Это совместный пост, написанный совместно AWS и Voxel51. Voxel51 — компания, разработавшая FiftyOne, набор инструментов с открытым исходным кодом для создания высококачественных наборов данных и моделей компьютерного зрения.
Розничная компания разрабатывает мобильное приложение, чтобы помочь покупателям покупать одежду. Для создания этого приложения им нужен высококачественный набор данных, содержащий изображения одежды, помеченные разными категориями. В этом посте мы покажем, как перепрофилировать существующий набор данных с помощью очистки данных, предварительной обработки и предварительной маркировки с помощью нулевой модели классификации в Пятьдесят один, и корректируя эти метки с помощью Amazon SageMaker - основа правды.
Вы можете использовать Ground Truth и FiftyOne для ускорения вашего проекта маркировки данных. Мы покажем, как без проблем использовать два приложения вместе для создания высококачественных размеченных наборов данных. Для нашего примера использования мы работаем с Набор данных Fashion200K, выпущенный на ICCV 2017.
Обзор решения
Ground Truth — это полностью автономная и управляемая служба маркировки данных, которая позволяет специалистам по данным, инженерам по машинному обучению (ML) и исследователям создавать высококачественные наборы данных. Пятьдесят один by Воксель51 — это набор инструментов с открытым исходным кодом для курирования, визуализации и оценки наборов данных компьютерного зрения, чтобы вы могли обучать и анализировать лучшие модели, ускоряя свои варианты использования.
В следующих разделах мы покажем, как сделать следующее:
- Визуализируйте набор данных в FiftyOne
- Очистите набор данных с помощью фильтрации и дедупликации изображений в FiftyOne.
- Предварительно пометьте очищенные данные нулевой классификацией в FiftyOne.
- Пометьте меньший кураторский набор данных с помощью Ground Truth
- Вставьте помеченные результаты из Ground Truth в FiftyOne и просмотрите помеченные результаты в FiftyOne.
Обзор вариантов использования
Предположим, вы владеете розничной компанией и хотите создать мобильное приложение, чтобы давать персонализированные рекомендации, чтобы помочь пользователям решить, что им надеть. Ваши потенциальные пользователи ищут приложение, которое сообщает им, какие предметы одежды в их шкафу хорошо сочетаются друг с другом. Вы видите здесь возможность: если вы можете определить хорошие наряды, вы можете использовать это, чтобы рекомендовать новые предметы одежды, которые дополняют одежду, которая уже есть у покупателя.
Вы хотите сделать все как можно проще для конечного пользователя. В идеале, кто-то, использующий ваше приложение, должен только сфотографировать одежду в своем гардеробе, а ваши модели ML творят чудеса за кулисами. Вы можете обучить универсальную модель или настроить модель под уникальный стиль каждого пользователя с помощью некоторой формы обратной связи.
Однако сначала вам нужно определить, какой тип одежды снимает пользователь. Это рубашка? Пара брюк? Или что-то другое? В конце концов, вы, вероятно, не захотите рекомендовать наряд, состоящий из нескольких платьев или нескольких шляп.
Чтобы решить эту первоначальную задачу, вы хотите создать обучающий набор данных, состоящий из изображений различных предметов одежды с различными узорами и стилями. Чтобы создать прототип с ограниченным бюджетом, вы хотите использовать существующий набор данных.
Чтобы проиллюстрировать и показать вам процесс в этом посте, мы используем набор данных Fashion200K, выпущенный на ICCV 2017. Это установленный и хорошо цитируемый набор данных, но он не подходит напрямую для вашего варианта использования.
Хотя предметы одежды помечены категориями (и подкатегориями) и содержат множество полезных тегов, извлеченных из первоначальных описаний продуктов, данные не систематически маркируются информацией о шаблонах или стилях. Ваша цель — превратить этот существующий набор данных в надежный обучающий набор данных для ваших моделей классификации одежды. Вам нужно очистить данные, дополнив схему маркировки метками стилей. И вы хотите сделать это быстро и с минимальными затратами.
Загрузите данные локально
Сначала загрузите zip-файл women.tar и папку labels (со всеми вложенными папками), следуя инструкциям, приведенным в Репозиторий GitHub набора данных Fashion200K. После того, как вы распаковали их оба, создайте родительский каталог fashion200k и переместите в него папки labels и women. К счастью, эти изображения уже обрезаны до ограничивающих рамок обнаружения объектов, поэтому мы можем сосредоточиться на классификации, а не беспокоиться об обнаружении объектов.
Несмотря на «200K» в названии, извлеченный нами женский каталог содержит 338,339 200 изображений. Чтобы создать официальный набор данных Fashion300,000K, авторы набора данных просканировали более XNUMX XNUMX товаров в Интернете, и только товары с описаниями, содержащими более четырех слов, попали в список. Для наших целей, когда описание продукта не является существенным, мы можем использовать все просканированные изображения.
Давайте посмотрим, как организованы эти данные: в папке для женщин изображения упорядочены по типу статьи верхнего уровня (юбки, топы, брюки, жакеты и платья) и подкатегории типа статьи (блузки, футболки, рубашки с длинными рукавами). вершины).
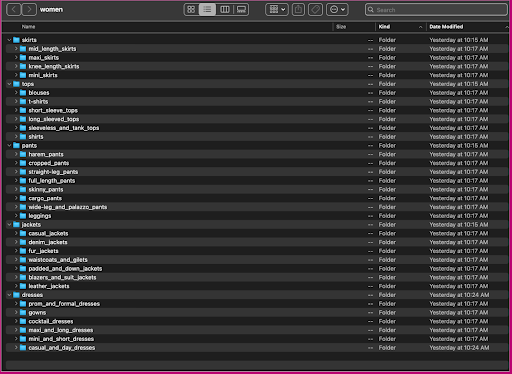
В каталогах подкатегорий есть подкаталог для каждого списка продуктов. Каждый из них содержит переменное количество изображений. Например, подкатегория «cropped_pants» содержит следующие списки продуктов и связанные с ними изображения.
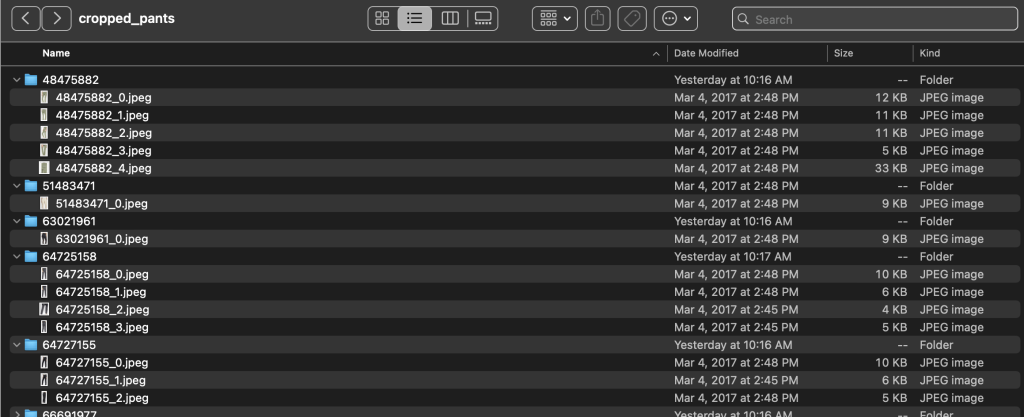
Папка labels содержит текстовый файл для каждого типа статьи верхнего уровня, как для поездов, так и для тестов. В каждом из этих текстовых файлов есть отдельная строка для каждого изображения с указанием относительного пути к файлу, оценки и тегов из описания продукта.
