AWS Glue Studio este o interfață grafică care facilitează crearea, rularea și monitorizarea activităților de extragere, transformare și încărcare (ETL) în AWS Adeziv. Vă permite să compuneți vizual fluxuri de lucru de transformare a datelor folosind noduri care reprezintă diferiți pași de prelucrare a datelor, care ulterior sunt convertite automat în cod pentru a rula.
AWS Glue Studio recent lansat Încă 10 transformări vizuale pentru a permite crearea de locuri de muncă mai avansate într-un mod vizual fără abilități de codare. În această postare, discutăm cazuri potențiale de utilizare care reflectă nevoile comune ETL.
Noile transformări care vor fi demonstrate în această postare sunt: Concatenate, Split String, Array To Columns, Add Current Timestamp, Pivot Rows To Columns, Unpivot Columns To Rows, Lookup, Explode Array sau Map Into Colons, Derived Column, and Autobalance Processing .
Prezentare generală a soluțiilor
În acest caz de utilizare, avem câteva fișiere JSON cu operațiuni de opțiuni pe acțiuni. Dorim să facem unele transformări înainte de stocarea datelor pentru a fi mai ușor de analizat și, de asemenea, dorim să producem un rezumat separat al setului de date.
În acest set de date, fiecare rând reprezintă o tranzacție de contracte de opțiuni. Opțiunile sunt instrumente financiare care oferă dreptul, dar nu și obligația, de a cumpăra sau vinde acțiuni la un preț fix (numit pretul de exercitare) înainte de o dată de expirare definită.
Date de intrare
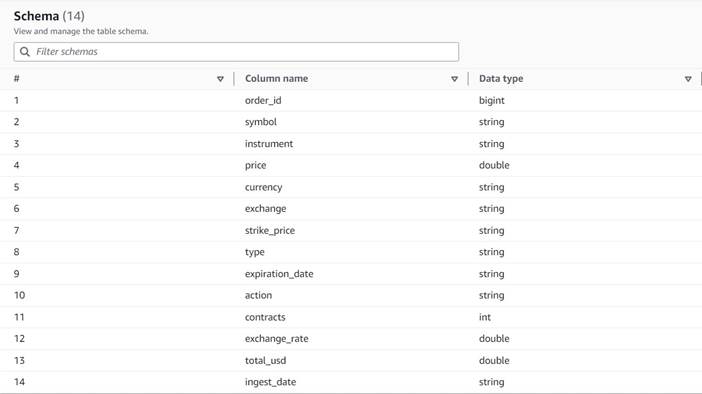
Datele urmează următoarea schemă:
- Comanda ID - Un ID unic
- simbol – Un cod bazat în general pe câteva litere pentru a identifica corporația care emite acțiunile de bază
- instrument – Numele care identifică opțiunea specifică care este cumpărată sau vândută
- valută – Codul monedei ISO în care este exprimat prețul
- preţ – Suma care a fost plătită pentru achiziționarea fiecărui contract de opțiune (la majoritatea burselor, un contract vă permite să cumpărați sau să vindeți 100 de acțiuni)
- schimb – Codul centrului de schimb sau locului unde a fost tranzacționată opțiunea
- vândut – O listă a numărului de contracte care au fost alocate pentru a îndeplini ordinul de vânzare atunci când aceasta este o tranzacție de vânzare
- au cumpărat – O listă a numărului de contracte care au fost alocate pentru a îndeplini ordinul de cumpărare atunci când acesta este tranzacție de cumpărare
Mai jos este o mostră de date sintetice generate pentru această postare:
Cerințe ETL
Aceste date au o serie de caracteristici unice, așa cum se găsesc adesea pe sistemele mai vechi, care fac datele mai greu de utilizat.
Următoarele sunt cerințele ETL:
- Numele instrumentului are informații valoroase pe care oamenii le pot înțelege; dorim să-l normalizăm în coloane separate pentru o analiză mai ușoară.
- Atributele
boughtșisoldse exclud reciproc; le putem consolida într-o singură coloană cu numerele contractului și avem o altă coloană care indică dacă contractele au fost cumpărate sau vândute în această comandă. - Dorim să păstrăm informațiile despre alocările individuale de contracte, dar ca rânduri individuale, în loc să forțăm utilizatorii să se ocupe de o serie de numere. Am putea aduna cifrele, dar am pierde informații despre modul în care a fost completată comanda (indicând lichiditatea pieței). În schimb, alegem să denormalizăm tabelul astfel încât fiecare rând să aibă un singur număr de contracte, împărțind comenzile cu mai multe numere în rânduri separate. Într-un format de coloană comprimat, dimensiunea suplimentară a setului de date a acestei repetiții este adesea mică atunci când se aplică compresia, deci este acceptabil să faci setul de date mai ușor de interogat.
