
Изображение из Bing Image Creator
Исследовательский анализ данных (EDA) — самая важная задача, которую необходимо выполнить в начале каждого проекта по науке о данных.
По сути, это включает в себя тщательное изучение и характеристику ваших данных, чтобы найти лежащие в их основе характеристика, возможный аномалии, и скрыто паттеранами и отношений.
Это понимание ваших данных — вот что в конечном итоге выполнить следующие шаги вашего конвейера машинного обучения, от предварительной обработки данных до построения модели и анализа результатов.
Процесс EDA принципиально включает в себя три основные задачи:
- Шаг 1: Обзор набора данных и описательная статистика
- Шаг 2: Оценка характеристик и визуализацияи
- Шаг 3: Оценка качества данных
Как вы уже догадались, каждая из этих задач может повлечь за собой довольно обширный объем анализов, которые легко заставят вас нарезайте, печатайте и рисуйте фреймы данных pandas как сумасшедший.
Если только вы не выберете правильный инструмент для работы.
В этой статье, мы погрузимся в каждый шаг эффективного процесса EDA, и обсудите, почему вы должны обратиться ydata-профилирование в свой универсальный магазин, чтобы освоить его.
к продемонстрировать лучшие практики и изучить идеи, мы будем использовать Набор данных о доходах переписи взрослого населения, свободно доступный на Kaggle или в репозитории UCI (лицензия: CC0: общественное достояние).
Когда мы впервые получаем в руки неизвестный набор данных, сразу же возникает автоматическая мысль: С чем я работаю?
Нам необходимо иметь глубокое понимание наших данных, чтобы эффективно обрабатывать их в будущих задачах машинного обучения.
Как правило, мы традиционно начинаем с характеристики данных относительно числа наблюдения, число и типы функций, в общем и целом недостающая ставка, и процент дублировать наблюдения.
С некоторыми манипуляциями с пандами и правильной шпаргалкой мы могли бы в конечном итоге распечатать приведенную выше информацию с помощью нескольких коротких фрагментов кода:
Обзор набора данных: набор данных переписи взрослого населения. Количество наблюдений, объектов, типов объектов, повторяющихся строк и отсутствующих значений. Фрагмент автора.
В общем, выходной формат не идеален… Если вы знакомы с pandas, вы также знаете стандарт образ действия запуска процесса EDA — df.describe():
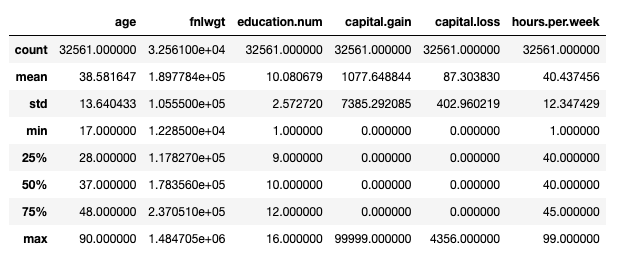
Набор данных для взрослых: основные статистические данные представлены df.describe (). Изображение автора.
Это, однако, рассматривает только числовые функции. Мы могли бы использовать df.describe(include='object') распечатать дополнительную информацию о категориальные особенности (количество, уникальность, режим, частота), но простая проверка существующих категорий потребовала бы чего-то более подробного:
Обзор набора данных: набор данных переписи взрослого населения. Печать существующих категорий и соответствующих частот для каждой категориальной функции в данных. Фрагмент автора.
Однако мы можем сделать это — и знаете что, все последующие задачи EDA! - в одной строке кода, С помощью ydata-профилирование:
Отчет о профилировании набора данных переписи взрослого населения с использованием ydata-profiling. Фрагмент автора.
Приведенный выше код создает полный отчет о профилировании данных., который мы можем использовать для дальнейшего продвижения нашего процесса EDA без необходимости писать дополнительный код!
Мы рассмотрим различные разделы отчета в следующих разделах. В том, что касается общие характеристики данных, вся информация, которую мы искали, включена в Обзор .:
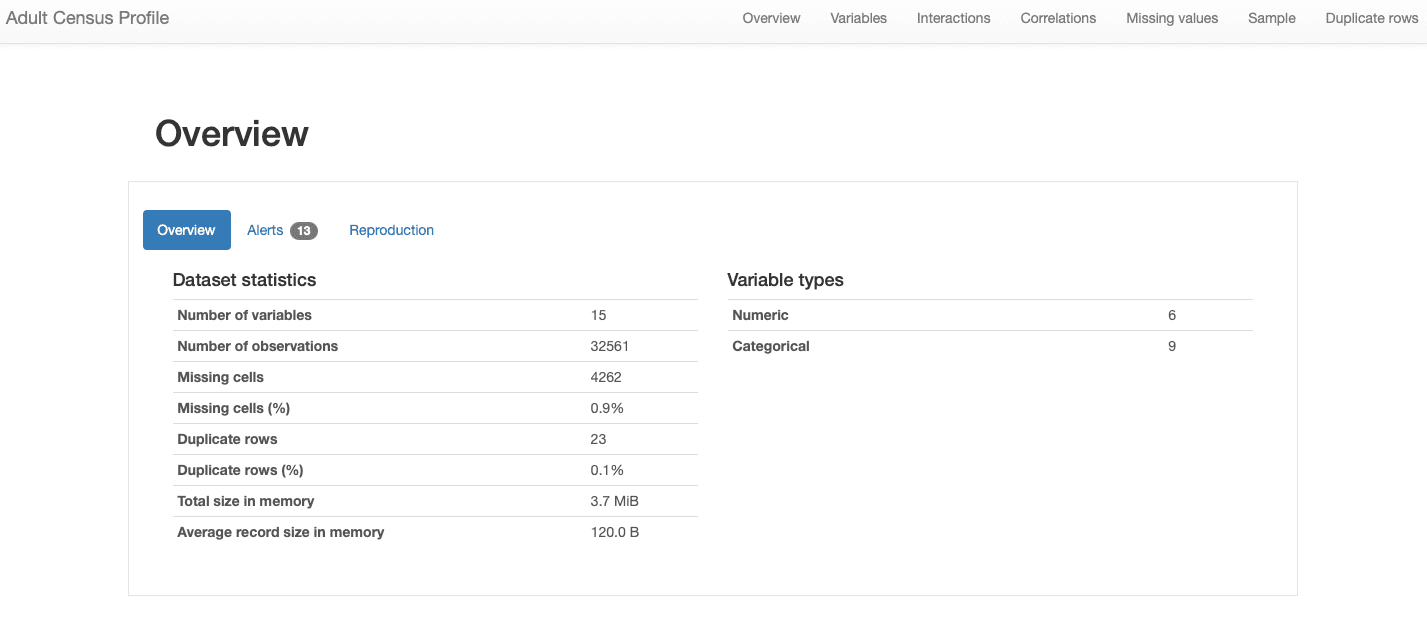
ydata-profiling: отчет о профилировании данных — обзор набора данных. Изображение автора.