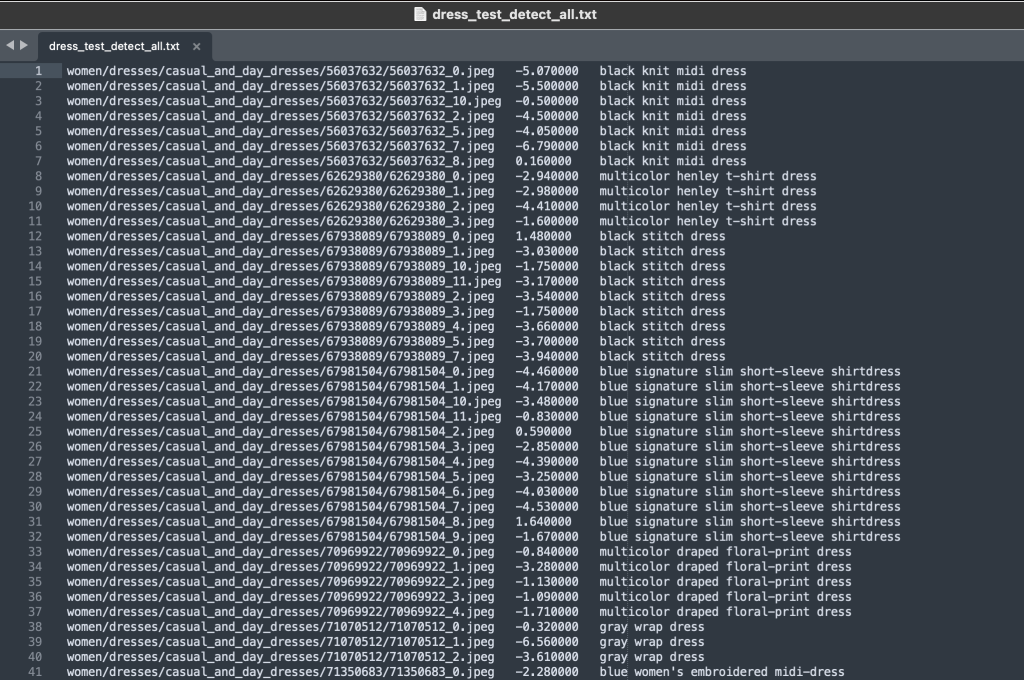
Поскольку мы переназначаем набор данных, мы объединяем все изображения поезда и теста. Мы используем их для создания высококачественного набора данных для конкретного приложения. После того, как мы завершим этот процесс, мы можем случайным образом разделить полученный набор данных на новые поезда и тесты.
Внедрение, просмотр и курирование набора данных в FiftyOne
Если вы еще этого не сделали, установите FiftyOne с открытым исходным кодом, используя pip:
Лучше всего делать это в новой виртуальной среде (venv или conda). Затем импортируйте соответствующие модули. Импортируйте базовую библиотеку, пятьдесят один, FiftyOne Brain со встроенными методами машинного обучения, FiftyOne Zoo, из которого мы будем загружать модель, которая будет генерировать для нас нулевые метки, и ViewField, который позволяет нам эффективно фильтровать данные в нашем наборе данных:
Вы также хотите импортировать модули glob и os Python, которые помогут нам работать с путями и сопоставлением шаблонов в содержимом каталога:
Теперь мы готовы загрузить набор данных в FiftyOne. Во-первых, мы создаем набор данных с именем fashion200k и делаем его постоянным, что позволяет нам сохранять результаты операций с интенсивными вычислениями, поэтому нам нужно вычислить указанные количества только один раз.
Теперь мы можем перебирать все каталоги подкатегорий, добавляя все изображения в каталоги продуктов. Мы добавляем классификационную метку FiftyOne к каждому образцу с именем поля article_type, заполненным категорией статьи верхнего уровня изображения. Мы также добавляем информацию о категориях и подкатегориях в виде тегов:
На данный момент мы можем визуализировать наш набор данных в приложении FiftyOne, запустив сеанс:
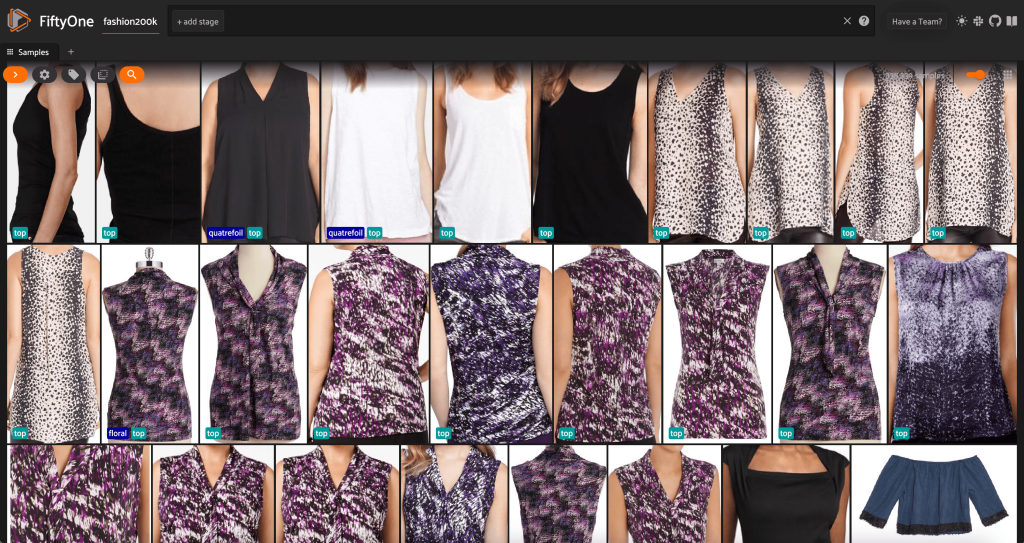
Мы также можем распечатать сводку набора данных в Python, запустив print(dataset):
Мы также можем добавить теги из labels каталог с образцами в нашем наборе данных:
Глядя на данные, становится ясно несколько вещей:
- Некоторые изображения довольно зернистые, с низким разрешением. Вероятно, это связано с тем, что эти изображения были сгенерированы путем обрезки исходных изображений в ограничивающих прямоугольниках обнаружения объектов.
- Какую-то одежду носит человек, а какую-то фотографирует самостоятельно. Эти детали инкапсулируются
viewpointимущество. - Многие изображения одного и того же продукта очень похожи, поэтому, по крайней мере на начальном этапе, включение более одного изображения для каждого продукта может не добавить большой предсказательной силы. По большей части первое изображение каждого продукта (заканчивающееся на
_0.jpeg) самый чистый.
Первоначально мы можем захотеть обучить нашу модель классификации стиля одежды на контролируемом подмножестве этих изображений. С этой целью мы используем изображения наших продуктов с высоким разрешением и ограничиваем наше представление одним репрезентативным образцом для каждого продукта.
Сначала мы отфильтровываем изображения с низким разрешением. Мы используем compute_metadata() метод для вычисления и сохранения ширины и высоты изображения в пикселях для каждого изображения в наборе данных. Затем мы нанимаем FiftyOne ViewField для фильтрации изображений на основе минимально допустимых значений ширины и высоты. См. следующий код:
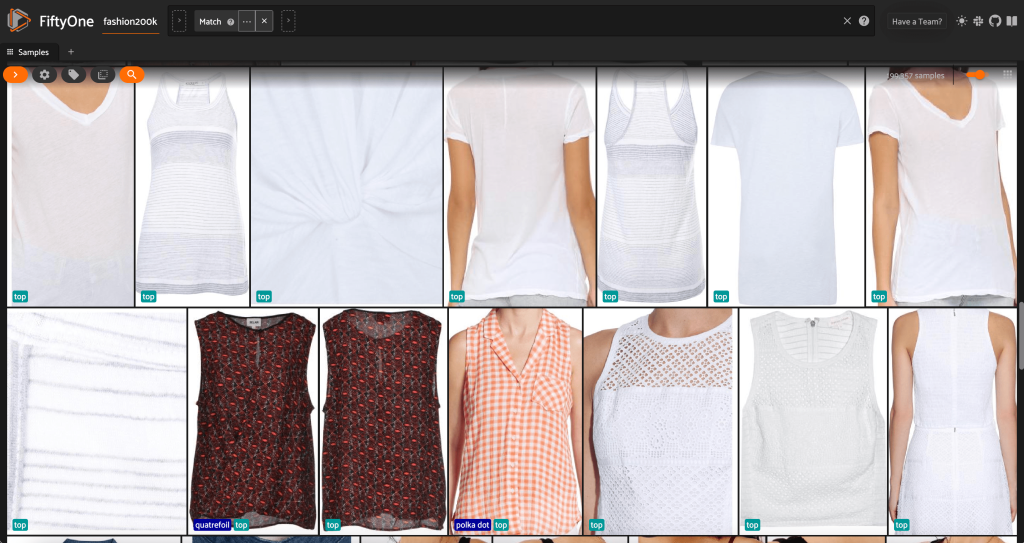
Это подмножество с высоким разрешением содержит чуть менее 200,000 XNUMX сэмплов.
