Această postare este scrisă împreună cu Pramod Nayak, LakshmiKanth Mannem și Vivek Aggarwal de la Low Latency Group al LSEG.
Analiza costurilor de tranzacție (TCA) este utilizată pe scară largă de către comercianți, administratorii de portofoliu și brokerii pentru analize pre-tranzacționare și post-tranzacționare și îi ajută să măsoare și să optimizeze costurile tranzacției și eficacitatea strategiilor lor de tranzacționare. În această postare, analizăm diferențele dintre opțiunile licitare și cerere din Istoricul căpuțelor LSEG – PCAP setul de date folosind Amazon Athena pentru Apache Spark. Vă arătăm cum să accesați date, să definiți funcții personalizate de aplicat asupra datelor, să interogați și să filtrați setul de date și să vizualizați rezultatele analizei, totul fără a vă face griji cu privire la configurarea infrastructurii sau configurarea Spark, chiar și pentru seturi de date mari.
Context
Options Price Reporting Authority (OPRA) servește ca un procesator de informații esențial privind valorile mobiliare, colectând, consolidând și difuzând rapoarte de ultima vânzare, cotații și informații relevante pentru Opțiunile din SUA. Cu 18 burse active de opțiuni din SUA și peste 1.5 milioane de contracte eligibile, OPRA joacă un rol esențial în furnizarea de date complete de piață.
Pe 5 februarie 2024, Securities Industry Automation Corporation (SIAC) este setat să actualizeze fluxul OPRA de la 48 la 96 de canale multicast. Această îmbunătățire urmărește să optimizeze distribuția simbolurilor și utilizarea capacității liniei ca răspuns la creșterea activității de tranzacționare și a volatilității pe piața de opțiuni din SUA. SIAC a recomandat firmelor să se pregătească pentru rate de date de vârf de până la 37.3 GBiți pe secundă.
În ciuda faptului că actualizarea nu modifică imediat volumul total de date publicate, aceasta permite OPRA să disemineze datele într-un ritm semnificativ mai rapid. Această tranziție este crucială pentru a răspunde cerințelor pieței de opțiuni dinamice.
OPRA se remarcă drept unul dintre cele mai voluminoase fluxuri, cu un vârf de 150.4 miliarde de mesaje într-o singură zi în T3 2023 și o cerință de capacitate de 400 de miliarde de mesaje într-o singură zi. Captarea fiecărui mesaj este esențială pentru analiza costurilor de tranzacție, monitorizarea lichidității pieței, evaluarea strategiei de tranzacționare și cercetarea pieței.
Despre date
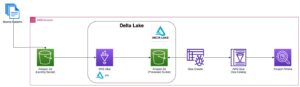
Istoricul căpuțelor LSEG – PCAP este un depozit bazat pe cloud, care depășește 30 PB, care adăpostește date de piață globală de foarte înaltă calitate. Aceste date sunt capturate cu meticulozitate direct în centrele de schimb de date, utilizând procese de captare redundante poziționate strategic în centrele de schimb de date principale și de rezervă din întreaga lume. Tehnologia de captare a LSEG asigură captarea datelor fără pierderi și folosește o sursă de timp GPS pentru precizia marcajului de timp în nanosecunde. În plus, sunt folosite tehnici sofisticate de arbitrare a datelor pentru a umple fără probleme orice goluri de date. După capturare, datele sunt supuse procesării și arbitrajului meticulos și apoi sunt normalizate în formatul Parquet folosind Ultra Direct în timp real al LSEG (RTUD) manipulatoare de furaje.
Procesul de normalizare, care este parte integrantă a pregătirii datelor pentru analiză, generează până la 6 TB de fișiere Parquet comprimate pe zi. Volumul masiv de date este atribuit naturii cuprinzătoare a OPRA, care acoperă mai multe schimburi și prezentând numeroase contracte de opțiuni caracterizate de atribute diverse. Volatilitatea crescută a pieței și activitatea de creare a pieței pe bursele de opțiuni contribuie și mai mult la volumul de date publicate pe OPRA.
