Bun venit în era datelor. Volumul uriaș de date capturate zilnic continuă să crească, necesitând platforme și soluții să evolueze. Servicii precum Serviciul Amazon de stocare simplă (Amazon S3) oferă o soluție scalabilă care se adaptează, dar rămâne rentabilă pentru seturi de date în creștere. The Amazon Sustainability Data Initiative (ASDI) folosește capacitățile Amazon S3 pentru a oferi o soluție gratuită pentru a stoca și a partaja sarcinile de lucru din domeniul științei climatice pe tot globul. Programul Amazon de sponsorizare pentru date deschise permite organizațiilor să găzduiască gratuit pe AWS.
În ultimul deceniu, am observat o creștere a cadrelor de știință a datelor care se concretizează, împreună cu adoptarea în masă de către comunitatea științei datelor. Un astfel de cadru este Bord, care este puternic pentru capacitatea sa de a furniza o orchestrare de noduri de calcul ale lucrătorilor, accelerând astfel analiza complexă pe seturi de date mari.
În această postare, vă arătăm cum să implementați un personalizat Kit AWS Cloud Development (AWS CDK) soluție care extinde funcționalitatea Dask pentru a funcționa inter-regional în rețeaua globală Amazon. Soluția AWS CDK implementează o rețea de lucrători Dask în două regiuni AWS, conectându-se la o regiune client. Pentru mai multe informații, consultați Ghid pentru calcularea distribuită cu Cross Regional Dask pe AWS si GitHub repo pentru codul open-source.
După implementare, utilizatorul va avea acces la un notebook Jupyter, unde poate interacționa cu două seturi de date de la ASDI pe AWS: Proiectul de intercomparație cu modele cuplate 6 (CMIP6) și Reanaliza ECMWF ERA5. CMIP6 se concentrează pe cea de-a șasea fază a ansamblului de modele de circulație generală cuplată ocean-atmosfera globală; ERA5 este a cincea generație de reanalize atmosferice ECMWF ale climei globale și prima reanaliza produsă ca serviciu operațional.
Această soluție a fost inspirată de lucrul cu un client cheie AWS, the Regatul Unit Met Office. Met Office a fost fondat în 1854 și este serviciul meteorologic național pentru Marea Britanie. Acestea oferă predicții despre vreme și climă pentru a vă ajuta să luați decizii mai bune pentru a rămâne în siguranță și a prospera. O colaborare între Met Office și EUMETSAT, detaliată în Calcularea proximă a datelor pe un cluster Dask distribuit între centrele de date, subliniază nevoia tot mai mare de a dezvolta o soluție durabilă, eficientă și scalabilă pentru știința datelor. Această soluție realizează acest lucru prin apropierea procesului de calcul de date, mai degrabă decât forțând datele să se apropie de resursele de calcul, ceea ce adaugă cost, latență și energie.
Prezentare generală a soluțiilor
În fiecare zi, Ministerul Meteorologic al Marii Britanii produce până la 300 TB de date meteorologice și climatice, o parte dintre acestea fiind publicată către ASDI. Aceste seturi de date sunt distribuite în întreaga lume și găzduite pentru uz public. Met Office ar dori să le permită consumatorilor să folosească mai mult din datele lor pentru a ajuta la informarea deciziilor critice privind abordarea unor probleme precum o mai bună pregătire pentru incendii și inundații cauzate de schimbările climatice și reducerea insecurității alimentare printr-o analiză mai bună a recoltei.
Soluțiile tradiționale utilizate în prezent, în special cu datele climatice, sunt consumatoare de timp și nesustenabile, replicând seturi de date în diferite regiuni. Transferul de date inutil pe scara petabyte este costisitor, lent și consumă energie.
Am estimat că dacă această practică ar fi adoptată de utilizatorii Met Office, echivalentul a consumului zilnic de energie a 40 de locuințe ar putea fi economisit în fiecare zi și ar putea, de asemenea, să reducă transferul de date între regiuni.
Următoarea diagramă ilustrează arhitectura soluției.
