Multe organizații, mici și mari, lucrează pentru a migra și a-și moderniza sarcinile de lucru de analiză pe Amazon Web Services (AWS). Există multe motive pentru ca clienții să migreze la AWS, dar unul dintre motivele principale este capacitatea de a utiliza servicii complet gestionate, mai degrabă decât să-și petreacă timp întreținând infrastructura, corecție, monitorizare, backup și multe altele. Echipele de conducere și dezvoltare pot petrece mai mult timp optimizând soluțiile actuale și chiar experimentând noi cazuri de utilizare, mai degrabă decât întreținând infrastructura actuală.
Având capacitatea de a vă mișca rapid pe AWS, trebuie, de asemenea, să fiți responsabil cu datele pe care le primiți și procesați pe măsură ce continuați să creșteți. Aceste responsabilități includ respectarea legilor și reglementărilor privind confidențialitatea datelor și nu stocarea sau expunerea datelor sensibile, cum ar fi informații de identificare personală (PII) sau informații de sănătate protejate (PHI) din surse din amonte.
În această postare, trecem printr-o arhitectură de nivel înalt și un caz de utilizare specific care demonstrează cum puteți continua să scalați platforma de date a organizației dvs. fără a fi nevoie să petreceți o cantitate mare de timp de dezvoltare pentru a rezolva preocupările privind confidențialitatea datelor. Folosim AWS Adeziv pentru a detecta, masca și redacta datele PII înainte de a le încărca Serviciul Amazon OpenSearch.
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează arhitectura soluției de nivel înalt. Am definit toate straturile și componentele designului nostru în conformitate cu Lentila de analiză a datelor cadru bine arhitecturat AWS.
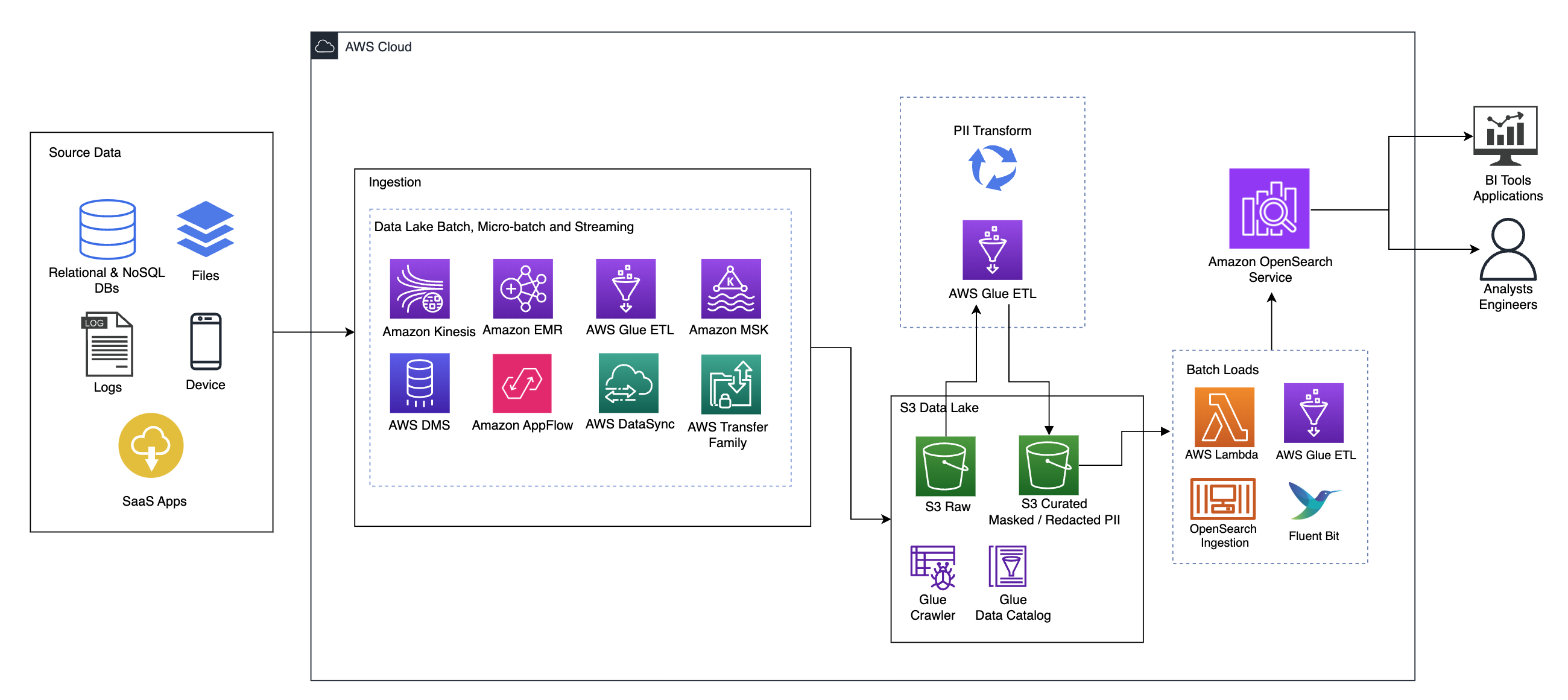
Arhitectura este compusă dintr-un număr de componente:
Date sursă
Datele pot proveni de la multe zeci până la sute de surse, inclusiv baze de date, transferuri de fișiere, jurnale, aplicații software ca serviciu (SaaS) și multe altele. Este posibil ca organizațiile să nu aibă întotdeauna control asupra datelor care vin prin aceste canale și în stocarea și aplicațiile lor din aval.
Ingestie: lot lac de date, micro-lot și streaming
Multe organizații își transferă datele sursă în lacul lor de date în diferite moduri, inclusiv joburi în lot, micro-loturi și streaming. De exemplu, Amazon EMR, AWS Adeziv, și Serviciul de migrare a bazelor de date AWS (AWS DMS) pot fi folosite toate pentru a efectua operațiuni de lot și/sau de streaming care se cufundă într-un lac de date pe Serviciul Amazon de stocare simplă (Amazon S3). Amazon App Flow poate fi folosit pentru a transfera date din diferite aplicații SaaS într-un lac de date. AWS DataSync și Familia AWS Transfer poate ajuta la mutarea fișierelor către și de la un lac de date printr-un număr de protocoale diferite. Amazon Kinesis și Amazon MSK au, de asemenea, capabilități de a transmite date direct către un lac de date pe Amazon S3.
