Reziliența joacă un rol esențial în dezvoltarea oricărei sarcini de lucru și AI generativă sarcinile de lucru nu sunt diferite. Există considerații unice atunci când proiectați sarcinile de lucru AI generative prin prisma rezilienței. Înțelegerea și prioritizarea rezilienței este esențială pentru sarcinile de lucru AI generative pentru a îndeplini cerințele privind disponibilitatea organizațională și continuitatea afacerii. În această postare, discutăm despre diferitele stive ale unei sarcini de lucru AI generative și care ar trebui să fie aceste considerente.
AI generativ full stack
Deși o mare parte din entuziasmul AI generativ se concentrează pe modele, o soluție completă implică oameni, abilități și instrumente din mai multe domenii. Luați în considerare următoarea imagine, care este o vedere AWS a stivei de aplicații emergente a16z pentru modele de limbaj mari (LLM).
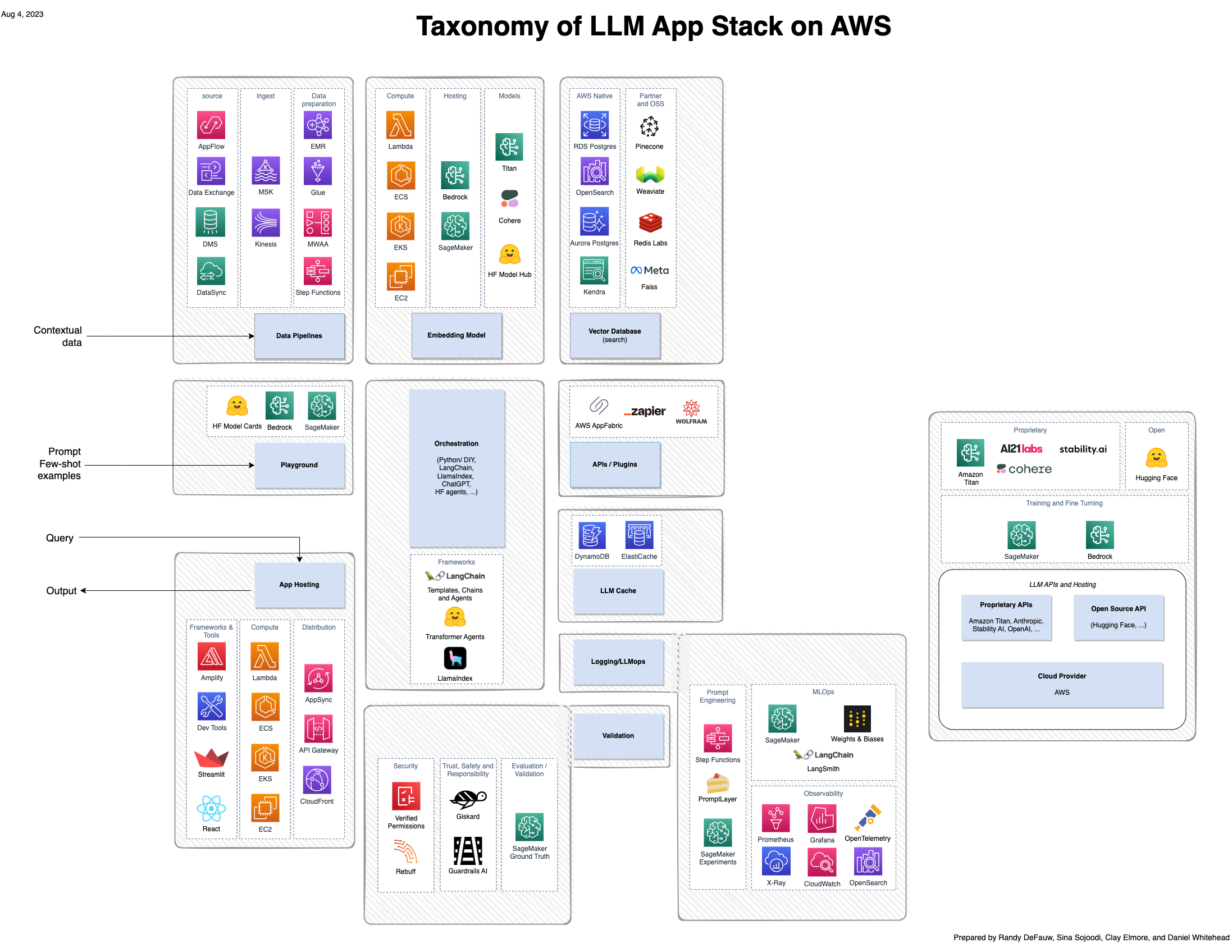
În comparație cu o soluție mai tradițională construită în jurul AI și învățarea automată (ML), o soluție AI generativă implică acum următoarele:
- Roluri noi – Trebuie să luați în considerare tunerele de modele, precum și constructorii de modele și integratorii de modele
- Instrumente noi – Stiva tradițională MLOps nu se extinde pentru a acoperi tipul de urmărire sau observabilitate a experimentelor necesare pentru inginerie promptă sau agenți care invocă instrumente pentru a interacționa cu alte sisteme
Raționamentul agentului
Spre deosebire de modelele tradiționale AI, Retrieval Augmented Generation (RAG) permite răspunsuri mai precise și mai relevante din punct de vedere contextual prin integrarea surselor externe de cunoștințe. Următoarele sunt câteva considerații atunci când utilizați RAG:
- Setarea timeout-urilor adecvate este importantă pentru experiența clientului. Nimic nu spune o experiență proastă a utilizatorului mai mult decât să fii în mijlocul unui chat și să te deconectezi.
- Asigurați-vă că validați datele de introducere promptă și dimensiunea de intrare promptă pentru limitele de caractere alocate care sunt definite de modelul dvs.