- Dorim să generăm un tabel rezumativ al volumului pentru fiecare tip de opțiune (call și put) pentru fiecare stoc. Acest lucru oferă o indicație a sentimentului pieței pentru fiecare acțiune și a pieței în general (lacomie vs. frică).
- Pentru a permite rezumatele comerciale generale, dorim să furnizăm pentru fiecare operațiune totalul general și să standardizăm moneda în dolari SUA, folosind o referință aproximativă de conversie.
- Vrem să adăugăm data când au avut loc aceste transformări. Acest lucru ar putea fi util, de exemplu, pentru a avea o referință despre când a fost efectuată conversia valutară.
Pe baza acestor cerințe, postul va produce două rezultate:
- Un fișier CSV cu un rezumat al numărului de contracte pentru fiecare simbol și tip
- Un tabel de catalog pentru a păstra un istoric al comenzii, după efectuarea transformărilor indicate
Cerințe preliminare
Veți avea nevoie de propriul dvs. bucket S3 pentru a urma împreună cu acest caz de utilizare. Pentru a crea o găleată nouă, consultați Crearea unei găleți.
Generați date sintetice
Pentru a urma această postare (sau a experimenta singur acest tip de date), puteți genera acest set de date sintetic. Următorul script Python poate fi rulat într-un mediu Python cu Boto3 instalat și acces la Serviciul Amazon de stocare simplă (Amazon S3).
Pentru a genera datele, parcurgeți următorii pași:
- Pe AWS Glue Studio, creați o nouă lucrare cu opțiunea Editor de scripturi shell Python.
- Dați un nume locului de muncă și pe Detaliile postului fila, selectați a rol potrivit și un nume pentru scriptul Python.
- În Detaliile postului secțiune, extinde Proprietăți avansate și derulați în jos până la Parametrii jobului.
- Introduceți un parametru numit
--bucketși atribuiți ca valoare numele găleții pe care doriți să o utilizați pentru a stoca datele eșantionului. - Introduceți următorul script în editorul shell AWS Glue:
- Rulați lucrarea și așteptați până când se afișează ca finalizată cu succes în fila Runs (ar trebui să dureze doar câteva secunde).
Fiecare rulare va genera un fișier JSON cu 1,000 de rânduri sub compartimentul specificat și prefix transformsblog/inputdata/. Puteți rula lucrarea de mai multe ori dacă doriți să testați cu mai multe fișiere de intrare.
Fiecare linie din datele sintetice este un rând de date care reprezintă un obiect JSON ca următorul:
Creați lucrarea vizuală AWS Glue
Pentru a crea lucrarea vizuală AWS Glue, parcurgeți următorii pași:
- Accesați AWS Glue Studio și creați o lucrare folosind opțiunea Vizual cu o pânză goală.
- Editati
Untitled jobpentru a-i da un nume și a atribui un rol potrivit pentru AWS Glue pe Detaliile postului tab. - Adăugați o sursă de date S3 (o puteți denumi
JSON files source) și introduceți adresa URL S3 sub care sunt stocate fișierele (de exemplu,s3://<your bucket name>/transformsblog/inputdata/), apoi selectați JSON ca format de date. - Selectați Deduceți schema deci setează schema de ieșire pe baza datelor.
Din acest nod sursă, veți continua să înlănțuiți transformările. Când adăugați fiecare transformare, asigurați-vă că nodul selectat este ultimul adăugat, astfel încât să fie atribuit ca părinte, dacă nu se indică altfel în instrucțiuni.
Dacă nu ați selectat părintele potrivit, puteți oricând să editați părintele selectându-l și alegând un alt părinte în panoul de configurare.
Pentru fiecare nod adăugat, îi veți da un nume specific (deci scopul nodului se arată în grafic) și configurație pe Transforma tab.
De fiecare dată când o transformare modifică schema (de exemplu, adăugați o nouă coloană), schema de ieșire trebuie actualizată, astfel încât să fie vizibilă pentru transformările din aval. Puteți edita manual schema de ieșire, dar este mai practic și mai sigur să o faceți folosind previzualizarea datelor.
În plus, în acest fel puteți verifica că transformarea funcționează până în prezent conform așteptărilor. Pentru a face acest lucru, deschideți Previzualizare date cu transformarea selectată și începeți o sesiune de previzualizare. După ce ați verificat că datele transformate arată așa cum vă așteptați, accesați Schema de ieșire filă și alegeți Utilizați schema de previzualizare a datelor pentru a actualiza schema automat.
Pe măsură ce adăugați noi tipuri de transformări, previzualizarea poate afișa un mesaj despre o dependență lipsă. Când se întâmplă acest lucru, alegeți Încheierea sesiunii iar începeți unul nou, astfel încât previzualizarea preia noul tip de nod.
Extrageți informații despre instrument
Să începem prin a trata informațiile de pe numele instrumentului pentru a le normaliza în coloane care sunt mai ușor de accesat în tabelul rezultat.
