Изображение по автору
Погружаясь в мир науки о данных и машинного обучения, одним из фундаментальных навыков, с которыми вы столкнетесь, является искусство чтения данных. Если у вас уже есть некоторый опыт работы с ним, вы, вероятно, знакомы с JSON (нотация объектов JavaScript) — популярным форматом хранения и обмена данными.
Подумайте о том, как базы данных NoSQL, такие как MongoDB, любят хранить данные в формате JSON или как API-интерфейсы REST часто отвечают в том же формате.
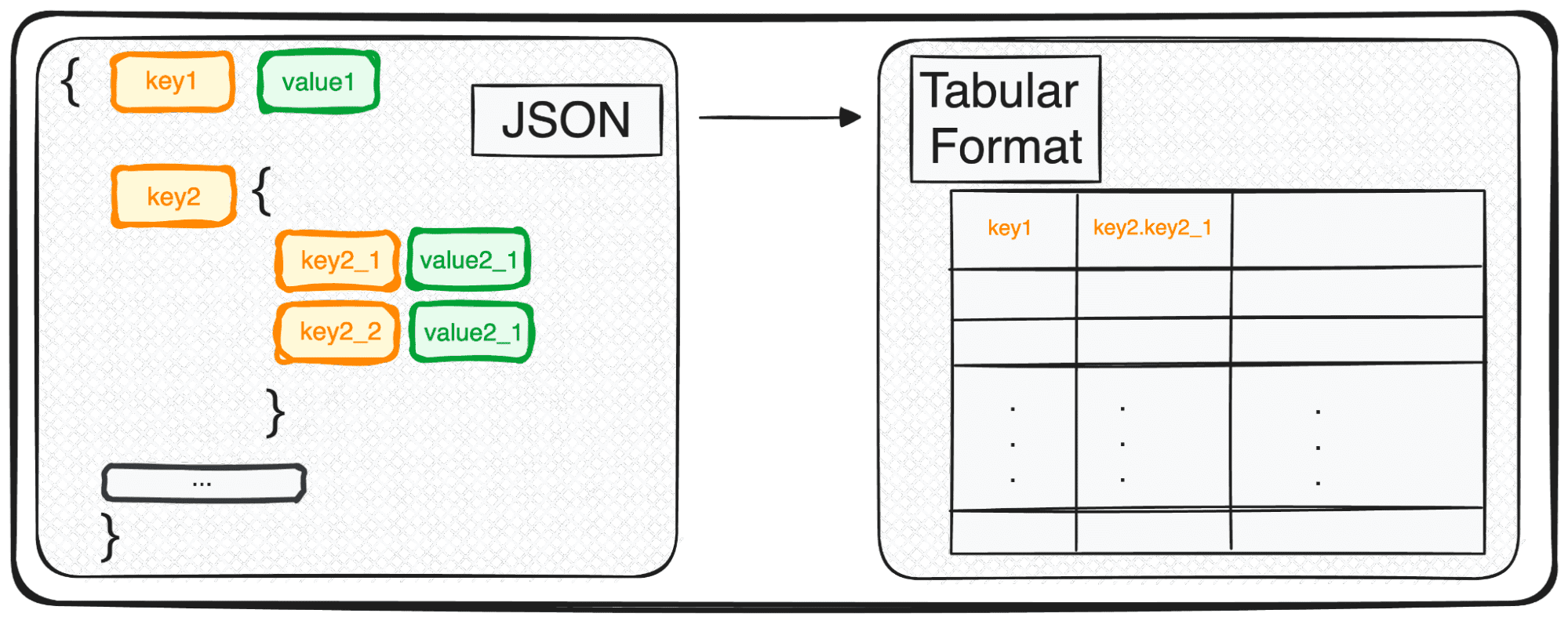
Однако JSON, хотя и идеален для хранения и обмена, в чистом виде не совсем готов к углубленному анализу. Здесь мы преобразуем его в нечто более удобное для анализа – табличный формат.
Итак, имеете ли вы дело с одним объектом JSON или с восхитительным их массивом, с точки зрения Python, вы, по сути, обрабатываете словарь или список словарей.
Давайте вместе исследуем, как разворачивается эта трансформация, благодаря чему наши данные созревают для анализа ????
Сегодня я объясню волшебную команду, которая позволяет нам легко преобразовать любой JSON в табличный формат за считанные секунды.
И это… пд.json_normalize()
Итак, давайте посмотрим, как это работает с различными типами JSON.
