Introducere
În lumea cu ritm rapid de astăzi, serviciul pentru clienți este un aspect crucial al oricărei afaceri. Un Zendesk Answer Bot, alimentat de modele de limbaj mari (LLM) precum GPT-4, poate îmbunătăți semnificativ eficiența și calitatea asistenței clienților prin automatizarea răspunsurilor. Această postare de blog vă va ghida prin construirea și implementarea propriului dvs. Zendesk Auto Responder folosind LLM-uri și implementarea fluxurilor de lucru bazate pe RAG în GenAI pentru a simplifica procesul.

Ce sunt fluxurile de lucru bazate pe RAG în GenAI
Fluxurile de lucru bazate pe RAG (Retrieval Augmented Generation) în GenAI (Generative AI) combină beneficiile recuperării și generării pentru a îmbunătăți capacitățile sistemului AI, în special în manipularea datelor din lumea reală, specifice domeniului. În termeni simpli, RAG permite AI să extragă informații relevante dintr-o bază de date sau din alte surse pentru a sprijini generarea de răspunsuri mai precise și mai informate. Acest lucru este deosebit de benefic în mediile de afaceri în care acuratețea și contextul sunt esențiale.
Care sunt componentele unui flux de lucru bazat pe RAG
- Bază de cunoștințe: Baza de cunoștințe este un depozit centralizat de informații la care se referă sistemul atunci când răspunde la întrebări. Poate include întrebări frecvente, manuale și alte documente relevante.
- Declanșare/Interogare: Această componentă este responsabilă pentru inițierea fluxului de lucru. De obicei, întrebarea sau cererea unui client necesită un răspuns sau o acțiune.
- Sarcină/Acțiune: Pe baza analizei declanșatorului/interogării, sistemul efectuează o sarcină sau o acțiune specifică, cum ar fi generarea unui răspuns sau efectuarea unei operații de backend.
Câteva exemple de fluxuri de lucru bazate pe RAG
- Flux de lucru pentru interacțiunea cu clienții în domeniul bancar:
- Chatbot-urile alimentate de GenAI și RAG pot îmbunătăți semnificativ ratele de implicare în industria bancară prin personalizarea interacțiunilor.
- Prin intermediul RAG, chatboții pot prelua și utiliza informații relevante dintr-o bază de date pentru a genera răspunsuri personalizate la întrebările clienților.
- De exemplu, în timpul unei sesiuni de chat, un sistem GenAI bazat pe RAG ar putea extrage istoricul tranzacțiilor clientului sau informațiile despre cont dintr-o bază de date pentru a oferi răspunsuri mai informate și personalizate.
- Acest flux de lucru nu numai că îmbunătățește satisfacția clienților, ci și potențial crește rata de retenție, oferind o experiență de interacțiune mai personalizată și mai informativă.
- Flux de lucru pentru campanii prin e-mail:
- În marketing și vânzări, crearea de campanii direcționate este crucială.
- RAG poate fi folosit pentru a extrage cele mai recente informații despre produse, feedback-ul clienților sau tendințele pieței din surse externe pentru a ajuta la generarea de materiale de marketing / vânzări mai informate și mai eficiente.
- De exemplu, atunci când creați o campanie de e-mail, un flux de lucru bazat pe RAG ar putea prelua recenzii pozitive recente sau noi caracteristici ale produsului pentru a le include în conținutul campaniei, îmbunătățind astfel ratele de implicare și rezultatele vânzărilor.
- Flux de lucru automatizat de documentare și modificare a codului:
- Inițial, un sistem RAG poate extrage documentația de cod existentă, baza de cod și standardele de codare din depozitul de proiect.
- Când un dezvoltator trebuie să adauge o nouă caracteristică, RAG poate genera un fragment de cod urmând standardele de codificare ale proiectului, făcând referire la informațiile preluate.
- Dacă este necesară o modificare a codului, sistemul RAG poate propune modificări prin analiza codului și documentației existente, asigurând coerența și aderarea la standardele de codare.
- Modificarea sau adăugarea codului poștal, RAG poate actualiza automat documentația codului pentru a reflecta modificările, extragând informațiile necesare din baza de cod și din documentația existentă.
Cum să descărcați și să indexați toate biletele Zendesk pentru recuperare
Să începem acum cu tutorialul. Vom construi un bot pentru a răspunde biletelor Zendesk primite în timp ce folosim o bază de date personalizată cu bilete și răspunsuri Zendesk anterioare pentru a genera răspunsul cu ajutorul LLM-urilor.
- Accesați API-ul Zendesk: Utilizați Zendesk API pentru a accesa și descărca toate biletele. Asigurați-vă că aveți permisiunile și cheile API necesare pentru a accesa datele.
Mai întâi creăm cheia API Zendesk. Asigurați-vă că sunteți administrator și accesați următorul link pentru a vă crea cheia API – https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/apis/zendesk-api/settings/tokens
Creați o cheie API și copiați-o în clipboard.

Să începem acum cu un caiet Python.
