cu Amazon EMR 6.15, ne-am lansat Formația lacului AWS controale de acces cu granulație fină (FGAC) pe Open Table Formats (OTF), inclusiv Apache Hudi, Apache Iceberg și Delta Lake. Acest lucru vă permite să simplificați securitatea și guvernarea lacuri de date tranzacționale prin furnizarea de controale de acces la permisiuni la nivel de tabel, coloană și rând cu joburile dvs. Apache Spark. Multe companii mari caută să-și folosească lacul de date tranzacționale pentru a obține informații și pentru a îmbunătăți procesul decizional. Puteți construi o arhitectură a casei lacului folosind Amazon EMR integrat cu Lake Formation pentru FGAC. Această combinație de servicii vă permite să efectuați analize de date pe lacul dvs. de date tranzacționale, asigurând în același timp acces sigur și controlat.
Componenta serverului de înregistrări Amazon EMR acceptă funcționalitatea de filtrare a datelor la nivel de tabel, coloane, rânduri, celule și imbricate la nivel de atribut. Acesta extinde suportul pentru formatele Hive, Apache Hudi, Apache Iceberg și Delta lake atât pentru citire (inclusiv călătorie în timp și interogare incrementală) cât și pentru operațiuni de scriere (pe instrucțiuni DML, cum ar fi INSERT). În plus, cu versiunea 6.15, Amazon EMR introduce protecție pentru controlul accesului pentru interfața web a aplicației, cum ar fi Spark History Server din cluster, Yarn Timeline Server și Yarn Resource Manager UI.
În această postare, demonstrăm cum să implementăm FGAC Apache Hudi tabele care utilizează Amazon EMR integrat cu Lake Formation.
Cazul de utilizare a lacului de date privind tranzacțiile
Clienții Amazon EMR folosesc adesea Open Table Formats pentru a-și susține tranzacțiile ACID și nevoile de călătorie în timp într-un lac de date. Prin păstrarea versiunilor istorice, călătoria în timp a lacului de date oferă beneficii cum ar fi auditarea și conformitatea, recuperarea și derularea datelor, analiză reproductibilă și explorarea datelor în momente diferite.
Un alt caz popular de utilizare a lacului de date pentru tranzacții este interogarea incrementală. Interogarea incrementală se referă la o strategie de interogare care se concentrează pe procesarea și analizarea numai a datelor noi sau actualizate dintr-un lac de date de la ultima interogare. Ideea cheie din spatele interogărilor incrementale este utilizarea metadatelor sau a mecanismelor de urmărire a modificării pentru a identifica datele noi sau modificate de la ultima interogare. Prin identificarea acestor modificări, motorul de interogare poate optimiza interogarea pentru a procesa doar datele relevante, reducând semnificativ timpul de procesare și cerințele de resurse.
Prezentare generală a soluțiilor
În această postare, demonstrăm cum să implementăm FGAC pe tabele Apache Hudi folosind Amazon EMR Cloud Elastic de calcul Amazon (Amazon EC2) integrat cu Lake Formation. Apache Hudi este un cadru open source tranzacțional lac de date care simplifică foarte mult procesarea incrementală a datelor și dezvoltarea conductelor de date. Această nouă caracteristică FGAC acceptă toate OTF. Pe lângă demonstrarea cu Hudi aici, vom continua cu alte tabele OTF cu alte bloguri. Folosim notebook-uri in Amazon SageMaker Studio pentru a citi și scrie date Hudi prin diferite permisiuni de acces de utilizator printr-un cluster EMR. Acest lucru reflectă scenarii de acces la date din lumea reală - de exemplu, dacă un utilizator de inginerie are nevoie de acces complet la date pentru a depana pe o platformă de date, în timp ce analiștii de date ar putea avea nevoie doar să acceseze un subset al acestor date care nu conține informații de identificare personală (PII). ). Integrarea cu Lake Formation prin intermediul Rol de execuție Amazon EMR În plus, vă permite să vă îmbunătățiți postura de securitate a datelor și simplifică gestionarea controlului datelor pentru sarcinile de lucru Amazon EMR. Această soluție asigură un mediu securizat și controlat pentru accesul la date, satisfacând diversele nevoi și cerințe de securitate ale diferiților utilizatori și roluri dintr-o organizație.
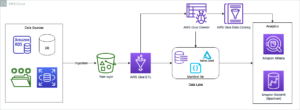
Următoarea diagramă ilustrează arhitectura soluției.
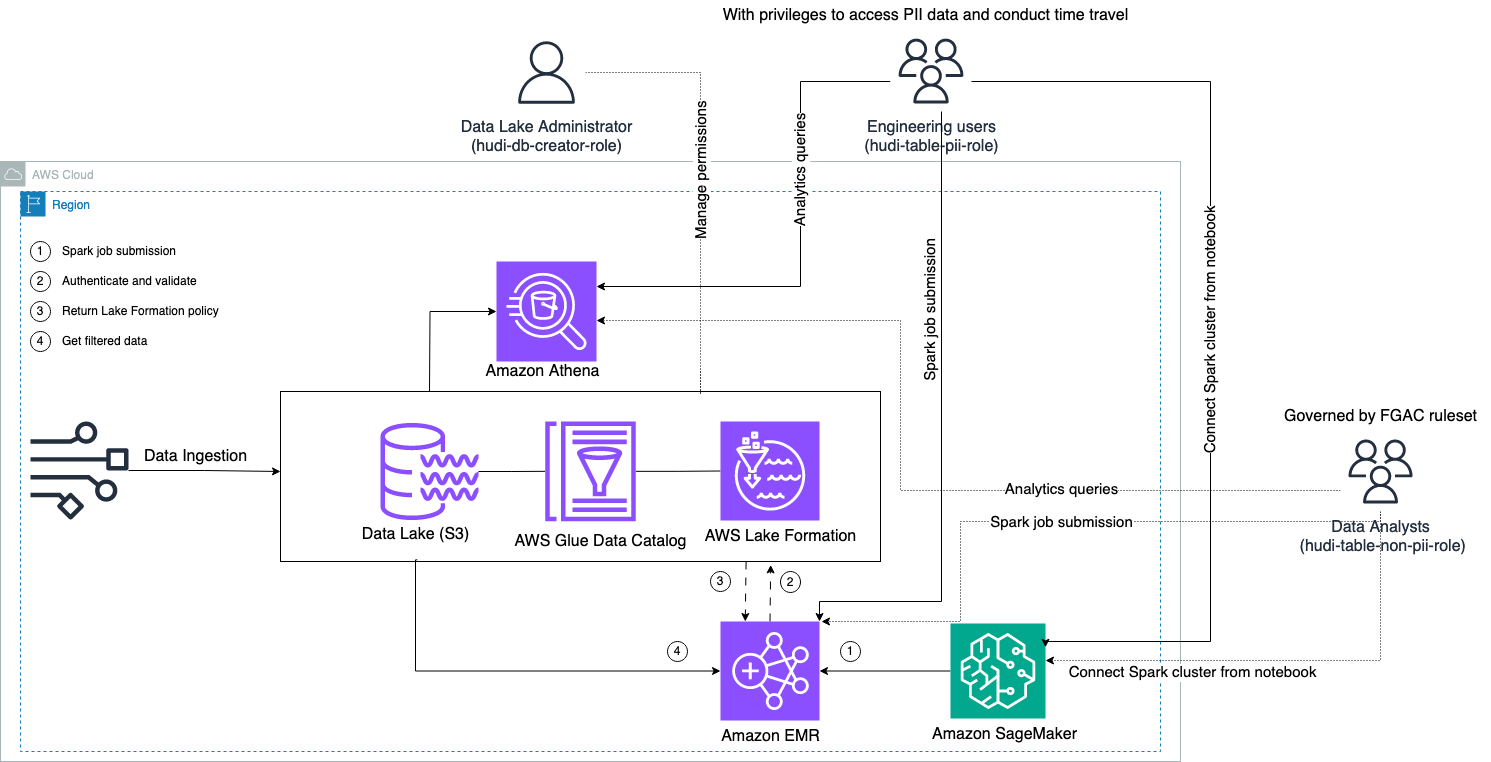
Efectuăm un proces de asimilare a datelor pentru a actualiza (actualiza și introduce) un set de date Hudi într-un Serviciul Amazon de stocare simplă (Amazon S3) și persistă sau actualizați schema tabelului în AWS Adeziv Catalog de date. Cu zero mișcare a datelor, putem interoga tabelul Hudi guvernat de Lake Formation prin diferite servicii AWS, cum ar fi Amazon Atena, Amazon EMR și Amazon SageMaker.
Când utilizatorii trimit o lucrare Spark prin intermediul oricărui punct final al clusterului EMR (EMR Steps, Livy, EMR Studio și SageMaker), Lake Formation își validează privilegiile și solicită clusterului EMR să filtreze datele sensibile, cum ar fi datele PII.
Această soluție are trei tipuri diferite de utilizatori cu diferite niveluri de permisiuni pentru a accesa datele Hudi:
- rol-creator-hudi-db – Acesta este utilizat de administratorul lacului de date care are privilegii pentru a efectua operațiuni DDL, cum ar fi crearea, modificarea și ștergerea obiectelor bazei de date. Ei pot defini reguli de filtrare a datelor pe Lake Formation pentru controlul accesului la date la nivel de rând și la nivel de coloană. Aceste reguli FGAC asigură că lacul de date este securizat și îndeplinește reglementările necesare privind confidențialitatea datelor.
