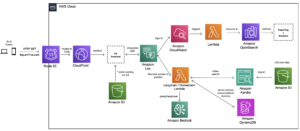
Astăzi, suntem încântați să anunțăm disponibilitatea inferenței Llama 2 și a suportului de reglare fină AWS Trainium și Inferentia AWS instanțe în Amazon SageMaker JumpStart. Utilizarea instanțelor bazate pe AWS Trainium și Inferentia, prin SageMaker, poate ajuta utilizatorii să reducă costurile de reglare fină cu până la 50% și să scadă costurile de implementare de 4.7 ori, reducând în același timp latența pe token. Llama 2 este un model de limbaj text generativ auto-regresiv care utilizează o arhitectură transformatoare optimizată. Ca model disponibil public, Llama 2 este proiectat pentru multe sarcini NLP, cum ar fi clasificarea textului, analiza sentimentelor, traducerea limbii, modelarea limbii, generarea de text și sistemele de dialog. Reglarea fină și implementarea LLM-urilor, cum ar fi Llama 2, pot deveni costisitoare sau provocatoare pentru a îndeplini performanța în timp real pentru a oferi o experiență bună pentru clienți. Trainium și AWS Inferentia, activate de AWS Neuron Kitul de dezvoltare software (SDK), oferă o opțiune de înaltă performanță și rentabilă pentru instruirea și deducerea modelelor Llama 2.
În această postare, demonstrăm cum să implementați și să reglați fin Llama 2 pe instanțele Trainium și AWS Inferentia în SageMaker JumpStart.
Prezentare generală a soluțiilor
În acest blog, vom parcurge următoarele scenarii:
- Implementați Llama 2 pe instanțe AWS Inferentia în ambele Amazon SageMaker Studio UI, cu o experiență de implementare cu un singur clic și SDK-ul SageMaker Python.
- Ajustați Llama 2 pe instanțele Trainium atât în interfața de utilizare SageMaker Studio, cât și în SDK-ul SageMaker Python.
- Comparați performanța modelului Llama 2 reglat cu cea a modelului pre-antrenat pentru a arăta eficiența reglajului fin.
Pentru a pune mâna pe mână, vezi Exemplu de notebook GitHub.
Implementați Llama 2 pe instanțe AWS Inferentia utilizând interfața de utilizare SageMaker Studio și SDK-ul Python
În această secțiune, demonstrăm cum să implementăm Llama 2 pe instanțe AWS Inferentia utilizând interfața de utilizare SageMaker Studio pentru o implementare cu un singur clic și SDK-ul Python.
Descoperiți modelul Llama 2 în interfața de utilizare SageMaker Studio
SageMaker JumpStart oferă acces atât la cele disponibile public, cât și la cele proprietare modele de fundație. Modelele de fundație sunt integrate și întreținute de la furnizori terți și proprietari. Ca atare, ele sunt eliberate sub diferite licențe, așa cum este desemnat de sursa modelului. Asigurați-vă că revizuiți licența pentru orice model de fundație pe care îl utilizați. Sunteți responsabil pentru revizuirea și respectarea oricăror termeni de licență aplicabili și pentru a vă asigura că aceștia sunt acceptabili pentru cazul dvs. de utilizare înainte de a descărca sau utiliza conținutul.
Puteți accesa modelele de fundație Llama 2 prin SageMaker JumpStart în SageMaker Studio UI și SageMaker Python SDK. În această secțiune, vom analiza cum să descoperiți modelele în SageMaker Studio.
SageMaker Studio este un mediu de dezvoltare integrat (IDE) care oferă o interfață vizuală unică bazată pe web, unde puteți accesa instrumente special create pentru a efectua toți pașii de dezvoltare a învățării automate (ML), de la pregătirea datelor până la construirea, instruirea și implementarea ML. modele. Pentru mai multe detalii despre cum să începeți și să configurați SageMaker Studio, consultați Amazon SageMaker Studio.
După ce vă aflați în SageMaker Studio, puteți accesa SageMaker JumpStart, care conține modele pre-antrenate, notebook-uri și soluții prefabricate, sub Soluții preconstruite și automatizate. Pentru informații mai detaliate despre cum să accesați modelele proprietare, consultați Utilizați modele proprietare de fond de ten de la Amazon SageMaker JumpStart în Amazon SageMaker Studio.
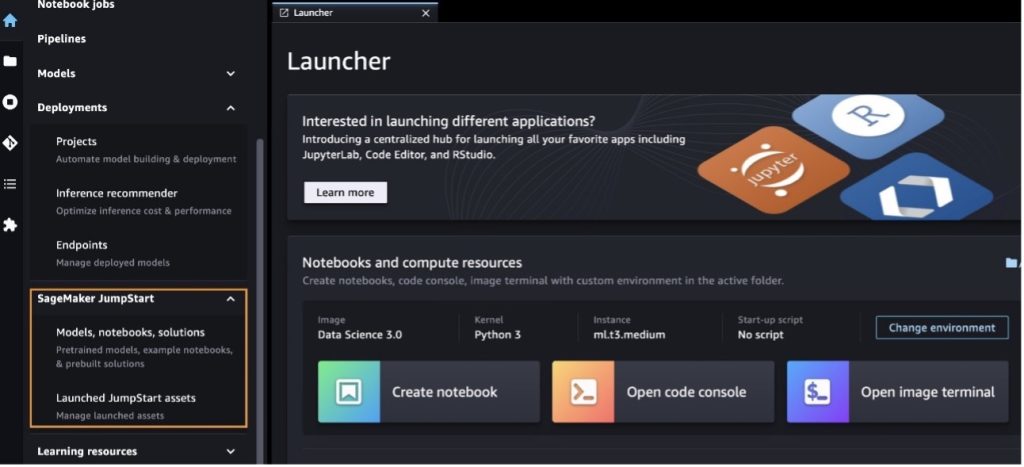
Din pagina de destinație SageMaker JumpStart, puteți căuta soluții, modele, notebook-uri și alte resurse.
Dacă nu vedeți modelele Llama 2, actualizați versiunea SageMaker Studio prin închiderea și repornirea. Pentru mai multe informații despre actualizările versiunii, consultați Închideți și actualizați aplicațiile Studio Classic.

Poti gasi si alte variante de model alegand Explorați toate modelele de generare de text sau căutarea llama or neuron în caseta de căutare. Veți putea vizualiza modelele Llama 2 Neuron pe această pagină.
