Recunoașterea optică a caracterelor (OCR), metoda de conversie a textelor scrise de mână/tipărite în text codificat automat, a fost întotdeauna un domeniu major de cercetare în viziunea computerizată datorită numeroaselor sale aplicații în diferite domenii — Băncile folosesc OCR pentru a compara declarațiile; Guvernele folosesc OCR pentru culegeri de feedback pentru sondaje.

Datorită diversității stilurilor de scris de mână și de text tipărit, abordările recente ale OCR încorporează învățări profunde pentru a obține o precizie mai mare. Întrucât învățarea profundă necesită cantități mari de date pentru formarea modelelor, companii precum Google au un avans în producerea de rezultate promițătoare cu serviciile lor OCR.
Acest articol analizează detaliile OCR Google Vision, inclusiv un tutorial simplu în python, gama de aplicații, prețuri și alte alternative.
- Ce este Google Cloud Vision OCR?
- Un tutorial simplu
- De ce OCR?
- Exemple de cazuri de utilizare
- Tarif
- Caracteristici esențiale ale Google Cloud Vision OCR
- Alternative
- Probleme comune
Ce este Google Cloud Vision?

Google Cloud Vision OCR face parte din API-ul Google Cloud Vision pentru a extrage text din imagini. Mai exact, există două adnotări care ajută la recunoașterea caracterelor:
- Text_Adnotation: Extrage și emite texte codificate de mașină din orice imagine (de exemplu, fotografii cu vederi stradale sau peisaje). Deoarece a fost conceput inițial pentru a fi utilizabil în diferite situații de iluminare, modelul este într-un anumit sens mai robust în citirea cuvintelor de diferite stiluri, dar doar la un nivel mai rar. Fișierul JSON returnat include șirurile întregi, precum și cuvintele individuale și casetele lor de delimitare corespunzătoare.
- Document_Text_Adnotation: Acesta este conceput în special pentru documente text cu dens prezentate (de exemplu, cărți scanate). Astfel, în timp ce acceptă citirea textelor mai mici și mai concentrate, este mai puțin adaptabil la imaginile în sălbăticie. Informații precum paragrafe, blocuri și pauze sunt incluse în fișierul JSON de ieșire.
Cauți o soluție OCR care să depășească deficiențele Google Cloud Vision sau OCR zonal? Dă Nanonets™ o rotire pentru o precizie mai mare, o flexibilitate mai mare și tipuri de documente mai largi!
Un tutorial simplu
Următoarea secțiune prezintă un tutorial simplu pentru începerea utilizării API-ului Google Vision, în special despre cum să îl utilizați pentru serviciul OCR Google Cloud Vision.
Privire de ansamblu simplă
Ideea din spatele acestui lucru este foarte intuitivă și simplă.
1) În esență, trimiteți o imagine (la distanță sau din stocarea dvs. locală) către API-ul Google Cloud Vision.
2) Imaginea este procesată de la distanță pe Google Cloud și produce formatele JSON corespunzătoare funcției pe care ați apelat-o.
3) Fișierul JSON este returnat ca rezultat după apelarea funcției.
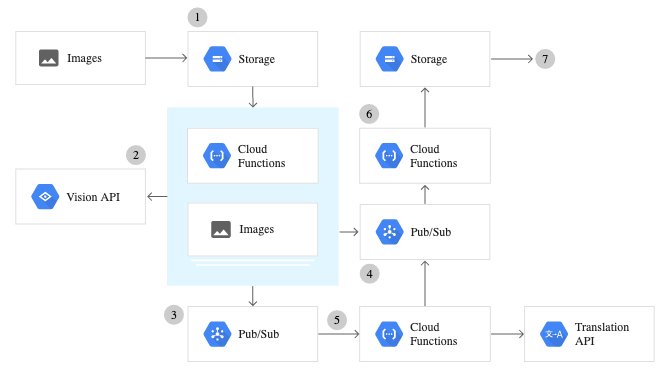
Configurarea API-ului Google Cloud Vision
Pentru a utiliza orice servicii furnizate de API-ul Google Vision, trebuie să configurați Google Cloud Console și să efectuați o serie de pași pentru autentificare. Mai jos este o prezentare generală pas cu pas a modului de configurare a întregului serviciu API Vision.