Lacul de date S3
Utilizarea Amazon S3 pentru lacul dvs. de date este în conformitate cu strategia modernă de date. Oferă stocare la costuri reduse fără a sacrifica performanța, fiabilitatea sau disponibilitatea. Cu această abordare, puteți aduce calcul la datele dvs. după cum este necesar și puteți plăti doar pentru capacitatea de care are nevoie pentru a rula.
În această arhitectură, datele brute pot proveni dintr-o varietate de surse (interne și externe), care pot conține date sensibile.
Folosind crawlerele AWS Glue, putem descoperi și cataloga datele, care vor construi schemele de tabel pentru noi și, în cele din urmă, vor simplifica utilizarea AWS Glue ETL cu transformarea PII pentru a detecta și masca sau și redacta orice date sensibile care ar fi putut ajunge. în lacul de date.
Contextul de afaceri și seturile de date
Pentru a demonstra valoarea abordării noastre, să ne imaginăm că faceți parte dintr-o echipă de inginerie a datelor pentru o organizație de servicii financiare. Cerințele dvs. sunt să detectați și să mascați datele sensibile pe măsură ce acestea sunt ingerate în mediul cloud al organizației dvs. Datele vor fi consumate de procesele analitice din aval. În viitor, utilizatorii dvs. vor putea căuta în siguranță tranzacțiile de plată istorice pe baza fluxurilor de date colectate de la sistemele bancare interne. Rezultatele căutării de la echipele de operare, clienți și aplicațiile de interfață trebuie să fie mascate în câmpuri sensibile.
Următorul tabel prezintă structura de date utilizată pentru soluție. Pentru claritate, am mapat numele de coloane brute cu organizate. Veți observa că mai multe câmpuri din această schemă sunt considerate date sensibile, cum ar fi numele, numele, numărul de securitate socială (SSN), adresa, numărul cardului de credit, numărul de telefon, e-mailul și adresa IPv4.
| Numele coloanei brute | Nume de coloană îngrijit | Tip |
| c0 | Nume | şir |
| c1 | Numele de familie | şir |
| c2 | ssn | şir |
| c3 | adresa | şir |
| c4 | cod poștal | şir |
| c5 | ţară | şir |
| c6 | site_de_cumpărare | şir |
| c7 | Numărul cărții de credit | şir |
| c8 | furnizor_card_de_credit | şir |
| c9 | valută | şir |
| c10 | valoare_de_cumpărare | întreg |
| c11 | Data tranzacției | data |
| c12 | numar de telefon | şir |
| c13 | şir | |
| c14 | ipv4 | şir |
Caz de utilizare: detectarea lotului PII înainte de încărcare în Serviciul OpenSearch
Clienții care implementează următoarea arhitectură și-au construit lacul de date pe Amazon S3 pentru a rula diferite tipuri de analize la scară. Această soluție este potrivită pentru clienții care nu necesită ingerare în timp real în Serviciul OpenSearch și intenționează să utilizeze instrumente de integrare a datelor care rulează conform unui program sau sunt declanșate prin evenimente.
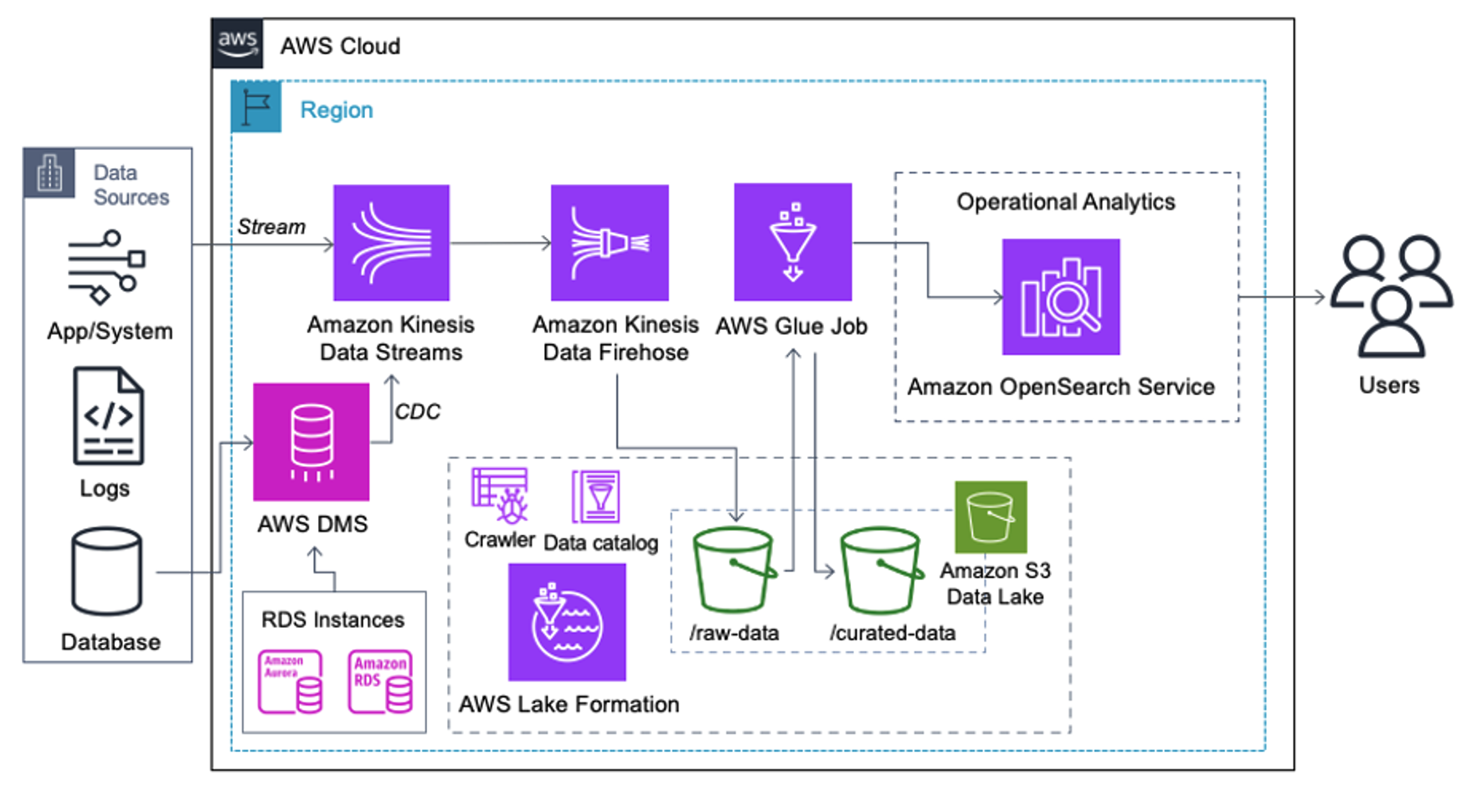
Înainte ca înregistrările de date să ajungă pe Amazon S3, implementăm un strat de asimilare pentru a aduce toate fluxurile de date în mod fiabil și sigur în lacul de date. Kinesis Data Streams este implementat ca un strat de asimilare pentru preluarea accelerată a fluxurilor de date structurate și semi-structurate. Exemple de acestea sunt modificările bazelor de date relaționale, aplicațiile, jurnalele de sistem sau fluxurile de clic. Pentru cazurile de utilizare pentru capturarea datelor de modificare (CDC), puteți utiliza Kinesis Data Streams ca țintă pentru AWS DMS. Aplicațiile sau sistemele care generează fluxuri care conțin date sensibile sunt trimise către fluxul de date Kinesis prin una dintre cele trei metode acceptate: Amazon Kinesis Agent, AWS SDK pentru Java sau Kinesis Producer Library. Ca ultim pas, Firehose Amazon Kinesis Data ne ajută să încărcăm în mod fiabil loturi de date aproape în timp real în destinația noastră lacul de date S3.