Atributele Tick History – PCAP permit firmelor să efectueze diverse analize, inclusiv următoarele:
- Analiză înainte de tranzacționare – Evaluați impactul potențial al comerțului și explorați diferite strategii de execuție bazate pe date istorice
- Evaluare post-tranzacționare – Măsurați costurile reale de execuție în raport cu valorile de referință pentru a evalua performanța strategiilor de execuție
- Optimizat execuție – Ajustați strategiile de execuție pe baza modelelor istorice ale pieței pentru a minimiza impactul pe piață și a reduce costurile globale de tranzacționare
- de gestionare a riscurilor – Identificați modelele de alunecare, identificați valorile aberante și gestionați în mod proactiv riscurile asociate activităților de tranzacționare
- Atribuirea performanței – Separați impactul deciziilor de tranzacționare de deciziile de investiții atunci când analizați performanța portofoliului
Setul de date LSG Tick History – PCAP este disponibil în Schimb de date AWS și poate fi accesat pe Piața AWS. Cu AWS Data Exchange pentru Amazon S3, puteți accesa datele PCAP direct de la LSEG Serviciul Amazon de stocare simplă (Amazon S3), eliminând nevoia firmelor de a stoca propria copie a datelor. Această abordare simplifică gestionarea și stocarea datelor, oferind clienților acces imediat la PCAP de înaltă calitate sau la date normalizate cu ușurință în utilizare, integrare și economii substanțiale de stocare a datelor.
Athena pentru Apache Spark
Pentru eforturi analitice, Athena pentru Apache Spark oferă o experiență simplificată de notebook accesibilă prin consola Athena sau API-urile Athena, permițându-vă să construiți aplicații interactive Apache Spark. Cu un timp de rulare Spark optimizat, Athena ajută la analiza petaocteților de date prin scalarea dinamică a numărului de motoare Spark la mai puțin de o secundă. Mai mult, bibliotecile Python obișnuite, cum ar fi Pandas și NumPy, sunt integrate perfect, permițând crearea unei logici complexe a aplicației. Flexibilitatea se extinde la importul de biblioteci personalizate pentru utilizare în notebook-uri. Athena pentru Spark găzduiește majoritatea formatelor de date deschise și este integrat perfect cu AWS Adeziv Catalog de date.
Setul de date
Pentru această analiză, am folosit setul de date LSEG Tick History – PCAP OPRA din 17 mai 2023. Acest set de date cuprinde următoarele componente:
- Cea mai bună ofertă și ofertă (BBO) – Raportează cea mai mare ofertă și cea mai mică cerere pentru un titlu la o anumită bursă
- Cea mai bună ofertă și ofertă națională (NBBO) – Raportează cea mai mare ofertă și cea mai mică cerere pentru o valoare pe toate schimburile
- Tranzacții – Înregistrează tranzacțiile finalizate pe toate bursele
Setul de date implică următoarele volume de date:
- Tranzacții – 160 MB distribuiti în aproximativ 60 de fișiere Parquet comprimate
- BBO – 2.4 TB distribuite în aproximativ 300 de fișiere Parquet comprimate
- NBBO – 2.8 TB distribuite în aproximativ 200 de fișiere Parquet comprimate
Prezentare generală a analizei
Analiza datelor OPRA Tick History pentru Analiza costurilor de tranzacție (TCA) implică examinarea cotațiilor și tranzacțiilor de pe piață în jurul unui anumit eveniment comercial. Utilizăm următoarele valori ca parte a acestui studiu:
- spread cotat (QS) – Calculat ca diferență între cererea BBO și oferta BBO
- Răspândire efectivă (ES) – Calculat ca diferență dintre prețul de tranzacționare și punctul de mijloc al BBO (BBO bid + (BBO ask – BBO bid)/2)
- Marja efectivă/cotată (EQF) – Calculat ca (ES / QS) * 100
Calculăm aceste spread-uri înainte de tranzacționare și, suplimentar, la patru intervale după tranzacție (imediat după, 1 secundă, 10 secunde și 60 de secunde după tranzacție).
