать
- Проект
- проектирование
- подробность
- устройство
- различный
- Размеры
- размеры
- обсуждать
- отчетливый
- распределение
- do
- домен
- сделанный
- Dont
- вниз
- управлять
- дубликаты
- каждый
- Ранее
- легко
- легко
- редактор
- эффективный
- или
- встроенный
- включить
- позволяет
- конец
- впритык
- зацепляет
- инженер
- обеспечивать
- обеспечивает
- обеспечение
- Весь
- организация
- Эфир (ETH)
- События
- События
- Каждая
- каждый день
- пример
- Примеры
- Расширьте
- опыт
- опытные
- Экспозиция
- извлечение
- факт
- фактор
- факторы
- Факты
- не удается
- Ошибка
- Особенности
- несколько
- поле
- Поля
- пятой
- фигура
- фильтр
- окончательный
- Во-первых,
- Впервые
- соответствовать
- внимание
- после
- Что касается
- форма
- формат
- 4
- от
- полностью
- далее
- будущее
- Gain
- порождать
- генерируется
- генерирует
- получить
- получающий
- Дайте
- данный
- хорошо
- управление
- Расти
- удобный
- Есть
- he
- наивысший
- его
- исторический
- Выходные
- Как
- How To
- HTML
- HTTP
- HTTPS
- IAM
- идентифицированный
- определения
- идентифицирующий
- Личность
- if
- иллюстрирует
- Влияние
- осуществлять
- в XNUMX году
- Осуществляющий
- важную
- улучшать
- улучшение
- in
- В том числе
- Индия
- указывать
- с указанием
- info
- размышления
- интегрированный
- интеграции.
- целостность
- Интеллекта
- интерактивный
- в
- IT
- ЕГО
- присоединиться
- присоединился
- присоединение
- Играя
- JPG
- Сохранить
- хранение
- Основные
- ключи
- озеро
- язык
- новее
- последний
- слой
- оставил
- объектив
- Lets
- уровень
- линия
- загрузка
- погрузка
- грузы
- расположенный
- искать
- сделанный
- ДЕЛАЕТ
- управляемого
- Маркетинг
- соответствует
- смысл
- проводить измерение
- упомянутый
- идти
- Метрика
- против
- ошибка
- модель
- моделирование
- моделирование
- Модели
- Месяц
- БОЛЕЕ
- самых
- с разными
- имена
- натуральный
- Откройте
- Необходимость
- нуждающихся
- потребности
- Новые
- Заметки
- уведомление
- Уведомления
- сейчас
- многочисленный
- целей
- of
- предлагают
- .
- on
- только
- оперативный
- or
- организация
- наши
- за
- общий
- параметр
- часть
- страстный
- для
- выполнять
- производительность
- возможно
- периодический
- Часть
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Точка
- населенный
- После
- мощностью
- практика
- предпосылки
- представить
- первичный
- процедуры
- Процедуры
- процесс
- Процессы
- Продукт
- обеспечивать
- при условии
- приводит
- что такое варган?
- публиковать
- целей
- Вопросы
- быстро
- повышение
- Сырье
- необработанные данные
- запись
- учет
- уменьшить
- назвало
- отражает
- область
- отношения
- остатки
- удаление
- замещать
- отчету
- Reporting
- Отчеты
- Требования
- Полезные ресурсы
- ответственность
- Роли
- Катить
- РЯД
- Run
- работает
- sale
- главная
- то же
- Пример набора данных
- масштабируемые
- график
- планирование
- разделах
- сектор
- безопасность
- посмотреть
- отдельный
- служит
- обслуживание
- Услуги
- сессиях
- набор
- несколько
- должен
- показывать
- Шоу
- просто
- простота
- одинарной
- Медленно
- небольшой
- меньше
- Снимок
- So
- проданный
- Решение
- некоторые
- Источник
- Источники
- Space
- специалист
- конкретный
- конкретно
- Этап
- инсценировка
- Звезда
- и политические лидеры
- Начало
- заявление
- Шаг
- Шаги
- диск
- магазин
- хранить
- стратегий
- Стратегия
- Структура
- успешный
- Успешно
- такие
- система
- ТАБЛИЦЫ
- временный
- десятки
- terms
- чем
- который
- Ассоциация
- Источник
- мир
- их
- тогда
- Там.
- следовательно
- Эти
- они
- этой
- тысячи
- Через
- билет
- продажа билетов
- билеты
- время
- раз
- отметка времени
- Советы
- в
- сегодня
- вместе
- приняли
- Всего
- трек
- сделка
- Transform
- преобразован
- путешественник
- напишите
- Типы
- типично
- понимание
- созданного
- общественного.
- уникальность
- неизвестный
- Обновление ПО
- обновление
- us
- Применение
- использование
- прецедент
- используемый
- пользователей
- использования
- через
- обычно
- ценный
- ценностное
- Наши ценности
- различный
- место встречи
- центры
- с помощью
- Вид
- объем
- прохождение
- хотеть
- Склады
- законопроект
- способы
- we
- Web
- веб-сервисы
- веб-сайты
- неделя
- когда
- который
- в то время как
- будете
- в
- без
- работает
- Мир
- Неправильно
- год
- лет
- являетесь
- ВАШЕ
- зефирнет