- Adauga o Împărțire șir nod și denumește-l
Split instrument, care va tokeniza coloana instrumentului folosind o expresie regex cu spații albe:s+(un singur spațiu ar fi potrivit în acest caz, dar acest mod este mai flexibil și mai clar vizual). - Dorim să păstrăm informațiile originale ale instrumentului așa cum sunt, așa că introduceți un nou nume de coloană pentru matricea divizată:
instrument_arr.
- Adăugați un Matrice către coloane nod și denumește-l
Instrument columnspentru a converti coloana matrice tocmai creată în câmpuri noi, cu excepțiasymbol, pentru care avem deja o coloană. - Selectați coloana
instrument_arr, săriți peste primul simbol și spuneți-i să extragă coloanele de ieșiremonth, day, year, strike_price, typefolosind indici2, 3, 4, 5, 6(spațiile de după virgule sunt pentru lizibilitate, nu afectează configurația).
Anul extras este exprimat numai cu două cifre; haideți să presupunem că este în acest secol dacă folosesc doar două cifre.
- Adauga o Coloană derivată nod și denumește-l
Four digits year. - Intrați
yearca coloană derivată, astfel încât să o înlocuiască și introduceți următoarea expresie SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Pentru comoditate, construim un expiration_date câmp pe care un utilizator îl poate avea ca referință a ultimei date în care poate fi exercitată opțiunea.
- Adauga o Concatenează coloanele nod și denumește-l
Build expiration date. - Denumiți noua coloană
expiration_date, selectați coloaneleyear,month, șiday(în această ordine) și o cratimă ca distanțier.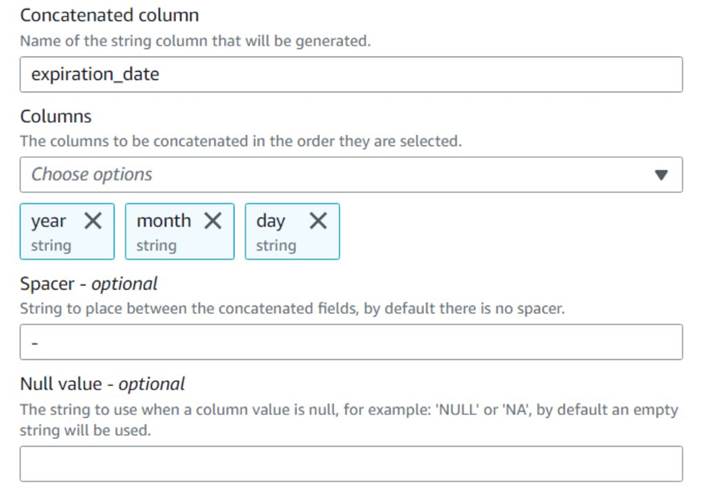
Diagrama de până acum ar trebui să arate ca exemplul următor.
![]()
Previzualizarea datelor noilor coloane de până acum ar trebui să arate ca următoarea captură de ecran.
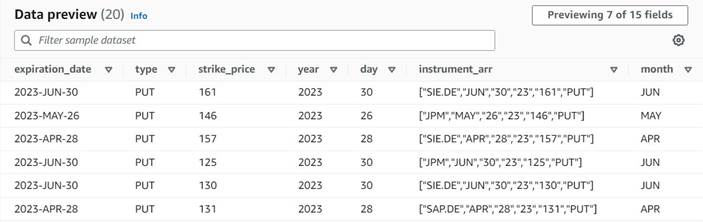
Normalizați numărul de contracte
Fiecare dintre rândurile din date indică numărul de contracte ale fiecărei opțiuni care au fost cumpărate sau vândute și loturile pe care au fost completate comenzile. Fără a pierde informațiile despre loturile individuale, dorim să avem fiecare cantitate pe un rând individual cu o singură valoare a cantității, în timp ce restul informațiilor este replicată în fiecare rând produs.
Mai întâi, să îmbinăm sumele într-o singură coloană.
- Adăugați un Anulați pivotarea coloanelor în rânduri nod și denumește-l
Unpivot actions. - Alegeți coloanele
boughtșisoldpentru a debloca și a stoca numele și valorile în coloanele numiteactionșicontracts, respectiv.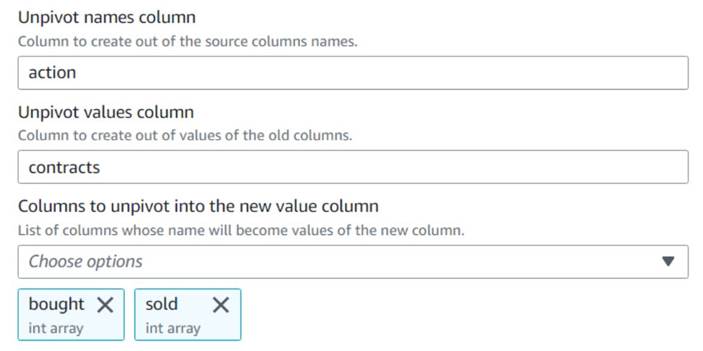
Observați în previzualizare că noua coloanăcontractseste încă o serie de numere după această transformare.
