Многие организации, малые и крупные, работают над миграцией и модернизацией своих аналитических рабочих нагрузок на Amazon Web Services (AWS). У клиентов есть много причин для перехода на AWS, но одна из основных — это возможность использовать полностью управляемые сервисы вместо того, чтобы тратить время на обслуживание инфраструктуры, установку исправлений, мониторинг, резервное копирование и многое другое. Руководители и команды разработчиков могут тратить больше времени на оптимизацию текущих решений и даже экспериментирование с новыми вариантами использования, а не на поддержание текущей инфраструктуры.
Имея возможность быстро развиваться на AWS, вам также необходимо нести ответственность за данные, которые вы получаете и обрабатываете по мере дальнейшего масштабирования. Эти обязанности включают соблюдение законов и правил о конфиденциальности данных, а также отказ от хранения и раскрытия конфиденциальных данных, таких как информация, позволяющая установить личность (PII) или защищенная медицинская информация (PHI), из вышестоящих источников.
В этом посте мы рассмотрим высокоуровневую архитектуру и конкретный вариант использования, который демонстрирует, как вы можете продолжать масштабировать платформу данных вашей организации, не тратя много времени на разработку для решения проблем конфиденциальности данных. Мы используем Клей AWS для обнаружения, маскировки и редактирования данных PII перед их загрузкой в Сервис Amazon OpenSearch.
Обзор решения
На следующей диаграмме показана высокоуровневая архитектура решения. Мы определили все слои и компоненты нашего проекта в соответствии с Объектив анализа данных AWS Well-Architected Framework.
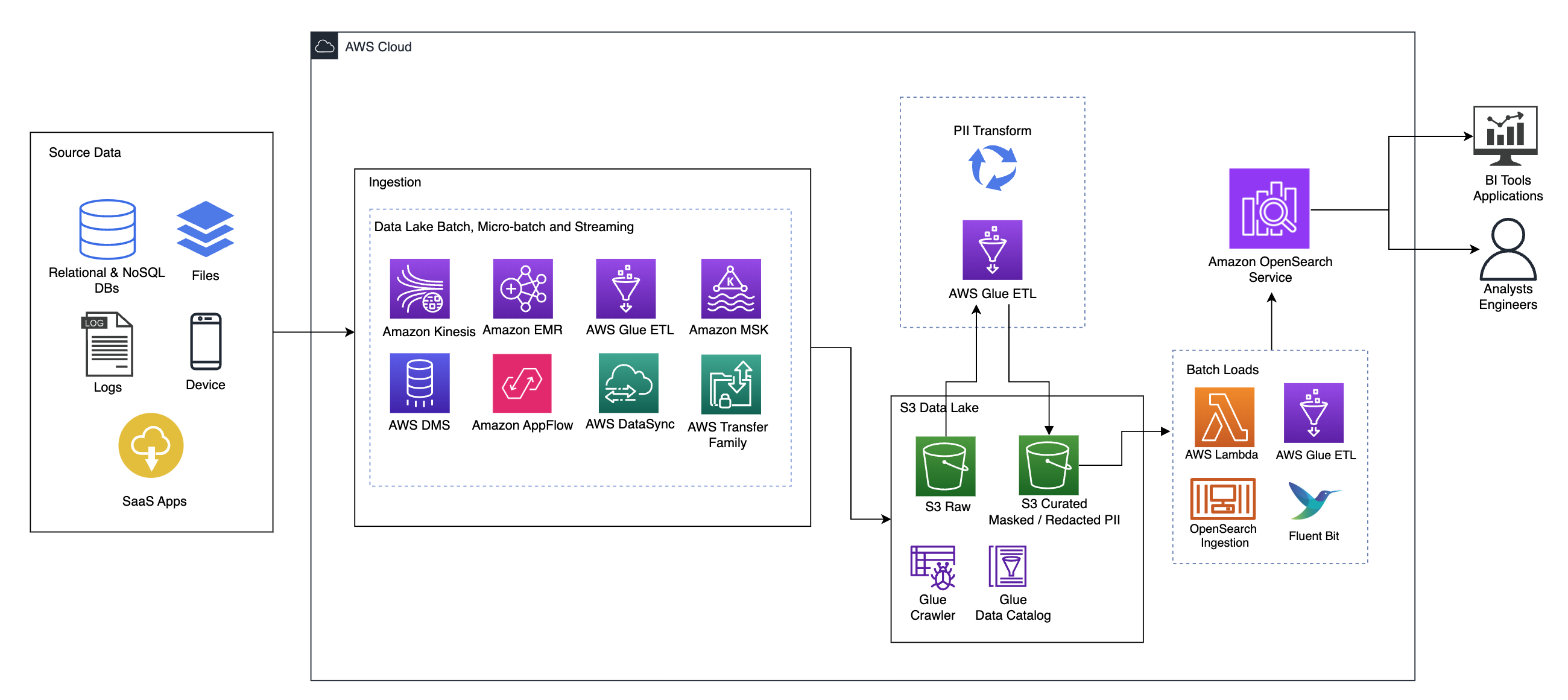
Архитектура состоит из ряда компонентов:
Источник данных
Данные могут поступать из многих десятков или сотен источников, включая базы данных, передачу файлов, журналы, приложения «программное обеспечение как услуга» (SaaS) и многое другое. Организации не всегда могут контролировать, какие данные поступают по этим каналам в их последующие хранилища и приложения.
Прием: пакетная обработка озера данных, микропакетная обработка и потоковая передача.
Многие организации помещают исходные данные в свое озеро данных различными способами, включая пакетные, микропакетные и потоковые задания. Например, Амазонка ЭМИ, Клей AWSи Сервис миграции баз данных AWS (AWS DMS) можно использовать для выполнения пакетных и/или потоковых операций, которые попадают в озеро данных на Простой сервис хранения Amazon (Amazon S3). Поток приложений Amazon может использоваться для передачи данных из различных приложений SaaS в озеро данных. Синхронизация данных AWS и Семейство AWS Transfer может помочь с перемещением файлов в озеро данных и из него по ряду различных протоколов. Амазонка Кинезис и Amazon MSK также имеют возможность передавать данные непосредственно в озеро данных на Amazon S3.
