În această postare, demonstrăm cum să folosim tăierea structurală bazată pe căutarea arhitecturii neuronale (NAS) pentru a comprima un model BERT ajustat pentru a îmbunătăți performanța modelului și a reduce timpii de inferență. Modelele lingvistice pre-instruite (PLM) sunt în curs de adoptare rapidă comercială și de întreprindere în domeniile instrumentelor de productivitate, serviciului clienți, căutării și recomandărilor, automatizării proceselor de afaceri și creării de conținut. Implementarea punctelor finale de inferență PLM este de obicei asociată cu o latență mai mare și cu costuri de infrastructură mai mari datorită cerințelor de calcul și eficienței de calcul reduse din cauza numărului mare de parametri. Tunderea unui PLM reduce dimensiunea și complexitatea modelului, păstrând în același timp capacitățile sale de predicție. PLM-urile tăiate realizează o amprentă de memorie mai mică și o latență mai mică. Demonstrăm că prin tăierea unui PLM și schimbând numărul de parametri și eroarea de validare pentru o anumită sarcină țintă și suntem capabili să obținem timpi de răspuns mai rapid în comparație cu modelul PLM de bază.
Optimizarea multi-obiectivă este o zonă de luare a deciziilor care optimizează mai mult de o funcție obiectivă, cum ar fi consumul de memorie, timpul de antrenament și resursele de calcul, pentru a fi optimizate simultan. Tăierea structurală este o tehnică de reducere a dimensiunii și cerințelor de calcul ale PLM prin tăierea straturilor sau a neuronilor/nodurilor, încercând în același timp să păstreze acuratețea modelului. Prin îndepărtarea straturilor, tăierea structurală realizează rate de compresie mai mari, ceea ce duce la o structura structurată prietenoasă cu hardware-ul care reduce timpii de rulare și timpii de răspuns. Aplicarea unei tehnici de tăiere structurală la un model PLM are ca rezultat un model mai ușor, cu o amprentă de memorie mai mică, care, atunci când este găzduit ca punct final de inferență în SageMaker, oferă o eficiență îmbunătățită a resurselor și costuri reduse în comparație cu PLM-ul original reglat fin.
Conceptele ilustrate în această postare pot fi aplicate aplicațiilor care utilizează funcții PLM, cum ar fi sistemele de recomandare, analiza sentimentelor și motoarele de căutare. Mai exact, puteți utiliza această abordare dacă aveți echipe dedicate de învățare automată (ML) și știință a datelor care își ajustează propriile modele PLM utilizând seturi de date specifice domeniului și implementează un număr mare de puncte finale de inferență folosind Amazon SageMaker. Un exemplu este un comerciant online care implementează un număr mare de puncte finale de inferență pentru rezumarea textului, clasificarea catalogului de produse și clasificarea sentimentului de feedback despre produs. Un alt exemplu ar putea fi un furnizor de asistență medicală care utilizează puncte finale de inferență PLM pentru clasificarea documentelor clinice, recunoașterea entității numite din rapoartele medicale, chatbot-uri medicale și stratificarea riscului pentru pacient.
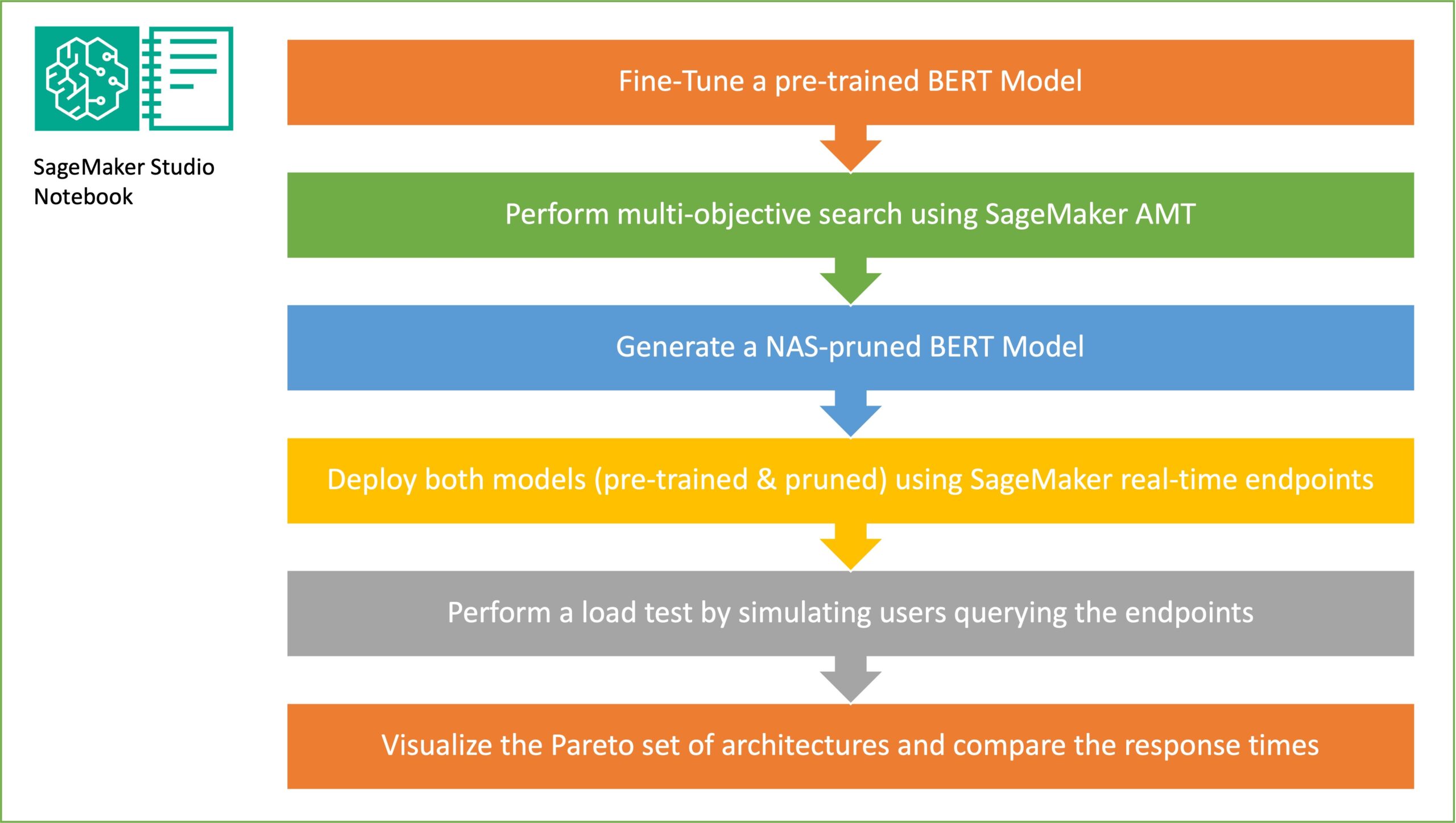
Prezentare generală a soluțiilor
