В современной бизнес-среде, основанной на данных, организации сталкиваются с проблемой эффективной подготовки и преобразования больших объемов данных для целей аналитики и науки о данных. Предприятиям необходимо создавать хранилища и озера данных на основе оперативных данных. Это обусловлено необходимостью централизации и интеграции данных, поступающих из разрозненных источников.
В то же время оперативные данные часто поступают из приложений, поддерживаемых устаревшими хранилищами данных. Модернизация приложений требует микросервисной архитектуры, которая, в свою очередь, требует консолидации данных из нескольких источников для создания оперативного хранилища данных. Без модернизации устаревшие приложения могут повлечь за собой увеличение затрат на обслуживание. Модернизация приложений предполагает замену базового ядра базы данных на современную базу данных на основе документов, такую как MongoDB.
Эти две задачи (создание озер или хранилищ данных и модернизация приложений) включают перемещение данных, которое использует процесс извлечения, преобразования и загрузки (ETL). Задание ETL — это ключевая функция для хорошо структурированного процесса, обеспечивающего успех.
Клей AWS — это бессерверная служба интеграции данных, которая упрощает обнаружение, подготовку, перемещение и интеграцию данных из нескольких источников для аналитики, машинного обучения (ML) и разработки приложений. Атлас MongoDB — это интегрированный набор облачных баз данных и сервисов данных, который сочетает в себе транзакционную обработку, поиск по релевантности, аналитику в реальном времени и синхронизацию данных между мобильными устройствами и облаком в элегантной интегрированной архитектуре.
Используя AWS Glue с MongoDB Atlas, организации могут оптимизировать процессы ETL. Благодаря полностью управляемому, масштабируемому и безопасному решению для баз данных MongoDB Atlas обеспечивает гибкую и надежную среду для хранения и управления операционными данными. Вместе AWS Glue ETL и MongoDB Atlas представляют собой мощное решение для организаций, стремящихся оптимизировать создание озер и хранилищ данных, а также модернизировать свои приложения, чтобы повысить эффективность бизнеса, сократить расходы, а также стимулировать рост и успех.
В этом посте мы покажем, как перенести данные из Простой сервис хранения Amazon (Amazon S3) выполняет сегментацию в MongoDB Atlas с помощью AWS Glue ETL и способы извлечения данных из MongoDB Atlas в озеро данных на базе Amazon S3.
Обзор решения
В этой статье мы рассмотрим следующие варианты использования:
- Извлечение данных из MongoDB – MongoDB – популярная база данных, используемая тысячами клиентов для хранения данных приложений в большом масштабе. Корпоративные клиенты могут централизовать и интегрировать данные, поступающие из нескольких хранилищ данных, путем создания озер и хранилищ данных. Этот процесс включает в себя извлечение данных из хранилищ операционных данных. Когда данные находятся в одном месте, клиенты могут быстро использовать их для нужд бизнес-аналитики или машинного обучения.
- Загрузка данных в MongoDB – MongoDB также служит базой данных без SQL для хранения данных приложений и создания хранилищ операционных данных. Модернизация приложений часто предполагает миграцию оперативного хранилища в MongoDB. Клиентам потребуется извлекать существующие данные из реляционных баз данных или из плоских файлов. Мобильные и веб-приложения часто требуют, чтобы инженеры данных создавали конвейеры данных для создания единого представления данных в Atlas, одновременно получая данные из нескольких разрозненных источников. Во время этой миграции им нужно будет объединить разные базы данных для создания документов. Для этой сложной операции соединения потребуется значительная единовременная вычислительная мощность. Разработчикам также необходимо будет быстро создать это для переноса данных.
В таких случаях пригодится AWS Glue благодаря модели оплаты по мере использования и ее способности выполнять сложные преобразования в огромных наборах данных. Разработчики могут использовать AWS Glue Studio для эффективного создания таких конвейеров данных.