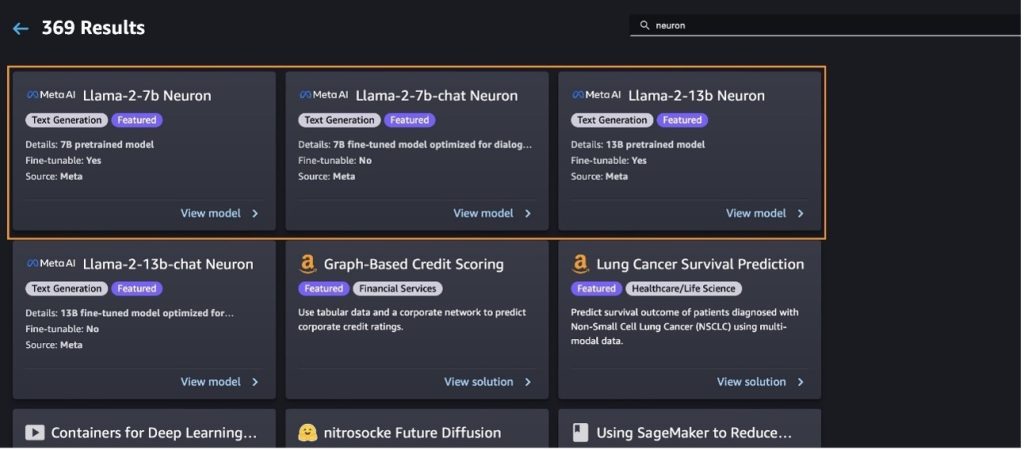
Implementați modelul Llama-2-13b cu SageMaker Jumpstart
Puteți alege cardul de model pentru a vedea detalii despre model, cum ar fi licența, datele utilizate pentru antrenament și modul de utilizare. De asemenea, puteți găsi două butoane, Lansa și Deschide caietul, care vă ajută să utilizați modelul folosind acest exemplu fără cod.
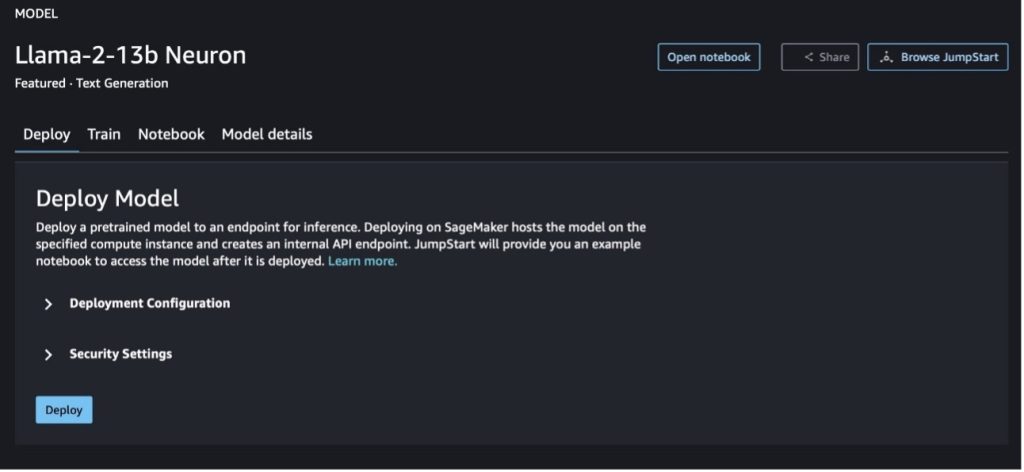
Când alegeți oricare dintre butoane, o fereastră pop-up va afișa Acordul de licență pentru utilizatorul final și Politica de utilizare acceptabilă (AUP) pe care să le confirmați.
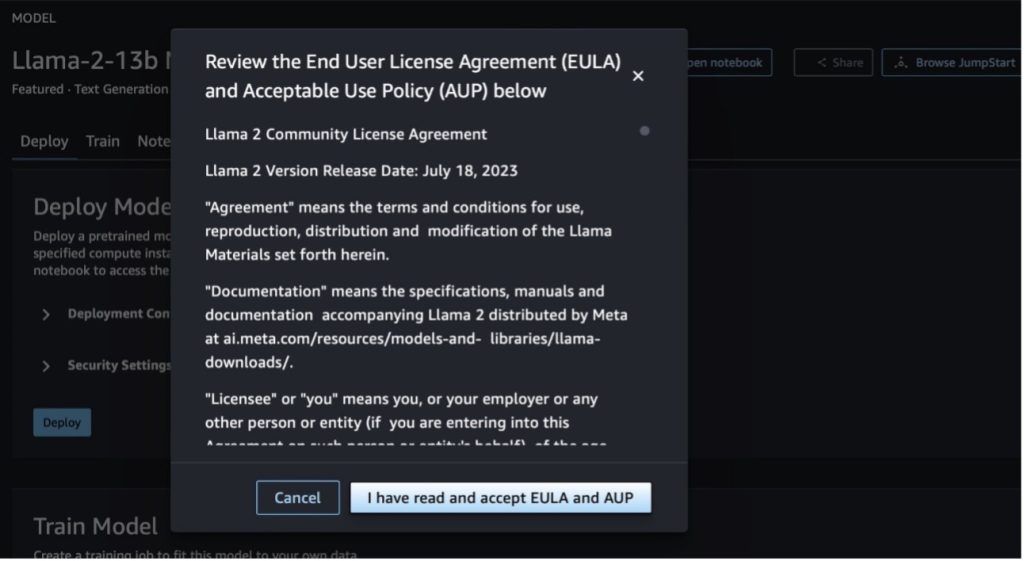
După ce confirmați politicile, puteți implementa punctul final al modelului și îl puteți utiliza prin pașii din secțiunea următoare.
Implementați modelul Llama 2 Neuron prin intermediul SDK-ului Python
Când alegi Lansa și acceptați termenii, va începe implementarea modelului. Alternativ, puteți implementa prin exemplul de blocnotes, alegând Deschide caietul. Exemplul de blocnotes oferă îndrumări de la capăt la capăt cu privire la modul de implementare a modelului pentru inferență și curățarea resurselor.
Pentru a implementa sau a regla fin un model pe instanțele Trainium sau AWS Inferentia, mai întâi trebuie să apelați PyTorch Neuron (torță-neuronx) pentru a compila modelul într-un grafic specific neuronului, care îl va optimiza pentru NeuronCores de la Inferentia. Utilizatorii pot instrui compilatorul să optimizeze pentru cea mai scăzută latență sau cel mai mare debit, în funcție de obiectivele aplicației. În JumpStart, am pre-compilat graficele Neuron pentru o varietate de configurații, pentru a permite utilizatorilor să bea pașii de compilare, permițând reglajul fin și implementarea modelelor mai rapid.
Rețineți că graficul pre-compilat Neuron este creat pe baza unei versiuni specifice a versiunii Neuron Compiler.