- hudi-table-pii-role – Acesta este folosit de utilizatorii de inginerie. Utilizatorii de inginerie sunt capabili să efectueze călătorii în timp și interogări incrementale atât pe Copy-on-Write (CoW) cât și Merge-on-Read (MoR). Ei au, de asemenea, privilegiul de a accesa datele PII pe baza oricăror marcaje temporale.
- hudi-table-non-pii-role – Acesta este folosit de analiștii de date. Drepturile de acces la date ale analiștilor de date sunt guvernate de regulile autorizate FGAC controlate de administratorii lacului de date. Nu au vizibilitate pe coloanele care conțin date PII, cum ar fi numele și adresele. În plus, nu pot accesa rânduri de date care nu îndeplinesc anumite condiții. De exemplu, utilizatorii pot accesa doar rândurile de date care aparțin țării lor.
Cerințe preliminare
Cele trei caiete folosite în această postare le puteți descărca de la GitHub repo.
Înainte de a implementa soluția, asigurați-vă că aveți următoarele:
Parcurgeți următorii pași pentru a vă configura permisiunile:
- Conectați-vă la contul dvs. AWS cu utilizatorul IAM administrator.
Asigurați-vă că vă aflați înus-east-1Regiune.
- Creați o găleată S3 în
us-east-1Regiunea (de exemplu,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Apoi, activăm formarea lacului prin modificarea modelului de permisiuni implicit.
- Conectați-vă la consola Lake Formation ca utilizator administrator.
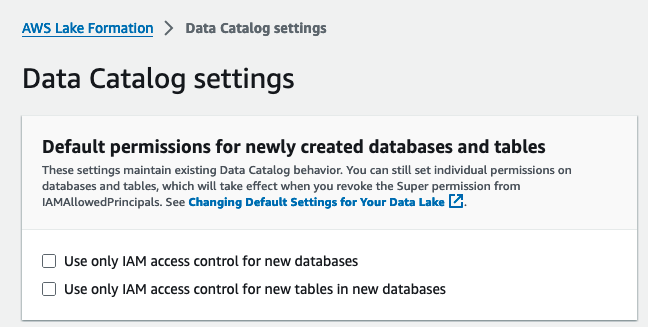
- Alege Setări Catalog de date în Administrare în panoul de navigare.
- În Permisiuni implicite pentru bazele de date și tabele nou create, deselectați Utilizați numai controlul accesului IAM pentru noile baze de date și Utilizați numai controlul accesului IAM pentru tabele noi din bazele de date noi.
- Alege Economisiți.
Alternativ, trebuie să revocați IAMAllowedPrincipals pentru resursele (baze de date și tabele) create dacă ați pornit Lake Formation cu opțiunea implicită.
În cele din urmă, creăm o pereche de chei pentru Amazon EMR.
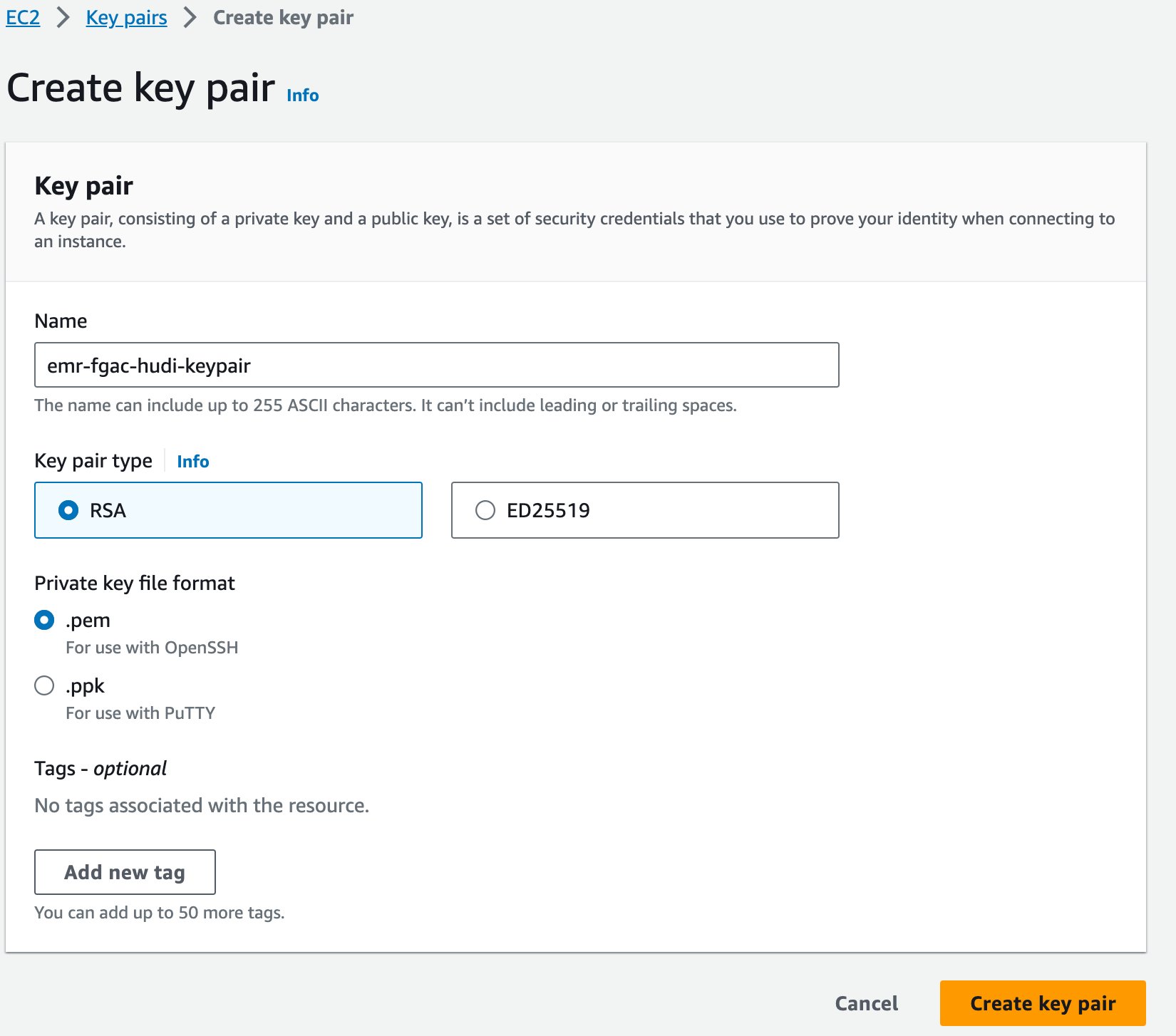
- Pe consola Amazon EC2, alegeți Perechi de chei în panoul de navigare.
- Alege Creați pereche de chei.
- Pentru Nume si Prenume, introduceți un nume (de exemplu
emr-fgac-hudi-keypair). - Alege Creați pereche de chei.
Perechea de chei generată (pentru această postare, emr-fgac-hudi-keypair.pem) se va salva pe computerul local.
În continuare, creăm un AWS Cloud9 mediu de dezvoltare interactiv (IDE).
- Pe consola AWS Cloud9, alegeți medii în panoul de navigare.
- Alege Creați mediu.
- Pentru Nume si Prenume¸ introduceți un nume (de exemplu,
emr-fgac-hudi-env). - Păstrați celelalte setări ca implicite.
- Alege Crea.
- Când IDE-ul este gata, alegeți Operatii Deschise să o deschidă.
- În IDE-ul AWS Cloud9, pe Fișier meniu, alegeți Încărcați fișiere locale.

- Încărcați fișierul pereche de chei (
emr-fgac-hudi-keypair.pem). - Alegeți semnul plus și alegeți Terminal nou.
- În terminal, introduceți următoarele linii de comandă:
Rețineți că exemplul de cod este o dovadă a conceptului doar în scopuri demonstrative. Pentru sistemele de producție, utilizați o autoritate de certificare (CA) de încredere pentru a emite certificate. A se referi la Furnizarea de certificate pentru criptarea datelor în tranzit cu criptarea Amazon EMR pentru detalii.
Implementați soluția prin AWS CloudFormation
Oferim un Formarea AWS Cloud șablon care configurează automat următoarele servicii și componente:
- O găleată S3 pentru lacul de date. Conține setul de date eșantion TPC-DS.
- Un cluster EMR cu configurație de securitate și DNS public activate.
- Roluri IAM de execuție EMR cu permisiuni detaliate Lake Formation:
- -hudi-db-creator-role – Acest rol este folosit pentru a crea baze de date și tabele Apache Hudi.
- -hudi-table-pii-rol – Acest rol oferă permisiunea de a interoga toate coloanele tabelelor Hudi, inclusiv coloanele cu PII.
- -hudi-table-non-pii-role – Acest rol oferă permisiunea de a interoga tabele Hudi care au filtrat coloanele PII după Lake Formation.
- Roluri de execuție SageMaker Studio care permit utilizatorilor să-și asume rolurile de execuție EMR corespunzătoare.
- Resurse de rețea, cum ar fi VPC, subrețele și grupuri de securitate.
Parcurgeți următorii pași pentru a implementa resursele:
- Alege Stivă de creare rapidă pentru a lansa stiva CloudFormation.
- Pentru Numele stivei, introduceți un nume de stivă (de exemplu,
rsv2-emr-hudi-blog). - Pentru Ec2KeyPair, introduceți numele perechii de chei.