Introducem acreditările Zendesk, inclusiv cheia API pe care tocmai am obținut-o.
subdomain = YOUR_SUBDOMAIN
username = ZENDESK_USERNAME
password = ZENDESK_API_KEY
username = '{}/token'.format(username)Acum recuperăm datele biletelor. În codul de mai jos, am preluat interogări și răspunsuri de la fiecare bilet și stocăm fiecare set [interogare, matrice de răspunsuri] reprezentând un bilet într-o matrice numită datele biletelor.
Aducem doar cele mai recente 1000 de bilete. Puteți modifica acest lucru după cum este necesar.
import requests ticketdata = []
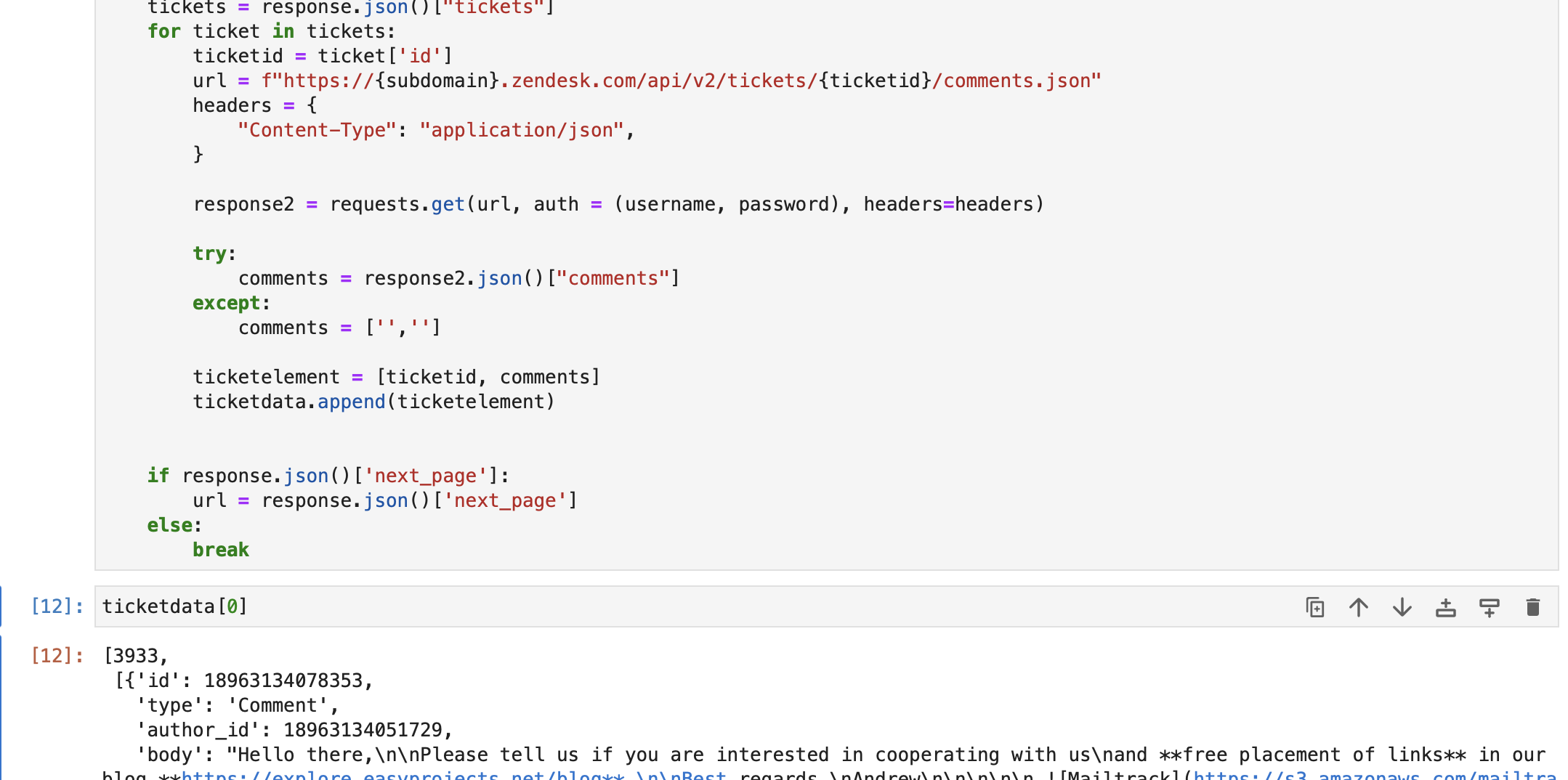
url = f"https://{subdomain}.zendesk.com/api/v2/tickets.json" params = {"sort_by": "created_at", "sort_order": "desc"} headers = {"Content-Type": "application/json"} tickettext = "" while len(ticketdata) <= 1000: response = requests.get( url, auth=(username, password), params=params, headers=headers ) tickets = response.json()["tickets"] for ticket in tickets: ticketid = ticket["id"] url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticketid}/comments.json" headers = { "Content-Type": "application/json", } response2 = requests.get(url, auth=(username, password), headers=headers) try: comments = response2.json()["comments"] except: comments = ["", ""] ticketelement = [ticketid, comments] ticketdata.append(ticketelement) if response.json()["next_page"]: url = response.json()["next_page"] else: breakDupă cum puteți vedea mai jos, am preluat datele biletelor din Zendesk db. Fiecare element din datele biletelor conţine -
A. ID-ul biletului
b. Toate comentariile/răspunsurile în bilet.