Următoarea captură de ecran arată modul în care datele circulă prin Kinesis Data Streams prin intermediul Vizualizator de date și preia date eșantion care aterizează pe prefixul S3 brut. Pentru această arhitectură, am urmat ciclul de viață al datelor pentru prefixele S3, așa cum se recomandă în Fundația Data Lake.
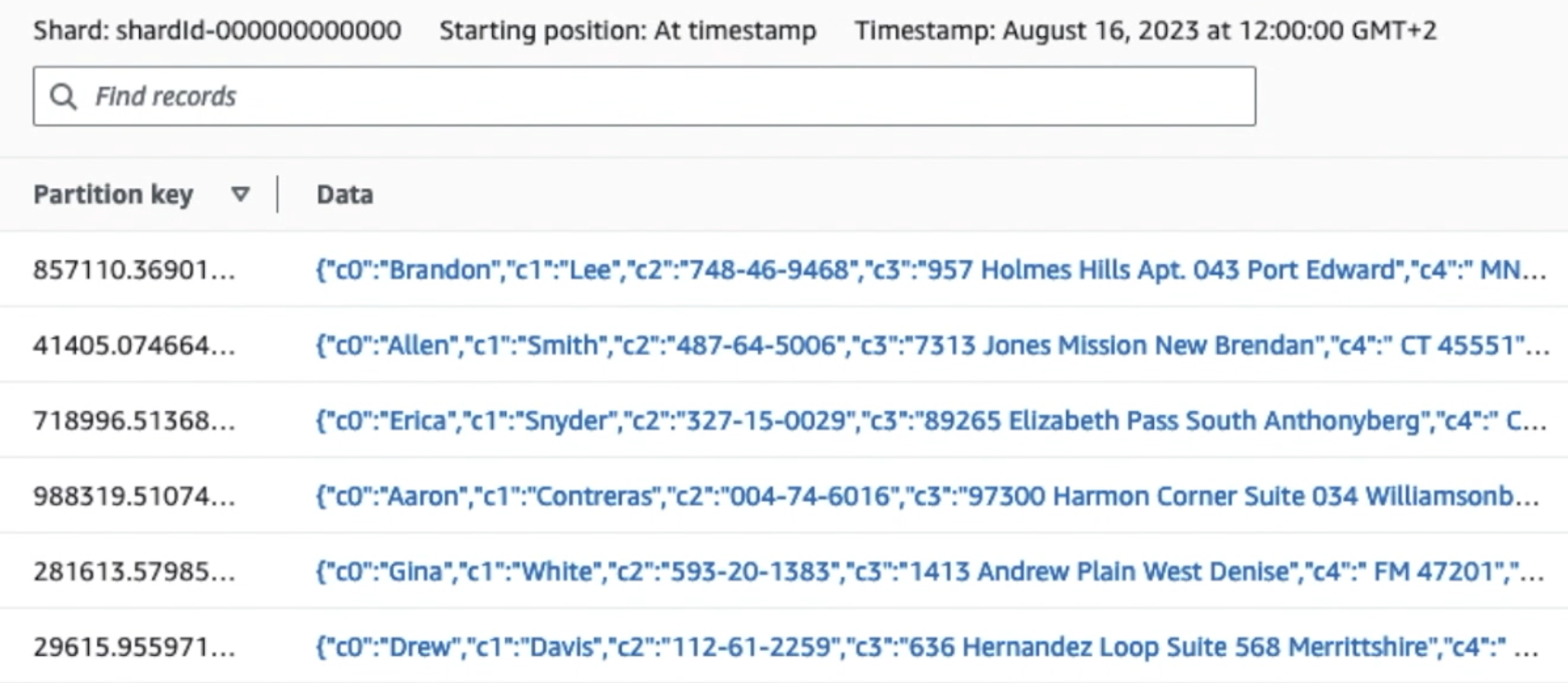
După cum puteți vedea din detaliile primei înregistrări din următoarea captură de ecran, sarcina utilă JSON urmează aceeași schemă ca în secțiunea anterioară. Puteți vedea datele neredactate care curg în fluxul de date Kinesis, care vor fi obscucate mai târziu în etapele ulterioare.