Мы видим, что наш набор данных включает 15 признаков и 32561 наблюдение, 23 повторяющиеся записи и общий процент пропущенных записей 0.9%.
Кроме того, набор данных был правильно идентифицирован как табличный набор данных, и довольно неоднородный, представляющий как числовые и категориальные признаки. Для данные временного ряда, который зависит от времени и представляет различные типы паттернов, ydata-profiling будет включать прочая статистика и анализ в отчете.
Мы можем дополнительно осмотреть необработанные данные и существующие повторяющиеся записи чтобы получить общее представление об особенностях, прежде чем переходить к более сложному анализу:
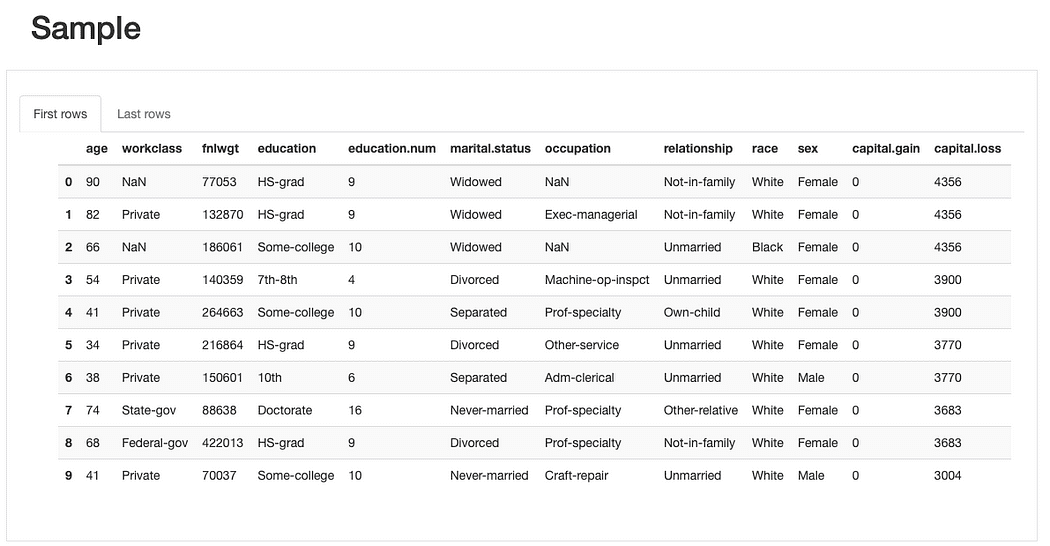
ydata-profiling: отчет о профилировании данных — пример предварительного просмотра. Изображение автора.
Из краткого превью образца выборки данных, мы сразу видим, что хотя набор данных имеет низкий процент отсутствующих данных в целом, некоторые функции могут быть затронуты этим больше, чем другие. Мы также можем определить довольно значительное количество категорий для некоторых функций и функций с нулевым значением (или, по крайней мере, со значительным количеством нулей).
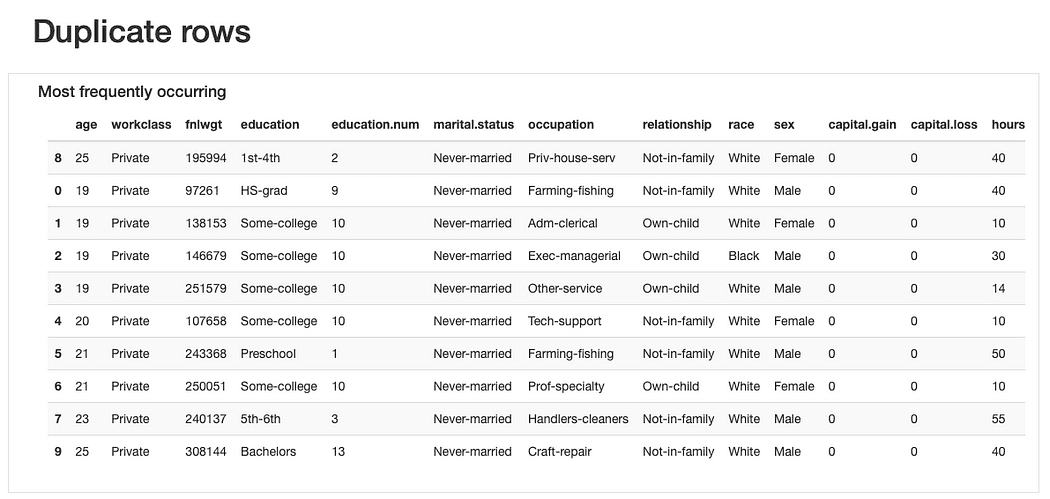
ydata-profiling: отчет о профилировании данных — предварительный просмотр повторяющихся строк. Изображение автора.
По поводу повторяющихся строк, было бы не странно обнаружить «повторяющиеся» наблюдения, учитывая, что большинство признаков представляют собой категории, в которые одновременно могут «подходить» несколько человек.
Тем не менее, возможно, «запах данных» может быть, эти наблюдения имеют одни и те же age ценности (что правдоподобно) и точно такие же fnlwgt в что, учитывая представленные значения, кажется труднее поверить. Поэтому потребуется дальнейший анализ, но мы должны скорее всего сбросите эти дубликаты позже.
В целом, обзор данных может быть простым анализом, но чрезвычайно впечатляющий, так как это поможет нам определить предстоящие задачи в нашем конвейере.
Взглянув на общие дескрипторы данных, нам нужно увеличить характеристики нашего набора данных, чтобы получить некоторое представление об их индивидуальных свойствах — Одномерный анализ — а также их взаимодействия и отношения — Многомерный анализ.
Обе задачи сильно зависят от исследование адекватных статистических данных и визуализаций, который должен быть с учетом типа функции под рукой (например, числовой, категориальный), и поведение мы хотим анализировать (например, взаимодействия, корреляции).
Давайте рассмотрим лучшие практики для каждой задачи.
Одномерный анализ
Анализ индивидуальных характеристик каждой функции имеет решающее значение, поскольку это поможет нам принять решение об их актуальность для анализа и тип подготовки данных они могут потребоваться для достижения оптимальных результатов.
Например, мы можем найти значения, которые сильно выходят за пределы допустимого диапазона и могут относиться к несоответствия or выбросы. Нам может понадобиться стандартизировать численный данным или выполнить однократное кодирование категориального функции, в зависимости от количества существующих категорий. Или нам, возможно, придется выполнить дополнительную подготовку данных для обработки числовых функций, которые смещены или перекошены, если алгоритм машинного обучения, который мы собираемся использовать, ожидает определенного распределения (обычно гауссовского).
