Odată cu apariția AI generativă, modelele de bază (FM) de astăzi, cum ar fi modelele de limbaj mari (LLM) Claude 2 și Llama 2, pot îndeplini o serie de sarcini generative, cum ar fi răspunsul la întrebări, rezumarea și crearea de conținut pe date text. Cu toate acestea, datele din lumea reală există în mai multe modalități, cum ar fi text, imagini, video și audio. Luați un pachet de diapozitive PowerPoint, de exemplu. Poate conține informații sub formă de text sau încorporate în grafice, tabele și imagini.
În această postare, vă prezentăm o soluție care utilizează FM-uri multimodale, cum ar fi Embeddings multimodale Amazon Titan model și LLaVA 1.5 și servicii AWS, inclusiv Amazon Bedrock și Amazon SageMaker pentru a efectua sarcini generative similare pe date multimodale.
Prezentare generală a soluțiilor
Soluția oferă o implementare pentru a răspunde la întrebări folosind informațiile conținute în text și elementele vizuale ale unui pachet de diapozitive. Designul se bazează pe conceptul de Retrieval Augmented Generation (RAG). În mod tradițional, RAG a fost asociat cu date textuale care pot fi procesate de către LLM. În această postare, extindem RAG pentru a include și imagini. Aceasta oferă o capacitate puternică de căutare pentru a extrage conținut relevant din punct de vedere contextual din elemente vizuale precum tabele și grafice împreună cu text.
Există diferite moduri de a proiecta o soluție RAG care include imagini. Am prezentat o abordare aici și vom continua cu o abordare alternativă în al doilea post al acestei serii de trei părți.
Această soluție include următoarele componente:
- Modelul Amazon Titan Multimodal Embeddings – Acest FM este folosit pentru a genera încorporare pentru conținutul din pachetul de diapozitive utilizat în această postare. Ca model multimodal, acest model Titan poate procesa text, imagini sau o combinație ca intrare și poate genera înglobări. Modelul Titan Multimodal Embeddings generează vectori (embeddings) de 1,024 de dimensiuni și este accesat prin Amazon Bedrock.
- Asistent pentru limbaj și viziune mare (LLaVA) – LLaVA este un model multimodal open source pentru înțelegerea vizuală și a limbajului și este utilizat pentru a interpreta datele din diapozitive, inclusiv elemente vizuale, cum ar fi grafice și tabele. Folosim versiunea cu parametri de 7 miliarde LLaVA 1.5-7b in aceasta solutie.
- Amazon SageMaker – Modelul LLaVA este implementat pe un punct final SageMaker folosind serviciile de găzduire SageMaker și folosim punctul final rezultat pentru a rula inferențe împotriva modelului LLaVA. De asemenea, folosim notebook-uri SageMaker pentru a orchestra și a demonstra această soluție cap la cap.
- Amazon OpenSearch Serverless – OpenSearch Serverless este o configurație la cerere fără server pentru Serviciul Amazon OpenSearch. Folosim OpenSearch Serverless ca bază de date vectorială pentru stocarea înglobărilor generate de modelul Titan Multimodal Embeddings. Un index creat în colecția OpenSearch Serverless servește drept magazin de vectori pentru soluția noastră RAG.
- Amazon OpenSearch Ingestion (OSI) – OSI este un colector de date complet gestionat, fără server, care furnizează date către domeniile OpenSearch Service și colecțiile OpenSearch Serverless. În această postare, folosim o conductă OSI pentru a livra date către magazinul de vectori OpenSearch Serverless.
Arhitectura soluțiilor
Proiectarea soluției constă din două părți: asimilare și interacțiune cu utilizatorul. În timpul ingerării, procesăm pachetul de diapozitive de intrare transformând fiecare diapozitiv într-o imagine, generăm încorporare pentru aceste imagini și apoi populăm depozitul de date vectoriale. Acești pași sunt finalizați înainte de pașii de interacțiune cu utilizatorul.
În faza de interacțiune cu utilizatorul, o întrebare a utilizatorului este convertită în înglobări și se execută o căutare de similaritate în baza de date vectorială pentru a găsi un diapozitiv care ar putea conține răspunsuri la întrebarea utilizatorului. Apoi oferim acest diapozitiv (sub forma unui fișier imagine) modelului LLaVA și întrebarea utilizatorului ca o solicitare pentru a genera un răspuns la interogare. Tot codul pentru această postare este disponibil în GitHub odihnă.
Următoarea diagramă ilustrează arhitectura de asimilare.