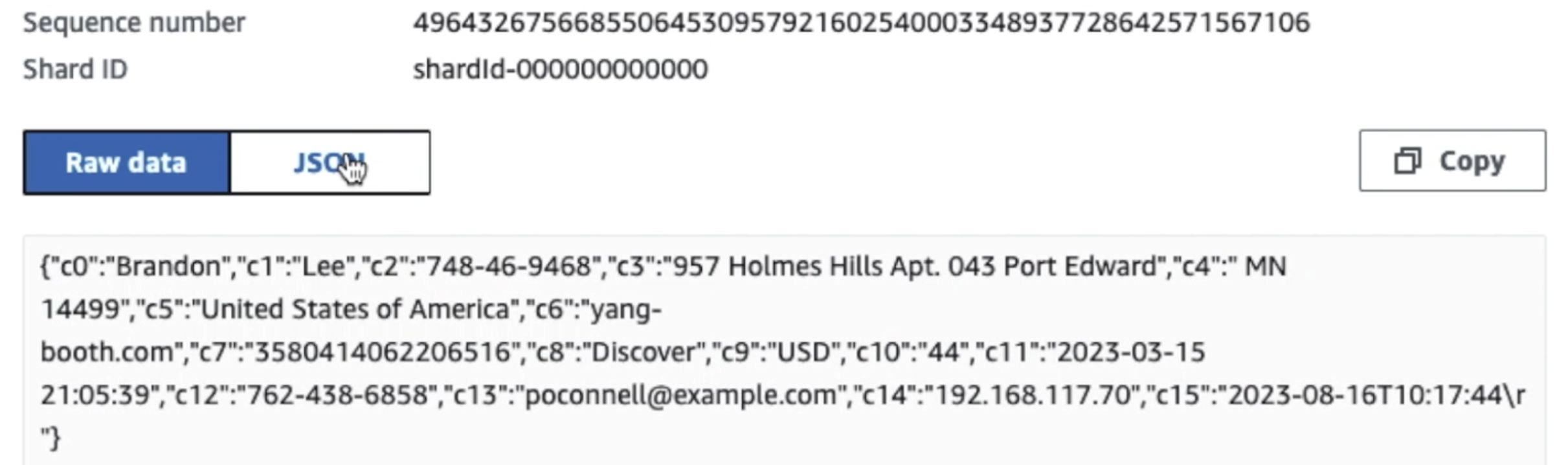
După ce datele sunt colectate și ingerate în Kinesis Data Streams și livrate în compartimentul S3 folosind Kinesis Data Firehose, stratul de procesare al arhitecturii preia controlul. Folosim transformarea AWS Glue PII pentru a automatiza detectarea și mascarea datelor sensibile din conducta noastră. După cum se arată în următoarea diagramă a fluxului de lucru, am adoptat o abordare ETL vizuală fără cod pentru a implementa munca noastră de transformare în AWS Glue Studio.
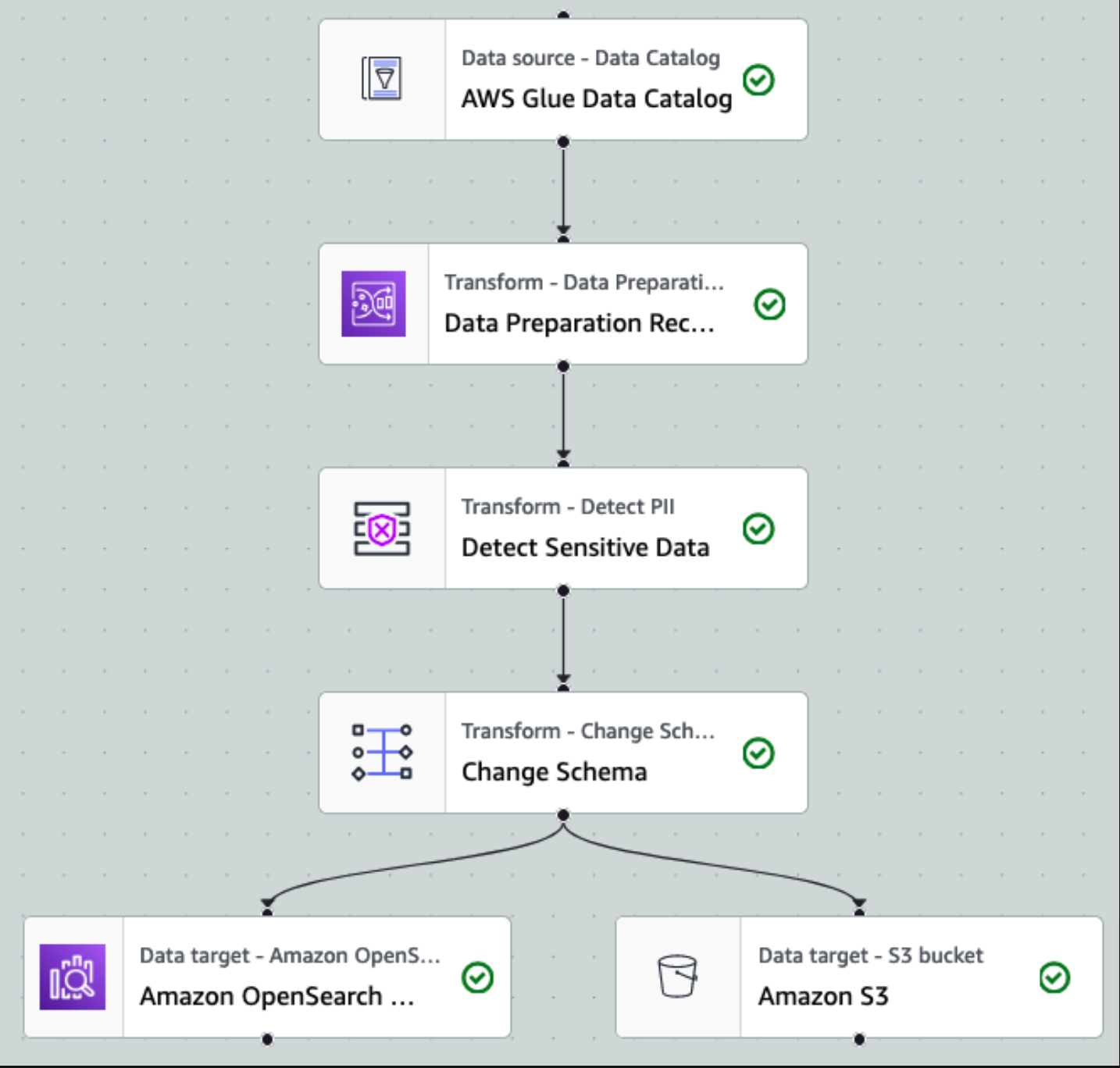
Mai întâi, accesăm tabelul sursă Data Catalog brut din pii_data_db Bază de date. Tabelul are structura schemei prezentată în secțiunea anterioară. Pentru a urmări datele brute prelucrate, am folosit marcaje de locuri de muncă.