Există două moduri de a implementa LIama 2 pe instanțe bazate pe AWS Inferentia. Prima metodă utilizează configurația pre-construită și vă permite să implementați modelul în doar două linii de cod. În al doilea, aveți un control mai mare asupra configurației. Să începem cu prima metodă, cu configurația pre-construită și să folosim ca exemplu modelul neuron Llama 2 13B pre-antrenat. Următorul cod arată cum să implementați Llama 13B cu doar două linii:
Pentru a efectua inferențe asupra acestor modele, trebuie să specificați argumentul accept_eula pentru a fi True Ca parte a model.deploy() apel. Setarea acestui argument ca fiind adevărat, confirmă că ați citit și acceptat EULA-ul modelului. EULA poate fi găsit în descrierea cardului model sau din Meta site.
Tipul de instanță implicit pentru Llama 2 13B este ml.inf2.8xlarge. De asemenea, puteți încerca alte ID-uri de modele acceptate:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(model de chat)meta-textgenerationneuron-llama-2-13b-f(model de chat)
Alternativ, dacă doriți să aveți mai mult control asupra configurațiilor de implementare, cum ar fi lungimea contextului, gradul paralel al tensorului și dimensiunea maximă a lotului de rulare, le puteți modifica prin variabile de mediu, așa cum este demonstrat în această secțiune. Containerul de învățare profundă (DLC) de bază al implementării este DLC NeuronX de inferență pe modele mari (LMI).. Variabilele de mediu sunt următoarele:
- OPTION_N_POSITIONS – Numărul maxim de jetoane de intrare și de ieșire. De exemplu, dacă compilați modelul cu
OPTION_N_POSITIONSca 512, atunci puteți utiliza un jeton de intrare de 128 (dimensiunea promptului de intrare) cu un jeton de ieșire maxim de 384 (totalul jetonelor de intrare și de ieșire trebuie să fie 512). Pentru simbolul maxim de ieșire, orice valoare sub 384 este în regulă, dar nu puteți depăși (de exemplu, intrarea 256 și ieșirea 512). - OPTION_TENSOR_PARALLEL_DEGREE – Numărul de NeuronCores pentru a încărca modelul în instanțe AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – Dimensiunea maximă a lotului pentru solicitările concurente.
- OPTION_DTYPE – Tipul de dată pentru încărcarea modelului.
Compilarea graficului Neuron depinde de lungimea contextului (OPTION_N_POSITIONS), grad tensor paralel (OPTION_TENSOR_PARALLEL_DEGREE), dimensiunea maximă a lotului (OPTION_MAX_ROLLING_BATCH_SIZE), și tipul de date (OPTION_DTYPE) pentru a încărca modelul. SageMaker JumpStart are grafice Neuron pre-compilate pentru o varietate de configurații pentru parametrii precedenți, pentru a evita compilarea timpului de execuție. Configurațiile graficelor precompilate sunt enumerate în tabelul următor. Atâta timp cât variabilele de mediu se încadrează în una dintre următoarele categorii, compilarea graficelor neuronilor va fi omisă.
| LIama-2 7B și LIama-2 7B Chat | ||||
| Tipul instanței | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B și LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Următorul este un exemplu de implementare a Llama 2 13B și setarea tuturor configurațiilor disponibile.
Acum că am implementat modelul Llama-2-13b, putem rula inferențe cu acesta invocând punctul final. Următorul fragment de cod demonstrează utilizarea parametrilor de inferență acceptați pentru a controla generarea de text:
- lungime maxima – Modelul generează text până când lungimea de ieșire (care include lungimea contextului de intrare) atinge
max_length. Dacă este specificat, trebuie să fie un număr întreg pozitiv. - max_new_tokens – Modelul generează text până când lungimea de ieșire (excluzând lungimea contextului de intrare) atinge
max_new_tokens. Dacă este specificat, trebuie să fie un număr întreg pozitiv. - num_grinzi – Aceasta indică numărul de fascicule utilizate în căutarea lacomă. Dacă este specificat, trebuie să fie un număr întreg mai mare sau egal cu
num_return_sequences. - no_repeat_ngram_size – Modelul asigură că o succesiune de cuvinte de
no_repeat_ngram_sizenu se repetă în secvența de ieșire. Dacă este specificat, trebuie să fie un număr întreg pozitiv mai mare decât 1. - temperatură – Acest lucru controlează aleatoritatea în ieșire. O temperatură mai mare are ca rezultat o secvență de ieșire cu cuvinte cu probabilitate scăzută; o temperatură mai scăzută are ca rezultat o secvență de ieșire cu cuvinte cu probabilitate mare. Dacă
temperatureeste egal cu 0, rezultă o decodare lacomă. Dacă este specificat, trebuie să fie un float pozitiv. - oprire_devreme - În cazul în care
True, generarea textului este terminată când toate ipotezele fasciculului ajung la sfârșitul simbolului propoziției. Dacă este specificat, trebuie să fie boolean. - do_sample - În cazul în care
True, modelul eșantionează următorul cuvânt în funcție de probabilitate. Dacă este specificat, trebuie să fie boolean. - top_k – În fiecare pas de generare a textului, modelul prelevează numai din
top_kcuvintele cel mai probabil. Dacă este specificat, trebuie să fie un număr întreg pozitiv. - sus_p – În fiecare pas de generare a textului, modelul prelevează din cel mai mic set posibil de cuvinte cu o probabilitate cumulată de
top_p. Dacă este specificat, acesta trebuie să fie un float între 0-1. - opri – Dacă este specificat, trebuie să fie o listă de șiruri. Generarea textului se oprește dacă este generat oricare dintre șirurile specificate.
Următorul cod arată un exemplu:
producție:
Pentru mai multe informații despre parametrii din sarcina utilă, consultați Parametri detaliate.
De asemenea, puteți explora implementarea parametrilor din caiet pentru a adăuga mai multe informații despre link-ul caietului.
Ajustați modelele Llama 2 pe instanțele Trainium utilizând interfața de utilizare SageMaker Studio și SDK-ul SageMaker Python
Modelele de bază ale AI generative au devenit un obiectiv principal în ML și AI, cu toate acestea, generalizarea lor largă poate fi insuficientă în domenii specifice, cum ar fi asistența medicală sau serviciile financiare, în care sunt implicate seturi de date unice. Această limitare evidențiază necesitatea de a ajusta aceste modele AI generative cu date specifice domeniului pentru a le îmbunătăți performanța în aceste domenii specializate.
Acum, că am implementat versiunea pre-antrenată a modelului Llama 2, să vedem cum putem ajusta aceasta la datele specifice domeniului pentru a crește acuratețea, a îmbunătăți modelul în ceea ce privește completările prompte și a adapta modelul la cazul și datele dvs. specifice de utilizare în afaceri. Puteți ajusta modelele folosind fie SageMaker Studio UI, fie SageMaker Python SDK. Discutăm ambele metode în această secțiune.