озеро данных S3
Использование Amazon S3 для вашего озера данных соответствует современной стратегии обработки данных. Он обеспечивает недорогое хранилище без ущерба для производительности, надежности и доступности. Благодаря такому подходу вы можете при необходимости использовать вычислительные ресурсы для своих данных и платить только за ту мощность, которая им необходима.
В этой архитектуре необработанные данные могут поступать из различных источников (внутренних и внешних), которые могут содержать конфиденциальные данные.
Используя сканеры AWS Glue, мы можем обнаруживать и каталогизировать данные, которые будут создавать для нас схемы таблиц и, в конечном итоге, упрощать использование AWS Glue ETL с преобразованием PII для обнаружения и маскировки или редактирования любых конфиденциальных данных, которые могли попасть в систему. в озере данных.
Бизнес-контекст и наборы данных
Чтобы продемонстрировать ценность нашего подхода, давайте представим, что вы являетесь частью команды по разработке данных в организации, предоставляющей финансовые услуги. Ваши требования — обнаруживать и маскировать конфиденциальные данные при их попадании в облачную среду вашей организации. Данные будут использоваться последующими аналитическими процессами. В будущем ваши пользователи смогут безопасно искать исторические платежные операции на основе потоков данных, собранных из внутренних банковских систем. Результаты поиска от оперативных групп, клиентов и взаимодействующих приложений должны быть замаскированы в конфиденциальных полях.
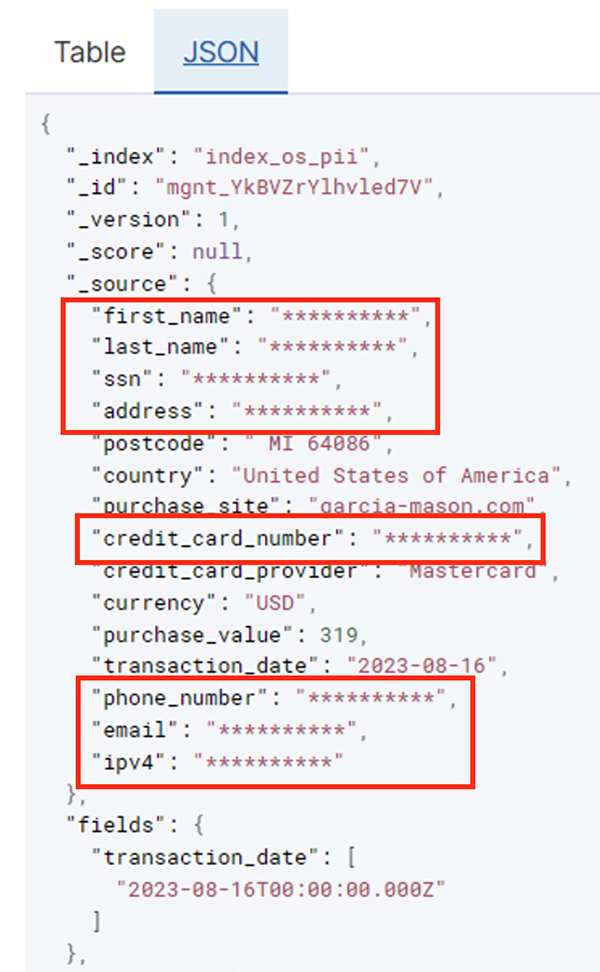
В следующей таблице показана структура данных, используемая для решения. Для ясности мы сопоставили необработанные имена столбцов с рекомендованными. Вы заметите, что несколько полей в этой схеме считаются конфиденциальными данными, такими как имя, фамилия, номер социального страхования (SSN), адрес, номер кредитной карты, номер телефона, адрес электронной почты и адрес IPv4.
| Необработанное имя столбца | Название выбранного столбца | Тип |
| c0 | имя | string |
| c1 | Фамилия | string |
| c2 | ПЛА | string |
| c3 | адрес | string |
| c4 | почтовый индекс | string |
| c5 | страна | string |
| c6 | покупка_сайт | string |
| c7 | Номер кредитной карты | string |
| c8 | кредитная_карта_провайдер | string |
| c9 | валюта | string |
| c10 | Purchase_value | целое |
| c11 | Дата сделки | даты |
| c12 | телефонный номер | string |
| c13 | string | |
| c14 | ipv4 | string |
Вариант использования: обнаружение пакетов PII перед загрузкой в службу OpenSearch.
Клиенты, реализующие следующую архитектуру, создали свое озеро данных на Amazon S3 для запуска различных типов аналитики в больших масштабах. Это решение подходит для клиентов, которым не требуется передача данных в службу OpenSearch в режиме реального времени и которые планируют использовать инструменты интеграции данных, которые запускаются по расписанию или запускаются через события.