- Adăugați un Explodați matrice sau hartă în rânduri rând numit
Explode contracts. - Alege
contractscoloană și introducețicontractsca nouă coloană pentru a o suprascrie (nu trebuie să păstrăm matricea originală).
Previzualizarea arată acum că fiecare rând are un singur rând contracts suma, iar restul câmpurilor sunt aceleași.
Aceasta înseamnă și că order_id nu mai este o cheie unică. Pentru propriile cazuri de utilizare, trebuie să decideți cum să vă modelați datele și dacă doriți să denormalizați sau nu.
Următoarea captură de ecran este un exemplu despre cum arată noile coloane după transformările de până acum.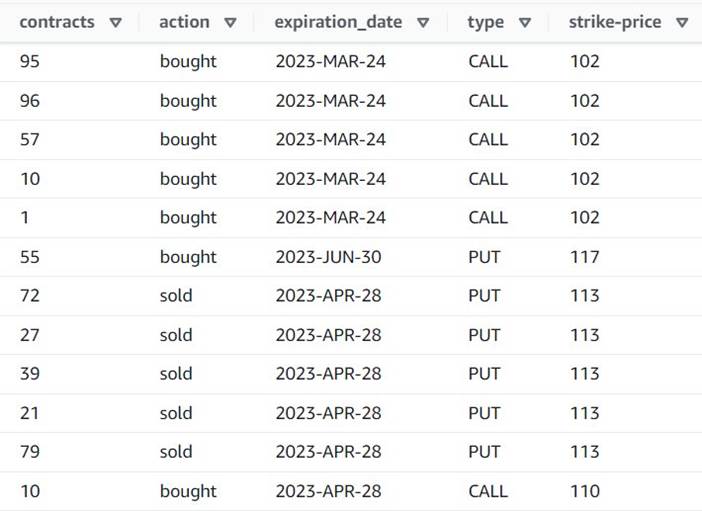
Creați un tabel rezumativ
Acum creați un tabel rezumat cu numărul de contracte tranzacționate pentru fiecare tip și fiecare simbol bursier.
Să presupunem, în scopuri ilustrative, că fișierele procesate aparțin unei singure zile, astfel încât acest rezumat oferă utilizatorilor de afaceri informații despre interesul și sentimentul pieței în acea zi.
- Adauga o Selectați Câmpuri nod și selectați următoarele coloane de păstrat pentru rezumat:
symbol,type, șicontracts.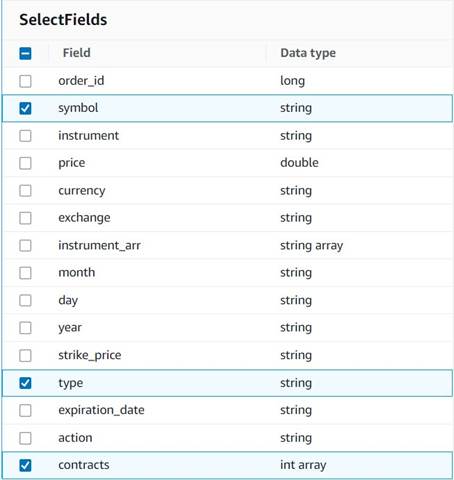
- Adauga o Pivotați rândurile în coloane nod și denumește-l
Pivot summary. - Agregat pe
contractscoloana folosindsumși alegeți să convertițitypecoloana.
În mod normal, l-ați stoca într-o bază de date sau fișier extern pentru referință; în acest exemplu, îl salvăm ca fișier CSV pe Amazon S3.
- Adăugați un Procesare autoechilibrare nod și denumește-l
Single output file. - Deși acest tip de transformare este utilizat în mod normal pentru a optimiza paralelismul, aici îl folosim pentru a reduce rezultatul la un singur fișier. Prin urmare, intra
1în configurația numărului de partiții.
- Adăugați o țintă S3 și denumiți-o
CSV Contract summary. - Alegeți CSV ca format de date și introduceți o cale S3 în care rolul jobului are permisiunea de a stoca fișiere.
Ultima parte a lucrării ar trebui să arate acum ca exemplul următor.![]()
- Salvați și rulați lucrarea. Folosește Rulează pentru a verifica când s-a terminat cu succes.
Veți găsi un fișier sub acea cale care este un CSV, deși nu are această extensie. Probabil că va trebui să adăugați extensia după ce o descărcați pentru a o deschide.
Pe un instrument care poate citi CSV, rezumatul ar trebui să arate ceva ca următorul exemplu.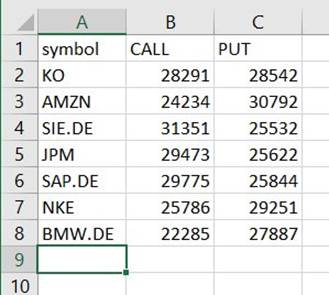
Curățați coloanele temporare
În pregătirea pentru salvarea comenzilor într-un tabel istoric pentru analize viitoare, să curățăm câteva coloane temporare create pe parcurs.