Apoi trecem la crearea unui șir bazat pe text cu interogările și primele răspunsuri de la toate biletele recuperate, folosind datele biletelor matrice.
for ticket in ticketdata: try: text = ( "nnn" + "Question - " + ticket[1][0]["body"] + "n" + "Answer - " + ticket[1][1]["body"] ) tickettext = tickettext + text except: passtextul biletului șirul conține acum toate biletele și primele răspunsuri, cu datele fiecărui bilet separate prin caractere newline.

Opțional: De asemenea, puteți prelua date din articolele dvs. de asistență Zendesk pentru a extinde și mai mult baza de cunoștințe, rulând codul de mai jos.
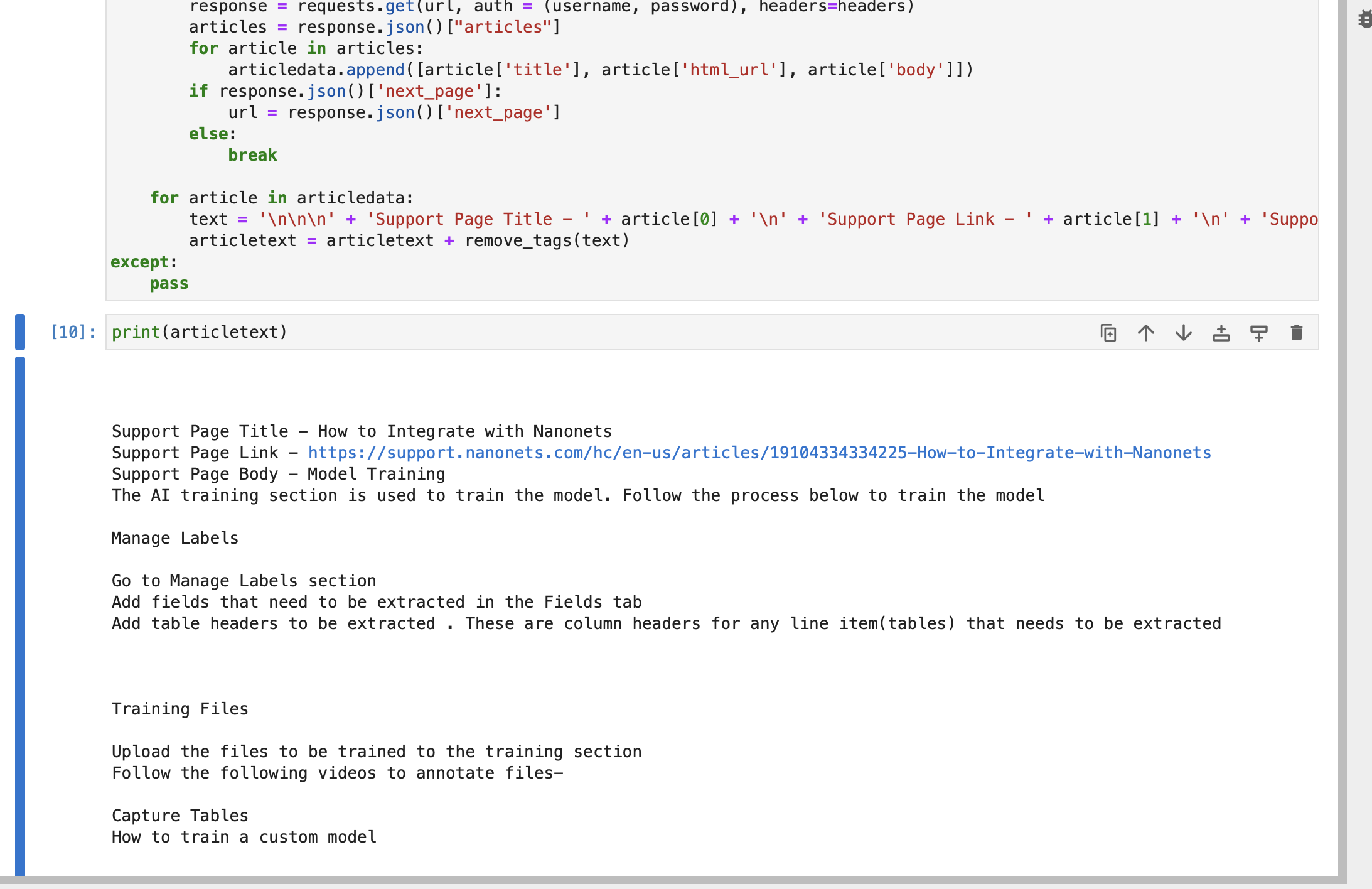
import re def remove_tags(text): clean = re.compile("<.*?>") return re.sub(clean, "", text) articletext = ""
try: articledata = [] url = f"https://{subdomain}.zendesk.com/api/v2/help_center/en-us/articles.json" headers = {"Content-Type": "application/json"} while True: response = requests.get(url, auth=(username, password), headers=headers) articles = response.json()["articles"] for article in articles: articledata.append([article["title"], article["html_url"], article["body"]]) if response.json()["next_page"]: url = response.json()["next_page"] else: break for article in articledata: text = ( "nnn" + "Support Page Title - " + article[0] + "n" + "Support Page Link - " + article[1] + "n" + "Support Page Body - " + article[2] ) articletext = articletext + remove_tags(text)
except: passȘirul textul articolului conține titlul, linkul și corpul fiecărui articol din paginile dvs. de asistență Zendesk.