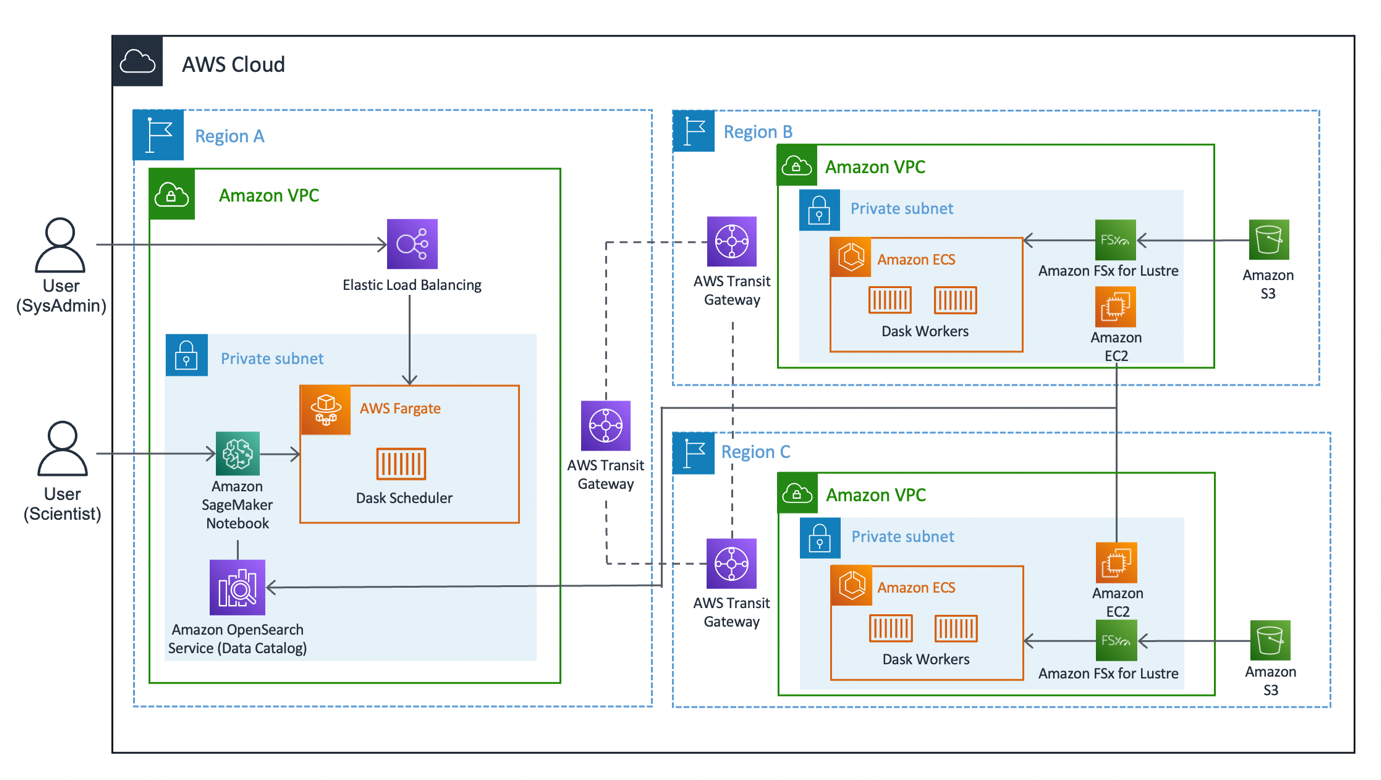
Soluția poate fi împărțită în trei segmente majore: client, lucrători și rețea. Să ne aruncăm în fiecare și să vedem cum se adună.
Client
Clientul reprezintă regiunea sursă la care se conectează oamenii de știință de date. Această regiune (Regiunea A din diagramă) conține un Caietul de sarcini Amazon SageMaker, O Serviciul Amazon OpenSearch domeniu, și a Dask scheduler ca componente cheie. Administratorii de sistem au acces la tabloul de bord Dask încorporat, expus prin intermediul unui Elastic Load Balancer.
Oamenii de știință de date au acces la notebook-ul Jupyter găzduit pe SageMaker. Notebook-ul poate să se conecteze și să ruleze încărcături de lucru în planificatorul Dask. Domeniul OpenSearch Service stochează metadate pe seturile de date conectate la regiuni. Utilizatorii de notebook-uri pot interoga acest serviciu pentru a prelua detalii, cum ar fi regiunea corectă a lucrătorilor Dask, fără a fi nevoie să cunoască în prealabil locația regională a datelor.
Lucrător
Fiecare dintre regiunile lucrătoare (regiunile B și C din diagramă) este compusă dintr-un Serviciul Amazon de containere elastice (Amazon ECS) cluster de Lucrători de la Dask, O Amazon FSx pentru Luster sistem de fișiere și unul autonom Cloud Elastic de calcul Amazon (Amazon EC2). FSx for Luster permite lucrătorilor Dask să acceseze și să proceseze datele Amazon S3 dintr-un sistem de fișiere de înaltă performanță, conectând sistemele dvs. de fișiere la compartimentele S3. Oferă latențe sub milisecunde, debit de până la sute de GB/s și milioane de IOPS. O caracteristică cheie a Luster este că numai metadatele sistemului de fișiere sunt sincronizate. Luster gestionează echilibrul fișierelor care urmează să fie încărcate și păstrate la cald, în funcție de cerere.
Clusterele de lucrători se scalează în funcție de utilizarea procesorului, furnizează angajați suplimentari în perioade prelungite de cerere și reduc pe măsură ce resursele devin inactive.