- Creați un proiect în Google Cloud Console — Trebuie creat un proiect pentru a începe să utilizați orice serviciu Vision. Proiectul organizează resurse precum colaboratori, API-uri și informații despre prețuri.
- Activați facturarea — Pentru a activa API-ul Vision, trebuie mai întâi să activați facturarea pentru proiectul dvs. Detaliile privind prețurile vor fi abordate în secțiunile ulterioare.
- Activați Vision API
- Creare cont de serviciu — Creați un cont de serviciu și conectați-vă la proiectul creat, apoi creați o cheie de cont de serviciu. Cheia va fi scoasă și descărcată ca fișier JSON pe computer.
- Configurați variabila de mediu GOOGLE_APPLICATION_CREDENTIALS; Pentru a configura această variabilă de mediu, rulați-o pe Mac/Linux sau Windows.
- Blocuri de cod pentru Mac/Linux
- Blocuri de cod pentru Windows
O procedură mai detaliată a pașilor menționați mai sus poate fi găsită din documentația oficială oferită de Google Cloud de aici:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Funcție simplă Google Vision OCR în Python
API-ul Google Cloud Vision funcționează cu numeroase limbaje populare, de la Java, Node.js, Python până la propriul limbaj Google Go. Pentru simplitate, introducem o metodă simplă de apelare în Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Cu alte cuvinte, metoda apelează în consecință funcția adnotare_text, apoi extrageți în continuare răspunsurile și imprimați informațiile. document_text_annotation poate fi, de asemenea, apelat folosind același mod pentru a prelua texte dense. De asemenea, se pot detecta imagini de la distanță setând imaginea prin:
image.source.image_uri = uriunde uri este uri-ul imaginii.
Mai multe detalii despre coduri pot fi preluate aici:
https://cloud.google.com/vision
Căutați o soluție OCR care să depășească deficiențele Google Cloud Vision? Dă Nanonets™ o rotire pentru o precizie mai mare, o flexibilitate mai mare și tipuri de documente mai largi!
Nivelul de ieșire oferit
Pentru a ajuta la analiza ulterioară a datelor a textului, cele două funcții OCR Google oferă diferite niveluri de ieșire pe care utilizatorii le pot utiliza: pentru adnotare_text, atât șirurile întregi (dacă sunt considerate de Google ca o singură propoziție sau expresie), cât și cuvintele individuale din interior; pentru document_text_annotation, deoarece modelul este optimizat pentru text dens, pagină, bloc, paragraf, cuvânt și pauză sunt toate oferite ca parte a rezultatului.
Cât de bine funcționează totuși?
Cât de robuste sunt modelele?
După cum am menționat anterior, Google oferă două funcții pentru OCR în două situații diferite. În cele ce urmează, se descrie capacitatea a două funcții de a prelua diferite tipuri de date.
Date tipărite
Cel mai ușor tip de date de interpretat sunt datele text tipărite, adică textul scris de computer, imprimat și scanat. OCR este necesar atunci când avem doar copia tipărită a acestor date în loc de textele originale codificate de mașină. Deoarece majoritatea acestor texte sunt strânse și împachetate în pagini, document_text_annotation ar fi o opțiune mai bună.
Date scrise de mână
Conținutul poate conține text scris de mână, iar stilurile de date scrise de mână pot varia drastic. Cu toate acestea, Google Vision OCR oferă o precizie decentă, atâta timp cât notele scrise de mână nu sunt prea dezordonate. În funcție de cât de împachetat este prezentat mediul de date scrise de mână, folosim una dintre cele două funcții de la caz la caz.
Date rotite/in-the-Wild
Când imaginile sau fotografiile scanate sunt prezentate în unghiuri neortodoxe sau nealiniate, le considerăm date în sălbăticie. Textele ar putea fi mai dificil de detectat în primul rând și, prin urmare, folosim de obicei adnotare_text funcție care a fost concepută pentru a procesa date în sălbăticie în primul rând. Pe baza unor experimente de trecere prin texte verticale și semne rutiere capturate în diferite unghiuri, arătăm că Google Vision OCR are de fapt performanțe decente pe date din diverse medii.
De ce OCR?
