Автоматизированный анализ данных (ADA) на AWS — это решение AWS, позволяющее за считанные минуты извлекать полезные сведения из данных с помощью простого и интуитивно понятного пользовательского интерфейса. ADA предлагает собственную платформу анализа данных AWS, готовую к использованию аналитиками данных в самых разных случаях. С помощью ADA команды могут получать, преобразовывать, управлять и запрашивать разнообразные наборы данных из различных источников данных, не требуя специальных технических навыков. ADA предоставляет набор готовые соединители получать данные из различных источников, включая Простой сервис хранения Amazon (Амазон С3), Потоки данных Amazon Kinesis, Amazon CloudWatch, Amazon CloudTrailи Amazon DynamoDB а также многие другие.
ADA предоставляет базовую платформу, которую аналитики данных могут использовать в самых разных случаях, включая ИТ, финансы, маркетинг, продажи и безопасность. Готовый коннектор данных CloudWatch ADA позволяет получать данные из журналов CloudWatch в той же учетной записи AWS, в которой развернута ADA, или из другой учетной записи AWS.
В этом посте мы покажем, как разработчик или тестировщик приложений может использовать ADA для получения оперативной информации о приложениях, работающих в AWS. Мы также покажем, как можно использовать решение ADA для подключения к различным источникам данных в AWS. Мы первые развернуть решение ADA в аккаунт AWS и настроить решение ADA создавая данные продукты с помощью коннекторов данных. Затем мы используем ADA Query Workbench, чтобы объединить отдельные наборы данных и запросить коррелированные данные, используя знакомый язык структурированных запросов (SQL), чтобы получить представление. Мы также демонстрируем, как ADA можно интегрировать с инструментами бизнес-аналитики (BI), такими как Tableau, для визуализации данных и создания отчетов.
Обзор решения
В этом разделе мы представляем архитектуру решения для демонстрации и объясняем рабочий процесс. В демонстрационных целях специальное приложение моделируется с использованием AWS Lambda функция, которая выдает логи Формат журнала Apache с заданным интервалом с помощью Amazon EventBridge. Этот стандартный формат может создаваться множеством различных веб-серверов и считываться многими программами анализа журналов. Журналы приложения (функция Lambda) отправляются в группу журналов CloudWatch. Исторические журналы приложений хранятся в корзине S3 для справки и запросов. Справочная таблица со списком Коды статуса HTTP вместе с описаниями хранится в таблице DynamoDB. Эти три служат источниками, из которых данные поступают в ADA для корреляции, запросов и анализа. Мы развернуть решение ADA в аккаунт AWS и настроить АДА. Затем мы создаем данные продукты в рамках АДА для Группа журналов CloudWatch, Ковш S3и DynamoDB. По мере настройки продуктов данных ADA подготавливает конвейеры данных для приема данных из источников. С помощью ADA Query Workbench вы можете запрашивать полученные данные с помощью простого SQL для устранения неполадок приложений или диагностики проблем.
На следующей диаграмме представлен обзор архитектуры и рабочего процесса использования ADA для получения информации о журналах приложений.
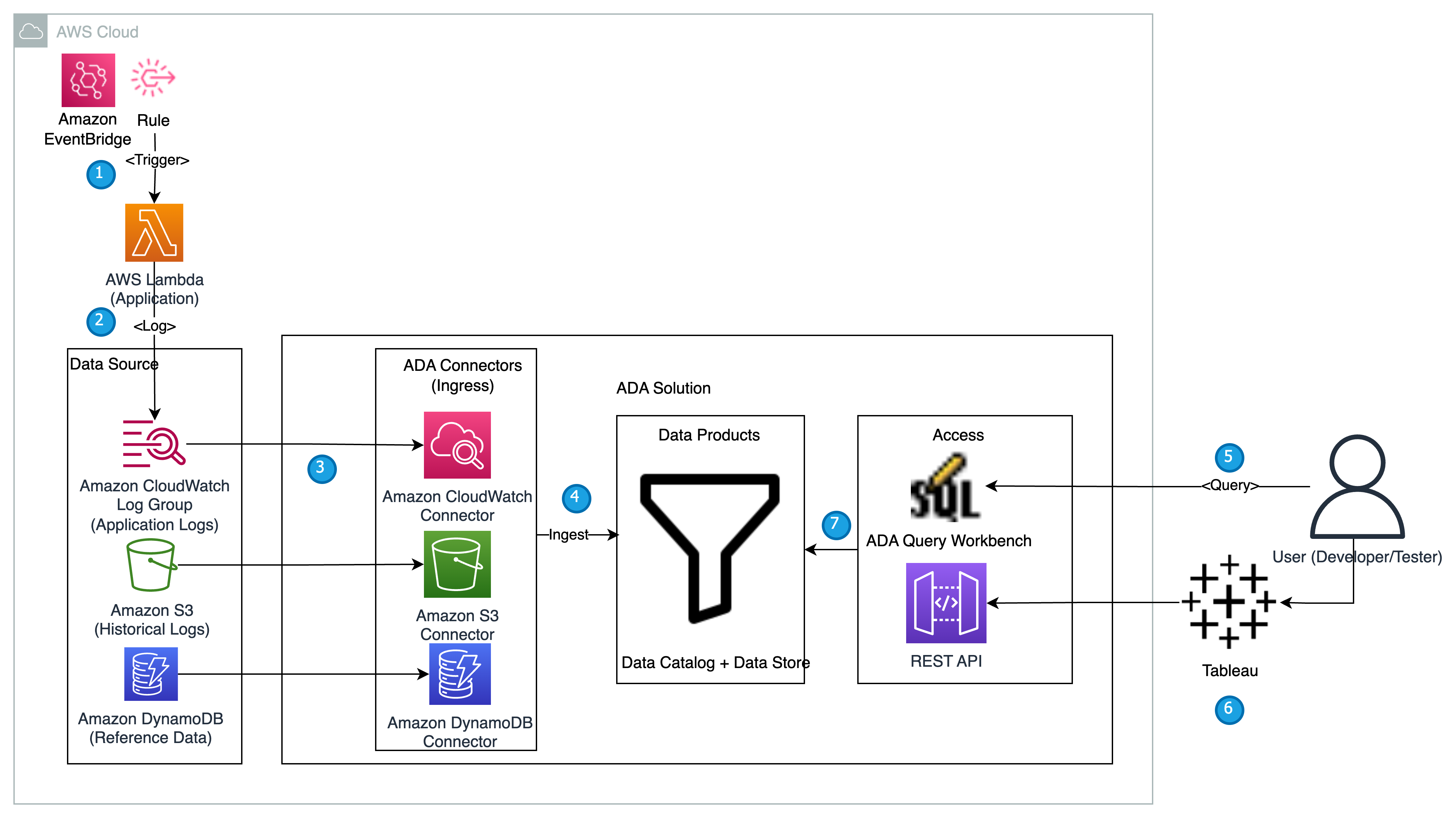
Рабочий процесс включает в себя следующие шаги:
- Функция Lambda должна запускаться с интервалом в 2 минуты с помощью EventBridge.
- Функция Lambda создает журналы, которые хранятся в указанной группе журналов CloudWatch в разделе
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Журналы приложений создаются с использованием схемы формата журнала Apache, но сохраняются в группе журналов CloudWatch в формате JSON. - Продукты данных для CloudWatch, Amazon S3 и DynamoDB создаются в ADA. Продукт данных CloudWatch подключается к группе журналов CloudWatch, в которой хранятся журналы приложения (функция Lambda). Соединитель Amazon S3 подключается к папке корзины S3, в которой хранятся исторические журналы. Соединитель DynamoDB подключается к таблице DynamoDB, где хранятся коды состояния, на которые ссылается приложение, и журналы истории.
- Для каждого продукта данных ADA развертывает инфраструктуру конвейера данных для приема данных из источников. Когда прием данных завершен, вы можете писать запросы с использованием SQL через ADA Query Workbench.
- Вы можете войти на портал ADA и составить SQL-запросы из Query Workbench, чтобы получить представление о журналах приложений. При желании вы можете сохранить запрос и поделиться им с другими пользователями ADA в том же домене. Функция запроса ADA основана на Амазонка Афина, который представляет собой бессерверную интерактивную аналитическую службу, предоставляющую упрощенный и гибкий способ анализа петабайт данных.
- Tableau настроен на доступ к продуктам данных ADA через конечные точки выхода ADA. Затем вы создаете информационную панель с двумя диаграммами. Первая диаграмма представляет собой тепловую карту, которая показывает распространенность кодов ошибок HTTP, связанных с конечными точками API приложения. Вторая диаграмма представляет собой столбчатую диаграмму, которая показывает 10 основных API-интерфейсов приложений с общим количеством кодов ошибок HTTP из исторических данных.
Предпосылки
Для этого поста вам необходимо выполнить следующие предварительные условия:
- Установить Интерфейс командной строки AWS (интерфейс командной строки AWS), Комплект для разработки облачных сервисов AWS (ЦДК АМС) предпосылки, специфичный для TypeScript предпосылкии мерзавец.
- Развертывание решение ADA в вашей учетной записи AWS в
us-east-1Область.- Укажите адрес электронной почты администратора при запуске ADA. AWS CloudFormation куча. Это необходимо для того, чтобы ADA отправила пароль пользователя root. Телефонный номер администратора требуется для получения сообщения с одноразовым паролем, если включена многофакторная аутентификация (MFA). Для этой демонстрации MFA не включен.
- Соберите и разверните пример приложения (доступно на Репо GitHub) решение, чтобы следующие ресурсы могли быть предоставлены в вашей учетной записи в
us-east-1Область:- Функция Lambda, имитирующая приложение для ведения журнала, и правило EventBridge, которое вызывает функцию приложения с двухминутными интервалами.
- Сегмент S3 с соответствующими политиками сегментов и CSV-файл, содержащий исторические журналы приложений.
- Таблица DynamoDB с данными поиска.
- Соответствующий Управление идентификацией и доступом AWS (IAM) роли и разрешения, необходимые для служб.
- При желании установите Tableau Desktop, сторонний поставщик бизнес-аналитики. Для этого поста мы используем Tableau Desktop версии 2021.2. За использование лицензионной версии приложения Tableau Desktop взимается плата. Для получения дополнительной информации см. Лицензирование таблиц Информация.
Развертывание и настройка ADA
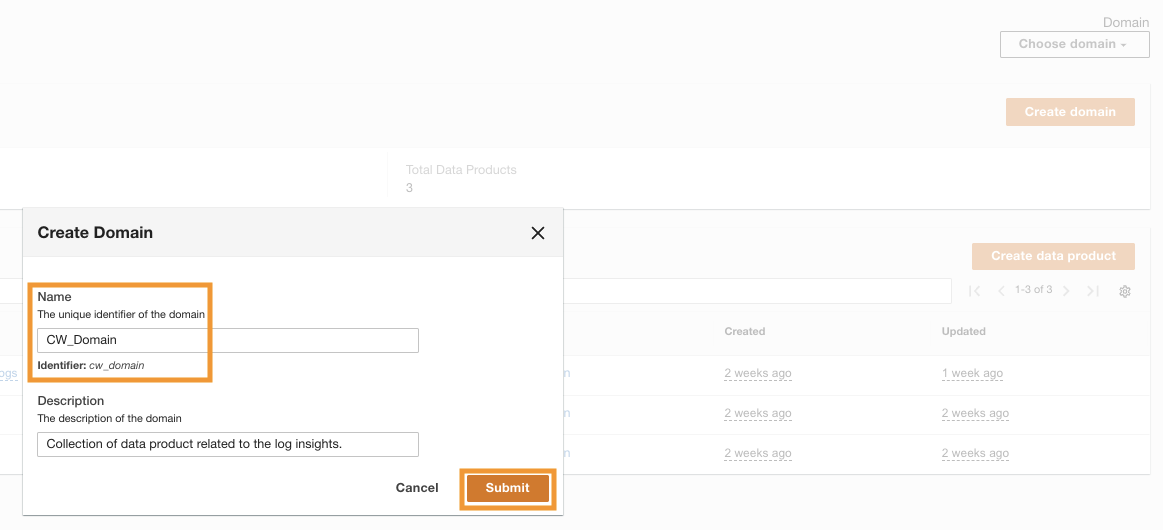
После успешного развертывания ADA вы можете авторизоваться используя адрес электронной почты администратора, указанный во время установки. Затем вы создаете домен названный CW_Domain. Домен — это определяемый пользователем набор продуктов данных. Например, домен может быть командой или проектом. Домены предоставляют пользователям структурированный способ организации своих продуктов данных и управления разрешениями на доступ.
- В консоли ADA выберите Домены в навигационной панели.
- Выберите Создать домен.
- Введите имя (
CW_Domain) и описание, затем выберите Отправить.
Настройте инфраструктуру примера приложения с помощью AWS CDK.
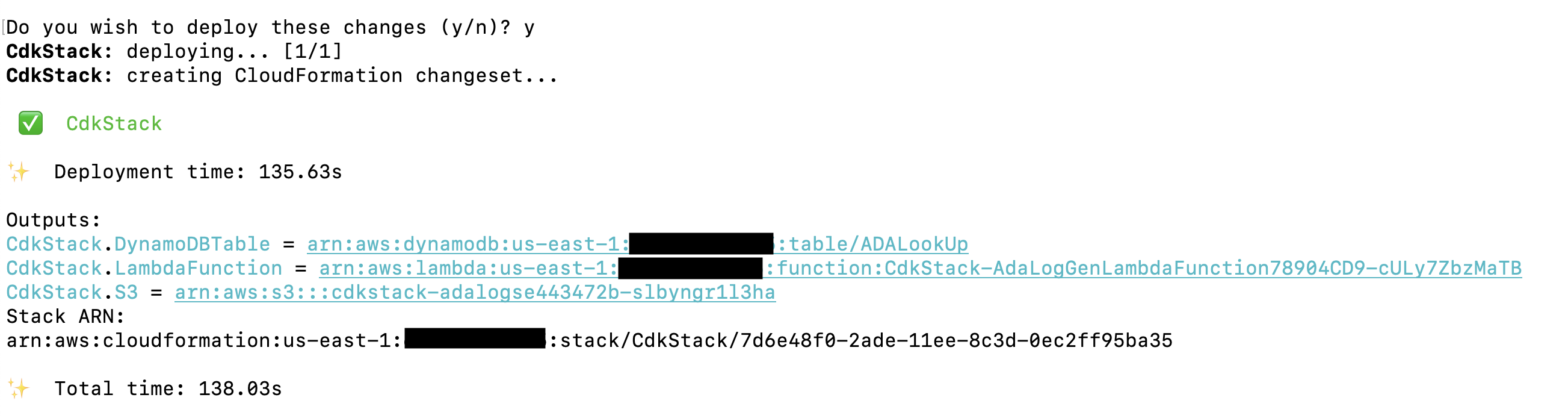
Решение AWS CDK, которое развертывает демонстрационное приложение, размещено на GitHub. В этом разделе подробно описаны шаги по клонированию репозитория и настройке проекта AWS CDK. Прежде чем запускать эти команды, обязательно конфигурировать ваши учетные данные AWS. Создайте папку, откройте терминал и перейдите в папку, в которую необходимо установить решение AWS CDK. Запустите следующий код:
Эти шаги выполняют следующие действия:
- Установите зависимости библиотеки
- Построить проект
- Создайте действительный шаблон CloudFormation
- Разверните стек с помощью AWS CloudFormation в своей учетной записи AWS.
