Amazon RedShift, un depozit de date cloud utilizat pe scară largă, a evoluat semnificativ pentru a îndeplini cerințele de performanță ale celor mai solicitante sarcini de lucru. Această postare acoperă o astfel de caracteristică nouă - cheia de sortare a aspectului de date multidimensional.
Amazon Redshift vă îmbunătățește acum performanța interogărilor prin acceptarea cheilor de sortare cu aspect de date multidimensionale, care este un nou tip de cheie de sortare care sortează datele unui tabel după predicate de filtrare în loc de coloanele fizice ale tabelului. Cheile de sortare cu aspect multidimensional de date vor îmbunătăți semnificativ performanța scanărilor tabelelor, mai ales atunci când volumul de lucru al interogărilor conține filtre de scanare repetitive.
Amazon Redshift oferă deja capacitatea de optimizarea automată a tabelului (ATO), care optimizează automat proiectarea tabelelor prin aplicarea cheilor de sortare și distribuție fără a fi nevoie de intervenția administratorului. În această postare, introducem cheile de sortare cu aspect multidimensional de date ca o capacitate suplimentară oferită de ATO și consolidată de algoritmul de consilier al cheii de sortare al Amazon Redshift.
Taste de sortare multidimensionale pentru aspectul datelor
Când definiți un tabel cu cheia de sortare AUTO, Amazon Redshift ATO va analiza istoricul interogărilor dvs. și va selecta automat fie o cheie de sortare pe o singură coloană, fie o cheie de sortare cu aspect multidimensional pentru tabelul dvs., în funcție de opțiunea care este mai bună pentru volumul de lucru. Când este selectat aspectul de date multidimensionale, Amazon Redshift va construi o funcție de sortare multidimensională care localizează în comun rândurile care sunt de obicei accesate de aceleași interogări, iar funcția de sortare este utilizată ulterior în timpul rulărilor de interogări pentru a ignora blocurile de date și chiar pentru a omite scanarea predicatului individual. coloane.
Luați în considerare următoarea interogare a utilizatorului, care este un model de interogare dominant în volumul de lucru al utilizatorului:
Amazon Redshift stochează datele pentru fiecare coloană în blocuri de disc de 1 MB și stochează valorile minime și maxime în fiecare bloc ca parte a metadatelor tabelului. Dacă o interogare folosește a predicat restrâns în gamă, Amazon Redshift poate folosi valorile minime și maxime pentru a trece rapid peste un număr mare de blocuri în timpul scanărilor de tabel. Cu toate acestea, filtrul acestei interogări din coloana subregiune nu poate fi folosit pentru a determina ce blocuri să omite pe baza valorilor minime și maxime și, ca urmare, Amazon Redshift scanează toate rândurile din tabelul cu titluri:
Când interogarea utilizatorului a fost executată cu titles folosind o cheie de sortare pe o singură coloană subregion, rezultatul interogării precedente este următorul:
Aceasta arată că scanarea tabelului a citit 2,164,081,640 de rânduri.
Pentru a îmbunătăți scanările pe titles tabel, Amazon Redshift ar putea decide automat să utilizeze o cheie de sortare a aspectului de date multidimensional. Toate rândurile care satisfac lower(subregion) like '%United States%' predicatul ar fi co-locat într-o regiune dedicată a tabelului și, prin urmare, Amazon Redshift va scana doar blocurile de date care satisfac predicatul.
Când interogarea utilizatorului este rulată cu titles folosind o cheie de sortare multidimensională a aspectului de date care include lower(subregion) like '%United States%' ca predicat, rezultatul sys_query_detail interogarea este după cum urmează:
Aceasta arată că scanarea tabelului a citit 152,324,046 de rânduri, ceea ce reprezintă doar 7% din original și a folosit cheia de sortare a aspectului de date multidimensional.
Rețineți că acest exemplu folosește o singură interogare pentru a prezenta caracteristica de aranjare a datelor multidimensionale, dar Amazon Redshift va lua în considerare toate interogările care rulează pe tabel și poate crea mai multe regiuni pentru a satisface predicatele cel mai frecvent executate.