Reglați fin modelul Llama-2-13b Neuron cu SageMaker Studio
În SageMaker Studio, navigați la modelul Llama-2-13b Neuron. Pe Lansa fila, puteți indica spre Serviciul Amazon de stocare simplă Bucket (Amazon S3) care conține seturile de date de instruire și validare pentru reglare fină. În plus, puteți configura configurația de implementare, hiperparametrii și setările de securitate pentru reglare fină. Atunci alege Tren pentru a începe munca de instruire pe o instanță SageMaker ML.

Pentru a utiliza modelele Llama 2, trebuie să acceptați EULA și AUP. Va apărea când vei alege Tren. Alege Am citit și accept EULA și AUP pentru a începe lucrarea de reglare fină.
Puteți vedea starea activității dvs. de antrenament pentru modelul ajustat în consola SageMaker, alegând Locuri de muncă de formare în panoul de navigare.
Puteți fie să vă reglați fin modelul Llama 2 Neuron utilizând acest exemplu fără cod, fie să îl reglați fin prin intermediul SDK-ului Python, așa cum este demonstrat în secțiunea următoare.
Ajustați modelul Llama-2-13b Neuron prin intermediul SDK-ului SageMaker Python
Puteți ajusta setul de date cu formatul de adaptare a domeniului sau reglare fină bazată pe instrucțiuni format. Următoarele sunt instrucțiunile despre modul în care datele de antrenament ar trebui să fie formatate înainte de a fi trimise în reglare fină:
- Intrare - A
traindirector care conține fie un fișier formatat cu linii JSON (.jsonl) sau text (.txt).- Pentru fișierul linii JSON (.jsonl), fiecare linie este un obiect JSON separat. Fiecare obiect JSON ar trebui să fie structurat ca o pereche cheie-valoare, unde ar trebui să fie cheia
text, iar valoarea este conținutul unui exemplu de antrenament. - Numărul de fișiere din directorul trenului ar trebui să fie egal cu 1.
- Pentru fișierul linii JSON (.jsonl), fiecare linie este un obiect JSON separat. Fiecare obiect JSON ar trebui să fie structurat ca o pereche cheie-valoare, unde ar trebui să fie cheia
- producție – Un model antrenat care poate fi implementat pentru inferență.
În acest exemplu, folosim un subset al Setul de date Dolly într-un format de reglare a instrucțiunilor. Setul de date Dolly conține aproximativ 15,000 de înregistrări de urmărire a instrucțiunilor pentru diferite categorii, cum ar fi răspunsul la întrebări, rezumatul și extragerea de informații. Este disponibil sub licența Apache 2.0. Noi folosim information_extraction exemple de reglare fină.
- Încărcați setul de date Dolly și împărțiți-l în
train(pentru reglaj fin) șitest(pentru evaluare):
- Utilizați un șablon prompt pentru preprocesarea datelor într-un format de instrucțiuni pentru jobul de instruire:
- Examinați hiperparametrii și suprascrieți-i pentru propriul caz de utilizare:
- Ajustați modelul și începeți o muncă de instruire SageMaker. Scripturile de reglare fină se bazează pe neuronx-nemo-megatron depozit, care sunt versiuni modificate ale pachetelor nemo și Apex care au fost adaptate pentru utilizare cu instanțe Neuron și EC2 Trn1. The neuronx-nemo-megatron depozitul are paralelism 3D (date, tensor și conductă) pentru a vă permite să reglați fin LLM-urile la scară. Instanțele Trainium acceptate sunt ml.trn1.32xlarge și ml.trn1n.32xlarge.
- În cele din urmă, implementați modelul reglat fin într-un punct final SageMaker:
Comparați răspunsurile dintre modelele Llama 2 Neuron pre-antrenate și cele reglate fin
Acum că am implementat versiunea pre-antrenată a modelului Llama-2-13b și am reglat-o fin, putem vedea câteva dintre comparațiile de performanță ale completărilor prompte de la ambele modele, așa cum se arată în tabelul următor. Oferim, de asemenea, un exemplu de reglare fină a Llama 2 pe un set de date de înregistrare SEC în format .txt. Pentru detalii, consultați Exemplu de notebook GitHub.
| Articol | Intrări | Adevărul de bază | Răspuns de la modelul neajustat | Răspuns de la modelul reglat fin |
| 1 | Mai jos este o instrucțiune care descrie o sarcină, asociată cu o intrare care oferă context suplimentar. Scrieți un răspuns care completează în mod corespunzător solicitarea.nn### Instrucțiune:nExtrageți universitățile la care a studiat Moret și anul de absolvire pentru fiecare și puneți-le într-o listă cu marcatori.nn### Intrare:nMoret sa născut în 1953 în Vevey, Elveția , și și-a făcut studiile universitare la École Polytechnique Fédérale de Lausanne (EPFL), absolvind în 1975. A continuat studiile postuniversitare la Universitatea din Tennessee, obținând un doctorat. în 1980. S-a alăturat apoi la facultatea Universității din New Mexico, unde a rămas până în 2006, când s-a mutat la EPFL. Sa retras de la EPFL în decembrie 2016.nnÎn 1996, Moret a fondat ACM Journal of Experimental Algorithmics și a rămas redactor-șef al revistei până în 2003. În 2001, Moret a fondat Workshop in Algorithms for Bioinformatics (WABI) și rămâne pe Comitetul de conducere al conferinței.nnÎn 2018, Moret a fost ales ca membru al Societății Internaționale de Biologie Computațională, pentru contribuțiile sale remarcabile în domeniile biologiei computaționale și bioinformaticii.nn### Răspuns:n | * École Polytechnique Fédérale de Lausanne (EPFL) (a absolvit 1975)n* Universitatea din Tennessee (a absolvit 1980) | Moret a studiat la École Polytechnique Fédérale de Lausanne (EPFL) și la Universitatea din Tennessee, absolvind în 1975 și, respectiv, 1980.nn### Sugestie:nn- Folosiți funcția `split` pentru a împărți intrarea într-o listă de propoziții.n- Utilizați funcția `split` pentru a împărți fiecare propoziție într-o listă de cuvinte.n- Utilizați funcția `split` pentru a împărți | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexico-École Polytechnique Fédérale de Lausanne (EPFL),2006nn Mai jos este o instrucțiune care descrie o sarcină, asociată cu o intrare care oferă un context suplimentar. Scrieți un răspuns care completează în mod corespunzător cererea.n |