- Pentru IdleTimeout, introduceți un timeout inactiv pentru clusterul EMR pentru a evita plata pentru cluster atunci când acesta nu este utilizat.
- Pentru InitS3Bucket, introduceți numele compartimentului S3 pe care l-ați creat pentru a salva fișierul .zip al certificatului de criptare Amazon EMR.
- Pentru S3CertsZip, introduceți URI-ul S3 al fișierului .zip al certificatului de criptare Amazon EMR.
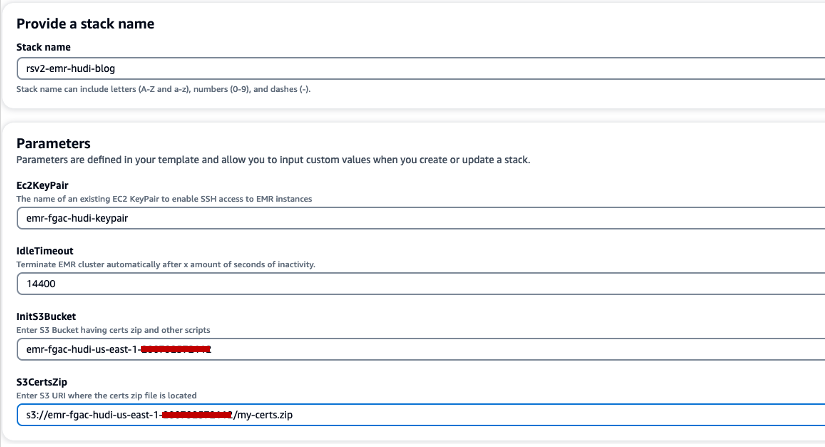
- Selectați Recunosc că AWS CloudFormation ar putea crea resurse IAM cu nume personalizate.
- Alege Creați stivă.
Implementarea stivei CloudFormation durează aproximativ 10 minute.
Configurați Lake Formation pentru integrarea Amazon EMR
Parcurgeți următorii pași pentru a configura Lake Formation:
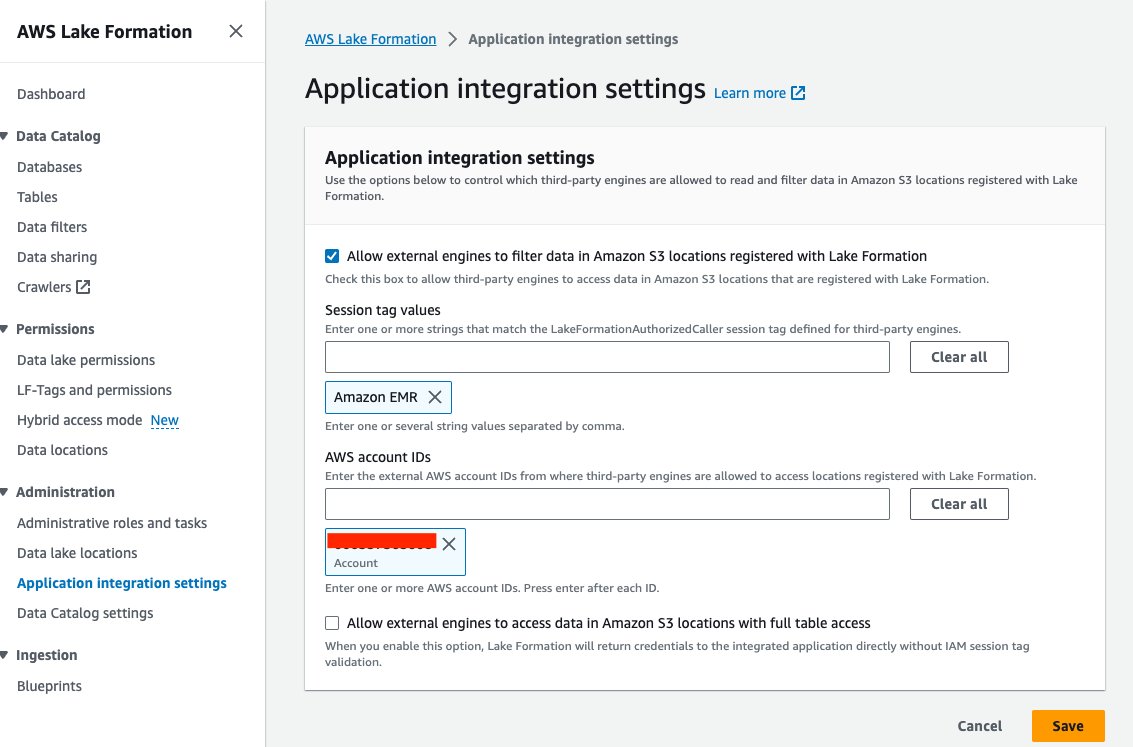
- Pe consola Lake Formation, alegeți Setări de integrare a aplicației în Administrare în panoul de navigare.
- Selectați Permiteți motoarelor externe să filtreze datele din locațiile Amazon S3 înregistrate la Lake Formation.
- Alege Amazon EMR pentru Valorile etichetelor de sesiune.
- Introduceți ID-ul contului dvs. AWS pentru ID-urile conturilor AWS.
- Alege Economisiți.
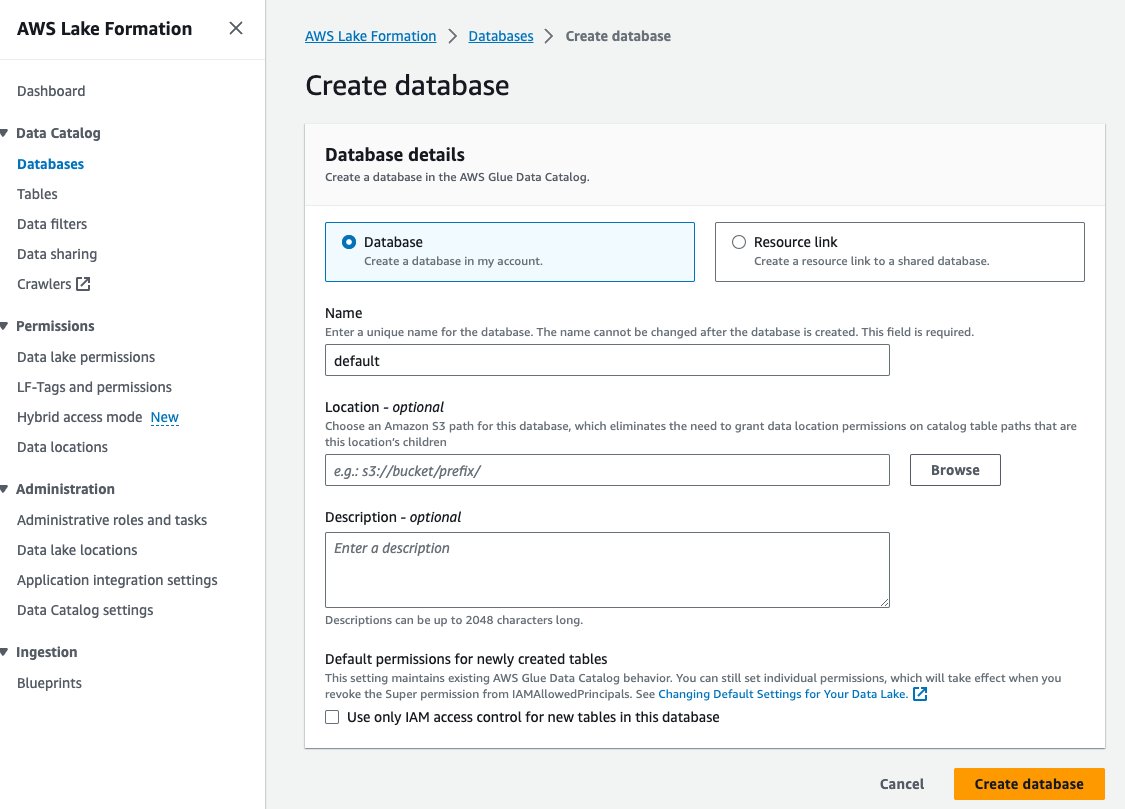
- Alege Baze de date în Catalog de date în panoul de navigare.
- Alege Creați o bază de date.
- Pentru Nume si Prenume, introduceți implicit.
- Alege Creați o bază de date.