- Dacă efectuați inginerie promptă, ar trebui să păstrați solicitările într-un depozit de date de încredere. Acest lucru vă va proteja solicitările în caz de pierdere accidentală sau ca parte a strategiei generale de recuperare în caz de dezastru.
Conducte de date
În cazurile în care trebuie să furnizați date contextuale modelului de fundație folosind modelul RAG, aveți nevoie de o conductă de date care să poată asimila datele sursă, să le convertească în vectori de încorporare și să stocheze vectorii de încorporare într-o bază de date vectorială. Acest pipeline poate fi un lot dacă pregătiți date contextuale în avans sau un pipeline cu latență scăzută dacă încorporați noi date contextuale din mers. În cazul loturilor, există câteva provocări în comparație cu conductele de date tipice.
Sursele de date pot fi documente PDF dintr-un sistem de fișiere, date dintr-un sistem software ca serviciu (SaaS) cum ar fi un instrument CRM sau date dintr-un wiki sau bază de cunoștințe existente. Ingerarea din aceste surse este diferită de sursele tipice de date, cum ar fi datele de jurnal într-un Serviciul Amazon de stocare simplă (Amazon S3) găleată sau date structurate dintr-o bază de date relațională. Nivelul de paralelism pe care îl puteți atinge poate fi limitat de sistemul sursă, așa că trebuie să țineți cont de throttling și să utilizați tehnici de backoff. Unele dintre sistemele sursă pot fi fragile, așa că trebuie să construiți logica de gestionare a erorilor și reîncercați.
Modelul de încorporare ar putea fi un blocaj de performanță, indiferent dacă îl rulați local în conductă sau apelați un model extern. Modelele de încorporare sunt modele de bază care rulează pe GPU și nu au capacitate nelimitată. Dacă modelul rulează local, trebuie să atribuiți lucrul pe baza capacității GPU. Dacă modelul rulează extern, trebuie să vă asigurați că nu saturați modelul extern. În ambele cazuri, nivelul de paralelism pe care îl puteți obține va fi dictat de modelul de încorporare, mai degrabă decât de cât de mult CPU și RAM aveți la dispoziție în sistemul de procesare batch.
În cazul cu latență scăzută, trebuie să luați în considerare timpul necesar pentru a genera vectorii de încorporare. Aplicația care apelează ar trebui să invoce conducta în mod asincron.