Из этого представления мы можем создать новое представление в нашем наборе данных, содержащее только одну репрезентативную выборку (максимум) для каждого продукта. Мы используем ViewField еще раз, сопоставление с образцом для путей к файлам, которые заканчиваются на _0.jpeg:
Давайте посмотрим на случайный порядок изображений в этом подмножестве:
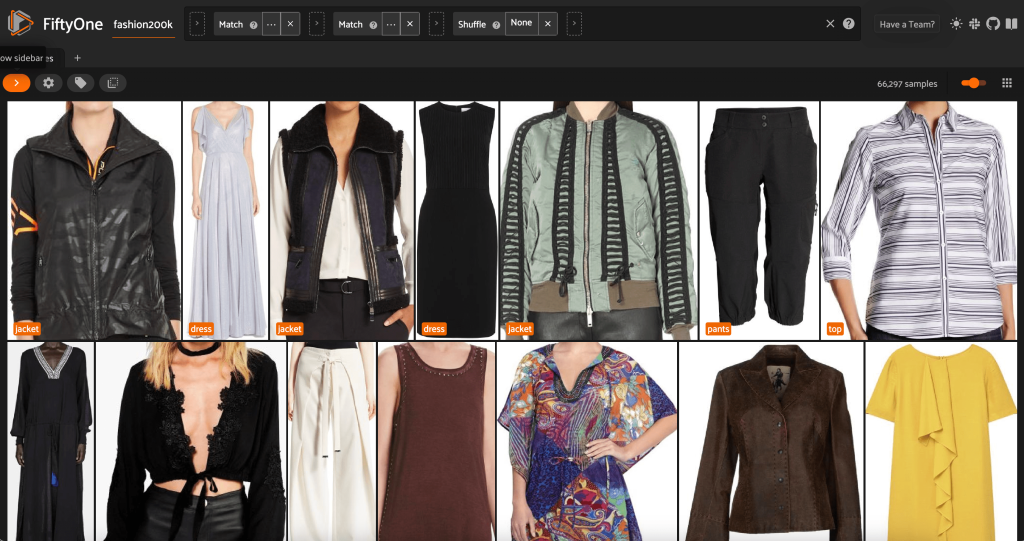
Удалите лишние изображения в наборе данных
Это представление содержит 66,297 19 изображений, или чуть более XNUMX% исходного набора данных. Однако, когда мы смотрим на вид, мы видим, что есть много очень похожих продуктов. Сохранение всех этих копий, скорее всего, только добавит стоимости нашей маркировке и обучению моделей без заметного повышения производительности. Вместо этого давайте избавимся от почти дубликатов, чтобы создать меньший набор данных, который по-прежнему обладает тем же эффектом.
Поскольку эти изображения не являются точными копиями, мы не можем проверить равенство по пикселям. К счастью, мы можем использовать FiftyOne Brain для очистки нашего набора данных. В частности, мы вычислим вложение для каждого изображения — маломерный вектор, представляющий изображение, — а затем будем искать изображения, чьи векторы вложения близки друг к другу. Чем ближе векторы, тем больше похожи изображения.
Мы используем модель CLIP для создания 512-мерного вектора встраивания для каждого изображения и сохраняем эти вложения в полях вложений образцов в нашем наборе данных:
Затем мы вычисляем близость между вложениями, используя косинусное подобие, и утверждают, что любые два вектора, сходство которых превышает некоторый порог, скорее всего, будут почти дубликатами. Показатели косинусного подобия лежат в диапазоне [0, 1], и, глядя на данные, пороговый показатель thresh=0.5 кажется правильным. Опять же, это не должно быть идеально. Несколько почти дублирующихся изображений вряд ли испортят нашу прогностическую способность, а удаление нескольких неповторяющихся изображений не повлияет существенно на производительность модели.
Мы можем просмотреть предполагаемые дубликаты, чтобы убедиться, что они действительно избыточны:
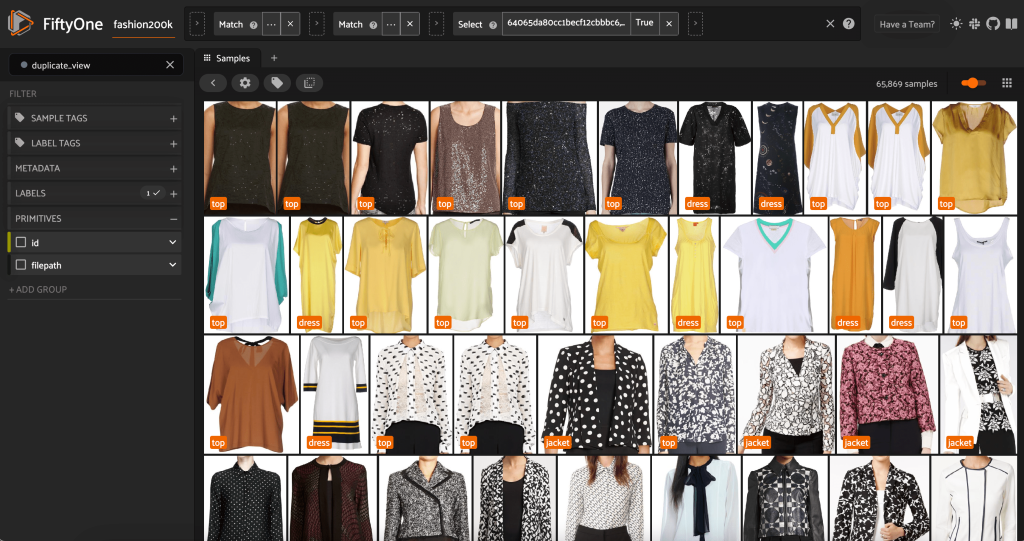
Когда мы довольны результатом и считаем, что эти изображения действительно близки к дубликатам, мы можем выбрать один образец из каждого набора похожих образцов, чтобы сохранить его, и проигнорировать остальные:
Сейчас в этом представлении 3,729 изображений. Путем очистки данных и определения высококачественного подмножества набора данных Fashion200K FiftyOne позволяет нам ограничить наше внимание с более чем 300,000 4,000 изображений до чуть менее 98 90, что представляет собой сокращение на XNUMX%. Использование встраивания только для удаления почти дубликатов изображений привело к снижению общего количества рассматриваемых изображений более чем на XNUMX%, практически не влияя на модели, которые будут обучаться на этих данных.