- Adauga o Drop Fields nodul cu
Explode contractsnodul selectat ca părinte (ramificăm conducta de date pentru a genera o ieșire separată). - Selectați câmpurile care trebuie aruncate:
instrument_arr,month,day, șiyear.
Restul vrem să le păstrăm, astfel încât să fie salvate în tabelul istoric pe care îl vom crea mai târziu.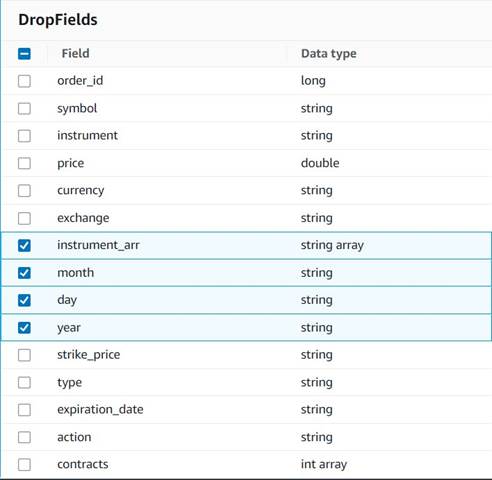
Standardizarea valutară
Aceste date sintetice conțin operațiuni fictive pe două valute, dar într-un sistem real ai putea obține valute de pe piețele din întreaga lume. Este util să standardizați monedele gestionate într-o singură monedă de referință, astfel încât acestea să poată fi comparate și agregate cu ușurință pentru raportare și analiză.
Noi folosim Amazon Atena pentru a simula un tabel cu conversii valutare aproximative care este actualizat periodic (aici presupunem că procesăm comenzile suficient de timp pentru ca conversia să fie un reprezentant rezonabil în scopuri de comparație).
- Deschideți consola Athena în aceeași regiune în care utilizați AWS Glue.
- Rulați următoarea interogare pentru a crea tabelul setând o locație S3 în care atât rolurile dvs. Athena, cât și AWS Glue pot citi și scrie. De asemenea, poate doriți să stocați tabelul într-o altă bază de date decât
default(dacă faceți acest lucru, actualizați numele calificat de tabel în mod corespunzător în exemplele furnizate). - Introduceți câteva exemple de conversii în tabel:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Acum ar trebui să puteți vizualiza tabelul cu următoarea interogare:
SELECT * FROM default.exchange_rates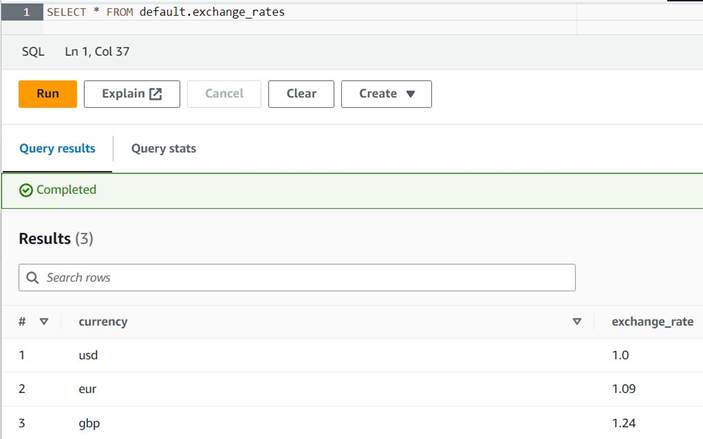
- Înapoi la lucrarea vizuală AWS Glue, adăugați un Căutare nod (ca copil al
Drop Fields) și denumiți-oExchange rate. - Introduceți numele calitativ al tabelului pe care tocmai l-ați creat, folosind
currencyca tasta și selectațiexchange_ratecâmp de utilizat.