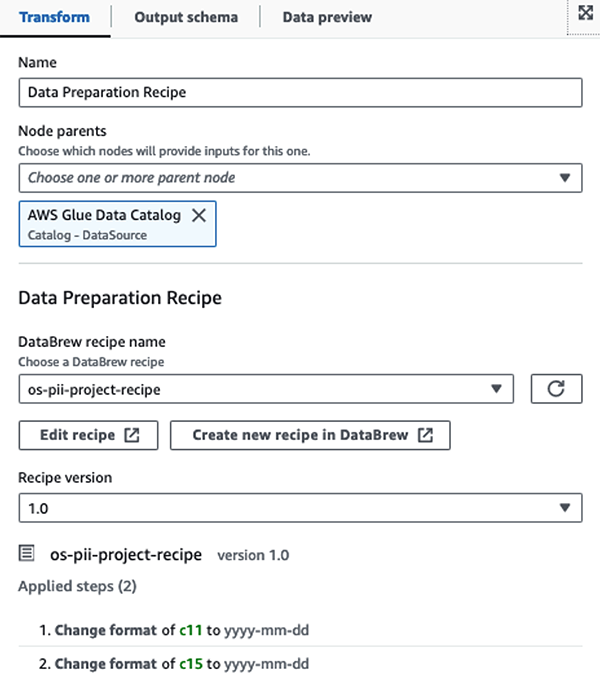
Noi folosim Rețete AWS Glue DataBrew în jobul ETL vizual AWS Glue Studio pentru a transforma două atribute de dată pentru a fi compatibile cu OpenSearch așteptat Formate. Acest lucru ne permite să avem o experiență completă fără cod.
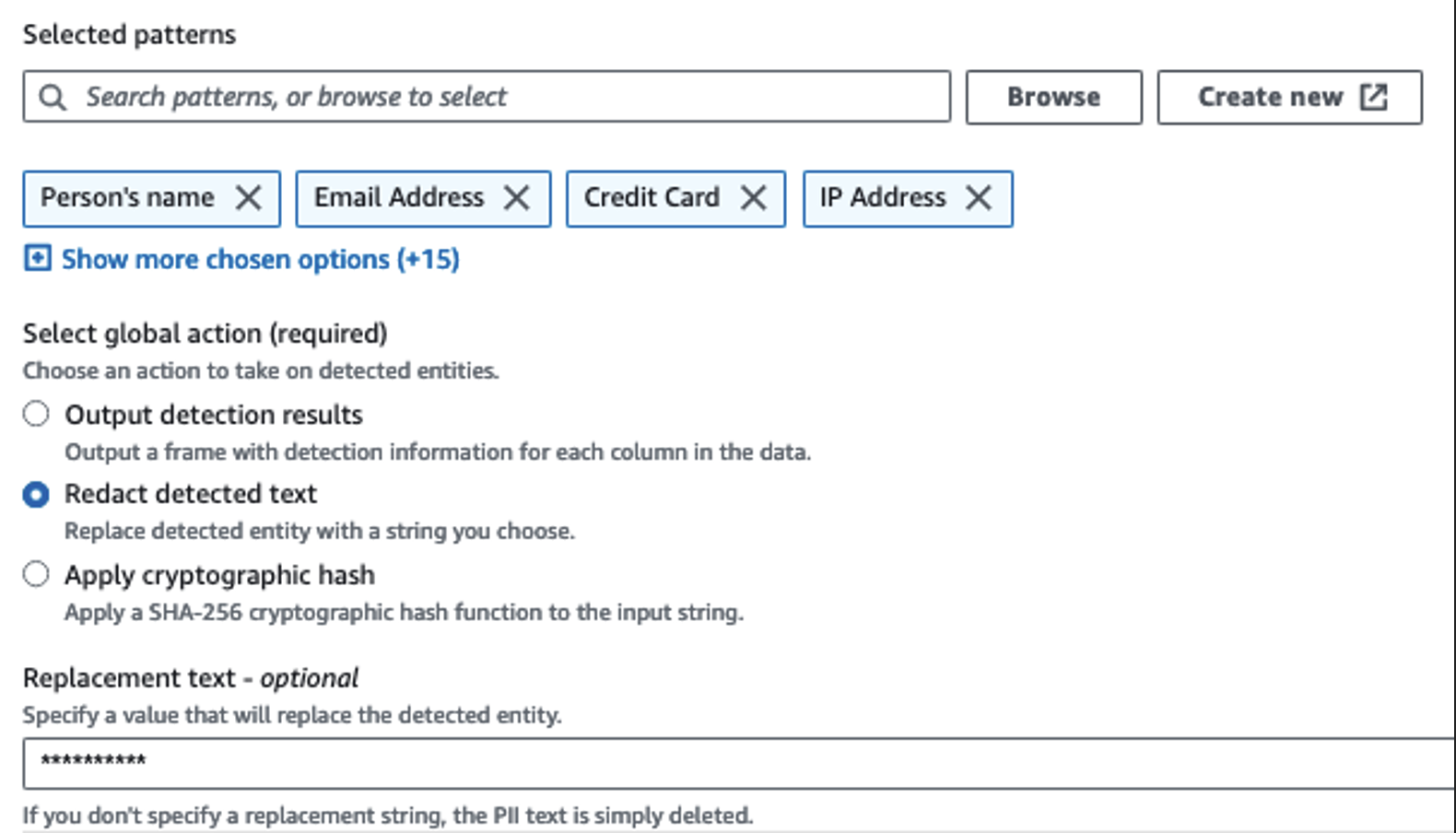
Folosim acțiunea Detect PII pentru a identifica coloanele sensibile. Lăsăm AWS Glue să determine acest lucru pe baza modelelor selectate, a pragului de detectare și a porțiunii de eșantion de rânduri din setul de date. În exemplul nostru, am folosit modele care se aplică în mod specific Statelor Unite (cum ar fi SSN) și este posibil să nu detecteze date sensibile din alte țări. Puteți căuta categorii și locații disponibile aplicabile cazului dvs. de utilizare sau puteți utiliza expresii regulate (regex) în AWS Glue pentru a crea entități de detectare a datelor sensibile din alte țări.
Este important să selectați metoda corectă de eșantionare oferită de AWS Glue. În acest exemplu, se știe că datele care vin din flux au date sensibile pe fiecare rând, așa că nu este necesar să eșantionați 100% dintre rândurile din setul de date. Dacă aveți o cerință în care nu sunt permise date sensibile către sursele din aval, luați în considerare eșantionarea 100% din date pentru modelele pe care le-ați ales sau scanați întregul set de date și acționați asupra fiecărei celule individuale pentru a vă asigura că toate datele sensibile sunt detectate. Beneficiul pe care îl obțineți în urma eșantionării sunt costurile reduse, deoarece nu trebuie să scanați atât de multe date.