Multe dintre datele pe care le avem astăzi sunt în format nestructurat. De exemplu, având în vedere o imagine, un document scanat sau o fotografie, în timp ce oamenii pot recunoaște rapid textele și pot interpreta în continuare semnificațiile, toate datele textului sunt doar pixeli cu culori, fără a oferi un sens real mașinilor.

Atunci când companiile sau corporațiile mari au de-a face cu cantități masive de documente, volumul mare de date ar face imposibilă ca orice clasificări sau prelucrare a datelor să se facă doar cu efort uman - atunci textul codificat pe mașină devine la îndemână.
După conversia OCR, informațiile pot fi apoi analizate cu mai multe metode diferite, în funcție de natura datelor:
- Pentru datele numerice, metodele statistice ar putea fi aplicate direct pentru a analiza eventualele corelații. De asemenea, am putea adopta metode tradiționale de învățare automată (de exemplu, KNN, K-Means, regresie liniară) sau abordări de învățare profundă pentru a crea modele predictive pentru regresie și/sau clasificare.
- Pentru datele text, pot fi necesare mai multe etape de procesare. Procesul de analiză și interpretare a datelor text în statistici semnificative este adesea denumit procesare a limbajului natural (NLP). Mai exact, am putea extrage numere sau chiar semantică/atmosferă pe baza conținutului dat.
Toate aceste analize ar putea permite companiilor, în special celor cu cantități mari de date noi în fiecare zi, să creeze modele robuste și chiar să automatizeze o mulțime de procese și să înlocuiască abordările tradiționale care necesită o forță de muncă intensivă și pline de erori. Următoarea secțiune analizează câteva exemple detaliate despre cum poate fi utilizat OCR.
Căutați o soluție OCR care să depășească deficiențele Google Cloud Vision? Dă Nanonets™ o rotire pentru o precizie mai mare, o flexibilitate mai mare și tipuri de documente mai largi!
Exemple de cazuri de utilizare
Citirea plăcuței de înmatriculare

Poate că una dintre cele mai comune utilizări ale OCR în zilele noastre este aplicația în citirea plăcuțelor de înmatriculare. În țările dezvoltate, parcările sunt adesea însoțite de modele de citire a plăcuțelor de înmatriculare pentru a determina ora de intrare, ora de ieșire și chiar locația exactă a parcării per mașină. Unele parcări sunt chiar conectate la rețeaua guvernamentală pentru a percepe taxele de parcare direct către familii – toate acestea ușurând eforturile umane redundante.
Modelele OCR ale plăcuței de înmatriculare pot fi adoptate și pentru depistarea încălcărilor rutiere, ușurând timpul ca poliția să introducă manual datele mașinii care încalcă.
Scanarea chitanțelor și a facturii

Proiecțiile financiare și echilibrarea activelor și pasivelor companiilor sunt activități importante pentru orice firmă. Pe măsură ce companiile mari fac achiziții în cantități mari din mai multe sectoare de-a lungul anului, acestea sunt obligate să adune și să proceseze cu meticulozitate toate facturile și chitanțele atunci când creează situații financiare.
Cu ajutorul OCR, putem crea conducte automate care recunoașteți o serie de formate de factură și transformați-le în numere. Eforturile de muncă sunt necesare doar pentru verificare, iar datele și numerele structurate pot permite companiei să echilibreze rapid intrările și ieșirile, să creeze previziuni financiare, precum și să țină seama de orice manipulări rău intenționate ale finanțelor companiei.
Înregistrări medicale electrice

Datele pacienților sunt adesea împrăștiate într-o regiune, țară sau chiar între țări, în funcție de stilul de viață al indivizilor. Datorită stilurilor diferite de clinici și spitale (spitalele mari pot avea baze de date organizate, în timp ce medicii din clinicile mai mici pot doar să noteze înregistrările de mână), vârsta pacienților (pacienții mai în vârstă pot fi inserați într-o anumită bază de date înainte de renovare și încorporare a computere) și locațiile persoanelor (oamenii se pot muta într-un alt oraș sau chiar în străinătate), păstrarea unui medical universal poate fi de fapt foarte dificilă.
Un OCR bine instruit devine astfel util atunci când se transferă EMR de la un spital la altul sau când se transformă datele scrise de mână în text automat - ambele putând accelera procesul de înțelegere a istoricului medical al pacienților într-un mod rapid și concis.