Baze de date vectoriale
O bază de date vectorială are două funcții: stochează vectori de încorporare și rulează o căutare de similaritate pentru a găsi cel mai apropiat k se potrivește cu un nou vector. Există trei tipuri generale de baze de date vectoriale:
- Opțiuni SaaS dedicate, cum ar fi Pinecone.
- Caracteristicile bazei de date vectoriale integrate în alte servicii. Aceasta include servicii native AWS, cum ar fi Serviciul Amazon OpenSearch și Amazon Aurora.
- Opțiuni în memorie care pot fi utilizate pentru date tranzitorii în scenarii cu latență scăzută.
Nu acoperim în detaliu capabilitățile de căutare a similarității în această postare. Deși sunt importante, sunt un aspect funcțional al sistemului și nu afectează în mod direct rezistența. În schimb, ne concentrăm pe aspectele de reziliență ale unei baze de date vectoriale ca sistem de stocare:
- Latență – Poate baza de date vectorială să funcționeze bine împotriva unei sarcini mari sau imprevizibile? Dacă nu, aplicația care apelează trebuie să se ocupe de limitarea ratei și să se retragă și să încerce din nou.
- scalabilitate – Câți vectori poate conține sistemul? Dacă depășiți capacitatea bazei de date vectoriale, va trebui să căutați sharding sau alte soluții.
- Disponibilitate ridicată și recuperare în caz de dezastru – Încorporarea vectorilor sunt date valoroase, iar recrearea acestora poate fi costisitoare. Este baza dvs. de date vectorială foarte disponibilă într-o singură regiune AWS? Are capacitatea de a replica datele în altă regiune în scopuri de recuperare în caz de dezastru?
Nivelul de aplicație
Există trei considerații unice pentru nivelul de aplicație atunci când se integrează soluții AI generative:
- Latență potențial mare – Modelele de bază rulează adesea pe instanțe GPU mari și pot avea o capacitate limitată. Asigurați-vă că utilizați cele mai bune practici pentru limitarea ratei, retragerea și reîncercarea și reducerea încărcăturii. Utilizați modele asincrone, astfel încât latența mare să nu interfereze cu interfața principală a aplicației.
- Postura de securitate – Dacă utilizați agenți, instrumente, pluginuri sau alte metode de conectare a unui model la alte sisteme, acordați o atenție sporită poziției dvs. de securitate. Modelele pot încerca să interacționeze cu aceste sisteme în moduri neașteptate. Urmați practica obișnuită a accesului cu cel mai mic privilegiu, de exemplu restricționarea solicitărilor primite de la alte sisteme.
- Cadre care evoluează rapid – Cadrele open source precum LangChain evoluează rapid. Utilizați o abordare cu microservicii pentru a izola alte componente din aceste cadre mai puțin mature.
Capacitate
Ne putem gândi la capacitate în două contexte: conducte de date model de inferență și antrenament. Capacitatea este o considerație atunci când organizațiile își construiesc propriile conducte. Cerințele CPU și memorie sunt două dintre cele mai mari cerințe atunci când alegeți instanțe pentru a vă rula sarcinile de lucru.
Instanțele care pot suporta sarcini de lucru AI generative pot fi mai dificil de obținut decât tipul de instanță de uz general mediu. Flexibilitatea instanțelor poate ajuta la planificarea capacității și a capacității. În funcție de regiunea AWS în care rulați sarcina de lucru, sunt disponibile diferite tipuri de instanțe.
Pentru călătoriile utilizatorilor care sunt critice, organizațiile vor dori să ia în considerare fie rezervarea, fie pre-provizionarea tipurilor de instanță pentru a asigura disponibilitatea atunci când este necesar. Acest model realizează o arhitectură stabilă din punct de vedere static, care este o bună practică de reziliență. Pentru a afla mai multe despre stabilitatea statică în pilonul de fiabilitate AWS Well-Architected Framework, consultați Utilizați stabilitatea statică pentru a preveni comportamentul bimodal.
observability
Pe lângă valorile de resurse pe care le colectați de obicei, cum ar fi utilizarea CPU și RAM, trebuie să monitorizați îndeaproape utilizarea GPU dacă găzduiți un model pe Amazon SageMaker or Cloud Elastic de calcul Amazon (Amazon EC2). Utilizarea GPU-ului se poate schimba în mod neașteptat dacă modelul de bază sau datele de intrare se modifică, iar epuizarea memoriei GPU poate pune sistemul într-o stare instabilă.