Acțiunea Detectare PII vă permite să selectați un șir implicit atunci când mascați datele sensibile. În exemplul nostru, folosim șirul **********.
Folosim operația de aplicare de mapare pentru a redenumi și a elimina coloanele inutile, cum ar fi ingestion_year, ingestion_month, și ingestion_day. Acest pas ne permite, de asemenea, să schimbăm tipul de date al uneia dintre coloane (purchase_value) de la șir la număr întreg.

Din acest moment, jobul se împarte în două destinații de ieșire: OpenSearch Service și Amazon S3.
Clusterul nostru de servicii OpenSearch furnizat este conectat prin intermediul Conector încorporat OpenSearch pentru Glue. Specificăm indexul OpenSearch în care dorim să scriem, iar conectorul se ocupă de acreditările, domeniul și portul. În captura de ecran de mai jos, scriem la indexul specificat index_os_pii.
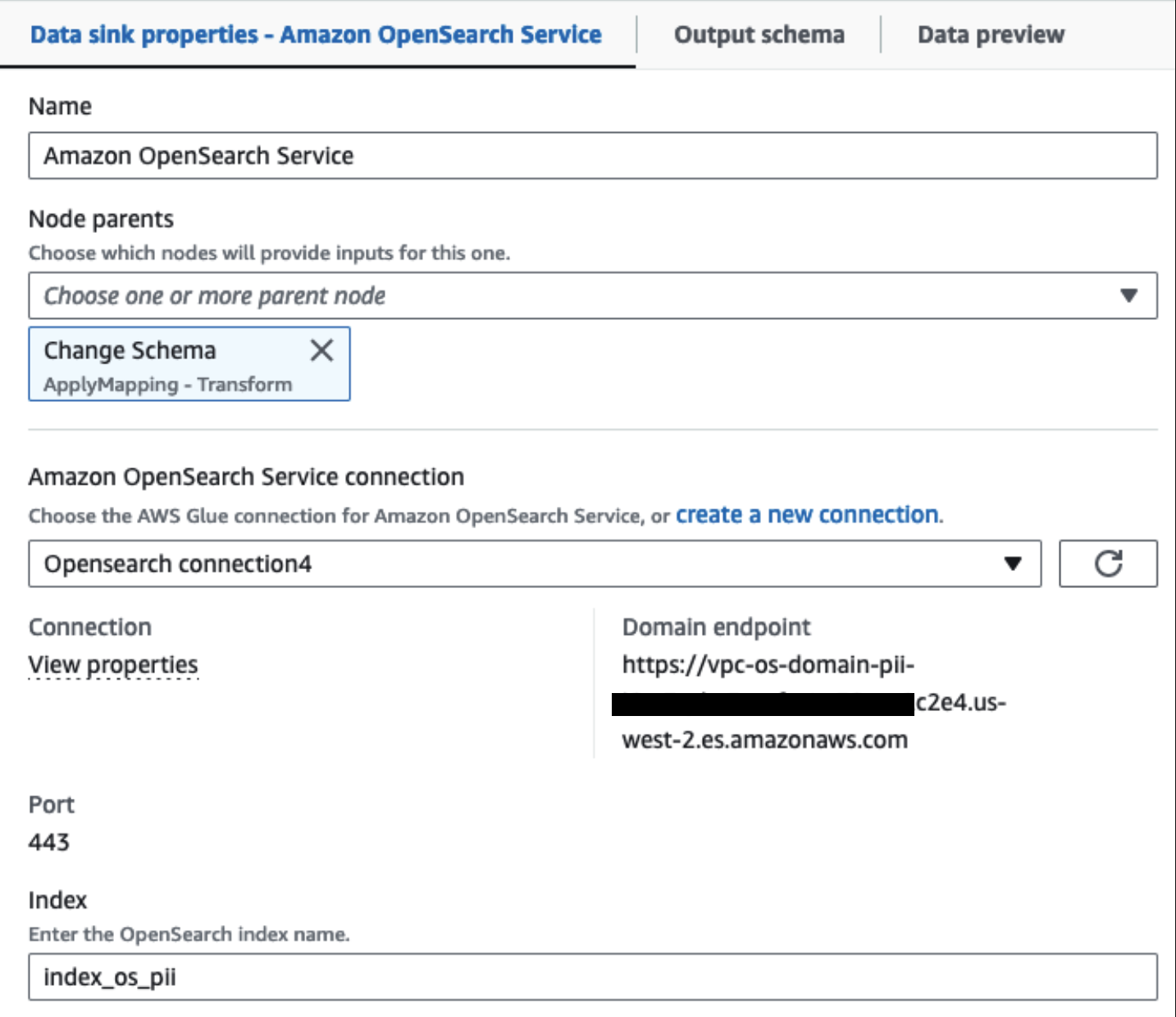
Stocăm setul de date mascat în prefixul S3 curat. Acolo, avem date normalizate pentru un caz de utilizare specific și un consum sigur de către oamenii de știință de date sau pentru nevoi de raportare ad-hoc.
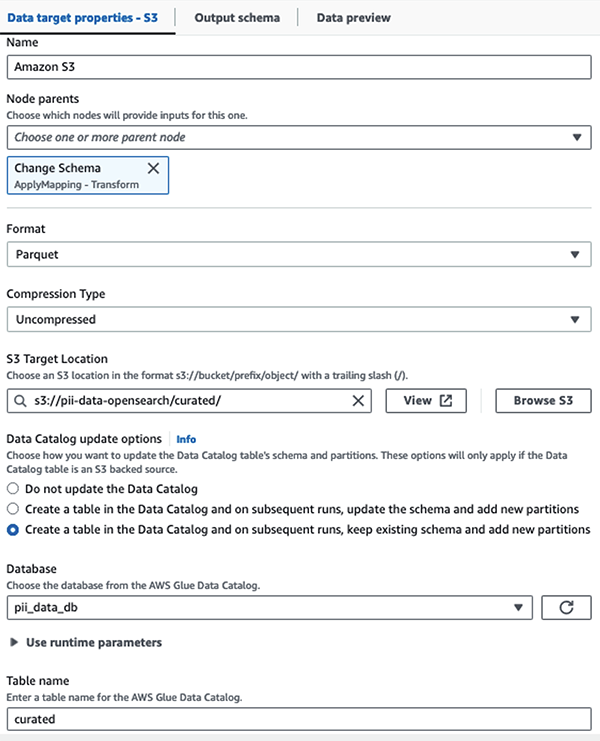
Pentru guvernanță unificată, control al accesului și urmăriri de audit pentru toate seturile de date și tabelele Catalog de date, puteți utiliza Formația lacului AWS. Acest lucru vă ajută să restricționați accesul la tabelele AWS Glue Data Catalog și la datele subiacente numai la acelor utilizatori și roluri cărora li s-au acordat permisiunile necesare pentru a face acest lucru.