În fiecare noapte, la 0:00 UTC, o lucrare de sincronizare a datelor solicită sistemului de fișiere Luster să se resincronizeze cu compartimentul S3 atașat și extrage un catalog de metadate actualizat al compartimentului. Ulterior, instanța EC2 autonomă împinge aceste actualizări în Serviciul OpenSearch, respectiv indexul regiunii respective. Serviciul OpenSearch oferă clientului informațiile necesare cu privire la grupul de lucrători care trebuie apelat pentru un anumit set de date.
Reţea
Rețeaua reprezintă cheia acestei soluții, utilizând rețeaua internă a Amazon. Prin utilizarea AWS Transit Gateway, suntem capabili să conectăm fiecare dintre regiuni una la alta fără a fi nevoie să traversăm internetul public. Fiecare dintre lucrători se poate conecta dinamic la planificatorul Dask, permițând oamenilor de știință să execute interogări interregionale prin Dask.
Cerințe preliminare
Pachetul AWS CDK utilizează limbajul de programare TypeScript. Urmați pașii din Noțiuni introductive pentru AWS CDK pentru a configura mediul dvs. local și a porni contul de dezvoltare (va trebui să porniți toate Regiunile specificate în GitHub repo).
Pentru o implementare de succes, veți avea nevoie Docker instalat și rulează pe mașina dvs. locală.
Implementați pachetul AWS CDK
Implementarea unui pachet AWS CDK este simplă. După ce instalați cerințele preliminare și porniți contul, puteți continua cu descărcarea bazei de cod.
- Descărcați GitHub depozit:
- Instalați module nod:
- Implementați AWS CDK:
Implementarea stivei poate dura peste o oră și jumătate.
Prezentare cod
În această secțiune, inspectăm unele dintre caracteristicile cheie ale bazei de cod. Dacă doriți să inspectați întreaga bază de cod, consultați GitHub depozit.
Configurați și personalizați-vă stiva
În dosar bin/variabile.ts, veți găsi două declarații variabile: una pentru client și una pentru lucrători. Declarația clientului este un dicționar cu o referință la o regiune și un interval CIDR. Personalizarea acestor variabile va schimba atât regiunea, cât și intervalul CIDR în care vor fi implementate resursele clientului.
Variabila lucrător copiază aceeași funcționalitate; cu toate acestea, este o listă de dicționare pentru a permite adăugarea sau scăderea seturilor de date pe care utilizatorul dorește să le includă. În plus, fiecare dicționar conține câmpurile adăugate ale dataset și lustreFileSystemPath. Setul de date este utilizat pentru a specifica URI-ul S3 de conectare la care se conectează Luster. The lustreFileSystemPath variabila este utilizată ca mapare pentru modul în care utilizatorul dorește ca acel set de date să fie mapat local pe sistemul de fișiere lucrător. Vezi următorul cod:
Publicați în mod dinamic IP-ul de planificare
O provocare inerentă naturii transregionale a acestui proiect a fost menținerea unei conexiuni dinamice între lucrătorii Dask și planificator. Cum am putea publica o adresă IP, care poate fi schimbată, în regiunile AWS? Am putut realiza acest lucru prin utilizarea Harta AWS Cloud și asociați-vpc-cu-zona-găzduită. Rezumatele serviciului permit AWS să gestioneze în mod privat acest spațiu de nume DNS. Vezi următorul cod:
Jupyter notebook UI
Notebook-ul Jupyter găzduit pe SageMaker oferă oamenilor de știință un mediu gata de implementare pentru a se conecta și experimenta cu ușurință seturile de date încărcate. Am folosit un script de configurare a ciclului de viață pentru a furniza notebook-ului un mediu de dezvoltator preconfigurat și o bază de cod de exemplu. Vezi următorul cod:
Noduri de lucru Dask
Când vine vorba de lucrătorii Dask, este oferită o mai mare personalizare, mai precis în ceea ce privește tipul de instanță, firele pe container și alarmele de scalare. În mod implicit, lucrătorii furnizează pe tipul de instanță m5d.4xlarge, se montează în sistemul de fișiere Luster la lansare și își subdivizează lucrătorii și firele de execuție în mod dinamic în porturi. Toate acestea sunt opțional personalizabile. Vezi următorul cod:
Performanţă
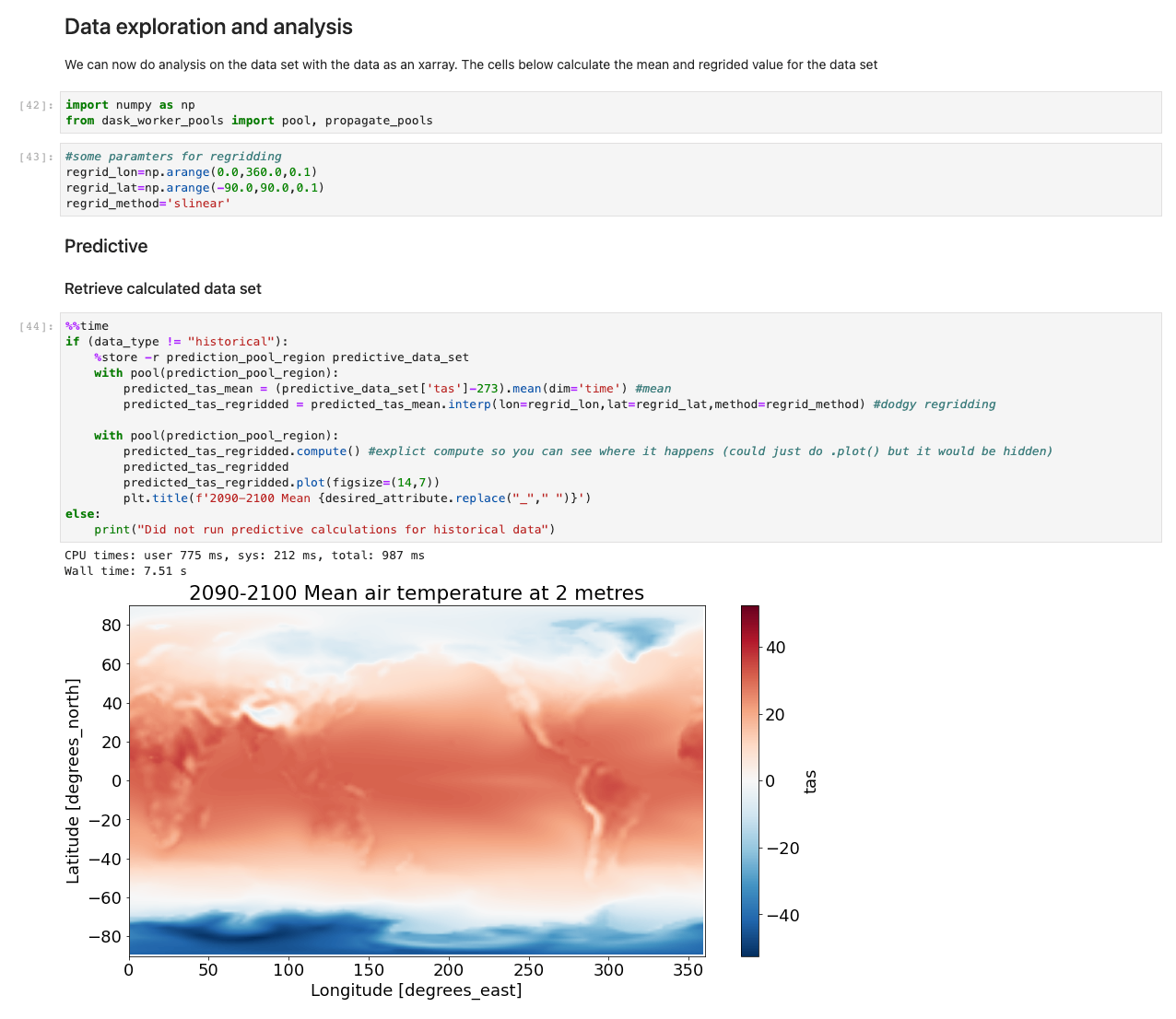
Pentru a evalua performanța, folosim un calcul de probă și un grafic al temperaturii aerului la 2 metri pe baza diferenței dintre predicția CMIP6 pentru o lună și temperatura medie a aerului ERA5 pentru 10 ani. Am stabilit un etalon de doi lucrători în fiecare regiune și evaluăm diferența de reducere a timpului pe măsură ce s-au adăugat lucrători suplimentari. În teorie, pe măsură ce soluția crește, ar trebui să existe o diferență materială productivă în reducerea timpului total.
Următorul tabel rezumă detaliile setului nostru de date.
| Setul de date | Variabile | Dimensiunea discului | Dimensiunea setului de date Xarray | Regiune |
| ERA5 | 2011–2020 (120 de fișiere netcdf) | 53.5GB | 364.1 GB | noi-est-1 |
| CMIP6 | 1.13GB | 0.11 GB | noi-vest-2 |
Următorul tabel arată rezultatele colectate, prezentând timpul (în secunde) pentru fiecare calcul și predicție în trei etape în calculul predicției CMIP6, ERA5 și diferenței.
| . | . | Numărul de muncitori | |||
| Calcula | Regiune | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
noi-vest-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
noi-est-1 | 1512 | 711 | 427 | 202 |
Diferență (propogated pool) |
noi-vest-2 și noi-est-1 | 1527 | 906 | 469 | 251 |
Următorul grafic vizualizează performanța și scara.