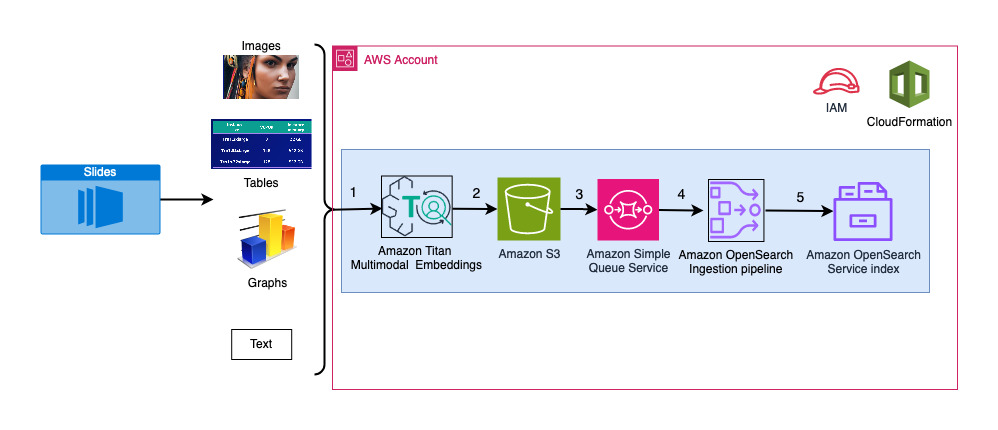
Pașii fluxului de lucru sunt următorii:
- Diapozitivele sunt convertite în fișiere imagine (unul per diapozitiv) în format JPG și trecute la modelul Titan Multimodal Embeddings pentru a genera încorporare. În această postare, folosim pachetul de diapozitive intitulat Antrenați și implementați Stable Diffusion folosind AWS Trainium și AWS Inferentia de la AWS Summit de la Toronto, iunie 2023, pentru a demonstra soluția. Pachetul de mostre are 31 de diapozitive, așa că generăm 31 de seturi de înglobare vectorială, fiecare cu 1,024 de dimensiuni. Adăugăm câmpuri de metadate suplimentare la aceste înglobări vectoriale generate și creăm un fișier JSON. Aceste câmpuri de metadate suplimentare pot fi folosite pentru a efectua interogări de căutare bogate folosind capabilitățile puternice de căutare ale OpenSearch.
- Înglobările generate sunt reunite într-un singur fișier JSON care este încărcat în Serviciul Amazon de stocare simplă (Amazon S3).
- Prin intermediul Notificări de evenimente Amazon S3, un eveniment este pus într-un Serviciul de coadă simplă Amazon (Amazon SQS) coadă.
- Acest eveniment din coada SQS acționează ca un declanșator pentru a rula conducta OSI, care, la rândul său, ingerează datele (fișierul JSON) ca documente în indexul OpenSearch Serverless. Rețineți că indexul OpenSearch Serverless este configurat ca receptor pentru această conductă și este creat ca parte a colecției OpenSearch Serverless.
Următoarea diagramă ilustrează arhitectura de interacțiune cu utilizatorul.
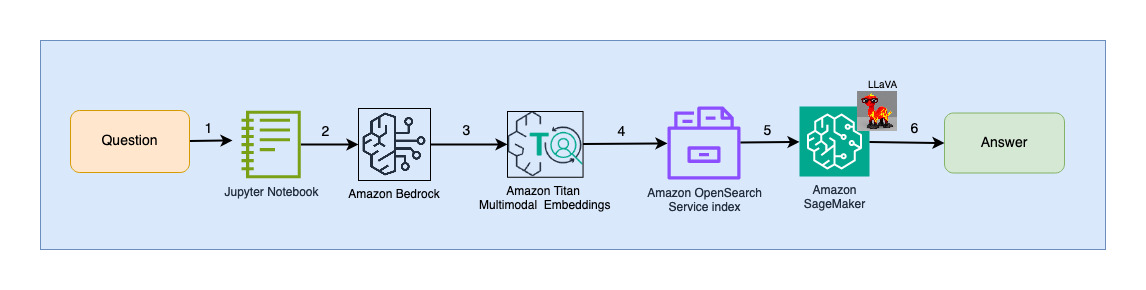
Pașii fluxului de lucru sunt următorii:
- Un utilizator trimite o întrebare legată de pachetul de diapozitive care a fost ingerat.
- Intrarea utilizatorului este convertită în înglobări folosind modelul Titan Multimodal Embeddings accesat prin Amazon Bedrock. O căutare vectorială OpenSearch este efectuată folosind aceste înglobări. Efectuăm o căutare de k-cel mai apropiat vecin (k=1) pentru a regăsi cea mai relevantă încorporare care se potrivește cu interogarea utilizatorului. Setarea k=1 preia diapozitivul cel mai relevant pentru întrebarea utilizatorului.
- Metadatele răspunsului de la OpenSearch Serverless conţin o cale către imaginea corespunzătoare celui mai relevant diapozitiv.
- Un prompt este creat combinând întrebarea utilizatorului și calea imaginii și este furnizat la LLaVA găzduit pe SageMaker. Modelul LLaVA este capabil să înțeleagă întrebarea utilizatorului și să îi răspundă examinând datele din imagine.
- Rezultatul acestei inferențe este returnat utilizatorului.
Acești pași sunt discutați în detaliu în secțiunile următoare. Vezi REZULTATE secțiune pentru capturi de ecran și detalii despre ieșire.
Cerințe preliminare
Pentru a implementa soluția oferită în această postare, ar trebui să aveți un Cont AWS și familiaritatea cu FM, Amazon Bedrock, SageMaker și OpenSearch Service.
Această soluție folosește modelul Titan Multimodal Embeddings. Asigurați-vă că acest model este activat pentru utilizare în Amazon Bedrock. Pe consola Amazon Bedrock, alegeți Acces model în panoul de navigare. Dacă Titan Multimodal Embeddings este activat, starea accesului se va indica Acces permis.
