Мы живем в эпоху данных и аналитики в реальном времени, основанных на приложениях потоковой передачи данных с малой задержкой. Сегодня каждый ожидает персонализированного опыта в любом приложении, и организации постоянно внедряют инновации, чтобы повысить скорость бизнес-операций и принятия решений. Объем производимых срочных данных быстро растет, при этом в новых предприятиях и сценариях использования клиентами внедряются различные форматы данных. Поэтому для организаций крайне важно использовать масштабируемую и надежную инфраструктуру потоковой передачи данных с малой задержкой для предоставления бизнес-приложений в реальном времени и улучшения качества обслуживания клиентов.
Это первая публикация в серии блогов, в которой предлагаются общие архитектурные шаблоны построения инфраструктур потоковой передачи данных в реальном времени с использованием Kinesis Data Streams для широкого спектра вариантов использования. Его цель — предоставить основу для создания потоковых приложений с малой задержкой в облаке AWS с использованием Потоки данных Amazon Kinesis и Специализированные сервисы AWS для анализа данных.
В этом посте мы рассмотрим общие архитектурные шаблоны двух вариантов использования: анализ данных временных рядов и микросервисы, управляемые событиями. В следующем посте нашей серии мы рассмотрим архитектурные шаблоны построения потоковых конвейеров для информационных панелей BI в реальном времени, агента контакт-центра, данных бухгалтерской книги, персонализированных рекомендаций в реальном времени, аналитики журналов, данных IoT, сбора измененных данных и реальных данных. -временные маркетинговые данные. Все эти архитектурные шаблоны интегрированы с Amazon Kinesis Data Streams.
Потоковая передача в реальном времени с помощью Kinesis Data Streams
Amazon Kinesis Data Streams — это облачная бессерверная служба потоковой передачи данных, которая позволяет легко собирать, обрабатывать и хранить данные в реальном времени в любом масштабе. С помощью Kinesis Data Streams вы можете собирать и обрабатывать сотни гигабайт данных в секунду из сотен тысяч источников, что позволяет легко писать приложения, обрабатывающие информацию в режиме реального времени. Собранные данные доступны в течение миллисекунд, что позволяет использовать аналитику в реальном времени, например, панели мониторинга в реальном времени, обнаружение аномалий в реальном времени и динамическое ценообразование. По умолчанию данные в потоке данных Kinesis хранятся в течение 24 часов с возможностью увеличения срока хранения данных до 365 дней. Если клиенты хотят обрабатывать одни и те же данные в режиме реального времени с помощью нескольких приложений, они могут использовать функцию Enhanced Fan-Out (EFO). До появления этой функции каждое приложение, потребляющее данные из потока, разделяло выходные данные со скоростью 2 МБ/секунду/осколок. Настраивая потребителей потока на использование расширенного разветвления, каждый потребитель данных получает выделенный канал с пропускной способностью чтения 2 МБ/с на каждый сегмент, что еще больше снижает задержку при извлечении данных.
Для обеспечения высокой доступности и надежности Kinesis Data Streams обеспечивает высокую надежность за счет синхронной репликации потоковых данных в трех зонах доступности в регионе AWS и дает вам возможность хранить данные до 365 дней. В целях безопасности Kinesis Data Streams обеспечивает шифрование на стороне сервера, поэтому вы можете удовлетворить строгие требования к управлению данными, шифруя хранящиеся данные и конечные точки интерфейса Amazon Virtual Private Cloud (VPC), чтобы обеспечить конфиденциальность трафика между Amazon VPC и Kinesis Data Streams.
Kinesis Data Streams имеет встроенную интеграцию с другими сервисами AWS, такими как Клей AWS и Amazon EventBridge для создания приложений потоковой передачи в реальном времени на AWS. Дополнительные сведения см. в разделе «Интеграции Amazon Kinesis Data Streams».
Современная архитектура потоковой передачи данных с помощью Kinesis Data Streams
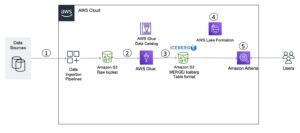
Современная архитектура потоковой передачи данных с помощью Kinesis Data Streams может быть спроектирована как стек из пяти логических уровней; каждый уровень состоит из нескольких специально созданных компонентов, отвечающих конкретным требованиям, как показано на следующей схеме:
Архитектура состоит из следующих ключевых компонентов:
- Потоковые источники – Ваш источник потоковых данных включает такие источники данных, как данные о посещениях, датчики, социальные сети, устройства Интернета вещей (IoT), файлы журналов, созданные с помощью ваших веб-приложений и мобильных приложений, а также мобильные устройства, которые генерируют полуструктурированные и неструктурированные данные в виде непрерывных потоков. на высокой скорости.