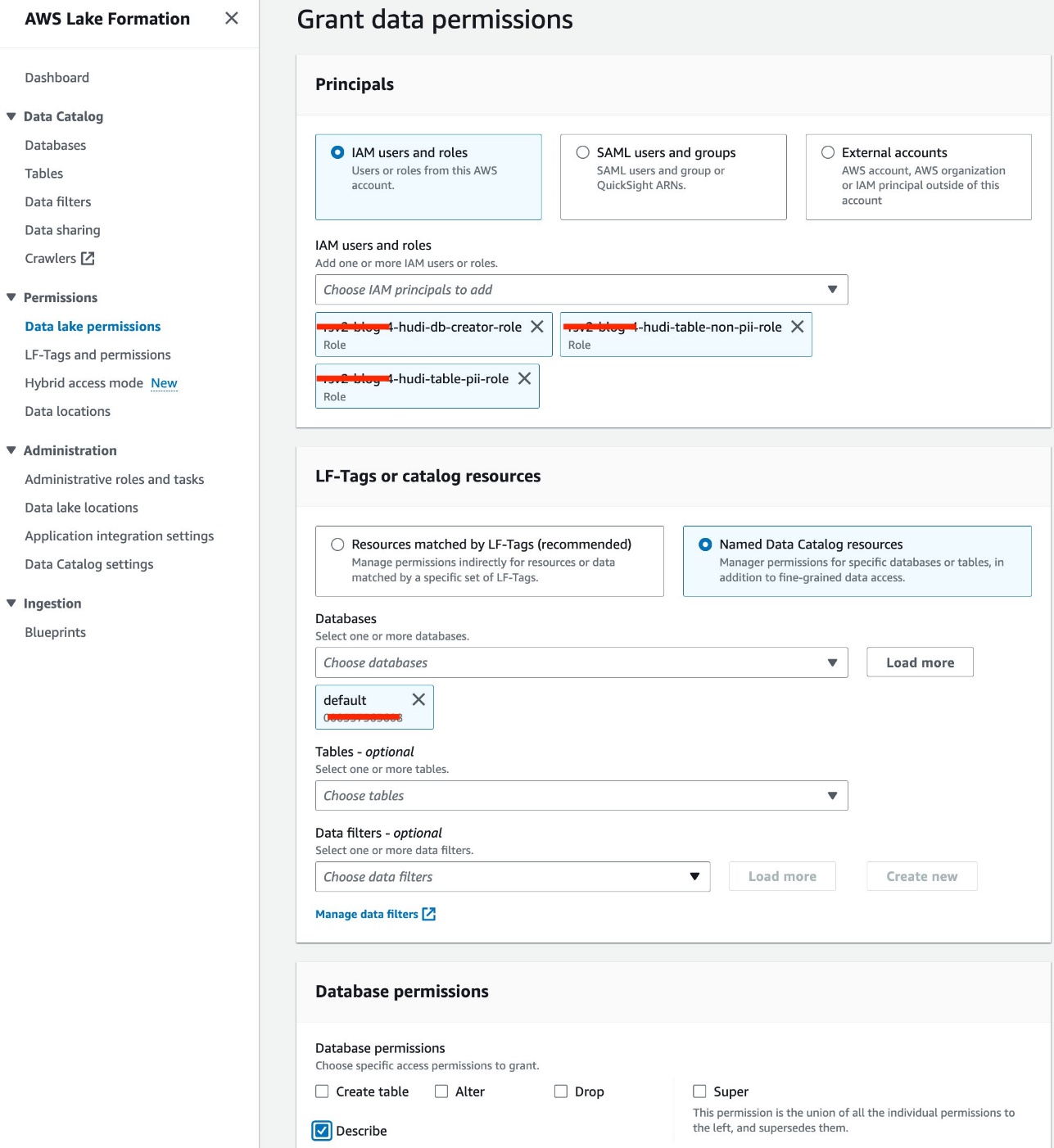
- Alege Permisiunile lacului de date în Permisiuni în panoul de navigare.
- Alege Grant.
- Selectați Utilizatori și roluri IAM.
- Alegeți-vă rolurile IAM.
- Pentru Baze de date, alege implicit.
- Pentru Permisiunile bazei de date, Selectați Descrie.
- Alege Grant.
Copiați fișierul Hudi JAR pe Amazon EMR HDFS
La utilizați Hudi cu notebook-urile Jupyter, trebuie să parcurgeți următorii pași pentru clusterul EMR, care include copierea unui fișier JAR Hudi din directorul local Amazon EMR în stocarea HDFS, astfel încât să puteți configura o sesiune Spark pentru a utiliza Hudi:
- Autorizați traficul SSH de intrare (portul 22).
- Copiați valoarea pentru DNS public nod primar (de exemplu, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) din clusterul EMR Rezumat secţiune.
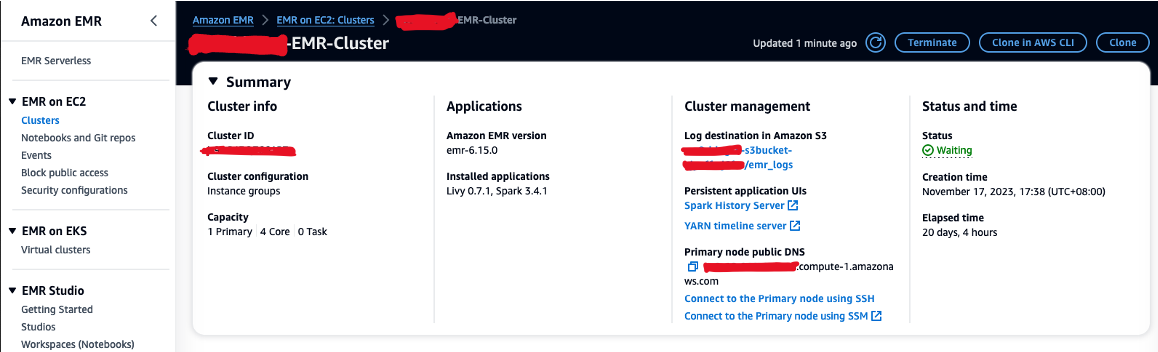
- Reveniți la terminalul AWS Cloud9 anterior pe care l-ați folosit pentru a crea perechea de chei EC2.
- Rulați următoarea comandă către SSH în nodul primar EMR. Înlocuiți substituentul cu numele dvs. de gazdă EMR DNS:
- Rulați următoarea comandă pentru a copia fișierul Hudi JAR în HDFS:
Creați baza de date și tabele Hudi în Lake Formation
Acum suntem gata să creăm baza de date și tabele Hudi cu FGAC activat de rolul de rulare EMR. The Rol de rulare EMR este un rol IAM pe care îl puteți specifica atunci când trimiteți un job sau o interogare la un cluster EMR.
Acordați permisiunea de creare a bazei de date
În primul rând, să acordăm permisiunea creatorului bazei de date Lake Formation să<STACK-NAME>-hudi-db-creator-role:
- Conectați-vă la contul dvs. AWS ca administrator.
- Pe consola Lake Formation, alegeți Roluri și sarcini administrative în Administrare în panoul de navigare.
- Confirmați că utilizatorul dvs. de conectare AWS a fost adăugat ca administrator al lacului de date.
- În Creator baze de date secțiune, pentru a alege Grant.
- Pentru Utilizatori și roluri IAM, alege
<STACK-NAME>-hudi-db-creator-role. - Pentru Permisiuni de catalog, Selectați Creați o bază de date.
- Alege Grant.
Înregistrați locația lacului de date
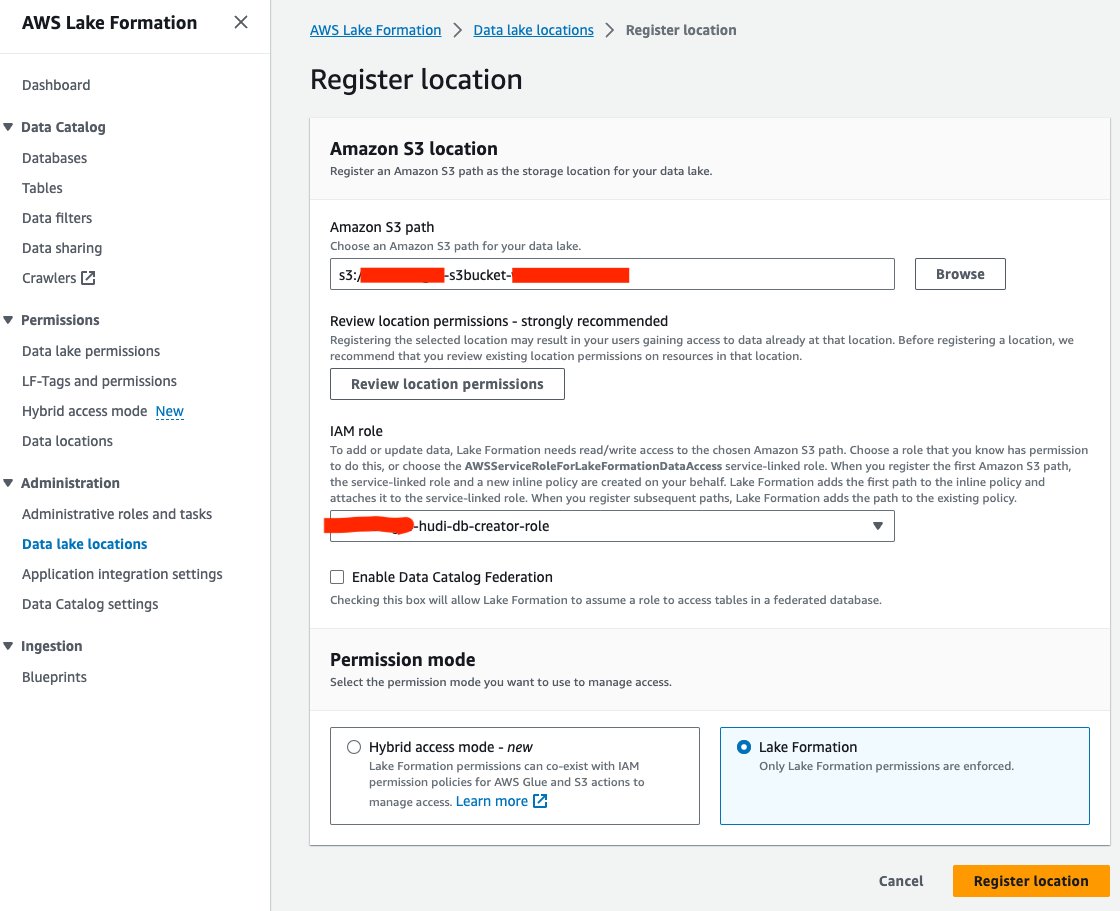
În continuare, să înregistrăm locația lacului de date S3 în Lake Formation:
- Pe consola Lake Formation, alegeți Locațiile lacului de date în Administrare în panoul de navigare.