Mai sus în stivă, veți dori, de asemenea, să urmăriți fluxul de apeluri prin sistem, captând interacțiunile dintre agenți și instrumente. Deoarece interfața dintre agenți și instrumente este definită mai puțin formal decât un contract API, ar trebui să monitorizați aceste urme nu numai pentru performanță, ci și pentru a captura noi scenarii de eroare. Pentru a monitoriza modelul sau agentul pentru orice riscuri și amenințări de securitate, puteți utiliza instrumente precum Serviciul de gardă Amazon.
De asemenea, ar trebui să capturați liniile de bază ale vectorilor de încorporare, solicitărilor, contextului și ieșirii, precum și interacțiunile dintre acestea. Dacă acestea se modifică în timp, poate indica faptul că utilizatorii folosesc sistemul în moduri noi, că datele de referință nu acoperă spațiul de întrebări în același mod sau că rezultatul modelului este brusc diferit.
Recuperare în caz de dezastru
A avea un plan de continuitate a afacerii cu o strategie de recuperare în caz de dezastru este o necesitate pentru orice volum de muncă. Sarcinile de lucru AI generative nu sunt diferite. Înțelegerea modurilor de eșec care sunt aplicabile sarcinii dvs. de lucru vă va ajuta să vă ghidați strategia. Dacă utilizați servicii gestionate AWS pentru volumul dvs. de lucru, cum ar fi Amazon Bedrock și SageMaker, asigurați-vă că serviciul este disponibil în regiunea dvs. AWS de recuperare. În momentul în care scriem aceste documente, aceste servicii AWS nu acceptă replicarea datelor în regiunile AWS în mod nativ, așa că trebuie să vă gândiți la strategiile de gestionare a datelor pentru recuperarea în caz de dezastru și, de asemenea, poate fi necesar să ajustați mai multe regiuni AWS.
Concluzie
Această postare a descris cum să țineți cont de reziliență atunci când construiți soluții AI generative. Deși aplicațiile AI generative au câteva nuanțe interesante, modelele de reziliență existente și cele mai bune practici încă se aplică. Este doar o chestiune de evaluare a fiecărei părți a unei aplicații AI generative și de aplicarea celor mai bune practici relevante.
Pentru mai multe informații despre AI generativă și despre utilizarea acesteia cu serviciile AWS, consultați următoarele resurse:
Despre Autori
 Jennifer Moran este un AWS Senior Resiliency Specialist Solutions Architect cu sediul în New York City. Ea are o experiență diversă, a lucrat în multe discipline tehnice, inclusiv dezvoltarea de software, leadership agil și DevOps, și este un avocat al femeilor în tehnologie. Îi face plăcere să ajute clienții să proiecteze soluții rezistente pentru a îmbunătăți postura de rezistență și vorbește public despre toate subiectele legate de rezistență.
Jennifer Moran este un AWS Senior Resiliency Specialist Solutions Architect cu sediul în New York City. Ea are o experiență diversă, a lucrat în multe discipline tehnice, inclusiv dezvoltarea de software, leadership agil și DevOps, și este un avocat al femeilor în tehnologie. Îi face plăcere să ajute clienții să proiecteze soluții rezistente pentru a îmbunătăți postura de rezistență și vorbește public despre toate subiectele legate de rezistență.
 Randy DeFauw este arhitect principal principal de soluții la AWS. El deține un MSEE de la Universitatea din Michigan, unde a lucrat la viziunea computerizată pentru vehicule autonome. De asemenea, deține un MBA de la Universitatea de Stat din Colorado. Randy a ocupat o varietate de poziții în spațiul tehnologic, de la inginerie software la managementul produselor. A intrat în spațiul big data în 2013 și continuă să exploreze acea zonă. Lucrează activ la proiecte în spațiul ML și a prezentat la numeroase conferințe, inclusiv Strata și GlueCon.