În această secțiune, prezentăm fluxul de lucru general și explicăm abordarea. În primul rând, folosim un Amazon SageMaker Studio caiet pentru a regla fin un model BERT pre-antrenat pe o sarcină țintă folosind un set de date specific domeniului. OARET (Reprezentările codificatorului bidirecțional de la Transformers) este un model de limbaj pre-antrenat bazat pe arhitectura transformatorului utilizat pentru sarcini de procesare a limbajului natural (NLP). Căutarea în arhitectură neuronală (NAS) este o abordare pentru automatizarea proiectării rețelelor neuronale artificiale și este strâns legată de optimizarea hiperparametrului, o abordare utilizată pe scară largă în domeniul învățării automate. Scopul NAS este să găsească arhitectura optimă pentru o anumită problemă prin căutarea într-un set mare de arhitecturi candidate folosind tehnici precum optimizarea fără gradient sau prin optimizarea metricilor dorite. Performanța arhitecturii este de obicei măsurată folosind metrici precum pierderea de validare. Reglarea automată a modelului SageMaker (AMT) automatizează procesul obositor și complex de găsire a combinațiilor optime de hiperparametri ai modelului ML care oferă cea mai bună performanță a modelului. AMT utilizează algoritmi de căutare inteligenți și evaluări iterative folosind o serie de hiperparametri pe care îi specificați. Alege valorile hiperparametrului care creează un model care are cele mai bune performanțe, măsurate prin valorile de performanță, cum ar fi acuratețea și scorul F-1.
Abordarea de reglare fină descrisă în această postare este generică și poate fi aplicată oricărui set de date bazat pe text. Sarcina atribuită BERT PLM poate fi o sarcină bazată pe text, cum ar fi analiza sentimentelor, clasificarea textului sau întrebări și răspunsuri. În această demonstrație, sarcina țintă este o problemă de clasificare binară în care BERT este utilizat pentru a identifica, dintr-un set de date care constă dintr-o colecție de perechi de fragmente de text, dacă semnificația unui fragment de text poate fi dedusă din celălalt fragment. Noi folosim Recunoașterea setului de date de implicare textuală din suita de benchmarking GLUE. Efectuăm o căutare multi-obiectivă folosind SageMaker AMT pentru a identifica subrețelele care oferă compromisuri optime între numărul de parametri și acuratețea predicției pentru sarcina țintă. Atunci când efectuăm o căutare cu mai multe obiective, începem cu definirea preciziei și a numărului de parametri ca obiective pe care ne propunem să le optimizăm.
În cadrul rețelei BERT PLM, pot exista subrețele modulare, autonome, care permit modelului să aibă capabilități specializate, cum ar fi înțelegerea limbajului și reprezentarea cunoștințelor. BERT PLM utilizează o subrețea de auto-atenție cu mai multe capete și o subrețea de tip feed-forward. Un strat de auto-atenție cu mai multe capete permite BERT să relaționeze diferite poziții ale unei singure secvențe pentru a calcula o reprezentare a secvenței, permițând mai multor capete să se ocupe de mai multe semnale de context. Intrarea este împărțită în mai multe subspații și autoatenția este aplicată fiecăruia dintre subspații separat. Mai multe capete dintr-un transformator PLM permit modelului să se ocupe în comun de informații din diferite subspații de reprezentare. O subrețea de tip feed-forward este o rețea neuronală simplă care preia ieșirea din subrețeaua de auto-atenție cu mai multe capete, procesează datele și returnează reprezentările finale ale codificatorului.