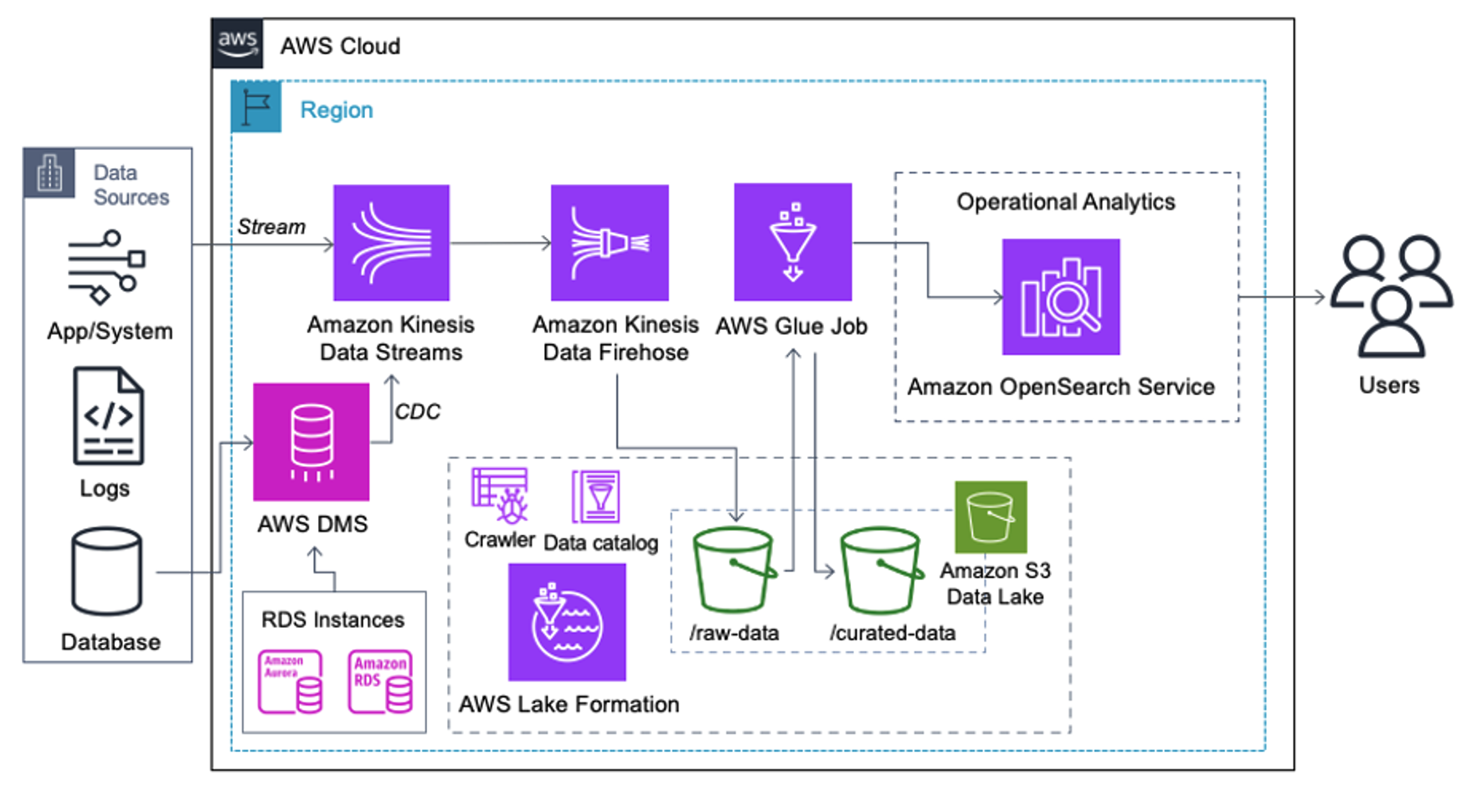
Прежде чем записи данных попадут в Amazon S3, мы реализуем уровень приема, чтобы надежно и безопасно доставлять все потоки данных в озеро данных. Kinesis Data Streams развертывается как уровень приема для ускоренного приема структурированных и полуструктурированных потоков данных. Примерами этого являются изменения в реляционных базах данных, приложениях, системных журналах или потоках посещений. В случаях использования системы отслеживания измененных данных (CDC) вы можете использовать Kinesis Data Streams в качестве цели для AWS DMS. Приложения или системы, генерирующие потоки, содержащие конфиденциальные данные, отправляются в поток данных Kinesis одним из трех поддерживаемых методов: агент Amazon Kinesis, AWS SDK для Java или библиотека Kinesis Producer. В качестве последнего шага Пожарный шланг данных Amazon Kinesis помогает нам надежно загружать пакеты данных практически в реальном времени в наше озеро данных S3.
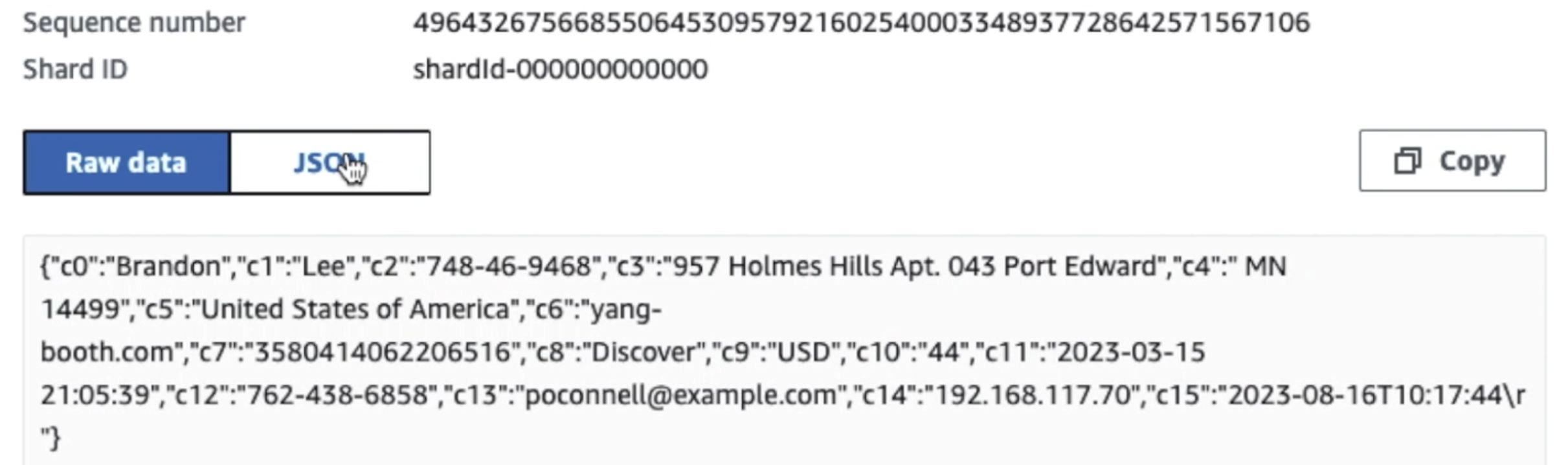
На следующем снимке экрана показано, как данные проходят через Kinesis Data Streams через Средство просмотра данных и извлекает образцы данных, которые попадают в необработанный префикс S3. Для этой архитектуры мы следовали жизненному циклу данных для префиксов S3, как рекомендовано в разделе Основание озера данных.