Deoarece câmpul este numit același atât în tabelul de date, cât și în tabelul de căutare, putem doar să introducem numelecurrencyși nu este nevoie să definiți o mapare.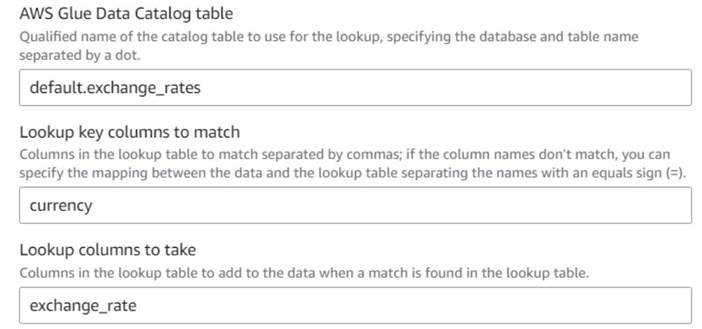
La momentul scrierii acestui articol, transformarea Căutare nu este acceptată în previzualizarea datelor și va afișa o eroare că tabelul nu există. Aceasta este doar pentru previzualizarea datelor și nu împiedică executarea corectă a sarcinii. Cei câțiva pași rămași ai postării nu necesită actualizarea schemei. Dacă trebuie să rulați o previzualizare a datelor pe alte noduri, puteți elimina temporar nodul de căutare și apoi îl puteți pune înapoi. - Adauga o Coloană derivată nod și denumește-l
Total in usd. - Denumiți coloana derivată
total_usdși utilizați următoarea expresie SQL:round(contracts * price * exchange_rate, 2)
- Adauga o Adăugați marcaj temporal curent nod și denumește coloana
ingest_date. - Utilizați formatul
%Y-%m-%dpentru marca dvs. de timp (în scopuri demonstrative, folosim doar data; o puteți face mai precisă dacă doriți).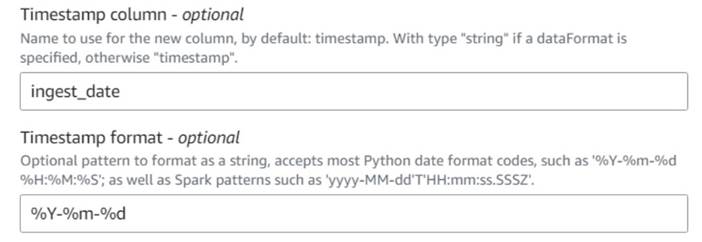
Salvați tabelul de comenzi istorice
Pentru a salva tabelul de comenzi istorice, parcurgeți următorii pași:
- Adăugați un nod țintă S3 și denumiți-l
Orders table. - Configurați formatul Parquet cu compresie rapidă și furnizați o cale țintă S3 sub care să stocați rezultatele (separat de rezumatul).
- Selectați Creați un tabel în Catalogul de date și, la rulările ulterioare, actualizați schema și adăugați noi partiții.
- Introduceți o bază de date țintă și un nume pentru noul tabel, de exemplu:
option_orders.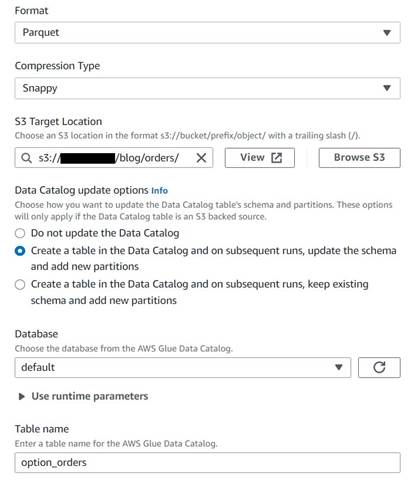
Ultima parte a diagramei ar trebui să arate acum similar cu următoarea, cu două ramuri pentru cele două ieșiri separate.![]()
După ce executați jobul cu succes, puteți utiliza un instrument precum Athena pentru a examina datele pe care le-a produs jobul interogând noul tabel. Puteți găsi tabelul pe lista Athena și alegeți Previzualizare tabel sau pur și simplu rulați o interogare SELECT (actualizarea numelui tabelului la numele și catalogul pe care le-ați folosit):
SELECT * FROM default.option_orders limit 10
Conținutul tabelului ar trebui să arate similar cu următoarea captură de ecran.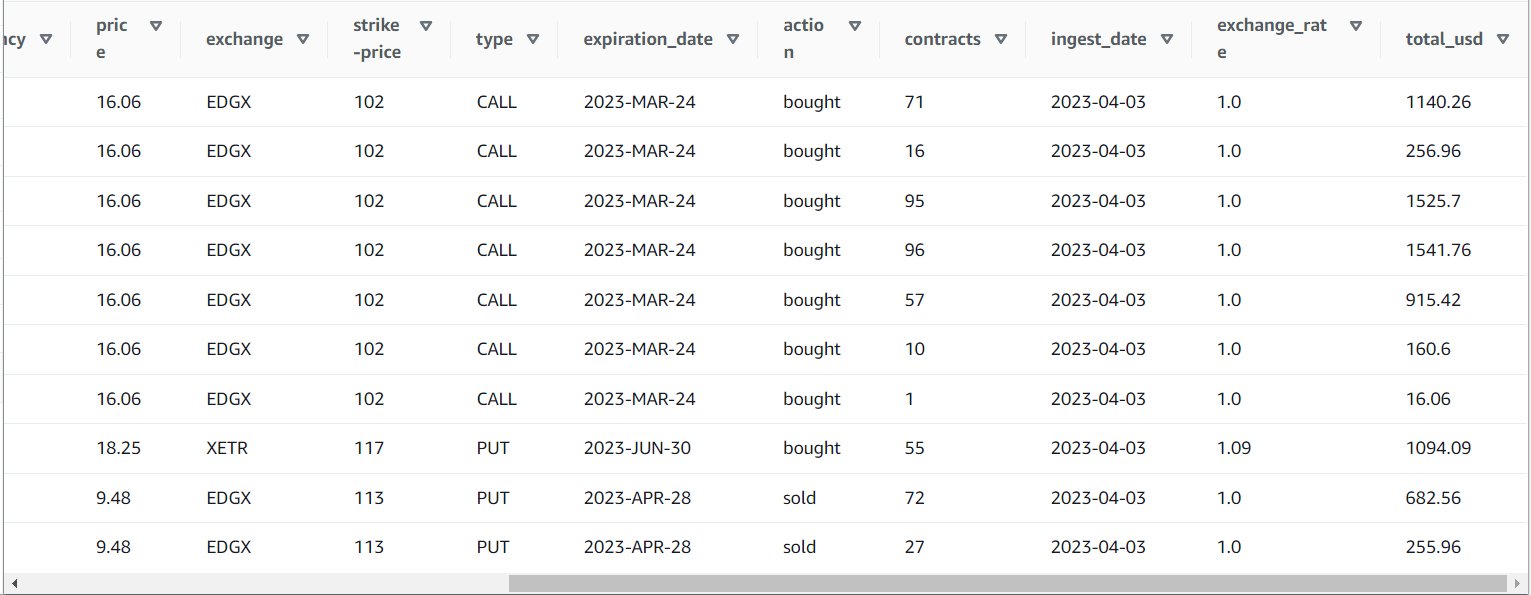
A curăța
Dacă nu doriți să păstrați acest exemplu, ștergeți cele două joburi pe care le-ați creat, cele două tabele din Athena și căile S3 în care au fost stocate fișierele de intrare și de ieșire.
Concluzie
În această postare, am arătat cum noile transformări din AWS Glue Studio vă pot ajuta să faceți o transformare mai avansată cu o configurație minimă. Aceasta înseamnă că puteți implementa mai multe cazuri de utilizare ETL fără a fi nevoie să scrieți și să întrețineți niciun cod. Noile transformări sunt deja disponibile pe AWS Glue Studio, așa că puteți folosi noile transformări astăzi în joburile dvs. vizuale.
Despre autor
![]() Gonzalo Herreros este arhitect senior Big Data în echipa AWS Glue.