Scopul eșantionării aleatorii în subrețea este de a antrena modele BERT mai mici care pot funcționa suficient de bine în sarcinile țintă. Eșantionăm 100 de subrețele aleatorii din modelul de bază BERT reglat și evaluăm 10 rețele simultan. Subrețelele antrenate sunt evaluate pentru metricile obiective, iar modelul final este ales pe baza compromisurilor găsite între metricile obiective. Vizualizam Frontul Pareto pentru subrețelele eșantionate, care conține modelul tăiat care oferă compromisul optim între acuratețea modelului și dimensiunea modelului. Selectăm subrețeaua candidată (modelul BERT tăiat prin NAS) în funcție de dimensiunea și acuratețea modelului pe care suntem dispuși să o schimbăm. Apoi, găzduim punctele finale, modelul de bază BERT pre-antrenat și modelul BERT tăiat de NAS folosind SageMaker. Pentru a efectua testarea de sarcină, folosim roșcov, un instrument open source de testare a încărcării pe care îl puteți implementa folosind Python. Executăm teste de încărcare pe ambele puncte finale folosind Locust și vizualizăm rezultatele folosind frontul Pareto pentru a ilustra compromisul dintre timpii de răspuns și precizie pentru ambele modele. Următoarea diagramă oferă o privire de ansamblu asupra fluxului de lucru explicat în această postare.
Cerințe preliminare
Pentru această postare sunt necesare următoarele condiții preliminare:
De asemenea, trebuie să măriți cota de serviciu pentru a accesa cel puțin trei instanțe de ml.g4dn.xlarge în SageMaker. Tipul de instanță ml.g4dn.xlarge este instanța GPU rentabilă care vă permite să rulați PyTorch nativ. Pentru a crește cota de servicii, parcurgeți următorii pași:
- Pe consolă, navigați la Cote de servicii.
- Pentru Gestionați cotele, alege Amazon SageMaker, Apoi alegeți Vedeți cotele.

- Căutați „ml-g4dn.xlarge for training job usage” și selectați elementul de cotă.
- Alege Solicitați o creștere la nivel de cont.
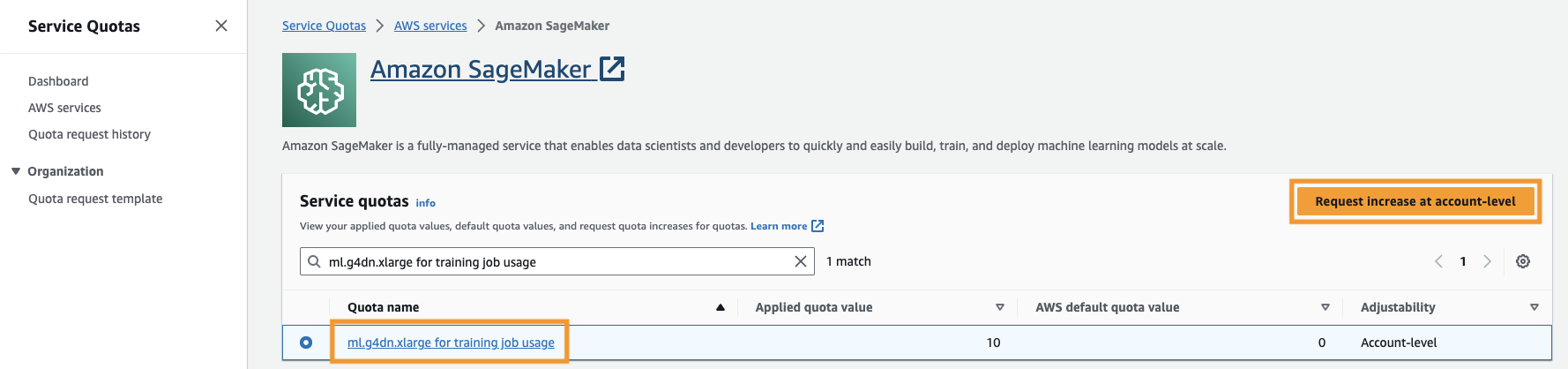
- Pentru Creșteți valoarea cotei, introduceți o valoare de 5 sau mai mare.
- Alege Cerere.
Finalizarea aprobării cotei solicitate poate dura ceva timp, în funcție de permisiunile contului.

- Deschideți SageMaker Studio din consola SageMaker.

- Alege Terminal de sistem în Utilități și fișiere.

- Rulați următoarea comandă pentru a clona GitHub repo la instanța SageMaker Studio:
- Navigheaza catre
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Deschideți fișierul
nas_for_llm_with_amt.ipynb. - Configurați mediul cu un
ml.g4dn.xlargeinstanță și alegeți Selectați.

Configurați modelul BERT pre-antrenat
În această secțiune, importăm setul de date Recognizing Textual Entailment din biblioteca setului de date și împărțim setul de date în seturi de instruire și validare. Acest set de date este format din perechi de propoziții. Sarcina PLM BERT este să recunoască, având în vedere două fragmente de text, dacă semnificația unui fragment de text poate fi dedusă din celălalt fragment. În exemplul următor, putem deduce semnificația primei fraze din a doua frază:
Încărcăm setul de date de implicare a recunoașterii textului din GLUE suita de benchmarking prin intermediul biblioteca de seturi de date din Hugging Face în scenariul nostru de antrenament (./training.py). Am împărțit setul de date de antrenament original de la GLUE într-un set de instruire și validare. În abordarea noastră, reglam fin modelul BERT de bază folosind setul de date de antrenament, apoi efectuăm o căutare multi-obiectivă pentru a identifica setul de subrețele care echilibrează optim între metricile obiective. Folosim setul de date de antrenament exclusiv pentru reglarea fină a modelului BERT. Cu toate acestea, folosim date de validare pentru căutarea cu mai multe obiective prin măsurarea acurateței setului de date de validare holdout.