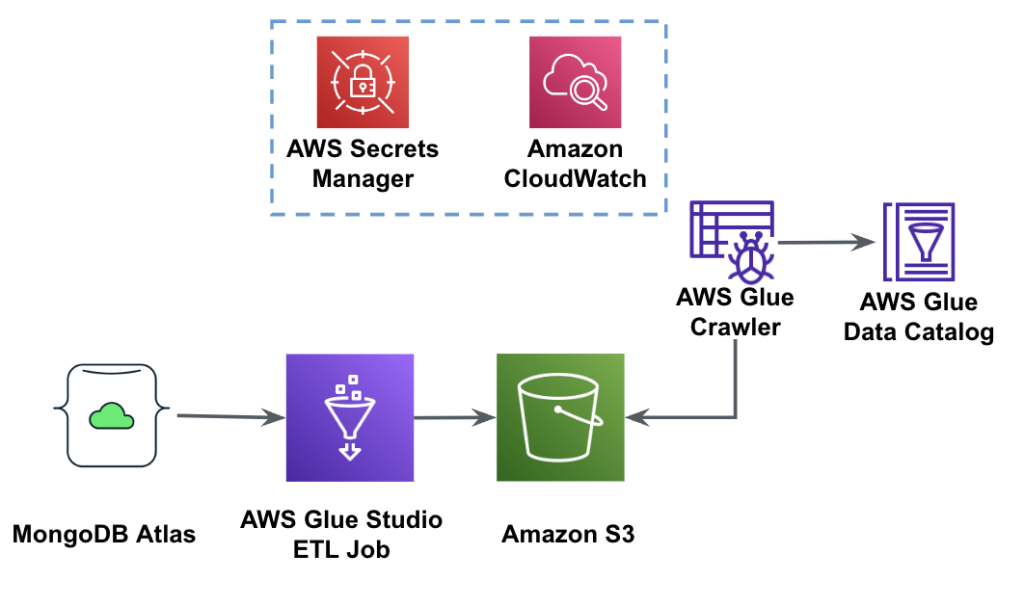
На следующей диаграмме показан рабочий процесс извлечения данных из MongoDB Atlas в корзину S3 с помощью AWS Glue Studio.
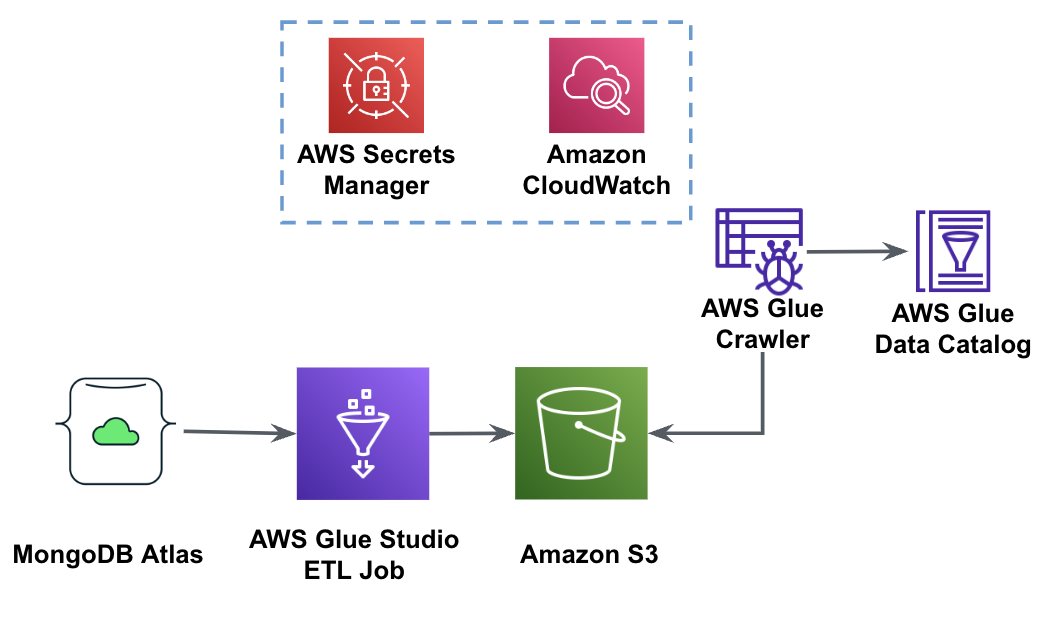
Для реализации этой архитектуры вам понадобится кластер MongoDB Atlas, корзина S3 и Управление идентификацией и доступом AWS (IAM) роль для AWS Glue. Чтобы настроить эти ресурсы, выполните необходимые шаги в следующих разделах. Репо GitHub.