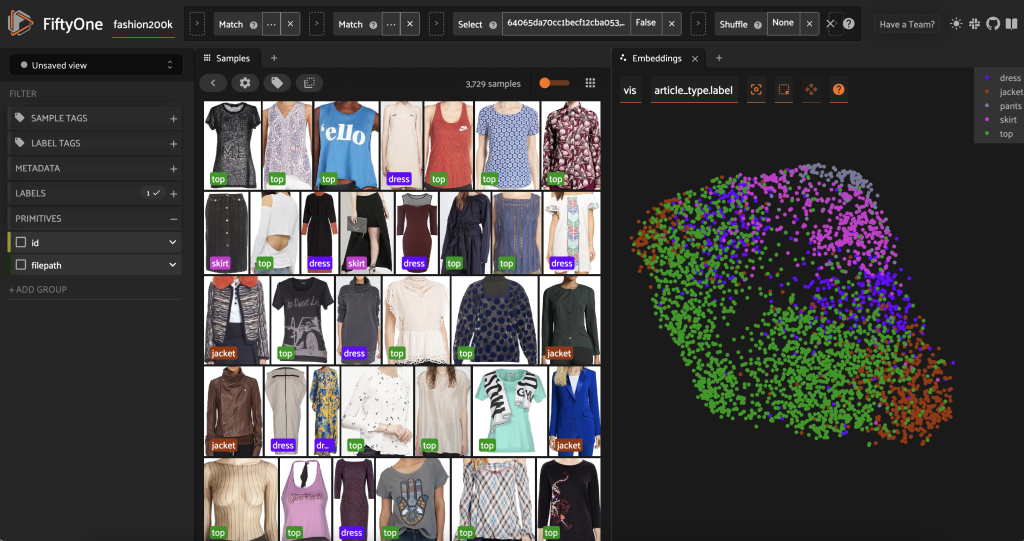
Перед предварительной маркировкой этого подмножества мы можем лучше понять данные, визуализируя уже вычисленные вложения. Мы можем использовать встроенный в FiftyOne Brain compute_visualization(), который использует технику равномерного многообразия (UMAP) для проецирования 512-мерных векторов вложения в двумерное пространство, чтобы мы могли их визуализировать:
Мы открываем новый Панель встраивания в приложении FiftyOne и раскрашивание по типу статьи, и мы видим, что эти вложения примерно кодируют понятие типа статьи (среди прочего!).
Теперь мы готовы предварительно разметить эти данные.
Изучая эти очень уникальные изображения с высоким разрешением, мы можем создать достойный начальный список стилей для использования в качестве классов в нашей нулевой классификации с предварительной маркировкой. Наша цель в предварительной маркировке этих изображений не обязательно правильно маркировать каждое изображение. Скорее, наша цель — предоставить хорошую отправную точку для людей-аннотаторов, чтобы мы могли сократить время и стоимость маркировки.
Затем мы можем создать экземпляр нулевой модели классификации для этого приложения. Мы используем модель CLIP, которая представляет собой модель общего назначения, обученную как изображениям, так и естественному языку. Мы создаем модель CLIP с текстовой подсказкой «Одежда в стиле», чтобы при заданном изображении модель выдавала класс, для которого лучше всего подходит «Одежда в стиле [класс]». CLIP не обучается на данных, связанных с розничной торговлей или модой, поэтому он не будет идеальным, но он может сэкономить вам затраты на маркировку и аннотацию.
Затем мы применяем эту модель к нашему сокращенному подмножеству и сохраняем результаты в article_style поле:
Запустив приложение FiftyOne еще раз, мы можем визуализировать изображения с этими метками предсказанного стиля. Мы сортируем по достоверности предсказания, поэтому сначала просматриваем наиболее достоверные предсказания стиля:
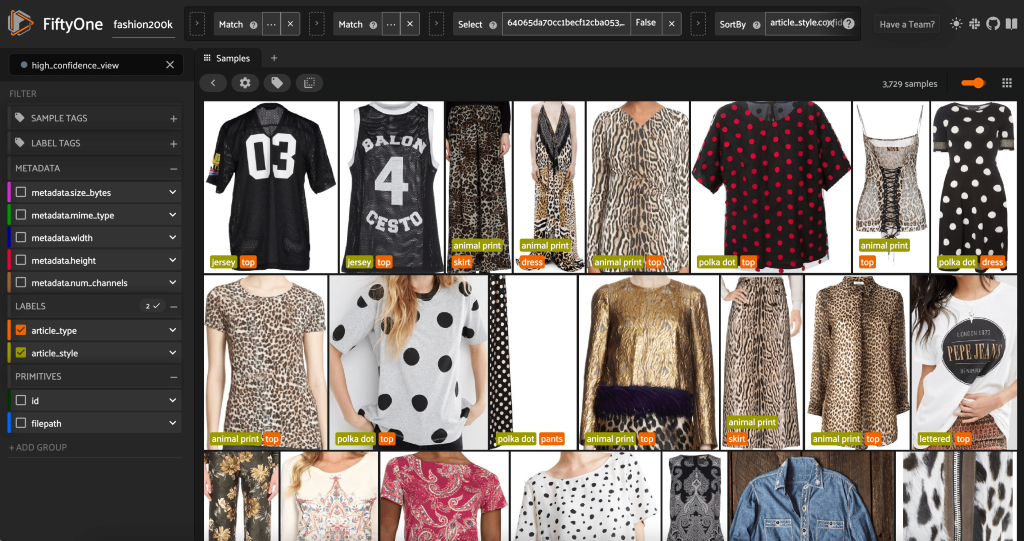
Мы видим, что прогнозы с наивысшей достоверностью кажутся для стилей «джерси», «звериный принт», «горошек» и «буквы». Это имеет смысл, потому что эти стили относительно различны. Также кажется, что по большей части предсказанные метки стилей точны.
Мы также можем взглянуть на предсказания стиля с самой низкой достоверностью:
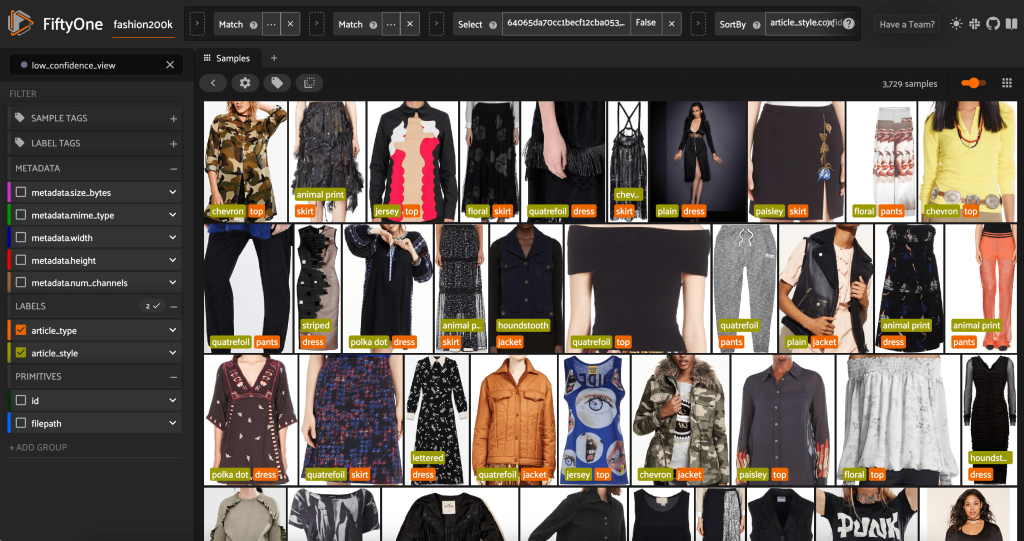
Для некоторых из этих изображений соответствующая категория стиля указана в предоставленном списке, а предмет одежды помечен неправильно. Например, первое изображение в сетке должно быть явно «камуфляж», а не «шеврон». В других случаях, однако, продукты не вписываются точно в категории стилей. Платье на втором изображении во втором ряду, например, не совсем «полосатое», но с учетом тех же вариантов маркировки человек-аннотатор также мог столкнуться с конфликтом. По мере того, как мы создаем наш набор данных, нам нужно решить, следует ли удалить такие пограничные случаи, добавить новые категории стилей или расширить набор данных.
Экспортируйте окончательный набор данных из FiftyOne
Экспортируйте окончательный набор данных с помощью следующего кода:
Мы можем экспортировать меньший набор данных, например, 16 изображений, в папку 200kFashionDatasetExportResult-16Images. Мы создаем задание корректировки Ground Truth, используя его:
Загрузите исправленный набор данных, преобразуйте формат метки в Ground Truth, загрузите в Amazon S3 и создайте файл манифеста для задания корректировки.