Formulare și Sondaje

Organizațiile (fie guvernamentale sau neguvernamentale) pot solicita adesea feedback din partea clienților sau cetățenilor pentru a-și îmbunătăți planurile și produsele promoționale actuale. Deoarece formularele sunt de obicei scrise de mână, ar fi potențial dificil să se efectueze orice analiză statistică directă. Prin urmare, procesul de conversie a datelor nestructurate și a anchetelor scrise de mână în cifre numerice pentru a facilita calculele ar putea fi asistat și accelerat de OCR.
Căutați o soluție OCR care să depășească deficiențele Google Cloud Vision? Dă Nanonets™ o rotire pentru o precizie mai mare, o flexibilitate mai mare și tipuri de documente mai largi!
Prețuri Cloud Vision
Potrivit Google , ambii adnotare_text și document_text_annotation sunt oferite la același nivel de preț ca următoarele:
Pentru fiecare lună, primele 1000 de unități sunt oferite gratuit, cu cele 1000-5000000 taxate la 1.5 USD per 1000 de unități. După atingerea pragului de 5000000, prețul scade la 0.6 USD per 1000 de unități (Fiecare imagine trimisă prin API-ul Google Vision este considerată o unitate).
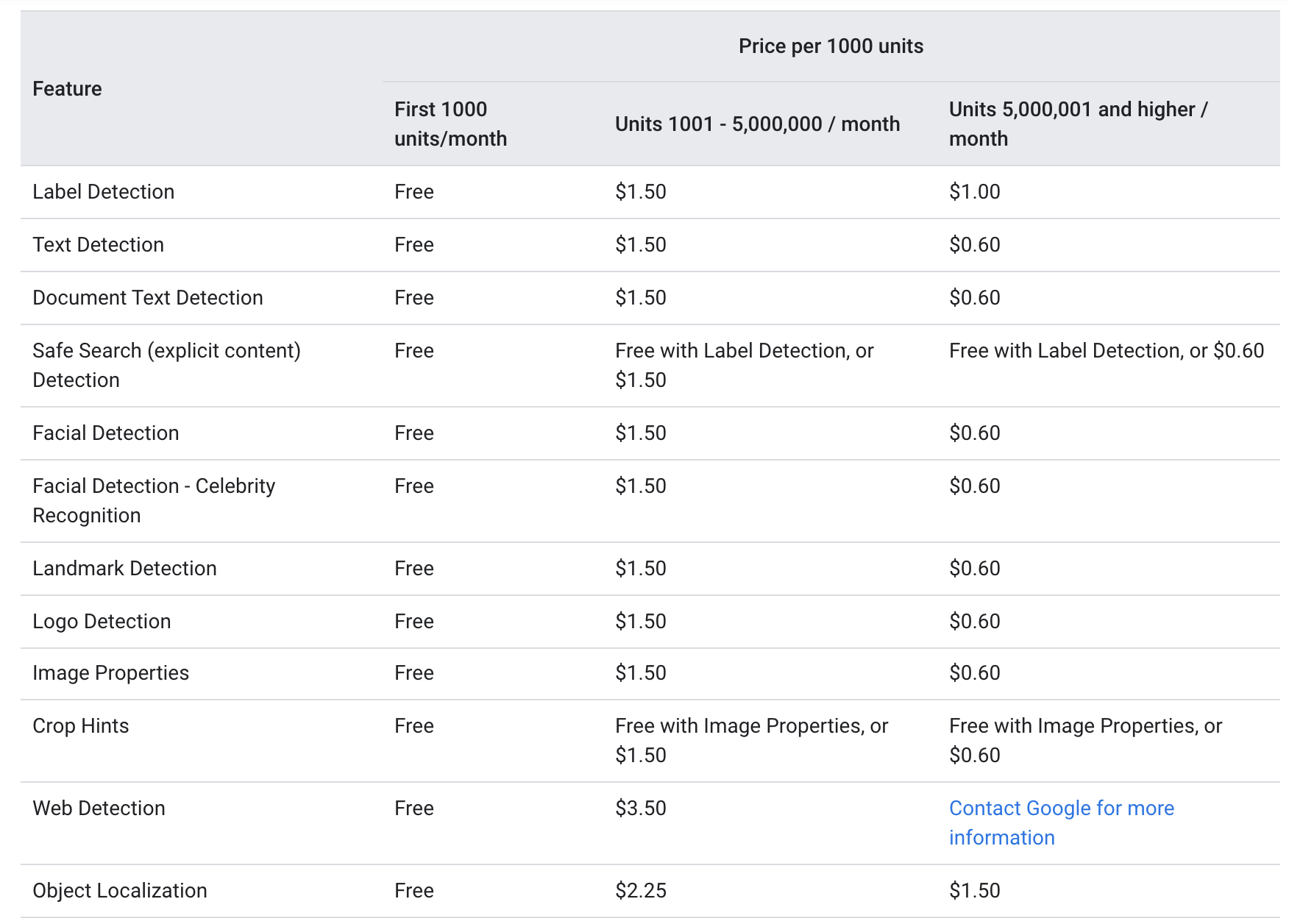
Prețurile de mai sus sugerează că serviciul OCR este relativ accesibil atât pentru companiile mici cu utilizări mai puțin frecvente, cât și pentru corporațiile mari unde serviciul este necesar de mult mai mult de 5000000 de ori pe lună.
