
Imagine de la Adobe Firefly
„Eram prea mulți. Am avut acces la prea mulți bani, prea mult echipament și, încetul cu încetul, am înnebunit.”
Francis Ford Coppola nu făcea o metaforă pentru companiile de inteligență artificială care cheltuiesc prea mult și își pierd drumul, dar ar fi putut să fie. Apocalipsa acum a fost epic, dar și un proiect lung, dificil și costisitor de realizat, la fel ca GPT-4. Aș sugera că dezvoltarea LLM-urilor a gravitat către prea mulți bani și prea mult echipament. Și o parte din hype-ul „tocmai am inventat inteligența generală” este puțin nebunește. Dar acum este rândul comunităților cu sursă deschisă să facă ceea ce fac cel mai bine: să ofere software concurent gratuit, folosind mult mai puțini bani și echipamente.
OpenAI a preluat finanțare de 11 miliarde de dolari și se estimează că GPT-3.5 costă 5-6 milioane de dolari pe cursă de antrenament. Știm foarte puține despre GPT-4, deoarece OpenAI nu spune, dar cred că este sigur să presupunem că nu este mai mic decât GPT-3.5. În prezent, există un deficit de GPU la nivel mondial și, pentru o schimbare, nu este din cauza celei mai recente criptomonede. Start-up-urile generative de inteligență artificială obțin runde din seria A de peste 100 de milioane de dolari la evaluări uriașe atunci când nu dețin niciun IP pentru LLM pe care îl folosesc pentru a-și alimenta produsul. Trenul LLM este în viteză mare și banii curg.
Părea că zarul a fost turnat: doar companii cu buzunare adânci precum Microsoft/OpenAI, Amazon și Google își puteau permite să antreneze modele cu o sută de miliarde de parametri. Se presupunea că modelele mai mari sunt modele mai bune. GPT-3 a greșit ceva? Așteptați până când există o versiune mai mare și totul va fi bine! Companiile mai mici care doresc să concureze au trebuit să strângă mult mai mult capital sau să fie lăsate să construiască integrări de mărfuri pe piața ChatGPT. Academia, cu bugete de cercetare și mai restrânse, a fost retrogradată pe margine.
Din fericire, o grămadă de oameni inteligenți și proiecte open source au considerat asta mai degrabă o provocare decât o restricție. Cercetătorii de la Stanford au lansat Alpaca, un model cu 7 miliarde de parametri a cărui performanță se apropie de modelul de 3.5 de miliarde de parametri al lui GPT-175. Neavând resursele necesare pentru a construi un set de antrenament de dimensiunea folosită de OpenAI, ei au ales în mod inteligent să ia un LLM, LLaMA, cu sursă deschisă instruit, și să-l ajusteze pe o serie de solicitări și ieșiri GPT-3.5. În esență, modelul a învățat ce face GPT-3.5, ceea ce se dovedește a fi o strategie foarte eficientă pentru replicarea comportamentului său.
Alpaca este licențiat pentru utilizare necomercială atât în cod, cât și în date, deoarece utilizează modelul LLaMA non-comercial cu sursă deschisă, iar OpenAI interzice în mod explicit orice utilizare a API-urilor sale pentru a crea produse concurente. Acest lucru creează perspectiva tentantă de a ajusta un alt LLM cu sursă deschisă diferit la solicitările și rezultatele lui Alpaca... creând un al treilea model asemănător GPT-3.5 cu posibilități diferite de licențiere.
Există un alt strat de ironie aici, în sensul că toate LLM-urile majore au fost instruite pe text și imagini protejate prin drepturi de autor disponibile pe Internet și nu au plătit un ban deținătorilor de drepturi. Companiile susțin scutirea de „utilizare corectă” conform legislației americane privind drepturile de autor cu argumentul că utilizarea este „transformatoare”. Cu toate acestea, când vine vorba de rezultatul modelelor pe care le construiesc cu date gratuite, chiar nu doresc ca nimeni să le facă același lucru. Mă aștept că acest lucru se va schimba pe măsură ce deținătorii de drepturi se vor înțelepți și ar putea ajunge în instanță la un moment dat.
