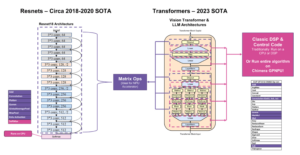
Технический документ под названием «Массивный дата-центричный параллелизм в эпоху чиплетов» был опубликован исследователями Принстонского университета.
Абстрактные:
«Традиционно приложения с массовым параллелизмом выполняются в распределенных системах, где вычислительные узлы расположены достаточно далеко, поэтому схемы распараллеливания должны минимизировать обмен данными и синхронизацию для достижения масштабируемости. Сопоставление ресурсоемких рабочих нагрузок с распределенными системами требует сложного разделения проблем и предварительной обработки набора данных. Учитывая текущую тенденцию использования искусственного интеллекта, заключающуюся в наличии тысяч взаимосвязанных процессоров на одном кристалле, появляется возможность переосмыслить эти рабочие нагрузки, связанные с узкими местами связи. Это узкое место часто возникает из-за обхода структуры данных, что приводит к нерегулярному доступу к памяти и плохой локальности кэша.
В недавних работах были представлены схемы распараллеливания на основе задач для ускорения обхода графа и других разреженных рабочих нагрузок. Обход структуры данных разбивается на задачи и распределяется по конвейерам между процессорами (PU). Dalorex продемонстрировал высочайшую масштабируемость (до тысяч PU на одном чипе), имея весь набор данных на кристалле, разбросанный по PU и выполняя задачи на том PU, где данные являются локальными. Однако это также подняло вопросы о том, как масштабироваться для более крупных наборов данных, когда вся память находится на кристалле, и какой ценой.
Для решения этих проблем мы предлагаем масштабируемую архитектуру, состоящую из сетки микросхем Data-Centric Reconfigurable Array (DCRA). Реконфигурация во время пакета позволяет создавать продукты на основе микросхем, которые оптимизируются для различных целевых показателей, таких как время принятия решения, энергопотребление или стоимость, а реконфигурация программного обеспечения позволяет избежать перенасыщения сети при масштабировании до миллионов PU во многих пакетах микросхем. Мы оцениваем шесть приложений и четыре набора данных с несколькими конфигурациями и технологиями памяти, чтобы обеспечить подробный анализ производительности, мощности и стоимости локального выполнения данных в масштабе. Наше распараллеливание поиска в ширину с RMAT-26 на миллионе PU достигает 3323 GTEPS».
Найдите техническое бумага здесь. Опубликовано в апреле 2023 г. (препринт).
Оренеш-Вера, Марсело, Эсин Туречи, Дэвид Венцлаф и Маргарет Мартоноси. «Массовый параллелизм, ориентированный на данные, в эпоху чиплетов». Препринт arXiv arXiv: 2304.09389 (2023).
Похожие страницы:
Мини-консорциумы формируются вокруг чиплетов
Коммерческие рынки чиплетов все еще находятся на отдаленном горизонте, но компании начинают рано начинать с более ограниченного партнерства.
Риски безопасности чипсетов недооценены
Масштабы проблем безопасности для коммерческих чиплетов пугают.
Гонка за чипсетами смешанного производства
Проблемы сборки чиплетов на разных литейных заводах только начинают проявляться.
Аспекты проектирования и последние достижения в области чиплетов (Калифорнийский университет в Беркли/Пекинский университет)
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Источник: https://semiengineering.com/data-centric-reconfigurable-array-dcra-chiplets-princeton/
- :является
- :куда
- $UP
- 2023
- a
- ускорять
- Достигать
- через
- адрес
- достижения
- Все
- причислены
- an
- анализ
- и
- Приложения
- апрель
- архитектура
- МЫ
- около
- массив
- AS
- At
- начало
- но
- by
- кэш
- Вызывать
- проблемы
- чип
- коммерческая
- Связь
- Компании
- сложный
- состоящие
- вычисление
- соображения
- Цена
- Создающий
- Текущий
- данным
- Наборы данных
- Давид
- убивают
- подробный
- различный
- отдаленный
- распределенный
- распределенные системы
- Рано
- позволяет
- энергетика
- достаточно
- Весь
- Эпоха
- оценивать
- проведение
- выполнение
- Что касается
- 4
- от
- получающий
- график
- сетка
- Есть
- имеющий
- наивысший
- горизонт
- Как
- How To
- Однако
- HTTPS
- in
- взаимосвязано
- в
- выпустили
- IT
- всего
- больше
- Ограниченный
- локальным
- многих
- отображение
- рынки
- массивно
- Память
- Метрика
- миллиона
- миллионы
- БОЛЕЕ
- сеть
- узлы
- of
- on
- Возможность
- Оптимизировать
- or
- Другое
- наши
- пакеты
- бумага & картон
- Параллельные
- партнерства
- Пекин
- производительность
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- состояния потока
- мощностью
- Принстон
- Проблема
- обработка
- процессоры
- Продукция
- предлагает
- обеспечивать
- опубликованный
- Вопросы
- Гонки
- поднятый
- доходит до
- последний
- требуется
- исследователи
- рисках,
- Масштабируемость
- масштабируемые
- Шкала
- масштабирование
- рассеянный
- схемы
- безопасность
- риски безопасности
- несколько
- одинарной
- ШЕСТЬ
- Software
- раскол
- Начало
- По-прежнему
- Структура
- такие
- синхронизация
- системы
- цель
- задачи
- Технический
- технологии
- который
- Ассоциация
- Там.
- Эти
- этой
- тысячи
- титулованный
- в
- к
- тенденция
- единиц
- Университет
- законопроект
- we
- Что
- который
- в то время как
- работает
- зефирнет