Să luăm un alt exemplu, cu predicate mai complexe și interogări multiple de data aceasta.
Imaginează-ți că ai o masă items (cost int, available int, demand int) cu patru rânduri, așa cum se arată în exemplul următor.
| #id | costa | disponibil | cerere |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Volumul dvs. de lucru dominant este format din două interogări:
- 70% model de interogări:
- 20% model de interogări:
Cu tehnicile tradiționale de sortare, ați putea alege să sortați tabelul peste coloana de cost, astfel încât evaluarea cost > 3 va beneficia de acest fel. Deci, tabelul de articole după sortare folosind un singur cost coloana va arăta ca următorul.
| #id | costa | disponibil | cerere |
| Regiunea #1, cu cost <= 3 | |||
| Regiunea #2, cu cost > 3 | |||
| #id | costa | disponibil | cerere |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Folosind acest sort tradițional, putem exclude imediat primele două rânduri (albastre) cu ID 4 și ID 2, deoarece nu satisfac cost > 3.
Pe de altă parte, cu o cheie de sortare cu aspect de date multidimensionale, tabelul va fi sortat pe baza unei combinații a celor două predicate care apar frecvent în volumul de lucru al utilizatorului, care sunt cost > 3 și available < demand. Ca rezultat, rândurile tabelului sunt sortate în patru regiuni.
| #id | costa | disponibil | cerere |
| Regiunea #1, cu cost <= 3 și disponibil < cerere | |||
| Regiunea #2, cu cost <= 3 și disponibil >= cerere | |||
| Regiunea #3, cu cost > 3 și disponibil < cerere | |||
| Regiunea #4, cu cost > 3 și disponibil >= cerere | |||
| #id | costa | disponibil | cerere |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Acest concept este și mai puternic atunci când este aplicat la blocuri întregi în loc de rânduri unice, atunci când este aplicat la predicate complexe care folosesc operatori nepotriviți pentru tehnicile tradiționale de sortare (cum ar fi like), și atunci când se aplică la mai mult de două predicate.
Tabelele de sistem
Următoarele tabele de sistem Amazon Redshift vor arăta utilizatorilor dacă sunt utilizate machete de date multidimensionale în tabelele și interogările lor:
- Pentru a determina dacă un anumit tabel folosește o cheie de sortare cu aspect de date multidimensionale, puteți verifica dacă
sortkey1in svv_table_info este egal cuAUTO(SORTKEY(padb_internal_mddl_key_col)). - Pentru a determina dacă o anumită interogare folosește aspectul de date multidimensionale pentru a accelera scanarea tabelelor, puteți verifica