На следующем рисунке показан рабочий процесс загрузки данных из корзины S3 в MongoDB Atlas с использованием AWS Glue.
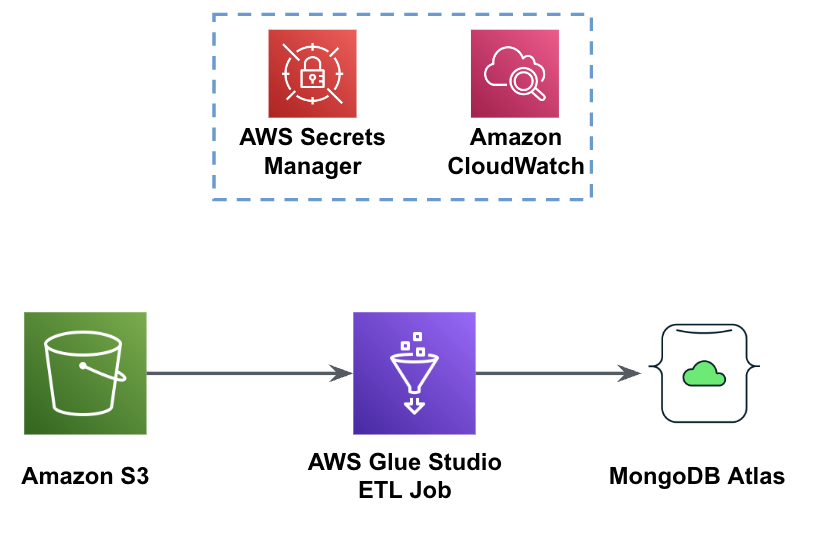
Здесь необходимы те же предварительные условия: корзина S3, роль IAM и кластер MongoDB Atlas.
Загрузка данных из Amazon S3 в MongoDB Atlas с помощью AWS Glue
Следующие шаги описывают, как загрузить данные из корзины S3 в MongoDB Atlas с помощью задания AWS Glue. Процесс извлечения из MongoDB Atlas в Amazon S3 очень похож, за исключением используемого скрипта. Назовем различия между этими двумя процессами.
- Создать бесплатный кластер в Атласе MongoDB.
- Загрузить пример файла JSON в корзину S3.
- Создайте новое задание AWS Glue Studio с помощью Редактор скриптов Spark опцию.

- В зависимости от того, хотите ли вы загрузить или извлечь данные из кластера MongoDB Atlas, введите загрузить скрипт or извлечь скрипт в редакторе сценариев AWS Glue Studio.
На следующем снимке экрана показан фрагмент кода для загрузки данных в кластер MongoDB Atlas.

Код использует Менеджер секретов AWS чтобы получить имя кластера MongoDB Atlas, имя пользователя и пароль. Затем он создает DynamicFrame для корзины S3 и имени файла, передаваемого сценарию в качестве параметров. Код извлекает имена базы данных и коллекций из конфигурации параметров задания. Наконец, код записывает DynamicFrame в кластер MongoDB Atlas, используя полученные параметры.