Развертывание занимает около 1–2 минут и создает таблицу поиска DynamoDB, функцию Lambda и корзину S3, содержащую файлы журналов истории в качестве выходных данных. Скопируйте эти значения в приложение для редактирования текста, например Блокнот.
Создание продуктов данных ADA
Для этой демонстрации мы создаем три разных продукта данных, по одному для каждого источника данных, к которому вы будете запрашивать операционную информацию. Продукт данных — это набор данных (набор данных, таких как таблица или файл CSV), который был успешно импортирован в ADA и к которому можно запросить.
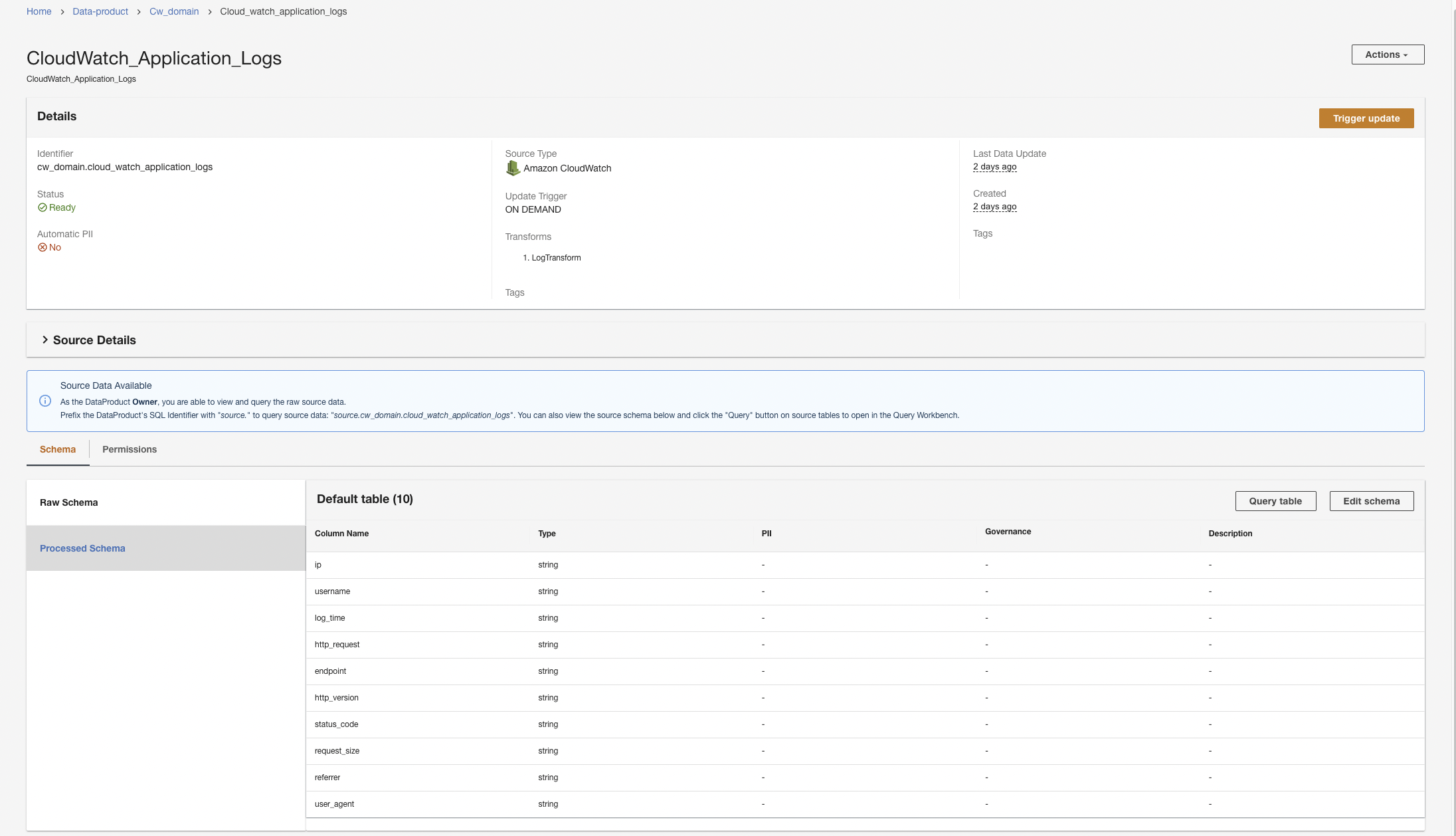
Создайте продукт данных CloudWatch
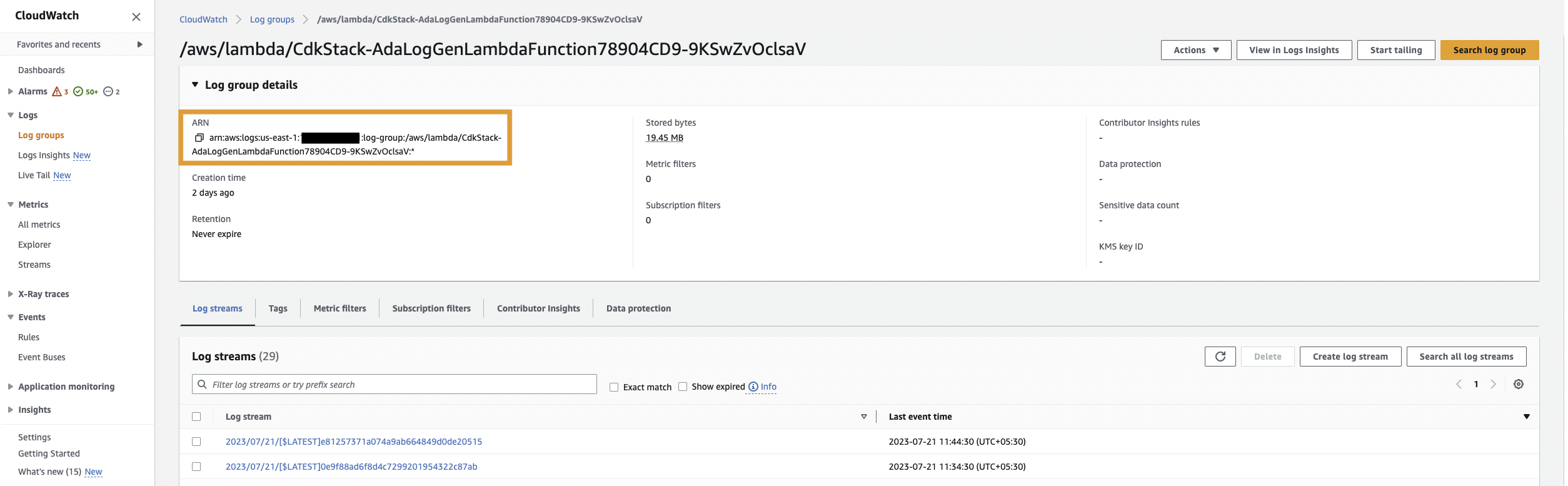
Сначала мы создаем продукт данных для журналов приложений, настроив ADA для приема группы журналов CloudWatch для примера приложения (функция Lambda). Использовать CdkStack.LambdaFunction output, чтобы получить ARN функции Lambda и найти соответствующую группу журналов CloudWatch ARN на консоли CloudWatch.
Затем выполните следующие действия:
- В консоли ADA перейдите в домен ADA и создайте продукт данных CloudWatch.
- Что касается Имя¸ введите имя.
- Что касается Тип источника, укажите Amazon CloudWatch.
- Отключить Автоматическая персональная информация.
В ADA есть функция, которая автоматически обнаруживает данные личной информации (PII) во время импорта, которая включена по умолчанию. Для этой демонстрации мы отключили эту опцию для продукта данных, поскольку обнаружение данных PII не входит в область этой демонстрации.
- Выберите Следующая.
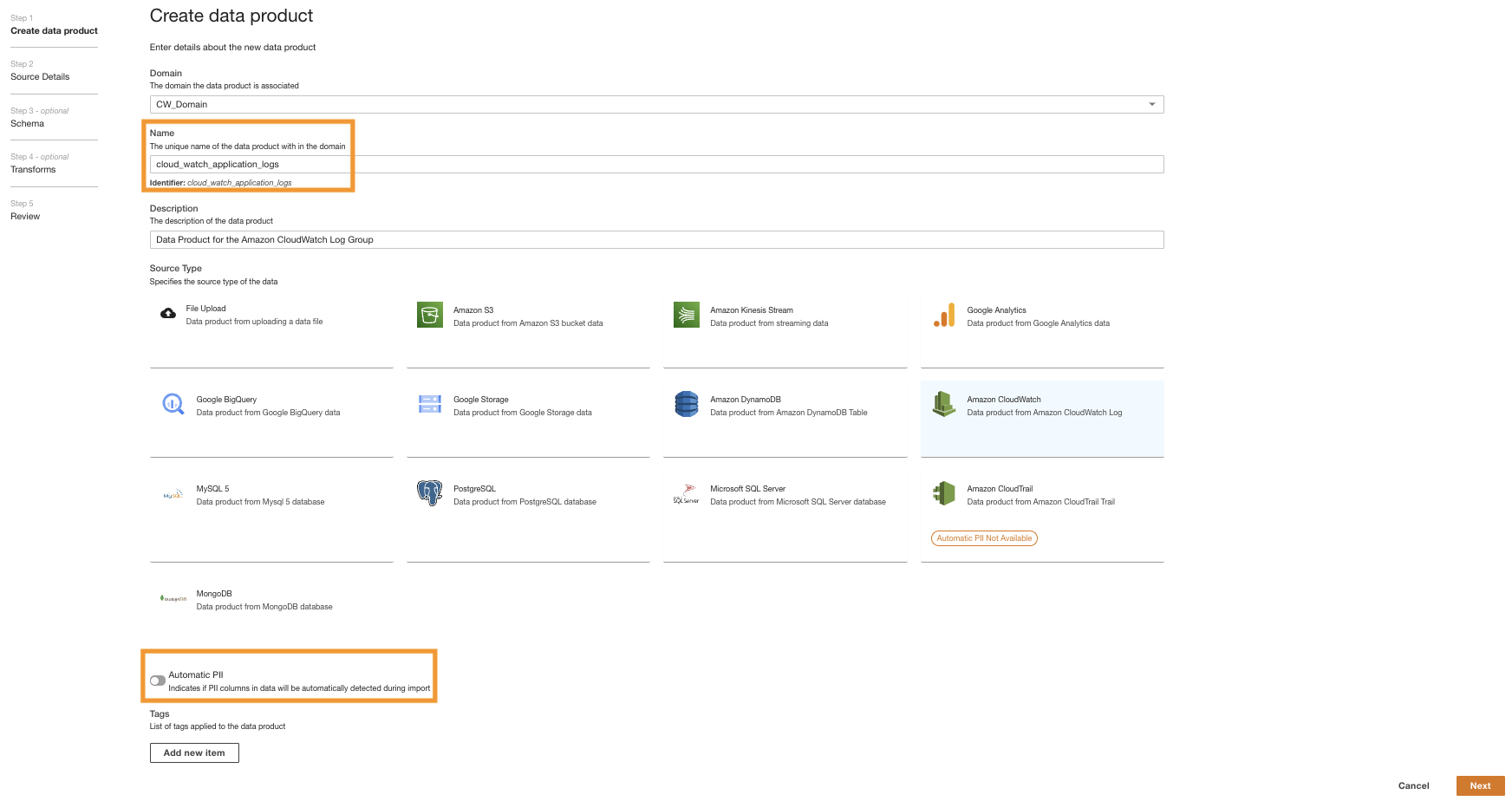
- Найдите и выберите ARN группы журналов CloudWatch, скопированный с предыдущего шага.

- Скопируйте группу журналов ARN.