- Прием потока – Уровень приема потока отвечает за прием данных на уровень хранения потока. Он предоставляет возможность собирать данные из десятков тысяч источников данных и обрабатывать их в режиме реального времени. Вы можете использовать Кинезис SDK для приема потоковых данных через API, Библиотека продюсеров Kinesis для создания высокопроизводительных и долговечных потоковых продюсеров или Кинезис агент для сбора набора файлов и загрузки их в потоки данных Kinesis. Кроме того, вы можете использовать множество готовых интеграций, таких как Служба миграции баз данных AWS (AWS DMS), Amazon DynamoDBи Ядро Интернета вещей AWS для приема данных без использования кода. Вы также можете получать данные со сторонних платформ, таких как Apache Spark и Apache Kafka Connect.
- Хранение потока – Kinesis Data Streams предлагает два режима поддержки пропускной способности данных: по требованию и предоставленный. Режим по требованию, который теперь является выбором по умолчанию, может гибко масштабироваться для поглощения переменной пропускной способности, поэтому клиентам не нужно беспокоиться об управлении емкостью и платить за пропускную способность данных. В режиме «По требованию» емкость потока автоматически увеличивается вдвое по сравнению с историческим максимальным количеством принимаемых данных, чтобы обеспечить достаточную емкость для неожиданных пиков приема данных. Альтернативно, клиенты, которым нужен детальный контроль над потоковыми ресурсами, могут использовать режим Provisioned и активно увеличивать и уменьшать количество шардов в соответствии со своими требованиями к пропускной способности. Кроме того, Kinesis Data Streams по умолчанию может хранить потоковые данные до 2 часов, но может продлиться до 24 или 7 дней в зависимости от вариантов использования. Несколько приложений могут использовать один и тот же поток.
- Потоковая обработка – Уровень потоковой обработки отвечает за преобразование данных в потребляемое состояние посредством проверки, очистки, нормализации, преобразования и обогащения данных. Потоковые записи считываются в том порядке, в котором они создаются, что позволяет проводить аналитику в реальном времени, создавать управляемые событиями приложения или осуществлять потоковую передачу ETL (извлечение, преобразование и загрузка). Вы можете использовать Управляемый сервис Amazon для Apache Flink для сложной потоковой обработки данных, AWS Lambda для обработки потоковых данных без сохранения состояния и Клей AWS & Амазонка ЭМИ для вычислений почти в реальном времени. Вы также можете создавать индивидуальные потребительские приложения с помощью Потребительская библиотека Kinesis, который будет решать множество сложных задач, связанных с распределенными вычислениями.
- Назначения - Уровень назначения похож на специально созданный пункт назначения в зависимости от вашего варианта использования. Вы можете передавать данные непосредственно в Амазонка Redshift для хранилищ данных и Amazon EventBridge для создания приложений, управляемых событиями. Вы также можете использовать Пожарный шланг данных Amazon Kinesis для интеграции потоковой передачи, где вы можете облегчить обработку потоковой передачи с помощью AWS Lambda, а затем доставить обработанную потоковую передачу в такие места назначения, как Amazon S3 озеро данных, служба OpenSearch для оперативной аналитики, хранилище данных Redshift, базы данных No-SQL, такие как Amazon DynamoDB, и реляционные базы данных, такие как Амазон РДС для использования потоков реального времени в бизнес-приложениях. Местом назначения может быть приложение, управляемое событиями, для информационных панелей в реальном времени, автоматических решений на основе обработанных потоковых данных, изменения в реальном времени и многого другого.
Архитектура аналитики в реальном времени для временных рядов
Данные временных рядов — это последовательность точек данных, записанных в течение определенного интервала времени для измерения событий, которые изменяются с течением времени. Примерами являются цены на акции с течением времени, потоки посещений веб-страниц и журналы устройств с течением времени. Клиенты могут использовать данные временных рядов для отслеживания изменений с течением времени, чтобы они могли обнаруживать аномалии, выявлять закономерности и анализировать, как определенные переменные влияют с течением времени. Данные временных рядов обычно генерируются из нескольких источников в больших объемах, и их необходимо экономично собирать практически в реальном времени.