Randy DeFauw este arhitect principal principal de soluții la AWS. El deține un MSEE de la Universitatea din Michigan, unde a lucrat la viziunea computerizată pentru vehicule autonome. De asemenea, deține un MBA de la Universitatea de Stat din Colorado. Randy a ocupat o varietate de poziții în spațiul tehnologic, de la inginerie software la managementul produselor. A intrat în spațiul big data în 2013 și continuă să exploreze acea zonă. Lucrează activ la proiecte în spațiul ML și a prezentat la numeroase conferințe, inclusiv Strata și GlueCon.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- :are
- :este
- :nu
- :Unde
- $UP
- 100
- 2013
- 90
- a
- a16z
- capacitate
- Despre Noi
- acces
- accidental
- Cont
- precis
- Obține
- Realizeaza
- peste
- activ
- avansa
- avocat
- afecta
- împotriva
- Agent
- agenţi
- agil
- AI
- Modele AI
- TOATE
- alocate
- permite
- de asemenea
- Cu toate ca
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- și
- O alta
- Orice
- api
- aplicaţia
- aplicabil
- aplicație
- aplicatii
- Aplică
- Aplicarea
- abordare
- adecvat
- arhitectură
- SUNT
- ZONĂ
- în jurul
- AS
- aspect
- aspecte
- At
- atenţie
- augmented
- autonom
- autovehicule autonome
- disponibilitate
- disponibil
- in medie
- AWS
- fundal
- Rău
- de bază
- bazat
- BE
- deoarece
- fiind
- CEL MAI BUN
- Cele mai bune practici
- între
- Mare
- Datele mari
- Cea mai mare
- strangulare
- construi
- constructori
- Clădire
- construit
- afaceri
- continuitatea afacerii
- dar
- by
- apel
- apel
- apeluri
- CAN
- capacități
- Capacitate
- captura
- capturarea
- caz
- cazuri
- provocări
- Schimbare
- Modificări
- caracter
- Chat
- alegere
- Oraș
- îndeaproape
- colecta
- Colorado
- comparație
- Completă
- componente
- Calcula
- calculator
- Computer Vision
- conferințe
- Conectarea
- Lua în considerare
- considerare
- Considerații
- context
- contexte
- contextual
- continuă
- continuitate
- contract
- converti
- ar putea
- Cuplu
- acoperi
- acoperire
- Procesor
- critic
- CRM
- crucial
- client
- experienta clientului
- clienţii care
- de date
- management de date
- Baza de date
- baze de date
- definit
- În funcție
- descris
- Amenajări
- proiect
- modele
- detaliu
- Dezvoltare
- DevOps
- dictat
- diferit
- dificil
- direct
- dezastru
- discipline
- decuplat
- discuta
- diferit
- do
- documente
- face
- Nu
- domenii
- Dont
- fiecare
- oricare
- Încorporarea
- șmirghel
- Inginerie
- asigura
- a intrat
- eroare
- Eter (ETH)
- evaluarea
- evoluție
- exemplu
- depăși
- Excitare
- existent
- scump
- experienţă
- experiment
- explora
- extinde
- extern
- extern
- suplimentar
- Eșec
- DESCRIERE
- Fișier
- Găsi
- Flexibilitate
- debit
- Concentra
- se concentrează
- urma
- următor
- Pentru
- Oficial
- Fundație
- Cadru
- cadre
- din
- funcțional
- funcții
- General
- scop general
- genera
- generaţie
- generativ
- AI generativă
- obtinerea
- GPU
- unități de procesare grafică
- ghida
- manipula
- Manipularea
- Avea
- având în
- he
- Held
- ajutor
- ajutor
- Înalt
- extrem de
- deţine
- deține
- gazdă
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- if
- important
- îmbunătăţi
- in
- include
- Inclusiv
- Intrare
- care încorporează
- indica
- informații
- intrare
- instanță
- cazuri
- in schimb
- integrarea
- interacţiona
- interacţiuni
- interesant
- interfaţă
- interfera
- în
- implică
- IT
- călătoriile
- doar
- cunoştinţe
- limbă
- mare
- Latență
- Conducere
- AFLAȚI
- învăţare
- Obiectiv
- mai puțin
- Nivel
- ca
- Limitat
- limitativ
- Limitele
- LLM
- încărca
- la nivel local
- log
- logică
- Uite
- de pe
- Lot
- maşină
- masina de învățare
- Principal
- face
- gestionate
- administrare
- multe
- meciuri
- materie
- matur
- Mai..