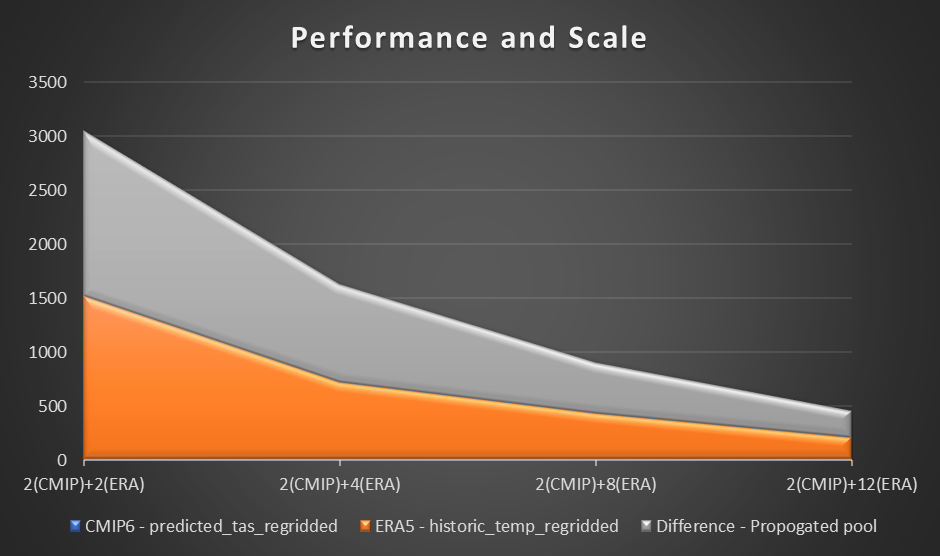
Din experimentul nostru, am observat o îmbunătățire liniară a calculului pentru setul de date ERA5, pe măsură ce numărul de lucrători a crescut. Pe măsură ce numărul de lucrători a crescut, timpul de calcul s-a redus uneori la jumătate.
Caiet Jupyter
Ca parte a lansării soluției, implementăm un notebook Jupyter preconfigurat pentru a ajuta la testarea soluției interregionale Dask. Notebook-ul demonstrează eliminarea îngrijorării de a avea nevoie de a cunoaște locația regională a seturilor de date, în schimb interogând un catalog printr-o serie de notebook-uri Jupyter care rulează în fundal.
Pentru a începe, urmați instrucțiunile din această secțiune.
Codul pentru caiete poate fi găsit în lib/SagemakerCode cu caietul principal fiind ux_notebook.ipynb. Acest notebook apelează la alte notebook-uri, declanșând scripturi de ajutor. ux_notebook este conceput pentru a fi punctul de intrare pentru oamenii de știință, fără a fi nevoie să mergeți în altă parte.