Reglați fin PLM-ul BERT folosind un set de date specific domeniului
Cazurile de utilizare tipice pentru un model brut BERT includ predicția următoarei propoziții sau modelarea limbajului mascat. Pentru a utiliza modelul BERT de bază pentru sarcini din aval, cum ar fi implicarea recunoașterii textuale, trebuie să reglam în continuare modelul folosind un set de date specific domeniului. Puteți utiliza un model BERT ajustat pentru sarcini precum clasificarea secvenței, răspunsul la întrebări și clasificarea token-ului. Cu toate acestea, în scopul acestei demonstrații, folosim modelul ajustat pentru clasificarea binară. Ajustăm modelul BERT pre-antrenat cu setul de date de antrenament pe care l-am pregătit anterior, folosind următorii hiperparametri:
Salvăm punctul de control al antrenamentului model într-un Serviciul Amazon de stocare simplă (Amazon S3), astfel încât modelul să poată fi încărcat în timpul căutării multi-obiective bazate pe NAS. Înainte de a antrena modelul, definim metrici precum epoca, pierderea antrenamentului, numărul de parametri și eroarea de validare:
După începerea procesului de reglare fină, procesul de antrenament durează aproximativ 15 minute.
Efectuați o căutare cu mai multe obiective pentru a selecta subrețele și a vizualiza rezultatele
În pasul următor, efectuăm o căutare multi-obiectivă pe modelul de bază BERT reglat fin prin eșantionarea subrețelelor aleatoare folosind SageMaker AMT. Pentru a accesa o sub-rețea din cadrul super-rețelei (modelul BERT ajustat), mascam toate componentele PLM care nu fac parte din sub-rețea. Mascarea unei super-rețele pentru a găsi subrețele într-un PLM este o tehnică folosită pentru a izola și a identifica modele de comportament ale modelului. Rețineți că transformatoarele Hugging Face trebuie ca dimensiunea ascunsă să fie un multiplu al numărului de capete. Dimensiunea ascunsă într-un PLM transformator controlează dimensiunea spațiului vectorial de stare ascuns, ceea ce afectează capacitatea modelului de a învăța reprezentări și modele complexe în date. Într-un PLM BERT, vectorul de stare ascuns are o dimensiune fixă (768). Nu putem modifica dimensiunea ascunsă și, prin urmare, numărul de capete trebuie să fie în [1, 3, 6, 12].
Spre deosebire de optimizarea cu un singur obiectiv, în contextul cu mai multe obiective, de obicei nu avem o singură soluție care să optimizeze simultan toate obiectivele. În schimb, ne propunem să colectăm un set de soluții care domină toate celelalte soluții în cel puțin un obiectiv (cum ar fi eroarea de validare). Acum putem începe căutarea multi-obiective prin AMT setând metricile pe care dorim să le reducem (eroarea de validare și numărul de parametri). Subrețelele aleatoare sunt definite de parametru max_jobs iar numărul de joburi simultane este definit de parametru max_parallel_jobs. Codul pentru a încărca punctul de control al modelului și pentru a evalua subrețeaua este disponibil în evaluate_subnetwork.py script-ul.
Lucrarea de reglare AMT durează aproximativ 2 ore și 20 de minute. După ce jobul de reglare AMT rulează cu succes, analizăm istoricul jobului și colectăm configurațiile sub-rețelei, cum ar fi numărul de capete, numărul de straturi, numărul de unități și valorile corespunzătoare, cum ar fi eroarea de validare și numărul de parametri. Următoarea captură de ecran arată rezumatul unei lucrări de tuner AMT de succes.
În continuare, vizualizăm rezultatele utilizând o mulțime Pareto (cunoscută și ca frontieră Pareto sau mulțime optimă Pareto), care ne ajută să identificăm seturi optime de subrețele care domină toate celelalte subrețele în metrica obiectivă (eroare de validare):
În primul rând, colectăm datele din jobul de reglare AMT. Apoi trasăm setul Pareto folosind matplotlob.pyplot cu număr de parametri pe axa x și eroare de validare pe axa y. Aceasta implică faptul că atunci când trecem de la o subrețea a setului Pareto la alta, trebuie fie să sacrificăm performanța, fie dimensiunea modelului, dar să o îmbunătățim pe cealaltă. În cele din urmă, setul Pareto ne oferă flexibilitatea de a alege subrețeaua care se potrivește cel mai bine preferințelor noastre. Putem decide cât de mult dorim să reducem dimensiunea rețelei noastre și câte performanțe suntem dispuși să sacrificăm.

Implementați modelul BERT reglat fin și modelul de subrețea optimizat pentru NAS folosind SageMaker
Apoi, implementăm cel mai mare model din setul nostru Pareto care duce la cea mai mică cantitate de degenerare a performanței la un Punct final SageMaker. Cel mai bun model este cel care oferă un compromis optim între eroarea de validare și numărul de parametri pentru cazul nostru de utilizare.