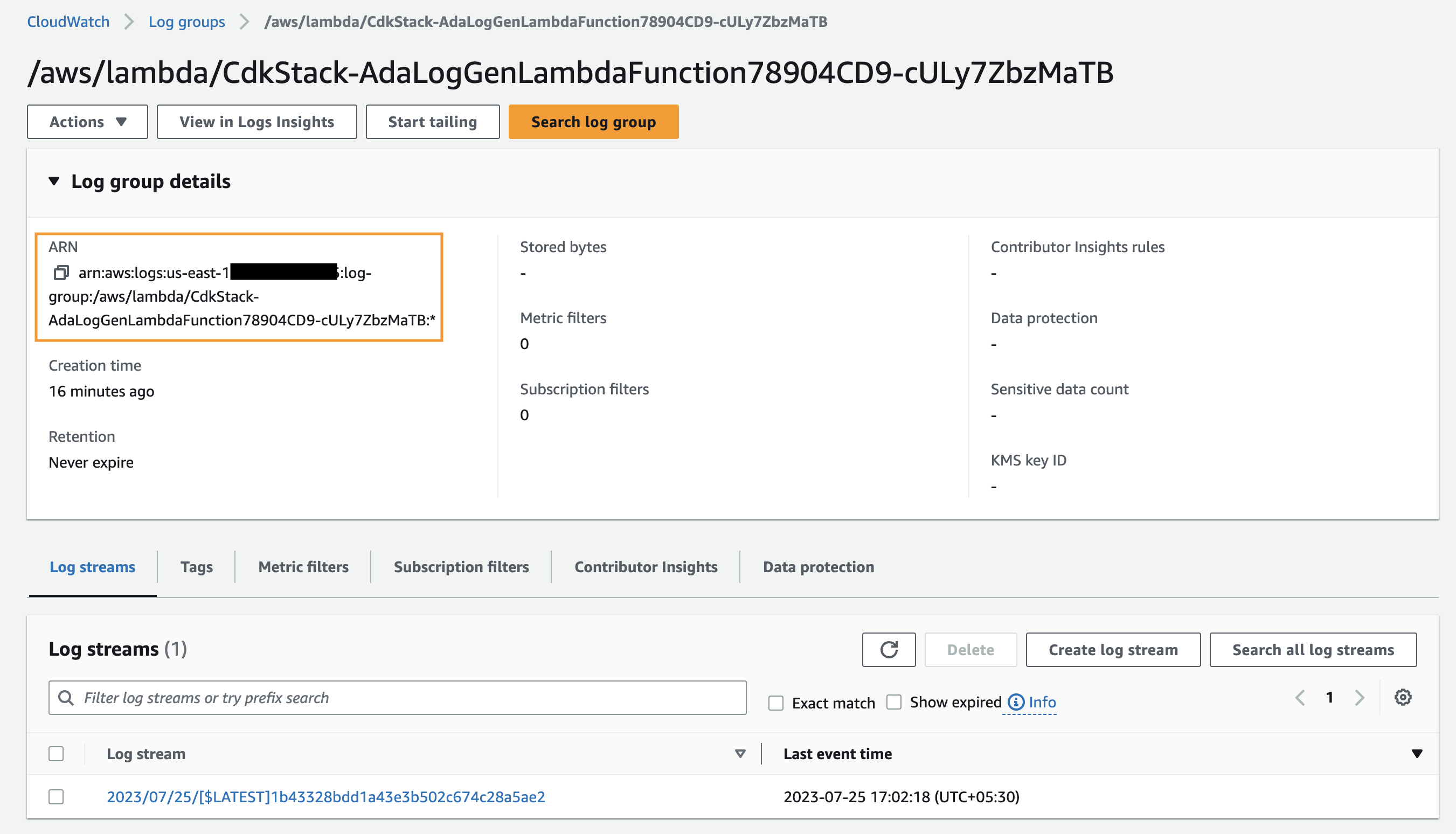
- На странице продукта данных введите группу журналов ARN.
- Что касается Запрос CloudWatch, введите запрос, который должен получить ADA из группы журналов.
В этой демонстрации мы запрашиваем поле @message, поскольку нам нужно получить журналы приложений из группы журналов.
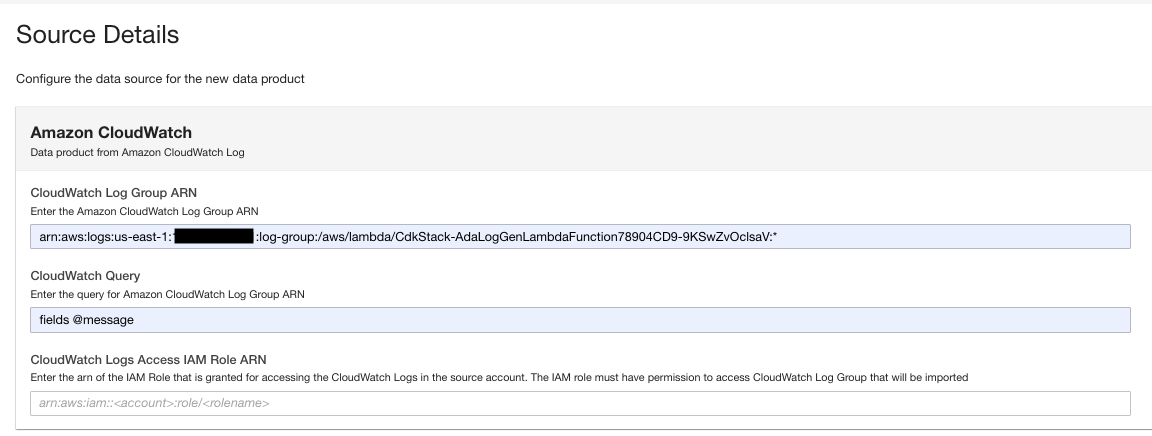
- Выберите способ запуска обновлений данных после первоначального импорта.
ADA можно настроить на получение данных из источника с гибкими интервалами (до 15 минут или позже) или по требованию. Для демонстрации мы настроили обновление данных ежечасно.
- Выберите Следующая.
Затем ADA подключится к группе журналов и запросит схему. Поскольку журналы имеют формат журнала Apache, мы преобразуем журналы в отдельные поля, чтобы можно было выполнять запросы к определенным полям журнала. АДА предоставляет четыре по умолчанию преобразования и поддерживает пользовательское преобразование с помощью скрипта Python. В этой демонстрации мы запускаем собственный скрипт Python для преобразования поля сообщения JSON в поля формата журнала Apache.
- Выберите Схема преобразования.
- Выберите Создать новое преобразование.
- Загрузить
apache-log-extractor-transform.pyсценарий из/asset/transform_logs/папку. - Выберите Отправить.
ADA преобразует журналы CloudWatch с помощью скрипта и представит обработанную схему.
- Выберите Следующая.
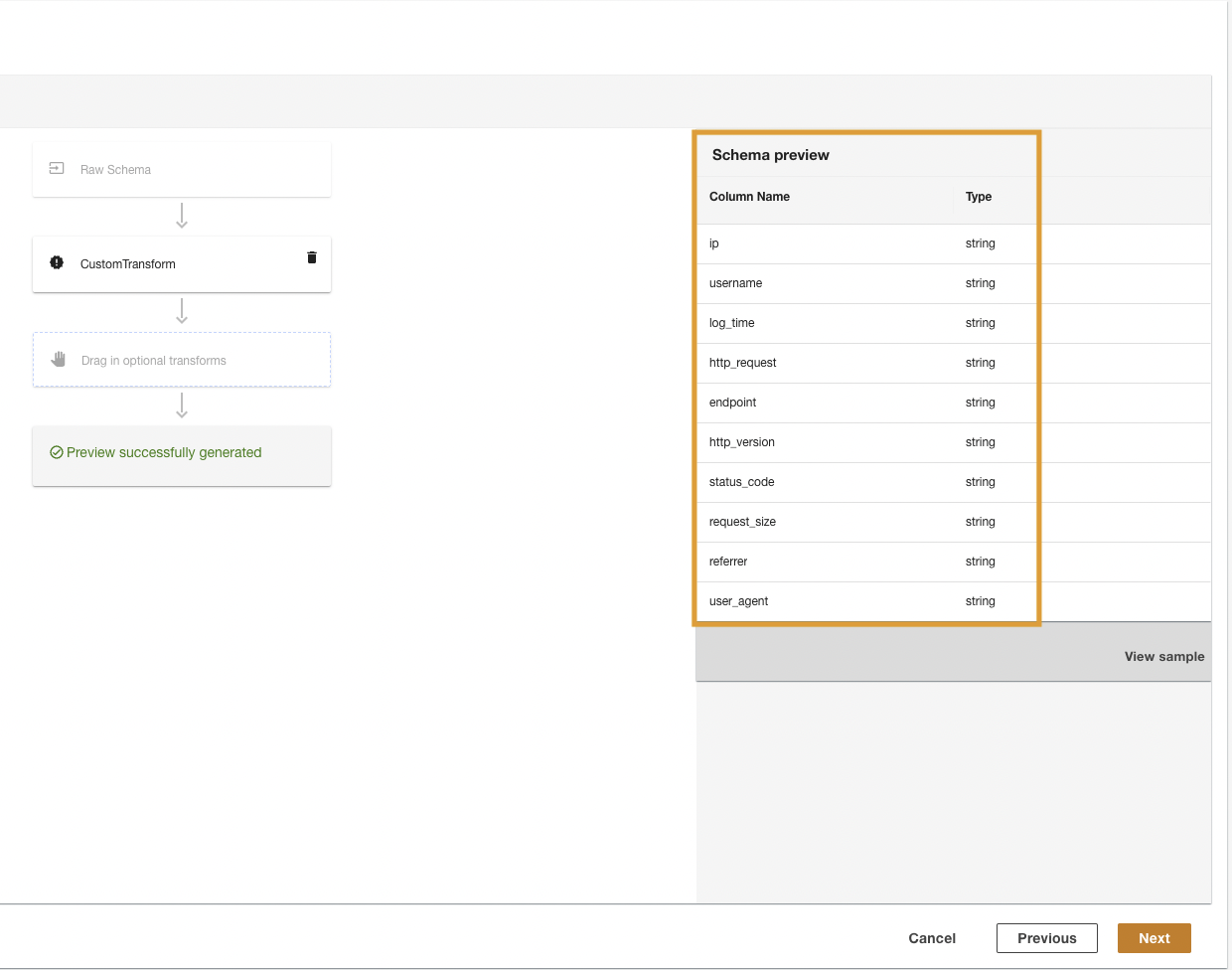
- На последнем шаге просмотрите шаги и выберите Отправить.
ADA начнет обработку данных, создаст конвейеры данных и подготовит группы журналов CloudWatch для запроса из Query Workbench. Этот процесс займет несколько минут и будет показан на консоли ADA в разделе Информационные продукты.
Создание продукта данных Amazon S3
Мы повторяем шаги, чтобы добавить исторические журналы из источника данных Amazon S3 и найти справочные данные из таблицы DynamoDB. Для этих двух источников данных мы не создаем настраиваемые преобразования, поскольку форматы данных — CSV (для исторических журналов) и ключевые атрибуты (для справочных данных поиска).
- В консоли ADA создайте новый продукт данных.
- Введите имя (
hist_logs) и выберите Amazon S3.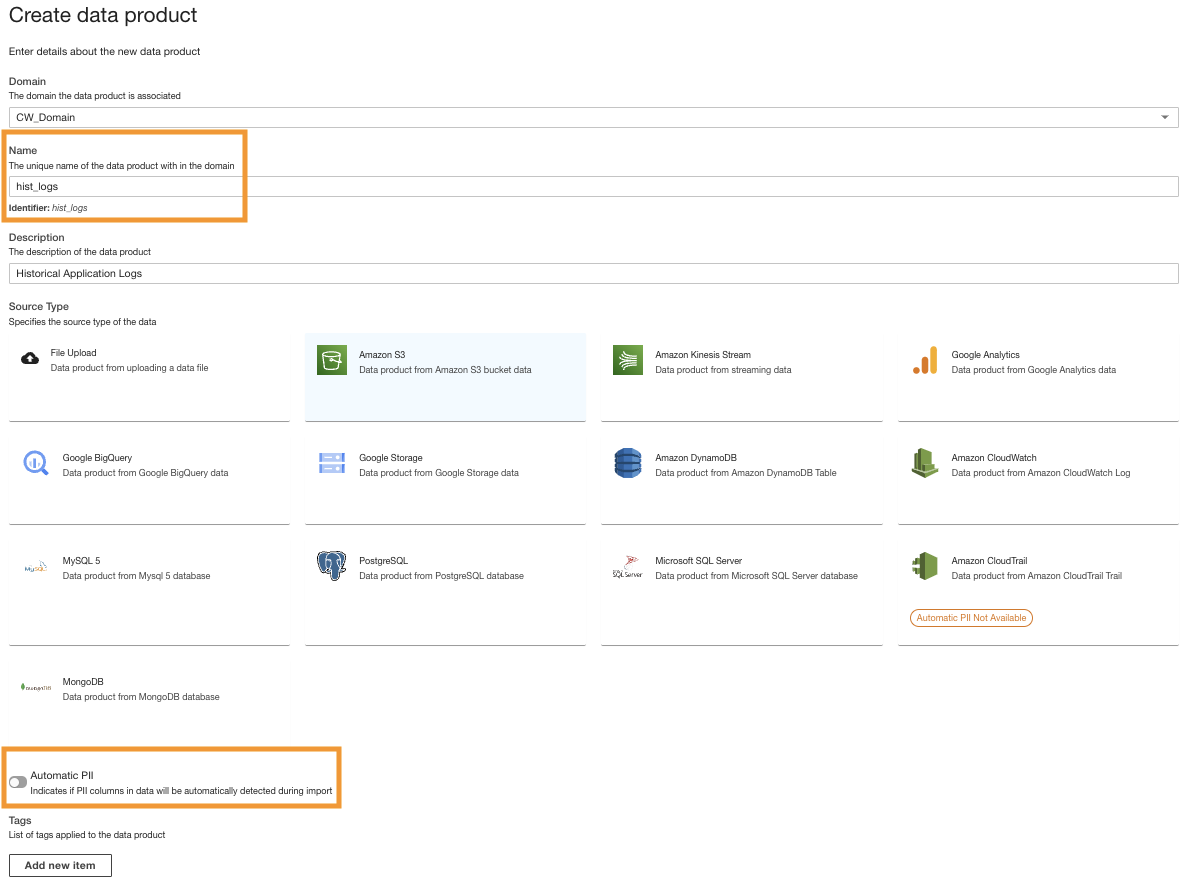
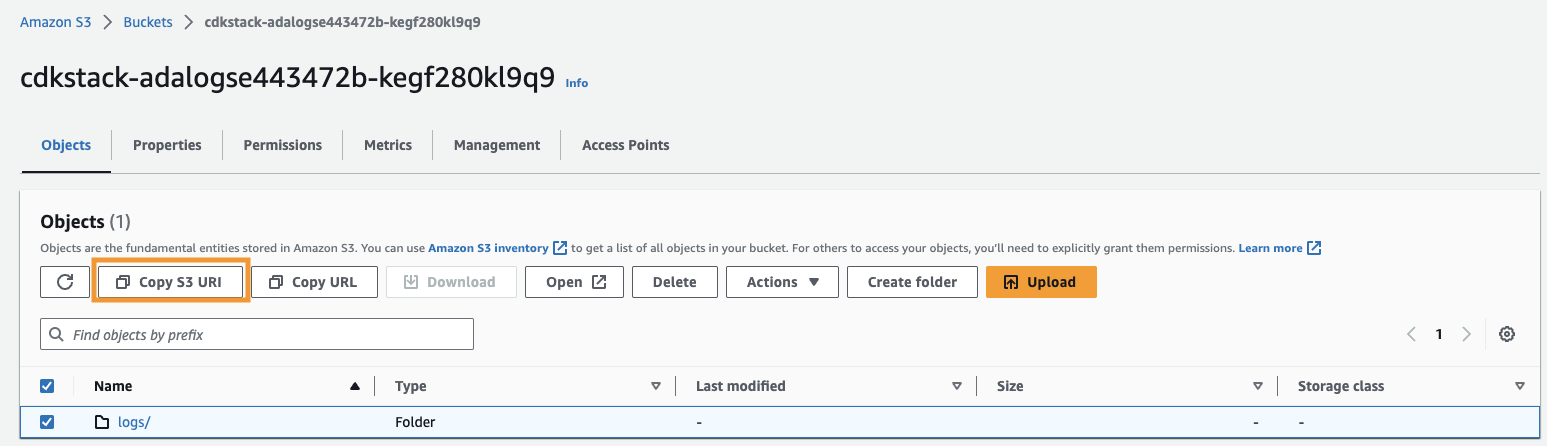
- Скопируйте URI Amazon S3 (текст после
arn:aws:s3:::) СCdkStack.S3output и перейдите в консоль Amazon S3. - В поле поиска введите скопированный текст, откройте корзину S3, выберите
/logsпапку и выберите Копировать S3 URI.