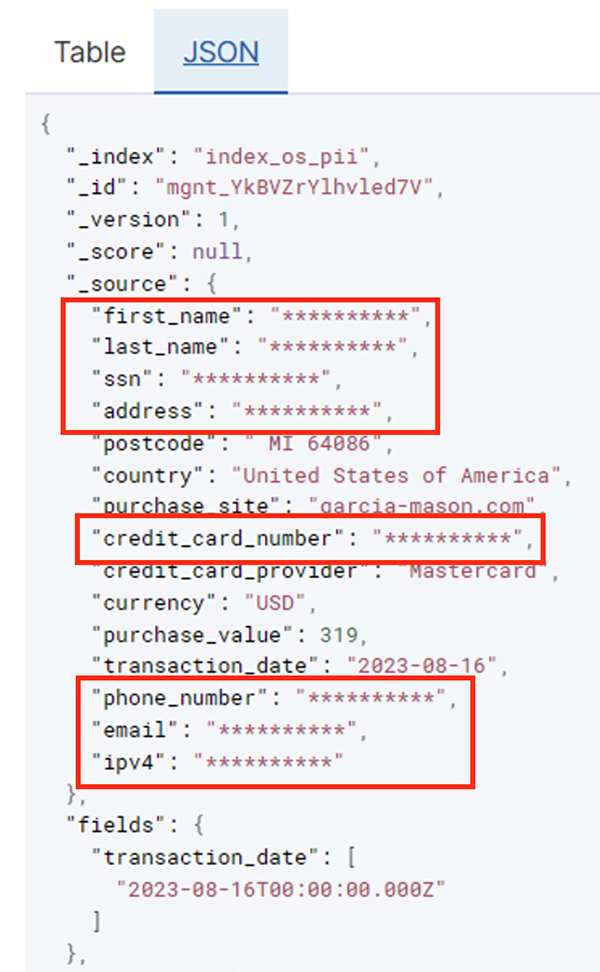
După ce jobul lot rulează cu succes, puteți utiliza OpenSearch Service pentru a rula interogări de căutare sau rapoarte. După cum se arată în următoarea captură de ecran, conducta a mascat automat câmpurile sensibile, fără eforturi de dezvoltare a codului.

Puteți identifica tendințele din datele operaționale, cum ar fi cantitatea de tranzacții pe zi filtrată de furnizorul cardului de credit, așa cum se arată în captura de ecran anterioară. De asemenea, puteți determina locațiile și domeniile în care utilizatorii fac achiziții. The transaction_date atributul ne ajută să vedem aceste tendințe în timp. Următoarea captură de ecran arată o înregistrare cu toate informațiile tranzacției redactate corespunzător.
Pentru metode alternative despre cum să încărcați date în Amazon OpenSearch, consultați Încărcarea datelor de streaming în Amazon OpenSearch Service.
În plus, datele sensibile pot fi descoperite și mascate folosind alte soluții AWS. De exemplu, ai putea folosi Amazon Macie pentru a detecta date sensibile într-un compartiment S3 și apoi utilizați Amazon Comprehend pentru a redacta datele sensibile care au fost detectate. Pentru mai multe informații, consultați Tehnici obișnuite pentru detectarea datelor PHI și PII folosind AWS Services.
Concluzie
Această postare a discutat despre importanța manipulării datelor sensibile în mediul dvs. și a diferitelor metode și arhitecturi pentru a rămâne conforme, permițând totodată organizației dvs. să se extindă rapid. Acum ar trebui să înțelegeți bine cum să detectați, să mascați sau să redactați și să vă încărcați datele în Amazon OpenSearch Service.
Despre autori
 Michael Hamilton este un arhitect senior de soluții de analiză care se concentrează pe a ajuta clienții întreprinderilor să își modernizeze și să-și simplifice sarcinile de lucru de analiză pe AWS. Îi place să meargă cu bicicleta montană și să petreacă timpul cu soția și cei trei copii atunci când nu lucrează.
Michael Hamilton este un arhitect senior de soluții de analiză care se concentrează pe a ajuta clienții întreprinderilor să își modernizeze și să-și simplifice sarcinile de lucru de analiză pe AWS. Îi place să meargă cu bicicleta montană și să petreacă timpul cu soția și cei trei copii atunci când nu lucrează.
 Daniel Rozo este arhitect senior de soluții cu AWS, care sprijină clienții din Țările de Jos. Pasiunea lui este să creeze soluții simple de date și analize și să ajute clienții să treacă la arhitecturi moderne de date. În afara serviciului, îi place să joace tenis și să meargă cu bicicleta.