Configurați Athena pentru Apache Spark
Pentru a configura Athena pentru Apache Spark, parcurgeți următorii pași:
- Pe consola Athena, sub Incepe, Selectați Analizați-vă datele folosind PySpark și Spark SQL.
- Dacă este prima dată când utilizați Athena Spark, alegeți Creați un grup de lucru.

- Pentru Numele grupului de lucru¸ introduceți un nume pentru grupul de lucru, cum ar fi
tca-analysis. - În Motor de analiză secțiune, selectați Apache Spark.
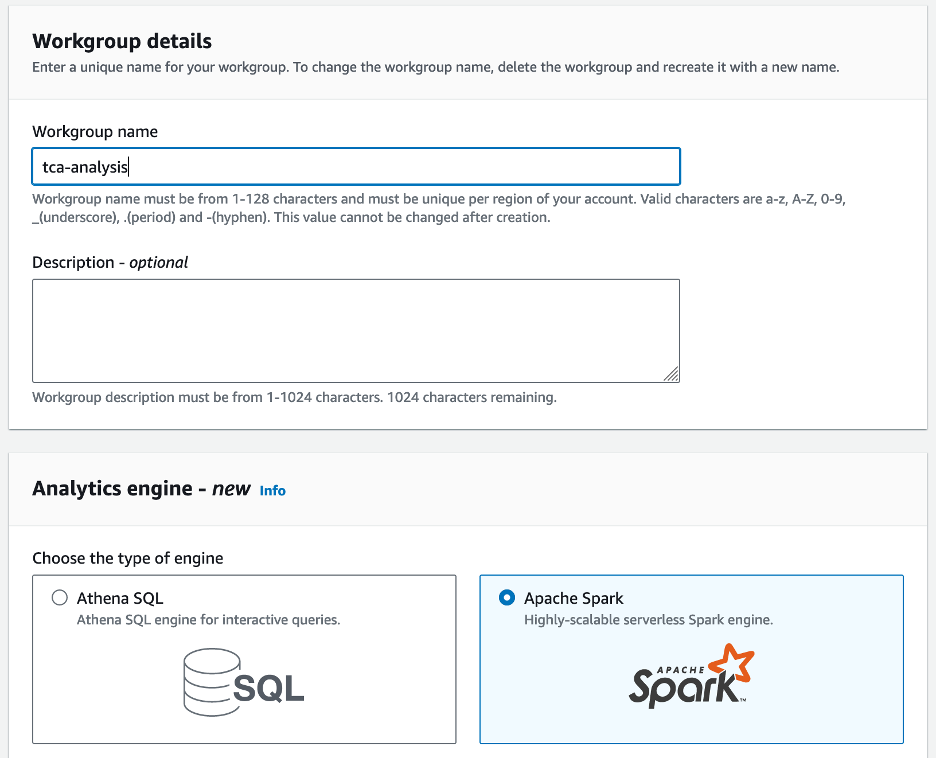
- În Configurații suplimentare secțiunea, puteți alege Utilizați valorile implicite sau furnizați un obicei Gestionarea identității și accesului AWS (IAM) și locația Amazon S3 pentru rezultatele calculului.
- Alege Creați un grup de lucru.
- După ce creați grupul de lucru, navigați la notebook-uri filă și alegeți Creați un caiet.
- Introduceți un nume pentru blocnotes, cum ar fi
tca-analysis-with-tick-history. - Alege Crea pentru a-ți crea caietul.
Lansați blocnotesul
Dacă ați creat deja un grup de lucru Spark, selectați Lansați editorul de notebook în Incepe.
![]()
După ce ați creat blocnotesul, veți fi redirecționat către editorul interactiv de blocnotes.