step_attributeîn sys_query_detail vedere. Valoarea va fi egală cumulti-dimensionaldacă în timpul scanării a fost folosită cheia de sortare a aspectului de date multidimensional a tabelului.
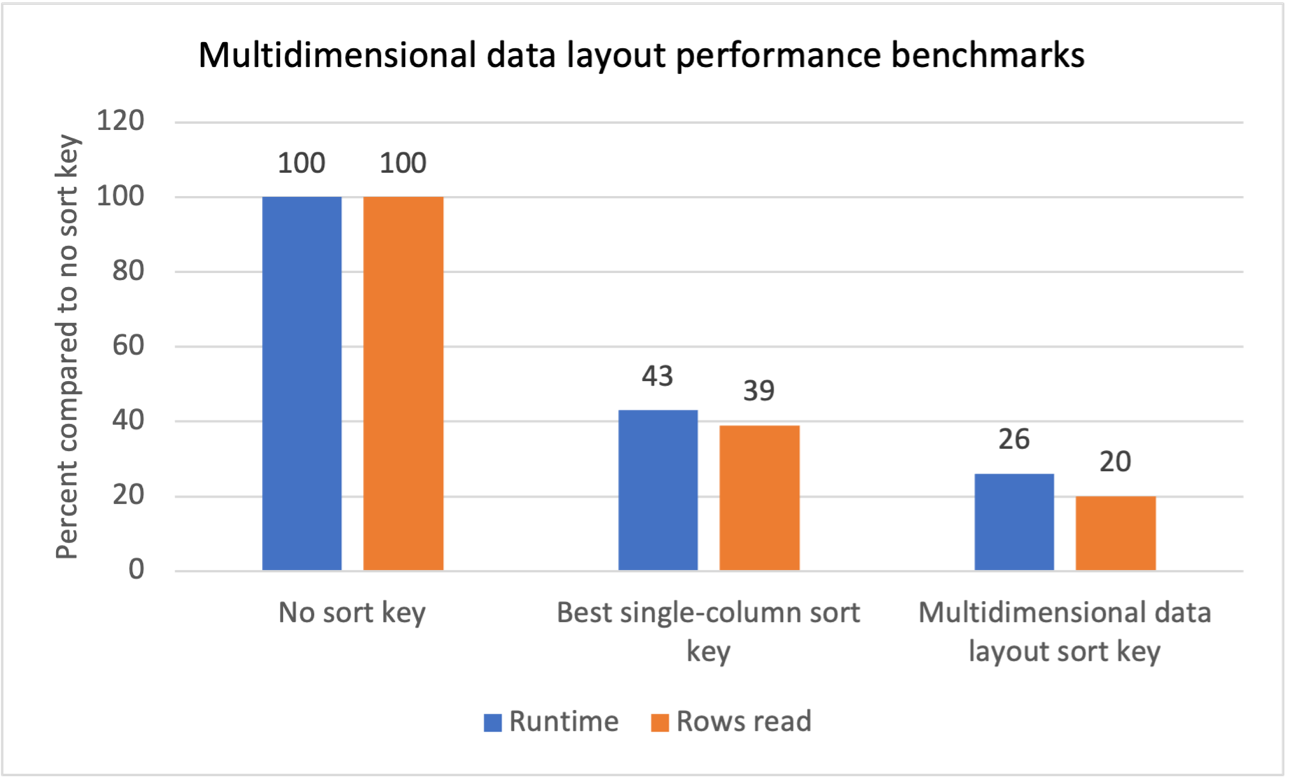
Benchmark-uri de performanță
Am efectuat teste interne de referință pentru mai multe sarcini de lucru cu filtre de scanare repetitivă și am constatat că introducerea cheilor de sortare cu aspect multidimensional de date a produs următoarele rezultate:
- O reducere totală a timpului de rulare cu 74% în comparație cu lipsa unei chei de sortare.
- O reducere totală a timpului de rulare cu 40% în comparație cu cea mai bună cheie de sortare pe o singură coloană din fiecare tabel.
- O reducere cu 80% a numărului total de rânduri citite din tabele, comparativ cu lipsa unei chei de sortare.
- O reducere cu 47% a numărului total de rânduri citite din tabele, comparativ cu cea mai bună cheie de sortare pe o singură coloană din fiecare tabel.
Comparație de caracteristici
Odată cu introducerea cheilor de sortare cu aspect de date multidimensionale, tabelele pot fi acum sortate după expresii bazate pe predicatele de filtru care apar frecvent în volumul de lucru. Următorul tabel oferă o comparație de caracteristici pentru Amazon Redshift față de doi concurenți.
| Caracteristică | Amazon RedShift | Concurentul A | Concurentul B |
| Suport pentru sortare pe coloane | Da | Da | Da |
| Suport pentru sortarea după expresie | Da | Da | Nu |
| Selectarea automată a coloanei pentru sortare | Da | Nu | Da |
| Selectarea automată a expresiilor pentru sortare | Da | Nu | Nu |
| Selectare automată între sortarea coloanelor sau sortarea expresiilor | Da | Nu | Nu |
| Utilizarea automată a proprietăților de sortare pentru expresii în timpul scanărilor | Da | Nu | Nu |
Considerații
Rețineți următoarele atunci când utilizați un aspect de date multidimensional:
- Dispunerea datelor multidimensionale este activată atunci când setați tabelul ca SORTKEY AUTO.
- Amazon Redshift Advisor va alege automat fie o cheie de sortare pe o singură coloană, fie un aspect multidimensional de date pentru tabel, analizând volumul de lucru istoric.
- Amazon Redshift ATO ajustează rezultatele sortării aspectului de date multidimensional în funcție de modul în care interogările în curs de desfășurare interacționează cu volumul de lucru.