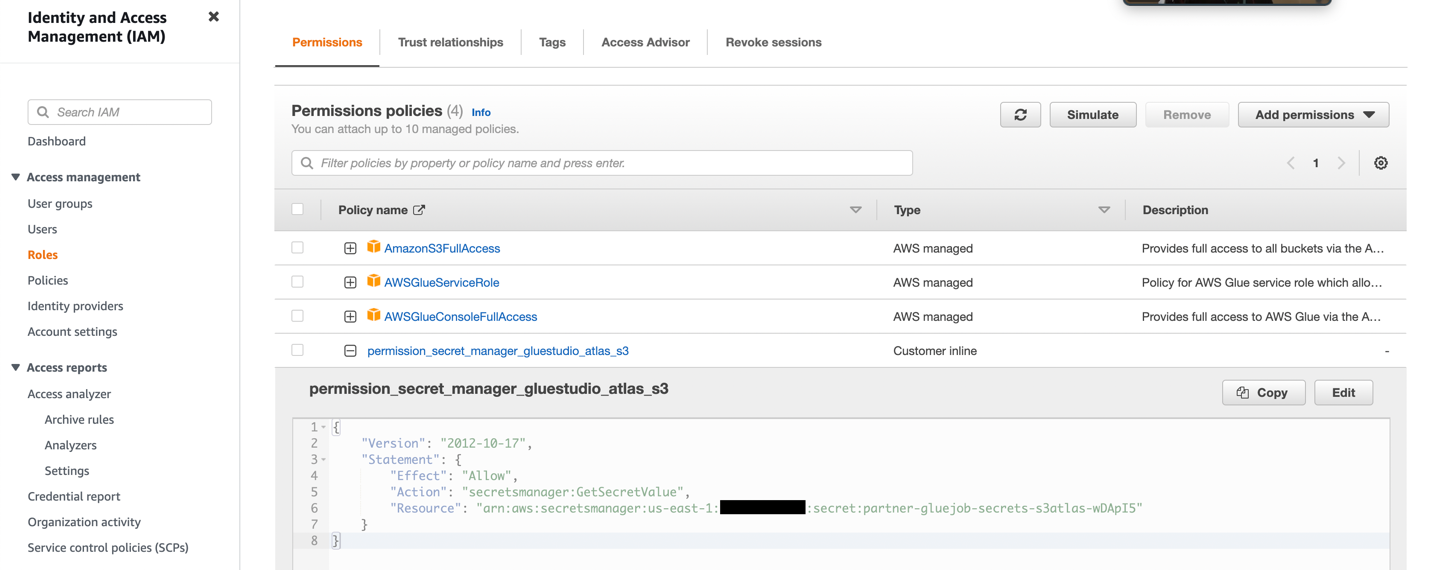
- Создайте роль IAM с разрешениями, как показано на следующем снимке экрана.
Подробнее см. Настройте роль IAM для вашего задания ETL..
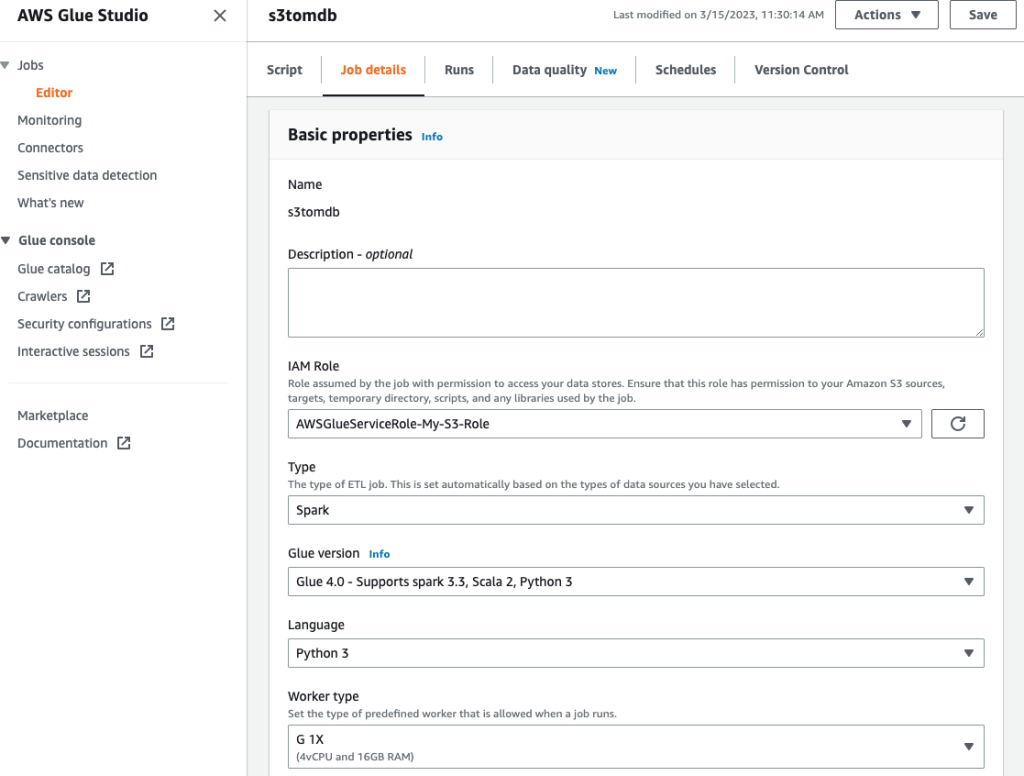
- Дайте заданию имя и укажите роль IAM, созданную на предыдущем шаге. Детали работы меню.