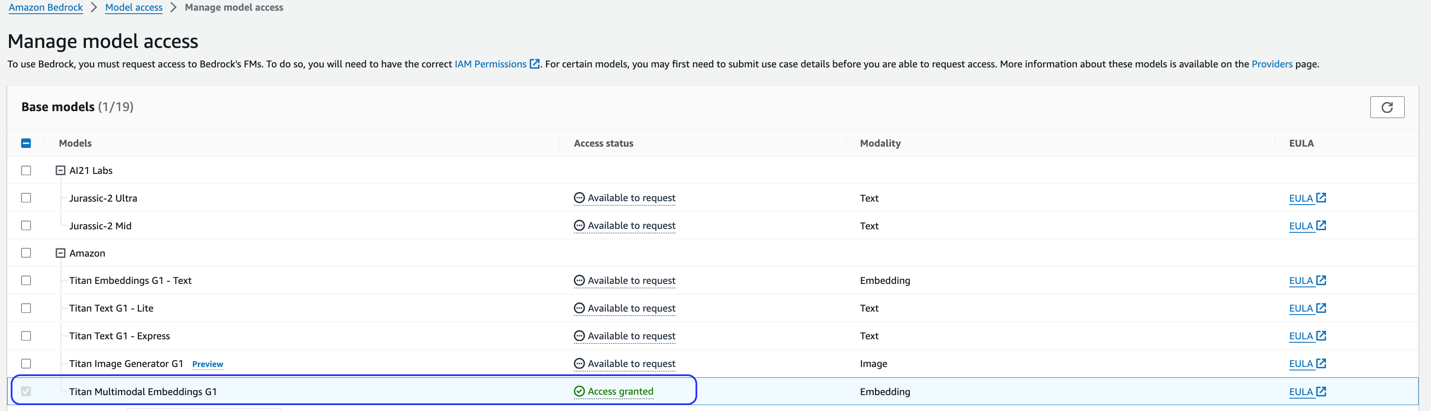
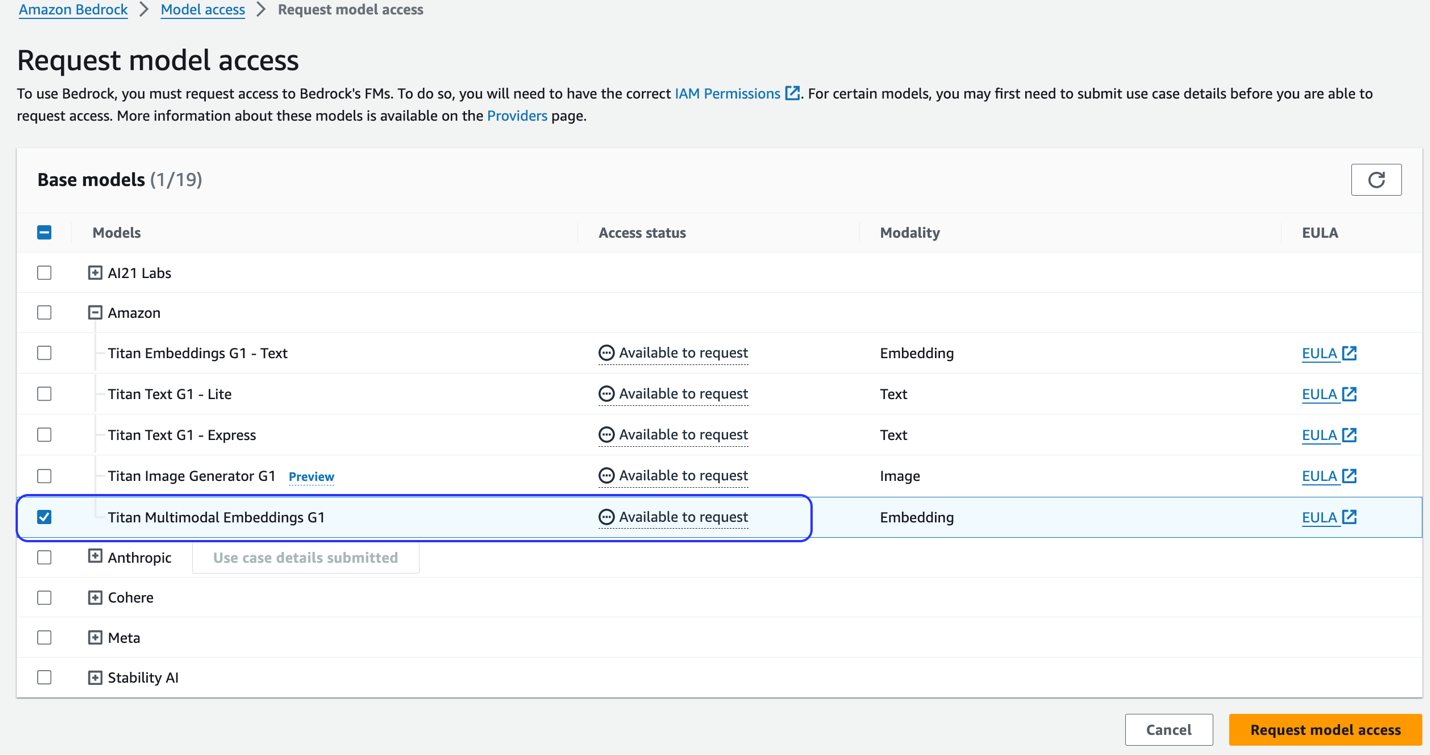
Dacă modelul nu este disponibil, permiteți accesul la model selectând Gestionați accesul la model, selectând Titan Multimodal Embeddings G1, și alegerea Solicitați acces la model. Modelul este activat pentru utilizare imediat.
Utilizați un șablon AWS CloudFormation pentru a crea stiva de soluții
Utilizați una dintre următoarele Formarea AWS Cloud șabloane (în funcție de regiunea dvs.) pentru a lansa resursele soluției.
| Regiunea AWS | Link |
|---|---|
us-east-1 |
|
us-west-2 |
După ce stiva este creată cu succes, navigați la stiva ieşiri pe consola AWS CloudFormation și notați valoarea pentru MultimodalCollectionEndpoint, pe care îl folosim în pașii următori.