Caracteristici esențiale ale Google Cloud Vision OCR
Google OCR are diverse beneficii, aici descriem câteva dintre cele mai semnificative beneficii:
- Robust - Cele două funcții, care deservesc două tipuri de documente text în funcție de decizia utilizatorilor, fac ca Google Vision OCR să fie relativ mai robust decât motoarele OCR cu un singur model.
- Suport lingvistic - Cu probabil cea mai mare bază de date lingvistică, Google a sfătuit că OCR-ul său este aplicabil în peste 60 de limbi, experimentând încă câteva zeci și mapează multe dintre celelalte cu un alt cod de limbă sau un sistem de recunoaștere general de limbă.
- Ușurință în utilizare - Modelul în sine face parte din biblioteca Google Vision încorporată. După procesul puțin mai deranjant de configurare a cheii API (care este cerut de aproape toate motoarele OCR), metoda de apelare a funcției poate fi utilizată în numeroase limbi într-un mod foarte simplu.
- Scalabilitate - Strategia de prețuri a Google încurajează utilizatorii să extindă utilizarea API-ului, deoarece o utilizare mai mare duce la un preț mediu mai ieftin.
- Viteza - Platforma de stocare Google Cloud însoțește minunat utilizarea API-ului. Prin încărcarea imaginilor în unitate, timpul de răspuns al API-ului poate fi foarte rapid și scalabil.

Căutați o soluție OCR care să depășească deficiențele Google Cloud Vision? Dă Nanonets™ o rotire pentru o precizie mai mare, o flexibilitate mai mare și tipuri de documente mai largi!
Alternative
Următoarele sunt câteva servicii OCR alternative, altele decât API-ul Google Vision, împreună cu avantajele și dezavantajele fiecărui serviciu.
ABBYY
ABBYY FineReader PDF este un OCR dezvoltat de ABBYY, care se concentrează în special pe citirea pdf-urilor.
- Pro-uri: ABBYY este mult mai ieftin pentru utilizatorii individuali, deoarece prețul este segmentat în sectoare mai mici (1000, 2000 de pagini etc.). De asemenea, este direcționată către clienții care nu fac parte din inginerie, deoarece este o aplicație comercializată.
- Contra: Software-ul se concentrează doar pe formatul PDF, iar prețul devine foarte scump atunci când faceți OCR la scară largă.
- Când să utilizați: Pentru utilizatorii individuali care doresc doar să gestioneze rapid fișierele PDF, ABBYY poate fi o opțiune mai viabilă decât API-ul Google Vision, care oferă mai multă flexibilitate, dar necesită coduri suplimentare.
Microsoft
Microsoft Azure oferă, de asemenea, Read API pentru OCR.
- Pro-uri: Microsoft oferă un preț mai ieftin pentru un număr și mai mare de date de utilizat. Stocarea în cloud Azure oferă servicii similare cu Google Cloud.
- Contra: Nu există un nivel gratuit, în timp ce alte opțiuni oferă apeluri API gratuite pentru utilizare redusă.