![]()
Acum putem adăuga și rula următorul cod pe notebook-ul nostru.
Creați o analiză
Parcurgeți următorii pași pentru a crea o analiză:
- Importă biblioteci comune:
- Creați cadrele noastre de date pentru BBO, NBBO și tranzacții:
- Acum putem identifica o tranzacție de utilizat pentru analiza costurilor de tranzacție:
Obținem următoarea ieșire:
Folosim informațiile comerciale evidențiate în viitor pentru produsul comercial (tp), prețul comercial (tpr) și timpul de tranzacționare (tt).
- Aici creăm o serie de funcții de ajutor pentru analiza noastră
- În următoarea funcție, creăm setul de date care conține toate cotațiile înainte și după tranzacție. Athena Spark determină automat câte DPU-uri să lanseze pentru procesarea setului nostru de date.
- Acum să apelăm funcția de analiză TCA cu informațiile din comerțul nostru selectat:
Vizualizați rezultatele analizei
Acum să creăm cadrele de date pe care le folosim pentru vizualizarea noastră. Fiecare cadru de date conține citate pentru unul dintre cele cinci intervale de timp pentru fiecare flux de date (BBO, NBBO):
În secțiunile următoare, oferim exemplu de cod pentru a crea diferite vizualizări.
Plot QS și NBBO înainte de tranzacționare
Utilizați următorul cod pentru a reprezenta un grafic spread-ul cotat și NBBO înainte de tranzacționare:
![]()
Trasează QS pentru fiecare piață și NBBO după tranzacție
Utilizați următorul cod pentru a reprezenta un grafic spread-ul cotat pentru fiecare piață și NBBO imediat după tranzacție:
![]()
Trasează QS pentru fiecare interval de timp și pentru fiecare piață pentru BBO
Utilizați următorul cod pentru a reprezenta un grafic spread-ul cotat pentru fiecare interval de timp și fiecare piață pentru BBO:
![]()
Graficul ES pentru fiecare interval de timp și piață pentru BBO
Utilizați următorul cod pentru a reprezenta un grafic spread-ul efectiv pentru fiecare interval de timp și piață pentru BBO:
Trasează EQF pentru fiecare interval de timp și piață pentru BBO
Utilizați următorul cod pentru a reprezenta un grafic spread-ul efectiv/cotat pentru fiecare interval de timp și piață pentru BBO:
Performanța calculului Athena Spark
Când rulați un bloc de cod, Athena Spark determină automat de câte DPU-uri necesită pentru a finaliza calculul. În ultimul bloc de cod, unde numim tca_analysis de fapt, instruim Spark să proceseze datele și apoi convertim cadrele de date Spark rezultate în cadre de date Pandas. Aceasta constituie cea mai intensă parte de procesare a analizei, iar când Athena Spark rulează acest bloc, arată bara de progres, timpul scurs și câte DPU-uri procesează date în prezent. De exemplu, în calculul următor, Athena Spark utilizează 18 DPU-uri.
![]()
Când vă configurați notebook-ul Athena Spark, aveți opțiunea de a seta numărul maxim de DPU-uri pe care le poate folosi. Valoarea implicită este de 20 de DPU, dar am testat acest calcul cu 10, 20 și 40 de DPU pentru a demonstra modul în care Athena Spark se scalează automat pentru a rula analiza noastră. Am observat că Athena Spark scalează liniar, luând 15 minute și 21 de secunde când notebook-ul a fost configurat cu maximum 10 DPU, 8 minute și 23 de secunde când notebook-ul a fost configurat cu 20 DPU și 4 minute și 44 de secunde când notebook-ul a fost configurat. configurat cu 40 DPU-uri. Deoarece Athena Spark taxează pe baza utilizării DPU, la o granularitate pe secundă, costul acestor calcule este similar, dar dacă setați o valoare maximă DPU mai mare, Athena Spark poate returna rezultatul analizei mult mai rapid. Pentru mai multe detalii despre prețurile Athena Spark, vă rugăm să faceți clic aici.