Gonzalo Herreros este arhitect senior Big Data în echipa AWS Glue.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Mintând viitorul cu Adryenn Ashley. Accesați Aici.
- Cumpărați și vindeți acțiuni în companii PRE-IPO cu PREIPO®. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Capabil
- Despre Noi
- acceptabil
- acces
- în consecință
- adăuga
- adăugat
- adăugare
- avansat
- După
- TOATE
- alocate
- alocări
- permite
- permite
- de-a lungul
- deja
- de asemenea
- mereu
- Amazon
- sumă
- Sume
- an
- analiză
- analiza
- și
- O alta
- Orice
- aplicat
- aproximativ
- aprilie
- SUNT
- argument
- Mulțime
- AS
- alocate
- At
- atribute
- în mod automat
- disponibil
- AWS
- AWS Adeziv
- înapoi
- bazat
- BE
- înainte
- fiind
- Mare
- Datele mari
- necompletat
- BMW
- atât
- au cumpărat
- ramuri
- construi
- afaceri
- dar
- cumpăra
- by
- apel
- CAN
- caz
- cazuri
- catalog
- Centru
- Secol
- Modificări
- Caracteristici
- verifica
- copil
- Alege
- alegere
- mai clar
- cod
- Codificare
- Coloană
- Coloane
- Comun
- comparație
- comparație
- Completă
- Terminat
- Configuraţie
- Consoleze
- consolida
- conține
- conţinut
- contract
- contracte
- comoditate
- Convertire
- conversii
- converti
- convertit
- CORPORAȚIE
- ar putea
- crea
- a creat
- Crearea
- Moneda
- Monedă
- Curent
- DAG
- de date
- Baza de date
- Data
- Date
- datetime
- zi
- afacere
- abuzive
- decide
- Mod implicit
- definit
- demonstrat
- Dependenţă
- Derivat
- În ciuda
- detalii
- diferit
- cifre
- discuta
- do
- Nu
- face
- de dolari
- Dont
- dubla
- jos
- Picătură
- scăzut
- fiecare
- mai ușor
- cu ușurință
- uşor
- editor
- permite
- suficient de
- Intrați
- Mediu inconjurator
- eroare
- Eter (ETH)
- EURO
- exemplu
- exemple
- Cu excepția
- schimb
- Platforme de tranzacţionare
- Exclusiv
- exista
- Extinde
- de aşteptat
- experiment
- expirare
- și-a exprimat
- extensie
- extern
- suplimentar
- extrage
- departe
- frică
- puțini
- fictiv
- camp
- Domenii
- Fișier
- Fişiere
- umple
- umplut
- financiar
- Instrumente financiare
- Găsi
- First
- fixată
- flexibil
- urma
- următor
- urmează
- Pentru
- format
- găsit
- din
- viitor
- lira sterlină
- General
- în general
- genera
- generată
- obține
- Da
- oferă
- Go
- grafic
- Lăcomie
- Manipularea
- se întâmplă
- Avea
- având în
- ajutor
- aici
- istoric
- istorie
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- Oamenii
- i
- identifică
- identifica
- if
- Impactul
- punerea în aplicare a
- import
- in
- indexurile
- indicată
- indică
- indicând
- indicaţie
- individ
- informații
- intrare
- instanță
- in schimb
- instrucțiuni
- instrument
- instrumente
- interes
- interfaţă
- în
- ISO
- IT
- ESTE
- Loc de munca
- Locuri de munca
- jpg
- JSON
- doar
- A pastra
- Cheie
- Copil
- Nume
- mai tarziu
- ca
- LIMITĂ
- Linie
- Lichiditate
- Listă
- încărca
- locaţie
- mai lung
- Uite
- arată ca
- Se pare
- căutare
- pierde
- care pierde
- făcut
- menține
- face
- FACE
- manual
- Hartă
- cartografiere
- Piață
- sentiment de piață
- pieţe
- Mai..