Обычно при обработке данных временных рядов клиенты хотят достичь трех основных целей:
- Получайте в режиме реального времени информацию о производительности системы и обнаруживайте аномалии.
- Понимайте поведение конечных пользователей, чтобы отслеживать тенденции и запрашивать/создавать визуализации на основе этих данных.
- Получите надежное решение для хранения данных, позволяющее принимать и хранить как архивные, так и часто используемые данные.
С помощью Kinesis Data Streams клиенты могут непрерывно собирать терабайты данных временных рядов из тысяч источников для очистки, обогащения, хранения, анализа и визуализации.
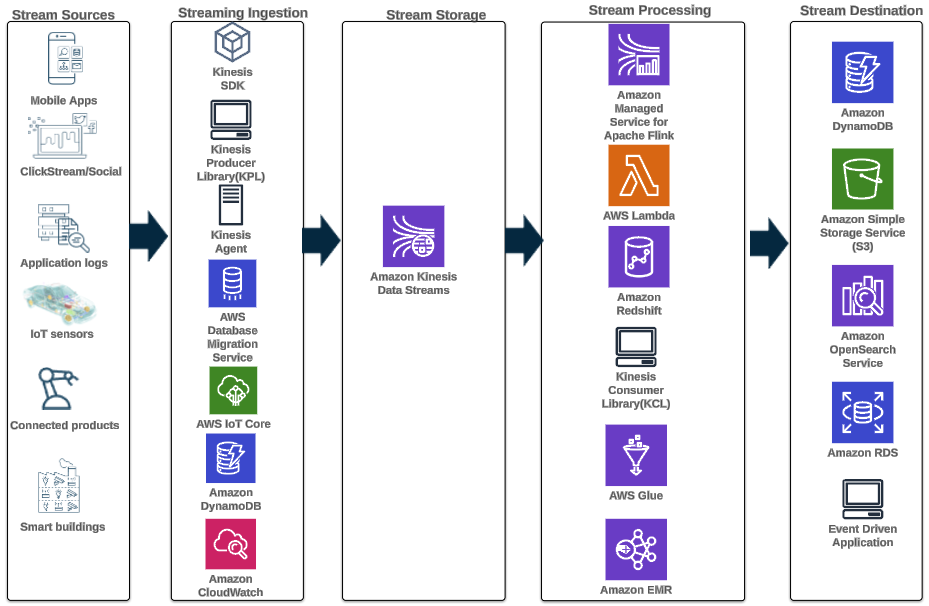
Следующий шаблон архитектуры иллюстрирует, как можно реализовать аналитику в реальном времени для данных временных рядов с помощью Kinesis Data Streams:
Этапы рабочего процесса следующие:
- Прием и хранение данных – Kinesis Data Streams может непрерывно захватывать и хранить терабайты данных из тысяч источников.
- Потоковая обработка – Приложение, созданное с помощью Управляемый сервис Amazon для Apache Flink может читать записи из потока данных, чтобы обнаруживать и устранять любые ошибки в данных временных рядов, а также дополнять данные конкретными метаданными для оптимизации оперативного анализа. Использование потока данных посередине дает преимущество одновременного использования данных временных рядов в других процессах и решениях. Затем с этими событиями вызывается лямбда-функция, которая может выполнять вычисления временных рядов в памяти.
- Направления – После очистки и обогащения обработанные данные временных рядов можно передать в потоковом режиме Amazon Таймстрим базу данных для создания информационных панелей и анализа в реальном времени или храниться в таких базах данных, как DynamoDB, для запросов конечных пользователей. Необработанные данные можно передать в Amazon S3 для архивирования.
- Визуализация и получение информации – Клиенты могут запрашивать, визуализировать и создавать оповещения, используя Управляемый сервис Amazon для Grafana. Grafana поддерживает источники данных, которые являются серверами хранения данных временных рядов. Чтобы получить доступ к вашим данным из Timestream, вам необходимо установить плагин Timestream для Grafana. Конечные пользователи могут запрашивать данные из таблицы DynamoDB с помощью Шлюз API Amazon выступая в качестве прокси.