Исторические журналы хранятся по этому пути.
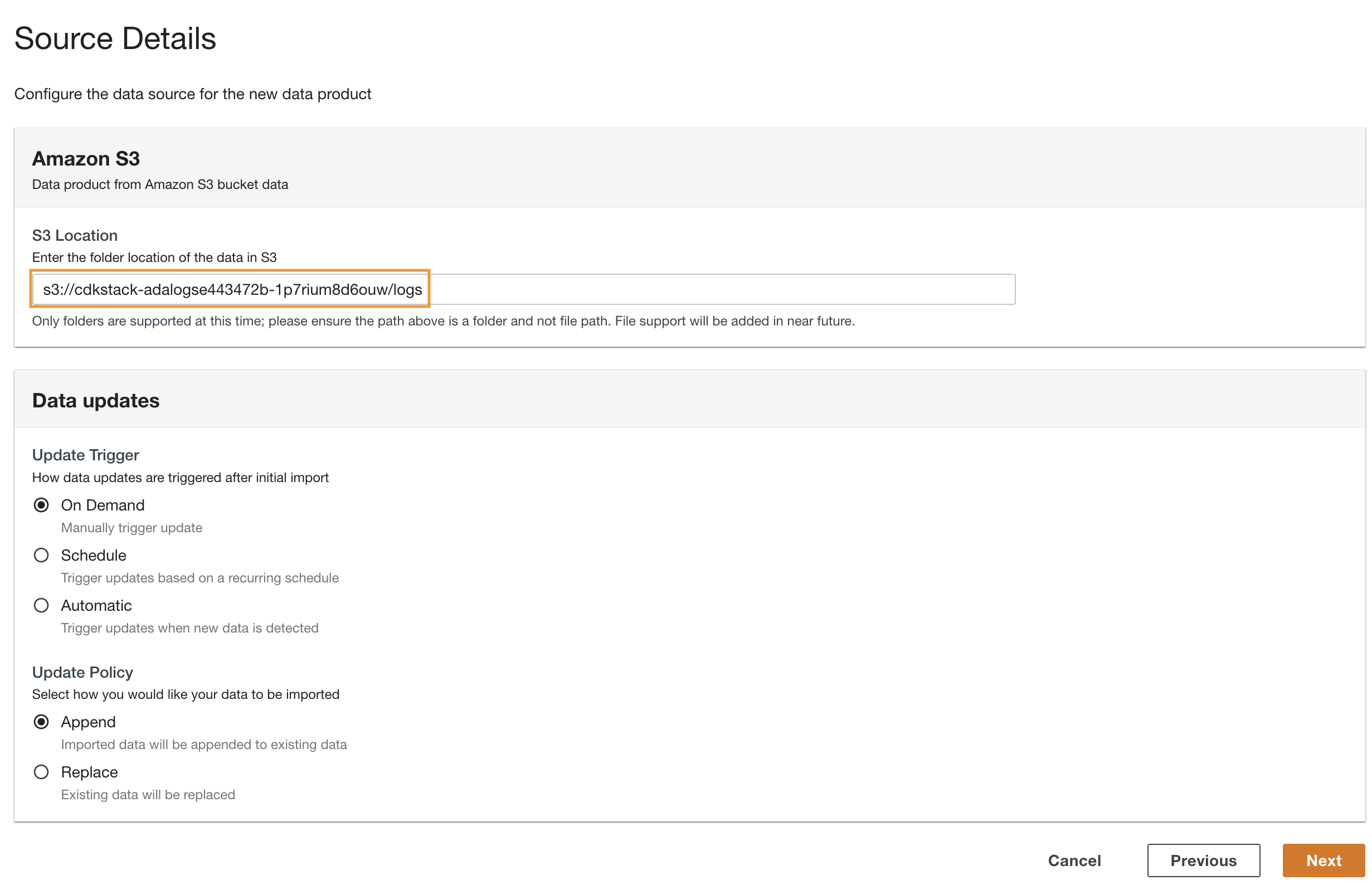
- Вернитесь к консоли ADA и введите скопированный URI S3 для S3 местоположение.
- Что касается Обновить триггер, наведите на On Demand потому что исторические журналы обновляются с неопределенной частотой.
- Что касается Обновить политику, наведите на присоединять чтобы добавить вновь импортированные данные к существующим данным.
- Выберите Следующая.
ADA обрабатывает схему для файлов в выбранном пути к папке. Поскольку журналы имеют формат CSV, ADA может считывать имена столбцов, не требуя дополнительных преобразований. Тем не менее, столбцы status_code и request_size выводятся ADA как длинный тип. Мы хотим, чтобы типы данных столбцов были согласованными между продуктами данных, чтобы мы могли соединять таблицы данных и запрашивать данные. Колонка status_code будет использоваться для создания объединений между таблицами данных.
- Выберите Схема преобразования чтобы изменить типы данных двух столбцов на строковый тип данных.
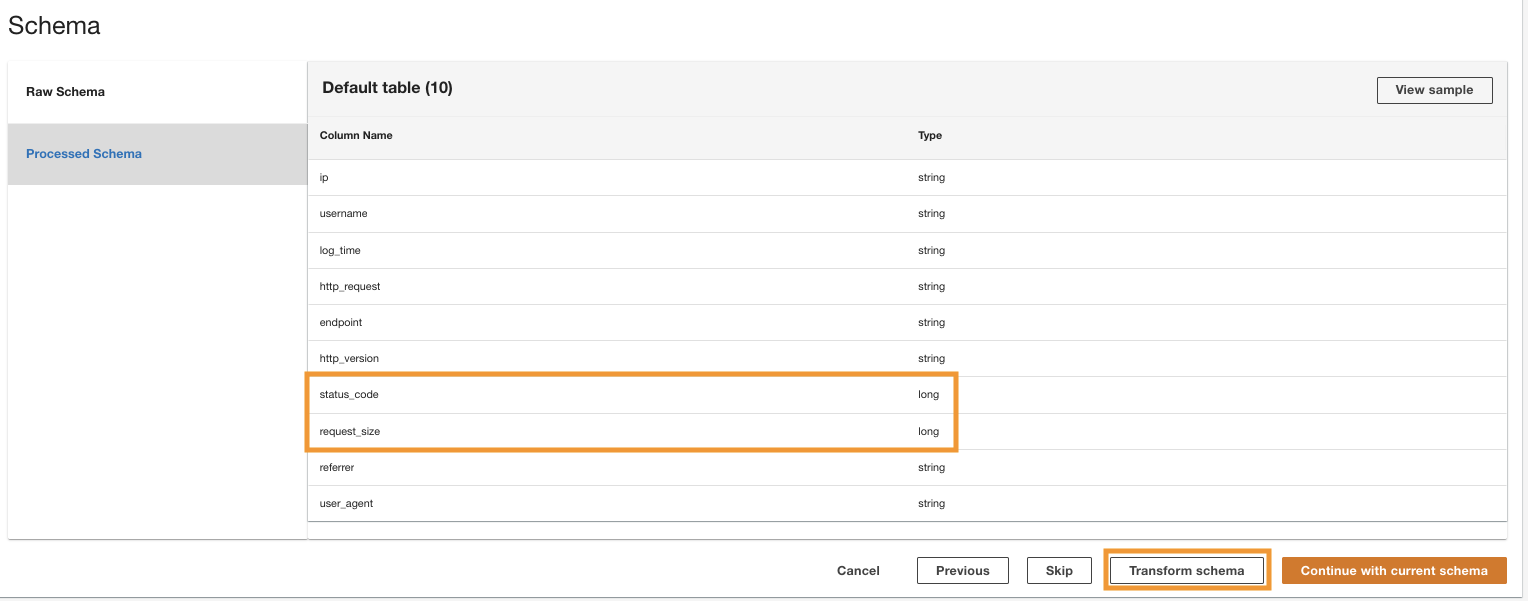
Обратите внимание на выделенные имена столбцов в Предварительный просмотр схемы панели перед применением преобразований типа данных.
- В Преобразовать план панель, под Встроенные преобразования, выберите Применить сопоставление.
Эта опция позволяет изменить тип данных с одного типа на другой.
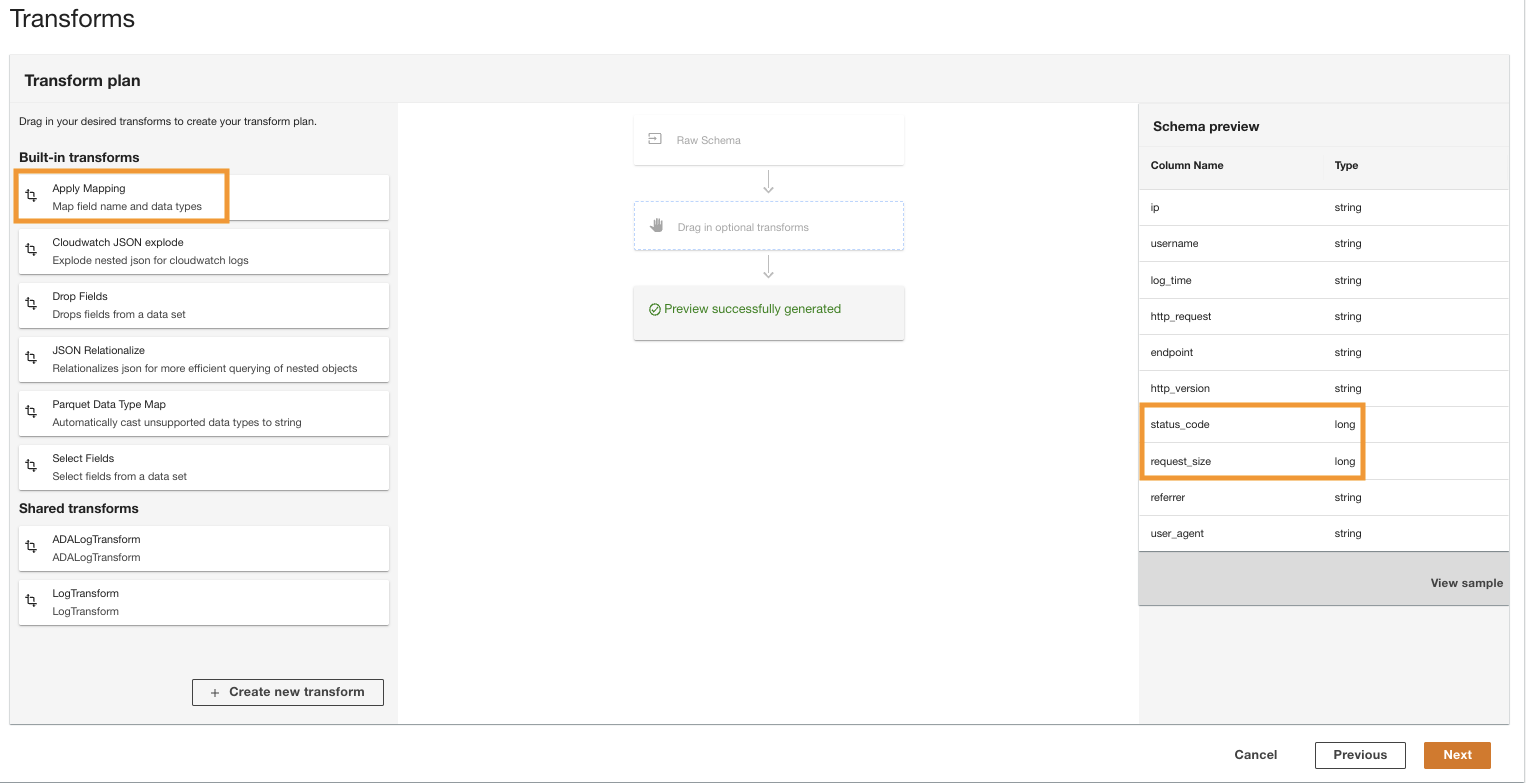
- В Применить сопоставление раздел, снять выделение Удалить другие поля.
Если этот параметр не отключен, будут сохранены только преобразованные столбцы, а все остальные столбцы будут удалены. Поскольку мы хотим сохранить все столбцы, мы отключаем эту опцию.
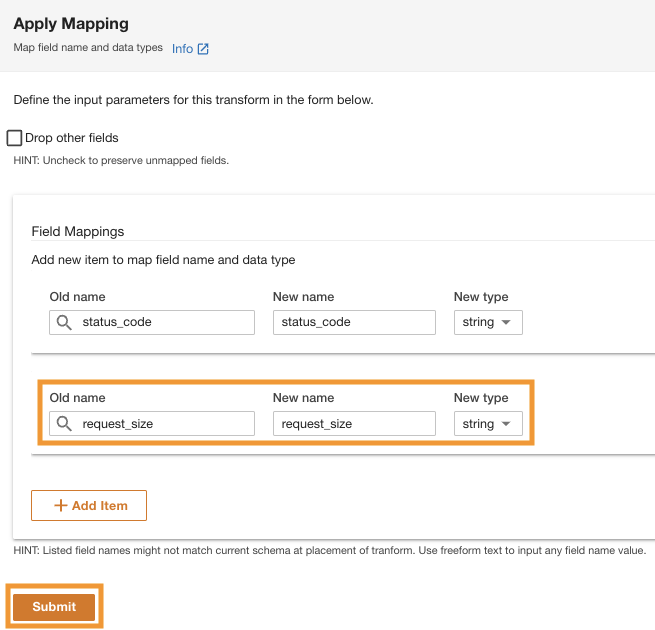
- Под Сопоставления полейдля Старое название и Новое наименование, войти
status_codeи для Новый тип, войтиstring.
- Выберите Добавить элемент.