Daniel Rozo este arhitect senior de soluții cu AWS, care sprijină clienții din Țările de Jos. Pasiunea lui este să creeze soluții simple de date și analize și să ajute clienții să treacă la arhitecturi moderne de date. În afara serviciului, îi place să joace tenis și să meargă cu bicicleta.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :are
- :este
- :nu
- :Unde
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- capacitate
- Capabil
- accelerat
- acces
- act
- Acțiune
- Ad
- adresa
- Agent
- TOATE
- permis
- Permiterea
- permite
- de asemenea
- mereu
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- sumă
- Sume
- an
- Analitic
- Google Analytics
- și
- Orice
- aplicabil
- aplicatii
- Aplică
- abordare
- în mod corespunzător
- arhitectură
- SUNT
- AS
- At
- atribute
- de audit
- automatizarea
- în mod automat
- disponibilitate
- disponibil
- AWS
- AWS Adeziv
- backup-uri
- Bancar
- Sisteme bancare
- bazat
- BE
- deoarece
- fost
- înainte
- fiind
- de mai jos
- beneficia
- aduce
- construi
- construit
- construit-in
- dar
- by
- CAN
- capacități
- Capacitate
- captura
- card
- caz
- cazuri
- catalog
- categorii
- CDC
- celulă
- Schimbare
- Modificări
- canale
- Copii
- a ales
- claritate
- Cloud
- Grup
- cod
- Coloană
- Coloane
- cum
- vine
- venire
- compatibil
- conforme
- componente
- Compus
- Calcula
- preocupările
- legat
- Lua în considerare
- luate în considerare
- consumate
- consum
- conţine
- context
- continua
- Control
- corecta
- Cheltuieli
- ar putea
- țări
- crea
- scrisori de acreditare
- credit
- card de credit
- curator
- Curent
- clienţii care
- de date
- Analiza datelor
- integrarea datelor
- Lacul de date
- Platforma de date
- confidențialitatea datelor
- strategie de date
- Baza de date
- baze de date
- seturi de date
- Data
- zi
- Mod implicit
- definit
- livrate
- demonstra
- demonstrează
- dislocate
- Amenajări
- destinație
- destinații
- detalii
- detecta
- detectat
- Detectare
- Determina
- Dezvoltare
- echipe de dezvoltare
- diferit
- direct
- descoperi
- a descoperit
- discutat
- do
- domeniu
- domenii
- Dont
- fiecare
- Eforturile
- Inginerie
- asigura
- Afacere
- clienții întreprinderii
- Întreg
- entități
- Mediu inconjurator
- Eter (ETH)
- Chiar
- evenimente
- Fiecare
- exemplu
- exemple
- de aşteptat
- experienţă
- expresii
- extern
- FAST
- Domenii
- Fișier
- Fişiere
- financiar
- Servicii financiare
- First
- Curgere
- fluxurilor
- concentrându-se
- a urmat
- următor
- urmează
- Pentru
- Cadru
- din
- Complet
- complet
- viitor
- generator
- obține
- bine
- guvernare
- acordate
- Mânere
- Manipularea
- Avea
- he
- Sănătate
- informație despre sănătate
- ajutor
- ajutor
- ajută
- la nivel înalt
- lui
- istoric
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- sute
- identifica
- if
- ilustrează
- imagina
- punerea în aplicare a
- importanță
- important
- in
- include
- Inclusiv
- index
- individ
- informații
- Infrastructură
- în interiorul
- integrare
- intern
- în
- IT
- Java
- Loc de munca
- Locuri de munca
- jpg
- JSON
- A pastra
- Kinesis Data Firehose
- Fluxuri de date Kinesis
- cunoscut
- lac
- Țară
- terenuri
- mare
- Nume
- mai tarziu
- legii
- Legi și reglementări
- strat
- straturi
- Conducere
- lăsa
- Bibliotecă
- ciclu de viață
- ca
- Linie
- încărca
- încărcare
- Locații
- Uite
- low-cost
- Principal
- mentine
- face
- gestionate
- multe
- cartografiere
- masca
- Mai..
- metodă
- Metode
- migra
- migrațiune
- Modern
- moderniza
- Monitorizarea
- mai mult
- Munte
- muta
- în mişcare
- mult
- multiplu
- trebuie sa
- nume
- nume
- necesar
- Nevoie
- necesar
- au nevoie
- nevoilor
- Olanda
- Nou
- Nu.
- noduri
- Înștiințare..
- acum
- număr
- of
- promoții
- on
- ONE
- afară
- operaţie
- operațional
- Operațiuni
- optimizarea
- Opţiuni
- or
- organizație
- organizații
- Altele
- al nostru
- producție
- exterior
- peste
- parte
- pasiune
- patching
- modele
- Plătește
- plată
- pentru
- efectua
- performanță
- permisiuni
- Personal
- telefon
- PII
- conducte
- plan
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- joc
- Punct
- porţiune
- Post
- precedent
- prezentat
- precedent
- intimitate
- legile de confidențialitate
- prelucrate
- procese
- prelucrare
- producător
- protejat
- protocoale
- furnizorul
- furnizează
- achiziții
- interogări
- repede
- mai degraba
- Crud
- date neprelucrate
- în timp real
- motive
- primire
- Recipes, Romania
- recomandat
- record
- înregistrări
- Redus
- trimite
- regulat
- regulament
- încredere
- rămâne
- scoate
- Raportarea
- Rapoarte
- necesita
- cerință
- Cerinţe
- responsabilităţi
- responsabil
- restrânge
- REZULTATE
- rolurile
- RÂND
- Alerga
- ruleaza
- SaaS
- sacrificare
- sigur
- în siguranță
- acelaşi
- Scară
- scanare
- programa
- oamenii de stiinta
- Ecran
- sdk
- Caută
- Secțiune
- în siguranță,
- securitate
- vedea
- selecta
- selectate
- senior
- sensibil
- trimis
- serviciu
- Servicii
- shot
- să
- indicat
- Emisiuni
- simplu
- simplifica
- mic
- So
- Social
- Software
- sistem de operare ca serviciu
- soluţie
- soluţii
- Sursă
- Surse
- specific
- specific
- specificată
- petrece
- Cheltuire
- șpalturi
- Stadiile
- Statele
- Pas
- depozitare
- stoca
- simplu
- Strategie
- curent
- de streaming
- fluxuri
- Şir
- structura
- structurat
- studio
- ulterior
- Reușit
- astfel de
- potrivit
- Suportat
- De sprijin
- sistem
- sisteme
- tabel
- ia
- Ţintă
- echipă
- echipe
- tehnici de
- tenis
- zeci
- decât
- acea
- Viitorul
- Olanda
- Sursa
- lor
- apoi
- Acolo.
- Acestea
- acest
- aceste
- trei
- prag
- Prin
- timp
- la
- a luat
- Unelte
- urmări
- Tranzacții
- transfer
- Transferuri
- Transforma
- Transformare
- Tendinţe
- a declanșat
- Două
- tip
- Tipuri
- în cele din urmă
- care stau la baza
- înţelegere
- unificat
- Unit
- Statele Unite
- us
- utilizare
- carcasa de utilizare
- utilizat
- utilizatorii
- folosind
- valoare
- varietate
- diverse
- de
- vizual
- umbla
- a fost
- modalități de
- we
- web
- servicii web
- Ce
- cand
- care
- în timp ce
- OMS
- soţie
- voi
- cu
- în
- fără
- Apartamente
- flux de lucru
- de lucru
- scrie
- tu
- Ta
- zephyrnet