Concluzie
În această postare, am demonstrat cum puteți utiliza datele OPRA de înaltă fidelitate din Tick History-PCAP de la LSEG pentru a efectua analize ale costurilor de tranzacție folosind Athena Spark. Disponibilitatea în timp util a datelor OPRA, completată cu inovațiile de accesibilitate ale AWS Data Exchange pentru Amazon S3, reduce strategic timpul de analiză pentru firmele care doresc să creeze informații utile pentru deciziile de tranzacționare critice. OPRA generează aproximativ 7 TB de date Parquet normalizate în fiecare zi, iar gestionarea infrastructurii pentru a oferi analize bazate pe datele OPRA este o provocare.
Scalabilitatea Athena în gestionarea procesării datelor la scară largă pentru Tick History – PCAP pentru datele OPRA îl face o alegere convingătoare pentru organizațiile care caută soluții de analiză rapide și scalabile în AWS. Această postare arată interacțiunea perfectă dintre ecosistemul AWS și datele Tick History-PCAP și modul în care instituțiile financiare pot profita de această sinergie pentru a stimula luarea deciziilor bazate pe date pentru strategii critice de tranzacționare și investiții.
Despre Autori
![]() Pramod Nayak este director de management de produs al grupului de latență scăzută la LSEG. Pramod are peste 10 ani de experiență în industria tehnologiei financiare, concentrându-se pe dezvoltarea de software, analiză și managementul datelor. Pramod este un fost inginer de software și pasionat de datele de piață și de tranzacționarea cantitativă.
Pramod Nayak este director de management de produs al grupului de latență scăzută la LSEG. Pramod are peste 10 ani de experiență în industria tehnologiei financiare, concentrându-se pe dezvoltarea de software, analiză și managementul datelor. Pramod este un fost inginer de software și pasionat de datele de piață și de tranzacționarea cantitativă.
![]() LakshmiKanth Mannem este manager de produs în grupul Low Latency al LSEG. El se concentrează pe produse de date și platforme pentru industria datelor de piață cu latență scăzută. LakshmiKanth îi ajută pe clienți să construiască cele mai optime soluții pentru nevoile lor de date pe piață.
LakshmiKanth Mannem este manager de produs în grupul Low Latency al LSEG. El se concentrează pe produse de date și platforme pentru industria datelor de piață cu latență scăzută. LakshmiKanth îi ajută pe clienți să construiască cele mai optime soluții pentru nevoile lor de date pe piață.
![]() Vivek Aggarwal este inginer senior de date în grupul Low Latency al LSEG. Vivek lucrează la dezvoltarea și menținerea conductelor de date pentru procesarea și livrarea fluxurilor de date de piață capturate și a fluxurilor de date de referință.
Vivek Aggarwal este inginer senior de date în grupul Low Latency al LSEG. Vivek lucrează la dezvoltarea și menținerea conductelor de date pentru procesarea și livrarea fluxurilor de date de piață capturate și a fluxurilor de date de referință.
![]() Alket Memushaj este arhitect principal în echipa de dezvoltare a pieței de servicii financiare de la AWS. Alket este responsabil pentru strategia tehnică, lucrând cu parteneri și clienți pentru a implementa chiar și cele mai solicitante sarcini de lucru pe piețele de capital în AWS Cloud.