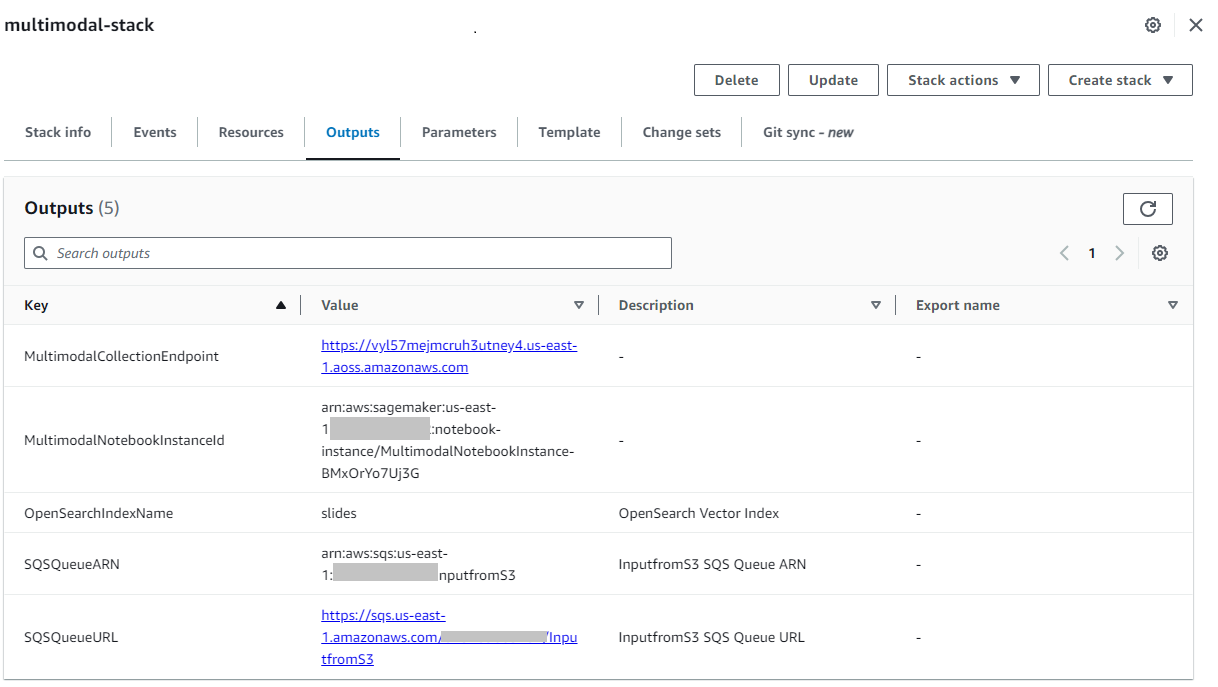
Șablonul CloudFormation creează următoarele resurse:
- Roluri IAM - Următoarele Gestionarea identității și accesului AWS (IAM) sunt create. Actualizați aceste roluri pentru a aplica permisiuni cu cel mai mic privilegiu.
SMExecutionRolecu acces complet Amazon S3, SageMaker, OpenSearch Service și Bedrock.OSPipelineExecutionRolecu acces la anumite acțiuni Amazon SQS și OSI.
- Caietul SageMaker – Tot codul pentru această postare este rulat prin intermediul acestui notebook.
- Colecție OpenSearch Serverless – Aceasta este baza de date vectorială pentru stocarea și preluarea înglobărilor.
- Conducta OSI – Acesta este canalul pentru ingerarea datelor în OpenSearch Serverless.
- Găleată S3 – Toate datele pentru această postare sunt stocate în această găleată.
- coada SQS – Evenimentele pentru declanșarea rulării conductei OSI sunt puse în această coadă.
Șablonul CloudFormation configurează conducta OSI cu procesarea Amazon S3 și Amazon SQS ca sursă și un index OpenSearch Serverless ca receptor. Orice obiecte create în compartimentul S3 și prefixul specificat (multimodal/osi-embeddings-json) va declanșa notificări SQS, care sunt utilizate de conducta OSI pentru a ingera date în OpenSearch Serverless.
De asemenea, șablonul CloudFormation creează reţea, criptare, și accesul la date politicile necesare pentru colecția OpenSearch Serverless. Actualizați aceste politici pentru a aplica permisiunile cu cel mai mic privilegiu.
Rețineți că numele șablonului CloudFormation este menționat în caietele SageMaker. Dacă numele implicit al șablonului este schimbat, asigurați-vă că îl actualizați în globals.py
Testați soluția
După ce pașii necesari sunt finalizați și stiva CloudFormation a fost creată cu succes, acum sunteți gata să testați soluția:
- Pe consola SageMaker, alegeți notebook-uri în panoul de navigare.