- Alege Înregistrați locația.
- Pentru Calea Amazon S3, Alegeți Naviga și alegeți găleata data Lake S3. (
<STACK_NAME>s3bucket-XXXXXXX) creat din stiva CloudFormation. - Pentru Rolul IAM, alege
<STACK-NAME>-hudi-db-creator-role. - Pentru Modul de permisiune, Selectați Formarea Lacului.
- Alege Înregistrați locația.
Acordați permisiunea privind locația datelor
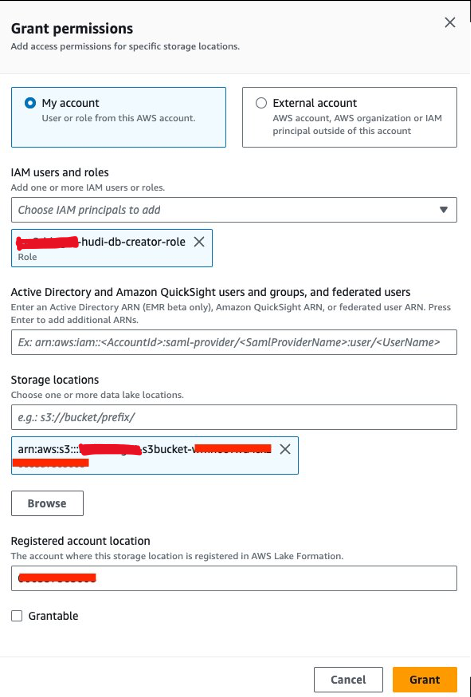
În continuare, trebuie să acordăm<STACK-NAME>-hudi-db-creator-rolepermisiunea locației datelor:
- Pe consola Lake Formation, alegeți Locațiile datelor în Permisiuni în panoul de navigare.
- Alege Grant.
- Pentru Utilizatori și roluri IAM, alege
<STACK-NAME>-hudi-db-creator-role. - Pentru Locații de depozitare, introduceți găleata S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Alege Grant.
Conectați-vă la clusterul EMR
Acum, să folosim un blocnotes Jupyter în SageMaker Studio pentru a vă conecta la clusterul EMR cu rolul de rulare EMR al creatorului bazei de date:
- Pe consola SageMaker, alegeți domenii în panoul de navigare.
- Alegeți domeniul
<STACK-NAME>-Studio-EMR-LF-Hudi. - Pe Lansa meniul de lângă profilul de utilizator
<STACK-NAME>-hudi-db-creator, alege Studio.
- Descărcați caietul rsv2-hudi-db-creator-notebook.
- Alegeți pictograma de încărcare.
- Alegeți caietul Jupyter descărcat și alegeți Operatii Deschise.
- Deschideți caietul încărcat.
- Pentru Imagine, alege SparkMagic.
- Pentru Nucleu, alege PySpark.
- Lăsați celelalte configurații ca implicite și alegeți Selectați.
- Alege Grup pentru a vă conecta la clusterul EMR.

- Alegeți EMR pe clusterul EC2 (
<STACK-NAME>-EMR-Cluster) creat cu stiva CloudFormation. - Alege Conectați.
- Pentru Rol de execuție EMR, alege
<STACK-NAME>-hudi-db-creator-role. - Alege Conectați.
Creați baze de date și tabele
Acum puteți urma pașii din blocnotes pentru a crea baza de date și tabelele Hudi. Pașii majori sunt următorii:
- Când porniți notebook-ul, configurați
“spark.sql.catalog.spark_catalog.lf.managed":"true"pentru a informa Spark că spark_catalog este protejat de Lake Formation. - Creați tabele Hudi folosind următorul SQL Spark.
- Inserați date din tabelul sursă în tabelele Hudi.
- Inserați din nou datele în tabelele Hudi.
Interogați tabelele Hudi prin Lake Formation cu FGAC
După ce creați baza de date și tabele Hudi, sunteți gata să interogați tabelele folosind controlul de acces cu granulație fină cu Lake Formation. Am creat două tipuri de tabele Hudi: Copy-On-Write (COW) și Merge-On-Read (MOR). Tabelul COW stochează datele într-un format de coloană (Parquet), iar fiecare actualizare creează o nouă versiune a fișierelor în timpul unei scrieri. Aceasta înseamnă că pentru fiecare actualizare, Hudi rescrie întregul fișier, care poate consuma mai mult resurse, dar oferă performanțe de citire mai rapide. MOR, pe de altă parte, este introdus pentru cazurile în care COW ar putea să nu fie optim, în special pentru sarcini de lucru grele de scriere sau schimbare. Într-un tabel MOR, de fiecare dată când există o actualizare, Hudi scrie doar rândul pentru înregistrarea modificată, ceea ce reduce costul și permite scrieri cu latență scăzută. Cu toate acestea, performanța de citire ar putea fi mai lentă în comparație cu tabelele COW.
Acordați permisiunea de acces la masă
Folosim rolul IAM<STACK-NAME>-hudi-table-pii-rolepentru a interoga Hudi COW și MOR care conțin coloane PII. Mai întâi acordăm permisiunea de acces la masă prin Lake Formation:
- Pe consola Lake Formation, alegeți Permisiunile lacului de date în Permisiuni în panoul de navigare.
- Alege Grant.
- Alege
<STACK-NAME>-hudi-table-pii-rolepentru Utilizatori și roluri IAM. - Alege
rsv2_blog_hudi_db_1baza de date pentru Baze de date. - Pentru Mese, alegeți cele patru tabele Hudi pe care le-ați creat în caietul Jupyter.
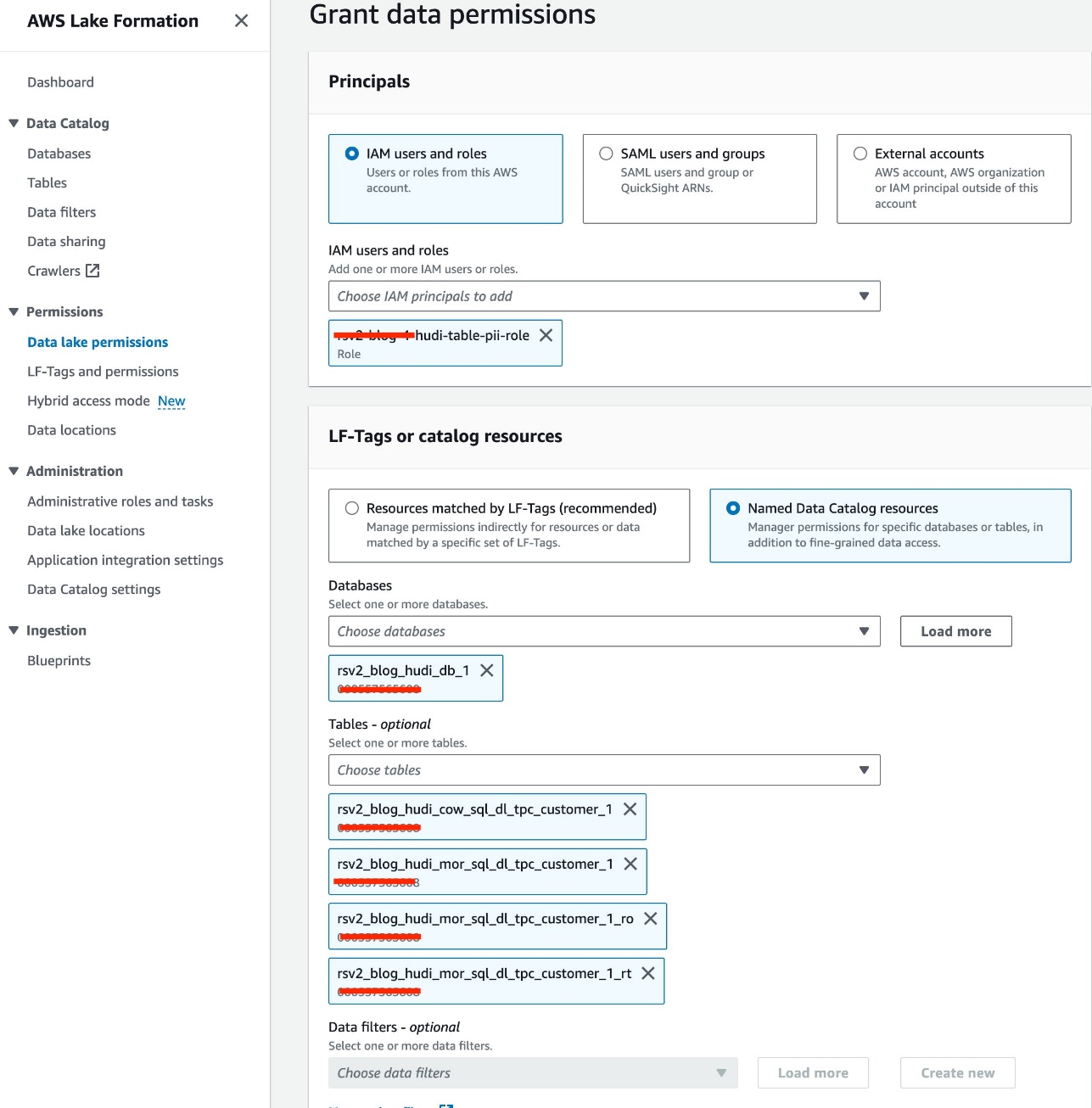
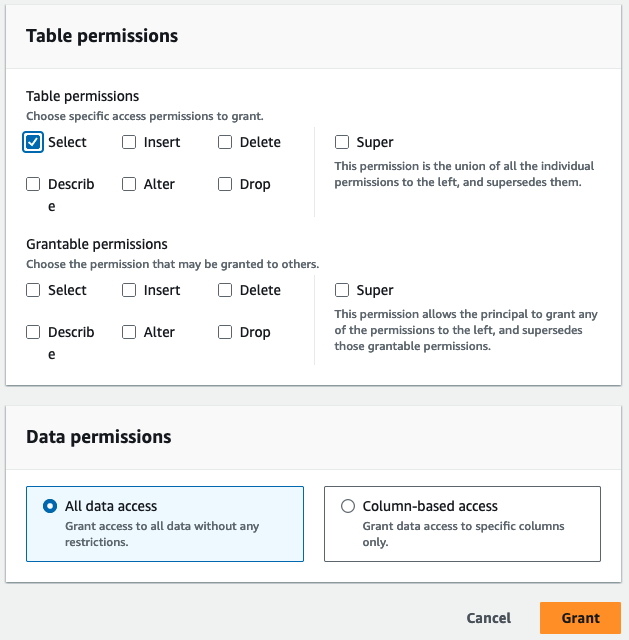
- Pentru Permisiuni de tabel, Selectați Selectați.