Поэтому лучшие практики требуют тщательного изучения отдельных свойств, таких как описательная статистика и распределение данных.
Это подчеркнет необходимость последующих задач по удалению выбросов, стандартизации, кодированию меток, вменению данных, дополнению данных и другим типам предварительной обработки.
Давайте исследовать race и capital.gain более подробно. Что мы можем сразу заметить?
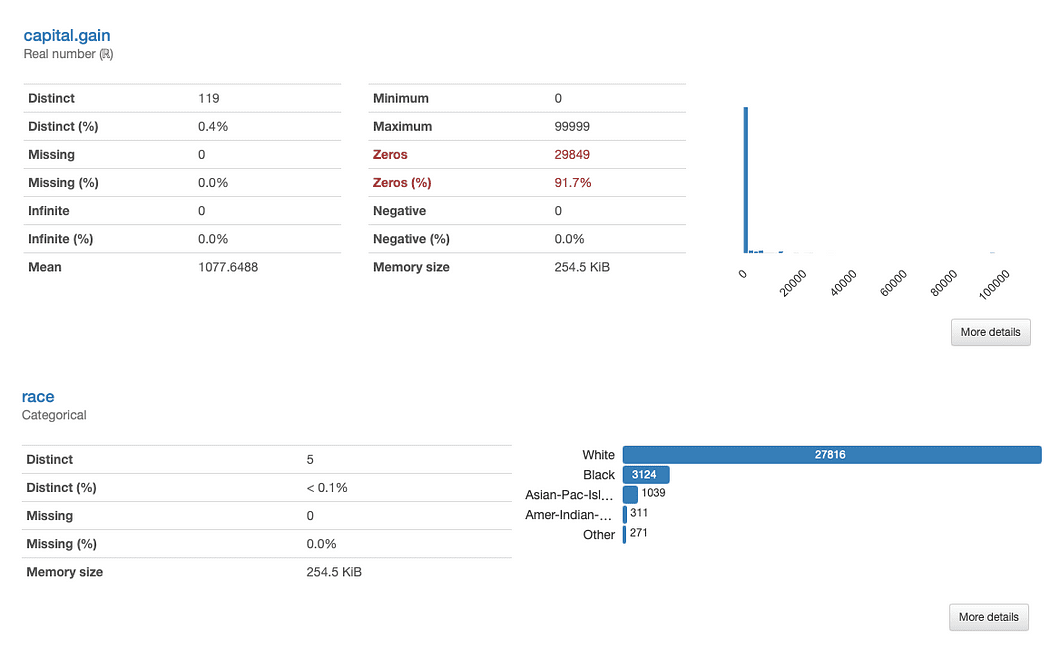
ydata-profiling: Отчет о профилировании (гонка и капитал. прирост). Изображение автора.
Оценка прирост капитала это просто:
Учитывая распределение данных, мы можем задаться вопросом, добавляет ли функция какую-либо ценность нашему анализу, поскольку 91.7% значений равны «0».
Анализируя раса немного сложнее:
Существует явное недопредставление рас, кроме White. Это наводит на мысль о двух основных проблемах:
- Одной из них является общая тенденция алгоритмов машинного обучения игнорировать менее представленные концепции, известная как проблема небольшие дизъюнкции, что приводит к снижению успеваемости;
- Другой является производным от этой проблемы: поскольку мы имеем дело с деликатной функцией, эта «тенденция упускать из виду» может иметь последствия, непосредственно связанные с смещение и справедливость вопросы. Что-то, что мы определенно не хотим внедрять в наши модели.
Принимая это во внимание, возможно, нам следует рассмотрите возможность увеличения данных на недопредставленных категориях, а также с учетом метрики справедливости для оценки модели, чтобы проверить любые расхождения в производительности, которые относятся к race значения.
Мы подробнее остановимся на других характеристиках данных, которые необходимо учитывать, когда будем обсуждать передовые методы обеспечения качества данных (шаг 3). Этот пример просто показывает, сколько информации мы можем получить, просто оценив каждую отдельную функцию. свойства.
Наконец, обратите внимание, как упоминалось ранее, разные типы объектов требуют разных статистических данных и стратегий визуализации:
- Числовые функции чаще всего содержат информацию о среднем значении, стандартном отклонении, асимметрии, эксцессе и других количественных статистических данных и лучше всего представляются с помощью графиков гистограмм;
- Категориальные особенности обычно описываются с использованием таблиц мод, медианы и частоты и представляются с помощью гистограмм для анализа категорий.
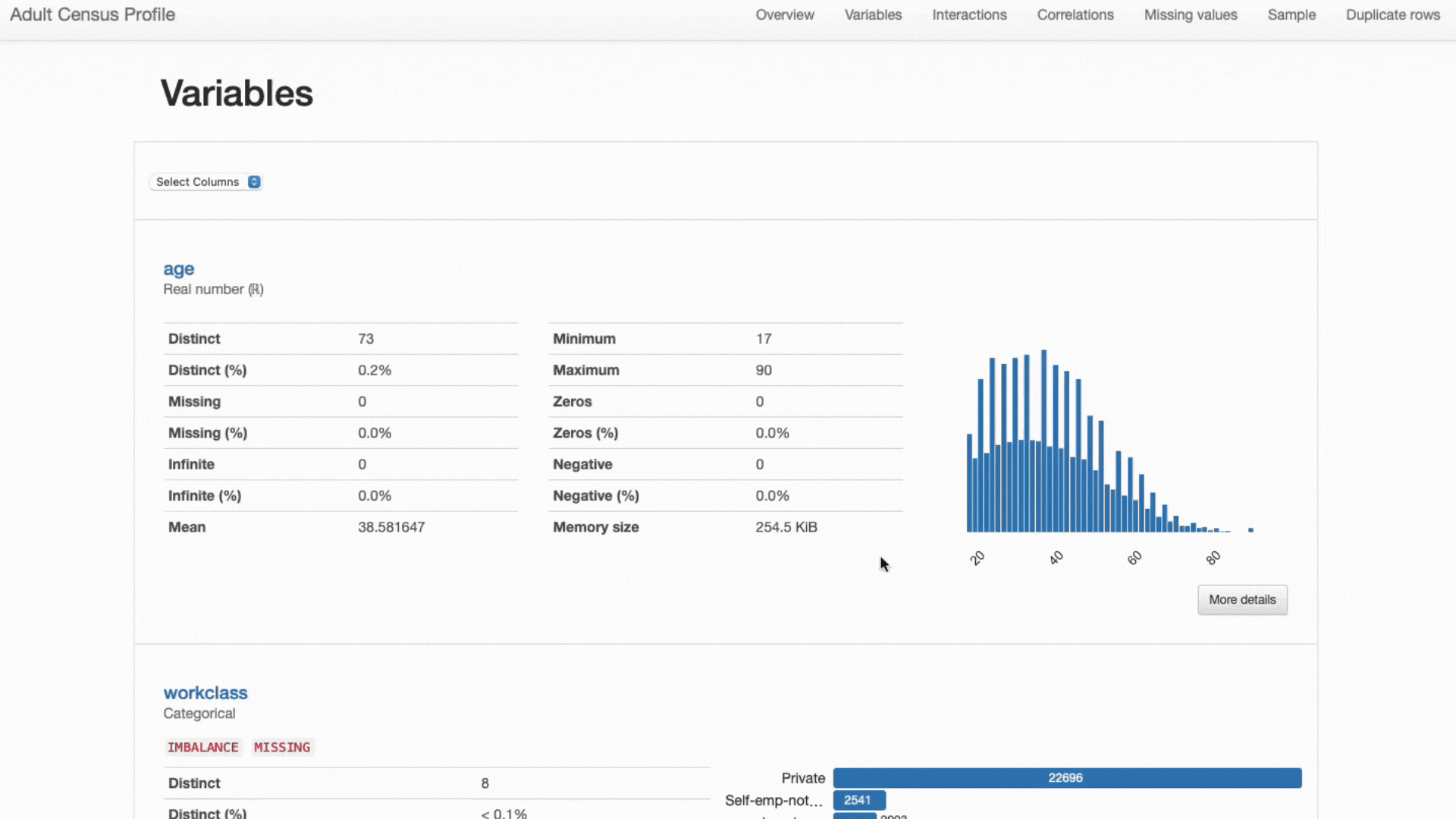
ydata-profiling: отчет о профилировании. Представленные статистические данные и визуализации настраиваются для каждого типа объекта. Скринкаст автора.