Opțional : Puteți să vă conectați baza de date cu clienți sau orice altă bază de date relevantă și apoi să o utilizați în timp ce creați magazinul de indexuri.
Combinați datele preluate.
knowledge = tickettext + "nnn" + articletext- Bilete de index: Odată descărcate, indexați biletele folosind o metodă de indexare adecvată pentru a facilita recuperarea rapidă și eficientă.
Pentru a face acest lucru, mai întâi instalăm dependențele necesare pentru crearea magazinului de vectori.
pip install langchain openai pypdf faiss-cpuCreați un magazin de index folosind datele preluate. Aceasta va acționa ca baza noastră de cunoștințe atunci când vom încerca să răspundem la noi bilete prin GPT.
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY" from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np tokenizer = GPT2TokenizerFast.from_pretrained("gpt2") def count_tokens(text: str) -> int: return len(tokenizer.encode(text)) text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=24, length_function=count_tokens,
) chunks = text_splitter.create_documents([knowledge]) token_counts = [count_tokens(chunk.page_content) for chunk in chunks]
df = pd.DataFrame({"Token Count": token_counts})
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
path = "zendesk-index"
db.save_local(path)
Indexul dvs. este salvat pe sistemul dvs. local.

- Actualizați indexul în mod regulat: Actualizați în mod regulat indexul pentru a include bilete noi și modificări la cele existente, asigurându-vă că sistemul are acces la cele mai recente date.
Putem programa scriptul de mai sus să ruleze în fiecare săptămână și să ne actualizăm „zendesk-index” sau orice altă frecvență dorită.
Cum se efectuează recuperarea atunci când intră un nou bilet
- Monitorizați pentru noi bilete: Configurați un sistem pentru a monitoriza permanent Zendesk pentru noi bilete.
Vom crea un API Flask de bază și îl vom găzdui. Pentru a incepe,
- Creați un folder nou numit „Zendesk Answer Bot”.
- Adăugați folderul db FAISS „zendesk-index” la folderul „Zendesk Answer Bot”.
- Creați un nou fișier python zendesk.py și copiați codul de mai jos în el.
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): return 'dummy response' if __name__ == '__main__': app.run(port=3001, debug=True)- Rulați codul python.

- Descărcați și configurați ngrok folosind instrucțiunile de aici. Asigurați-vă că configurați codul de autorizare ngrok în terminalul dvs., așa cum este indicat de pe link.
- Deschideți o nouă instanță de terminal și rulați comanda de mai jos.
ngrok http 3001- Acum avem serviciul nostru Flask expus pe un IP extern, folosindu-ne de care putem efectua apeluri API către serviciul nostru de oriunde.

- Apoi am configurat un Zendesk Webhook, fie vizitând următorul link – https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/webhooks/webhooks SAU rulând direct codul de mai jos în blocnotesul nostru original Jupyter.
NOTĂ: Este important să rețineți că, deși folosirea ngrok este bună în scopuri de testare, este recomandat să mutați serviciul API Flask pe o instanță de server. În acest caz, IP-ul static al serverului devine punctul final Zendesk Webhook și va trebui să configurați punctul final în Zendesk Webhook pentru a indica această adresă – https://YOUR_SERVER_STATIC_IP:3001/zendesk
zendesk_workflow_endpoint = "HTTPS_NGROK_FORWARDING_ADDRESS" url = "https://" + subdomain + ".zendesk.com/api/v2/webhooks"
payload = { "webhook": { "endpoint": zendesk_workflow_endpoint, "http_method": "POST", "name": "Nanonets Workflows Webhook v1", "status": "active", "request_format": "json", "subscriptions": ["conditional_ticket_events"], }
}
headers = {"Content-Type": "application/json"} auth = (username, password) response = requests.post(url, json=payload, headers=headers, auth=auth)
webhook = response.json() webhookid = webhook["webhook"]["id"]
- Acum am configurat un Zendesk Trigger, care va declanșa webhook-ul de mai sus pe care tocmai l-am creat pentru a rula ori de câte ori apare un nou bilet. Putem configura declanșatorul Zendesk fie accesând următorul link – https://YOUR_SUBDOMAIN.zendesk.com/admin/objects-rules/rules/triggers SAU rulând direct codul de mai jos în blocnotesul nostru original Jupyter.