Первый тип JSON, с которым мы можем работать, — это одноуровневые JSON с несколькими ключами и значениями. Мы определяем наши первые простые JSON-файлы следующим образом:
Код по автору
Итак, давайте смоделируем необходимость работы с этими JSON. Мы все знаем, что в их формате JSON особо нечего делать. Нам нужно преобразовать эти JSON в какой-то читаемый и изменяемый формат… что означает Pandas DataFrames!
1.1 Работа с простыми структурами JSON
Сначала нам нужно импортировать библиотеку pandas, а затем мы можем использовать команду pd.json_normalize() следующим образом:
import pandas as pd
pd.json_normalize(json_string)
Применяя эту команду к JSON с одной записью, мы получаем самую простую таблицу. Однако, когда наши данные немного более сложны и представляют собой список JSON, мы все равно можем использовать ту же команду без каких-либо дополнительных сложностей, и выходные данные будут соответствовать таблице с несколькими записями.

Изображение по автору
Легко… правда?
Следующий естественный вопрос — что происходит, когда некоторые значения отсутствуют.
1.2 Работа с нулевыми значениями
Представьте, что некоторые значения не сообщаются, например, отсутствует запись о доходах для Дэвида. При преобразовании нашего JSON в простой кадр данных pandas соответствующее значение будет отображаться как NaN.
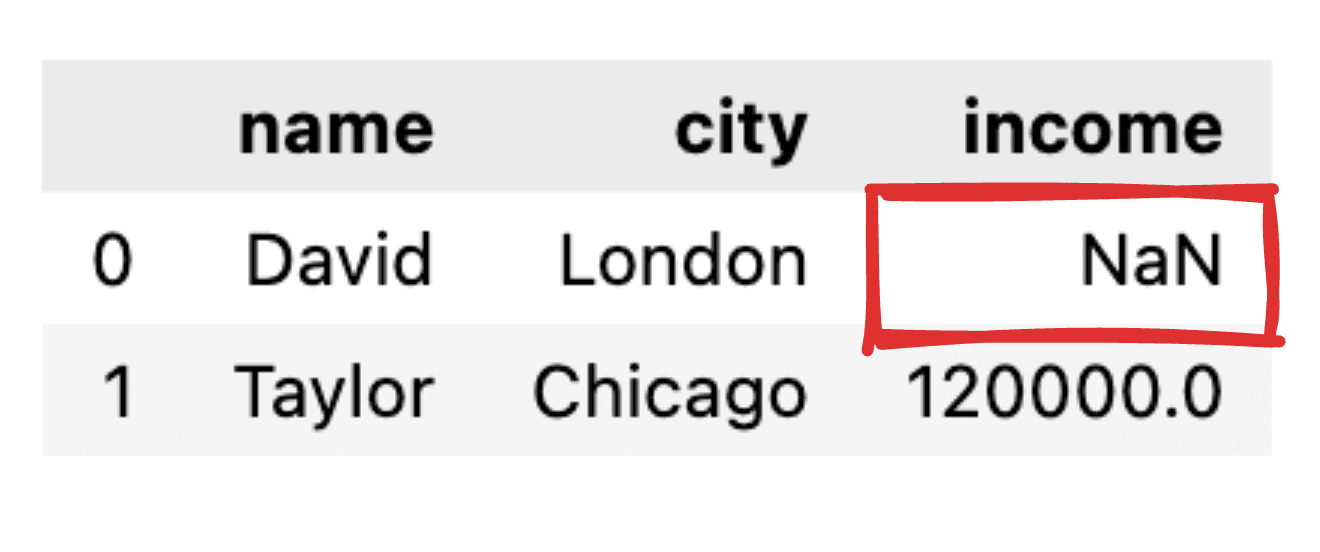
Изображение по автору
А что, если я хочу получить только некоторые поля?
1.3 Выбор только интересующих столбцов
Если мы просто хотим преобразовать некоторые конкретные поля в табличный DataFrame pandas, команда json_normalize() не позволяет нам выбирать, какие поля трансформировать.
Поэтому следует выполнить небольшую предварительную обработку JSON, в ходе которой мы фильтруем только интересующие столбцы.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Итак, давайте перейдем к более сложной структуре JSON.
Имея дело с многоуровневыми JSON, мы сталкиваемся с вложенными JSON на разных уровнях. Процедура такая же, как и раньше, но в этом случае мы можем выбрать, сколько уровней мы хотим преобразовать. По умолчанию команда всегда разворачивает все уровни и генерирует новые столбцы, содержащие объединенные имена всех вложенных уровней.
Итак, если мы нормализуем следующие файлы JSON.