Такой подробный анализ было бы обременительно проводить с обычными манипуляциями с пандами, но, к счастью, ydata-profiling имеет все эти функции, встроенные в ProfileReport для нашего удобства: никаких лишних строк кода в сниппет не добавлялось!
Многомерный анализ
Для многомерного анализа лучшие практики сосредоточены в основном на двух стратегиях: взаимодействие между признаками и анализируя их корреляции.
Анализ взаимодействий
Взаимодействие позволяет нам визуально исследовать, как ведет себя каждая пара функций, т. е. как значения одного признака соотносятся со значениями другого.
Например, они могут проявлять положительный or отрицательный отношения, в зависимости от того, связано ли увеличение ценностей одного с увеличением или уменьшением ценностей другого соответственно.
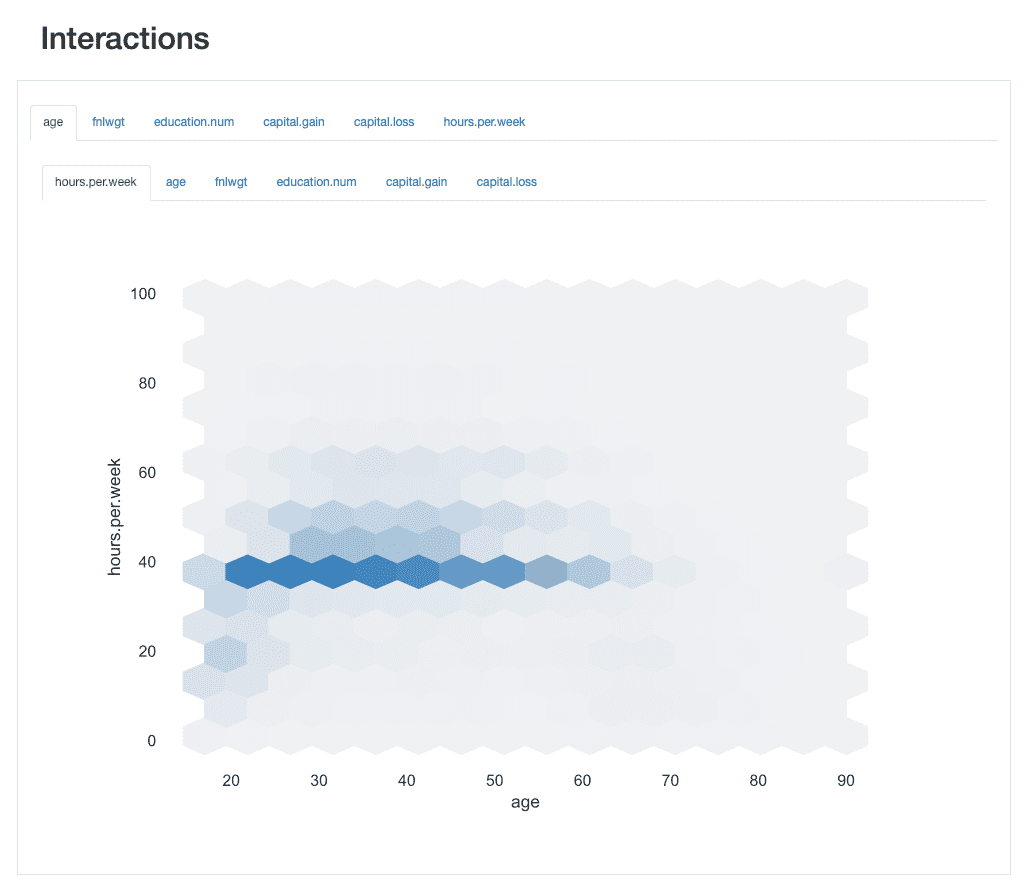
ydata-profiling: отчет о профилировании — взаимодействия. Изображение автора.
Взяв взаимодействие между age и hours.per.weekв качестве примера мы можем видеть, что подавляющее большинство рабочей силы работает по норме 40 часов. Тем не менее, есть некоторые «занятые пчелы», которые работают дольше (до 60 или даже 65 часов) в возрасте от 30 до 45 лет. Люди в возрасте 20 лет менее склонны к переутомлению и могут иметь более легкий график работы в некоторые дни. недели.
Анализ корреляций
Аналогично взаимодействиям, корреляции позволяют нам анализировать отношения между чертами. Корреляции, однако, «придают значение» этому, так что нам легче определить «силу» этой связи.