Мы можем преобразовать метки в наборе данных, чтобы они соответствовали выходная схема манифеста задания ограничительной рамки Ground Truth и загрузите изображения в Простой сервис хранения Amazon (Amazon S3) для запуска Работа по корректировке правды на землю:
Загрузите файл манифеста в Amazon S3 со следующим кодом:
Создавайте этикетки с исправленным стилем с помощью Ground Truth
Чтобы аннотировать ваши данные метками стиля с помощью Ground Truth, выполните необходимые шаги, чтобы начать задание маркировки ограничительной рамки, следуя процедуре, описанной в Начало работы с правдой на землю руководство с набором данных в той же корзине S3.
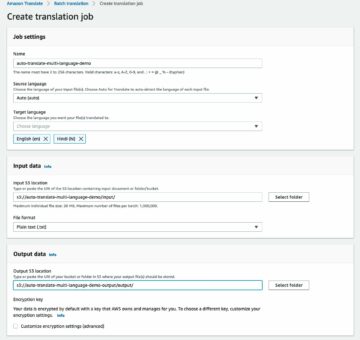
- На консоли SageMaker создайте задание маркировки Ground Truth.
- Установить Местоположение входного набора данных быть манифестом, который мы создали на предыдущих шагах.
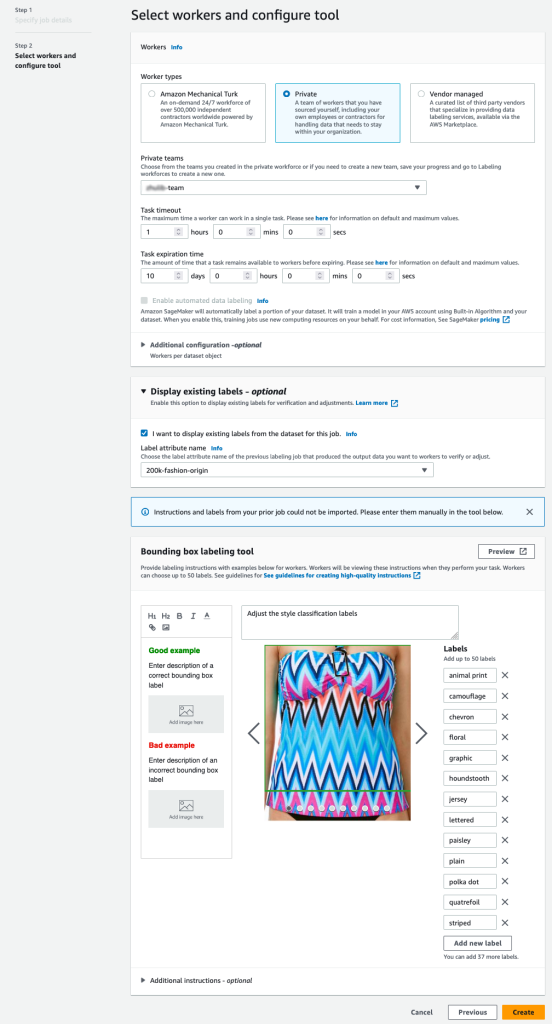
- Укажите путь S3 для Расположение выходного набора данных.
- Что касается Роль IAM, выберите Введите пользовательскую роль IAM РНК, затем введите роль ARN.
- Что касается Категория задачи, выберите Фото товара и Ограничительная рамка.
- Выберите Следующая.
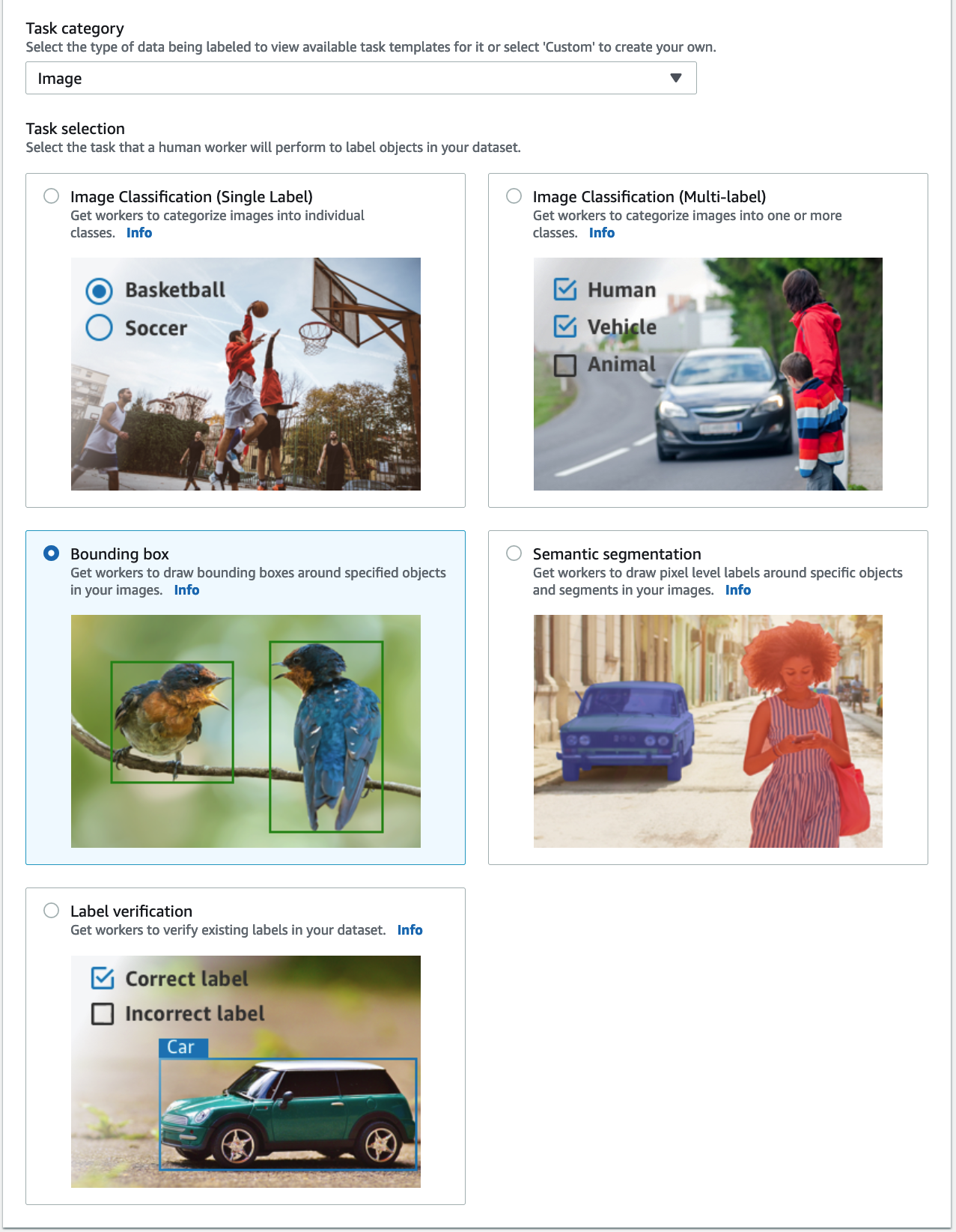
- В Рабочие раздел, выберите тип рабочей силы, которую вы хотели бы использовать.
Вы можете выбрать рабочую силу через Amazon Mechanical Turk, сторонних поставщиков или ваших собственных сотрудников. Дополнительные сведения о вариантах рабочей силы см. Создание и управление персоналом. - Расширьте Параметры отображения существующих ярлыков и Я хочу отобразить существующие метки из набора данных для этой работы.
- Что касается Атрибут ярлыка имя, выберите имя из манифеста, соответствующее меткам, которые вы хотите отобразить для настройки.
Вы увидите имена атрибутов меток только для меток, которые соответствуют типу задачи, выбранному на предыдущих шагах. - Вручную введите метки для Инструмент маркировки ограничивающей рамки.