- Când să utilizați: Conductele de producție OCR la scară foarte mare ar putea beneficia de prețurile Microsoft.
cofax
Similar cu ABBYY, Kofax oferă și citirea OCR a PDF-urilor
- Pro-uri: Prețul este fix pentru utilizare individuală, iar reducerile sunt oferite pentru întreprinderi. De asemenea, este oferit asistență pentru clienți 24/7.
- Contra: Se pretinde că calitatea nu este la fel de înaltă ca cea a lui ABBYY.
- Când să utilizați: Întreprinderi mici cu cerințe reduse de utilizare.
AWS Text
AWS Texttract are un rol foarte similar în comparație cu API-ul Google Vision. Serviciile și prețurile lor sunt foarte asemănătoare, așa că pe care să o adoptăm se bazează complet pe preferințele clienților.
Nanoneți
Spre deosebire de serviciile discutate anterior, OCR-urile Nanonets sunt clasificate în continuare în categorii specifice, cu modele robuste instruite pe fiecare tip de date (de exemplu, chitanțe, facturi, permise de conducere).
- Pro-uri: OCR-uri specifice categoriei, oferind astfel rezultate și mai bune în ceea ce privește acuratețea atunci când firmele necesită OCR pentru aplicații specifice țintei.
- Contra: Nanonets OCR poate fi mai puțin aplicabil setărilor în sălbăticie datorită modelelor foarte specifice și personalizate
- Când să utilizați: Dacă firmele necesită OCR pentru un anumit tip de date, cum ar fi facturile, Nanonets poate fi o opțiune ieftină și foarte precisă.
Poti încercați Nanonets Online OCR aici.
Probleme frecvente cu Cloud Vision
În această secțiune finală, ne propunem să abordăm câteva întrebări de la Stackoverflow cu privire la scanarea documentelor și OCR
Recunoașterea documentelor folosind rețele neuronale
Aceasta este utilizarea exactă a Google OCR! Urmați pașii de mai sus pentru a scana documente și pentru a efectua recuperarea textului.
Obținerea celor mai importante detalii după OCR
Ideea de a analiza conținutul cel mai semnificativ în orice document se numește procesare a limbajului natural. Deoarece fiecare document conține astfel de informații în formate diferite, ar fi recomandat să se adopte unele abordări ML pentru a face acest lucru. Desigur, dacă toate cardurile sunt în același format, ar trebui să funcționeze și metodele bazate pe reguli pentru a prelua textele cu anumite caractere cheie (de exemplu, dacă conține @ este un e-mail).
Poate rula offline?
Legătură: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Din pacate, nu. API-ul apelează Google Cloud OCR de la distanță și nu puteți lucra offline, deoarece API-ul costă bani.
Poate detecta dacă un text este îngroșat sau cursiv?
Nu. Cel mai probabil, Google OCR va detecta conținutul textului chiar și atunci când este scris cu caractere aldine sau cursive, dar modelul OCR nu este conceput pentru a înțelege tipurile de fonturi.
Actualizați: S-au adăugat mai multe informații pe baza interogărilor cititorilor.