Обратитесь к Обработка практически в реальном времени с помощью Amazon Kinesis, Amazon Timestream и Grafana демонстрация бессерверного потокового конвейера для обработки и хранения данных телеметрии устройств IoT в хранилище данных, оптимизированном для временных рядов, таком как Amazon Timestream.
Обогащение и воспроизведение данных в режиме реального времени для микросервисов, отвечающих за события.
Микросервисы — это архитектурный и организационный подход к разработке программного обеспечения, при котором программное обеспечение состоит из небольших независимых сервисов, которые взаимодействуют через четко определенные API. При создании микросервисов, управляемых событиями, клиенты хотят добиться 1. высокой масштабируемости для обработки объема входящих событий и 2. надежности обработки событий и поддержания функциональности системы в случае сбоев.
Клиенты используют шаблоны микросервисной архитектуры для ускорения инноваций и сокращения времени вывода на рынок новых функций, поскольку это упрощает масштабирование и ускоряет разработку приложений. Однако обогатить и воспроизвести данные при сетевом вызове другого микросервиса сложно, поскольку это может повлиять на надежность приложения и затруднить отладку и отслеживание ошибок. Для решения этой проблемы использование источников событий является эффективным шаблоном проектирования, который централизует исторические записи всех изменений состояния для обогащения и воспроизведения, а также отделяет рабочие нагрузки чтения от записи. Клиенты могут использовать Kinesis Data Streams в качестве централизованного хранилища событий для микросервисов, получающих события, поскольку KDS может 1/ обрабатывать гигабайты данных в секунду на каждый поток и передавать данные за миллисекунды, чтобы удовлетворить требованиям высокой масштабируемости и режима, близкого к реальному времени. задержку, 2/ интеграцию с Flink и S3 для обогащения и достижения данных, при этом полностью отделенную от микросервисов, и 3/ разрешающую повторную попытку и асинхронное чтение в более позднее время, поскольку KDS сохраняет запись данных в течение 24 часов по умолчанию и опционально. до 365 дней.
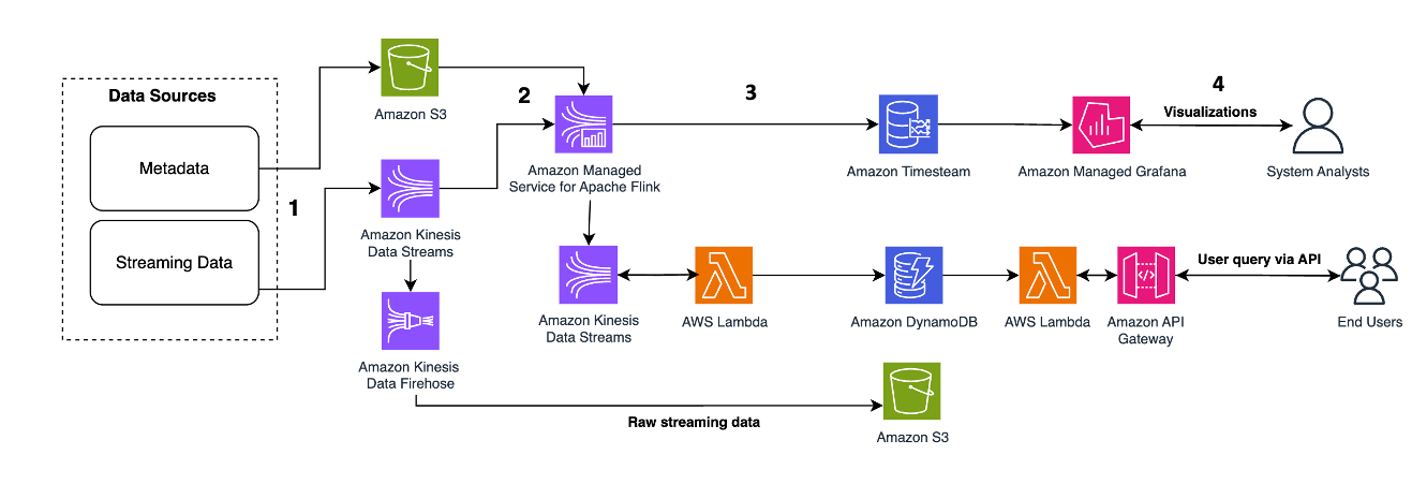
Следующий архитектурный шаблон является общей иллюстрацией того, как Kinesis Data Streams можно использовать для микросервисов источников событий:
Этапы рабочего процесса следующие:
- Прием и хранение данных – Вы можете агрегировать входные данные своих микросервисов в потоки данных Kinesis для хранения.