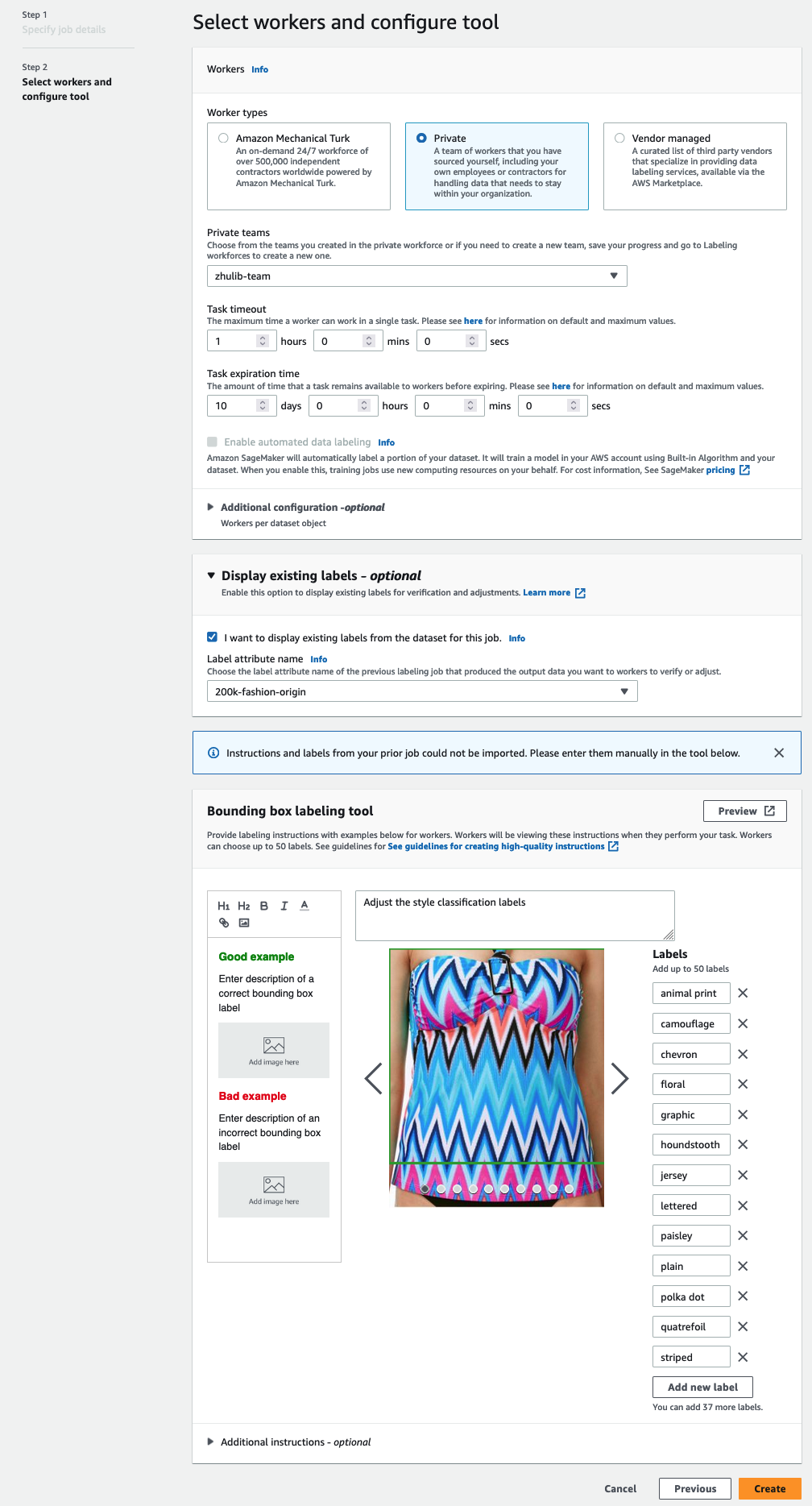 Метки должны содержать те же метки, что и в общедоступном наборе данных. Вы можете добавить новые метки. На следующем снимке экрана показано, как выбрать рабочих и настроить инструмент для своего задания по маркировке.
Метки должны содержать те же метки, что и в общедоступном наборе данных. Вы можете добавить новые метки. На следующем снимке экрана показано, как выбрать рабочих и настроить инструмент для своего задания по маркировке.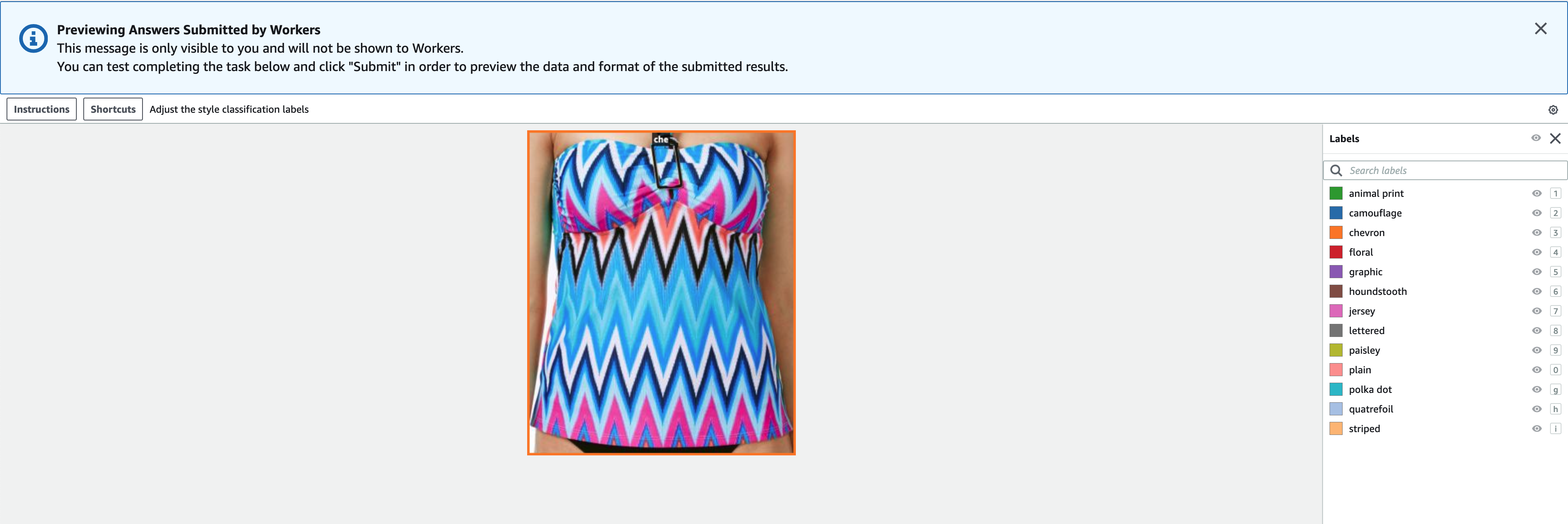
- Выберите предварительный просмотр для предварительного просмотра изображения и исходных аннотаций.
Теперь мы создали задание по маркировке в Ground Truth. После завершения нашей работы мы можем загрузить вновь сгенерированные размеченные данные в FiftyOne. Ground Truth создает выходные данные в выходном манифесте Ground Truth. Дополнительные сведения о выходном файле манифеста см. Выходные данные задания ограничивающей рамки. В следующем коде показан пример формата выходного манифеста:
Просмотрите помеченные результаты Ground Truth в FiftyOne
После завершения задания загрузите выходной манифест задания маркировки с Amazon S3.