Alket Memushaj este arhitect principal în echipa de dezvoltare a pieței de servicii financiare de la AWS. Alket este responsabil pentru strategia tehnică, lucrând cu parteneri și clienți pentru a implementa chiar și cele mai solicitante sarcini de lucru pe piețele de capital în AWS Cloud.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Despre Noi
- acces
- accesate
- accesibilitate
- accesibil
- peste
- activ
- activitate
- curent
- de fapt
- adăuga
- În plus,
- adresare
- Avantaj
- După
- împotriva
- Aggarwal
- isi propune
- TOATE
- Permiterea
- deja
- Amazon
- Amazon Atena
- Amazon Web Services
- an
- analize
- analiză
- Analitic
- Google Analytics
- analiza
- analiza
- și
- Orice
- Apache
- Apache Spark
- API-uri
- aplicație
- aplicatii
- Aplică
- abordare
- aproximativ
- arbitrajul
- arbitraj
- SUNT
- în jurul
- AS
- cere
- evalua
- asociate
- At
- atribute
- autoritate
- în mod automat
- Automatizare
- disponibilitate
- disponibil
- AWS
- Backup
- bar
- bazat
- BE
- deoarece
- înainte
- valori de referință
- CEL MAI BUN
- între
- ofertă
- Miliard
- Bloca
- brokeri
- construi
- dar
- by
- calcula
- calculată
- calcul
- apel
- CAN
- Capacitate
- capital
- Piețele de capital
- captura
- capturat
- capturarea
- catalog
- Centre
- provocare
- canale
- caracterizat
- taxe
- alegere
- Alege
- clientii
- Cloud
- cod
- Colectare
- Comun
- convingătoare
- Completă
- Terminat
- componente
- cuprinzător
- cuprinde
- Conduce
- configurat
- configurarea
- Consoleze
- consolidarea
- conține
- contracte
- a contribui
- converti
- CORPORAȚIE
- A costat
- Cheltuieli
- coscris
- crea
- a creat
- creaţie
- critic
- crucial
- În prezent
- personalizat
- clienţii care
- Liniuţă
- de date
- centre de date
- inginer de date
- Schimb de date
- management de date
- de prelucrare a datelor
- stocare a datelor
- Pe bază de date
- seturi de date
- zi
- Luarea deciziilor
- Deciziile
- Mod implicit
- defini
- livrare
- cerând
- cererile
- demonstra
- demonstrat
- implementa
- detalii
- determină
- în curs de dezvoltare
- Dezvoltare
- echipă de dezvoltare
- diferenţă
- diferit
- direct
- Director
- distribuite
- distribuire
- diferit
- dubla
- conduce
- dinamic
- dinamic
- dinamică
- fiecare
- uşura
- ușurință în utilizare
- ecosistem
- editor
- Eficace
- eficacitate
- eligibil
- eliminarea
- angajat
- angajarea
- permite
- permite
- care să cuprindă
- eforturi
- Motor
- inginer
- Motoare
- sporire
- asigură
- Intrați
- escaladarea
- Eter (ETH)
- evalua
- evaluare
- Chiar
- eveniment
- Fiecare
- exemplu
- schimb
- Platforme de tranzacţionare
- execuție
- experienţă
- explora
- expres
- extinde
- mai repede
- Dispunând
- februarie
- Smochin
- Fişiere
- umple
- filtru
- financiar
- Institutii financiare
- Servicii financiare
- tehnologie financiară
- firme
- First
- prima dată
- cinci
- Flexibilitate
- se concentrează
- concentrându-se
- următor
- Pentru
- format
- Fost
- Înainte
- patru
- FRAME
- din
- funcţie
- funcții
- mai mult
- lacune
- generează
- obține
- dat
- Caritate
- piata globala
- Go
- merge
- gps
- grup
- Manipularea
- Avea
- având în
- he
- loc de trecere
- ajută
- de înaltă calitate
- superior
- cea mai mare
- Evidențiat
- istoric
- istorie
- carcasă
- Cum
- Cum Pentru a
- http
- HTTPS
- IAM
- identifica
- Identitate
- if
- imediat
- imediat
- Impactul
- import
- in
- Inclusiv
- a crescut
- industrie
- informații
- Infrastructură
- inovații
- perspective
- instituții
- integrală
- integrate
- integrare
- interacţiune
- interactiv
- în
- complicat
- investiţie
- implică
- IT
- jpg
- doar
- mare
- pe scară largă
- Nume
- Latență
- lansa
- mai puțin
- biblioteci
- Linie
- Lichiditate
- locaţie
- logică
- cautati
- Jos
- cel mai mic
- mentine
- major
- FACE
- Efectuarea
- administra
- administrare
- manager
- Manageri
- de conducere
- manieră
- multe
- Piață
- Piata de date
- impactul pieței
- de cercetare de piață
- Volatilitatea pieței
- crearea de piață
- pieţe
- masiv
- Stăpânirea
- maxim
- Mai..