- Обработка потока – Функции с отслеживанием состояния Apache Flink упрощает создание распределенных приложений, управляемых событиями, с отслеживанием состояния. Он может получать события из входного потока данных Kinesis и направлять результирующий поток в выходной поток данных. Вы можете создать кластер функций с отслеживанием состояния с помощью Apache Flink на основе бизнес-логики вашего приложения.
- Снимок состояния в Amazon S3 – Вы можете сохранить снимок состояния в Amazon S3 для отслеживания.
- Выходные потоки – Выходные потоки можно использовать с помощью удаленных функций Lambda по протоколу HTTP/gRPC через шлюз API.
- Удаленные функции Lambda – Функции Lambda могут выступать в качестве микросервисов для различных приложений и бизнес-логики для обслуживания бизнес-приложений и мобильных приложений.
Чтобы узнать, как другие клиенты создавали свои микросервисы на основе событий с помощью Kinesis Data Streams, см. следующее:
Ключевые соображения и лучшие практики
Ниже приведены соображения и рекомендации, которые следует учитывать:
- Обнаружение данных должно стать вашим первым шагом в создании современных приложений потоковой передачи данных. Вы должны определить ценность бизнеса, а затем определить источники потоковых данных и пользователей для достижения желаемых бизнес-результатов.
- Выберите инструмент приема потоковых данных в зависимости от источника данных потоковой передачи. Например, вы можете использовать Кинезис SDK для приема потоковых данных через API, Библиотека продюсеров Kinesis для создания высокопроизводительных и долговечных потоковых продюсеров, Кинезис агент для сбора набора файлов и вставки их в потоки данных Kinesis, АМС DMS для сценариев использования потоковой передачи CDC и Ядро Интернета вещей AWS для приема данных устройств IoT в потоки данных Kinesis. Вы можете принимать потоковые данные непосредственно в Amazon Redshift для создания потоковых приложений с малой задержкой. Вы также можете использовать сторонние библиотеки, такие как Apache Spark и Apache Kafka, для приема потоковых данных в Kinesis Data Streams.
- Вам необходимо выбрать службы потоковой обработки данных, исходя из вашего конкретного варианта использования и бизнес-требований. Например, вы можете использовать Amazon Kinesis Managed Service для Apache Flink для расширенных сценариев использования потоковой передачи с несколькими пунктами назначения потоковой передачи и сложной обработкой потока с отслеживанием состояния или если вы хотите отслеживать бизнес-показатели в режиме реального времени (например, каждый час). Lambda хороша для обработки на основе событий и без сохранения состояния. Вы можете использовать Амазонка ЭМИ для потоковой обработки данных, чтобы использовать ваши любимые платформы больших данных с открытым исходным кодом. AWS Glue хорош для потоковой обработки данных практически в реальном времени в таких случаях, как потоковая передача ETL.
- Режим Kinesis Data Streams по требованию взимает плату в зависимости от использования и автоматически увеличивает емкость ресурсов, поэтому он хорош для резких рабочих нагрузок потоковой передачи и обслуживания без помощи рук. В выделенном режиме оплата взимается в зависимости от емкости и требует упреждающего управления емкостью, поэтому он хорош для предсказуемых рабочих нагрузок потоковой передачи.
- Вы можете использовать Общий калькулятор Kinesis для расчета количества осколков, необходимых для режима подготовки. Вам не нужно беспокоиться об осколках в режиме по требованию.
- Предоставляя разрешения, вы решаете, кто и какие разрешения получит для каких ресурсов Kinesis Data Streams. Вы разрешаете определенные действия, которые хотите разрешить на этих ресурсах. Поэтому следует предоставлять только те разрешения, которые необходимы для выполнения задачи. Вы также можете зашифровать хранящиеся данные с помощью ключа, управляемого клиентом KMS (CMK).
- Вы можете обновить срок хранения через консоль Kinesis Data Streams или с помощью Увеличение StreamRetentionPeriod и УменьшитьStreamRetentionPeriod операции на основе ваших конкретных случаев использования.