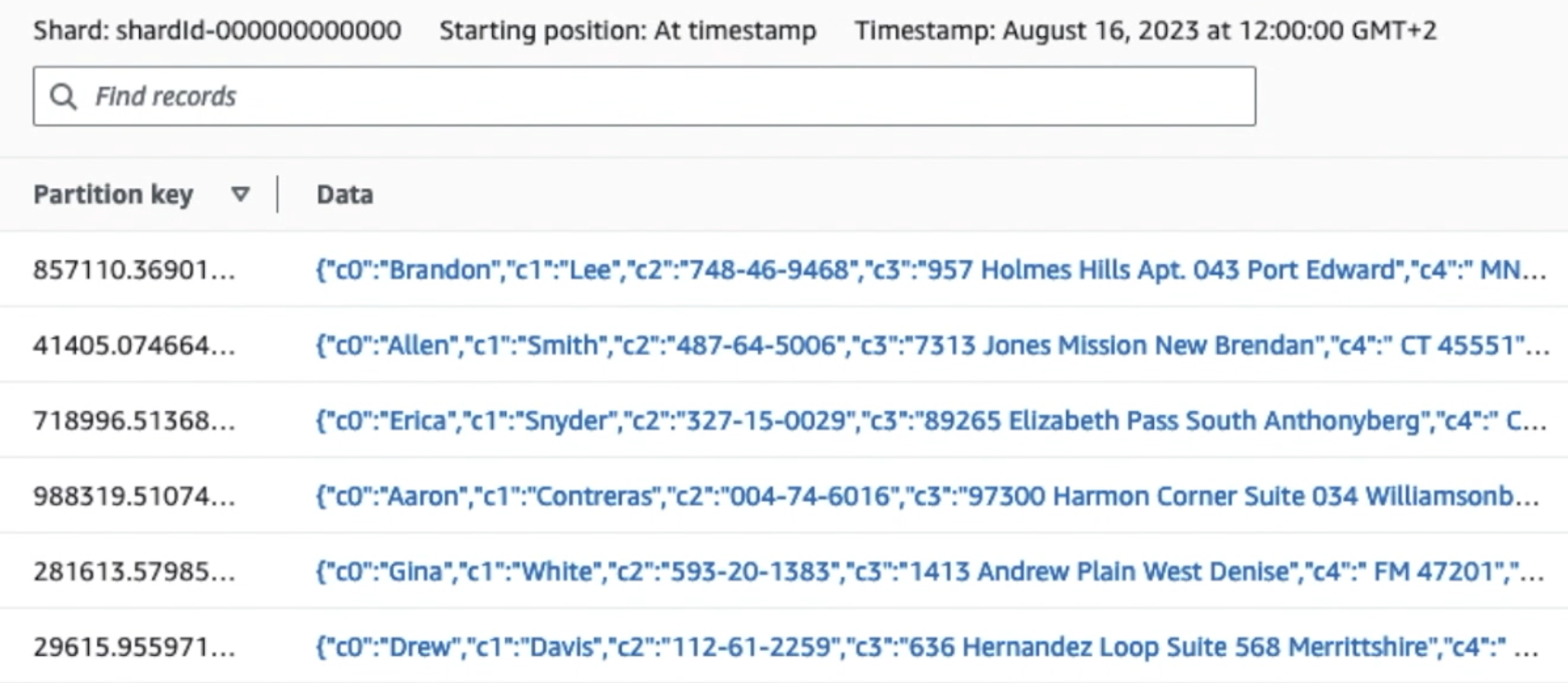
Как видно из деталей первой записи на следующем снимке экрана, полезная нагрузка JSON соответствует той же схеме, что и в предыдущем разделе. Вы можете увидеть неотредактированные данные, поступающие в поток данных Kinesis, которые будут затемнены позже на последующих этапах.
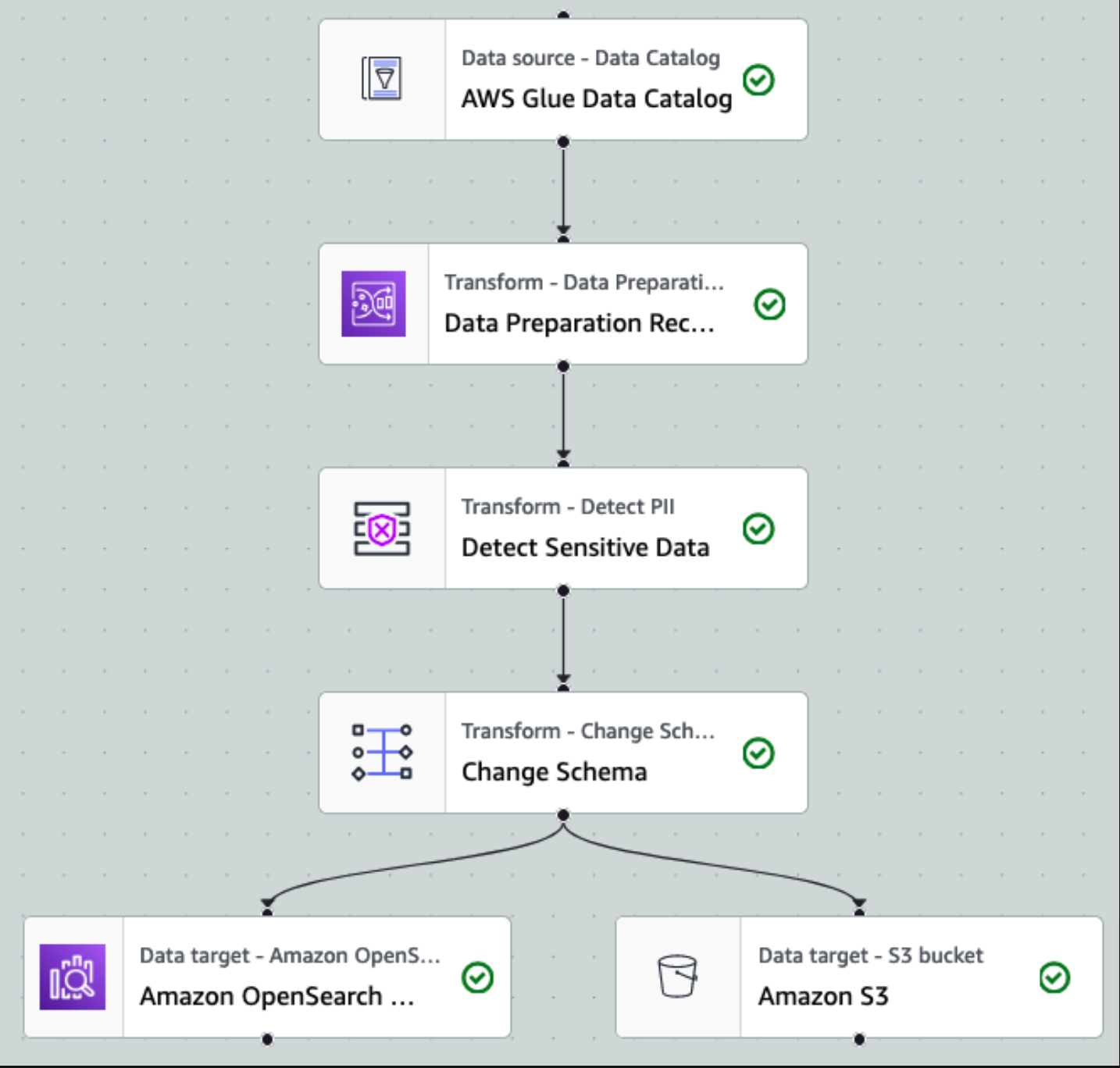
После того как данные собраны и загружены в потоки данных Kinesis и доставлены в корзину S3 с помощью Kinesis Data Firehose, уровень обработки архитектуры берет на себя управление. Мы используем преобразование AWS Glue PII для автоматизации обнаружения и маскировки конфиденциальных данных в нашем конвейере. Как показано на следующей диаграмме рабочего процесса, мы применили визуальный ETL-подход без кода для реализации нашего задания по преобразованию в AWS Glue Studio.