Эта «сила» измеряется коэффициентами корреляции и могут быть проанализированы либо численно (например, проверка корреляционная матрица) или с Тепловая карта, который использует цвет и затенение для визуального выделения интересных узоров:
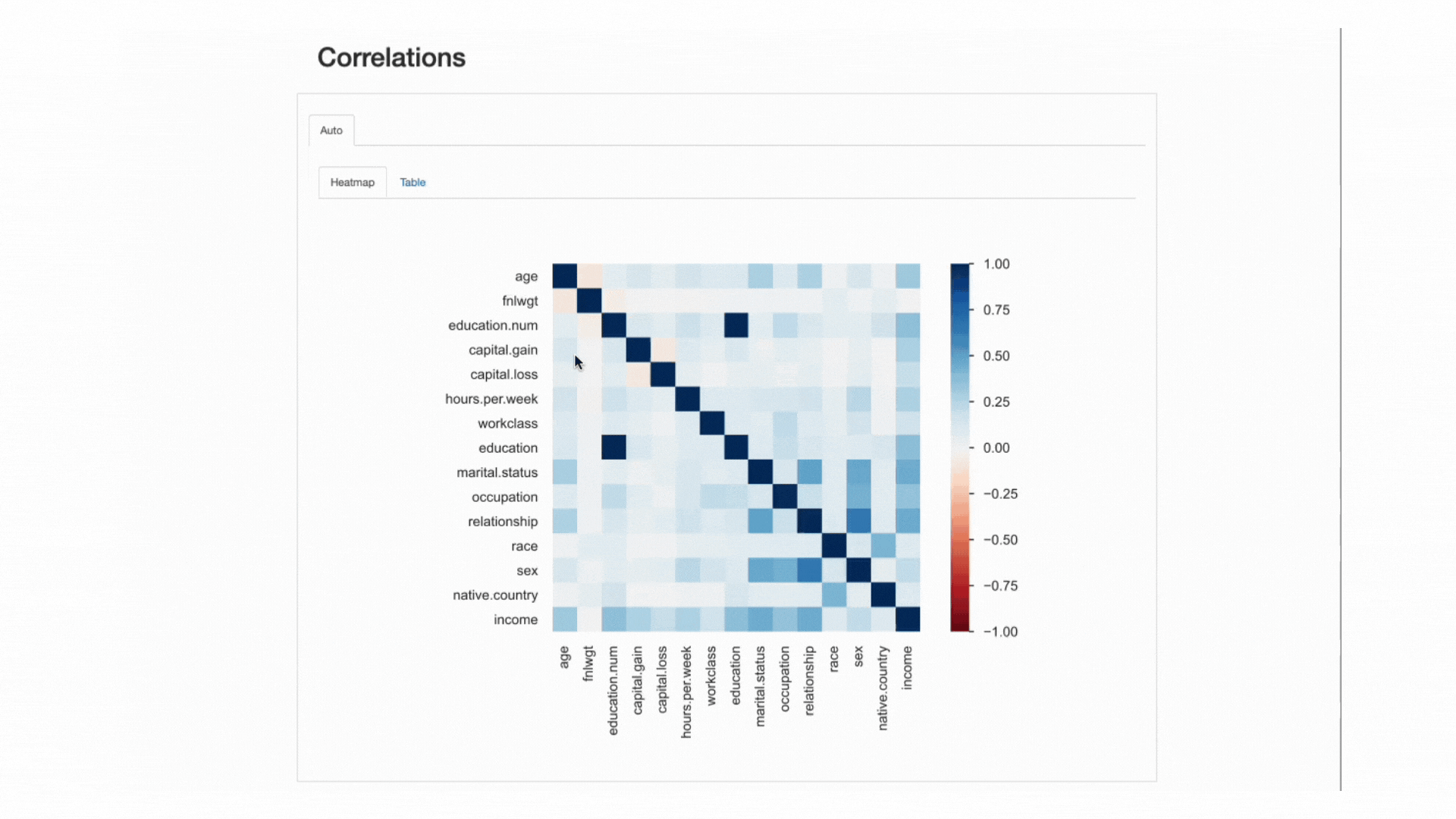
ydata-profiling: отчет о профилировании — тепловая карта и матрица корреляции. Скринкаст автора.
Что касается нашего набора данных, обратите внимание, как корреляция между education и education.num выделяется. Фактически, они содержат одинаковую информациюи education.num это просто биннинг education значения.
Другая закономерность, которая бросается в глаза, — это корреляция между sex и relationship хотя опять же не очень информативно: глядя на значения обоих признаков, мы бы поняли, что эти признаки, скорее всего, связаны, потому что male и female будет соответствовать husband и wife, Соответственно.
Этот тип избыточности можно проверить, чтобы увидеть, можем ли мы удалить некоторые из этих функций из анализа. (marital.status также связано с relationship и sex; native.country и race например, среди прочих).
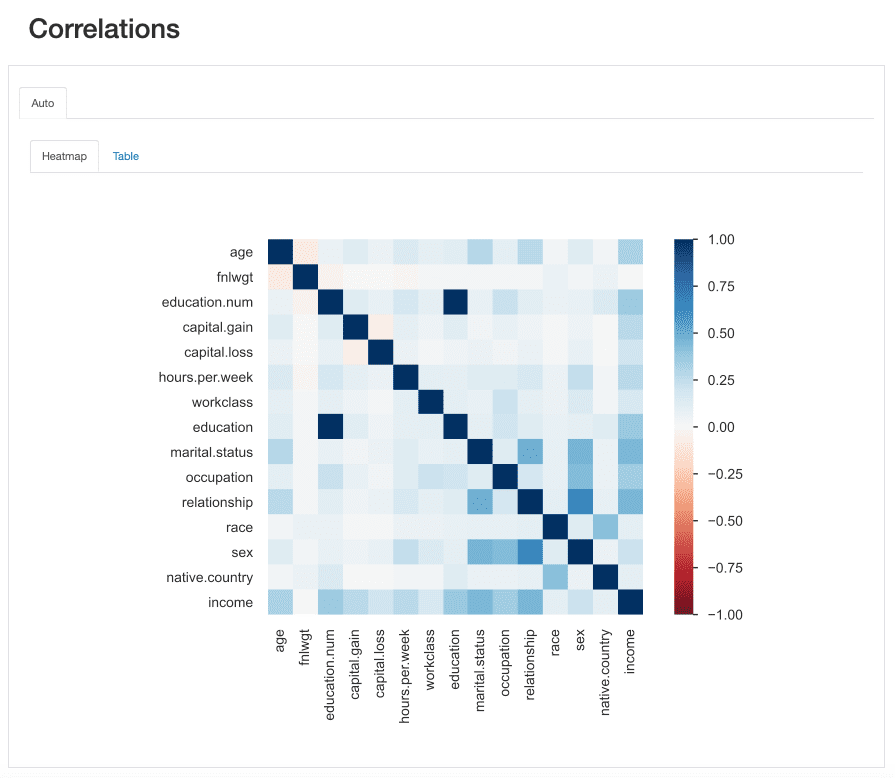
ydata-profiling: Отчет о профилировании — корреляции. Изображение автора.
Однако есть и другие корреляции, которые выделяются и могут быть интересны для целей нашего анализа.
Например, корреляция междуsex и occupationили sex и hours.per.week.