- Amazon Redshift ATO menține cheile de sortare cu aspect de date multidimensionale în același mod ca în prezent pentru cheile de sortare existente. A se referi la Lucrul cu optimizarea automată a tabelului pentru mai multe detalii despre ATO.
- Cheile de sortare cu aspect de date multidimensionale vor funcționa atât cu clustere furnizate, cât și cu grupuri de lucru fără server.
- Cheile de sortare cu aspect de date multidimensionale vor funcționa cu datele dvs. existente atâta timp cât AUTO SORTKEY este activată pe tabelul dvs. și este detectată un volum de lucru cu filtre de scanare repetitive. Tabelul va fi reorganizat pe baza rezultatelor funcției de sortare multidimensională.
- Pentru a dezactiva cheile de sortare a aspectului de date multidimensionale pentru un tabel, utilizați alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Aceasta dezactivează caracteristica tastei de sortare AUTO de pe masă. - Cheile de sortare cu aspect de date multidimensionale sunt păstrate la restaurarea sau migrarea clusterului dumneavoastră furnizat la un cluster fără server sau invers.
Concluzie
În această postare, am arătat că cheile de sortare cu aspect multidimensional de date pot îmbunătăți semnificativ performanța de rulare a interogărilor pentru sarcinile de lucru în care interogările dominante au filtre de scanare repetitive.
Pentru a crea un cluster de previzualizare din consola Amazon Redshift, navigați la clusterele pagina și alegeți Creați un cluster de previzualizare. Puteți crea un cluster în Regiunile S.U.A. de Est (Ohio), S.U.A. de Est (Virginia de Nord), S.U.A. de Vest (Oregon), Asia Pacific (Tokyo), Europa (Irlanda) și Europa (Stockholm) și să vă testați sarcinile de lucru.
Ne-ar plăcea să auzim feedback-ul dumneavoastră despre această nouă funcție și așteptăm cu nerăbdare comentariile voastre la această postare.
Despre autori
 Milind Oke este un arhitect specializat în soluții de depozit de date cu sediul în New York. El construiește soluții de depozit de date de peste 15 ani și este specializat în Amazon Redshift.
Milind Oke este un arhitect specializat în soluții de depozit de date cu sediul în New York. El construiește soluții de depozit de date de peste 15 ani și este specializat în Amazon Redshift.
 Jialin Ding este un om de știință aplicat în Learned Systems Group, specializat în aplicarea tehnicilor de învățare automată și optimizare pentru a îmbunătăți performanța sistemelor de date precum Amazon Redshift.
Jialin Ding este un om de știință aplicat în Learned Systems Group, specializat în aplicarea tehnicilor de învățare automată și optimizare pentru a îmbunătăți performanța sistemelor de date precum Amazon Redshift.
 Yanzhu Ji este manager de produs în echipa Amazon Redshift. Ea are experiență în viziunea și strategia de produs în produse și platforme de date de vârf în industrie. Are abilități remarcabile în construirea de produse software substanțiale folosind dezvoltarea web, proiectarea sistemului, bazele de date și tehnicile de programare distribuită. În viața ei personală, lui Yanzhu îi place pictura, fotografia și jocul de tenis.