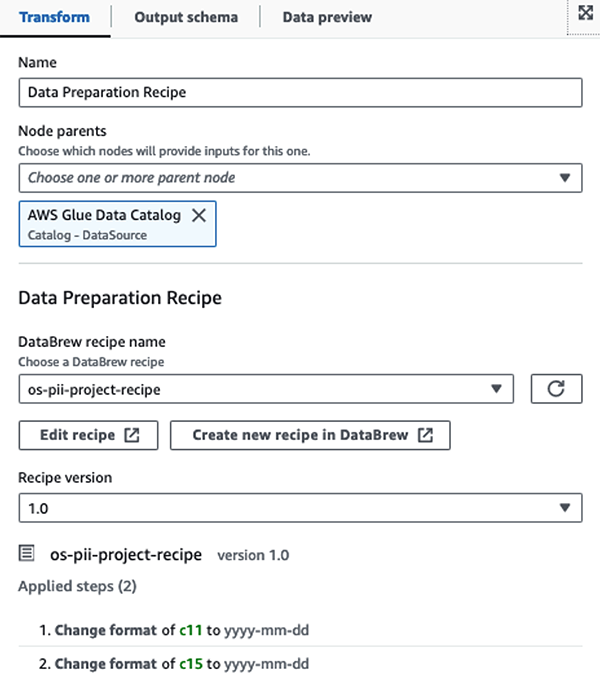
Сначала мы получаем доступ к исходной таблице каталога данных в исходном виде из pii_data_db база данных. Таблица имеет структуру схемы, представленную в предыдущем разделе. Чтобы отслеживать необработанные обработанные данные, мы использовали закладки вакансий.

Мы используем Рецепты AWS Glue DataBrew в визуальном задании ETL AWS Glue Studio чтобы преобразовать два атрибута даты для совместимости с ожидаемым OpenSearch Форматы. Это позволяет нам полностью работать без кода.
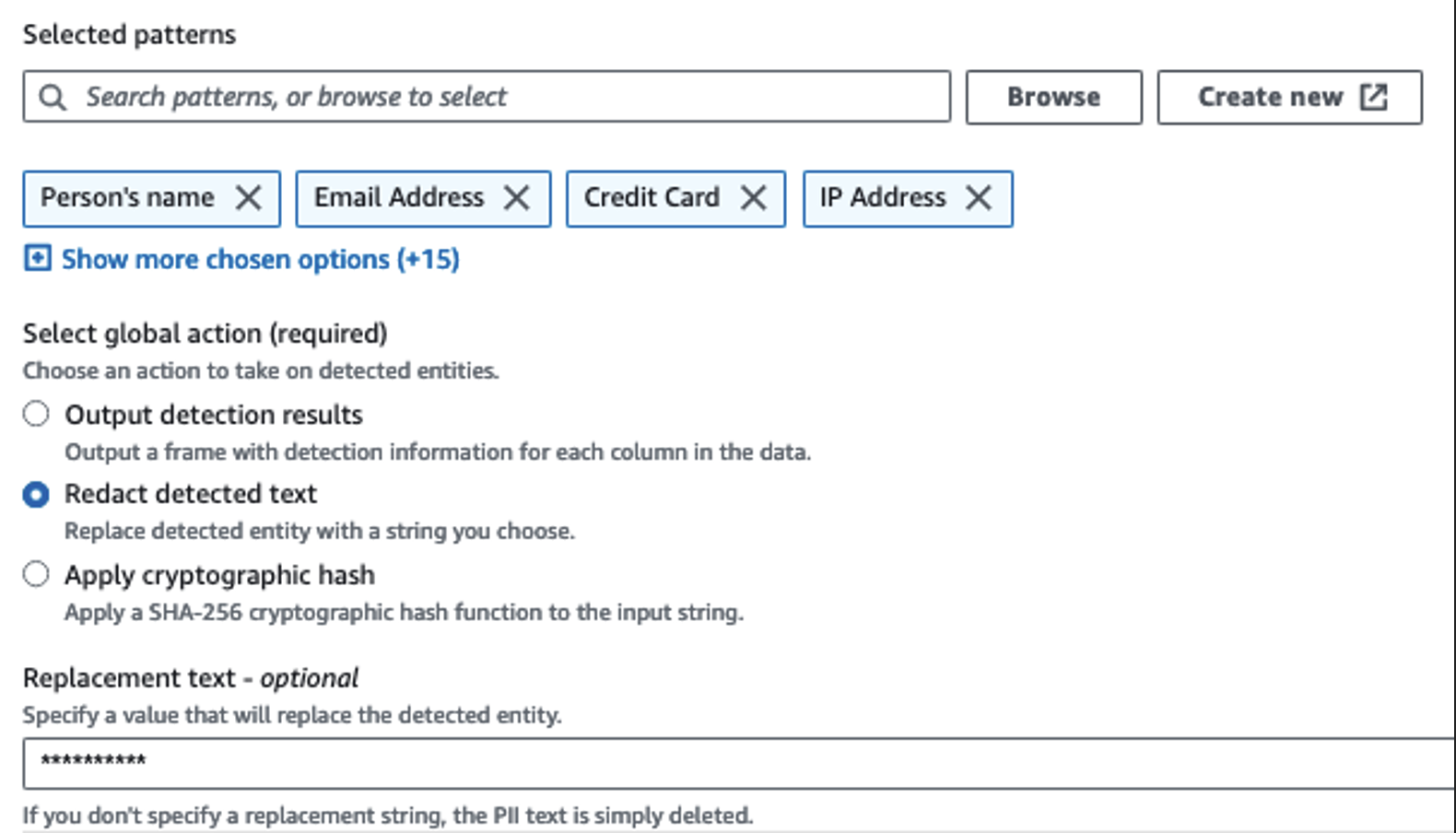
Мы используем действие «Определить личные данные» для определения конфиденциальных столбцов. Мы позволяем AWS Glue определить это на основе выбранных шаблонов, порога обнаружения и выборочной части строк из набора данных. В нашем примере мы использовали шаблоны, которые применимы конкретно к Соединенным Штатам (например, SSN) и могут не обнаруживать конфиденциальные данные из других стран. Вы можете искать доступные категории и местоположения, применимые к вашему варианту использования, или использовать регулярные выражения (регулярные выражения) в AWS Glue, чтобы создавать объекты обнаружения для конфиденциальных данных из других стран.