Код по автору
Мы получим следующую таблицу с тремя столбцами под полевыми навыками:
- навыки.python
- навыки.SQL
- навыки.GCP
и 4 столбца под ролями полей
- роли.менеджер проекта
- Роли, дата-инженер
- роли: специалист по данным
- аналитик ролей.данных

Изображение по автору
Однако представьте, что мы просто хотим преобразовать наш верхний уровень. Мы можем сделать это, специально определив для параметра max_level значение 0 (max_level, который мы хотим расширить).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Ожидающие значения будут храниться в файлах JSON внутри нашего DataFrame pandas.
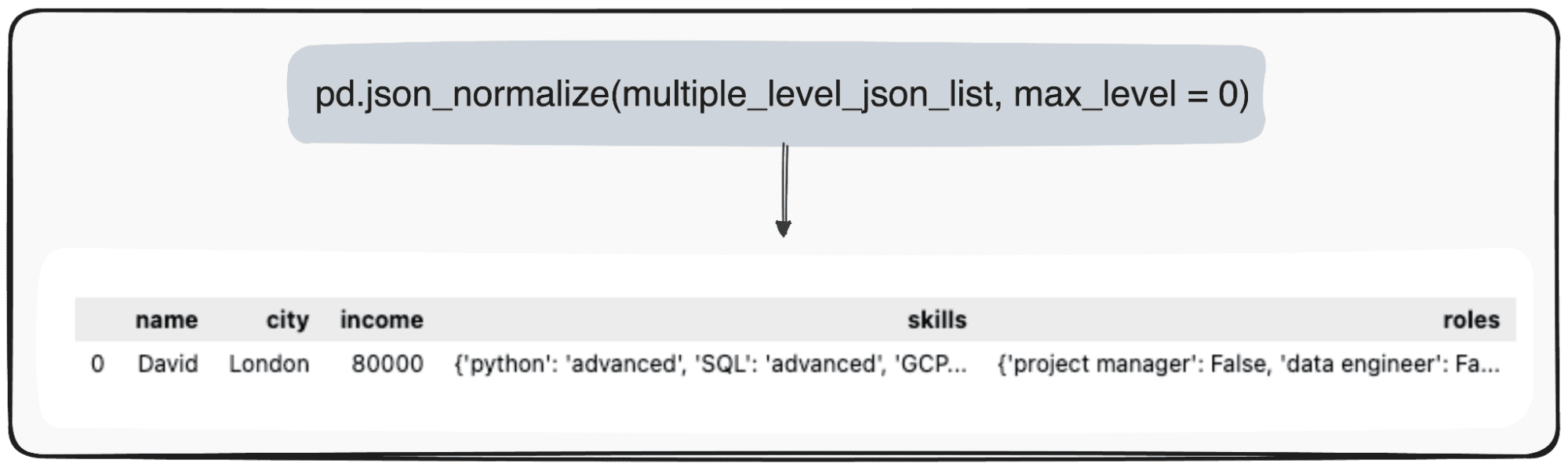
Изображение по автору
Последний случай, который мы можем обнаружить, — это вложенный список в поле JSON. Итак, мы сначала определяем наши JSON для использования.
Код по автору
Мы можем эффективно управлять этими данными, используя Pandas в Python. Функция pd.json_normalize() особенно полезна в этом контексте. Он может преобразовать данные JSON, включая вложенный список, в структурированный формат, подходящий для анализа. Когда эта функция применяется к нашим данным JSON, она создает нормализованную таблицу, которая включает вложенный список как часть своих полей.
Более того, Pandas предлагает возможность дальнейшего совершенствования этого процесса. Используя параметр Record_path в pd.json_normalize(), мы можем указать функции нормализовать вложенный список.
В результате этого действия создается специальная таблица исключительно для содержимого списка. По умолчанию этот процесс разворачивает только элементы внутри списка. Однако, чтобы обогатить эту таблицу дополнительным контекстом, например сохранить связанный идентификатор для каждой записи, мы можем использовать метапараметр.

Изображение по автору
Таким образом, преобразование данных JSON в файлы CSV с использованием библиотеки Pandas Python является простым и эффективным.
JSON по-прежнему остается наиболее распространенным форматом в современном хранении и обмене данными, особенно в базах данных NoSQL и API-интерфейсах REST. Однако при работе с данными в необработанном формате возникают некоторые важные аналитические проблемы.
Основная роль pd.json_normalize() в Pandas проявляется как отличный способ обработки таких форматов и преобразования наших данных в DataFrame pandas.
Я надеюсь, что это руководство было полезным, и в следующий раз, когда вы будете иметь дело с JSON, вы сможете сделать это более эффективно.
Вы можете проверить соответствующий блокнот Jupyter в после репозитория GitHub.
