Поиск похожих столбцов в озеро данных имеет важные приложения для очистки и аннотирования данных, сопоставления схем, обнаружения данных и аналитики из нескольких источников данных. Неспособность точно находить и анализировать данные из разрозненных источников представляет собой потенциальную угрозу эффективности для всех, от специалистов по данным, медицинских исследователей, ученых до финансовых и государственных аналитиков.
Обычные решения включают поиск по лексическому ключевому слову или сопоставление регулярных выражений, которые подвержены проблемам с качеством данных, таким как отсутствие имен столбцов или различные соглашения об именах столбцов в различных наборах данных (например, zip_code, zcode, postalcode).
В этом посте мы демонстрируем решение для поиска похожих столбцов на основе имени столбца, содержимого столбца или того и другого. Решение использует приближенные алгоритмы ближайших соседей доступна в Сервис Amazon OpenSearch для поиска семантически похожих столбцов. Чтобы облегчить поиск, мы создаем представления признаков (эмбеддинги) для отдельных столбцов в озере данных, используя предварительно обученные модели Transformer из библиотека преобразователей предложений in Создатель мудреца Амазонки. Наконец, чтобы взаимодействовать с нашим решением и визуализировать результаты, мы создаем интерактивный стримлит веб-приложение, работающее на АМС Фаргейт.
Мы включаем руководство по коду для вас, чтобы развернуть ресурсы для запуска решения на демонстрационных данных или ваших собственных данных.
Обзор решения
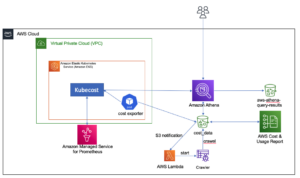
На следующей диаграмме архитектуры показан двухэтапный рабочий процесс поиска семантически похожих столбцов. Первый этап проходит Шаговые функции AWS рабочий процесс, который создает вложения из табличных столбцов и строит поисковый индекс службы OpenSearch. На втором этапе, или этапе онлайн-вывода, приложение Streamlit запускается через Fargate. Веб-приложение собирает входные поисковые запросы и извлекает из индекса службы OpenSearch примерно k столбцов, наиболее похожих на запрос.

Рисунок 1. Архитектура решения
Автоматизированный рабочий процесс состоит из следующих шагов:
- Пользователь загружает наборы табличных данных в Простой сервис хранения Amazon (Amazon S3), который вызывает AWS Lambda функция, которая инициирует рабочий процесс Step Functions.
- Рабочий процесс начинается с Клей AWS задание, которое преобразует файлы CSV в Паркет Apache формат данных.
- Задание SageMaker Processing создает вложения для каждого столбца с использованием предварительно обученных моделей или пользовательских моделей встраивания столбцов. Задание SageMaker Processing сохраняет вложения столбцов для каждой таблицы в Amazon S3.
- Функция Lambda создает домен и кластер службы OpenSearch для индексации внедрений столбцов, созданных на предыдущем шаге.
- Наконец, с Fargate развертывается интерактивное веб-приложение Streamlit. Веб-приложение предоставляет пользователю интерфейс для ввода запросов для поиска похожих столбцов в домене службы OpenSearch.
Вы можете скачать учебник по коду с GitHub чтобы попробовать это решение на демонстрационных данных или на ваших собственных данных. Инструкции по развертыванию необходимых ресурсов для этого руководства доступны на Github.
Предпосылки
Для реализации этого решения необходимо следующее:
- An Аккаунт AWS.
- Базовое знакомство с сервисами AWS, такими как Комплект для разработки облачных сервисов AWS (AWS CDK), Lambda, OpenSearch Service и SageMaker Processing.
- Табличный набор данных для создания поискового индекса. Вы можете принести свои собственные табличные данные или скачать примеры наборов данных на GitHub.
Создайте поисковый индекс
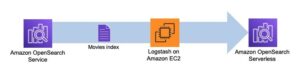
На первом этапе создается столбец индекса поисковой системы. На следующем рисунке показан рабочий процесс Step Functions, который запускает этот этап.

Рисунок 2 – Рабочий процесс пошаговых функций – несколько моделей внедрения
Datasets
В этом посте мы создадим поисковый индекс, включающий более 400 столбцов из более чем 25 наборов табличных данных. Наборы данных происходят из следующих общедоступных источников:
Полный список таблиц, включенных в указатель, см. в руководстве по коду на GitHub.
Вы можете принести свой собственный набор табличных данных, чтобы дополнить образцы данных или создать свой собственный поисковый индекс. Мы включили две функции Lambda, которые инициируют рабочий процесс Step Functions для построения поискового индекса для отдельных CSV-файлов или пакета CSV-файлов соответственно.