Важно выбрать правильный метод отбора проб, который предлагает AWS Glue. В этом примере известно, что данные, поступающие из потока, содержат конфиденциальные данные в каждой строке, поэтому нет необходимости выбирать 100% строк в наборе данных. Если у вас есть требование, согласно которому никакие конфиденциальные данные не допускаются к последующим источникам, рассмотрите возможность выборки 100 % данных для выбранных вами шаблонов или отсканируйте весь набор данных и воздействуйте на каждую отдельную ячейку, чтобы гарантировать обнаружение всех конфиденциальных данных. Преимущество, которое вы получаете от выборки, заключается в снижении затрат, поскольку вам не нужно сканировать столько данных.

Действие «Определить личные данные» позволяет выбрать строку по умолчанию при маскировке конфиденциальных данных. В нашем примере мы используем строку **********.
Мы используем операцию сопоставления Apply для переименования и удаления ненужных столбцов, таких как ingestion_year, ingestion_monthи ingestion_day. Этот шаг также позволяет нам изменить тип данных одного из столбцов (purchase_value) из строки в целое число.

С этого момента задание разделяется на два места назначения: OpenSearch Service и Amazon S3.
Наш подготовленный кластер OpenSearch Service подключен через Встроенный соединитель OpenSearch для клея. Мы указываем индекс OpenSearch, в который хотим записать, а соединитель обрабатывает учетные данные, домен и порт. На снимке экрана ниже мы пишем по указанному индексу index_os_pii.
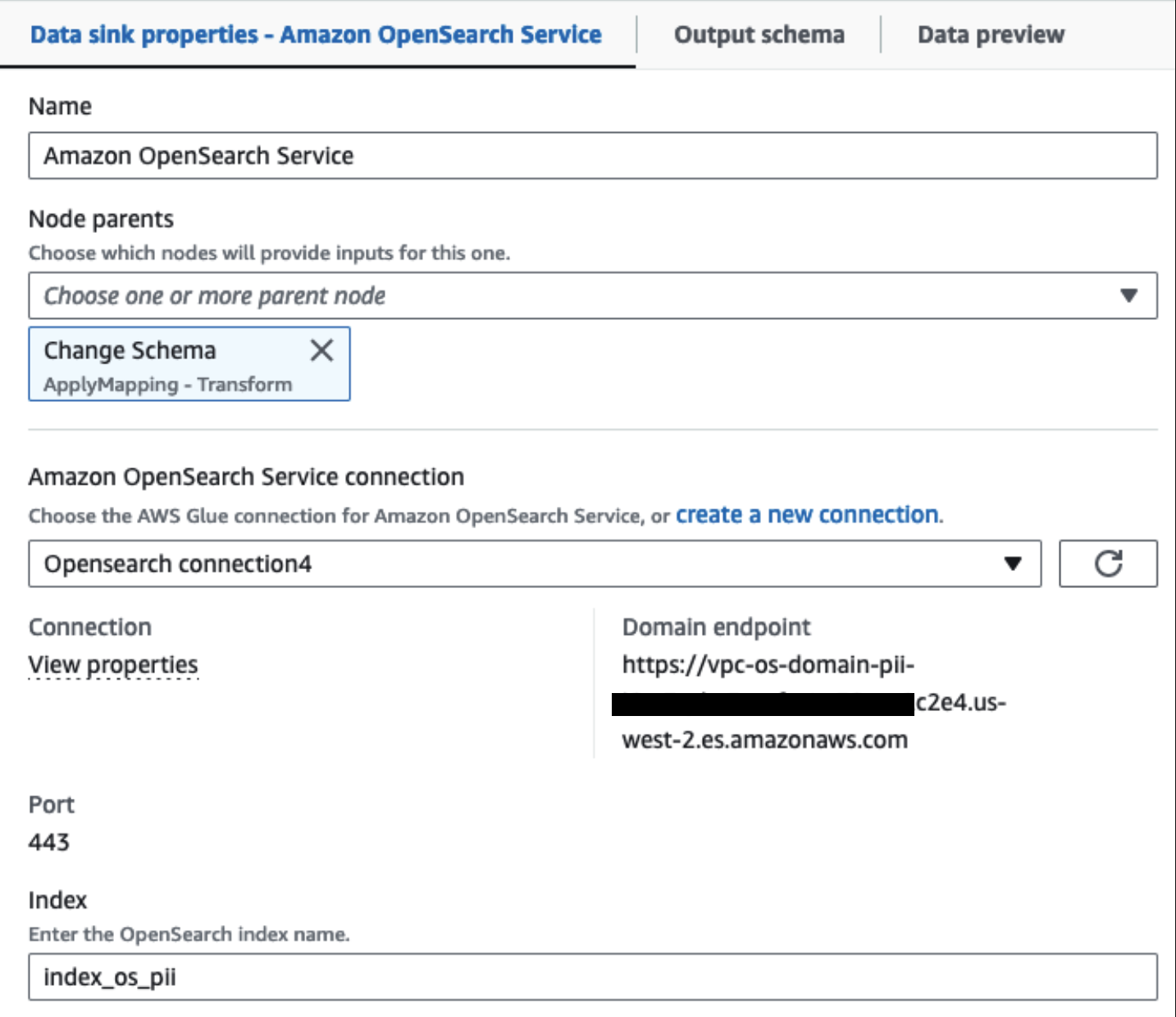
Мы храним замаскированный набор данных в курируемом префиксе S3. Там у нас есть данные, нормализованные для конкретного варианта использования и безопасного использования специалистами по обработке данных или для специальных нужд отчетности.