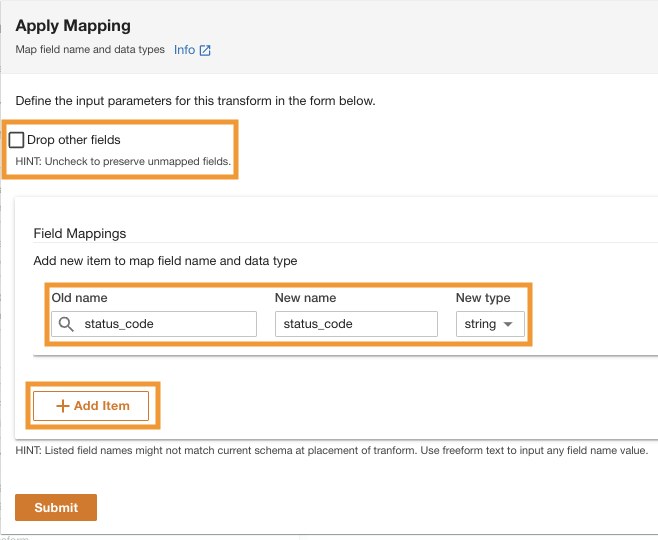
- Что касается Старое название и Новое наименование¸ введите request_size и для Новый тип данных, введите строку.
- Выберите Отправить.
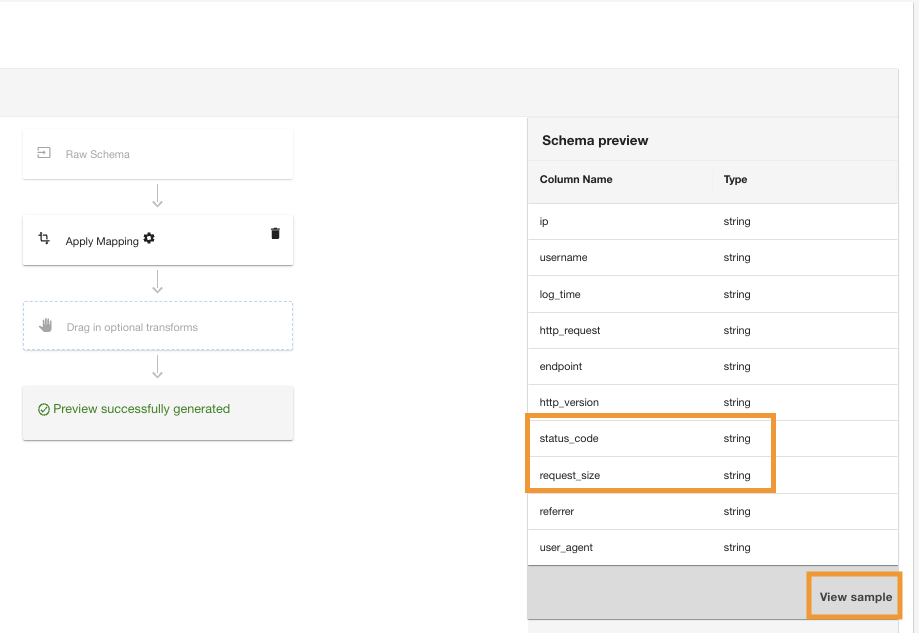
ADA применит преобразование сопоставления к источнику данных Amazon S3. Обратите внимание на типы столбцов в Предварительный просмотр схемы панель.
- Выберите Посмотреть образец для предварительного просмотра данных с примененным преобразованием.
ADA отобразит подтверждение данных PII, чтобы гарантировать, что либо только авторизованные пользователи могут просматривать данные, либо что набор данных не содержит никаких данных PII.
- Выберите Соглашаться чтобы продолжить просмотр демонстрационных данных.
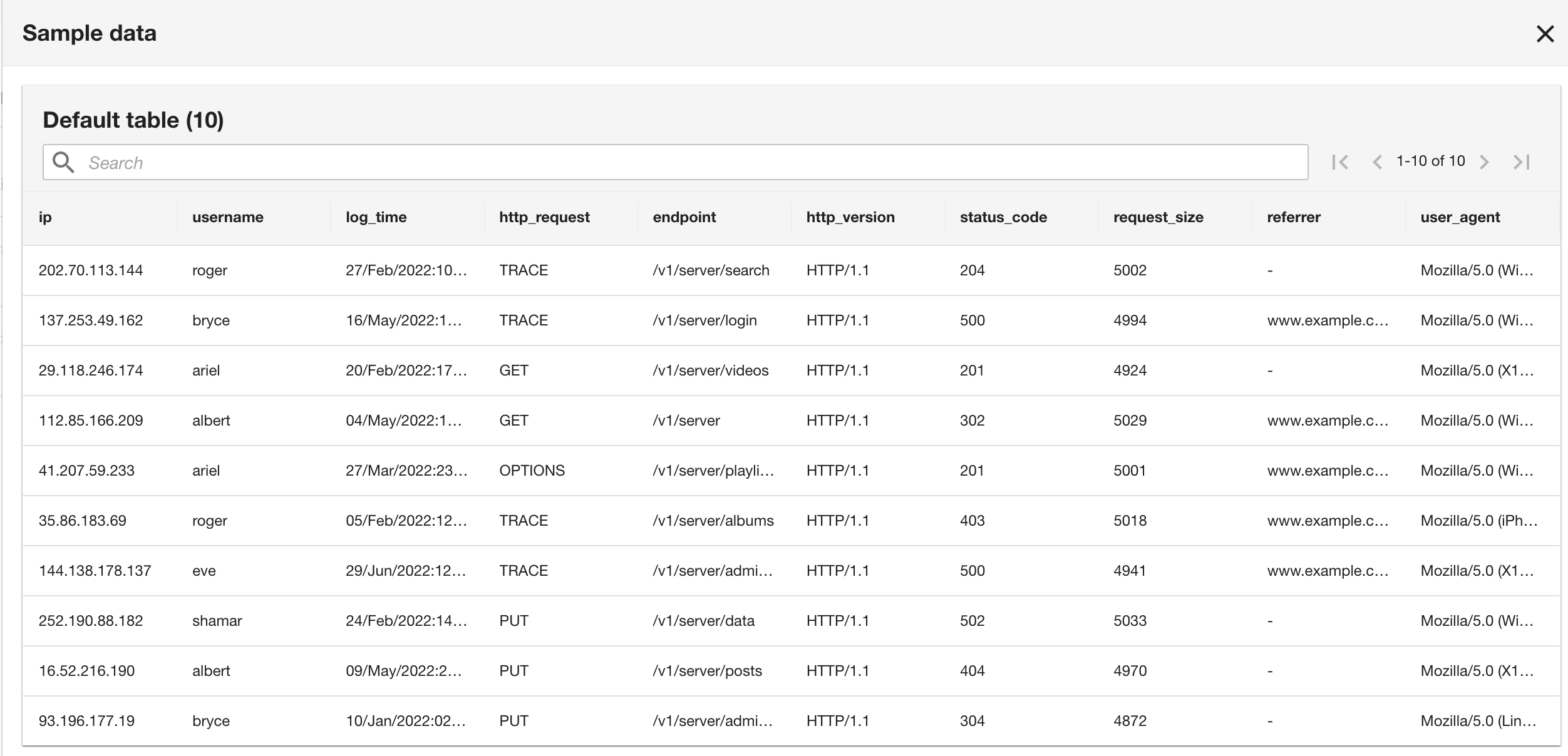
Обратите внимание, что эта схема идентична схеме группы журналов CloudWatch, потому что журналы текущих и прошлых приложений имеют формат журнала Apache.
- На последнем шаге просмотрите конфигурацию и выберите Отправить.
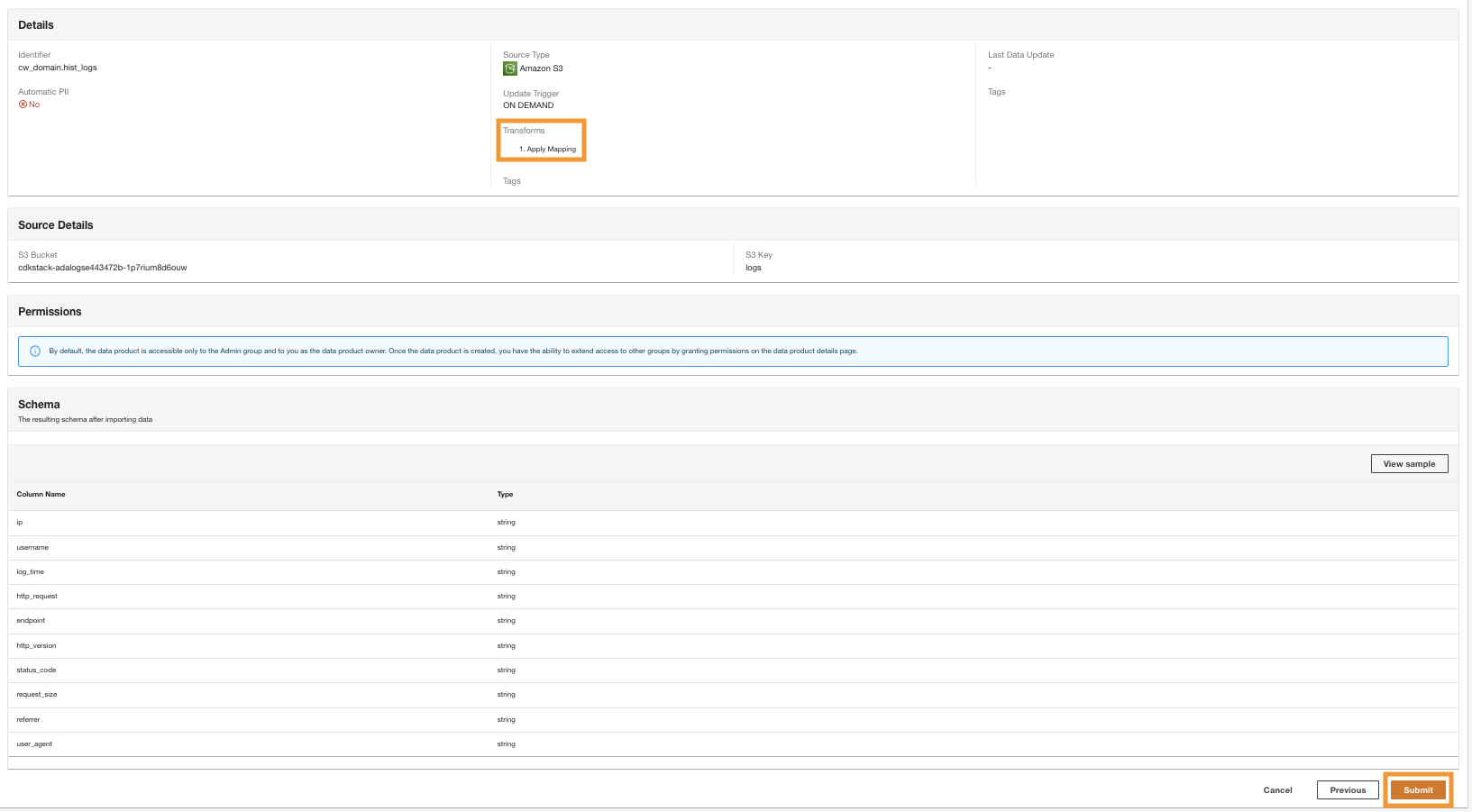
ADA начинает обрабатывать данные из источника Amazon S3, создает внутреннюю инфраструктуру и подготавливает продукт данных. Этот процесс занимает несколько минут в зависимости от размера данных.
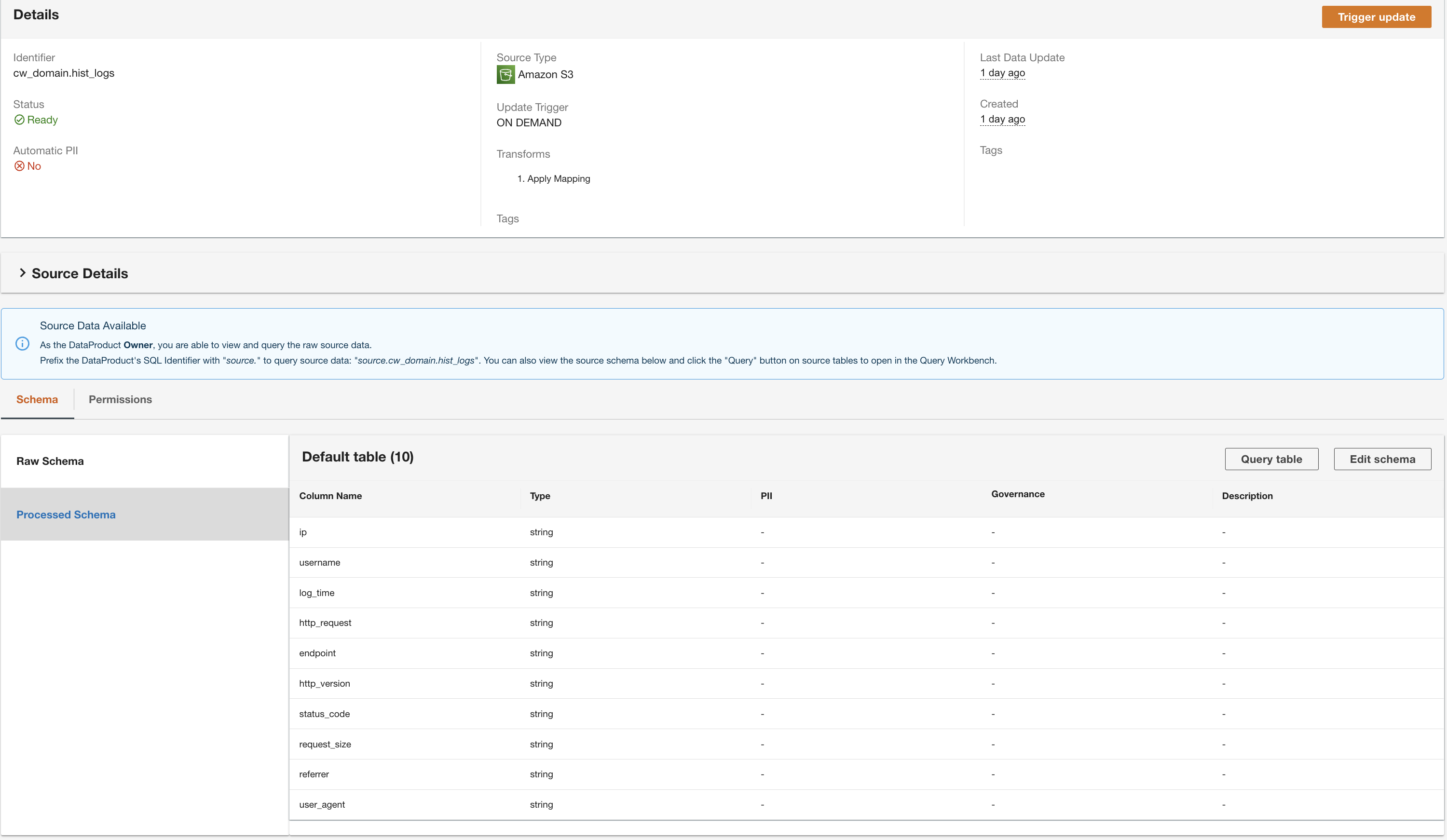
Создание продукта данных DynamoDB
Наконец, мы создаем продукт данных DynamoDB. Выполните следующие шаги:
- В консоли ADA создайте новый продукт данных.