Compararea modelului
Am luat un model BERT de bază pregătit în prealabil, l-am ajustat folosind un set de date specific domeniului, am efectuat o căutare NAS pentru a identifica subrețele dominante pe baza valorilor obiective și am implementat modelul tăiat pe un punct final SageMaker. În plus, am luat modelul de bază BERT pre-antrenat și am implementat modelul de bază pe un al doilea punct final SageMaker. Apoi, am fugit testarea la sarcină folosind Locust pe ambele puncte finale de inferență și a evaluat performanța în termeni de timp de răspuns.
Mai întâi, importăm bibliotecile necesare Locust și Boto3. Apoi construim metadatele cererii și înregistrăm ora de începere care va fi folosită pentru testarea încărcării. Apoi, sarcina utilă este transmisă API-ului de invocare a punctului final SageMaker prin BotoClient pentru a simula cererile reale ale utilizatorilor. Folosim Locust pentru a genera mai mulți utilizatori virtuali pentru a trimite cereri în paralel și pentru a măsura performanța punctului final sub sarcină. Testele sunt efectuate prin creșterea numărului de utilizatori pentru fiecare dintre cele două puncte finale, respectiv. După ce testele sunt finalizate, Locust emite un fișier CSV cu statistici de solicitare pentru fiecare dintre modelele implementate.
În continuare, generăm graficele timpului de răspuns din fișierele CSV descărcate după rularea testelor cu Locust. Scopul trasării timpului de răspuns față de numărul de utilizatori este de a analiza rezultatele testării de încărcare prin vizualizarea impactului timpului de răspuns al punctelor finale ale modelului. În graficul următor, putem vedea că punctul final al modelului tăiat de NAS realizează un timp de răspuns mai mic în comparație cu punctul final al modelului BERT de bază.
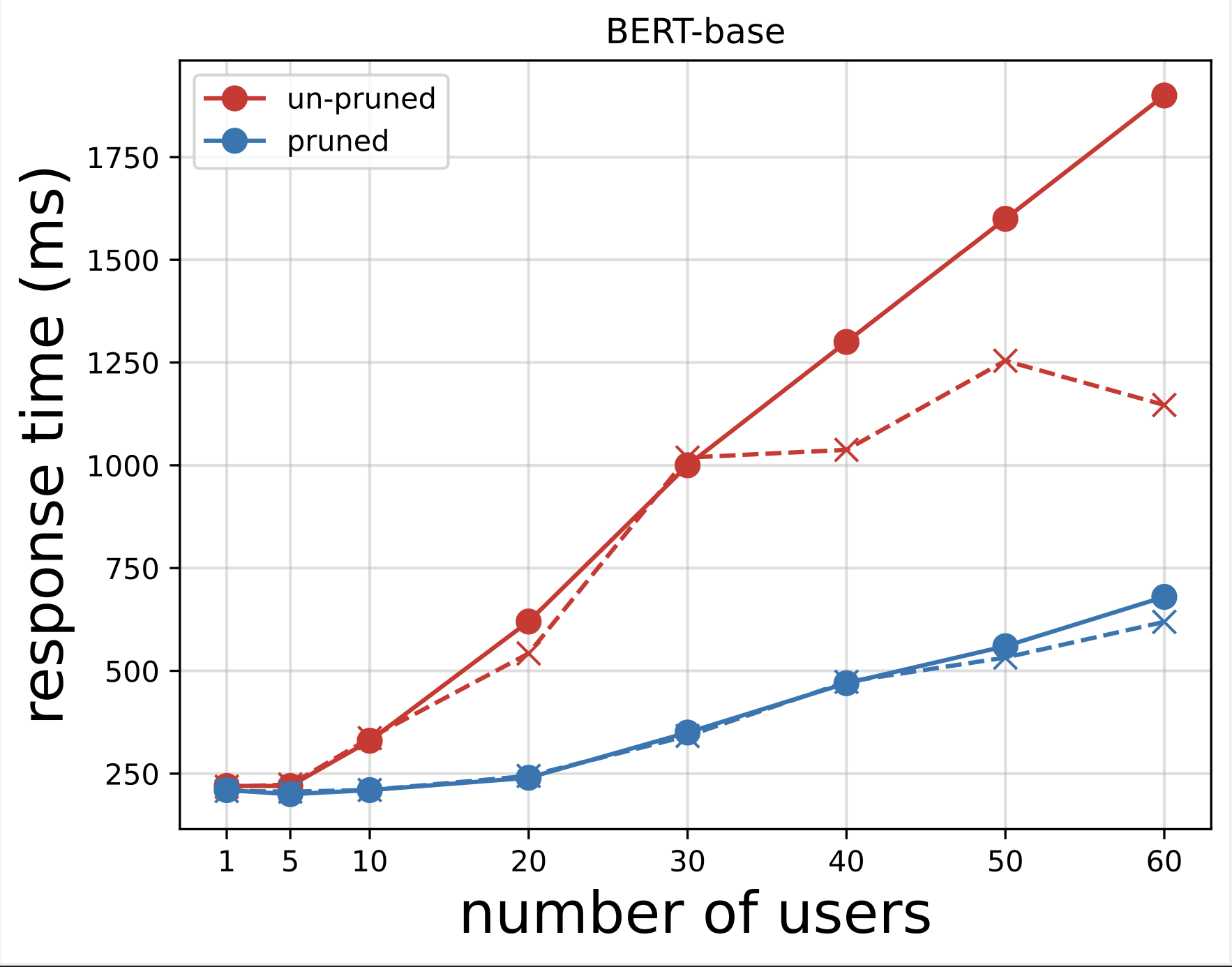
În cea de-a doua diagramă, care este o extensie a primei diagrame, observăm că după aproximativ 70 de utilizatori, SageMaker începe să reducă punctul final al modelului BERT de bază și aruncă o excepție. Cu toate acestea, pentru punctul final al modelului tăiat de NAS, limitarea are loc între 90-100 de utilizatori și cu un timp de răspuns mai mic.