- Alege Grant.
Interogați coloanele PII
Acum sunteți gata să rulați blocnotesul pentru a interoga tabelele Hudi. Să urmăm pași similari cu secțiunea anterioară pentru a rula blocnotesul în SageMaker Studio:
- Pe consola SageMaker, navigați la
<STACK-NAME>-Studio-EMR-LF-Hudidomeniu. - Pe Lansa meniul de lângă
<STACK-NAME>-hudi-table-readerprofil de utilizator, alegeți Studio. - Încărcați caietul descărcat rsv2-hudi-table-pii-reader-notebook.
- Deschideți caietul încărcat.
- Repetați pașii de configurare a notebook-ului și conectați-vă la același cluster EMR, dar utilizați rolul
<STACK-NAME>-hudi-table-pii-role.
În etapa actuală, clusterul EMR activat de FGAC trebuie să interogheze coloana de timp de comitere a lui Hudi pentru a efectua interogări incrementale și călătorie în timp. Nu acceptă sintaxa „timestamp la” a lui Spark și Spark.read(). Lucrăm activ la încorporarea suportului pentru ambele acțiuni în viitoarele versiuni Amazon EMR cu FGAC activat.
Acum puteți urma pașii din caiet. Următorii sunt câțiva pași evidențiați:
- Rulați o interogare instantanee.
- Rulați o interogare incrementală.
- Rulați o interogare de călătorie în timp.
- Rulați interogări MOR optimizate pentru citire și în timp real.
Interogați tabelele Hudi cu filtre de date la nivel de coloană și de rând
Folosim rolul IAM<STACK-NAME>-hudi-table-non-pii-rolepentru a interoga tabelele Hudi. Acest rol nu are permisiunea de a interoga nicio coloană care conține informații personale. Folosim filtrele de date Lake Formation la nivel de coloană și la nivel de rând pentru a implementa un control al accesului cu granulație fină:
- Pe consola Lake Formation, alegeți Filtre de date în Catalog de date în panoul de navigare.
- Alege Creați un filtru nou.
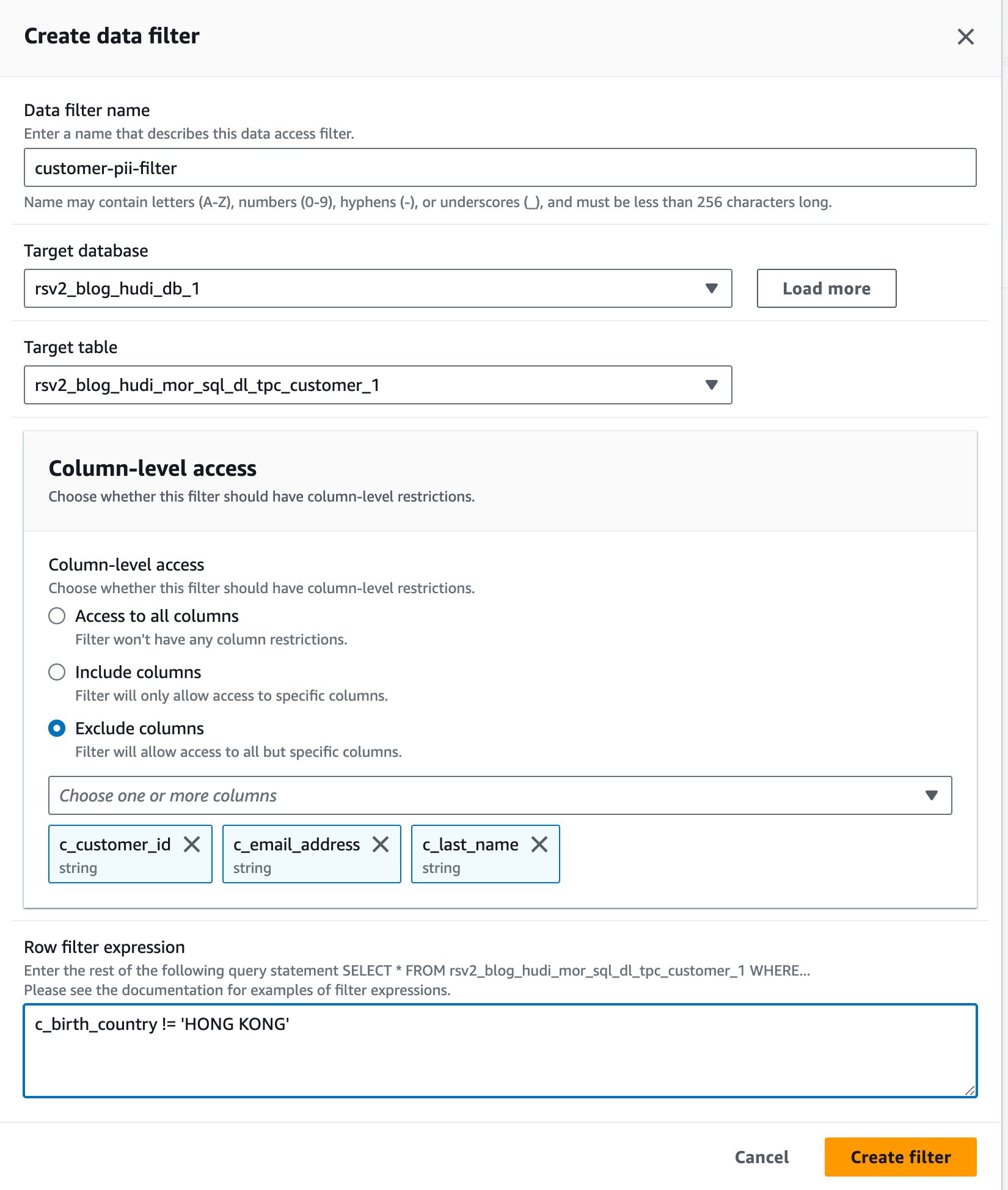
- Pentru Numele filtrului de date, introduce
customer-pii-filter. - Alege
rsv2_blog_hudi_db_1pentru Baza de date țintă. - Alege
rsv2_blog_hudi_mor_sql_dl_customer_1pentru Tabel țintă. - Selectați Excludeți coloanele și alegeți
c_customer_id,c_email_address, șic_last_namecoloane. - Intrați
c_birth_country != 'HONG KONG'pentru Expresie filtru rând. - Alege Creați filtru.
- Alege Permisiunile lacului de date în Permisiuni în panoul de navigare.
- Alege Grant.