Acesta este un punct separat și distinct față de cel ridicat de autorii open source cu licență restrictivă care, pentru AI generativă pentru produse Code, cum ar fi CoPilot, se opun ca codul lor să fie folosit pentru instruire pe motiv că licența nu este respectată. Problema pentru autorii individuali cu sursă deschisă este că trebuie să demonstreze statutul – copierea substanțială – și că au suferit daune. Și din moment ce modelele îngreunează legarea codului de ieșire la intrare (liniile de cod sursă ale autorului) și nu există nicio pierdere economică (se presupune că este gratuit), este mult mai greu să depunem un caz. Acest lucru este spre deosebire de creatorii cu scop profit (de exemplu, fotografi) al căror model de afaceri este în acordarea de licențe/vânzarea lucrărilor lor și care sunt reprezentați de agregatori precum Getty Images, care pot arăta o copie substanțială.
Un alt lucru interesant despre LLaMA este că a apărut din Meta. A fost lansat inițial doar cercetătorilor și apoi a fost difuzat prin BitTorrent în lume. Meta este într-o afacere fundamental diferită de OpenAI, Microsoft, Google și Amazon, prin aceea că nu încearcă să vă vândă servicii cloud sau software și, prin urmare, are stimulente foarte diferite. În trecut, și-a oferit proiecte de calcul open source (OpenCompute) și a văzut cum comunitatea le îmbunătățește - înțelege valoarea open source.
Meta s-ar putea dovedi a fi unul dintre cei mai importanți contributori open-source AI. Nu numai că are resurse masive, dar beneficiază dacă există o proliferare a tehnologiei AI generative excelente: va exista mai mult conținut pe care să-l monetizeze pe rețelele sociale. Meta a lansat alte trei modele AI open-source: ImageBind (indexarea datelor multidimensionale), DINOv2 (viziunea computerizată) și Segment Anything. Acesta din urmă identifică obiecte unice în imagini și este eliberat sub Licența Apache extrem de permisivă.
În cele din urmă, am avut, de asemenea, presupusa scurgere a unui document intern Google „Noi nu avem șanț, și nici nu OpenAI”, care prezintă o perspectivă vagă a modelelor închise față de inovația comunităților care produc modele mult mai mici, mai ieftine, cu performanțe apropiate sau mai bune decât omologii lor cu sursă închisă. Spun presupus pentru că nu există nicio modalitate de a verifica sursa articolului ca fiind internă Google. Cu toate acestea, conține acest grafic convingător:
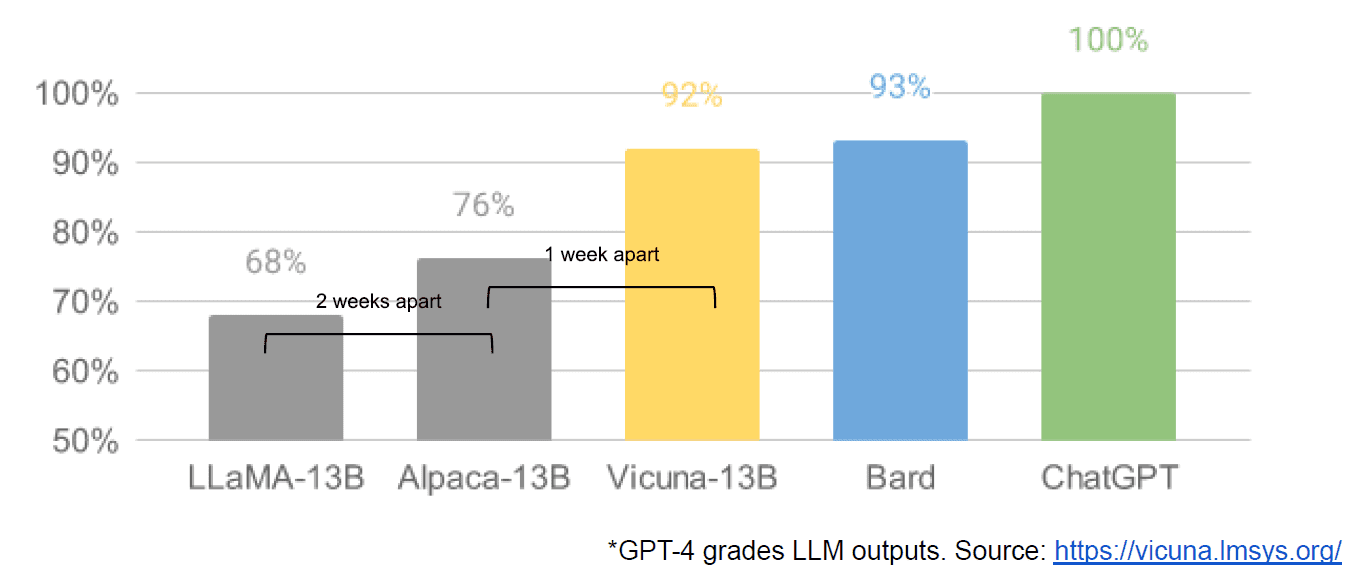