Наконец, корреляции между income а остальные функции действительно информативны, особенно в случае, если мы пытаемся наметить проблему классификации. Зная, какие наиболее коррелированный функции для нашего целевого класса помогает нам определить самый дискриминационный функции, а также найти возможные утечки данных, которые могут повлиять на нашу модель.
Судя по тепловой карте, marital.status or relationship являются одними из самых важных предикторов, в то время как fnlwgt например, похоже, не оказывает большого влияния на результат.
Подобно дескрипторам и визуализациям данных, взаимодействия и корреляции также должны учитывать типы имеющихся функций.
Другими словами, разные комбинации будут измеряться с разными коэффициентами корреляции. По умолчанию, ydata-profiling запускает корреляции на auto, что обозначает:
- Числовой против числового корреляции измеряются с помощью звание копейщика коэффициент корреляции;
- Категоричность против категоричности корреляции измеряются с помощью Крамер V;
- Числовой против Категориального корреляции также используют V Крамера, где сначала дискретизируется числовая характеристика;
И если вы хотите проверить другие коэффициенты корреляции (например, Pearson's, Kendall's, Phi), вы можете легко настроить параметры отчета.
По мере того, как мы направляемся к парадигма, ориентированная на данные развития ИИ, находясь на вершине возможные осложняющие факторы которые возникают в наших данных, имеет важное значение.
Под «осложняющими факторами» мы подразумеваем Ошибки которые могут возникнуть во время сбора данных или обработки, или внутренние характеристики данных которые являются просто отражением природа данных.
К ним относятся отсутствующий данные несбалансированный данные постоянная ценности, дубликаты, высоко коррелирует or избыточный функции, шумный данные, в том числе.
Проблемы качества данных: ошибки и внутренние характеристики данных. Изображение автора.
Обнаружение этих проблем с качеством данных в начале проекта (и их постоянный мониторинг во время разработки) имеет решающее значение.
Если их не выявить и не устранить до этапа построения модели, они могут поставить под угрозу весь конвейер машинного обучения и последующие анализы и выводы, которые могут быть получены на его основе.
Без автоматизированного процесса возможность выявления и решения этих проблем была бы полностью предоставлена личному опыту и знаниям человека, проводящего анализ EDA, что, очевидно, не идеально. Кроме того, какой груз ложиться на плечи, особенно с учетом многомерных наборов данных. Предупреждение о приближающемся кошмаре!
Это одна из наиболее высоко ценимых особенностей ydata-profiling, автоматическая генерация предупреждений о качестве данных:
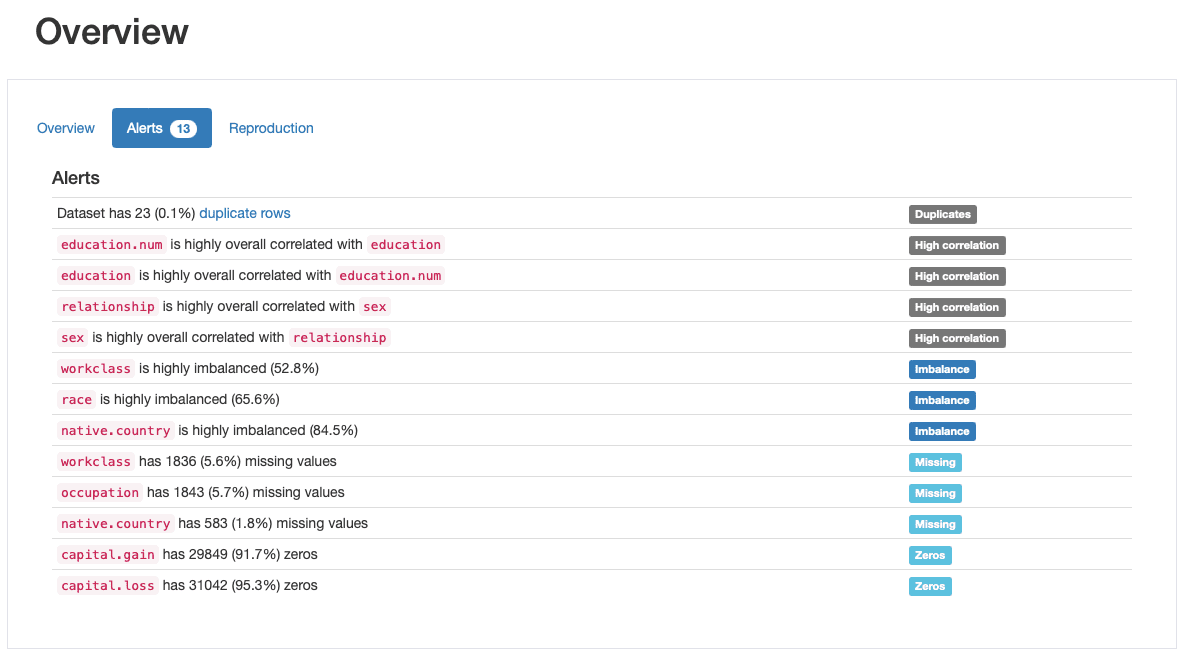
ydata-profiling: отчет о профилировании — предупреждения о качестве данных. Изображение автора.
Профиль выводит как минимум 5 различных типов проблем с качеством данных., А именно duplicates, high correlation, imbalance, missingи zeros.
Действительно, мы уже определили некоторые из них ранее, когда проходили шаг 2: race является очень несбалансированной функцией и capital.gain преимущественно населен 0-ми. Мы также видели тесную корреляцию между education и education.numи relationship и sex.
Анализ шаблонов отсутствующих данных
Среди всех рассматриваемых предупреждений ydata-profiling особенно помогает в анализ отсутствующих шаблонов данных.