Преобразование CSV в паркет
Необработанные файлы CSV преобразуются в формат данных Parquet с помощью AWS Glue. Parquet – это формат файла с ориентацией на столбцы, предпочтительный для аналитики больших данных, который обеспечивает эффективное сжатие и кодирование. В наших экспериментах формат данных Parquet позволил значительно уменьшить размер хранилища по сравнению с необработанными файлами CSV. Мы также использовали Parquet в качестве общего формата данных для преобразования других форматов данных (например, JSON и NDJSON), поскольку он поддерживает расширенные вложенные структуры данных.
Создание вложений табличных столбцов
Чтобы извлечь вложения для отдельных столбцов таблицы в примерах наборов табличных данных в этом посте, мы используем следующие предварительно обученные модели из sentence-transformers библиотека. Дополнительные модели см. Предварительно обученные модели.
Задание обработки SageMaker выполняется create_embeddings.py(код) для одной модели. Для извлечения вложений из нескольких моделей рабочий процесс запускает параллельные задания обработки SageMaker, как показано в рабочем процессе Step Functions. Мы используем модель для создания двух наборов вложений:
- имя_столбца_эмбеддинги – Вложения имен столбцов (заголовки)
- columns_content_embeddings – Среднее вложение всех строк в столбец
Дополнительные сведения о процессе внедрения столбцов см. в руководстве по коду на GitHub.
Альтернативой этапу обработки SageMaker является создание пакетного преобразования SageMaker для встраивания столбцов в большие наборы данных. Для этого потребуется развернуть модель на конечной точке SageMaker. Для получения дополнительной информации см. Использовать пакетное преобразование.
Встраивание индекса с помощью OpenSearch Service
На последнем этапе этого этапа лямбда-функция добавляет вложения столбцов в сервис OpenSearch, приближенный к k-Nearest-Neighbor (kNN) поисковый индекс. Каждой модели присваивается свой поисковый индекс. Дополнительные сведения о приблизительных параметрах поискового индекса kNN см. к-НН.
Онлайн-вывод и семантический поиск с помощью веб-приложения
На втором этапе рабочего процесса выполняется стримлит веб-приложение, в котором вы можете вводить данные и искать семантически похожие столбцы, проиндексированные в службе OpenSearch. Прикладной уровень использует Балансировщик нагрузки приложений, Фаргейт и Лямбда. Инфраструктура приложений автоматически развертывается как часть решения.
Приложение позволяет вводить данные и искать семантически похожие имена столбцов, содержимое столбцов или и то, и другое. Кроме того, вы можете выбрать модель встраивания и количество ближайших соседей для возврата из поиска. Приложение получает входные данные, встраивает их в указанную модель и использует поиск kNN в службе OpenSearch для поиска вложений индексированных столбцов и поиска столбцов, наиболее похожих на заданный вход. Отображаемые результаты поиска включают имена таблиц, имена столбцов и оценки сходства для идентифицированных столбцов, а также расположение данных в Amazon S3 для дальнейшего изучения.
На следующем рисунке показан пример веб-приложения. В этом примере мы искали в нашем озере данных столбцы со схожими Column Names (тип полезной нагрузки), Чтобы district (полезная нагрузка). Приложение, используемое all-MiniLM-L6-v2 как встраивание модели и вернулся 10 (k) ближайших соседей из нашего индекса OpenSearch Service.
Приложение вернулось transit_district, city, boroughи location как четыре наиболее похожих столбца на основе данных, проиндексированных в OpenSearch Service. Этот пример демонстрирует способность подхода поиска идентифицировать семантически похожие столбцы в наборах данных.

Рисунок 3: Пользовательский интерфейс веб-приложения
Убирать
Чтобы удалить ресурсы, созданные AWS CDK в этом руководстве, выполните следующую команду:
cdk destroy --allЗаключение
В этом посте мы представили сквозной рабочий процесс для создания семантической поисковой системы для табличных столбцов.
Начните сегодня с ваших собственных данных с помощью нашего руководства по коду, доступного на GitHub. Если вам нужна помощь в ускорении использования машинного обучения в ваших продуктах и процессах, обратитесь в Лаборатория решений для машинного обучения Amazon.
Об авторах
![]() Качи Одоемене является прикладным ученым в AWS AI. Он создает решения AI/ML для решения бизнес-задач клиентов AWS.
Качи Одоемене является прикладным ученым в AWS AI. Он создает решения AI/ML для решения бизнес-задач клиентов AWS.
![]() Тейлор МакНалли является архитектором глубокого обучения в лаборатории решений для машинного обучения Amazon. Он помогает клиентам из различных отраслей создавать решения с использованием AI/ML на AWS. Он любит хорошую чашку кофе, прогулки на свежем воздухе и время со своей семьей и энергичной собакой.
Тейлор МакНалли является архитектором глубокого обучения в лаборатории решений для машинного обучения Amazon. Он помогает клиентам из различных отраслей создавать решения с использованием AI/ML на AWS. Он любит хорошую чашку кофе, прогулки на свежем воздухе и время со своей семьей и энергичной собакой.