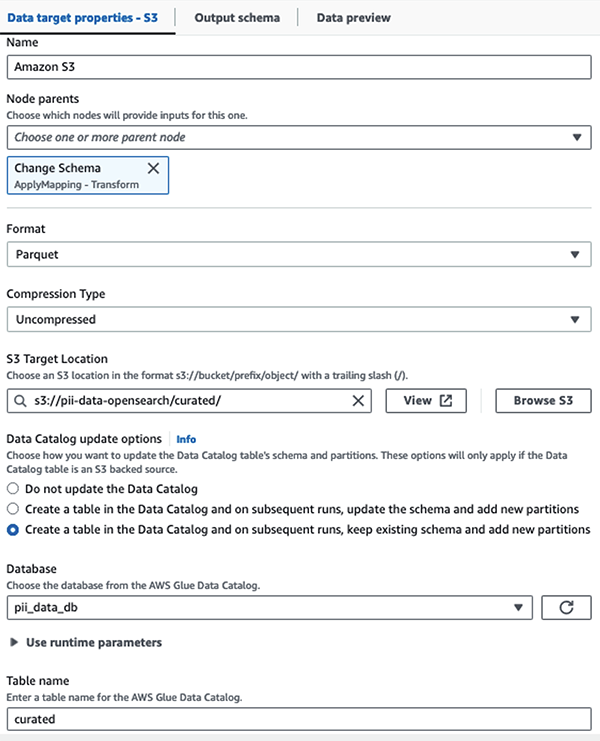
Для унифицированного управления, контроля доступа и отслеживания всех наборов данных и таблиц каталога данных вы можете использовать Формирование озера AWS. Это поможет вам ограничить доступ к таблицам каталога данных AWS Glue и базовым данным только для тех пользователей и ролей, которым предоставлены необходимые для этого разрешения.
После успешного выполнения пакетного задания вы можете использовать службу OpenSearch для выполнения поисковых запросов или отчетов. Как показано на следующем снимке экрана, конвейер автоматически маскирует конфиденциальные поля без каких-либо усилий по разработке кода.

Вы можете определить тенденции на основе операционных данных, таких как количество транзакций в день, отфильтрованных по поставщику кредитных карт, как показано на предыдущем снимке экрана. Вы также можете определить места и домены, где пользователи совершают покупки. transaction_date Атрибут помогает нам увидеть эти тенденции с течением времени. На следующем снимке экрана показана запись со всей информацией о транзакции, отредактированной соответствующим образом.
Альтернативные методы загрузки данных в Amazon OpenSearch см. Загрузка потоковых данных в Amazon OpenSearch Service.
Кроме того, конфиденциальные данные также можно обнаружить и замаскировать с помощью других решений AWS. Например, вы можете использовать Амазонка Мэйси для обнаружения конфиденциальных данных внутри корзины S3, а затем используйте Amazon Comprehend для редактирования обнаруженных конфиденциальных данных. Для получения дополнительной информации см. Общие методы обнаружения данных PHI и PII с помощью сервисов AWS.
Заключение
В этом посте обсуждалась важность обработки конфиденциальных данных в вашей среде, а также различные методы и архитектуры, чтобы обеспечить соответствие требованиям, а также обеспечить быстрое масштабирование вашей организации. Теперь вы должны хорошо понимать, как обнаруживать, маскировать или редактировать и загружать ваши данные в Amazon OpenSearch Service.
Об авторах
 Майкл Гамильтон — старший архитектор аналитических решений, который помогает корпоративным клиентам модернизировать и упростить аналитические рабочие нагрузки на AWS. Ему нравится кататься на горном велосипеде и проводить время с женой и тремя детьми, когда он не работает.
Майкл Гамильтон — старший архитектор аналитических решений, который помогает корпоративным клиентам модернизировать и упростить аналитические рабочие нагрузки на AWS. Ему нравится кататься на горном велосипеде и проводить время с женой и тремя детьми, когда он не работает.
 Даниэль Розо — старший архитектор решений компании AWS, поддерживающей клиентов в Нидерландах. Его страстью является разработка простых решений для обработки данных и аналитики, а также помощь клиентам в переходе на современные архитектуры данных. Вне работы он любит играть в теннис и кататься на велосипеде.