- Введите имя (
lookup) и выберите Amazon DynamoDB.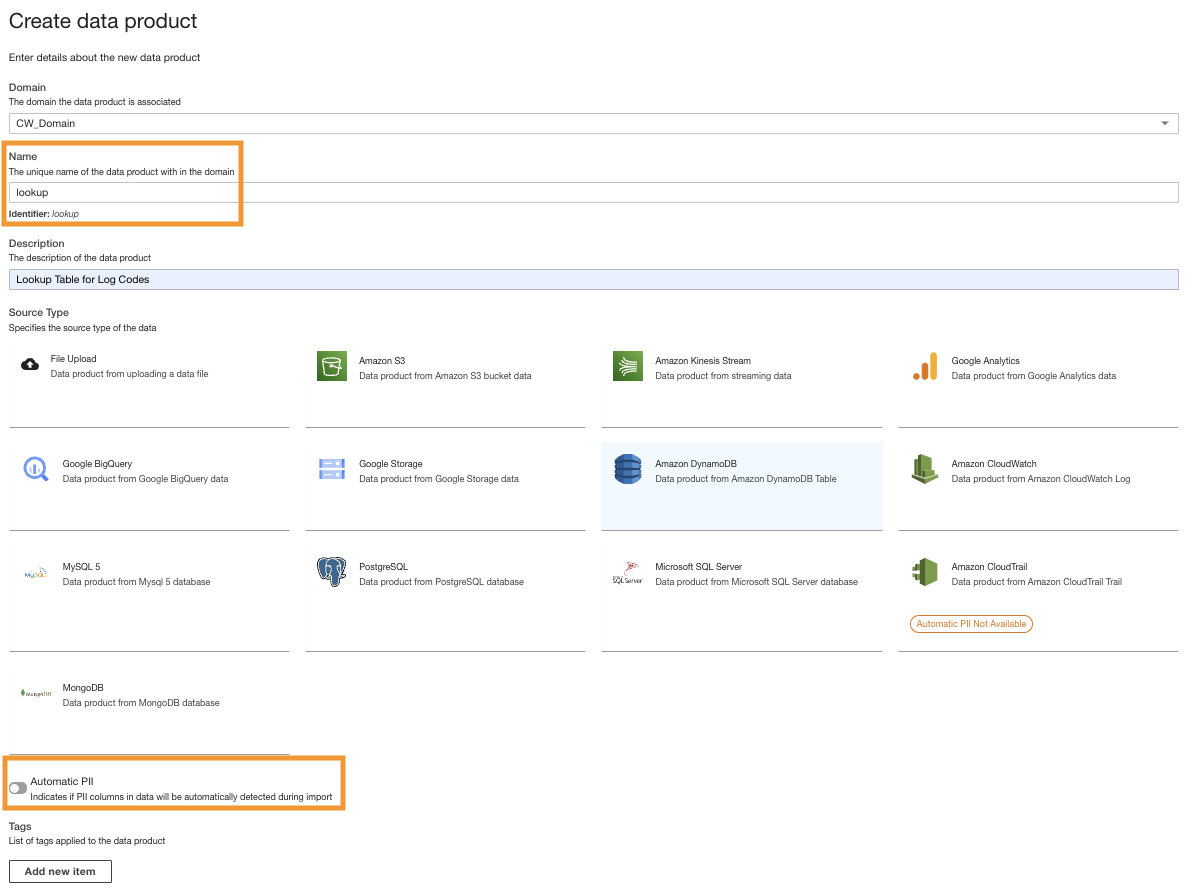
- Введите
Cdk.DynamoDBTableвыходная переменная для Таблица DynamoDB ARN.
Эта таблица содержит ключевые атрибуты, которые будут использоваться в качестве таблицы поиска в этой демонстрации. Для данных поиска мы используем коды HTTP, а также длинные и короткие описания кодов. В качестве альтернативы вы также можете использовать PostgreSQL, MySQL или исходный файл CSV.
- Что касается Обновить триггер, наведите на On-Demand.
Обновления будут выполняться по запросу, поскольку поиск в основном предназначен для справочных целей при запросе, а любые обновления данных поиска могут быть обновлены в ADA с помощью триггеров по запросу.
- Выберите Следующая.
ADA считывает схему из базовой схемы DynamoDB и предоставляет имя и тип столбца для необязательного преобразования. Мы продолжим выбор схемы по умолчанию, поскольку типы столбцов соответствуют типам из группы журналов CloudWatch и источника данных Amazon S3 CSV. Наличие типов данных, согласованных между источниками данных, позволяет нам писать запросы для извлечения записей путем объединения таблиц с использованием полей столбцов. Например, столбец key в схеме DynamoDB соответствует status_code в продуктах данных Amazon S3 и CloudWatch. Мы можем написать запросы, которые могут соединить три таблицы, используя имя столбца key. Пример показан в следующем разделе.
- Выберите Продолжить с текущей схемой.
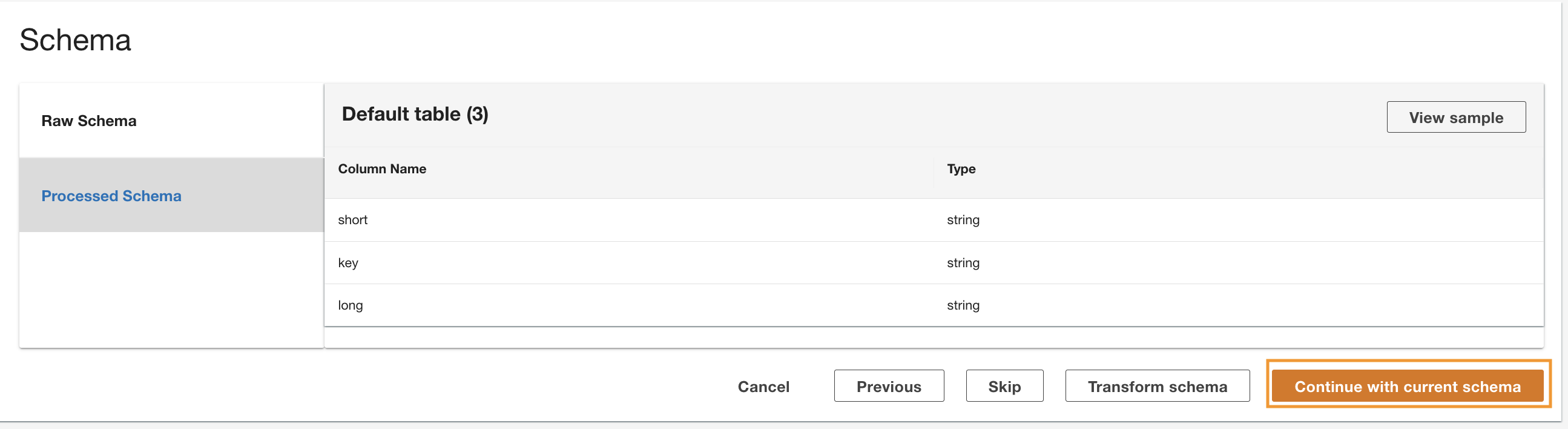
- Просмотрите конфигурацию и выберите Отправить.
ADA обработает данные из источника данных таблицы DynamoDB и подготовит продукт данных. В зависимости от размера данных этот процесс занимает несколько минут.
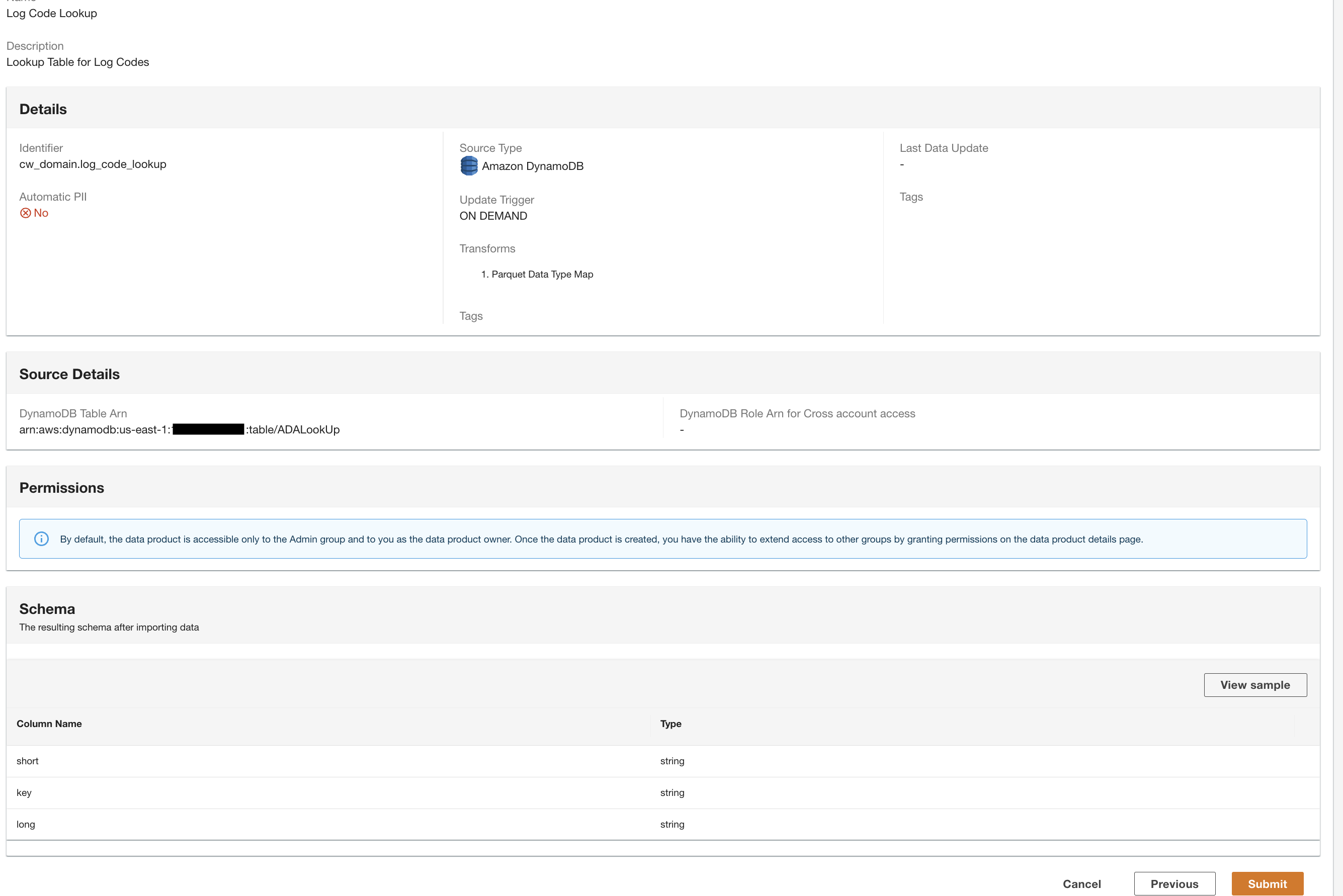
Теперь у нас есть все три продукта данных, обработанные ADA и доступные для выполнения запросов.