- Kinesis Data Streams поддерживает перешардинг. Рекомендуемый API для этой функции: Обновить шардкаунт, который позволяет вам изменять количество сегментов в потоке, чтобы адаптироваться к изменениям скорости потока данных через поток. API-интерфейсы перешардинга (Split и Merge) обычно используются для обработки «горячих» сегментов.
Заключение
В этом посте продемонстрированы различные архитектурные шаблоны для создания потоковых приложений с малой задержкой с помощью Kinesis Data Streams. Вы можете создавать свои собственные приложения обработки паром с малой задержкой с помощью Kinesis Data Streams, используя информацию в этом посте.
Подробные архитектурные шаблоны можно найти на следующих ресурсах:
Если вы хотите разработать видение и стратегию обработки данных, ознакомьтесь с AWS — все на основе данных (D2E) программа.
Об авторах
 Рагхаварао Содабатина — главный архитектор решений в AWS, специализирующийся на аналитике данных, искусственном интеллекте и машинном обучении и облачной безопасности. Он взаимодействует с клиентами для создания инновационных решений, которые решают бизнес-задачи клиентов и ускоряют внедрение сервисов AWS. В свободное время Рагхаварао любит проводить время со своей семьей, читать книги и смотреть фильмы.
Рагхаварао Содабатина — главный архитектор решений в AWS, специализирующийся на аналитике данных, искусственном интеллекте и машинном обучении и облачной безопасности. Он взаимодействует с клиентами для создания инновационных решений, которые решают бизнес-задачи клиентов и ускоряют внедрение сервисов AWS. В свободное время Рагхаварао любит проводить время со своей семьей, читать книги и смотреть фильмы.
 Ханг Цзо является старшим менеджером по продуктам в команде Amazon Kinesis Data Streams в Amazon Web Services. Он увлечен разработкой интуитивно понятных продуктов, которые решают сложные проблемы клиентов и позволяют клиентам достигать своих бизнес-целей.
Ханг Цзо является старшим менеджером по продуктам в команде Amazon Kinesis Data Streams в Amazon Web Services. Он увлечен разработкой интуитивно понятных продуктов, которые решают сложные проблемы клиентов и позволяют клиентам достигать своих бизнес-целей.
 Света Радхакришнан — архитектор решений AWS, специализирующийся на аналитике данных. Она разрабатывает решения, которые способствуют внедрению облачных технологий и помогают организациям принимать решения на основе данных в государственном секторе. Вне работы она любит танцевать, проводить время с друзьями и семьей, а также путешествовать.
Света Радхакришнан — архитектор решений AWS, специализирующийся на аналитике данных. Она разрабатывает решения, которые способствуют внедрению облачных технологий и помогают организациям принимать решения на основе данных в государственном секторе. Вне работы она любит танцевать, проводить время с друзьями и семьей, а также путешествовать.
 Бриттани Ли — архитектор решений в AWS. Она сосредоточена на оказании помощи корпоративным клиентам в их переходе на облачные технологии и их модернизации, а также интересуется сферой безопасности и аналитики. Вне работы она любит проводить время со своей собакой и играть в пиклбол.