- măsura
- mesaj
- mesaje
- meticulos
- meticulos
- Metrici
- milion
- minimaliza
- minute
- Monitorizarea
- mai mult
- În plus
- cele mai multe
- mult
- multiplu
- nume
- Natură
- Navigaţi
- Nevoie
- nevoilor
- Nici unul
- caiet
- notebook-uri
- număr
- numeroși
- NumPy
- observate
- of
- oferi
- promoții
- on
- ONE
- optimă
- Optimizați
- optimizate
- Opțiune
- Opţiuni
- or
- organizații
- al nostru
- afară
- producție
- peste
- global
- propriu
- panda
- parte
- parteneri
- pasionat
- modele
- Vârf
- pentru
- efectua
- performanță
- pivot
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- joacă
- "vă rog"
- intrigă
- portofoliu
- manageri de portofoliu
- poziţionat
- Post
- post-tranzacționare
- potenţial
- Precizie
- Pregăti
- pregătirea
- preţ
- de stabilire a prețurilor
- primar
- Principal
- proces
- procese
- prelucrare
- procesor
- Produs
- management de produs
- manager de produs
- Produse
- Progres
- furniza
- furnizarea
- publicat
- Piton
- Q3
- cantitativ
- cantitate
- întrebare
- Citate
- rată
- tarife
- Citeste
- real
- în timp real
- recomandat
- înregistrări
- Roșu
- reduce
- reduce
- referință
- refinitiv
- Raportarea
- Rapoarte
- depozit
- cerință
- Necesită
- cercetare
- răspuns
- responsabil
- rezultat
- rezultând
- REZULTATE
- reveni
- Riscurile
- Rol
- Alerga
- ruleaza
- sare
- scalabilitate
- scalabil
- cântare
- scalare
- fără sudură
- perfect
- Al doilea
- secunde
- Secțiune
- secțiuni
- Titluri de valoare
- securitate
- caută
- selecta
- selectate
- senior
- distinct
- servește
- Servicii
- set
- instalare
- Arăta
- Emisiuni
- semnificativ
- asemănător
- simplu
- simplificată
- singur
- alunecarea
- Software
- de dezvoltare de software
- Inginer Software
- soluţii
- sofisticat
- tensiune
- Scânteie
- specific
- răspândire
- Spread-
- Standuri
- paşi
- depozitare
- stoca
- Strategic
- strategii
- Strategie
- raționalizează
- Studiu
- ulterior
- astfel de
- SWIFT
- simbol
- sinergie
- Lua
- luare
- echipă
- Tehnic
- tehnici de
- Tehnologia
- testat
- decât
- acea
- informațiile
- lor
- Lor
- apoi
- Acestea
- acest
- Prin
- căpușă
- timp
- oportun
- timestamp-ul
- Titlu
- la
- Total
- tp
- TPR
- comerţului
- Comercianti
- meserii
- Trading
- Strategii de tranzacționare
- tranzacționare strategie
- tranzacție
- Costurile tranzactiei
- transformare
- tranziţie
- Ultra
- în
- este supus
- upgrade-ul
- us
- Folosire
- utilizare
- utilizat
- utilizări
- folosind
- Utilizand
- valoare
- diverse
- vizualizare
- imagina
- Volatilitate
- volum
- volume
- a fost
- we
- web
- servicii web
- cand
- care
- pe larg
- voi
- cu
- în
- fără
- Grup de lucru
- de lucru
- fabrică
- la nivel internațional.
- face griji
- X
- ani
- tu
- Ta
- zephyrnet