| 2 | Mai jos este o instrucțiune care descrie o sarcină, asociată cu o intrare care oferă context suplimentar. Scrieți un răspuns care completează în mod corespunzător cererea.nn### Instrucțiune:nDin pasaj identificați atributele lui Dionysos. Afișați rezultatele într-un format separat prin virgulă.nn### Intrare:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnZeul vinului, rodniciei, petrecerilor, festivalurilor, nebuniei, haosului, beției, vegetației, extazului și teatru. Este fiul născut de două ori al lui Zeus și Semele, prin aceea că Zeus l-a smuls din pântecele mamei sale și l-a cusut pe Dionysos în propria coapsă și l-a purtat până când a fost gata să se nască. În artă, el este reprezentat fie ca un zeu cu barbă mai bătrân (în special înainte de 430 î.Hr.), fie ca un tânăr efeminat, cu părul lung (în special după 430 î.Hr.). Atributele sale includ tirsul, o ceașcă de băut, vița de vie și o coroană de iederă. El este adesea în compania thiasosului său, un grup de însoțitori, inclusiv satiri, menade și vechiul său tutor Silenus. Consoarta lui Dionysos a fost Ariadna. S-a susținut cândva că Dionysius a fost o adăugare ulterioară la panteonul grec, dar descoperirea tăblițelor Linear B confirmă statutul său de zeitate dintr-o perioadă timpurie. Bacchus a fost un alt nume pentru el în greacă și a intrat în uz comun printre romani. Animalele sale sacre includ delfini, șerpi, tigri și măgari.nn### Răspuns:n | tirsul, o cană de băut, vița de vie, o coroană de iederă | Dionysos (Διόνυσος, Diónusos)nnZeul vinului, al rodniciei, al petrecerilor, al festivalurilor, al nebuniei, al haosului, al beției, al vegetației, al extazului și al teatrului. El este fiul născut de două ori al lui Zeus și Semele, prin aceea că Zeus l-a smuls din pântecele mamei sale și l-a cusut pe Dionysos în propria coapsă. | tirs, o ceașcă de băut, vița de vie, o coroană de ivynn Mai jos este o instrucțiune care descrie o sarcină, asociată cu o intrare care oferă context suplimentar. Scrieți un răspuns care completează în mod corespunzător solicitarea.nn### Instrucțiune:nCare este diferența dintre Imperiul Parth și Arsacid?nn### Intrare:nImperiul Parth, cunoscut și sub numele de Imperiul Arsacid, a fost un |
| 3 | Mai jos este o instrucțiune care descrie o sarcină, asociată cu o intrare care oferă context suplimentar. Scrieți un răspuns care completează în mod corespunzător solicitarea.nn### Instrucțiune:nDe ce capitala Uzbekistanului conține cea mai mare comunitate grecească?nn### Intrare:nGrecii din Uzbekistan sunt aproximativ 9,000. Comunitatea este formată din greci din Rusia care au fost deportați cu forța din acea țară în Uzbekistan în anii 1940 și refugiați politici din Grecia. Aproximativ 30,000 de greci au trăit în țară înainte de al Doilea Război Mondial și alți 11,000 au sosit după Războiul Civil grec și înfrângerea Armatei Democrate a Greciei. Numărul lor a scăzut de la un maxim de aproximativ 40,000 în anii 1960. Motivul principal este emigrarea în Grecia după sfârșitul Războiului Rece, când legile au permis întoarcerea tuturor etnicilor greci care au fost exilați din motive politice după Războiul Civil grec. Cea mai mare comunitate grecească din țară se află în capitala Tașkent, unde majoritatea refugiaților politici greci au fost relocați de autoritățile sovietice. În antichitate, sudul țării făcea parte din Regatul elenistic seleucid, dar puținele comunități grecești de acolo s-au asimilat de atunci. Cea mai importantă organizație care reprezintă etnicii greci este Asociația Culturală Greacă din Tașkent. Activitățile acestei organizații includ predarea limbii greacă (19 clase cu un total de 571 de elevi, cursuri pentru adulți) și predarea dansurilor și muzicii grecești.nn### Răspuns:n | Majoritatea refugiaților politici greci din Uzbekistan au fost relocați de autoritățile sovietice în capitala Tașkent. | n“`nCapitala Uzbekistanului conține cea mai mare comunitate grecească, deoarece grecii din Uzbekistan sunt aproximativ 9,000. Comunitatea este formată din greci din Rusia care au fost deportați cu forța din acea țară în Uzbekistan în anii 1940 și refugiați politici din Grecia. Aproximativ 30,000 de greci au trăit în țară înainte de al Doilea Război Mondial și încă 11,00 | Capitala Uzbekistanului conține cea mai mare comunitate greacă, deoarece acolo au fost relocați cei mai mulți dintre refugiații politici greci de către autoritățile sovietice după ce au fost deportați din Grecia.nn Mai jos este o instrucțiune care descrie o sarcină, împreună cu o intrare care oferă context mai departe. Scrieți un răspuns care completează în mod corespunzător cererea.nn### Instrucțiune:nCare este diferența dintre Imperiul Parth și Arsacid?nn### Intrare:n |
Putem vedea că răspunsurile de la modelul reglat fin demonstrează o îmbunătățire semnificativă a preciziei, relevanței și clarității în comparație cu cele din modelul pre-antrenat. În unele cazuri, utilizarea modelului pre-antrenat pentru cazul dvs. de utilizare ar putea să nu fie suficientă, așa că reglarea fină a acestuia folosind această tehnică va face soluția mai personalizată pentru setul dvs. de date.
A curăța
După ce ați terminat munca de formare și nu doriți să mai folosiți resursele existente, ștergeți resursele folosind următorul cod:
Concluzie
Implementarea și reglarea fină a modelelor Llama 2 Neuron pe SageMaker demonstrează un progres semnificativ în gestionarea și optimizarea modelelor AI generative la scară largă. Aceste modele, inclusiv variante precum Llama-2-7b și Llama-2-13b, folosesc Neuron pentru antrenament și inferență eficientă asupra instanțelor bazate pe AWS Inferentia și Trainium, îmbunătățind performanța și scalabilitatea acestora.
Abilitatea de a implementa aceste modele prin SageMaker JumpStart UI și Python SDK oferă flexibilitate și ușurință în utilizare. Neuron SDK, cu suportul său pentru cadrele ML populare și capabilitățile de înaltă performanță, permite manipularea eficientă a acestor modele mari.
Reglarea fină a acestor modele pe date specifice domeniului este crucială pentru îmbunătățirea relevanței și acurateței lor în domenii specializate. Procesul, pe care îl puteți desfășura prin SageMaker Studio UI sau Python SDK, permite personalizarea la nevoi specifice, ceea ce duce la îmbunătățirea performanței modelului în ceea ce privește completările prompte și calitatea răspunsului.
Comparativ, versiunile pre-antrenate ale acestor modele, deși puternice, pot oferi răspunsuri mai generice sau repetitive. Reglarea fină adaptează modelul la contexte specifice, rezultând răspunsuri mai precise, relevante și mai diverse. Această personalizare este deosebit de evidentă atunci când se compară răspunsurile de la modele pre-antrenate și cele reglate, unde acestea din urmă demonstrează o îmbunătățire vizibilă a calității și specificității rezultatelor. În concluzie, implementarea și reglarea fină a modelelor Neuron Llama 2 pe SageMaker reprezintă un cadru robust pentru gestionarea modelelor AI avansate, oferind îmbunătățiri semnificative în performanță și aplicabilitate, mai ales atunci când sunt adaptate unor domenii sau sarcini specifice.