Поскольку отсутствующие данные являются очень распространенной проблемой в реальных областях и могут поставить под угрозу применение некоторых классификаторов в целом или серьезно исказить их прогнозы, еще одна лучшая практика — тщательно проанализировать недостающие данные. процент и поведение, которое могут отображать наши функции:
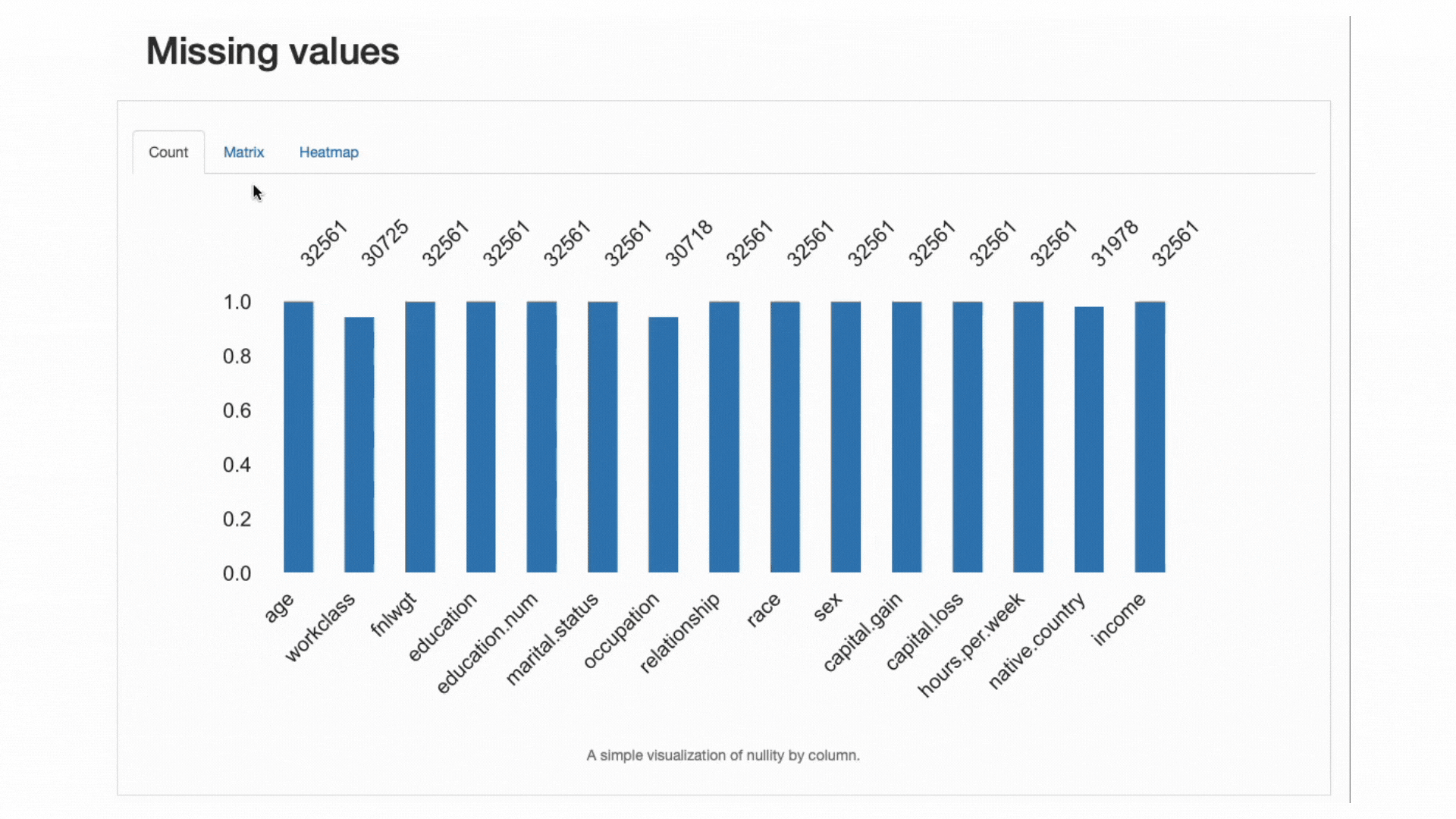
ydata-profiling: отчет о профилировании — анализ пропущенных значений. Скринкаст автора.
Из раздела предупреждений о данных мы уже знали, что workclass, occupationи native.country имели отсутствующие наблюдения. Далее тепловая карта говорит нам, что существует прямая связь с отсутствующим паттерном. in occupation и workclass: если в одной функции отсутствует значение, другая также будет отсутствовать.
Ключевой вывод: профилирование данных выходит за рамки EDA!
До сих пор мы обсуждали задачи, из которых состоит тщательный процесс EDA, и то, как оценка вопросов и характеристик качества данных - процесс, который мы можем назвать профилированием данных — определенно лучшая практика.
Тем не менее, важно уточнить, что профилирование данных выходит за рамки ЭДА. Принимая во внимание, что мы обычно определяем EDA как исследовательский интерактивный шаг перед разработкой любого типа конвейера данных, профилирование данных — это итеративный процесс, который должно происходить на каждом шагу предварительной обработки данных и построения модели.
Эффективная EDA закладывает основу успешного конвейера машинного обучения.
Это похоже на диагностику ваших данных, изучение всего, что вам нужно знать о том, что это влечет за собой — это свойства, отношений, вопросы — чтобы потом можно было решить их наилучшим образом.
Это также начало нашей фазы вдохновения: именно с EDA начинают возникать вопросы и гипотезы, и планируется анализ, чтобы подтвердить или опровергнуть их на этом пути.
На протяжении всей статьи мы рассмотрели 3 основных фундаментальных шага, которые проведут вас через эффективный EDA, и обсудили влияние наличия первоклассного инструмента — ydata-profiling - чтобы указать нам правильное направление, и сэкономит нам огромное количество времени и умственной нагрузки.
Я надеюсь, что это руководство поможет вам освоить искусство «игры в детектива данных». и, как всегда, обратная связь, вопросы и предложения высоко ценятся. Дайте мне знать, о каких еще темах я хотел бы написать, или, что еще лучше, приходите ко мне на Сообщество ИИ, ориентированное на данные и давайте сотрудничать!
Мириам Сантос сосредоточиться на обучении сообществ специалистов по науке о данных и машинному обучению тому, как перейти от необработанных, грязных, «плохих» или несовершенных данных к интеллектуальным, интеллектуальным, высококачественным данным, что позволит классификаторам машинного обучения делать точные и надежные выводы в нескольких отраслях (финтех). , здравоохранение и фармацевтика, телекоммуникации и розничная торговля).
Оригинал, Перемещено с разрешения.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ЭВМ Финанс. Единый интерфейс для децентрализованных финансов. Доступ здесь.