url = "https://" + subdomain + ".zendesk.com/api/v2/triggers.json" trigger_payload = { "trigger": { "title": "Nanonets Workflows Trigger v1", "active": True, "conditions": {"all": [{"field": "update_type", "value": "Create"}]}, "actions": [ { "field": "notification_webhook", "value": [ webhookid, json.dumps( { "ticket_id": "{{ticket.id}}", "org_id": "{{ticket.url}}", "subject": "{{ticket.title}}", "body": "{{ticket.description}}", } ), ], } ], }
} response = requests.post(url, auth=(username, password), json=trigger_payload)
trigger = response.json()
- Preluați informații relevante: Când apare un nou bilet, utilizați baza de cunoștințe indexată pentru a prelua informații relevante și bilete anterioare care pot ajuta la generarea unui răspuns.
După ce declanșatorul și webhook-ul au fost configurate, Zendesk se va asigura că serviciul nostru Flask care rulează în prezent va primi un apel API la ruta /zendesk cu ID-ul, subiectul și corpul biletului ori de câte ori sosește un nou bilet.
Acum trebuie să ne configuram serviciul Flask la
A. generați un răspuns folosind magazinul nostru de vectori „zendesk-index”.
b. actualizați biletul cu răspunsul generat.
Înlocuim codul nostru actual de service flask în zendesk.py cu codul de mai jos -
from flask import Flask, request, jsonify
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson['body'] zendb = FAISS.load_local('zendesk-index', zenembeddings) docs = zendb.similarity_search(query) if __name__ == '__main__': app.run(port=3001, debug=True)După cum puteți vedea, am efectuat o căutare de similaritate pe indexul nostru vectorial și am preluat cele mai relevante bilete și articole pentru a ajuta la generarea unui răspuns.
Cum să generați un răspuns și să postați pe Zendesk
- Generați răspuns: Utilizați LLM pentru a genera un răspuns coerent și precis bazat pe informațiile preluate și contextul analizat.
Să continuăm acum configurarea punctului final API. Modificăm în continuare codul, așa cum se arată mai jos, pentru a genera un răspuns bazat pe informațiile relevante preluate.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query)
răspunde variabila va conține răspunsul generat.
- Răspuns de revizuire: Opțional, solicitați unui agent uman să examineze răspunsul generat pentru acuratețe și corectitudine înainte de a posta.
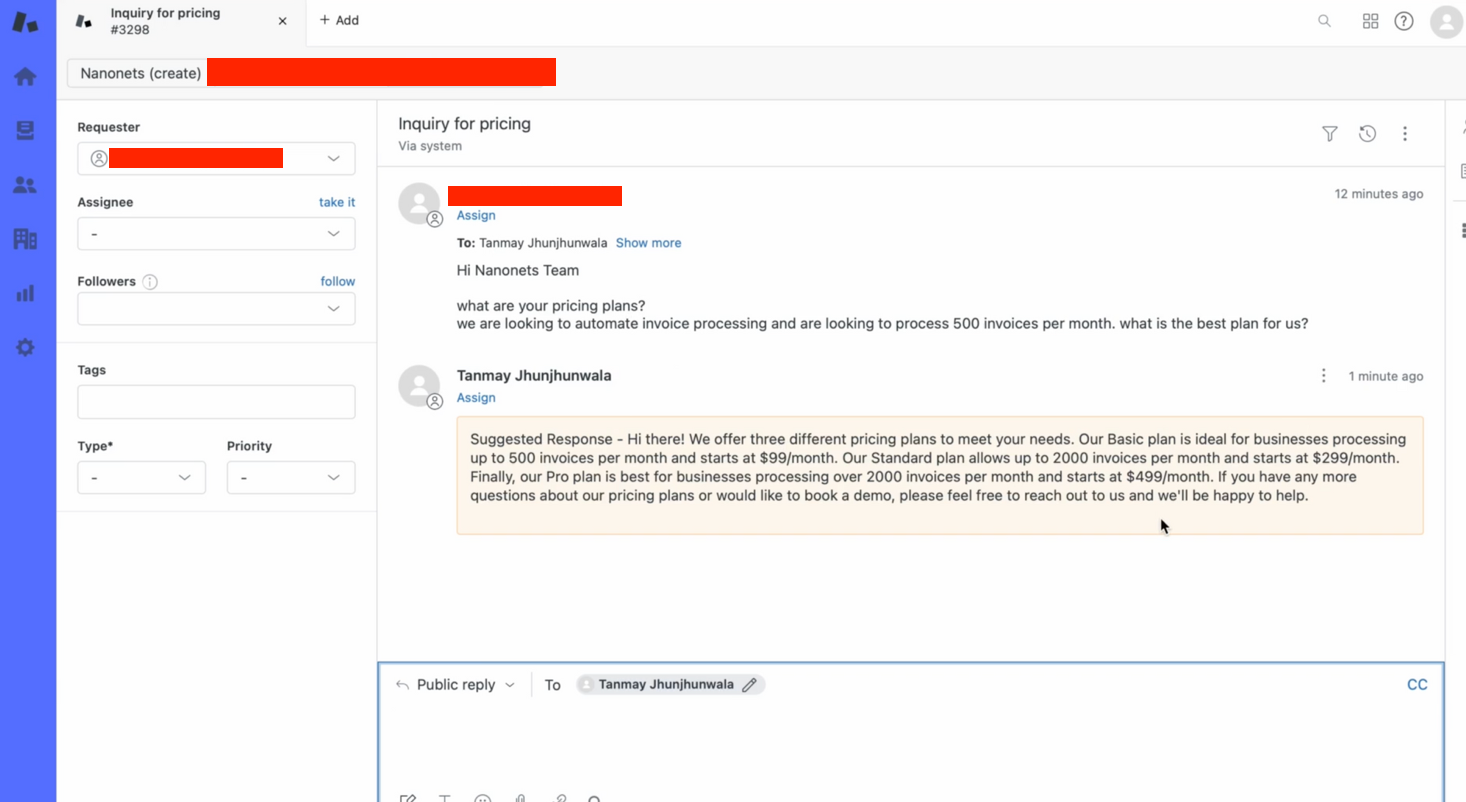
Modul în care ne asigurăm acest lucru este NU postăm răspunsul generat de GPT direct ca răspuns Zendesk. În schimb, vom crea o funcție pentru a actualiza biletele noi cu o notă internă care conține răspunsul generat de GPT.
Adăugați următoarea funcție la serviciul zendesk.py flask –