Прочитайте выходной файл манифеста:
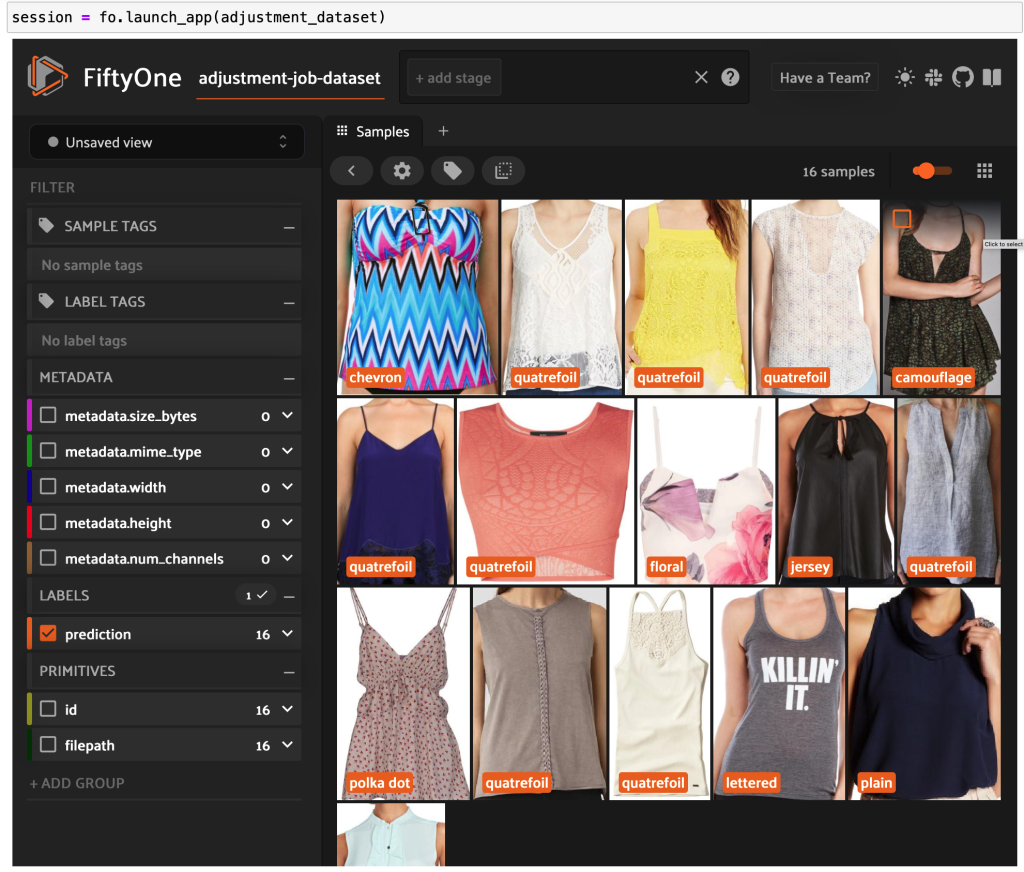
Создайте набор данных FiftyOne и преобразуйте строки манифеста в образцы в наборе данных:
Теперь вы можете видеть высококачественные размеченные данные из Ground Truth в FiftyOne.
Заключение
В этом посте мы показали, как создавать высококачественные наборы данных, комбинируя возможности Пятьдесят один by Воксель51, набор инструментов с открытым исходным кодом, который позволяет вам управлять, отслеживать, визуализировать и курировать ваш набор данных, и Ground Truth, службу маркировки данных, которая позволяет вам эффективно и точно маркировать наборы данных, необходимые для обучения систем машинного обучения, предоставляя доступ к множеству встроенных -в шаблонах задач и доступе к разнообразной рабочей силе через Mechanical Turk, сторонних поставщиков или вашу собственную частную рабочую силу.
Мы рекомендуем вам опробовать эту новую функцию, установив экземпляр FiftyOne и используя консоль Ground Truth для начала работы. Чтобы узнать больше о Ground Truth, см. Данные этикетки, Часто задаваемые вопросы о маркировке данных Amazon SageMaker, и Блог машинного обучения AWS.
Подключитесь к Сообщество машинного обучения и искусственного интеллекта если у вас есть какие-либо вопросы или отзывы!
Присоединяйтесь к сообществу FiftyOne!
Присоединяйтесь к тысячам инженеров и специалистов по данным, уже использующих FiftyOne для решения некоторых из самых сложных задач в области компьютерного зрения уже сегодня!
Об авторах
Шалендра Чабра в настоящее время является руководителем отдела управления продуктами Amazon SageMaker Human-in-the-Loop (HIL) Services. Ранее Шалендра разработала и руководила подразделением Language and Conversation Intelligence для собраний Microsoft Teams, была EIR в Amazon Alexa Techstars Startup Accelerator, вице-президентом по продукту и маркетингу в Обсудить.io, руководитель отдела продуктов и маркетинга в Clipboard (приобретен Salesforce) и ведущий менеджер по продуктам в Swype (приобретен Nuance). В общей сложности Shalendra помогла создать, поставить и продать продукты, которые затронули более миллиарда жизней.
Джейкоб Маркс является инженером по машинному обучению и разработчиком-евангелистом в Voxel51, где он помогает сделать мировые данные прозрачными и четкими. До прихода в Voxel51 Джейкоб основал стартап, чтобы помочь начинающим музыкантам общаться и делиться творческим контентом с фанатами. До этого он работал в Google X, Samsung Research и Wolfram Research. В прошлой жизни Джейкоб был физиком-теоретиком, получив докторскую степень в Стэнфорде, где он исследовал квантовые фазы материи. В свободное время Джейкоб любит лазать, бегать и читать фантастические романы.
Джейсон Корсо является соучредителем и генеральным директором Voxel51, где он руководит стратегией, помогая обеспечить прозрачность и ясность мировых данных с помощью современного гибкого программного обеспечения. Он также является профессором робототехники, электротехники и компьютерных наук в Мичиганском университете, где занимается передовыми проблемами на стыке компьютерного зрения, естественного языка и физических платформ. В свободное время Джейсон любит проводить время со своей семьей, читать, бывать на природе, играть в настольные игры и заниматься всевозможной творческой деятельностью.
Брайан Мур является соучредителем и техническим директором Voxel51, где он руководит технической стратегией и видением. Он имеет докторскую степень по электротехнике Мичиганского университета, где его исследования были сосредоточены на эффективных алгоритмах для крупномасштабных задач машинного обучения с особым акцентом на приложениях компьютерного зрения. В свободное время он любит бадминтон, гольф, походы и игры со своими близнецами йоркширскими терьерами.