- Остальные параметры вы можете оставить по умолчанию, как показано на следующих скриншотах.
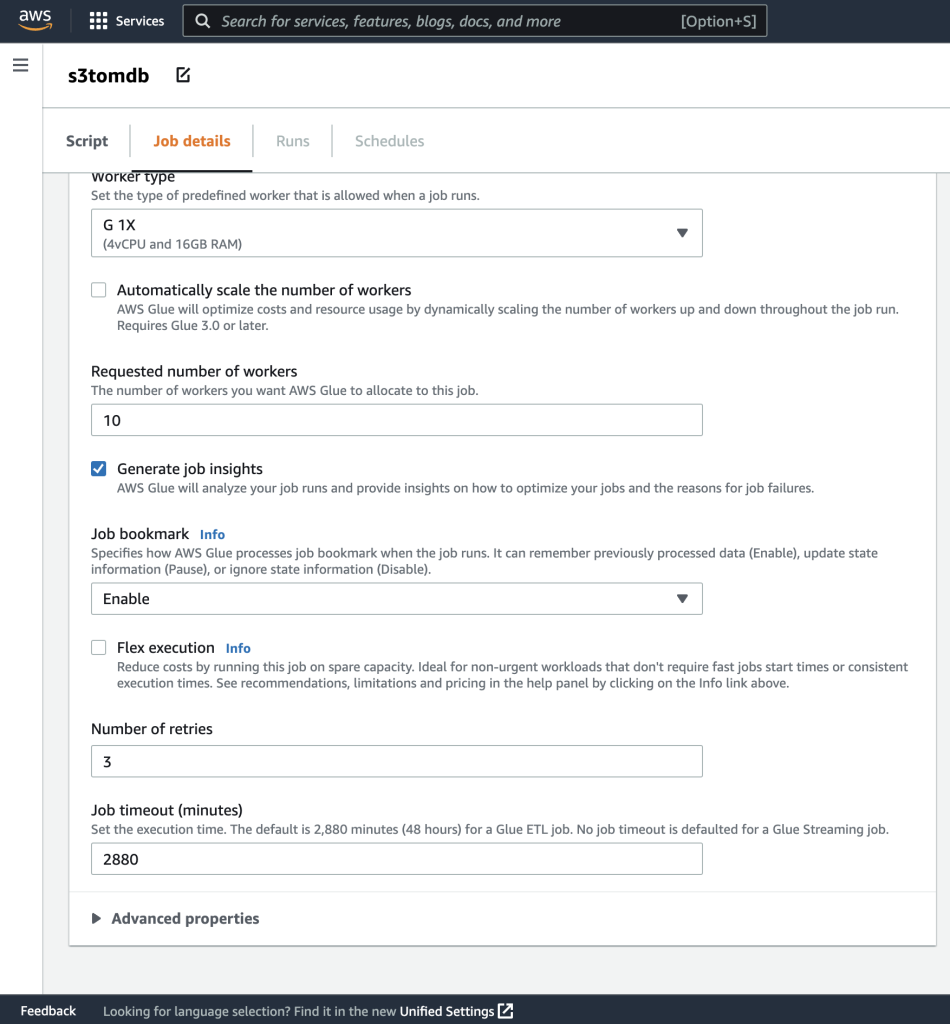
- Затем определите параметры задания, которые использует сценарий, и укажите значения по умолчанию.