def update_ticket_with_internal_note( subdomain, ticket_id, username, password, comment_body
): url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticket_id}.json" email = username headers = {"Content-Type": "application/json"} comment_body = "Suggested Response - " + comment_body data = {"ticket": {"comment": {"body": comment_body, "public": False}}} response = requests.put(url, json=data, headers=headers, auth=(email, password))
- Postați pe Zendesk: Utilizați API-ul Zendesk pentru a posta răspunsul generat pe biletul corespunzător, asigurând o comunicare în timp util cu clientul.
Să încorporăm acum funcția de creare a notelor interne în punctul nostru final API.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query) update_ticket_with_internal_note(subdomain, ticket, username, password, answer) return answer
Acest lucru completează fluxul nostru de lucru!
Să revizuim fluxul de lucru pe care l-am configurat -
- Zendesk Trigger începe fluxul de lucru atunci când apare un nou bilet Zendesk.
- Declanșatorul trimite datele noului bilet către webhook-ul nostru.
- Webhook-ul nostru trimite o solicitare către serviciul nostru Flask.
- Serviciul nostru Flask interogează magazinul de vectori creat folosind date Zendesk anterioare pentru a prelua biletele și articolele anterioare relevante pentru a răspunde noului bilet.
- Biletele și articolele anterioare relevante sunt transmise la GPT împreună cu datele noului bilet pentru a genera un răspuns.
- Noul bilet este actualizat cu o notă internă care conține răspunsul generat de GPT.
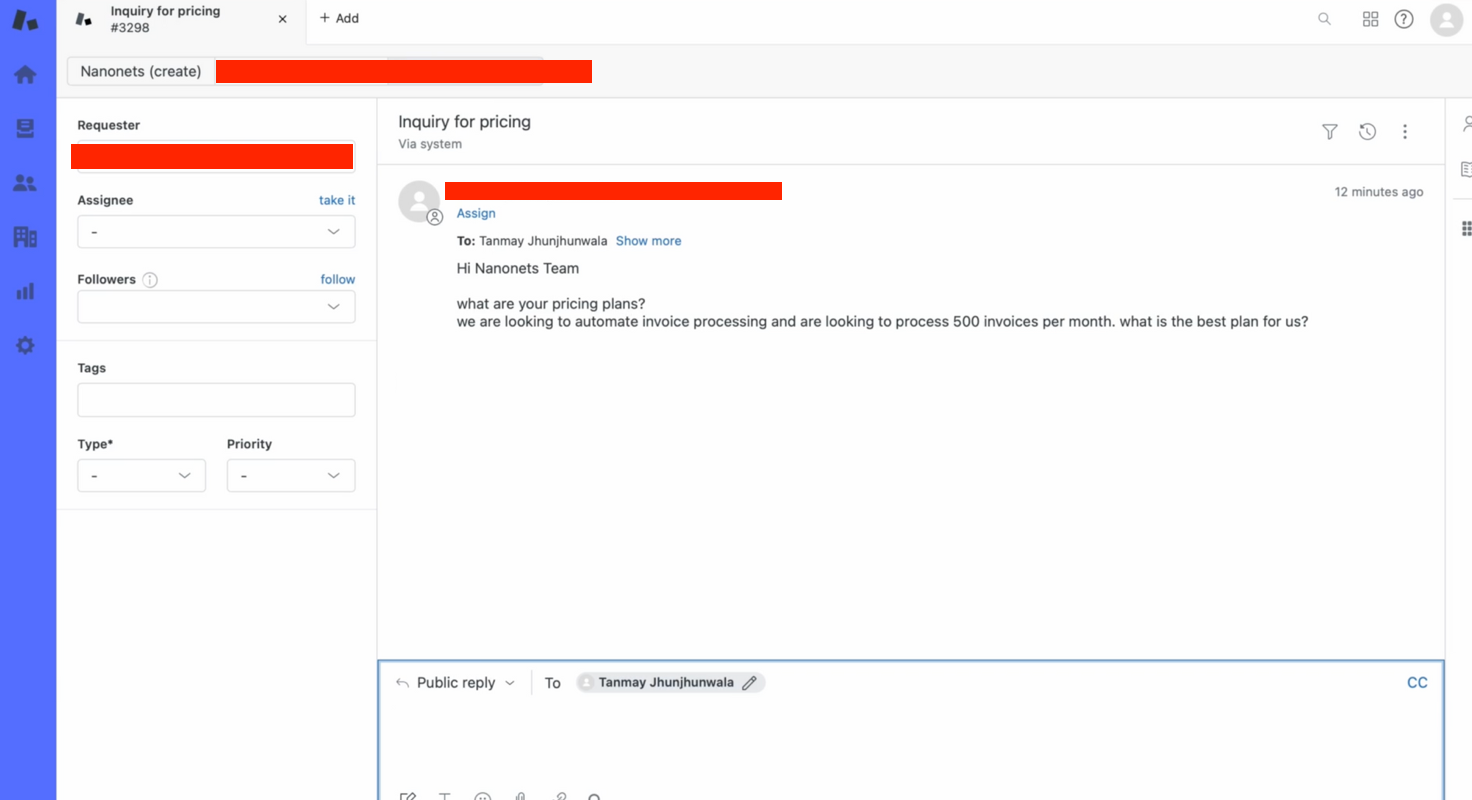
Putem testa acest lucru manual -
- Creăm manual un bilet pe Zendesk pentru a testa fluxul.
- În câteva secunde, botul nostru oferă un răspuns relevant la întrebarea de bilet!
Cum să faci întregul flux de lucru cu Nanonets
Nanonets oferă o platformă puternică pentru a implementa și gestiona fără probleme fluxurile de lucru bazate pe RAG. Iată cum puteți utiliza Nanonets pentru acest flux de lucru:
- Integrați cu Zendesk: Conectați Nanonets cu Zendesk pentru a monitoriza și a prelua biletele în mod eficient.
- Construiți și antrenați modele: Utilizați Nanonets pentru a construi și a instrui LLM-uri pentru a genera răspunsuri precise și coerente bazate pe baza de cunoștințe și contextul analizat.
- Răspunsuri automatizate: Configurați reguli de automatizare în Nanonets pentru a posta automat răspunsurile generate la Zendesk sau pentru a le transmite agenților umani pentru examinare.
- Monitorizați și optimizați: Monitorizați continuu performanța fluxului de lucru și optimizați modelele și regulile pentru a îmbunătăți acuratețea și eficiența.