Бриттани Ли — архитектор решений в AWS. Она сосредоточена на оказании помощи корпоративным клиентам в их переходе на облачные технологии и их модернизации, а также интересуется сферой безопасности и аналитики. Вне работы она любит проводить время со своей собакой и играть в пиклбол.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 100
- 24
- 7
- a
- способность
- О нас
- ускорять
- доступ
- Доступ
- Достигать
- достигнутый
- Достигает
- достижение
- через
- Действие (Act):
- действующий
- действия
- приспосабливать
- дополнение
- дополнительный
- Дополнительно
- адрес
- Принятие
- продвинутый
- плюс
- После
- возраст
- Агент
- совокупный
- AI / ML
- Цель
- оповещений
- Все
- позволять
- Позволяющий
- позволяет
- причислены
- Amazon
- Амазонка Кинезис
- Amazon Таймстрим
- Amazon Web Services
- an
- анализ
- аналитика
- анализировать
- и
- обнаружение аномалии
- Другой
- любой
- апаш
- Апач Кафка
- Apache Spark
- API
- API
- Применение
- Приложения
- подхода
- Программы
- архитектурный
- архитектура
- МЫ
- AS
- связанный
- At
- Автоматический
- автоматически
- свободных мест
- доступен
- AWS
- Клей AWS
- AWS Lambda
- основанный
- BE
- , так как:
- было
- поведение
- не являетесь
- ЛУЧШЕЕ
- лучшие практики
- Лучшая
- между
- большой
- Big Data
- Блог
- Книги
- изоферменты печени
- строить
- Строительство
- построенный
- бизнес
- Бизнес-приложения
- бизнес
- но
- by
- вычислять
- призывают
- CAN
- Пропускная способность
- захватить
- заботится
- случаев
- случаев
- CDC
- Центр
- централизованная
- определенный
- сложные
- изменение
- изменения
- расходы
- проверка
- выбор
- Выберите
- чистым
- Уборка
- облако
- принятие облака
- Cloud Security
- Кластер
- собирать
- Сбор
- Общий
- общаться
- полностью
- комплекс
- компоненты
- состоящие
- Вычисление
- вычисление
- обеспокоенный
- настройка
- соображения
- состоит
- Консоли
- постоянно
- потреблять
- потребленный
- потребитель
- Потребители
- обращайтесь
- контакт-центр
- (CIJ)
- непрерывно
- контроль
- Создайте
- создали
- критической
- клиент
- Клиенты
- подгонянный
- танцы
- щитки
- данным
- анализ данных
- Анализ данных
- обогащение данных
- Озеро данных
- управление данными
- точки данных
- обработка данных
- информационное хранилище
- управляемых данными
- База данных
- базы данных
- Дней
- решать
- решение
- Принятие решений
- решения
- разъединены
- преданный
- По умолчанию
- определять
- доставить
- убивают
- в зависимости
- Проект
- предназначенный
- желанный
- назначение
- направления
- подробный
- подробнее
- обнаруживать
- обнаружение
- развивать
- развивающийся
- Развитие
- устройство
- Устройства
- различный
- трудный
- непосредственно
- открытие
- распределенный
- распределенных вычислений
- do
- Собака
- Dont
- вниз
- управлять
- управляемый
- долговечность
- динамический
- каждый
- легче
- легко
- легко
- Эффективный
- обниматься
- включить
- шифрование
- конечные точки
- зацепляет
- расширение
- обогащать
- Предприятие
- корпоративные клиенты
- ошибки
- Эфир (ETH)
- События
- События
- Каждая
- все члены
- пример
- Примеры
- надеется
- опыт
- Впечатления
- Больше
- продлить
- извлечение
- Face
- сбои
- семья
- Фэшн
- быстрее
- Избранное
- Особенность
- Особенности
- поле
- Файлы
- Во-первых,
- 5
- поток
- Фокус
- внимание
- фокусировка
- после
- следующим образом
- Что касается
- Рамки
- каркасы
- часто
- друзья
- от
- функция
- функциональность
- Функции
- далее
- Gain
- шлюз
- порождать
- генерируется
- получающий
- GitHub
- дает
- Цели
- хорошо
- предоставлять
- предоставление
- обрабатывать
- Вешать
- he
- помощь
- помощь
- ее
- High
- высокая производительность
- его
- исторический
- ГОРЯЧИЙ
- час
- ЧАСЫ
- Как
- Однако
- HTML
- HTTP
- HTTPS
- Сотни
- определения
- if
- иллюстрирует
- Влияние
- in
- В других
- включает в себя
- Входящий
- Увеличение
- повышение
- независимые
- влияние
- информация
- Инфраструктура
- инфраструктура
- инновации
- Инновации
- инновационный
- вход
- размышления
- устанавливать
- интегрировать
- интегрированный
- интеграции.