Хосеп Феррер инженер-аналитик из Барселоны. Он получил диплом инженера-физика и в настоящее время работает в области науки о данных, применяемой к человеческой мобильности. Он по совместительству создает контент, специализирующийся на науке о данных и технологиях. Вы можете связаться с ним по LinkedIn, Twitter or Medium.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :является
- :нет
- :куда
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- О нас
- Действие
- дополнительный
- продвинутый
- Все
- позволять
- позволяет
- уже
- всегда
- an
- анализ
- аналитик
- аналитический
- аналитика
- и
- любой
- API
- появиться
- прикладной
- Применение
- МЫ
- массив
- Искусство
- AS
- связанный
- Барселона
- основной
- BE
- до
- Немного
- изоферменты печени
- но
- by
- CAN
- возможности
- случаев
- проблемы
- проверка
- Выберите
- Город
- Колонки
- Общий
- комплекс
- осложнения
- обращайтесь
- содержание
- содержание
- контекст
- конвертировать
- преобразование
- соответствовать
- соответствующий
- создатель
- В настоящее время
- данным
- аналитик данных
- инженер данных
- наука о данных
- ученый данных
- хранение данных
- базы данных
- Давид
- занимавшийся
- преданный
- По умолчанию
- определять
- определяющий
- восхитительный
- ДИКТ
- различный
- направлять
- do
- приносит
- каждый
- легко
- легко
- Эффективный
- фактически
- элементы
- возникает
- столкновение
- инженер
- Проект и
- обогащать
- по существу
- обмена
- обмена
- исключительно
- Расширьте
- опыт
- объясняя
- Больше
- знакомый
- несколько
- поле
- Поля
- Файлы
- фильтр
- Найдите
- First
- внимание
- после
- следующим образом
- Что касается
- форма
- формат
- дружественный
- от
- функция
- фундаментальный
- далее
- GCP
- порождать
- получить
- GitHub
- Go
- большой
- инструкция
- обрабатывать
- Управляемость
- происходит
- Есть
- имеющий
- he
- его
- надежды
- Как
- Однако
- HTTPS
- человек
- i
- БОЛЬНОЙ
- ID
- if
- картина
- Импортировать
- важную
- in
- углубленный
- включают
- В том числе
- доход
- включает в себя
- сообщил
- пример
- интерес
- в
- мобильной
- IT
- ЕГО
- JavaScript
- JSON
- Jupyter Notebook
- всего
- КДнаггетс
- Основные
- ключи
- Знать
- Фамилия
- изучение
- уровень
- уровни
- Библиотека
- такое как
- Список
- мало
- ll
- любят
- машина
- обучение с помощью машины
- магия
- поддержанный
- Создание
- управлять
- менеджер
- многих
- означает
- Мета
- отсутствующий
- мобильность
- Модерн
- MongoDB
- БОЛЕЕ
- самых
- двигаться
- много
- с разными
- имя
- натуральный
- Необходимость
- вложенные
- Новые
- следующий
- нет
- особенно
- ноутбук
- объект
- получать
- of
- Предложения
- .
- on
- ONE
- только
- or
- наши
- себя
- выходной
- панд
- параметр
- часть
- особенно
- в ожидании
- ИДЕАЛЬНОЕ
- выполнены
- Физика
- основной
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Популярное
- разрабатывает
- вероятно
- процедуры
- процесс
- производит
- Проект
- Питон
- вопрос
- вполне
- Сырье
- RE
- Reading
- готовый
- запись
- учет
- совершенствовать
- Реагируйте
- ОТДЫХ
- Итоги
- удерживающий
- правую
- Роли
- s
- то же
- Наука
- Наука и технологии
- Ученый
- секунды
- посмотреть
- выбор
- должен
- просто
- имитировать
- одинарной
- навыки
- небольшой
- So
- некоторые
- удалось
- конкретный
- конкретно
- SQL
- По-прежнему
- диск
- магазин
- Структура
- структурированный
- такие
- подходящее
- РЕЗЮМЕ
- T
- ТАБЛИЦЫ
- Технологии
- terms
- который
- Ассоциация
- мир
- их
- Их
- тогда
- Эти
- этой
- те
- время
- в
- вместе
- топ
- Transform
- трансформация
- превращение
- напишите
- Типы
- под
- us
- использование
- полезный
- через
- Использующий
- ценностное
- Наши ценности
- хотеть
- законопроект
- Путь..
- we
- Что
- когда
- будь то
- который
- в то время как
- будете
- в
- Работа
- работает
- работает
- Мир
- бы
- являетесь
- зефирнет