Prin integrarea LLM-urilor cu fluxurile de lucru bazate pe RAG în GenAI și prin valorificarea capabilităților Nanonets, companiile își pot îmbunătăți semnificativ operațiunile de asistență pentru clienți, oferind răspunsuri rapide și precise la întrebările clienților pe Zendesk.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://nanonets.com/blog/build-your-own-zendesk-answer-bot-with-llms/
- :are
- :este
- :nu
- :Unde
- $UP
- 06
- 08
- 1
- 2000
- 28
- 32
- 40
- 7
- a
- mai sus
- acces
- Cont
- precizie
- precis
- act
- Acțiune
- acțiuni
- activ
- adăuga
- plus
- adresa
- aderare
- admin
- Agent
- agenţi
- AI
- TOATE
- de-a lungul
- de asemenea
- an
- analiză
- analizate
- analiza
- și
- răspunde
- Orice
- oriunde
- api
- aplicaţia
- apare
- SUNT
- Mulțime
- soseşte
- articol
- bunuri
- AS
- aspect
- At
- încercare
- augmented
- AUTH
- Auto
- în mod automat
- automatizarea
- Automatizare
- Backend
- Bancar
- industria bancară
- de bază
- bazat
- de bază
- BE
- devine
- fost
- înainte
- de mai jos
- benefică
- Beneficiile
- Blog
- corp
- Bot
- Pauză
- construi
- Clădire
- afaceri
- întreprinderi
- dar
- by
- apel
- denumit
- apeluri
- Campanie
- Campanii
- CAN
- capacități
- caz
- centralizat
- lanţuri
- Modificări
- caractere
- chatbot
- chatbots
- cod
- codeBase
- Codificare
- COERENT
- COM
- combina
- vine
- comentariu
- comentarii
- Comunicare
- finalizeaza
- component
- componente
- Condiții
- Conectați
- conţine
- conține
- conţinut
- context
- continua
- continuu
- Corespunzător
- ar putea
- crea
- a creat
- Crearea
- creaţie
- scrisori de acreditare
- critic
- crucial
- Curent
- În prezent
- personalizat
- client
- Satisfactia clientului
- Serviciu clienți
- Relații Clienți
- de date
- Baza de date
- dependențe
- Implementarea
- dorit
- Dezvoltator
- dirijat
- direct
- do
- documentaţie
- documente
- Descarca
- în timpul
- fiecare
- Eficace
- eficiență
- eficient
- eficient
- oricare
- element
- altfel
- încorporat
- angajat
- permite
- Punct final
- angajament
- spori
- Îmbunătăţeşte
- asigura
- asigurare
- Întreg
- Eter (ETH)
- Fiecare
- exemplu
- exemple
- Cu excepția
- existent
- Extinde
- expus
- extern
- facilita
- fals
- ritm rapid
- Caracteristică
- DESCRIERE
- feedback-ul
- Adus
- camp
- Fișier
- First
- debit
- următor
- Pentru
- Înainte
- Frecvență
- din
- funcţie
- mai mult
- genera
- generată
- generator
- generaţie
- generativ
- AI generativă
- obține
- gif
- bine
- ghida
- Manipularea
- Avea
- având în
- anteturile
- ajutor
- istorie
- gazdă
- Cum
- http
- HTTPS
- uman
- ID
- if
- punerea în aplicare a
- Punere în aplicare a
- import
- important
- îmbunătăţi
- îmbunătățirea
- in