Yanzhu Ji este manager de produs în echipa Amazon Redshift. Ea are experiență în viziunea și strategia de produs în produse și platforme de date de vârf în industrie. Are abilități remarcabile în construirea de produse software substanțiale folosind dezvoltarea web, proiectarea sistemului, bazele de date și tehnicile de programare distribuită. În viața ei personală, lui Yanzhu îi place pictura, fotografia și jocul de tenis.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :are
- :este
- :nu
- :Unde
- 1
- 100
- ani 15
- 15%
- 152
- 7
- 8
- 9
- a
- accelera
- accesate
- Suplimentar
- consilier
- După
- împotriva
- Algoritmul
- TOATE
- deja
- Amazon
- Amazon Web Services
- an
- analiza
- analiza
- și
- O alta
- aplicat
- Aplicarea
- SUNT
- AS
- Asia
- Asia Pacific
- Auto
- Automat
- în mod automat
- disponibil
- AWS
- bazat
- BE
- deoarece
- fost
- Benchmark
- beneficia
- CEL MAI BUN
- Mai bine
- între
- Bloca
- Blocuri
- Albastru
- atât
- Clădire
- dar
- by
- CAN
- capacitate
- verifica
- Alege
- Cloud
- Grup
- Coloană
- Coloane
- combinaţie
- comentarii
- în mod obișnuit
- comparație
- comparație
- concurenți
- complex
- concept
- Lua în considerare
- constă
- Consoleze
- construi
- conține
- A costat
- acoperă
- crea
- În prezent
- de date
- depozit de date
- Baza de date
- decide
- dedicat
- defini
- Cerere
- cerând
- Amenajări
- detalii
- detectat
- Determina
- Dezvoltare
- distribuite
- distribuire
- face
- dominant
- Dont
- în timpul
- fiecare
- Est
- oricare
- activat
- Întreg
- egal
- mai ales
- Eter (ETH)
- Europa
- evaluare
- Chiar
- evoluat
- exemplu
- existent
- experienţă
- expresii
- Caracteristică
- feedback-ul
- filtru
- Filtre
- următor
- urmează
- Pentru
- Înainte
- patru
- din
- funcţie
- grup
- mână
- Avea
- având în
- he
- auzi
- ei
- istoric
- istorie
- Totuși
- HTML
- HTTPS
- ID
- if
- imediat
- îmbunătăţi
- îmbunătăţeşte
- in
- include
- individ
- lider în industrie
- in schimb
- interacţiona
- intern
- intervenţie
- în
- introduce
- introducerea
- Introducere
- Irlanda
- IT
- articole
- Cheie
- chei
- mare
- Aspect
- învățat
- învăţare
- Viaţă
- ca
- îi place
- Lung
- Uite
- arată ca
- dragoste
- maşină
- masina de învățare
- susține
- manager
- manieră
- maxim
- Întâlni
- Metadata
- ar putea
- Migrarea
- minte
- minim
- mai mult
- cele mai multe
- multiplu
- Navigaţi
- Nevoie
- Nou
- optiune noua
- New York
- Nu.
- acum
- numere
- care apar
- of
- de pe
- oferit
- Ohio
- on
- ONE
- în curs de desfășurare
- afară
- Operatorii
- optimizare
- Optimizează
- Opțiune
- or
- comandă
- Oregon
- original
- Altele
- afară
- remarcabil
- peste
- Pacific
- pictura
- parte
- special
- Model
- performanță
- efectuată
- personal
- fotografie
- fizic
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- joc
- Post
- puternic
- conservat
- Anunţ
- Produs
- Produs
- manager de produs
- Produse
- Programare
- proprietăţi
- furnizează
- interogări
- repede
- Citeste
- reducere
- trimite
- regiune
- regiuni
- repetitiv
- Cerinţe
- restabilirea
- rezultat
- REZULTATE
- Alerga
- funcţionare
- ruleaza
- acelaşi
- scanare
- scanare
- scanări
- Om de stiinta
- Sezon
- vedea
- selecta
- selectate
- selecţie
- serverless
- Servicii
- set
- ea
- Arăta
- prezenta
- a arătat
- indicat
- Emisiuni
- semnificativ
- singur
- calificare
- So
- Software
- soluţii
- specialist
- specializată
- specializata
- magazine
- Strategie
- Ulterior
- substanțial
- astfel de
- potrivit
- De sprijin
- sistem
- sisteme
- tabel
- Lua
- echipă
- tehnici de
- tenis
- test
- Testarea
- decât
- acea
- lor
- prin urmare
- ei
- acest
- timp
- titluri
- la
- Tokyo
- top
- Total
- tradiţional
- Două
- tip
- tipic
- us
- utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- valoare
- Valori
- viciu
- Vizualizare
- Virginia
- viziune
- Depozit
- a fost
- Cale..
- we
- web
- dezvoltare web
- servicii web
- Vest
- cand
- dacă
- care
- pe larg
- voi
- cu
- fără
- Apartamente
- ar
- ani
- York
- tu
- Ta
- zephyrnet