![]() Остин Уэлч работает специалистом по данным в лаборатории решений Amazon ML. Он разрабатывает пользовательские модели глубокого обучения, чтобы помочь клиентам AWS из государственного сектора ускорить внедрение ИИ и облачных технологий. В свободное время любит читать, путешествовать и заниматься джиу-джитсу.
Остин Уэлч работает специалистом по данным в лаборатории решений Amazon ML. Он разрабатывает пользовательские модели глубокого обучения, чтобы помочь клиентам AWS из государственного сектора ускорить внедрение ИИ и облачных технологий. В свободное время любит читать, путешествовать и заниматься джиу-джитсу.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- способность
- О нас
- отсутствующий
- ускорять
- ускоряющий
- точно
- через
- дополнительный
- Дополнительно
- Добавляет
- Принятие
- продвинутый
- AI
- AI / ML
- Все
- позволяет
- альтернатива
- Amazon
- Амазонское машинное обучение
- Лаборатория решений Amazon ML
- Аналитики
- аналитика
- анализировать
- и
- апаш
- Применение
- Приложения
- прикладной
- подхода
- архитектура
- назначенный
- Автоматизированный
- автоматически
- доступен
- в среднем
- AWS
- Клей AWS
- основанный
- , так как:
- большой
- Big Data
- приносить
- строить
- Строительство
- строит
- бизнес
- Уборка
- облако
- принятие облака
- Кластер
- код
- Кофе
- улавливается
- Column
- Колонки
- Общий
- сравненный
- обращайтесь
- содержание
- конвенции
- конвертировать
- переделанный
- Создайте
- создали
- создает
- чашка
- изготовленный на заказ
- Клиенты
- данным
- Анализ данных
- Озеро данных
- Качество данных
- ученый данных
- Наборы данных
- глубоко
- глубокое обучение
- демонстрировать
- демонстрирует
- развертывание
- развернуть
- развертывание
- уничтожить
- Развитие
- развивается
- различный
- открытие
- безрассудство
- Разное
- Собака
- домен
- скачать
- каждый
- затрат
- эффективный
- впритык
- Конечная точка
- Двигатель
- Эфир (ETH)
- все члены
- пример
- исследование
- извлечение
- содействовал
- фамильярность
- семья
- Особенности
- фигура
- Файл
- Файлы
- окончательный
- в заключение
- финансовый
- Найдите
- обнаружение
- Во-первых,
- после
- формат
- от
- полный
- функция
- Функции
- далее
- получить
- данный
- хорошо
- Правительство
- Заголовки
- помощь
- помогает
- Как
- How To
- HTML
- HTTPS
- идентифицированный
- определения
- осуществлять
- важную
- in
- неспособность
- включают
- включены
- индекс
- individual
- промышленности
- информация
- Инфраструктура
- инициировать
- Посвященные
- вход
- инструкции
- взаимодействовать
- интерактивный
- Интерфейс
- Запускает
- включать в себя
- вопросы
- IT
- работа
- Джобс
- JSON
- лаборатория
- озеро
- большой
- слой
- изучение
- Используя
- Библиотека
- Список
- загрузка
- места
- машина
- обучение с помощью машины
- согласование
- основным медицинским
- ML
- модель
- Модели
- БОЛЕЕ
- самых
- с разными
- имя
- имена
- именования
- Необходимость
- соседи
- номер
- предложенный
- онлайн
- Другое
- на открытом воздухе
- собственный
- Параллельные
- параметры
- часть
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пожалуйста
- После
- потенциал
- привилегированный
- представлены
- предыдущий
- проблемам
- доходы
- процесс
- Процессы
- обработка
- Произведенный
- Продукция
- обеспечивать
- приводит
- что такое варган?
- Сырье
- Reading
- получает
- регулярный
- представляет
- требовать
- обязательный
- исследователи
- Полезные ресурсы
- соответственно
- Итоги
- возвращают
- Run
- Бег
- sagemaker
- Ученый
- Ученые
- Поиск
- Поисковая система
- поиск
- Во-вторых
- сектор
- обслуживание
- Услуги
- Наборы
- показанный
- Шоу
- значительный
- аналогичный
- просто
- одинарной
- Размер
- Решение
- Решения
- РЕШАТЬ
- Источники
- указанный
- Этап
- и политические лидеры
- Шаг
- Шаги
- диск
- такие
- Поддержка
- восприимчивый
- ТАБЛИЦЫ
- Ассоциация
- их
- Через
- время
- в
- сегодня
- Transform
- трансформеры
- Путешествие
- учебник
- использование
- Информация о пользователе
- Пользовательский интерфейс
- различный
- Web
- веб приложение
- который
- рабочий
- бы
- ВАШЕ
- зефирнет