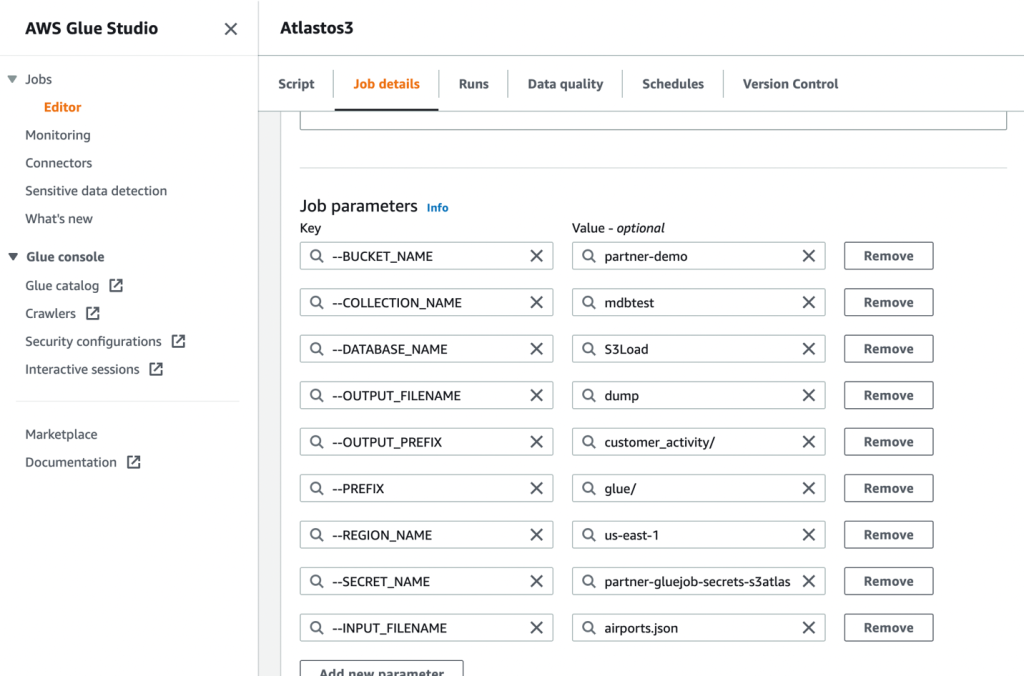
- Сохраните задание и запустите его.
- Чтобы подтвердить успешный запуск, просмотрите содержимое коллекции базы данных MongoDB Atlas при загрузке данных или корзины S3, если вы выполняли извлечение.



На следующем снимке экрана показаны результаты успешной загрузки данных из корзины Amazon S3 в кластер MongoDB Atlas. Данные теперь доступны для запросов в пользовательском интерфейсе MongoDB Atlas.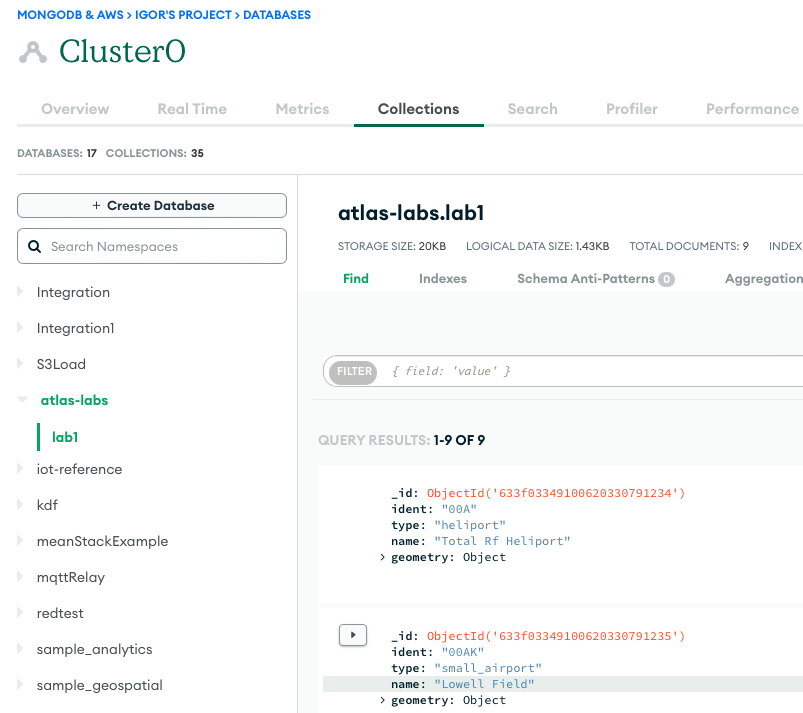
- Чтобы устранить неполадки при запуске, просмотрите Amazon CloudWatch журналы, используя ссылку на задание Run меню.