- selectaţi
MultimodalNotebookInstanceinstanță de notebook și alegeți Deschideți JupyterLab.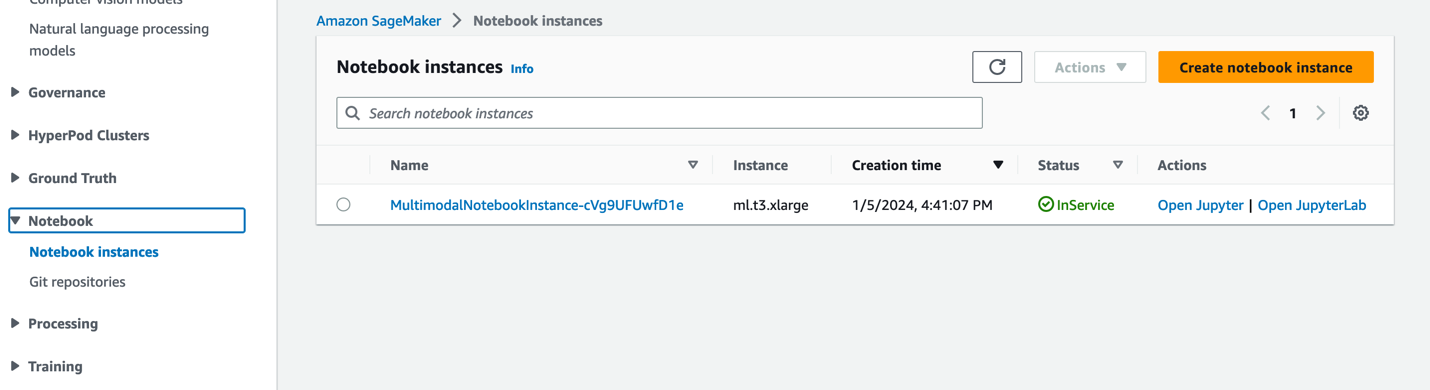
- In Browser de fișiere, treceți la folderul caiete pentru a vedea caietele și fișierele suport.
Caietele sunt numerotate în ordinea în care sunt rulate. Instrucțiunile și comentariile din fiecare caiet descriu acțiunile efectuate de acel caiet. Rulăm aceste caiete unul câte unul.
- Alege 0_deploy_llava.ipynb pentru a-l deschide în JupyterLab.
- Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
Acest notebook implementează modelul LLaVA-v1.5-7B la un punct final SageMaker. În acest notebook, descarcăm modelul LLaVA-v1.5-7B de la HuggingFace Hub, înlocuim scriptul inference.py cu llava_inference.pyși creați un fișier model.tar.gz pentru acest model. Fișierul model.tar.gz este încărcat pe Amazon S3 și utilizat pentru implementarea modelului pe punctul final SageMaker. The llava_inference.py scriptul are un cod suplimentar pentru a permite citirea unui fișier imagine de pe Amazon S3 și rularea inferenței asupra acestuia.
- Alege 1_data_prep.ipynb pentru a-l deschide în JupyterLab.
- Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
Acest notebook descarcă punte de alunecare, convertește fiecare diapozitiv în format de fișier JPG și le încarcă în compartimentul S3 folosit pentru această postare.
- Alege 2_data_ingestion.ipynb pentru a-l deschide în JupyterLab.
- Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
Facem următoarele în acest caiet:
- Creăm un index în colecția OpenSearch Serverless. Acest index stochează datele de încorporare pentru pachetul de diapozitive. Vezi următorul cod:
- Folosim modelul Titan Multimodal Embeddings pentru a converti imaginile JPG create în blocnotesul anterior în înglobări vectoriale. Aceste înglobări și metadate suplimentare (cum ar fi calea S3 a fișierului imagine) sunt stocate într-un fișier JSON și încărcate în Amazon S3. Rețineți că este creat un singur fișier JSON, care conține documente pentru toate diapozitivele (imaginile) convertite în încorporare. Următorul fragment de cod arată modul în care o imagine (sub forma unui șir codificat Base64) este convertită în înglobări:
- Această acțiune declanșează pipeline OpenSearch Ingestion, care procesează fișierul și îl ingerează în indexul OpenSearch Serverless. Următorul este un eșantion al fișierului JSON creat. (Un vector cu patru dimensiuni este afișat în codul exemplu. Modelul Titan Multimodal Embeddings generează 1,024 de dimensiuni.)
- Alege 3_rag_inference.ipynb pentru a-l deschide în JupyterLab.
- Pe Alerga meniu, alegeți Rulați toate celulele pentru a rula codul din acest caiet.
Acest notebook implementează soluția RAG: convertim întrebarea utilizatorului în înglobări, găsim o imagine similară (diapozitiv) din baza de date vectorială și furnizăm imaginea preluată către LLaVA pentru a genera un răspuns la întrebarea utilizatorului. Folosim următorul șablon prompt:
Următorul fragment de cod oferă fluxul de lucru RAG:
REZULTATE
Următoarea este o compilație a unor întrebări și răspunsuri ale utilizatorilor generate de implementarea noastră. The Întrebare coloana captează întrebarea utilizatorului și Răspunde coloana este răspunsul textual generat de LLaVA. Imagine este cea mai apropiată potrivire de diapozitive (k=1) returnată de căutarea vectorială OpenSearch Serverless. Acest diapozitiv este interpretat de LLaVA pentru a oferi răspunsul.