Din cele două grafice, observăm că modelul tăiat are un timp de răspuns mai rapid și se scalează mai bine în comparație cu modelul netăiat. Pe măsură ce creștem numărul de puncte finale de inferență, așa cum este cazul utilizatorilor care implementează un număr mare de puncte finale de inferență pentru aplicațiile lor PLM, beneficiile legate de costuri și îmbunătățirea performanței încep să devină destul de substanțiale.
A curăța
Pentru a șterge punctele finale SageMaker pentru modelul BERT de bază reglat fin și modelul tăiat prin NAS, parcurgeți următorii pași:
- Pe consola SageMaker, alegeți deducție și Puncte finale în panoul de navigare.
- Selectați punctul final și ștergeți-l.
Ca alternativă, din blocnotesul SageMaker Studio, rulați următoarele comenzi furnizând numele punctelor finale:
Concluzie
În această postare, am discutat despre cum să folosiți NAS pentru a tăia un model BERT reglat fin. Am antrenat mai întâi un model BERT de bază folosind date specifice domeniului și l-am implementat într-un punct final SageMaker. Am efectuat o căutare multi-obiectivă pe modelul de bază BERT reglat cu ajutorul SageMaker AMT pentru o sarcină țintă. Am vizualizat frontul Pareto și am selectat modelul BERT optimizat Pareto NAS și am implementat modelul la un al doilea punct final SageMaker. Am efectuat testarea de încărcare folosind Locust pentru a simula utilizatorii care interoghează ambele puncte finale și am măsurat și înregistrat timpii de răspuns într-un fișier CSV. Am trasat timpul de răspuns în funcție de numărul de utilizatori pentru ambele modele.
Am observat că modelul BERT tăiat a funcționat semnificativ mai bine atât în timpul de răspuns, cât și în pragul de accelerare a instanțelor. Am ajuns la concluzia că modelul tăiat prin NAS a fost mai rezistent la o sarcină crescută la punctul final, menținând un timp de răspuns mai mic chiar dacă mai mulți utilizatori au subliniat sistemul în comparație cu modelul BERT de bază. Puteți aplica tehnica NAS descrisă în această postare oricărui model de limbă mare pentru a găsi un model tăiat care poate îndeplini sarcina țintă cu un timp de răspuns semnificativ mai mic. Puteți optimiza și mai mult abordarea utilizând latența ca parametru în plus față de pierderea de validare.
Deși folosim NAS în această postare, cuantizarea este o altă abordare comună folosită pentru optimizarea și comprimarea modelelor PLM. Cuantizarea reduce precizia greutăților și activărilor într-o rețea antrenată de la virgulă mobilă de 32 de biți la lățimi mai mici de biți, cum ar fi numere întregi de 8 biți sau 16 biți, ceea ce are ca rezultat un model comprimat care generează o inferență mai rapidă. Cuantizarea nu reduce numărul de parametri; în schimb, reduce precizia parametrilor existenți pentru a obține un model comprimat. Eliminarea NAS elimină rețelele redundante dintr-un PLM, ceea ce creează un model rar cu mai puțini parametri. De obicei, tăierea și cuantizarea NAS sunt utilizate împreună pentru a comprima PLM-urile mari pentru a menține acuratețea modelului, a reduce pierderile de validare, îmbunătățind în același timp performanța și a reduce dimensiunea modelului. Celelalte tehnici utilizate în mod obișnuit pentru a reduce dimensiunea PLM-urilor includ distilare a cunoștințelor, factorizarea matriceală, și cascade de distilare.
Abordarea propusă în postarea de blog este potrivită pentru echipele care folosesc SageMaker pentru a antrena și a ajusta modelele folosind date specifice domeniului și pentru a implementa punctele finale pentru a genera inferențe. Dacă sunteți în căutarea unui serviciu complet gestionat care să ofere o gamă de modele de fundație de înaltă performanță necesare pentru a construi aplicații AI generative, luați în considerare utilizarea Amazon Bedrock. Dacă sunteți în căutarea unor modele open source pregătite în prealabil pentru o gamă largă de cazuri de utilizare în afaceri și doriți să accesați șabloane de soluții și exemple de notebook-uri, luați în considerare utilizarea Amazon SageMaker JumpStart. O versiune pre-antrenată a modelului de bază Hugging Face BERT pe care l-am folosit în această postare este disponibilă și de la SageMaker JumpStart.
Despre Autori
 Aparajithan Vaidyanathan este arhitect principal de soluții pentru întreprinderi la AWS. Este un arhitect cloud cu peste 24 de ani de experiență în proiectarea și dezvoltarea de sisteme software pentru întreprinderi, la scară largă și distribuite. El este specializat în IA generativă și ingineria datelor de învățare automată. Este un aspirant la maraton, iar hobby-urile sale includ drumeții, plimbări cu bicicleta și petrecerea timpului cu soția și cei doi băieți.