Pentru a începe, deschideți acest notebook în SageMaker după ce ați implementat AWS CDK. AWS CDK creează o instanță de blocnotes cu toate fișierele din depozit încărcate și copiate de rezervă într-un AWS CodeCommit repertoriu.
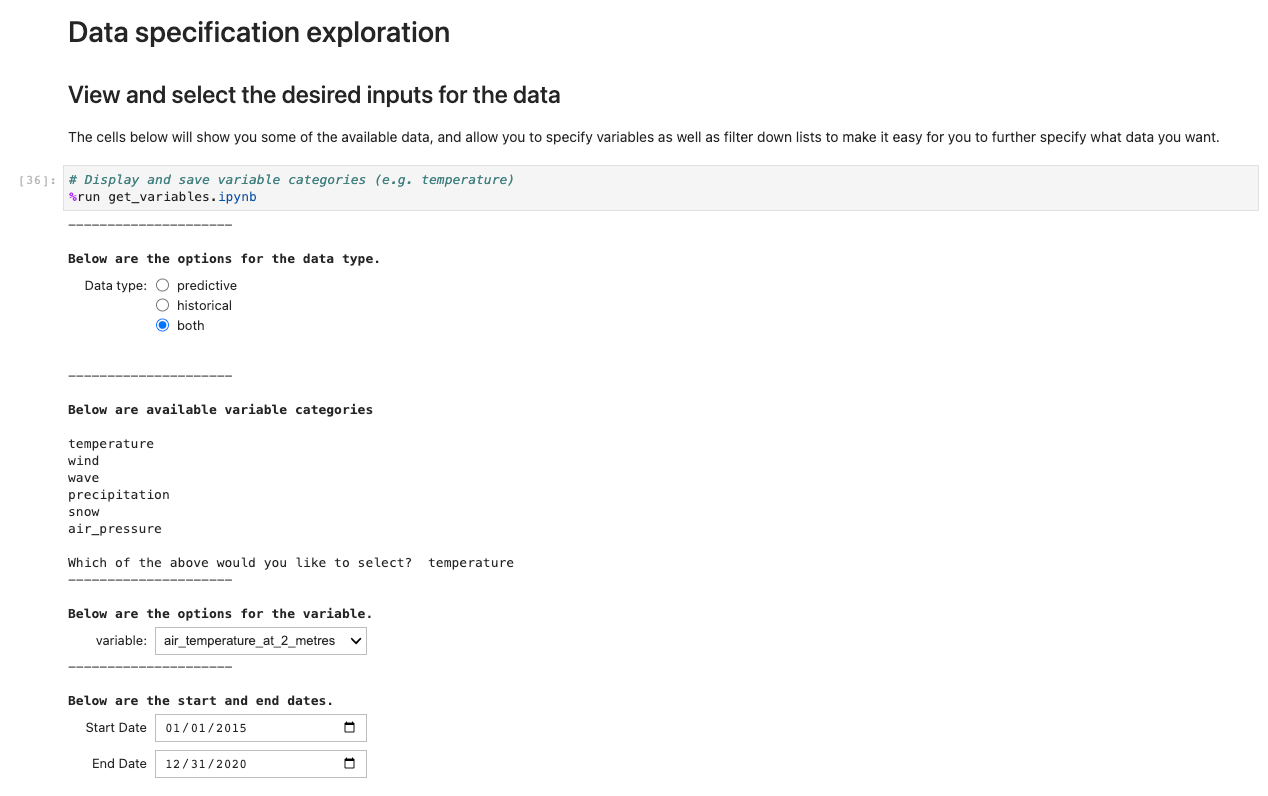
Pentru a rula aplicația, deschideți și rulați prima celulă a ux_notebook. Această celulă rulează get_variables notebook în fundal, care vă solicită o intrare pentru datele pe care doriți să le selectați. Includem un exemplu; totuși, rețineți că întrebările vor apărea numai după ce opțiunea anterioară a fost selectată. Acest lucru este intenționat în limitarea opțiunilor derulante și este opțional configurabil prin editarea get_variables caiet.
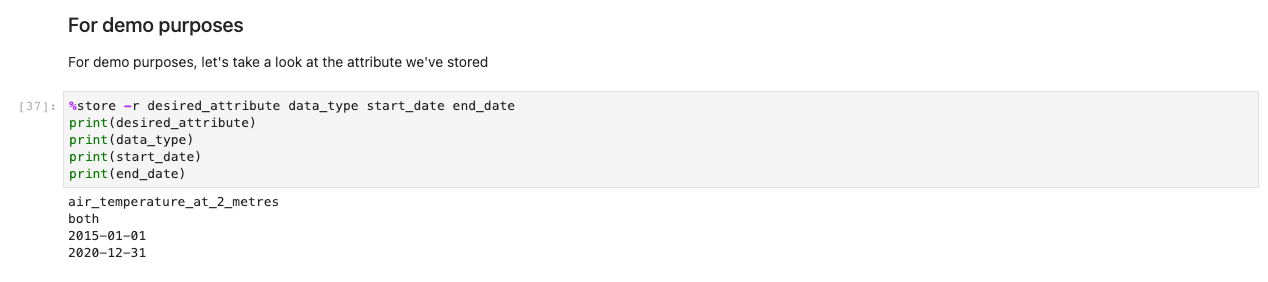
Codul precedent stochează variabile la nivel global, astfel încât alte notebook-uri să poată prelua și încărca selecția dvs. de opțiuni. Pentru demonstrație, următoarea celulă ar trebui să scoată variabilele de salvare de înainte.