Axa verticală este gradarea ieșirilor LLM de către GPT-4, pentru a fi clar.
Stable Diffusion, care sintetizează imagini din text, este un alt exemplu în care IA generativă open source a reușit să avanseze mai repede decât modelele proprietare. O iterație recentă a acestui proiect (ControlNet) l-a îmbunătățit astfel încât a depășit capacitățile lui Dall-E2. Acest lucru a apărut dintr-o mulțime de modificări din întreaga lume, rezultând într-un ritm de avans greu de egalat pentru orice instituție. Unii dintre acești lucrători și-au dat seama cum să facă Stable Diffusion mai rapid pentru antrenament și rulare pe hardware mai ieftin, permițând cicluri de iterație mai scurte de către mai mulți oameni.
Și așa am încheiat cercul. A nu avea prea mulți bani și prea mult echipament a inspirat un nivel viclean de inovație al unei întregi comunități de oameni obișnuiți. Ce timp să fii dezvoltator AI.
Mathew Lodge este CEO al Diffblue, un startup AI For Code. Are peste 25 de ani de experiență diversă în conducerea produselor la companii precum Anaconda și VMware. Lodge este în prezent membru al consiliului de administrație al Good Law Project și este vicepreședinte al Consiliului de administrație al Royal Photographic Society.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Mintând viitorul cu Adryenn Ashley. Accesați Aici.
- Cumpărați și vindeți acțiuni în companii PRE-IPO cu PREIPO®. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :are
- :este
- :nu
- :Unde
- $UP
- 9
- a
- Capabil
- Despre Noi
- Academie
- acces
- chirpici
- avansa
- Agregatoare
- AI
- TOATE
- pretins
- ar fi
- de asemenea
- Amazon
- an
- și
- O alta
- Orice
- oricine
- nimic
- Apache
- API-uri
- SUNT
- argument
- articol
- AS
- asumat
- At
- autor
- Autorii
- disponibil
- Axă
- BE
- deoarece
- fost
- fiind
- Beneficiile
- CEL MAI BUN
- Mai bine
- mai mare
- BitTorrent
- bord
- atât
- Bugete
- construi
- Clădire
- Buchet
- afaceri
- model de afaceri
- dar
- by
- a venit
- CAN
- capacități
- capital
- caz
- CEO
- Scaun
- contesta
- Schimbare
- Chat GPT
- mai ieftin
- a ales
- Cerc
- pretinde
- clar
- Închide
- închis
- Cloud
- servicii de tip cloud
- cod
- cum
- vine
- produs
- Comunități
- comunitate
- Companii
- convingătoare
- concura
- concurente
- Calcula
- calculator
- Computer Vision
- conţinut
- contribuitori
- copiere
- drepturi de autor
- Cheltuieli
- ar putea
- Tribunal
- crea
- Crearea
- Creatorii
- criptomonede
- În prezent
- cicluri
- de date
- livrarea
- adjunct
- modele
- Dezvoltator
- Dezvoltare
- .