Чжулин Бай работает инженером-разработчиком программного обеспечения в Amazon Web Services. Она занимается разработкой крупномасштабных распределенных систем для решения задач машинного обучения.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- О нас
- ускорять
- ускоряющий
- ускоритель
- доступ
- точный
- точно
- приобретенный
- активно
- Добавить
- добавить
- адрес
- Отрегулированный
- Регулировка
- После
- снова
- AI
- Alexa
- алгоритмы
- Все
- позволяет
- в одиночестве
- уже
- Также
- Amazon
- Amazon alexa
- Создатель мудреца Амазонки
- Amazon SageMaker - основа правды
- Amazon Web Services
- среди
- an
- анализировать
- и
- животное
- любой
- приложение
- Применение
- Приложения
- Применить
- соответствующий
- МЫ
- расположены
- гайд
- статьи
- AS
- связанный
- At
- Авторы
- прочь
- AWS
- Использование темпера с изогнутым основанием
- основанный
- BE
- , так как:
- становиться
- было
- до
- за
- за кулисами
- не являетесь
- верить
- ЛУЧШЕЕ
- Лучшая
- между
- миллиард
- доска
- Настольные игры
- КОСТИ
- Начальная загрузка
- изоферменты печени
- Коробка
- коробки
- Мозг
- Ломать
- приносить
- принес
- бюджет
- строить
- Строительство
- встроенный
- но
- купить
- by
- CAN
- Захват
- случаев
- случаев
- категории
- Категории
- Генеральный директор
- вызов
- сложные
- проверка
- Выберите
- ясность
- класс
- классов
- классификация
- Уборка
- Очистить
- явно
- клиент
- Восхождение
- Закрыть
- ближе
- одежда
- Одежда
- Соучредитель
- код
- объединять
- комбинируя
- Компания
- комплемент
- полный
- комплектующие
- Вычисление
- компьютер
- Информатика
- Компьютерное зрение
- Приложения компьютерного зрения
- доверие
- уверенный
- Свяжитесь
- рассмотрение
- Состоящий из
- Консоли
- содержит
- содержание
- содержание
- контроль
- диалоговый
- конвертировать
- копии
- Основные
- исправленный
- соответствует
- Цена
- Расходы
- Создайте
- создали
- творческий
- Полномочия
- CTO
- Куратор
- курирование
- В настоящее время
- изготовленный на заказ
- клиент
- Клиенты
- Порез
- передовой
- данным
- Наборы данных
- решать
- демонстрировать
- джинсовая ткань
- глубина
- описание
- подробнее
- обнаружение
- Застройщик
- развивающийся
- Развитие
- различный
- непосредственно
- каталоги
- Дисплей
- отчетливый
- распределенный
- распределенные системы
- Разное
- do
- не
- Собака
- дело
- сделанный
- Dont
- DOT
- вниз
- скачать
- дубликаты
- e
- каждый
- легко
- Edge
- эффект
- эффективный
- эффективно
- электротехника
- вложения
- появление
- акцент
- работает
- Наделяет
- инкапсулированный
- поощрять
- конец
- инженер
- Проект и
- Инженеры
- Enter
- Окружающая среда
- равенство
- существенный
- установленный
- Эфир (ETH)
- оценки
- Евангелист
- точно,
- пример
- существующий
- экспорт
- достаточно
- семья
- вентиляторы
- Обратная связь
- несколько
- Рассказы
- поле
- Поля
- Файл
- Файлы
- фильтр
- фильтрация
- окончательный
- First
- соответствовать
- гибкого
- Фокус
- внимание
- фокусируется
- после
- Что касается
- форма
- формат
- К счастью
- Основана
- 4
- Бесплатно
- от
- полностью
- функциональность
- Игры
- общее назначение
- порождать
- генерируется
- получить
- GitHub
- Дайте
- данный
- цель
- гольф
- хорошо
- большой
- сетка
- земля
- группы
- инструкция
- счастливый
- Есть
- he
- высота
- помощь
- помог
- полезный
- помогает
- здесь
- высококачественный
- высокое разрешение
- наивысший
- очень
- пеший туризм
- его
- имеет
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- человек
- i
- IAM
- ID
- определения
- идентифицирующий
- идентификаторы
- if
- изображение
- изображений
- Влияние
- Импортировать
- улучшение
- in
- В других
- В том числе
- неверно
- инкубационных
- информация
- начальный
- первоначально
- устанавливать
- Установка
- пример
- вместо
- инструкции
- Интеллекта
- пересечение
- в
- IT
- ЕГО
- Джерси
- работа
- присоединение
- совместная
- JSON
- всего
- Сохранить
- хранение
- этикетка
- маркировка
- Этикетки
- язык
- крупномасштабный
- запуск
- запуск
- вести
- Лиды
- УЧИТЬСЯ
- изучение
- наименее
- привело
- оставил
- Lets
- Библиотека
- ЖИЗНЬЮ
- такое как
- Вероятно
- ОГРАНИЧЕНИЯ
- Ограниченный
- линия
- линий
- Список
- листинг
- Объявления
- мало
- Живет
- загрузка
- посмотреть
- искать
- серия
- Низкий
- машина
- обучение с помощью машины
- сделанный
- магия
- сделать
- ДЕЛАЕТ
- управлять
- управляемого
- управление
- менеджер
- многих
- карта
- рынок
- Маркетинг
- Совпадение
- согласование
- материально
- Вопрос
- Май..
- механический
- Медиа
- заседаниях
- Мета
- Метаданные
- метод
- методы
- Мичиган
- Microsoft
- команды Microsoft
- может быть
- минимальный
- ML
- Мобильный телефон
- Мобильное приложение
- модель
- Модели
- Модули
- БОЛЕЕ
- самых
- двигаться
- много
- с разными
- музыканты
- должен
- имя
- Названный
- имена
- натуральный
- Естественный язык
- природа
- Возле
- обязательно
- необходимо
- Необходимость
- потребности
- Новые
- заметно
- понятие
- сейчас
- Нюанс
- номер
- объект
- Обнаружение объекта
- объекты
- of
- Официальный представитель в Грузии
- on
- консолидировать
- ONE
- онлайн
- только
- открытый
- с открытым исходным кодом
- Операционный отдел
- Возможность
- Опции
- or
- Организованный
- оригинал
- OS
- Другие контрактные услуги
- Другое
- наши
- внешний
- изложенные
- выходной
- за
- собственный
- владеет
- пакеты
- в паре
- часть
- особый
- мимо
- путь
- шаблон
- паттеранами
- ИДЕАЛЬНОЕ
- производительность
- человек
- Персонализированные
- Фазы Материи
- физический
- выбирать
- Картинки
- ПЛЕД
- одноцветный
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- Точка
- населенный
- возможное
- После
- мощностью
- практика
- предсказанный
- прогноз
- Predictions
- предварительный просмотр
- предыдущий
- предварительно
- Печать / PDF
- Предварительный
- частная
- вероятно
- проблемам
- процесс
- Продукт
- Управление продуктом
- Менеджер по продукции
- Продукция
- Профессор
- Проект
- собственность
- предполагаемый
- прототип
- обеспечивать
- при условии
- обеспечение
- что такое варган?
- перфоратор
- целей
- Питон
- Квантовый
- Вопросы
- быстро
- ассортимент
- скорее
- Reading
- готовый
- рекомендовать
- рекомендаций
- уменьшить
- Цена снижена
- снижение
- относительно
- выпустил
- соответствующие
- удаление
- представитель
- представляющий
- обязательный
- исследованиям
- исследователи
- Постановления
- ограничивать
- результат
- в результате
- Итоги
- розничный
- возвращают
- обзоре
- избавиться
- робототехника
- надежный
- Роли
- грубо
- РЯД
- губить
- Бег
- sagemaker
- Сказал
- Salesforce
- то же
- Samsung
- Сохранить
- Сцены
- Наука
- Научная фантастика
- Ученые
- Гол
- легко
- Во-вторых
- Раздел
- разделах
- посмотреть
- казаться
- кажется
- выбранный
- смысл
- отдельный
- обслуживание
- Услуги
- Сессия
- набор
- Поделиться
- она
- должен
- показывать
- Шоу
- SIM
- аналогичный
- просто
- меньше
- So
- Software
- разработка программного обеспечения
- РЕШАТЬ
- некоторые
- Кто-то
- удалось
- Space
- тратить
- Расходы
- раскол
- расколы
- Стэнфорд
- Начало
- и политические лидеры
- Начало
- ввод в эксплуатацию
- ускоритель запуска
- современное состояние
- Шаги
- По-прежнему
- диск
- магазин
- Стратегия
- стиль
- стили
- РЕЗЮМЕ
- Поддержанный
- системы
- взять
- Сложность задачи
- команды
- Технический
- TechStars
- говорит
- шаблоны
- тестXNUMX
- чем
- который
- Ассоциация
- их
- Их
- тогда
- теоретический
- Там.
- Эти
- они
- вещи
- think
- сторонние
- этой
- тысячи
- порог
- Через
- Бросание
- время
- в
- вместе
- инструментом
- Инструментарий
- топ
- верхний уровень
- Топы
- Всего
- тронутый
- трек
- Train
- специалистов
- Обучение
- Transform
- Прозрачность
- правда
- Правда
- ОЧЕРЕДЬ
- два
- напишите
- Типы
- под
- понимать
- созданного
- Университет
- Мичиганский университет
- Обновление ПО
- us
- использование
- прецедент
- используемый
- Информация о пользователе
- пользователей
- через
- Наши ценности
- разнообразие
- различный
- поставщики
- проверить
- очень
- с помощью
- Вид
- Виртуальный
- видение
- хотеть
- законопроект
- we
- Web
- веб-сервисы
- ЧТО Ж
- были
- Что
- когда
- будь то
- который
- Википедия.
- будете
- в
- без
- Женщина
- слова
- Работа
- работавший
- рабочие
- Трудовые ресурсы
- работает
- мире
- беспокоиться
- бы
- записывать
- X
- являетесь
- ВАШЕ
- зефирнет
- ZIP
- ZOO