Rezultate RAG multimodale
| Întrebare | Răspunde | Imagine |
|---|---|---|
| Cum se compară Inf2 ca performanță cu instanțele EC2 comparabile? Am nevoie de numere. | Potrivit slide-deck-ului, instanțele Inf2 de la AWS Inferentia2 oferă un randament de până la 4 ori mai mare și o latență de 10 ori mai mică în comparație cu instanțele EC2 comparabile. |  |
| Conform volantului AI/ML, ce oferă serviciile AWS AI/ML? | Serviciile AWS AI/ML oferă capabilități $/perfer mai bune, noi capabilități și investiții în inovare. | 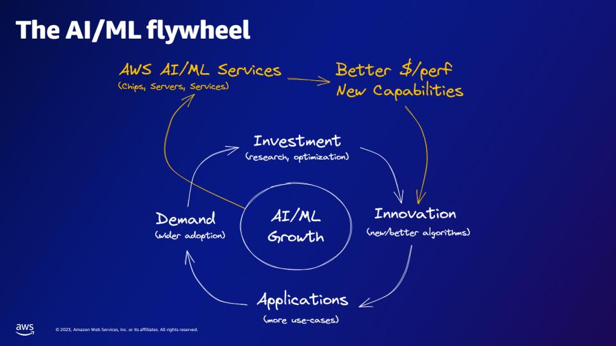 |
| În comparație cu GPT-2, câți parametri mai are GPT-3? Care este diferența numerică dintre dimensiunea parametrului GPT-2 și GPT-3? | Potrivit slide-ului, GPT-3 are 175 de miliarde de parametri, în timp ce GPT-2 are 1.5 miliarde de parametri. Diferența numerică dintre dimensiunea parametrilor GPT-2 și GPT-3 este de 173.5 miliarde. | 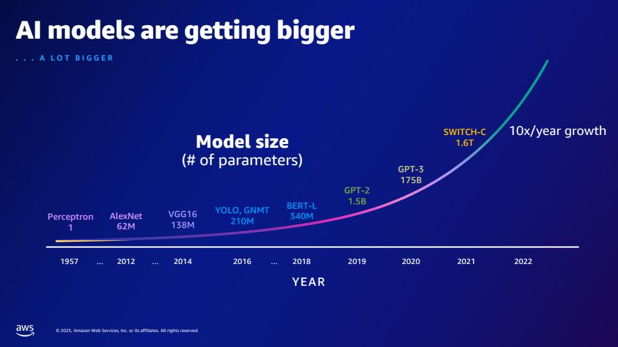 |
| Ce sunt quarkurile în fizica particulelor? | Nu am găsit răspunsul la această întrebare în pachetul de diapozitive. |  |
Simțiți-vă liber să extindeți această soluție la platformele dvs. de diapozitive. Pur și simplu actualizați variabila SLIDE_DECK în globals.py cu o adresă URL către pachetul de diapozitive și rulați pașii de asimilare detaliați în secțiunea anterioară.
varful
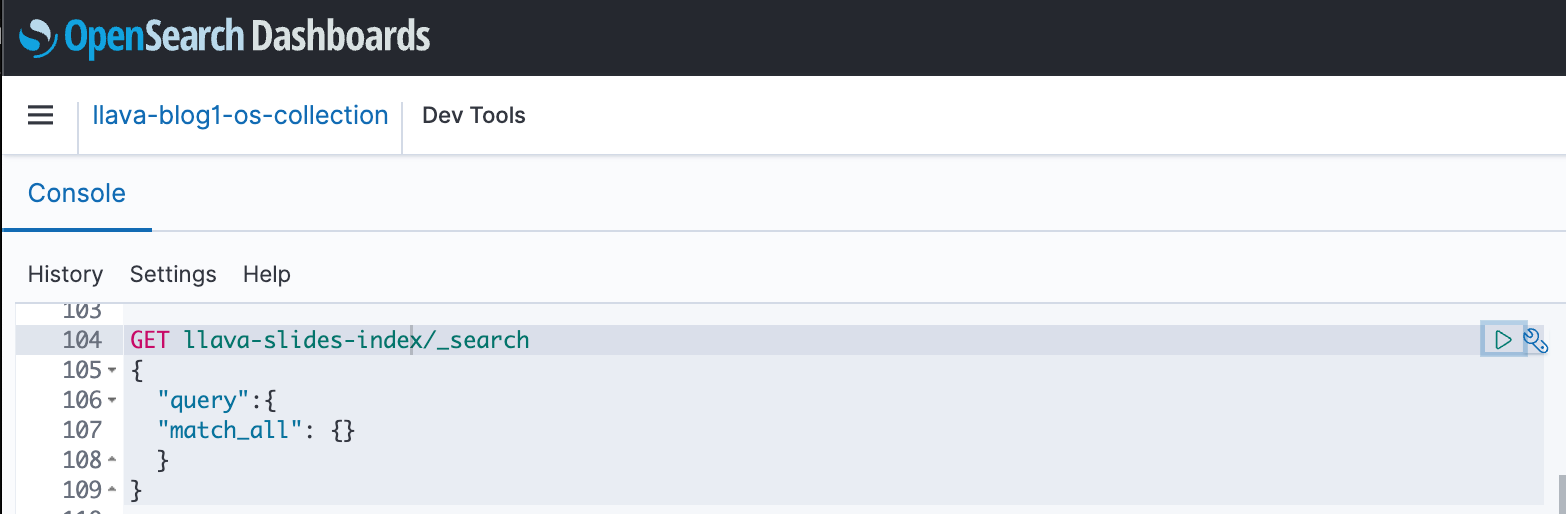
Puteți utiliza tablourile de bord OpenSearch pentru a interacționa cu API-ul OpenSearch pentru a rula teste rapide asupra indexului și a datelor ingerate. Următoarea captură de ecran arată un exemplu GET de tablou de bord OpenSearch.
A curăța
Pentru a evita costurile viitoare, ștergeți resursele pe care le-ați creat. Puteți face acest lucru ștergând stiva prin consola CloudFormation.

În plus, ștergeți punctul final de inferență SageMaker creat pentru inferența LLaVA. Puteți face acest lucru prin decomentarea pasului de curățare 3_rag_inference.ipynb și rulând celula, sau ștergând punctul final prin consola SageMaker: alegeți deducție și Puncte finale în panoul de navigare, apoi selectați punctul final și ștergeți-l.
Concluzie
Întreprinderile generează continut nou tot timpul, iar slide-urile sunt un mecanism comun utilizat pentru a partaja și a disemina informații în interior cu organizația și extern cu clienții sau la conferințe. De-a lungul timpului, informațiile bogate pot rămâne îngropate și ascunse în modalități non-text, cum ar fi graficele și tabelele din aceste pachete de diapozitive. Puteți folosi această soluție și puterea FM-urilor multimodale, cum ar fi modelul Titan Multimodal Embeddings și LLaVA pentru a descoperi noi informații sau a descoperi noi perspective asupra conținutului din slide-uri.