Используйте Query Workbench для запроса данных
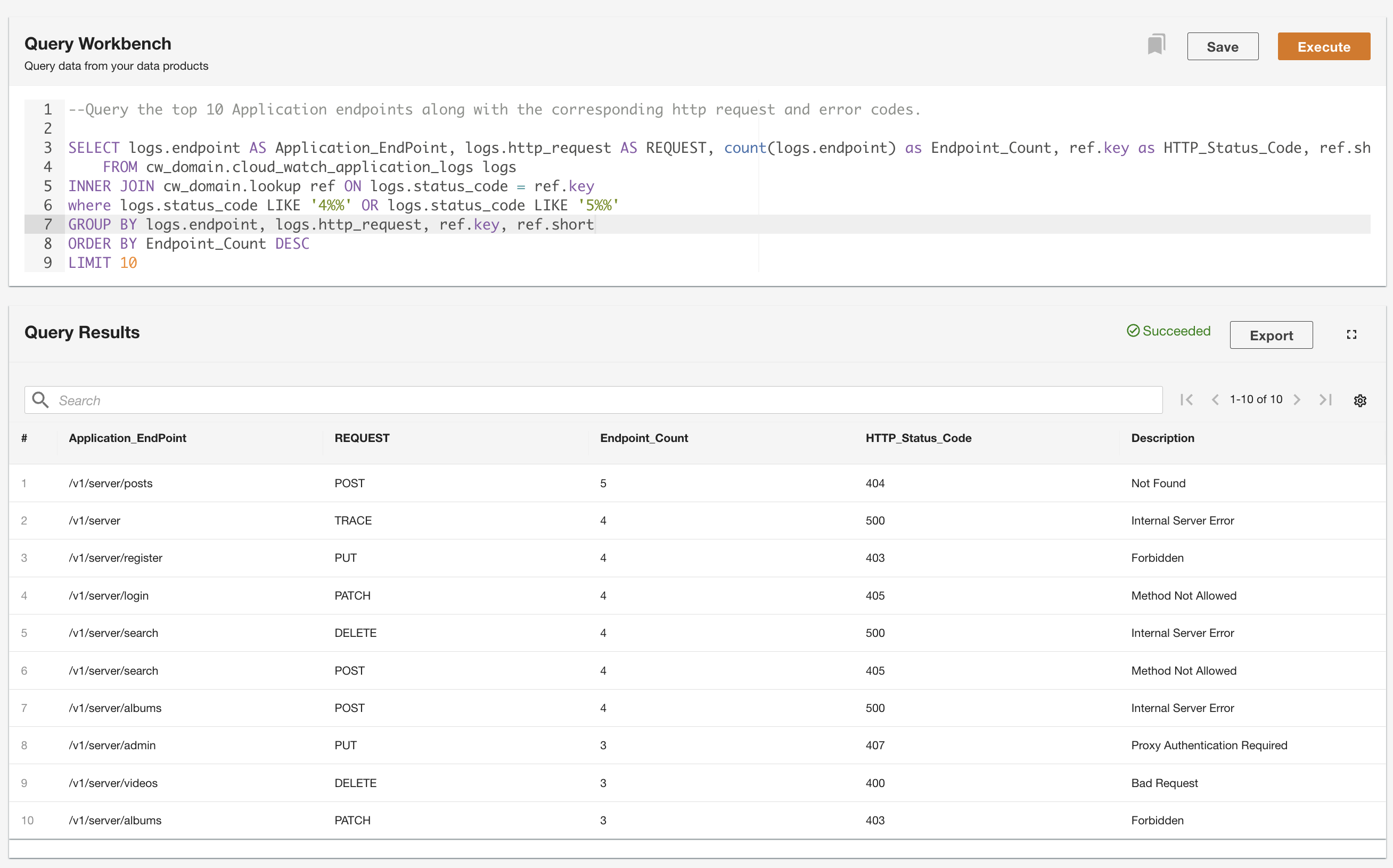
ADA позволяет выполнять запросы к продуктам данных, абстрагируя источник данных и делая его доступным с помощью SQL (язык структурированных запросов). Вы можете писать запросы и присоединяться к таблицам так же, как вы делаете запросы к таблицам в реляционной базе данных. Мы демонстрируем возможности запросов ADA через два пользовательских сценария. В обоих сценариях мы присоединяем набор данных журнала приложений к таблице поиска кодов ошибок. В первом случае мы запрашиваем текущие журналы приложений, чтобы определить 10 наиболее часто используемых конечных точек приложения вместе с соответствующими кодами состояния HTTP:
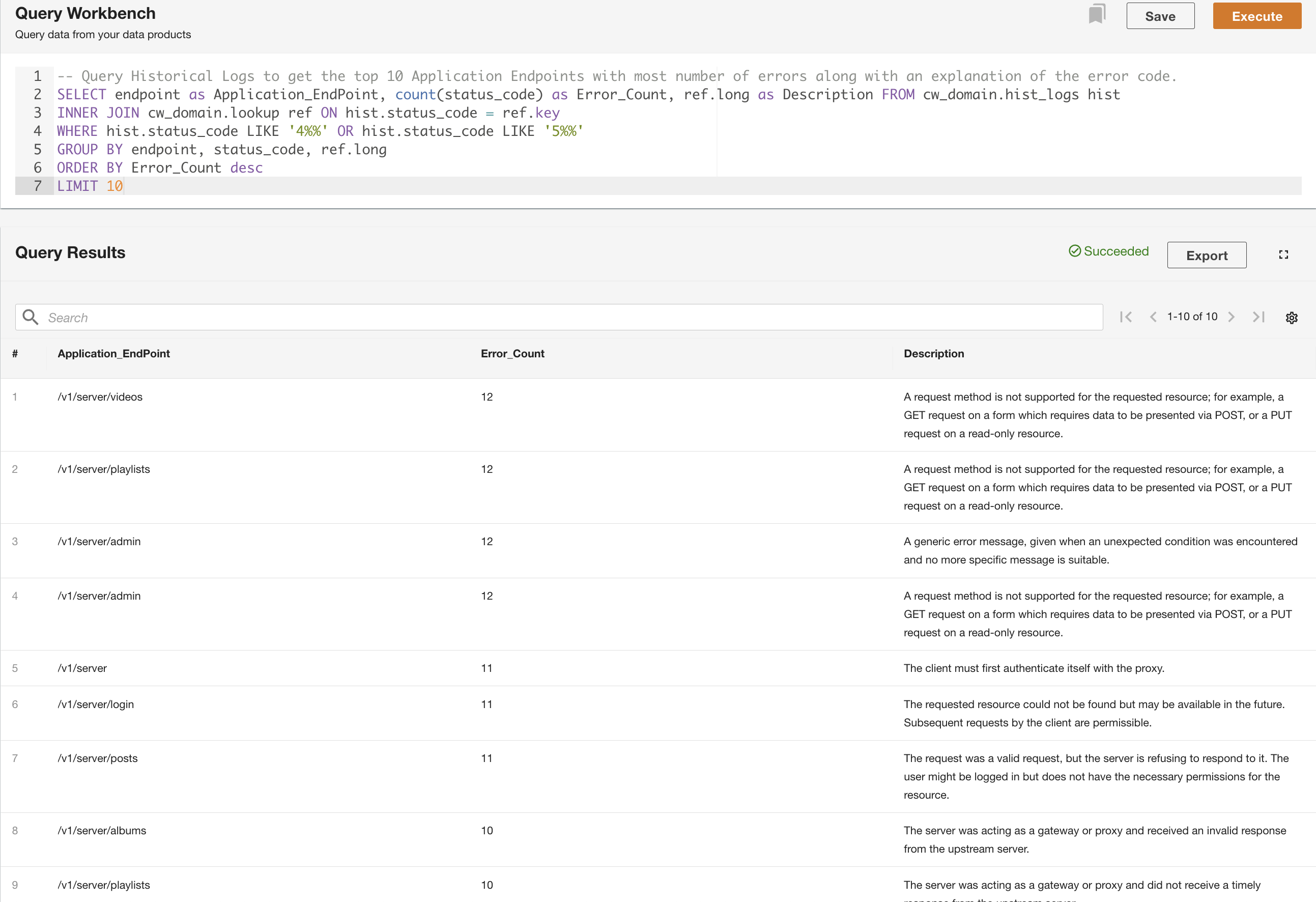
Во втором примере мы запрашиваем таблицу исторических журналов, чтобы получить 10 основных конечных точек приложения с наибольшим количеством ошибок, чтобы понять шаблон вызова конечной точки:
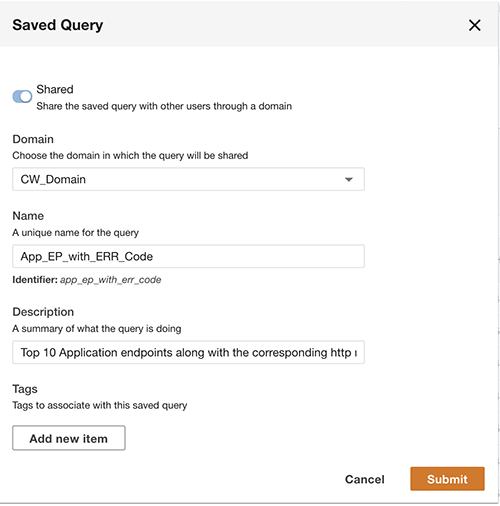
В дополнение к запросу вы можете при желании сохранить запрос и поделиться сохраненным запросом с другими пользователями в том же домене. Общие запросы доступны непосредственно из Query Workbench. Результаты запроса также можно экспортировать в формат CSV.
Визуализируйте продукты данных ADA в Tableau
ADA предлагает возможность соединяться к сторонним инструментам BI для визуализации данных и создания отчетов из продуктов данных ADA. В этой демонстрации мы используем встроенную интеграцию ADA с Tableau для визуализации данных из трех продуктов данных, которые мы настроили ранее. Используя коннектор Tableau Athena и следуя инструкциям в Конфигурация таблицы, вы можете настроить ADA в качестве источника данных в Tableau. После того, как между Tableau и ADA будет установлено успешное соединение, Tableau заполнит три продукта данных в каталоге Tableau. cw_domain.
Затем мы устанавливаем связь между тремя базами данных, используя код состояния HTTP в качестве столбца соединения, как показано на следующем снимке экрана. Tableau позволяет нам работать в онлайн и оффлайн режиме с источниками данных. В онлайн-режиме Tableau будет подключаться к ADA и запрашивать продукты данных в реальном времени. В автономном режиме мы можем использовать Выписка возможность извлекать данные из ADA и импортировать данные в Tableau. В этой демонстрации мы импортируем данные в Tableau, чтобы сделать запросы более отзывчивыми. Затем мы сохраняем рабочую книгу Tableau. Мы можем проверить данные из источников данных, выбрав базу данных и Обновить Сейчас.
С конфигурациями источников данных в Tableau мы можем создавать настраиваемые отчеты, диаграммы и визуализации в продуктах данных ADA. Давайте рассмотрим два варианта использования визуализаций.
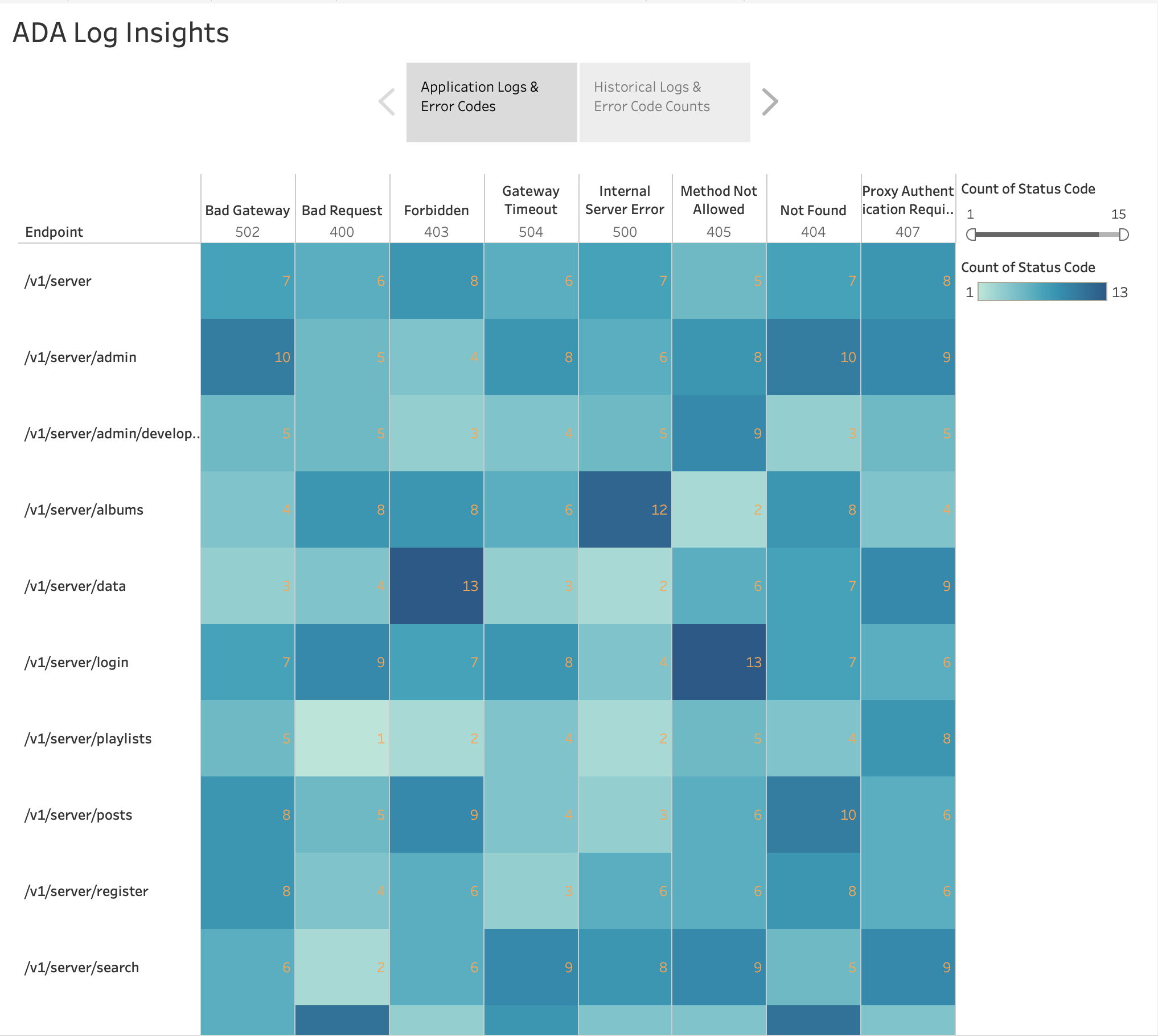
Как показано на следующем рисунке, мы визуализировали частоту ошибок HTTP по конечным точкам приложения, используя встроенный инструмент Tableau. тепловая карта диаграмма. Мы отфильтровали коды состояния HTTP, чтобы включить только коды ошибок в диапазоне 4xx и 5xx.