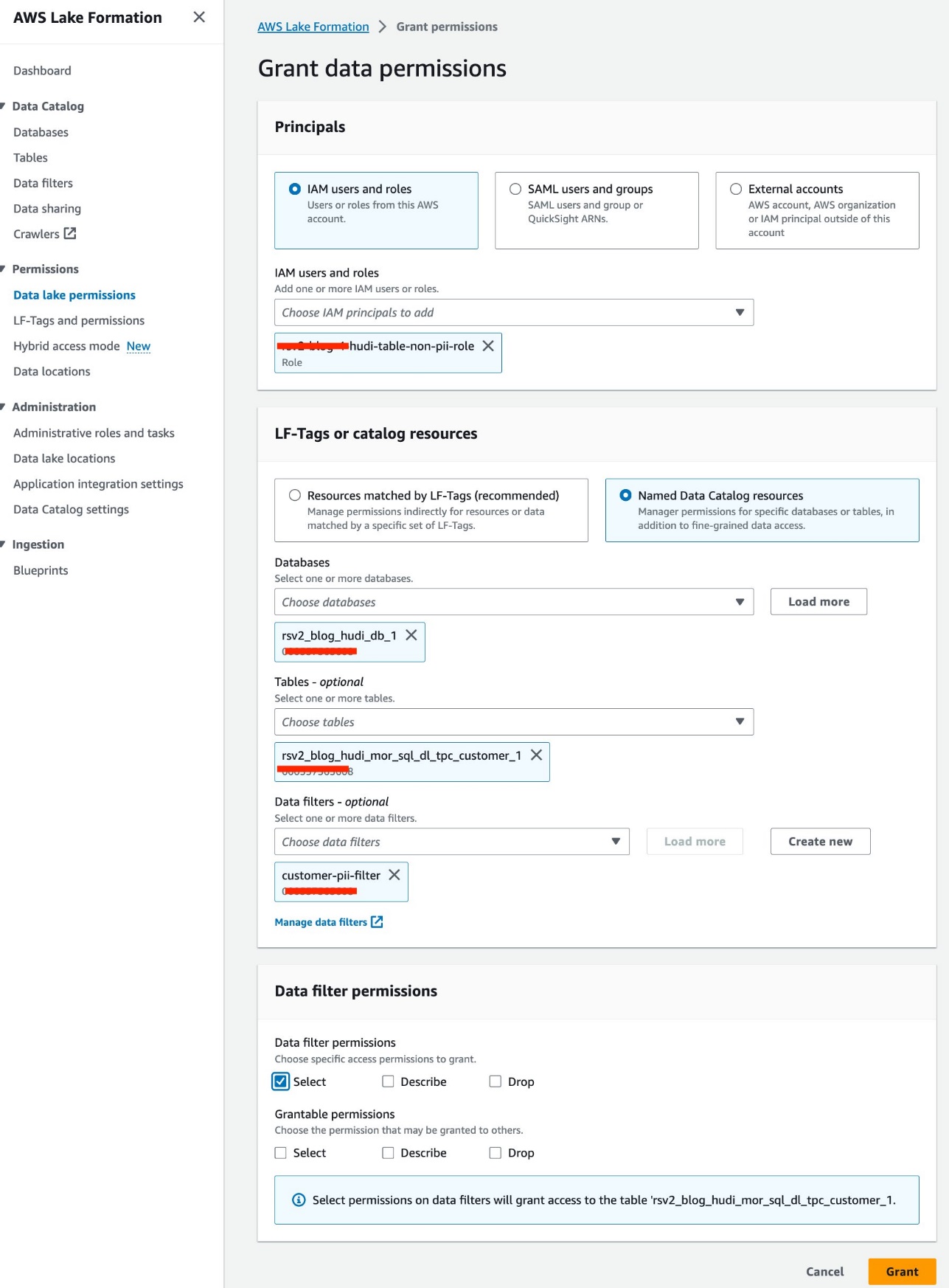
- Alege
<STACK-NAME>-hudi-table-non-pii-rolepentru Utilizatori și roluri IAM. - Alege
rsv2_blog_hudi_db_1pentru Baze de date. - Alege
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1pentru Mese. - Alege
customer-pii-filterpentru Filtre de date. - Pentru Permisiuni de filtrare a datelor, Selectați Selectați.
- Alege Grant.
Să urmăm pași similari pentru a rula blocnotesul în SageMaker Studio:
- Pe consola SageMaker, navigați la domeniu
Studio-EMR-LF-Hudi. - Pe Lansa meniu pentru
hudi-table-readerprofil de utilizator, alegeți Studio. - Încărcați caietul descărcat rsv2-hudi-table-non-pii-reader-notebook Și alegeți Operatii Deschise.
- Repetați pașii de configurare a notebook-ului și conectați-vă la același cluster EMR, dar selectați rolul
<STACK-NAME>-hudi-table-non-pii-role.
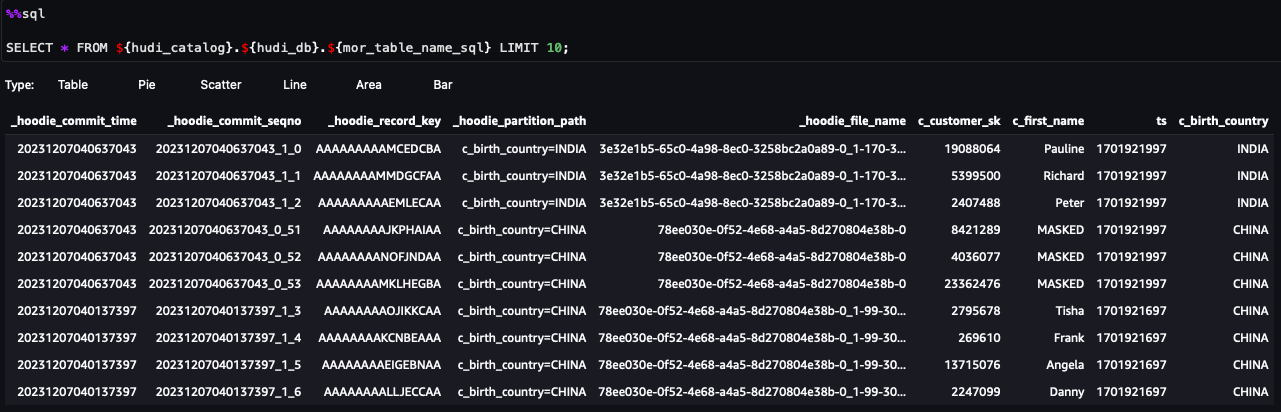
Acum puteți urma pașii din caiet. Din rezultatele interogării, puteți vedea că FGAC prin filtrul de date Lake Formation a fost aplicat. Rolul nu poate vedea coloanele PIIc_customer_id,c_last_name, șic_email_address. De asemenea, rândurile de laHONG KONGau fost filtrate.
A curăța
După ce ați terminat de experimentat cu soluția, vă recomandăm să curățați resursele cu următorii pași pentru a evita costurile neașteptate:
- Închideți aplicațiile SageMaker Studio pentru profilurile de utilizator.
Clusterul EMR va fi șters automat după valoarea de timeout inactiv.
- Ștergeți Sistem de fișiere elastice Amazon (Amazon EFS) volum creat pentru domeniu.
- Goliți gălețile S3 creat de stiva CloudFormation.
- Pe consola AWS CloudFormation, ștergeți stiva.
Concluzie
În această postare, am folosit Apachi Hudi, un tip de tabele OTF, pentru a demonstra această nouă caracteristică pentru a impune controlul precis al accesului pe Amazon EMR. Puteți defini permisiuni granulare în Lake Formation pentru tabelele OTF și le puteți aplica prin interogări Spark SQL pe clusterele EMR. De asemenea, puteți utiliza caracteristici ale lacului de date tranzacționale, cum ar fi rularea de interogări instantanee, interogări incrementale, călătorie în timp și interogare DML. Vă rugăm să rețineți că această nouă caracteristică acoperă toate tabelele OTF.
Această caracteristică este lansată începând cu versiunea 6.15 de Amazon EMR Regiuni unde este disponibil Amazon EMR. Cu integrarea Amazon EMR cu Lake Formation, puteți gestiona și procesa cu încredere datele mari, deblocând informații și facilitând luarea deciziilor în cunoștință de cauză, menținând în același timp securitatea și guvernanța datelor.
Pentru a afla mai multe, consultați Activați formarea lacului cu Amazon EMR și nu ezitați să contactați arhitecții dvs. de soluții AWS, care vă pot fi de ajutor în timpul călătoriei dvs. de date.
Despre autor
 Raymond Lai este un arhitect senior de soluții care este specializat în satisfacerea nevoilor clienților întreprinderi mari. Experiența sa constă în asistarea clienților cu migrarea sistemelor și bazelor de date complexe ale întreprinderii la AWS, construind platforme de depozitare de date și lac de date. Raymond excelează în identificarea și proiectarea de soluții pentru cazurile de utilizare AI/ML și se concentrează în special pe soluțiile AWS Serverless și pe proiectarea arhitecturii bazate pe evenimente.
Raymond Lai este un arhitect senior de soluții care este specializat în satisfacerea nevoilor clienților întreprinderi mari. Experiența sa constă în asistarea clienților cu migrarea sistemelor și bazelor de date complexe ale întreprinderii la AWS, construind platforme de depozitare de date și lac de date. Raymond excelează în identificarea și proiectarea de soluții pentru cazurile de utilizare AI/ML și se concentrează în special pe soluțiile AWS Serverless și pe proiectarea arhitecturii bazate pe evenimente.
 Bin Wang, PhD, este arhitect senior de soluții de specialitate analitică la AWS, cu peste 12 ani de experiență în industria ML, cu un accent deosebit pe publicitate. El are experiență în procesarea limbajului natural (NLP), sisteme de recomandare, diverși algoritmi ML și operațiuni ML. Este profund pasionat de aplicarea tehnicilor ML/DL și big data pentru a rezolva problemele din lumea reală.
Bin Wang, PhD, este arhitect senior de soluții de specialitate analitică la AWS, cu peste 12 ani de experiență în industria ML, cu un accent deosebit pe publicitate. El are experiență în procesarea limbajului natural (NLP), sisteme de recomandare, diverși algoritmi ML și operațiuni ML. Este profund pasionat de aplicarea tehnicilor ML/DL și big data pentru a rezolva problemele din lumea reală.