- mijloace
- Îmbina
- mesaj
- ar putea
- minim
- dispărut
- model
- monitor
- mai mult
- cele mai multe
- multiplu
- reciproc
- nume
- Numit
- nume
- Nevoie
- nevoilor
- Nou
- Nu.
- nod
- noduri
- în mod normal
- acum
- număr
- numere
- obiect
- of
- de multe ori
- on
- ONE
- afară
- deschide
- operaţie
- Operațiuni
- Optimizați
- Opțiune
- Opţiuni
- or
- comandă
- comenzilor
- original
- Altele
- in caz contrar
- producție
- peste
- global
- trece peste
- propriu
- plătit
- pâine
- parametru
- parte
- cale
- Alegerea
- conducte
- Pivot
- Loc
- Plato
- Informații despre date Platon
- PlatoData
- Post
- potenţial
- Practic
- precis
- împiedica
- Anunţ
- preţ
- probabil
- proces
- prelucrare
- produce
- Produs
- furniza
- prevăzut
- furnizează
- cumpărare
- scop
- scopuri
- pune
- Piton
- calificat
- ridica
- aleator
- Citeste
- real
- rezonabil
- reduce
- reflecta
- regiune
- rămas
- scoate
- replicat
- Raportarea
- reprezenta
- reprezentant
- reprezentând
- reprezintă
- necesita
- Cerinţe
- Necesită
- respectiv
- REST
- rezultând
- REZULTATE
- revizuiască
- Rol
- rolurile
- RÂND
- Alerga
- funcţionare
- mai sigur
- acelaşi
- sevă
- Economisiți
- economisire
- derulaţi
- secunde
- selectate
- selectarea
- vinde
- senior
- sentiment
- distinct
- sesiune
- Seturi
- instalare
- Acțiuni
- Coajă
- să
- Arăta
- Emisiuni
- asemănător
- simplu
- singur
- Mărimea
- aptitudini
- mic
- So
- până acum
- vândut
- unele
- ceva
- Sursă
- Spaţiu
- spații
- specific
- specificată
- împărţi
- Spreadsheet
- SQL
- Începe
- paşi
- Încă
- stoc
- depozitare
- stoca
- stocate
- Şir
- studio
- ulterior
- Reușit
- potrivit
- REZUMAT
- Suportat
- simbol
- sintetic
- date sintetice
- sintetic
- sistem
- sisteme
- tabel
- Lua
- Ţintă
- echipă
- spune
- temporar
- zece
- test
- decât
- acea
- Graficul
- informațiile
- lumea
- Lor
- apoi
- prin urmare
- Acestea
- ei
- acest
- aceste
- timp
- ori
- timestamp-ul
- la
- astăzi
- semn
- tokeniza
- a luat
- instrument
- Total
- comerţului
- firmei
- Transforma
- Transformare
- transformări
- transformat
- Două
- tip
- în
- care stau la baza
- înţelege
- unic
- până la
- Actualizează
- actualizat
- actualizarea
- URL-ul
- us
- Dolari SUA
- USD
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- Valoros
- Informatie pretioasa
- valoare
- Valori
- Locatia evenimentului
- verificat
- verifica
- Vizualizare
- vizibil
- volum
- vs
- aștepta
- vrea
- a fost
- Cale..
- we
- au fost
- Ce
- cand
- care
- în timp ce
- voi
- cu
- fără
- fluxuri de lucru
- de lucru
- lume
- ar
- scrie
- scris
- an
- tu
- Ta
- zephyrnet