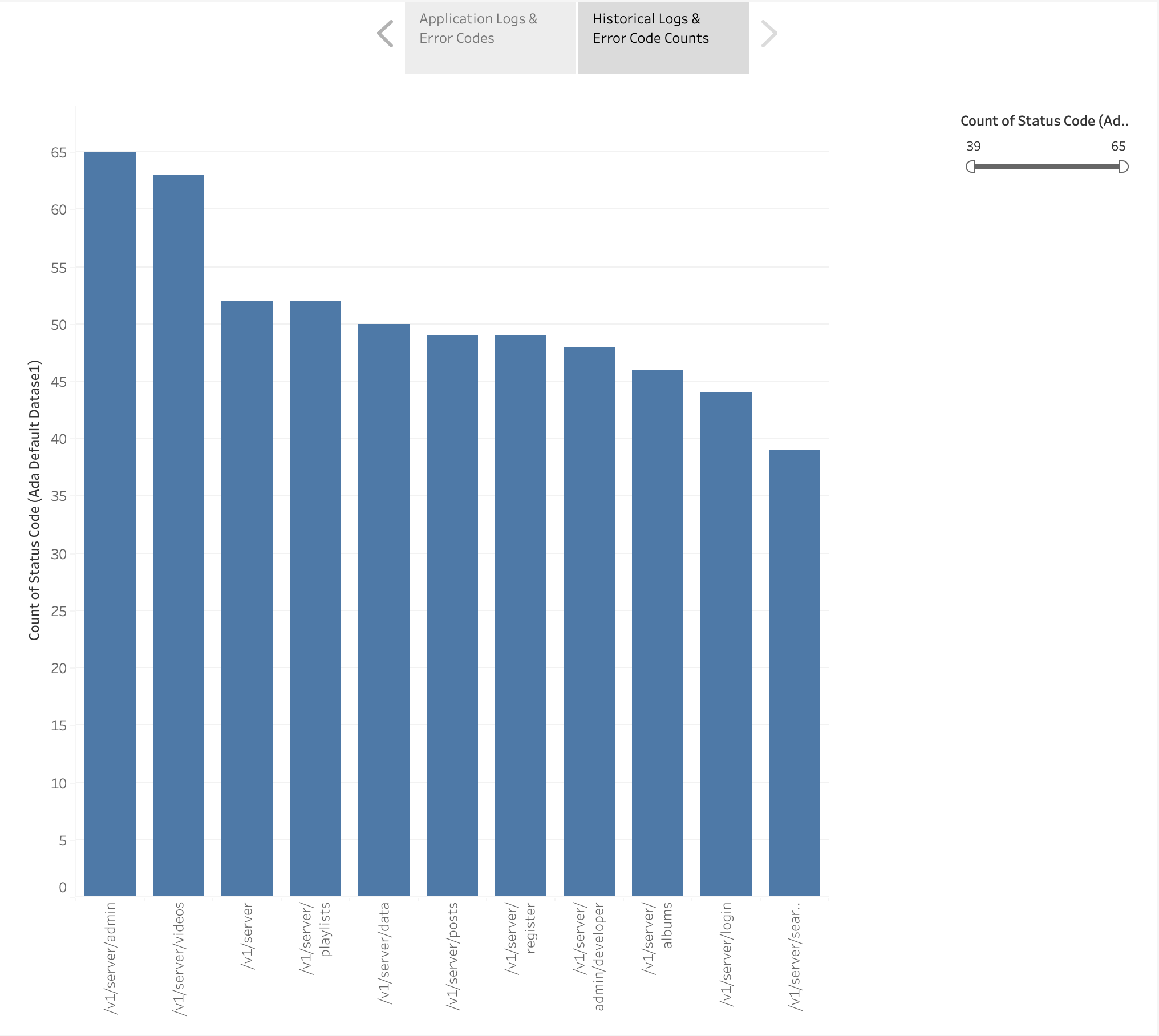
Мы также создали столбчатую диаграмму для отображения конечных точек приложений из исторических журналов, упорядоченных по количеству кодов ошибок HTTP. На этом графике мы видим, что /v1/server/admin конечная точка сгенерировала наибольшее количество кодов состояния ошибки HTTP.
Убирать
Очистка инфраструктуры примера приложения — это двухэтапный процесс. Во-первых, чтобы удалить инфраструктуру, подготовленную для этой демонстрации, выполните в терминале следующую команду:
В ответ на следующий вопрос введите y, и AWS CDK удалит ресурсы, развернутые для демонстрации:
Кроме того, вы можете удалить ресурсы через консоль AWS CloudFormation, перейдя к стеку CdkStack и выбрав Удалить.
Второй шаг — удалить ADA. Инструкции см. Удалить решение.
Заключение
В этом посте мы продемонстрировали, как использовать решение ADA для получения информации из журналов приложений, хранящихся в двух разных источниках данных. Мы продемонстрировали, как установить ADA в аккаунте AWS и развернуть демонстрационные компоненты с помощью AWS CDK. Мы создали продукты данных в ADA и настроили продукты данных с соответствующими источниками данных, используя встроенные соединители данных ADA. Мы продемонстрировали, как запрашивать продукты данных, используя стандартные запросы SQL, и получать ценные сведения о данных журнала. Мы также подключили клиент Tableau Desktop, сторонний продукт бизнес-аналитики, к ADA и продемонстрировали, как создавать визуализации для продуктов данных.
ADA автоматизирует процесс приема, преобразования, управления и запроса различных наборов данных и упрощает управление жизненным циклом данных. Предварительно созданные соединители ADA позволяют получать данные из различных источников данных. Команды разработчиков программного обеспечения, обладающие базовыми знаниями о продуктах и сервисах AWS, смогут за несколько часов настроить рабочую платформу для анализа данных и обеспечить безопасный доступ к данным. Затем данные можно легко и быстро запрашивать с помощью интуитивно понятного автономного пользовательского веб-интерфейса.
Попробуйте ADA сегодня, чтобы легко управлять данными и получать ценную информацию.
Об авторах
 Апараджитан Вайдьянатан является главным архитектором корпоративных решений в AWS. Он помогает корпоративным клиентам перенести и модернизировать свои рабочие нагрузки в облаке AWS. Он облачный архитектор с более чем 23-летним опытом проектирования и разработки корпоративных, крупномасштабных и распределенных программных систем. Он специализируется на машинном обучении и анализе данных, уделяя особое внимание области проектирования данных и функций. Он начинающий марафонец, и его хобби включают пешие прогулки, езду на велосипеде и времяпрепровождение с женой и двумя сыновьями.
Апараджитан Вайдьянатан является главным архитектором корпоративных решений в AWS. Он помогает корпоративным клиентам перенести и модернизировать свои рабочие нагрузки в облаке AWS. Он облачный архитектор с более чем 23-летним опытом проектирования и разработки корпоративных, крупномасштабных и распределенных программных систем. Он специализируется на машинном обучении и анализе данных, уделяя особое внимание области проектирования данных и функций. Он начинающий марафонец, и его хобби включают пешие прогулки, езду на велосипеде и времяпрепровождение с женой и двумя сыновьями.
 Рашим Рахман — разработчик программного обеспечения из Сиднея, Австралия, с более чем 10-летним опытом разработки программного обеспечения и архитектуры. В основном он работает над созданием крупномасштабных решений AWS с открытым исходным кодом для распространенных сценариев использования клиентов и бизнес-задач. В свободное время он любит заниматься спортом и проводить время с друзьями и семьей.
Рашим Рахман — разработчик программного обеспечения из Сиднея, Австралия, с более чем 10-летним опытом разработки программного обеспечения и архитектуры. В основном он работает над созданием крупномасштабных решений AWS с открытым исходным кодом для распространенных сценариев использования клиентов и бизнес-задач. В свободное время он любит заниматься спортом и проводить время с друзьями и семьей.
 Хафиз Саадулла является главным техническим менеджером по продуктам в Amazon Web Services. Хафиз фокусируется на решениях AWS, призванных помогать клиентам путем решения общих бизнес-проблем и сценариев использования.
Хафиз Саадулла является главным техническим менеджером по продуктам в Amazon Web Services. Хафиз фокусируется на решениях AWS, призванных помогать клиентам путем решения общих бизнес-проблем и сценариев использования.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Автомобили / электромобили, Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- ЧартПрайм. Улучшите свою торговую игру с ChartPrime. Доступ здесь.
- Смещения блоков. Модернизация права собственности на экологические компенсации. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :имеет
- :является
- :нет
- :куда
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- способность
- в состоянии
- О нас
- доступ
- Доступ
- доступной
- Учетная запись
- через
- действия
- ADA
- Добавить
- дополнение
- дополнительный
- адресация
- Администратор
- После
- против
- Все
- позволять
- позволяет
- вдоль
- причислены
- альтернатива
- Amazon
- Amazon Web Services
- среди
- an
- анализ
- Аналитики
- аналитика
- анализировать
- и
- Другой
- любой
- апаш
- API
- API
- Применение
- Приложения
- прикладной
- Применить
- Применение
- архитектура
- МЫ
- AS
- стремящийся
- At
- Атрибуты
- Австралия
- Аутентификация
- уполномоченный
- Автоматизированный
- автоматы
- автоматически
- доступен
- AWS
- AWS CloudFormation
- назад
- Backend
- бар
- основанный
- основной
- BE
- , так как:
- было
- до
- сделанный на заказ
- между
- изоферменты печени
- Коробка
- строить
- Строительство
- встроенный
- бизнес
- бизнес-аналитика
- но
- by
- призывают
- CAN
- возможности
- случаев
- случаев
- каталог
- CD
- изменение
- График
- Графики
- Выберите
- Выбирая
- клиент
- облако
- код
- Коды
- лыжных шлемов
- Column
- Колонки
- Общий
- полный
- компоненты
- Конфигурация
- настроить
- Свяжитесь
- подключенный
- связи
- подключает
- Рассматривать
- последовательный
- Консоли
- содержит
- продолжать
- коррелирует
- Корреляция
- соответствующий
- соответствует
- Цена
- Создайте
- создали
- создает
- Создающий
- Полномочия
- Текущий
- изготовленный на заказ
- клиент
- Клиенты
- приборная панель
- данным
- Анализ данных
- обработка данных
- База данных
- базы данных
- Наборы данных
- По умолчанию
- Спрос
- Демо
- демонстрировать
- убивают
- в зависимости
- развертывание
- развернуть
- развертывание
- развертывает
- описание
- предназначенный
- проектирование
- компьютера
- подробный
- подробнее
- Застройщик
- развивающийся
- Развитие
- диагностика
- различный
- непосредственно
- инвалид
- открытие
- Дисплей
- распределенный
- Разное
- не
- домен
- доменов
- Dont
- упал
- в течение
- каждый
- Ранее
- легко
- редактирование
- или
- включен
- позволяет
- Конечная точка
- конечные точки
- Проект и
- обеспечивать
- Enter
- Предприятие
- корпоративные клиенты
- Решения для предприятий
- ошибка
- ошибки
- установить
- установленный
- Эфир (ETH)
- пример
- существующий
- опыт
- Объяснять
- объяснение
- извлечение
- извлечь данные
- знакомый
- семья
- Особенность
- несколько
- поле
- Поля
- фигура
- Файл
- Файлы
- окончательный
- финансы
- Во-первых,
- гибкого
- Фокус
- фокусируется
- после
- Что касается
- формат
- 4
- частота
- друзья
- от
- функция
- Gain
- порождать
- генерируется
- получить
- получающий
- руководящий
- группы
- Группы
- Есть
- имеющий
- he
- помощь
- Выделенные
- пеший туризм
- его
- исторический
- Увлечения
- состоялся
- ЧАСЫ
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- IAM
- идентичный
- определения
- Личность
- if
- Импортировать
- in
- включают
- включает в себя
- В том числе
- информация
- Инфраструктура
- начальный
- размышления
- устанавливать
- установка
- инструкции
- интегрированный
- интеграции.
- Интеллекта
- интерактивный
- заинтересованный
- Интерфейс
- в
- интуитивный
- Запускает
- вовлеченный
- вопрос
- IT
- присоединиться
- присоединение
- Играя
- JPG
- JSON
- всего
- Сохранить
- Основные
- знания
- язык
- большой
- крупномасштабный
- Фамилия
- новее
- запуск
- изучение
- Библиотека
- Лицензирована
- Жизненный цикл
- такое как
- ОГРАНИЧЕНИЯ
- линия
- Список
- жить
- журнал
- каротаж
- Длинное
- посмотреть
- поиск
- машина
- обучение с помощью машины
- сделать
- Создание
- управлять
- управление
- менеджер
- многих
- карта
- отображение
- Марафон
- Маркетинг
- Вопрос
- значимым
- сообщение
- МИД
- может быть
- мигрировать
- минут
- режим
- модернизировать
- БОЛЕЕ
- самых
- в основном
- Mozilla
- многофакторная аутентификация
- MySQL
- имя
- Названный
- имена
- родной
- Откройте
- навигационный
- Навигация
- Необходимость
- необходимый
- потребности
- Новые
- вновь
- следующий
- номер
- of
- Предложения
- оффлайн
- Старый
- on
- On-Demand
- ONE
- онлайн
- только
- открытый
- с открытым исходным кодом
- оперативный
- Опция
- or
- заказ
- Другое
- Другое
- внешний
- выходной
- обзор
- страница
- хлеб
- Пароль
- путь
- шаблон
- выполнять
- Разрешения
- Лично
- Телефон
- PII
- трубопровод
- Часть
- одноцветный
- план
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- сборах
- Портал
- После
- Postgresql
- Питание
- Подготовить
- Готовит
- предпосылки
- представить
- разрабатывает
- предварительный просмотр
- предыдущий
- в первую очередь
- Основной
- Предварительный
- проблемам
- продолжить
- процесс
- обрабатываемых
- Процессы
- обработка
- Произведенный
- Продукт
- Менеджер по продукции
- Продукция
- Продукты и услуги
- Программы
- Проект
- обеспечивать
- при условии
- Недвижимости
- приводит
- цель
- целей
- Питон
- Запросы
- вопрос
- быстро
- ассортимент
- Читать
- готовый
- Получать
- учет
- назвало
- область
- отношения
- соответствующие
- удаление
- повторять
- Отчеты
- запросить
- обязательный
- Полезные ресурсы
- те
- отзывчивый
- Итоги
- сохранять
- обзоре
- верховая езда
- роли
- корень
- Правило
- Run
- бегун
- Бег
- главная
- то же
- Сохранить
- Шкала
- Сценарии
- считаться
- сфера
- Поиск
- Во-вторых
- Раздел
- безопасный
- безопасность
- посмотреть
- выбранный
- выбор
- Отправить
- послать
- отдельный
- служить
- Serverless
- обслуживание
- Услуги
- набор
- установка
- Поделиться
- общие
- Короткое
- показанный
- Шоу
- просто
- упрощенный
- упрощение
- Размер
- навыки
- So
- Software
- разработка программного обеспечения
- Решение
- Решения
- Источник
- Источники
- специалист
- специализируется
- конкретный
- указанный
- Расходы
- Спорт
- SQL
- стек
- автономные
- стандарт
- Начало
- начинается
- Статус:
- Шаг
- Шаги
- диск
- хранить
- строка
- структурированный
- успешный
- Успешно
- такие
- Поддержка
- Убедитесь
- Сидней
- системы
- ТАБЛИЦЫ
- Живая картина
- взять
- принимает
- команда
- команды
- Технический
- технические навыки
- Терминал
- который
- Ассоциация
- Источник
- их
- тогда
- Там.
- Эти
- сторонние
- этой
- три
- Через
- время
- в
- сегодня
- инструменты
- топ
- Топ-10
- Всего
- Transform
- трансформация
- преобразований
- преобразован
- превращение
- прообразы
- срабатывает
- два
- напишите
- Типы
- под
- лежащий в основе
- понимать
- обновление
- Updates
- на
- URI
- us
- использование
- прецедент
- используемый
- Информация о пользователе
- Пользовательский интерфейс
- пользователей
- через
- Наши ценности
- переменная
- разнообразие
- версия
- с помощью
- Вид
- хотеть
- Путь..
- we
- Web
- веб-сервисы
- ЧТО Ж
- когда
- который
- в то время как
- широкий
- Широкий диапазон
- жена
- будете
- в
- без
- Работа
- рабочий
- работает
- бы
- записывать
- лет
- являетесь
- ВАШЕ
- зефирнет