Începeți azi prin referire la exemplul SageMaker caiet.
Pentru mai multe informații despre implementarea și reglarea fină a modelelor Llama 2 pre-antrenate pe instanțele bazate pe GPU, consultați Reglați fin Llama 2 pentru generarea de text pe Amazon SageMaker JumpStart și Modelele de fond de ten Llama 2 de la Meta sunt acum disponibile în Amazon SageMaker JumpStart.
Autorii ar dori să recunoască contribuțiile tehnice ale lui Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne și Mike James.
Despre Autori
 Xin Huang este cercetător aplicat senior pentru algoritmii încorporați Amazon SageMaker JumpStart și Amazon SageMaker. El se concentrează pe dezvoltarea de algoritmi scalabili de învățare automată. Interesele sale de cercetare sunt în domeniul prelucrării limbajului natural, al învățării profunde explicabile pe date tabulare și al analizei robuste a grupării non-parametrice spațiu-timp. A publicat multe lucrări în ACL, ICDM, conferințe KDD și Royal Statistical Society: Series A.
Xin Huang este cercetător aplicat senior pentru algoritmii încorporați Amazon SageMaker JumpStart și Amazon SageMaker. El se concentrează pe dezvoltarea de algoritmi scalabili de învățare automată. Interesele sale de cercetare sunt în domeniul prelucrării limbajului natural, al învățării profunde explicabile pe date tabulare și al analizei robuste a grupării non-parametrice spațiu-timp. A publicat multe lucrări în ACL, ICDM, conferințe KDD și Royal Statistical Society: Series A.
 Nitin Eusebiu este arhitect senior de soluții de întreprindere la AWS, cu experiență în inginerie software, arhitectură întreprindere și AI/ML. El este profund pasionat de explorarea posibilităților AI generative. El colaborează cu clienții pentru a-i ajuta să construiască aplicații bine arhitecturate pe platforma AWS și este dedicat rezolvării provocărilor tehnologice și asistenței în călătoria lor în cloud.
Nitin Eusebiu este arhitect senior de soluții de întreprindere la AWS, cu experiență în inginerie software, arhitectură întreprindere și AI/ML. El este profund pasionat de explorarea posibilităților AI generative. El colaborează cu clienții pentru a-i ajuta să construiască aplicații bine arhitecturate pe platforma AWS și este dedicat rezolvării provocărilor tehnologice și asistenței în călătoria lor în cloud.
 Madhur Prashant lucrează în spațiul AI generativ la AWS. Este pasionat de intersecția dintre gândirea umană și inteligența artificială generativă. Interesele sale constau în IA generativă, în special construirea de soluții care sunt utile și inofensive și, mai ales, optime pentru clienți. În afara serviciului, îi place să facă yoga, să facă drumeții, să petreacă timp cu geamănul său și să cânte la chitară.
Madhur Prashant lucrează în spațiul AI generativ la AWS. Este pasionat de intersecția dintre gândirea umană și inteligența artificială generativă. Interesele sale constau în IA generativă, în special construirea de soluții care sunt utile și inofensive și, mai ales, optime pentru clienți. În afara serviciului, îi place să facă yoga, să facă drumeții, să petreacă timp cu geamănul său și să cânte la chitară.
 Dewan Choudhury este inginer de dezvoltare software cu Amazon Web Services. Lucrează la algoritmii Amazon SageMaker și la ofertele JumpStart. Pe lângă construirea de infrastructuri AI/ML, el este și pasionat de construirea de sisteme distribuite scalabile.
Dewan Choudhury este inginer de dezvoltare software cu Amazon Web Services. Lucrează la algoritmii Amazon SageMaker și la ofertele JumpStart. Pe lângă construirea de infrastructuri AI/ML, el este și pasionat de construirea de sisteme distribuite scalabile.
 Hao Zhou este cercetător de știință la Amazon SageMaker. Înainte de asta, a lucrat la dezvoltarea metodelor de învățare automată pentru detectarea fraudelor pentru Amazon Fraud Detector. Este pasionat de aplicarea tehnicilor de învățare automată, optimizare și AI generativă la diferite probleme din lumea reală. Este doctor în inginerie electrică de la Universitatea Northwestern.
Hao Zhou este cercetător de știință la Amazon SageMaker. Înainte de asta, a lucrat la dezvoltarea metodelor de învățare automată pentru detectarea fraudelor pentru Amazon Fraud Detector. Este pasionat de aplicarea tehnicilor de învățare automată, optimizare și AI generativă la diferite probleme din lumea reală. Este doctor în inginerie electrică de la Universitatea Northwestern.
 Qing Lan este inginer de dezvoltare software în AWS. El a lucrat la mai multe produse provocatoare în Amazon, inclusiv soluții de inferență ML de înaltă performanță și un sistem de înregistrare de înaltă performanță. Echipa Qing a lansat cu succes primul model cu miliard de parametri în Amazon Advertising, cu o latență foarte scăzută necesară. Qing are cunoștințe aprofundate despre optimizarea infrastructurii și accelerarea Deep Learning.
Qing Lan este inginer de dezvoltare software în AWS. El a lucrat la mai multe produse provocatoare în Amazon, inclusiv soluții de inferență ML de înaltă performanță și un sistem de înregistrare de înaltă performanță. Echipa Qing a lansat cu succes primul model cu miliard de parametri în Amazon Advertising, cu o latență foarte scăzută necesară. Qing are cunoștințe aprofundate despre optimizarea infrastructurii și accelerarea Deep Learning.
 Dr. Ashish Khetan este un om de știință senior aplicat cu algoritmi încorporați Amazon SageMaker și ajută la dezvoltarea algoritmilor de învățare automată. Și-a luat doctoratul la Universitatea din Illinois Urbana-Champaign. Este un cercetător activ în învățarea automată și inferența statistică și a publicat multe lucrări în conferințele NeurIPS, ICML, ICLR, JMLR, ACL și EMNLP.
Dr. Ashish Khetan este un om de știință senior aplicat cu algoritmi încorporați Amazon SageMaker și ajută la dezvoltarea algoritmilor de învățare automată. Și-a luat doctoratul la Universitatea din Illinois Urbana-Champaign. Este un cercetător activ în învățarea automată și inferența statistică și a publicat multe lucrări în conferințele NeurIPS, ICML, ICLR, JMLR, ACL și EMNLP.