На следующем снимке экрана показано, что задание выполнено успешно, с дополнительными сведениями, такими как ссылки на журналы CloudWatch.

Заключение
В этом посте мы описали, как извлекать и загружать данные в MongoDB Atlas с помощью AWS Glue.
С помощью ETL-заданий AWS Glue мы теперь можем переносить данные из MongoDB Atlas в источники, совместимые с AWS Glue, и наоборот. Вы также можете расширить решение для создания аналитики с помощью сервисов AWS AI и ML.
Чтобы узнать больше, обратитесь к Репозиторий GitHub пошаговые инструкции и пример кода. Вы можете приобрести Атлас MongoDB на торговой площадке AWS.
Об авторах

Игорь Алексеев является старшим архитектором партнерских решений в AWS в области данных и аналитики. В своей роли Игорь работает со стратегическими партнерами, помогая им создавать сложные архитектуры, оптимизированные для AWS. До прихода в AWS в качестве архитектора данных/решений он реализовал множество проектов в области больших данных, в том числе несколько озер данных в экосистеме Hadoop. В качестве инженера по обработке данных он занимался применением ИИ/МО для обнаружения мошенничества и автоматизации делопроизводства.
 Бабу Сринивасан является старшим архитектором партнерских решений в MongoDB. В своей текущей роли он работает с AWS над созданием технических интеграций и эталонных архитектур для решений AWS и MongoDB. Он имеет более чем двадцатилетний опыт работы с базами данных и облачными технологиями. Он увлечен предоставлением технических решений клиентам, работающим с несколькими глобальными системными интеграторами (GSI) в разных регионах.
Бабу Сринивасан является старшим архитектором партнерских решений в MongoDB. В своей текущей роли он работает с AWS над созданием технических интеграций и эталонных архитектур для решений AWS и MongoDB. Он имеет более чем двадцатилетний опыт работы с базами данных и облачными технологиями. Он увлечен предоставлением технических решений клиентам, работающим с несколькими глобальными системными интеграторами (GSI) в разных регионах.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :имеет
- :является
- 100
- 11
- a
- способность
- О нас
- доступ
- через
- дополнительный
- AI
- AI / ML
- Также
- Amazon
- суммы
- an
- аналитика
- и
- Применение
- Разработка приложения
- Приложения
- Применение
- Программы
- архитектура
- МЫ
- AS
- At
- Атлант
- автоматизация
- доступен
- AWS
- Клей AWS
- Торговая площадка AWS
- со спинкой
- основанный
- не являетесь
- между
- большой
- Big Data
- строить
- Строительство
- бизнес
- бизнес-аналитика
- эффективность бизнеса
- бизнес
- by
- призывают
- CAN
- случаев
- вызов
- изменения
- облако
- Кластер
- код
- лыжных шлемов
- комбинаты
- выходит
- приход
- комплекс
- Вычисление
- Конфигурация
- подтвердить
- консолидация
- строить
- содержание
- продолжающийся
- Расходы
- Создайте
- создали
- создает
- создание
- Текущий
- Клиенты
- данным
- инженер данных
- Интеграция данных
- Озеро данных
- наука о данных
- хранилища данных
- управляемых данными
- База данных
- базы данных
- Наборы данных
- десятилетия
- По умолчанию
- демонстрировать
- описывать