Aparajithan Vaidyanathan este arhitect principal de soluții pentru întreprinderi la AWS. Este un arhitect cloud cu peste 24 de ani de experiență în proiectarea și dezvoltarea de sisteme software pentru întreprinderi, la scară largă și distribuite. El este specializat în IA generativă și ingineria datelor de învățare automată. Este un aspirant la maraton, iar hobby-urile sale includ drumeții, plimbări cu bicicleta și petrecerea timpului cu soția și cei doi băieți.
 Aaron Klein este un om de știință senior aplicat la AWS care lucrează la metode automate de învățare automată pentru rețele neuronale profunde.
Aaron Klein este un om de știință senior aplicat la AWS care lucrează la metode automate de învățare automată pentru rețele neuronale profunde.
 Jacek Golebiowski este om de știință aplicat la AWS.
Jacek Golebiowski este om de știință aplicat la AWS.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :are
- :este
- :nu
- :Unde
- ][p
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- capacitate
- Capabil
- acces
- Cont
- precizie
- Obține
- Realizeaza
- activări
- plus
- Adoptare
- După
- AI
- urmări
- Urmarind
- algoritmi
- TOATE
- permite
- Permiterea
- permite
- de asemenea
- Amazon
- Amazon Web Services
- sumă
- an
- analiză
- Google Analytics
- analiza
- și
- O alta
- telefonic
- Orice
- api
- aplicatii
- aplicat
- Aplică
- Aplicarea
- abordare
- aprobare
- aproximativ
- arhitectură
- SUNT
- ZONĂ
- domenii
- argumente
- în jurul
- artificial
- rețele neuronale artificiale
- AS
- aspirant
- alocate
- asociate
- At
- încercarea
- asista la
- Automata
- învățare automată automată
- automate
- Automat
- automatizarea
- Automatizare
- disponibil
- AWS
- Axă
- Sold
- de bază
- bazat
- BE
- deveni
- înainte
- comportament
- analiza comparativă
- Beneficiile
- CEL MAI BUN
- Mai bine
- între
- Pic
- corp
- atât
- construi
- afaceri
- Procesul de afaceri
- Automatizarea proceselor de afaceri
- dar
- by
- CAN
- candidat
- capacități
- caz
- cazuri
- catalog
- Schimbare
- Diagramă
- Grafice
- chatbots
- alegere
- Alege
- ales
- clasă
- clasificare
- clinic
- îndeaproape
- Cloud
- cod
- colecta
- colectare
- combinaţii
- comercial
- Comun
- în mod obișnuit
- comparație
- Completă
- Terminat
- complex
- complexitate
- componente
- de calcul
- Calcula
- Concepte
- încheiat
- Lua în considerare
- constă
- Consoleze
- constrângeri
- construi
- consum
- conține
- conţinut
- crearea de continut
- context
- continua
- contrast
- controale
- Corespunzător
- A costat
- Cheltuieli
- conta
- crea
- creează
- creaţie
- client
- Serviciu clienți
- de date
- știința datelor
- seturi de date
- datetime
- decide
- Luarea deciziilor
- dedicat
- adânc
- rețele neuronale profunde
- defini
- definit
- definire
- Demo
- demonstra
- În funcție
- implementa
- dislocate
- Implementarea
- implementează
- descris
- Amenajări
- proiect
- dorit
- în curs de dezvoltare
- diferit
- discutat
- distribuite
- document
- Nu
- dominant
- domina
- Dont
- două
- în timpul
- e
- fiecare
- eficiență
- eficient
- oricare
- Punct final
- Obiective
- Inginerie
- Motoare
- suficient de
- Intrați
- Afacere
- adoptarea întreprinderii
- Soluții pentru întreprinderi
- entitate
- intrare
- Mediu inconjurator
- epocă
- eroare
- Eter (ETH)
- evalua
- evaluat
- evaluări
- Chiar
- evenimente
- exemplu
- Cu excepția
- excepție
- exclusiv
- existent
- experienţă
- Explica
- a explicat
- extensie
- Față
- fals
- mai repede
- DESCRIERE
- feedback-ul
- mai puține
- camp
- Fișier
- Fişiere
- final
- Găsi
- descoperire
- First
- fixată
- Flexibilitate
- plutitor
- următor
- urmă
- Pentru
- găsit
- Fundație
- din
- faţă
- Frontieră
- complet
- funcţie
- mai mult
- genera
- generează
- generativ
- AI generativă
- obține
- dat
- scop
- GPU
- gri
- se întâmplă
- Avea
- he
- cap
- capete
- de asistență medicală
- ajută
- Ascuns
- performanta inalta
- superior
- drumeții
- lui
- istorie
- hobby-uri
- gazdă
- găzduit
- ORE
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- Față îmbrățișată
- Optimizarea hiperparametrului
- Reglarea hiperparametrului
- i
- identifica
- idx
- if
- ilustra
- Impactul
- Impacturi
- punerea în aplicare a
- import
- îmbunătăţi
- îmbunătățit
- îmbunătățire
- îmbunătățirea
- in
- include
- Crește
- a crescut
- crescând
- informații
- Infrastructură
- intrare
- instanță
- cazuri
- in schimb
- Inteligent
- în
- IT
- ESTE
- Loc de munca
- Locuri de munca
- jpg
- JSON
- cunoştinţe
- cunoscut
- limbă
- mare
- pe scară largă
- cea mai mare
- Latență
- strat
- straturi
- Conduce
- AFLAȚI
- învăţare
- cel mai puțin
- lăsa
- biblioteci
- Bibliotecă
- Linie
- încărca
- log
- logare
- cautati
- de pe
- pierderi
- LOWER
- maşină
- masina de învățare
- menține
- mentine
- om
- gestionate
- Maraton
- masca
- matplotlib
- maxim
- Mai..