 Aditya Shah este inginer de dezvoltare software la AWS. Este interesat de bazele de date și motoarele de depozit de date și a lucrat la optimizări de performanță, conformitatea securității și conformitatea ACID pentru motoarele precum Apache Hive și Apache Spark.
Aditya Shah este inginer de dezvoltare software la AWS. Este interesat de bazele de date și motoarele de depozit de date și a lucrat la optimizări de performanță, conformitatea securității și conformitatea ACID pentru motoarele precum Apache Hive și Apache Spark.
 Melodie Yang este arhitect senior de soluții Big Data pentru Amazon EMR la AWS. Ea este un lider cu experiență în analiză care lucrează cu clienții AWS pentru a oferi îndrumări despre cele mai bune practici și sfaturi tehnice pentru a sprijini succesul acestora în transformarea datelor. Domeniile ei de interes sunt cadrele și automatizarea open-source, ingineria datelor și DataOps.
Melodie Yang este arhitect senior de soluții Big Data pentru Amazon EMR la AWS. Ea este un lider cu experiență în analiză care lucrează cu clienții AWS pentru a oferi îndrumări despre cele mai bune practici și sfaturi tehnice pentru a sprijini succesul acestora în transformarea datelor. Domeniile ei de interes sunt cadrele și automatizarea open-source, ingineria datelor și DataOps.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Despre Noi
- acces
- Cont
- recunoaște
- acțiuni
- activ
- adăugat
- În plus,
- adrese
- admin
- administratori
- Promovare
- sfat
- După
- din nou
- AI / ML
- algoritmi
- TOATE
- permite
- permis
- permite
- pe langa
- de asemenea
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- analiză
- analiști
- analitic
- Google Analytics
- analiza
- și
- Orice
- Apache
- Apache Spark
- aplicație
- aplicat
- Aplică
- Aplicarea
- arhitecți
- arhitectură
- SUNT
- domenii
- în jurul
- AS
- ajuta
- Asistență
- asistarea
- asuma
- At
- audit
- autoritate
- autorizat
- în mod automat
- Automatizare
- disponibil
- evita
- AWS
- AWS Cloud9
- Formarea AWS Cloud
- Formația lacului AWS
- înapoi
- bazat
- BE
- fost
- în spatele
- fiind
- Beneficiile
- in afara de asta
- CEL MAI BUN
- Mare
- Datele mari
- bloguri
- lăudăros
- atât
- construi
- dar
- by
- CA
- CAN
- capabil
- transporta
- purtător
- caz
- cazuri
- catalog
- catering
- sigur
- certificat
- Certificatele
- Certificare
- Schimbare
- si-a schimbat hainele;
- Modificări
- China
- Alege
- Curățenie
- Cloud9
- Grup
- cod
- Coloană
- Coloane
- COM
- combinaţie
- comite
- Companii
- comparație
- Completă
- conformitate
- component
- componente
- Calcula
- calculator
- concept
- Condiții
- Conduce
- cu încredere
- Configuraţie
- Conectați
- Consoleze
- construirea
- contactați-ne
- conţine
- conține
- Control
- controlată
- controale
- copiere
- Corespunzător
- A costat
- Cheltuieli
- ţară
- acoperă
- crea
- a creat
- creează
- Crearea
- creator
- Curent
- personalizat
- clienţii care
- de date
- accesul la date
- analiza datelor
- Lacul de date
- Platforma de date
- confidențialitatea datelor
- de prelucrare a datelor
- securitatea datelor
- depozit de date
- Baza de date
- baze de date
- Luarea deciziilor
- profund
- Mod implicit
- defini
- Deltă
- demonstra
- demonstrând
- implementa
- desfășurarea
- Amenajări
- proiect
- detalii
- Dezvoltare
- diferit
- distinct
- diferit
- dns
- do
- face
- Nu
- domeniu
- făcut
- Dont
- jos
- Descarca
- condus
- în timpul
- fiecare
- altfel
- permite
- activat
- permite
- criptare
- capăt
- Obiective
- aplica
- Motor
- inginer
- Inginerie
- Motoare
- asigura
- asigură
- asigurare
- Intrați
- Afacere
- clienții întreprinderii
- Întreg
- Mediu inconjurator
- Eter (ETH)
- eveniment
- Fiecare
- exemplu
- execuție
- există
- experienţă
- cu experienţă
- expertiză
- explorare
- extinde
- extern
- facilitând
- mai repede
- Caracteristică
- DESCRIERE
- simţi
- Fișier
- Fişiere
- filtru
- filtrare
- Filtre
- First
- Concentra
- se concentrează
- urma
- următor
- urmează
- Pentru
- format
- formare
- patru
- Cadru
- cadre
- Gratuit
- din
- Îndeplini
- Complet
- funcționalitate
- mai mult
- viitor
- Câştig
- generată
- guvernare
- guvernată
- acordarea
- foarte mult
- grup
- Grupului
- îndrumare
- mână
- Avea
- he
- ei
- aici
- Evidențiat
- lui
- istoric
- istorie
- Stup
- Hong
- Hong Kong
- casă
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- idee
- identifica
- identificarea
- Idle
- if
- ilustrează
- punerea în aplicare a
- îmbunătăţi
- in
- include
- Inclusiv
- care încorporează
- incrementală
- India
- industrie
- Informa
- informații
- informat
- intrare
- perspective
- integrate
- integrarea
- integrare
- interactiv
- interesat
- interese
- interfaţă
- intern
- în
- complicat
- introdus
- Prezintă
- problema
- IT
- ESTE
- Loc de munca
- Locuri de munca
- călătorie
- jpg
- Jupiter Notebook
- Cheie
- Kong
- lac
- limbă
- mare
- Nume
- lansa
- a lansat
- lider
- AFLAȚI
- nivelurile de
- se află
- ca
- LIMITĂ
- linii
- local
- locaţie
- Locații
- Logare
- major
- face
- administra
- gestionate
- administrare
- manager
- multe
- Mai..
- mijloace
- mecanisme
- Reuniunea
- Meniu
- Metadata
- ar putea
- Migrarea
- minute
- ML
- Algoritmi ML
- modificată
- mai mult
- mişcare
- nume
- nume
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Navigaţi
- Navigare
- Nevoie
- nevoilor
- Nou
- optiune noua
- recent
- următor
- nlp
- nod
- nota
- caiet
- notebook-uri
- acum
- obiecte
- of
- de multe ori
- on
- ONE
- afară
- deschide
- open-source
- OpenSSL
- Operațiuni
- optimă
- Optimizați
- Opțiune
- Opţiuni
- or
- comandă
- organizație
- Altele
- afară
- peste
- pereche
- pâine
- special
- în special
- pasionat
- de plată
- performanță
- efectuarea
- permisiune
- permisiuni
- Personal
- PhD
- PII
- înlocuitor
- platformă
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- la care se adauga
- puncte
- Popular
- posedă
- Post
- practică
- păstrarea
- precedent
- primar
- intimitate
- privilegiu
- privilegii
- probleme
- proces
- prelucrare
- producere
- Profil
- Profiluri
- dovadă
- dovada de concept
- protejat
- protecţie
- furniza
- furnizează
- furnizarea
- public
- scopuri
- interogări
- Citeste
- Citind
- gata
- lumea reală
- în timp real
- recomanda
- record
- recuperare
- reduce
- reducerea
- trimite
- se referă
- reflectă
- regiune
- Inregistreaza-te
- înregistrată
- regulament
- eliberaţi
- Lansări
- înlocui
- necesar
- Cerinţe
- resursă
- consumatoare de resurse
- Resurse
- rezultat
- REZULTATE
- Drepturile
- Rol
- rolurile
- RÂND
- rsa
- norme
- Alerga
- funcţionare
- sagemaker
- acelaşi
- Economisiți
- Secțiune
- sigur
- securizat
- securitate
- vedea
- Căuta
- selecta
- senior
- sensibil
- serverul
- serverless
- Servicii
- sesiune
- set
- Seturi
- setări
- configurarea
- ea
- semna
- semnificativ
- asemănător
- simplu
- Simplifică
- simplifica
- întrucât
- Instantaneu
- So
- Software
- de dezvoltare de software
- soluţie
- soluţii
- REZOLVAREA
- unele
- Sursă
- Scânteie
- specialist
- specializată
- SQL
- stivui
- Etapă
- Începe
- început
- Pornire
- Declarații
- paşi
- depozitare
- magazine
- Strategie
- Şir
- studio
- prezenta
- subrețele
- succes
- astfel de
- REZUMAT
- a sustine
- Sprijină
- sigur
- sintaxă
- sisteme
- tabel
- TAG
- ia
- Tehnic
- tehnici de
- șablon
- Terminal
- acea
- Sursa
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- acest
- trei
- Prin
- timp
- timp de călătorie
- cronologie
- la
- Urmărire
- tranzacție
- tranzacțional
- Transformare
- tranzit
- călătorie
- adevărat
- de încredere
- Ts
- Două
- tip
- Tipuri
- ui
- în
- Neașteptat
- necunoscut
- deblocare
- Actualizează
- actualizat
- susținător
- încărcat
- URI
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- validează
- valoare
- diverse
- versiune
- de
- vizibilitate
- volum
- Depozit
- depozitare
- we
- web
- servicii web
- cand
- întrucât
- care
- în timp ce
- OMS
- voi
- cu
- în
- a lucrat
- de lucru
- scrie
- ani
- tu
- Ta
- zephyrnet
- zero
- Zip