- описано
- подробнее
- обнаружение
- застройщиков
- Развитие
- Различия
- различный
- обнаружить
- безрассудство
- Документация
- домен
- управлять
- управляемый
- в течение
- экосистема
- редактор
- эффективно
- Двигатель
- инженер
- Инженеры
- Enter
- Предприятие
- корпоративные клиенты
- Окружающая среда
- Эфир (ETH)
- исключение
- существующий
- опыт
- Больше
- продлить
- извлечение
- добыча
- Face
- фигура
- Файл
- Файлы
- в заключение
- плоский
- гибкого
- после
- Что касается
- мошенничество
- обнаружение мошенничества
- Бесплатно
- от
- полностью
- функциональность
- географии
- Глобальный
- Рост
- Hadoop
- удобный
- имеющий
- he
- помощь
- здесь
- его
- Как
- How To
- HTML
- HTTP
- HTTPS
- огромный
- IAM
- Личность
- if
- осуществлять
- в XNUMX году
- улучшать
- in
- В том числе
- повышение
- вход
- инструкции
- интегрировать
- интегрированный
- интеграции.
- интеграций
- Интеллекта
- в
- включать в себя
- вовлеченный
- IT
- ЕГО
- работа
- Джобс
- присоединиться
- присоединение
- JSON
- Основные
- озеро
- большой
- УЧИТЬСЯ
- изучение
- Оставлять
- Наследие
- такое как
- LINK
- связи
- загрузка
- погрузка
- искать
- машина
- обучение с помощью машины
- техническое обслуживание
- ДЕЛАЕТ
- управляемого
- управления
- многих
- рынка
- Май..
- мигрировать
- миграция
- ML
- Мобильный телефон
- модель
- Модерн
- модернизация
- модернизировать
- MongoDB
- БОЛЕЕ
- двигаться
- движение
- с разными
- имя
- имена
- Необходимость
- необходимый
- потребности
- Новые
- сейчас
- наблюдать
- of
- Офис
- .
- on
- ONE
- операция
- оперативный
- Оптимизировать
- Опция
- or
- заказ
- организации
- внешний
- параметры
- партнер
- партнеры
- Прошло
- страстный
- Пароль
- производительность
- выполнения
- Разрешения
- Часть
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Популярное
- После
- мощностью
- мощный
- Подготовить
- подготовка
- предпосылки
- предыдущий
- Предварительный
- процесс
- Процессы
- обработка
- проектов
- приводит
- обеспечение
- целей
- Запросы
- быстро
- реального времени
- уменьшить
- складская
- требовать
- требуется
- Полезные ресурсы
- ОТДЫХ
- Итоги
- обзоре
- Роли
- Run
- то же
- масштабируемые
- Шкала
- Наука
- скриншоты
- Поиск
- безопасный
- старший
- Serverless
- служит
- обслуживание
- Услуги
- несколько
- показанный
- Шоу
- значительный
- аналогичный
- просто
- одинарной
- Решение
- Решения
- Источники
- Шаг
- Шаги
- диск
- магазин
- магазины
- простой
- Стратегический
- стратегические партнеры
- упорядочить
- студия
- быть успешными
- успех
- успешный
- Успешно
- такие
- suite
- поставка
- синхронизация
- система
- задачи
- Технический
- технологии
- чем
- который
- Ассоциация
- их
- Их
- тогда
- Эти
- они
- этой
- тысячи
- время
- в
- Сегодняшних
- вместе
- транзакционный
- перевод
- Transform
- преобразований
- превращение
- ОЧЕРЕДЬ
- два
- ui
- лежащий в основе
- использование
- используемый
- Информация о пользователе
- через
- Наши ценности
- очень
- Вид
- хотеть
- законопроект
- we
- Web
- были
- когда
- будь то
- который
- в то время как
- будете
- без
- рабочий
- работает
- бы
- являетесь
- ВАШЕ
- зефирнет