- MBA
- Întâlni
- Memorie
- Metode
- Metrici
- Michigan
- microservices
- De mijloc
- ML
- MLOps
- model
- Modele
- moduri de
- monitor
- mai mult
- mult
- multiplu
- trebuie sa
- nativ
- nativ
- necesar
- Nevoie
- necesar
- nevoilor
- Nou
- New York
- New York City
- Nu.
- normală.
- nimic
- acum
- umbrire
- numeroși
- obține
- of
- de multe ori
- on
- afară
- deschide
- open-source
- Opţiuni
- or
- de organizare
- organizații
- Altele
- afară
- producție
- peste
- global
- propriu
- parte
- Model
- modele
- Plătește
- oameni
- efectua
- performanță
- efectuarea
- imagine
- Stâlp
- conducte
- pivot
- plan
- planificare
- Plato
- Informații despre date Platon
- PlatoData
- joacă
- Plugin-uri
- poziţii
- Post
- practică
- practicile
- Pregăti
- prezentat
- împiedica
- Principal
- Stabilirea priorităților
- prelucrare
- Produs
- management de produs
- Proiecte
- solicitări
- furniza
- public
- scopuri
- pune
- întrebare
- cârpă
- RAM
- variind
- repede
- rată
- mai degraba
- recuperare
- trimite
- referință
- Fără deosebire
- regiune
- regiuni
- legate de
- încredere
- de încredere
- replică
- Cerinţe
- elasticitate
- elastic
- resursă
- Resurse
- răspunsuri
- restricționarea
- regăsire
- Riscurile
- Rol
- Alerga
- funcţionare
- ruleaza
- SaaS
- sagemaker
- acelaşi
- spune
- scenarii
- Caută
- căutare
- securitate
- riscuri de securitate
- senior
- serviciu
- Servicii
- câteva
- sharding
- ea
- vărsare
- să
- simplu
- singur
- Mărimea
- aptitudini
- So
- Software
- sistem de operare ca serviciu
- de dezvoltare de software
- Inginerie software
- soluţie
- soluţii
- unele
- Sursă
- Surse
- Spaţiu
- vorbeşte
- specialist
- Stabilitate
- stabil
- stivui
- Stive
- Stat
- Încă
- depozitare
- stoca
- strategii
- Strategie
- structurat
- astfel de
- a sustine
- sigur
- sistem
- sisteme
- Lua
- ia
- taxonomie
- tech
- Tehnic
- tehnici de
- Tehnologia
- decât
- acea
- Sursa
- lor
- Lor
- Acolo.
- Acestea
- ei
- crede
- acest
- aceste
- amenințări
- trei
- Prin
- Nivelul
- timp
- la
- instrument
- Unelte
- subiecte
- urmări
- Urmărire
- tradiţional
- Pregătire
- încerca
- Două
- tip
- Tipuri
- tipic
- tipic
- înţelegere
- Neașteptat
- unic
- universitate
- Universitatea din Michigan
- nelimitat
- imprevizibil
- utilizare
- utilizat
- Utilizator
- Experiența de utilizare
- utilizatorii
- folosind
- VALIDA
- Valoros
- varietate
- Vehicule
- Vizualizare
- viziune
- vrea
- Cale..
- modalități de
- we
- web
- servicii web
- BINE
- Ce
- cand
- dacă
- care
- voi
- cu
- Femei
- femei în tehnologie
- Apartamente
- a lucrat
- de lucru
- scris
- York
- tu
- Ta
- zephyrnet