- sens
- măsura
- măsurat
- măsurare
- medical
- Întâlni
- Memorie
- Metadata
- Metode
- metric
- Metrici
- ar putea
- minimaliza
- minute
- ML
- model
- modelare
- Modele
- modular
- mai mult
- muta
- mult
- multiplu
- trebuie sa
- nume
- Numit
- nume
- la
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Navigaţi
- Navigare
- necesar
- Nevoie
- necesar
- nevoilor
- reţea
- rețele
- neural
- rețele neuronale
- rețele neuronale
- următor
- nlp
- Nici unul
- nota
- caiet
- notebook-uri
- acum
- număr
- obiect
- obiectiv
- Obiectivele
- observa
- observate
- of
- de pe
- oferi
- promoții
- on
- ONE
- on-line
- retailer online
- afară
- deschide
- open-source
- optimă
- optimizare
- Optimizați
- optimizate
- Optimizează
- optimizarea
- or
- comandă
- original
- Altele
- al nostru
- afară
- producție
- iesiri
- peste
- global
- Prezentare generală
- propriu
- perechi
- pâine
- Paralel
- parametru
- parametrii
- Pareto
- parte
- Trecut
- cale
- pacient
- modele
- efectua
- performanță
- efectuată
- efectuarea
- efectuează
- permisiuni
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- puncte
- poziţii
- Post
- Precizie
- prezicere
- predictivă
- Predictor
- preferinţele
- pregătit
- premise
- prezenta
- în prealabil
- Principal
- Problemă
- proces
- Automatizarea procesului
- procese
- prelucrare
- Produs
- productivitate
- Instrumente de productivitate
- propus
- furnizorul
- furnizează
- furnizarea
- trăgând
- Trage
- scop
- scopuri
- Piton
- pirtorh
- Q & A
- întrebare
- cu totul
- aleator
- gamă
- rapid
- tarife
- Crud
- real
- recunoaştere
- recunoaște
- recunoscând
- Recomandare
- Recomandări
- record
- inregistrata
- Roșu
- reduce
- Redus
- reduce
- regres
- legate de
- Îndepărtează
- eliminarea
- Rapoarte
- reprezentare
- solicita
- solicitat
- cereri de
- necesar
- Cerinţe
- elastic
- resursă
- Resurse
- respectiv
- răspuns
- REZULTATE
- vânzător cu amănuntul
- reținere
- Returnează
- călărie
- Risc
- RÂND
- Alerga
- alergător
- funcţionare
- ruleaza
- s
- sacrificiu
- sagemaker
- SageMaker Inference
- Economisiți
- Scară
- cântare
- Ştiinţă
- Om de stiinta
- scor
- scenariu
- Caută
- Motoare de cautare
- căutare
- Al doilea
- Secțiune
- vedea
- selecta
- selectate
- SELF
- trimite
- propoziție
- sentiment
- Secvenţă
- serviciu
- Servicii
- sesiune
- set
- Seturi
- instalare
- Emisiuni
- semnalele
- semnificativ
- simplu
- simultan
- simultan
- singur
- Mărimea
- mai mici
- So
- Software
- soluţie
- soluţii
- unele
- Sursă
- Spaţiu
- Icre
- de specialitate
- specializată
- specific
- specific
- Cheltuire
- împărţi
- Începe
- începe
- Stat
- statistică
- Pas
- paşi
- depozitare
- structural
- structurat
- studio
- substanțial
- de succes
- Reușit
- astfel de
- potrivit
- suită
- REZUMAT
- sistem
- sisteme
- T
- Lua
- ia
- Ţintă
- Sarcină
- sarcini
- echipe
- tehnică
- tehnici de
- şabloane
- termeni
- Testarea
- teste
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- Clasificarea textului
- textual
- decât
- acea
- lor
- apoi
- Acolo.
- prin urmare
- Acestea
- acest
- trei
- prag
- Prin
- timp
- ori
- la
- împreună
- semn
- a luat
- instrument
- Unelte
- comerţului
- Trading
- Tren
- dresat
- Pregătire
- transformator
- transformatoare
- adevărat
- încerca
- Două
- tip
- Tipuri
- tipic
- tipic
- în cele din urmă
- în
- suferind
- înţelegere
- de unităţi
- us
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- validare
- valoare
- Valori
- versiune
- de
- Virtual
- imagina
- vs
- vrea
- a fost
- we
- web
- servicii web
- BINE
- cand
- dacă
- care
- în timp ce
- OMS
- larg
- Gamă largă
- pe larg
- soţie
- Wikipedia
- voi
- dispus
- cu
- în
- Apartamente
- flux de lucru
- de lucru
- X
- ani
- Randament
- tu
- Ta
- zephyrnet