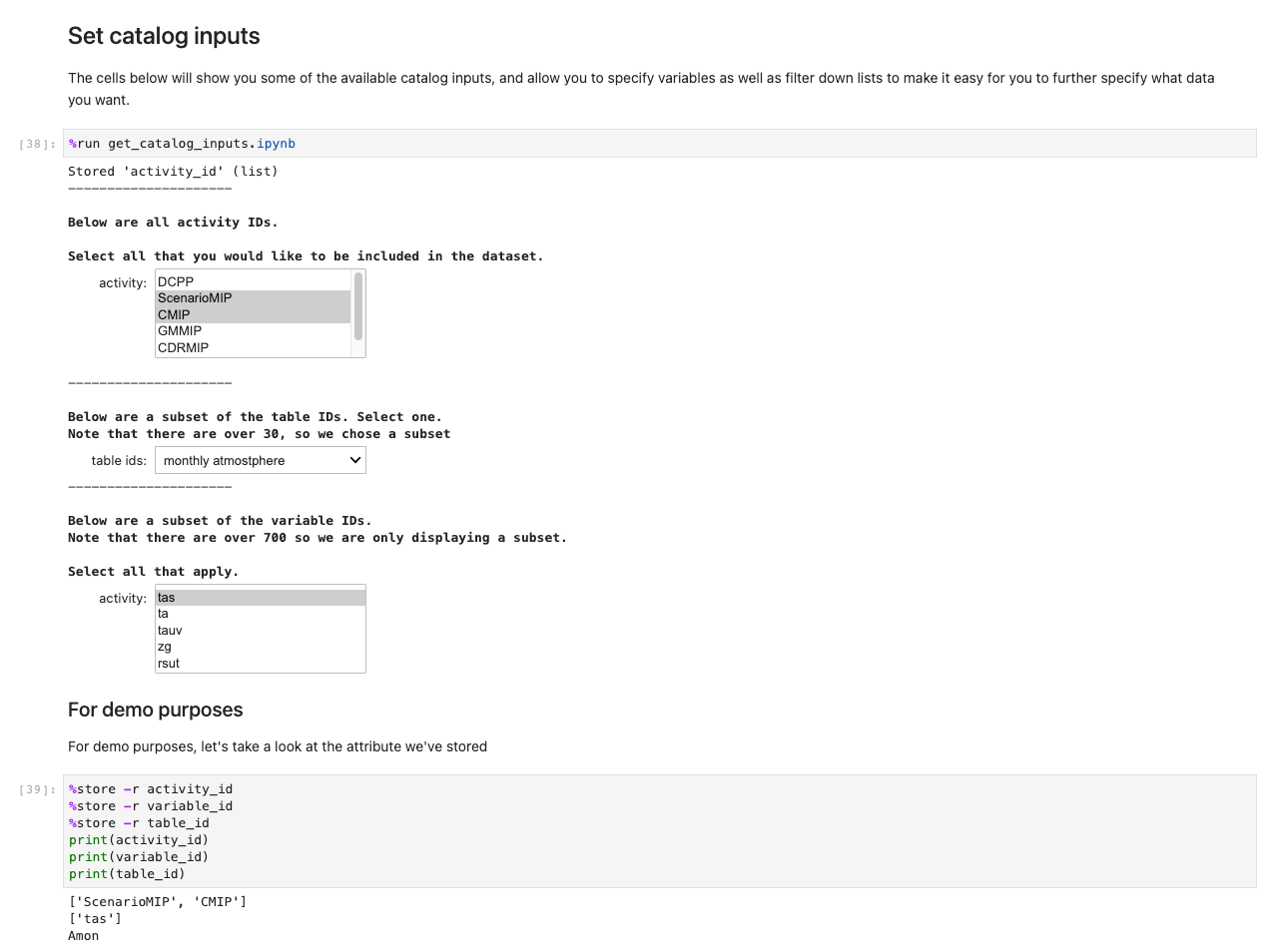
Apoi, apare o solicitare pentru specificații suplimentare de date. Această celulă rafinează datele pe care le căutați prezentând ID-urile tabelelor în format care poate fi citit de om. Utilizatorii selectează ca și cum ar fi un formular, dar titlurile se mapează la tabele din fundal care ajută sistemul să recupereze seturile de date adecvate.
După ce ați stocat toate opțiunile și celulele de selecție, încărcați datele în regiuni rulând celula din Obținerea datelor set secțiune. Comanda %%capture va suprima ieșirile inutile de la get_data caiet. Rețineți că puteți elimina acest lucru pentru a inspecta ieșirile de la celelalte notebook-uri. Datele sunt apoi preluate în backend.
În timp ce alte notebook-uri rulează în fundal, singurul punct de contact pentru utilizator este ux_notebook. Aceasta este pentru a abstrage procesul obositor de import de date într-un format pe care orice utilizator îl poate urmări cu ușurință.
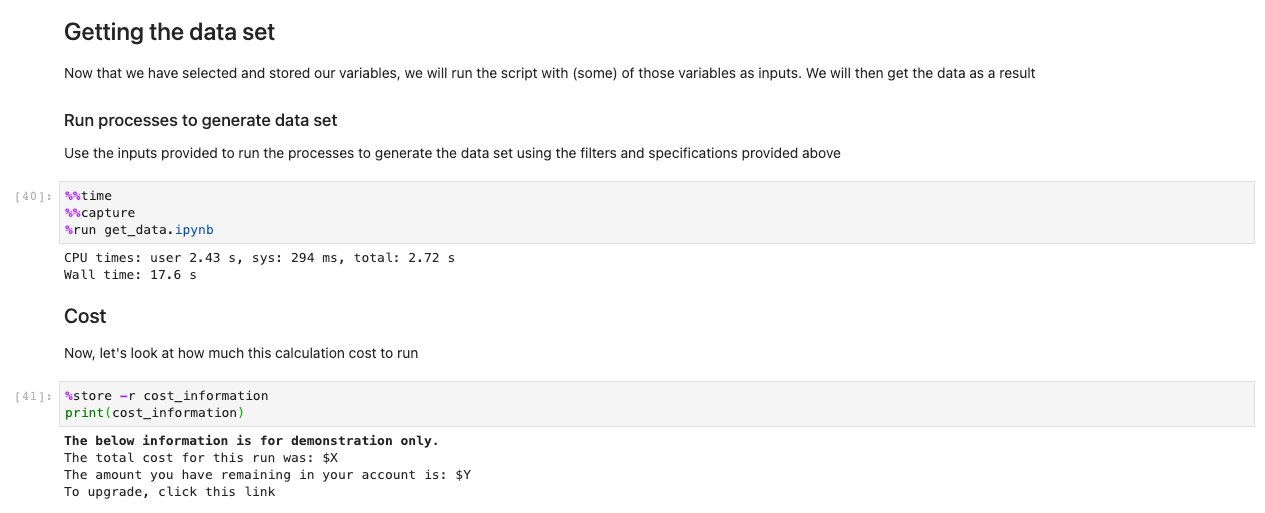
Cu datele încărcate acum, putem începe să interacționăm cu ele. Următoarele celule sunt exemple de calcule pe care le puteți efectua pe datele meteorologice. Folosind xarrays, importăm, calculăm și apoi trasăm acele seturi de date.