 Dr. Li Zhang este un director de produs principal-tehnic pentru Amazon SageMaker JumpStart și Amazon SageMaker algoritmi încorporați, un serviciu care îi ajută pe oamenii de știință de date și pe practicanții de învățare automată să înceapă cu instruirea și implementarea modelelor lor și utilizează învățarea prin consolidare cu Amazon SageMaker. Activitatea sa anterioară ca membru principal al personalului de cercetare și inventator principal la IBM Research a câștigat premiul pentru lucrări de testare a timpului la IEEE INFOCOM.
Dr. Li Zhang este un director de produs principal-tehnic pentru Amazon SageMaker JumpStart și Amazon SageMaker algoritmi încorporați, un serviciu care îi ajută pe oamenii de știință de date și pe practicanții de învățare automată să înceapă cu instruirea și implementarea modelelor lor și utilizează învățarea prin consolidare cu Amazon SageMaker. Activitatea sa anterioară ca membru principal al personalului de cercetare și inventator principal la IBM Research a câștigat premiul pentru lucrări de testare a timpului la IEEE INFOCOM.
 Kamran Khan, Senior Technical Business Development Manager pentru AWS Inferentina/Trianium la AWS. Are peste un deceniu de experiență în a ajuta clienții să implementeze și să optimizeze antrenamentul de deep learning și sarcinile de lucru de inferență folosind AWS Inferentia și AWS Trainium.
Kamran Khan, Senior Technical Business Development Manager pentru AWS Inferentina/Trianium la AWS. Are peste un deceniu de experiență în a ajuta clienții să implementeze și să optimizeze antrenamentul de deep learning și sarcinile de lucru de inferență folosind AWS Inferentia și AWS Trainium.
 Joe Senerchia este Senior Product Manager la AWS. El definește și construiește instanțe Amazon EC2 pentru învățare profundă, inteligență artificială și sarcini de lucru de calcul de înaltă performanță.
Joe Senerchia este Senior Product Manager la AWS. El definește și construiește instanțe Amazon EC2 pentru învățare profundă, inteligență artificială și sarcini de lucru de calcul de înaltă performanță.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- capacitate
- Capabil
- Despre Noi
- accelerare
- Accept
- acceptabil
- admis
- acces
- precizie
- precis
- recunoaște
- ACM
- activ
- activităţi de
- Adam
- adapta
- adaptare
- adaptate
- adăuga
- plus
- adulți
- avansat
- avansare
- Promovare
- După
- Acord
- AI
- Modele AI
- AI / ML
- algoritmi
- TOATE
- permite
- permis
- permite
- de asemenea
- Amazon
- Amazon EC2
- Detector de fraude Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- printre
- an
- analiză
- Vechi
- și
- animale
- anunța
- O alta
- Orice
- mai
- Apache
- separat
- aplicabil
- aplicație
- aplicatii
- aplicat
- Aplicarea
- în mod corespunzător
- aproximativ
- arhitectură
- SUNT
- ZONĂ
- domenii
- argument
- Armată
- a sosit
- Artă
- artificial
- inteligență artificială
- AS
- asistarea
- Asociație
- At
- însoţitorii
- atribute
- Autoritățile
- Autorii
- Automata
- disponibilitate
- disponibil
- evita
- AWS
- Inferentia AWS
- b
- bazat
- BE
- Grindă
- deoarece
- deveni
- fost
- înainte
- fiind
- Crede
- de mai jos
- între
- Dincolo de
- Cea mai mare
- biologie
- Blog
- născut
- atât
- Cutie
- larg
- construi
- Clădire
- construiește
- construit-in
- afaceri
- dezvoltarea afacerii
- dar
- buton
- butoane
- by
- apel
- a venit
- CAN
- capacități
- capital
- card
- transportate
- caz
- cazuri
- categorii
- Categorii
- provocări
- provocare
- Schimbare
- Haos
- Chat
- şef
- alegere
- Alege
- alegere
- Christopher
- Oraș
- civil
- claritate
- clase
- clasic
- clasificare
- curat
- Cloud
- clustering
- cod
- rece
- comitet
- Comun
- Comunități
- comunitate
- companie
- comparație
- compararea
- comparații
- Terminat
- finalizeaza
- de calcul
- tehnica de calcul
- concluzie
- concurent
- Conduce
- Conferință
- conferințe
- Configuraţie
- Confirma
- Consoleze
- conţine
- Recipient
- conține
- conţinut
- context
- contexte
- contribuţii
- Control
- controale
- A costat
- costisitor
- Cheltuieli
- ţară
- a creat
- Coroană
- crucial
- cultural
- Ceaşcă
- client
- experienta clientului
- clienţii care
- personalizare
- de date
- seturi de date
- Data
- de
- deceniu
- decembrie
- Decodare
- dedicat
- adânc
- învățare profundă
- profund
- Mod implicit
- defineste
- Grad
- livra
- democratic
- demonstra
- demonstrat
- demonstrează
- În funcție
- depinde de
- implementa
- dislocate
- Implementarea
- desfășurarea
- descrie
- descriere
- desemnat
- proiectat
- detaliat
- detalii
- Detectare
- dezvolta
- în curs de dezvoltare
- Dezvoltare
- Dialog
- FĂCUT
- diferenţă
- diferit
- descoperi
- descoperire
- discuta
- Afişa
- distribuite
- sisteme distribuite
- diferit
- face
- face
- păpușică
- domeniu
- domenii
- Dont
- jos
- fiecare
- Devreme
- Câștigul salarial
- uşura
- ușurință în utilizare
- editor
- Eficace
- eficacitate
- eficient
- oricare
- ales
- Inginerie Electrică
- Empire
- activat
- permite
- permițând
- capăt
- un capăt la altul
- Punct final
- inginer
- Inginerie
- spori
- consolidarea
- suficient de
- asigură
- Afacere
- Soluții pentru întreprinderi
- Mediu inconjurator
- de mediu
- egal
- este egală cu
- mai ales
- Eter (ETH)
- evalua
- evaluare
- evident
- exemplu
- exemple
- excitat
- F? r?