Vă încurajăm să aflați mai multe explorând Amazon SageMaker JumpStart, Modele Amazon Titan, Amazon Bedrock și OpenSearch Service și construirea unei soluții folosind exemplul de implementare furnizat în această postare.
Căutați două postări suplimentare ca parte a acestei serii. Partea 2 acoperă o altă abordare pe care ați putea să o luați pentru a vorbi cu pachetul de diapozitive. Această abordare generează și stochează inferențe LLaVA și utilizează acele inferențe stocate pentru a răspunde la interogările utilizatorilor. Partea 3 compară cele două abordări.
Despre autori
 Amit Arora este arhitect specialist AI și ML la Amazon Web Services, ajutând clienții întreprinderilor să folosească servicii de învățare automată bazate pe cloud pentru a-și scala rapid inovațiile. El este, de asemenea, lector adjunct în programul MS de știință a datelor și analiză la Universitatea Georgetown din Washington DC
Amit Arora este arhitect specialist AI și ML la Amazon Web Services, ajutând clienții întreprinderilor să folosească servicii de învățare automată bazate pe cloud pentru a-și scala rapid inovațiile. El este, de asemenea, lector adjunct în programul MS de știință a datelor și analiză la Universitatea Georgetown din Washington DC
 Manju Prasad este arhitect senior de soluții în cadrul Strategic Accounts la Amazon Web Services. Ea se concentrează pe furnizarea de îndrumare tehnică într-o varietate de domenii, inclusiv AI/ML unui client marcat de M&E. Înainte de a se alătura AWS, ea a proiectat și construit soluții pentru companii din sectorul serviciilor financiare și, de asemenea, pentru un startup.
Manju Prasad este arhitect senior de soluții în cadrul Strategic Accounts la Amazon Web Services. Ea se concentrează pe furnizarea de îndrumare tehnică într-o varietate de domenii, inclusiv AI/ML unui client marcat de M&E. Înainte de a se alătura AWS, ea a proiectat și construit soluții pentru companii din sectorul serviciilor financiare și, de asemenea, pentru un startup.
 Archana Inapudi este arhitect senior de soluții la AWS, care sprijină clienții strategici. Ea are peste un deceniu de experiență în a ajuta clienții să proiecteze și să construiască soluții de analiză a datelor și baze de date. Este pasionată de utilizarea tehnologiei pentru a oferi valoare clienților și pentru a obține rezultate în afaceri.
Archana Inapudi este arhitect senior de soluții la AWS, care sprijină clienții strategici. Ea are peste un deceniu de experiență în a ajuta clienții să proiecteze și să construiască soluții de analiză a datelor și baze de date. Este pasionată de utilizarea tehnologiei pentru a oferi valoare clienților și pentru a obține rezultate în afaceri.
 Antara Raisa este arhitect de soluții AI și ML la Amazon Web Services, care sprijină clienții strategici din Dallas, Texas. Ea are, de asemenea, experiență anterioară de lucru cu mari parteneri la AWS, unde a lucrat ca arhitect de soluții pentru succes pentru parteneri pentru clienții nativi digitali.
Antara Raisa este arhitect de soluții AI și ML la Amazon Web Services, care sprijină clienții strategici din Dallas, Texas. Ea are, de asemenea, experiență anterioară de lucru cu mari parteneri la AWS, unde a lucrat ca arhitect de soluții pentru succes pentru parteneri pentru clienții nativi digitali.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Capabil
- Despre Noi
- acces
- accesate
- Conturi
- Obține
- Acțiune
- acțiuni
- Acte
- adăuga
- Suplimentar
- adjunct
- venire
- împotriva
- AI
- AI / ML
- TOATE
- permite
- de-a lungul
- de asemenea
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- Google Analytics
- și
- O alta
- răspunde
- telefonic
- răspunsuri
- Orice
- api
- Aplică
- abordare
- abordari
- arhitectură
- SUNT
- AS
- cere
- Asistent
- asociate
- At
- audio
- augmented
- AUTH
- disponibil
- evita
- AWS
- Formarea AWS Cloud
- bazat
- BE
- fost
- Mai bine
- între
- Miliard
- corp
- construi
- Clădire
- construit
- afaceri
- by
- CAN
- capacități
- capacitate
- capturi
- celulă
- si-a schimbat hainele;
- taxe
- Alege
- alegere
- client
- cod
- colectare
- colecții
- colector
- Coloană
- combinaţie
- combinând
- comentarii
- Comun
- Companii
- comparabil
- comparaţie
- comparație
- Completă
- Terminat
- componente
- concept
- conferințe
- Configuraţie
- configurat
- constă
- Consoleze
- conţine
- conținute
- conține
- conţinut
- crearea de continut
- converti
- convertit
- de conversie a
- Corespunzător
- ar putea
- acoperă
- crea
- a creat
- creează
- Crearea
- creaţie
- scrisori de acreditare
- client
- clienţii care
- Dallas
- tablou de bord
- tablouri de bord
- de date