- include
- Inclusiv
- Intrare
- incorpora
- Creșteri
- index
- indexate
- industrie
- informații
- informativ
- informat
- inițierea
- intrare
- Cereri
- instala
- instanță
- in schimb
- instrucțiuni
- integrarea
- interacţiune
- interacţiuni
- intern
- în
- Introducere
- IP
- IT
- JSON
- Jupiter Notebook
- doar
- Cheie
- chei
- cunoştinţe
- limbă
- mare
- Ultimele
- Pârghie
- efectului de pârghie
- ca
- LINK
- local
- face
- administra
- manual
- Piață
- Tendințele pieței
- Marketing
- material
- metodă
- Modele
- modificările aduse
- modifica
- monitor
- mai mult
- cele mai multe
- muta
- nume
- necesar
- Nevoie
- necesar
- nevoilor
- Nou
- optiune noua
- produs nou
- nota
- caiet
- acum
- NumPy
- obținut
- of
- promoții
- on
- dată
- cele
- afară
- OpenAI
- operaţie
- Operațiuni
- Optimizați
- or
- original
- OS
- Altele
- al nostru
- peste
- propriu
- pagină
- pagini
- panda
- parte
- în special
- Trecut
- Parolă
- trecut
- cale
- efectua
- performanță
- efectuarea
- efectuează
- permisiuni
- Personalizat
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- pozitiv
- Post
- potenţial
- alimentat
- puternic
- proces
- Produs
- Informații despre produs
- proiect
- Proiecte
- propune
- furniza
- furnizează
- furnizarea
- public
- trăgând
- scopuri
- Piton
- calitate
- interogări
- întrebare
- Rapid
- rată
- tarife
- RE
- lumea reală
- recent
- recomandat
- corelarea
- se referă
- reflecta
- regulat
- înlocui
- răspuns
- depozit
- reprezentând
- solicita
- cereri de
- necesar
- răspuns
- răspunsuri
- responsabil
- retenţie
- reveni
- revizuiască
- Recenzii
- revizui
- Traseul
- norme
- Alerga
- funcţionare
- s
- de vânzări
- satisfacție
- salvate
- programa
- scenariu
- perfect
- Caută
- secunde
- vedea
- trimite
- serverul
- serviciu
- sesiune
- set
- instalare
- setări
- schimbare
- indicat
- semnificativ
- simplu
- fragment
- Surse
- specific
- standarde
- început
- începe
- Stare
- stoca
- simplifica
- Şir
- tare
- subdomeniu
- subiect
- Abonamente
- astfel de
- potrivit
- a sustine
- sigur
- SWIFT
- sistem
- vizate
- Sarcină
- Terminal
- termeni
- test
- Testarea
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- acea
- lor
- Lor
- apoi
- acest
- Prin
- Prin urmare
- bilet
- bilete
- oportun
- Titlu
- la
- azi
- semn
- față de
- Tren
- tranzacție
- transformatoare
- Tendinţe
- declanşa
- adevărat
- încerca
- tutorial
- Actualizează
- actualizat
- URL-ul
- us
- utilizare
- Utilizator
- folosind
- obișnuit
- folosi
- v1
- valoare
- de
- VIMEO
- Vizita
- Cale..
- we
- săptămână
- cand
- oricând
- care
- în timp ce
- voi
- cu
- flux de lucru
- fluxuri de lucru
- lume
- tu
- Ta
- Zendesk
- zephyrnet