- &
- a
- accelerat
- Cont
- precis
- peste
- activităţi de
- adresa
- Avantajele
- TOATE
- alternativă
- alternative
- mereu
- Sume
- analiză
- analiza
- O alta
- api
- API-uri
- aplicaţia
- aplicabil
- aplicație
- aplicatii
- aplicat
- abordari
- ZONĂ
- în jurul
- articol
- Bunuri
- Autentificare
- automatizarea
- Automata
- in medie
- Azuriu
- Azure Cloud
- fundal
- Băncile
- bază
- înainte
- beneficia
- Beneficiile
- facturare
- Bloca
- Manuale
- frontieră
- pauze
- mașină
- Carduri
- sigur
- caractere
- taxă
- încărcat
- mai ieftin
- control
- Oraș
- clasificare
- Cloud
- Stocare in cloud
- cod
- Comun
- Companii
- companie
- comparație
- complet
- calculator
- Calculatoare
- legat
- Lua în considerare
- Consoleze
- conține
- conţinut
- conținut
- Convertire
- Corporații
- Corespunzător
- Cheltuieli
- ar putea
- țări
- ţară
- crea
- a creat
- Crearea
- Curent
- client
- Relații Clienți
- clienţii care
- de date
- analiza datelor
- de prelucrare a datelor
- Baza de date
- baze de date
- zi
- abuzive
- decizie
- adânc
- Dependent/ă
- În funcție
- descrie
- proiectat
- detaliat
- detalii
- detectat
- Determina
- dezvoltat
- diferit
- dificil
- direcționa
- direct
- Diversitate
- Medici
- documente
- domenii
- jos
- conduce
- conducere
- fiecare
- easing
- Margine
- efort
- Eforturile
- a apărut
- permite
- încurajează
- Companii
- Mediu inconjurator
- mai ales
- În esență,
- etc
- exemple
- Ieşire
- extracte
- familii
- FAST
- DESCRIERE
- feedback-ul
- Taxe
- Finanţe
- financiar
- Firmă
- First
- fixată
- Flexibilitate
- se concentrează
- urma
- următor
- format
- formulare
- găsit
- Gratuit
- din
- funcţie
- funcții
- mai mult
- General
- obtinerea
- guvernamental
- guvernele
- mai mare
- manipula
- ajutor
- aici
- Înalt
- superior
- extrem de
- istorie
- spitale
- Cum
- Cum Pentru a
- HTTPS
- uman
- Oamenii
- idee
- imagine
- imagini
- important
- imposibil
- îmbunătăţi
- inclus
- include
- Inclusiv
- individ
- persoane fizice
- info
- informații
- instanță
- intuitiv
- probleme de
- IT
- în sine
- Java
- păstrare
- Cheie
- muncă
- limbă
- Limbă
- mare
- mai mare
- cea mai mare
- Conduce
- învăţare
- Nivel
- nivelurile de
- Bibliotecă
- Licență
- licențe
- stil de viaţă
- Probabil
- LINK
- local
- locaţie
- Locații
- Lung
- maşină
- masina de învățare
- Masini
- major
- face
- manieră
- manual
- Harta
- marca
- masiv
- sens
- semnificativ
- medical
- mediu
- menționat
- Metode
- Microsoft
- ML
- model
- Modele
- bani
- Lună
- mai mult
- cele mai multe
- muta
- multiplu
- Natural
- Natură
- nevoilor
- reţea
- cu toate acestea
- notițe
- număr
- numere
- numeroși
- oferit
- promoții
- oficial
- Offline
- on-line
- optimizate
- Opțiune
- Opţiuni
- comandă
- Organizat
- Altele
- propriu
- împachetat
- parcare
- parte
- special
- în special
- Care trece
- oameni
- poate
- Planurile
- platformă
- Police
- Popular
- puternic
- preţ
- de stabilire a prețurilor
- proces
- procese
- prelucrare
- producere
- Produse
- proiect
- proiecţiile
- promițător
- promoționale
- furniza
- prevăzut
- furnizează
- furnizarea
- achiziții
- calitate
- repede
- gamă
- variind
- RE
- cititori
- Citind
- recent
- recunoaște
- înregistrări
- cu privire la
- regiune
- la distanta
- necesita
- necesar
- Cerinţe
- Necesită
- cercetare
- Resurse
- răspuns
- REST
- REZULTATE
- drum
- Rol
- Alerga
- acelaşi
- scalabil
- Scară
- scanare
- scanare
- sectoare
- sens
- serie
- serviciu
- Servicii
- servire
- set
- instalare
- semnificativ
- Semne
- asemănător
- simplu
- întrucât
- mic
- So
- Software
- solid
- soluţie
- unele
- specific
- specific
- Rotire
- Stadiile
- început
- Declarații
- statistic
- statistică
- depozitare
- Strategie
- stradă
- structurat
- a sustine
- Sprijină
- Sondaj de opinie
- termeni
- prin urmare
- Prin
- de-a lungul
- timp
- ori
- astăzi
- față de
- tradiţional
- trafic
- Pregătire
- transferare
- transformare
- Tipuri
- în
- înţelege
- înţelegere
- de unităţi
- Universal
- utilizare
- utilizatorii
- obișnuit
- diverse
- viziune
- volum
- Ceas
- dacă
- în timp ce
- OMS
- mai larg
- ferestre
- în
- cuvinte
- Apartamente
- fabrică
- ar
- X
- an
- Ta