- Analiza datelor
- știința datelor
- Baza de date
- deceniu
- punte
- Mod implicit
- livra
- Oferă
- demonstra
- În funcție
- implementa
- dislocate
- Implementarea
- implementează
- descrie
- Amenajări
- proiectat
- detaliu
- detaliat
- detalii
- diagramă
- DICT
- FĂCUT
- diferenţă
- diferit
- difuziune
- digital
- Dimensiune
- Dimensiuni
- descoperi
- discutat
- Afişa
- do
- documente
- face
- domenii
- Descarca
- download-uri
- în timpul
- e
- fiecare
- element
- încorporat
- Încorporarea
- permite
- activat
- codificat
- încuraja
- capăt
- Punct final
- Motor
- asigura
- Afacere
- clienții întreprinderii
- eroare
- Eter (ETH)
- eveniment
- evenimente
- examinator
- exemplu
- Cu excepția
- excepție
- există
- experienţă
- Explorarea
- extinde
- extern
- extrage
- Familiaritate
- Domenii
- Fișier
- Fişiere
- financiar
- Servicii financiare
- Găsi
- se concentrează
- urma
- următor
- urmează
- Pentru
- formă
- format
- Fundație
- patru
- Gratuit
- din
- Complet
- complet
- viitor
- genera
- generată
- generează
- generaţie
- generativ
- AI generativă
- georgetown
- obține
- GitHub
- merge
- grafice
- îndrumare
- Avea
- he
- util
- ajutor
- aici
- Ascuns
- superior
- hit-uri
- gazdă
- găzduit
- găzduire
- Gazdele
- Cum
- Totuși
- HTML
- http
- HTTPS
- Butuc
- Față îmbrățișată
- i
- IAM
- Identitate
- if
- ilustrează
- imagine
- imagini
- imediat
- punerea în aplicare a
- implementarea
- ustensile
- in
- include
- include
- Inclusiv
- index
- Indici
- informații
- Inovaţie
- inovații
- intrare
- instanță
- cazuri
- instrucțiuni
- interacţiona
- interacţiune
- intern
- în
- investiţie
- IT
- aderarea
- jpg
- JSON
- iunie
- limbă
- mare
- Latență
- lansa
- AFLAȚI
- învăţare
- lector
- ca
- LINK
- Lamă
- local
- LOWER
- maşină
- masina de învățare
- face
- administra
- gestionate
- multe
- Meci
- potrivire
- mecanism
- Meniu
- Metadata
- metodă
- ML
- modalități
- model
- Modele
- mai mult
- cele mai multe
- MS
- multiplu
- nume
- nativ
- Navigaţi
- Navigare
- Nevoie
- Nou
- Nici unul
- nota
- caiet
- notebook-uri
- notificări
- acum
- numerotat
- numere
- obiecte
- of
- oferi
- on
- La cerere
- ONE
- afară
- deschide
- open-source
- or
- organizație
- OS
- al nostru
- afară
- rezultate
- producție
- peste
- pâine
- parametru
- parametrii
- parte
- particulă
- partener
- parteneri
- piese
- Trecut
- pasionat
- cale
- pentru
- efectua
- performanță
- efectuată
- permisiuni
- perspective
- fază
- Fizică
- poze
- conducte
- Plato
- Informații despre date Platon
- PlatoData
- Politicile
- Post
- postări
- potenţial
- putere
- puternic
- Predictor
- prezenta
- prezentat
- precedent
- anterior
- proces
- prelucrate
- procese
- prelucrare
- Program
- proprietăţi
- furniza
- prevăzut
- furnizează
- furnizarea
- pune
- Quarcurile
- interogări
- întrebare
- întrebare
- Întrebări
- Rapid
- cârpă
- gamă
- repede
- Citind
- gata
- lumea reală
- primit
- referință
- regiune
- legate de
- rămâne
- înlocui
- solicita
- necesar
- Resurse
- Răspunde
- răspuns
- răspunsuri
- rezultat
- rezultând
- REZULTATE
- regăsire
- reveni
- Bogat
- rolurile
- Alerga
- funcţionare
- sagemaker
- SageMaker Inference
- acelaşi
- Spune
- Scară
- Ştiinţă
- capturi de ecran
- scenariu
- Caută
- Al doilea
- Secțiune
- secțiuni
- sector
- vedea
- selecta
- selectarea
- senior
- Secvenţă
- serie
- serverless
- servește
- serviciu
- Servicii
- sesiune
- Seturi
- instalare
- setări
- Distribuie
- ea
- să
- indicat
- Emisiuni
- asemănător
- simplu
- pur şi simplu
- singur
- Mărimea
- Diapozitiv
- Diapozitive
- fragment
- So
- soluţie
- soluţii
- unele
- Sursă
- specialist
- specific
- specificată
- stabil
- stivui
- lansare
- Stat
- Stare
- Pas
- paşi
- depozitare
- stoca
- stocate
- magazine
- Strategic
- Şir
- ulterior
- succes
- Reușit
- astfel de
- Summit-ul
- De sprijin
- sigur
- tabel
- Lua
- Vorbi
- sarcini
- Tehnic
- Tehnologia
- șablon
- şabloane
- test
- teste
- Texas
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- textual
- acea
- informațiile
- lor
- apoi
- Acestea
- acest
- aceste
- debit
- timp
- gigant
- cu denumirea
- la
- azi
- împreună
- Toronto
- tradiţional
- traversa
- declanşa
- declanșând
- adevărat
- încerca
- ÎNTORCĂ
- Două
- tip
- descoperi
- înţelege
- înţelegere
- universitate
- Actualizează
- încărcat
- URL-ul
- utilizare
- utilizat
- Utilizator
- utilizări
- folosind
- valoare
- variabil
- varietate
- versiune
- de
- Video
- Vizualizare
- viziune
- vizual
- Washington
- modalități de
- we
- web
- servicii web
- BINE
- Ce
- Ce este
- care
- în timp ce
- voi
- cu
- în
- a lucrat
- flux de lucru
- de lucru
- tu
- Ta
- zephyrnet