Даниэль Розо — старший архитектор решений компании AWS, поддерживающей клиентов в Нидерландах. Его страстью является разработка простых решений для обработки данных и аналитики, а также помощь клиентам в переходе на современные архитектуры данных. Вне работы он любит играть в теннис и кататься на велосипеде.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :имеет
- :является
- :нет
- :куда
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- способность
- в состоянии
- ускоренный
- доступ
- Действие (Act):
- Действие
- Ad
- адрес
- Агент
- Все
- разрешено
- Позволяющий
- позволяет
- причислены
- всегда
- Amazon
- Амазонка Кинезис
- Amazon Web Services
- Веб-службы Amazon (AWS)
- количество
- суммы
- an
- Аналитические фармацевтические услуги
- аналитика
- и
- любой
- отношение
- Приложения
- Применить
- подхода
- надлежащим образом
- архитектура
- МЫ
- AS
- At
- Атрибуты
- аудит
- автоматизировать
- автоматически
- свободных мест
- доступен
- AWS
- Клей AWS
- Операции резервного копирования
- Банковское дело
- Банковские системы
- основанный
- BE
- , так как:
- было
- до
- не являетесь
- ниже
- польза
- приносить
- строить
- построенный
- встроенный
- но
- by
- CAN
- возможности
- Пропускная способность
- захватить
- карта
- случаев
- случаев
- каталог
- категории
- CDC
- ячейка
- изменение
- изменения
- каналы
- Дети
- выбрал
- ясность
- облако
- Кластер
- код
- Column
- Колонки
- как
- выходит
- приход
- совместим
- уступчивый
- компоненты
- Состоит
- Вычисление
- Обеспокоенность
- подключенный
- Рассматривать
- считается
- потребленный
- потребление
- содержать
- контекст
- продолжать
- контроль
- исправить
- Расходы
- может
- страны
- Создайте
- Полномочия
- кредит
- кредитная карта
- Куратор
- Текущий
- Клиенты
- данным
- Анализ данных
- Интеграция данных
- Озеро данных
- Платформа данных
- конфиденциальность данных
- стратегия данных
- База данных
- базы данных
- Наборы данных
- Время
- день
- По умолчанию
- определенный
- поставляется
- демонстрировать
- демонстрирует
- развернуть
- Проект
- назначение
- направления
- подробнее
- обнаруживать
- обнаруженный
- обнаружение
- Определять
- Развитие
- команды разработчиков
- различный
- непосредственно
- обнаружить
- открытый
- обсуждается
- do
- домен
- доменов
- Dont
- каждый
- усилия
- Проект и
- обеспечивать
- Предприятие
- корпоративные клиенты
- Весь
- лиц
- Окружающая среда
- Эфир (ETH)
- Даже
- События
- Каждая
- пример
- Примеры
- ожидаемый
- опыт
- выражения
- и, что лучший способ
- БЫСТРО
- Поля
- Файл
- Файлы
- финансовый
- финансовые услуги
- First
- текущий
- Потоки
- фокусировка
- следует
- после
- следующим образом
- Что касается
- Рамки
- от
- полный
- полностью
- будущее
- порождающий
- получить
- хорошо
- управление
- предоставленный
- Ручки
- Управляемость
- Есть
- he
- Медицина
- информация о здоровье
- помощь
- помощь
- помогает
- на высшем уровне
- его
- исторический
- Как
- How To
- HTML
- HTTP
- HTTPS
- Сотни
- определения
- if
- иллюстрирует
- картина
- осуществлять
- значение
- важную
- in
- включают
- В том числе
- индекс
- individual
- информация
- Инфраструктура
- внутри
- интеграции.
- в нашей внутренней среде,
- в
- IT
- Java
- работа
- Джобс
- JPG
- JSON
- Сохранить
- Пожарный шланг Kinesis Data
- Потоки данных Kinesis
- известный
- озеро
- Земля
- земли
- большой
- Фамилия
- новее
- Законодательство
- Законы и правила
- слой
- слоев
- Наша команда
- позволять
- Библиотека
- Жизненный цикл
- такое как
- линия
- загрузка
- погрузка
- места
- посмотреть
- бюджетный
- Главная
- сохранение
- сделать
- управляемого
- многих
- отображение
- маска
- Май..
- метод
- методы
- мигрировать
- миграция
- Модерн
- модернизировать
- Мониторинг
- БОЛЕЕ
- гора
- двигаться
- перемещение
- много
- с разными
- должен
- имя
- имена
- необходимо
- Необходимость
- необходимый
- нуждающихся
- потребности
- Нидерланды
- Новые
- нет
- узлы
- Уведомление..
- сейчас
- номер
- of
- Предложения
- on
- ONE
- только
- операция
- оперативный
- Операционный отдел
- оптимизирующий
- Опции
- or
- организация
- организации
- Другое
- наши
- выходной
- внешнюю
- за
- часть
- страсть
- Заделка
- паттеранами
- ОПЛАТИТЬ
- оплата
- для
- выполнять
- производительность
- Разрешения
- Лично
- Телефон
- PII
- трубопровод
- план
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- Точка
- часть
- После
- предшествующий
- представлены
- предыдущий
- политикой конфиденциальности.
- законы о конфиденциальности
- обрабатываемых
- Процессы
- обработка
- производитель
- защищенный
- протоколы
- Недвижимости
- приводит
- Покупка
- Запросы
- быстро
- скорее
- Сырье
- необработанные данные
- реального времени
- причины
- получение
- Рецепты
- Управление по борьбе с наркотиками (DEA)
- запись
- учет
- Цена снижена
- относиться
- регулярный
- правила
- надежность
- оставаться
- удаление
- Reporting
- Отчеты
- требовать
- требование
- Требования
- ответственности
- ответственный
- ограничивать
- Итоги
- роли
- РЯД
- Run
- работает
- SaaS
- пожертвовав
- безопасный
- безопасно
- то же
- Шкала
- сканирование
- график
- Ученые
- экран
- SDK
- Поиск
- Раздел
- безопасно
- безопасность
- посмотреть
- выберите
- выбранный
- старший
- чувствительный
- послать
- обслуживание
- Услуги
- выстрел
- должен
- показанный
- Шоу
- просто
- упростить
- небольшой
- So
- Соцсети
- Software
- программное обеспечение как услуга
- Решение
- Решения
- Источник
- Источники
- конкретный
- конкретно
- указанный
- тратить
- Расходы
- расколы
- этапы
- Области
- Шаг
- диск
- магазин
- простой
- Стратегия
- поток
- потоковый
- потоки
- строка
- Структура
- структурированный
- студия
- последующее
- Успешно
- такие
- подходящее
- Поддержанный
- поддержки
- система
- системы
- ТАБЛИЦЫ
- принимает
- цель
- команда
- команды
- снижения вреда
- теннис
- десятки
- чем
- который
- Ассоциация
- Будущее
- Нидерланды
- Источник
- их
- тогда
- Там.
- Эти
- этой
- те
- три
- порог
- Через
- время
- в
- приняли
- инструменты
- трек
- Сделки
- перевод
- переводы
- Transform
- трансформация
- Тенденции
- срабатывает
- два
- напишите
- Типы
- В конечном счете
- лежащий в основе
- понимание
- унифицированный
- Объединенный
- США
- us
- использование
- прецедент
- используемый
- пользователей
- через
- ценностное
- разнообразие
- различный
- с помощью
- визуальный
- от
- законопроект
- способы
- we
- Web
- веб-сервисы
- Что
- когда
- который
- в то время как
- КТО
- жена
- будете
- в
- без
- Работа
- рабочий
- работает
- записывать
- являетесь
- ВАШЕ
- зефирнет