- existent
- experienţă
- cu experienţă
- experimental
- explora
- Explorarea
- extracţie
- Cădea
- fals
- mai repede
- membru
- festivaluri
- puțini
- Domenii
- Fișier
- Fişiere
- Depunerea
- financiar
- Servicii financiare
- Găsi
- capăt
- First
- Flexibilitate
- pluti
- Concentra
- se concentrează
- următor
- urmează
- Pentru
- Forţarea
- format
- găsit
- Fundație
- Fondat
- Cadru
- cadre
- fraudă
- detectarea fraudei
- din
- funcţie
- mai mult
- generată
- generează
- generaţie
- generativ
- AI generativă
- obține
- Go
- Dumnezeu
- bine
- am
- absolvent
- grafic
- grafice
- mai mare
- Grecia
- Lacom
- greacă
- grup
- îndrumare
- chitară
- HAD
- Manipularea
- mâini
- fericit
- Avea
- he
- de asistență medicală
- Held
- ajutor
- util
- ajutor
- ajută
- Înalt
- performanta ridicata
- superior
- cea mai mare
- highlights-uri
- drumeții
- -l
- lui
- deține
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- uman
- i
- IBM
- ICLR
- identifica
- ID-uri
- IEEE
- if
- ii
- Illinois
- implementarea
- import
- important
- îmbunătăţi
- îmbunătățit
- îmbunătățire
- îmbunătățiri
- in
- în profunzime
- include
- include
- Inclusiv
- Crește
- indică
- informații
- extragerea informațiilor
- Infrastructură
- infrastructură
- intrare
- intrări
- instanță
- cazuri
- instrucțiuni
- integrate
- Inteligență
- interese
- interfaţă
- Internațional
- intersecție
- în
- implicat
- IT
- ESTE
- james
- Loc de munca
- Locuri de munca
- alăturat
- jonathan
- jurnal
- călătorie
- jpg
- JSON
- doar
- Cheie
- regat
- trusă
- Kit (SDK)
- cunoştinţe
- cunoscut
- aterizare
- Pagina de destinație
- limbă
- mare
- pe scară largă
- Latență
- mai tarziu
- a lansat
- legii
- conducere
- învăţare
- Lungime
- li
- Licență
- licențe
- minciună
- Viaţă
- ca
- probabilitate
- Probabil
- limitare
- Linie
- linii
- LINK
- Listă
- listat
- Lamă
- încărca
- local
- logare
- Lung
- Uite
- iubeste
- Jos
- LOWER
- scăderea
- cel mai mic
- maşină
- masina de învățare
- făcut
- Principal
- face
- Efectuarea
- manager
- de conducere
- Manan Shah
- multe
- maestru
- maxim
- Mai..
- sens
- Întâlni
- membru
- meta
- metodă
- Metode
- Mexic
- ar putea
- mike
- minte
- ML
- model
- modelare
- Modele
- modificată
- modifica
- mai mult
- cele mai multe
- mutat
- Muzică
- trebuie sa
- nume
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Navigaţi
- Navigare
- Nevoie
- nevoilor
- NeurIPS
- Nou
- următor
- nlp
- Universitatea Northwestern
- caiet
- notebook-uri
- acum
- număr
- numere
- obiect
- Obiectivele
- of
- oferi
- oferind
- ofertele
- promoții
- de multe ori
- Vechi
- mai în vârstă
- on
- dată
- ONE
- afară
- optimă
- optimizare
- Optimizați
- optimizate
- optimizarea
- Opțiune
- or
- organizație
- Altele
- producție
- exterior
- remarcabil
- peste
- propriu
- ofertele
- pagină
- pereche
- împerecheat
- pâine
- Hârtie
- lucrări
- Paralel
- parametrii
- parte
- în special
- petreceri
- trecere
- pasionat
- trecut
- pentru
- efectua
- performanță
- perioadă
- Personalizat
- PhD
- conducte
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- joc
- "vă rog"
- Punct
- Politicile
- Politica
- politic
- pop-up
- Popular
- pozitiv
- posibilităţile de
- posibil
- Post
- puternic
- precedent
- Precizie
- pregătirea
- primar
- Principal
- probabilitate
- probleme
- proces
- prelucrare
- Produs
- manager de produs
- Produse
- proprietate
- furniza
- furnizori
- furnizează
- public
- publicat
- pune
- Piton
- pirtorh
- calitate
- întrebare
- dezordine
- ajunge
- aTINGE
- Citeste
- gata
- real
- lumea reală
- în timp real
- motiv
- motive
- înregistrări
- trimite
- corelarea
- refugiaţi
- eliberat
- relevanţa
- Relocat
- a ramas
- rămășițe
- repetat
- repetitiv
- înlocui
- depozit
- reprezenta
- reprezentând
- solicita
- cereri de
- necesar
- cercetare
- cercetător
- Resurse
- respectiv
- răspuns
- răspunsuri
- responsabil
- rezultând
- REZULTATE
- reveni
- revizuiască
- revizuirea
- robust
- Rulare
- regal
- Alerga
- Rusia
- sagemaker
- scalabilitate
- scalabil
- Scară
- scenarii
- Om de stiinta
- oamenii de stiinta
- script-uri
- sdk
- Caută
- căutare
- SEC
- Depunerea SEC
- Al doilea
- Secțiune
- securitate
- vedea
- senior
- trimis
- propoziție
- sentiment
- distinct
- Secvenţă
- serie
- Seria A
- serviciu
- Servicii
- set
- instalare
- setări
- câteva
- Pantaloni scurți
- să
- Arăta
- indicat
- Emisiuni
- semnificativ
- simplu
- întrucât
- singur
- Mărimea
- fragment
- So
- Societate
- Software
- de dezvoltare de software
- kit de dezvoltare software
- Inginerie software
- soluţie
- soluţii
- Rezolvarea
- unele
- fiu
- Sursă
- Sud
- sovietic
- Spaţiu
- de specialitate
- specific
- specific
- specificitate
- specificată
- Cheltuire
- împărţi
- Personal
- Începe
- început
- Stat
- statistic
- Stare
- director
- Pas
- paşi
- opriri
- depozitare
- structurat
- Elevi
- studiat
- studiu
- studio
- Reușit
- astfel de
- a sustine
- Suportat
- sigur
- Elveția
- sistem
- sisteme
- tabel
- adaptate
- Sarcină
- sarcini
- Predarea
- echipă
- Tehnic
- tehnică
- tehnici de
- Tehnologia
- șablon
- Tennessee
- termeni
- test
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- Clasificarea textului
- generarea textului
- decât
- acea
- Zona
- Capitala
- Teatru
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- Gândire
- terț
- acest
- aceste
- Prin
- debit
- tigri
- timp
- ori
- la
- astăzi
- semn
- indicativele
- Unelte
- Total
- Tren
- dresat
- Pregătire
- transformator
- Traducere
- adevărat
- încerca
- geamăn
- Două
- tip
- ui
- în
- care stau la baza
- unic
- Universități
- universitate
- până la
- Actualizează
- actualizări
- Folosire
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- utilizări
- folosind
- utilizează
- Uzbekistanul
- validare
- valoare
- varietate
- diverse
- versiune
- foarte
- de
- Vizualizare
- de viţă de vie
- vizual
- umbla
- vrea
- război
- a fost
- modalități de
- we
- web
- servicii web
- bazat pe web
- a mers
- au fost
- cand
- care
- în timp ce
- OMS
- voi
- VIN
- cu
- Castigat
- Cuvânt
- cuvinte
- Apartamente
- a lucrat
- de lucru
- fabrică
- atelier
- lume
- ar
- scrie
- an
- yoga
- tu
- Ta
- tineret
- zephyrnet
- Zeus