- интеграций
- интерес
- Интерфейс
- Интернет
- Интернет вещей
- в
- выпустили
- интуитивный
- вызывается
- КАТО
- IoT-устройство
- IT
- ЕГО
- путешествие
- JPG
- Кафка
- Сохранить
- Основные
- Потоки данных Kinesis
- озеро
- Задержка
- новее
- слой
- слоев
- УЧИТЬСЯ
- Ledger
- библиотеки
- Библиотека
- легкий
- такое как
- жизнью
- загрузка
- журнал
- логика
- логический
- любит
- поддерживать
- техническое обслуживание
- сделать
- ДЕЛАЕТ
- Создание
- управляемого
- управление
- менеджер
- многих
- Маркетинг
- максимальный
- измерение
- Медиа
- Встречайте
- Память
- идти
- Метаданные
- Метрика
- microservices
- средняя
- миграция
- миллисекунды
- против
- Мобильный телефон
- Приложения для мобильных устройств
- мобильных устройств
- мобильные приложения-
- режим
- Модерн
- модернизация
- Режимы
- изменять
- монитор
- БОЛЕЕ
- Кино
- с разными
- должен
- родной
- Возле
- Необходимость
- необходимый
- потребности
- сеть
- Новые
- Новые функции
- сейчас
- номер
- of
- предлагают
- Предложения
- on
- On-Demand
- только
- открытый
- с открытым исходным кодом
- операция
- оперативный
- Операционный отдел
- Оптимизировать
- оптимизированный
- Опция
- or
- заказ
- организационной
- организации
- Другое
- наши
- внешний
- Результаты
- выходной
- внешнюю
- за
- собственный
- часть
- страстный
- шаблон
- паттеранами
- ОПЛАТИТЬ
- для
- выполнять
- производительность
- Разрешения
- Персонализированные
- труба
- трубопровод
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- плагин
- пунктов
- После
- практиками
- предсказуемый
- Цены
- цены
- первичный
- Основной
- Предварительный
- частная
- Проактивная
- Проблема
- проблемам
- процесс
- обрабатываемых
- Процессы
- обработка
- Произведенный
- производитель
- Производители
- Продукт
- Менеджер по продукции
- FitPartner™
- протокол
- обеспечивать
- приводит
- полномочие
- что такое варган?
- ассортимент
- быстро
- Обменный курс
- Сырье
- необработанные данные
- Читать
- Reading
- реальные
- реального времени
- данные в реальном времени
- Получать
- получает
- Рекомендация
- Управление по борьбе с наркотиками (DEA)
- запись
- записанный
- учет
- уменьшить
- относиться
- область
- надежность
- складская
- удаленные
- обязательный
- требование
- Требования
- требуется
- ресурс
- Полезные ресурсы
- ответственный
- ОТДЫХ
- в результате
- сохранять
- сохраняет
- сохранение
- обзоре
- дорога
- то же
- Масштабируемость
- масштабируемые
- Шкала
- Весы
- Во-вторых
- сектор
- безопасность
- старший
- датчик
- Последовательность
- Серии
- служить
- Serverless
- обслуживание
- Услуги
- набор
- общие
- она
- должен
- Showcasing
- упрощает
- небольшой
- Снимок
- So
- Соцсети
- социальные сети
- Software
- разработка программного обеспечения
- Решение
- Решения
- РЕШАТЬ
- Источник
- Источники
- Искриться
- конкретный
- скорость
- тратить
- Расходы
- шипы
- раскол
- стек
- Область
- Шаг
- Шаги
- акции
- диск
- магазин
- хранить
- Стратегия
- поток
- потоковый
- потоковый
- потоки
- строгий
- последующее
- такие
- достаточный
- поддержка
- Поддержка
- система
- ТАБЛИЦЫ
- взять
- Сложность задачи
- задачи
- команда
- десятки
- который
- Ассоциация
- информация
- Государство
- их
- Их
- тогда
- Там.
- следовательно
- Эти
- они
- вещи
- сторонние
- этой
- те
- тысячи
- три
- Через
- пропускная способность
- время
- Временные ряды
- чувствительный ко времени
- в
- сегодня
- инструментом
- прослеживать
- трек
- Отслеживание
- трафик
- Transform
- трансформация
- превращение
- Путешествие
- Тенденции
- два
- типично
- Неожиданный
- на
- Применение
- использование
- прецедент
- используемый
- Информация о пользователе
- через
- использовать
- Проверка
- ценностное
- переменная
- различный
- Скорость
- с помощью
- Виртуальный
- видение
- визуализация
- визуализации
- объем
- тома
- хотеть
- Склады
- Складирование
- наблюдение
- we
- Web
- веб-сервисы
- вполне определенный
- Что
- когда
- который
- в то время как
- КТО
- широкий
- Широкий диапазон
- будете
- в
- Работа
- рабочий
- беспокоиться
- записывать
- являетесь
- ВАШЕ
- зефирнет
- зоны