- Квантум Медиа Групп. ИК/PR усиление. Доступ здесь.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=a-data-scientists-essential-guide-to-exploratory-data-analysis
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 30
- 40
- 60
- 65
- 91
- a
- способность
- О нас
- выше
- отсутствующий
- Учетная запись
- точный
- Достигать
- через
- добавленный
- дополнительный
- Дополнительная информация
- адрес
- Добавляет
- Отрегулированный
- Для взрослых
- влиять на
- снова
- Века
- AI
- оповещений
- алгоритм
- алгоритмы
- Все
- вдоль
- уже
- причислены
- Несмотря на то, что
- в целом
- всегда
- am
- среди
- среди
- количество
- an
- анализ
- анализировать
- проанализированы
- анализ
- и
- любой
- Применение
- МЫ
- Искусство
- гайд
- AS
- Оценка
- оценки;
- связанный
- At
- посещать
- автор
- Автоматизированный
- Автоматический
- доступен
- прочь
- Плохой
- бар
- BE
- было
- до
- начало
- не являетесь
- верить
- ЛУЧШЕЕ
- лучшие практики
- Лучшая
- между
- Beyond
- смещение
- Bing
- изоферменты печени
- Приносит
- Строительство
- построенный
- бремя
- но
- by
- призывают
- CAN
- столица
- осторожно
- нести
- случаев
- категории
- Категории
- Перепись
- характеристика
- проверка
- проверил
- класс
- классификация
- Очистить
- код
- лыжных шлемов
- цвет
- комбинации
- как
- Общий
- Сообщества
- полный
- комплекс
- комплексный
- состоит из
- скомпрометированы
- Обеспокоенность
- Проводить
- проведение
- Последствия
- считается
- принимая во внимание
- непрерывно
- удобство
- Корреляция
- коэффициент корреляции
- может
- критической
- решающее значение
- данным
- анализ данных
- Подготовка данных
- Качество данных
- наука о данных
- Наборы данных
- занимавшийся
- решать
- снижение
- глубоко
- По умолчанию
- определенно
- Зависимость
- в зависимости
- производная
- описано
- подробность
- подробный
- Определять
- развивающийся
- Развитие
- отклонение
- диагностика
- различный
- направлять
- направление
- непосредственно
- обсуждать
- обсуждается
- обсуждающий
- Дисплей
- распределение
- do
- приносит
- доменов
- Dont
- рисовать
- Падение
- в течение
- e
- каждый
- легче
- легко
- обучение
- Эффективный
- эффективный
- эффективно
- или
- позволяет
- полностью
- ошибки
- особенно
- сущность
- существенный
- Эфир (ETH)
- Даже
- со временем
- Каждая
- многое
- Изучение
- пример
- существующий
- надеется
- опыт
- опыта
- Исследовательский анализ данных
- Больше
- дополнительно
- чрезвычайно
- Глаза
- факт
- знакомый
- далеко
- Особенность
- Особенности
- Обратная связь
- Найдите
- FinTech
- First
- Фокус
- после
- Что касается
- Форс-мажор
- формат
- Год основания
- частота
- от
- функциональность
- фундаментальный
- принципиально
- далее
- будущее
- Gain
- Общие
- в общем
- генерирует
- поколение
- получить
- GIF
- данный
- Go
- идет
- будет
- большой
- догадывался
- инструкция
- было
- рука
- обрабатывать
- Руки
- Есть
- имеющий
- здравоохранение
- сильно
- помощь
- полезный
- помогает
- высококачественный
- Выделите
- очень
- держать
- надежды
- ЧАСЫ
- Как
- How To
- Однако
- HTTPS
- i
- идеальный
- идентифицированный
- определения
- if
- изображение
- немедленно
- Влияние
- важную
- in
- включены
- доход
- Входящий
- Увеличение
- individual
- промышленности
- информация
- информативный
- понимание
- размышления
- Вдохновение
- пример
- Умный
- намереваться
- взаимодействие
- взаимодействие
- интерактивный
- интересный
- в
- внутренний
- исследовать
- ходе расследования,
- включать в себя
- вопрос
- вопросы
- IT
- ЕГО
- подвергать опасности
- работа
- JPG
- всего
- КДнаггетс
- Кендалла
- Знать
- знание
- известный
- эксцесс
- этикетка
- новее
- Lays
- Лиды
- изучение
- наименее
- оставил
- Меньше
- Лицензия
- легкий
- такое как
- Вероятно
- линия
- линий
- мало
- посмотреть
- искать
- Низкий
- машина
- обучение с помощью машины
- Главная
- в основном
- Большинство
- сделать
- Манипуляция
- карта
- мастер
- матрица
- Май..
- me
- значить
- означает
- измеренный
- Встречайте
- психический
- упомянутый
- Метрика
- может быть
- против
- отсутствующий
- ML
- режим
- модель
- Модели
- Мониторинг
- БОЛЕЕ
- самых
- двигаться
- много
- Откройте
- Необходимость
- нет
- нормально
- Уведомление..
- номер
- объект
- Очевидный
- происходить
- of
- .
- on
- ONE
- только
- оптимальный
- or
- заказ
- Другое
- Другое
- наши
- внешний
- Результат
- выходной
- общий
- обзор
- пара
- панд
- особый
- мимо
- шаблон
- паттеранами
- Люди
- процент
- выполнять
- производительность
- выполнения
- возможно
- разрешение
- человек
- личного
- Фармацевтика
- фаза
- выбирать
- трубопровод
- запланированный
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- правдоподобный
- Точка
- попсовый
- населенный
- возможное
- практика
- практиками
- Predictions
- преимущественно
- подготовка
- представлены
- разрабатывает
- предварительный просмотр
- предварительно
- Печать / PDF
- печать
- Предварительный
- Проблема
- процесс
- обработка
- Профиль
- профилирование
- Проект
- свойства
- что такое варган?
- цель
- вопрос
- Вопросы
- Гонки
- ассортимент
- Обменный курс
- скорее
- Сырье
- реальный мир
- реализовать
- учет
- Цена снижена
- отражение
- по
- Связанный
- отношения
- Отношения
- относительно
- складская
- полагаться
- осталось
- удаление
- удаление
- отчету
- хранилище
- представлять
- представленный
- требовать
- обязательный
- те
- соответственно
- Итоги
- розничный
- правую
- Правило
- Бег
- то же
- график
- Наука
- сфера
- Раздел
- разделах
- посмотреть
- казаться
- кажется
- видел
- чувствительный
- несколько
- сильно
- Поделиться
- Магазин
- Короткое
- должен
- показывать
- значительный
- просто
- просто
- одновременно
- одинарной
- умный
- So
- некоторые
- удалось
- в некотором роде
- Спотовая торговля
- Этап
- стоять
- стандарт
- стоит
- Начало
- Начало
- статистика
- Шаг
- Шаги
- простой
- стратегий
- последующее
- успешный
- такие
- взять
- цель
- Сложность задачи
- задачи
- говорит
- чем
- который
- Ассоциация
- информация
- их
- Их
- Там.
- следовательно
- Эти
- они
- этой
- тщательно
- мысль
- три
- Через
- время
- в
- инструментом
- топ
- Темы
- к
- Традиционно
- огромный
- по-настоящему
- два
- напишите
- Типы
- недопредставленными
- понимание
- созданного
- неизвестный
- до
- Предстоящие
- us
- использование
- использования
- через
- обычно
- VALIDATE
- ценностное
- Наши ценности
- различный
- Против
- очень
- визуализация
- хотеть
- Путь..
- we
- Недели
- вес
- ЧТО Ж
- пошел
- были
- Что
- когда
- будь то
- который
- все
- зачем
- Википедия.
- будете
- без
- слова
- Работа
- работает
- работает
- бы
- записывать
- еще
- являетесь
- ВАШЕ
- зефирнет
- зум