- diferit
- dificil
- difuziune
- distinct
- diferit
- do
- document
- face
- Dont
- e
- Economic
- Eficace
- permițând
- capăt
- Întreg
- EPIC
- echipament
- În esență,
- estimativ
- Chiar
- exemplu
- aștepta
- scump
- experienţă
- departe
- mai repede
- imaginat
- Curgere
- a urmat
- Pentru
- vad
- Gratuit
- din
- Complet
- fundamental
- de finanțare
- Gear
- General
- generativ
- AI generativă
- bine
- GPU
- grafic
- mare
- HAD
- Greu
- Piese metalice
- Avea
- având în
- he
- aici
- Înalt
- extrem de
- Titularii
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- mare
- hype
- i
- identifică
- if
- imagini
- important
- îmbunătăţi
- îmbunătățit
- in
- stimulente
- individ
- Inovaţie
- intrare
- NEBUN
- inspirat
- in schimb
- Instituţie
- integrările
- interesant
- intern
- Internet
- Inventat
- IP
- ironie
- IT
- repetare
- ESTE
- doar
- KDnuggets
- Cunoaște
- aterizare
- Ultimele
- Drept
- strat
- Conducere
- învățat
- stânga
- mai puțin
- Nivel
- Licență
- Autorizat
- de licențiere
- ca
- linii
- LINK
- mic
- Lamă
- Lung
- uitat
- cautati
- pierde
- de pe
- Lot
- major
- face
- Efectuarea
- multe
- piaţă
- masiv
- Meci
- Mai..
- Mass-media
- meta
- Microsoft
- model
- Modele
- genera bani
- bani
- mai mult
- cele mai multe
- mult
- Nevoie
- Nici
- Nu.
- non-comercial
- acum
- obiect
- obiecte
- of
- on
- ONE
- afară
- deschide
- open-source
- proiecte open source
- OpenAI
- or
- obișnuit
- iniţial
- Altele
- afară
- producție
- peste
- propriu
- Pace
- parametru
- trecut
- Plătește
- oameni
- efectua
- performanță
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- posibilităţile de
- putere
- Problemă
- Produs
- Produse
- proiect
- Proiecte
- proprietate
- perspectivă
- ridica
- ridicat
- mai degraba
- într-adevăr
- recent
- eliberat
- reprezentate
- cercetare
- cercetători
- Resurse
- restricţie
- rezultând
- Drepturile
- runde
- regal
- Alerga
- s
- sigur
- acelaşi
- Spune
- văzut
- segment
- vinde
- distinct
- serie
- Seria A
- servește
- Servicii
- set
- deficit
- Arăta
- întrucât
- singur
- Mărimea
- mai mici
- inteligent
- So
- Social
- social media
- Societate
- Software
- unele
- ceva
- Sursă
- cod sursă
- petrece
- stabil
- stanford
- start-up-uri
- lansare
- Strategie
- astfel de
- sugera
- a presupus
- depășit
- Lua
- luate
- ia
- Tehnologia
- decât
- acea
- Sursa
- lumea
- lor
- Lor
- apoi
- Acolo.
- ei
- lucru
- crede
- Al treilea
- acest
- aceste
- trei
- timp
- la
- de asemenea
- a luat
- Tren
- dresat
- Pregătire
- ÎNTORCĂ
- se transformă
- în
- înțelege
- unic
- spre deosebire de
- până la
- us
- utilizare
- utilizat
- utilizări
- folosind
- Valuations
- valoare
- verifica
- versiune
- vertical
- foarte
- de
- Vizualizare
- viziune
- VMware
- vs
- aștepta
- vrea
- a fost
- Cale..
- we
- a mers
- au fost
- Ce
- cand
- care
- OMS
- întreg
- a caror
- voi
- ÎNŢELEPT
- cu
- Apartamente
- lume
- Greșit
- tu
- zephyrnet