Eșantionul nostru ilustrează un grafic al datelor predictive care preia date, rulează calculul și trasează rezultatele în mai puțin de 7.5 secunde - ordine de mărime mai rapid decât o abordare tipică.
Sub capotă
Caietele get_catalog_input și get_variables folosește biblioteca ipywidgets pentru a afișa widget-uri, cum ar fi meniuri derulante și selecții cu mai multe casete. Aceste opțiuni sunt salvate global folosind comanda %%store, astfel încât să poată fi accesate din ux_notebook. Una dintre opțiuni vă solicită dacă doriți date istorice, date predictive sau ambele. Această variabilă este transmisă către get_data notebook pentru a determina ce notebook-uri ulterioare să ruleze.
get_data notebook-ul preia mai întâi domeniul comun OpenSearch Service salvat în Magazin de parametri AWS Systems Manager. Acest domeniu permite notebook-ului nostru să ruleze o interogare privind colectarea de informații care va indica unde sunt stocate la nivel regional seturile de date selectate. Cu acele seturi de date localizate la nivel regional, blocnotesul va face o încercare de conectare la planificatorul Dask, transmițând informațiile colectate de la Serviciul OpenSearch. La rândul său, programatorul Dask va putea apela lucrătorilor din regiunile corecte.
Cum să personalizați și să continuați dezvoltarea
Aceste caiete sunt menite să fie un exemplu despre cum puteți crea o modalitate prin care utilizatorii să interacționeze și să interacționeze cu datele. Blocnotesul din această postare servește ca o ilustrare a ceea ce este posibil și vă invităm să continuați să construiți pe baza soluției pentru a îmbunătăți în continuare implicarea utilizatorilor. Partea centrală a acestei soluții este tehnologia backend, dar fără vreun mecanism care să interacționeze cu acel backend, utilizatorii nu vor realiza întregul potențial al soluției.
Pentru a evita costurile viitoare, ștergeți resursele. Să distrugem soluția noastră implementată cu următoarea comandă:
Concluzie
Această postare prezintă extinderea Dask inter-regional pe AWS și o posibilă integrare cu seturi de date publice pe AWS. Soluția a fost construită ca un model generic, iar seturi de date suplimentare pot fi încărcate pentru a accelera analizele I/O ridicate pe date complexe.
Datele transformă fiecare domeniu și fiecare afacere. Cu toate acestea, având în vedere că datele cresc mai rapid decât pot urmări majoritatea companiilor, colectarea datelor și obținerea valorii acestora este o provocare. O strategie modernă de date vă poate ajuta să creați rezultate mai bune în afaceri cu date. AWS oferă cel mai complet set de servicii pentru călătoria de la un capăt la altul al datelor, pentru a vă ajuta să deblocați valoare din datele dvs. și să o transformați în perspectivă.
Pentru a afla mai multe despre diferitele moduri de a vă folosi datele în cloud, vizitați Blogul AWS Big Data. În continuare, vă invităm să comentați cu părerile dvs. despre această postare și dacă aceasta este o soluție pe care intenționați să o încercați.
Despre Autori
 Patrick O'Connor este un inginer de prototipuri WWSO cu sediul în Londra. El este un creativ care rezolvă probleme, adaptabil într-o gamă largă de tehnologii, cum ar fi IoT, tehnologie fără server, tehnologie spațială 3D și ML/AI, împreună cu o curiozitate neobosită cu privire la modul în care tehnologia poate continua să evolueze abordările de zi cu zi.
Patrick O'Connor este un inginer de prototipuri WWSO cu sediul în Londra. El este un creativ care rezolvă probleme, adaptabil într-o gamă largă de tehnologii, cum ar fi IoT, tehnologie fără server, tehnologie spațială 3D și ML/AI, împreună cu o curiozitate neobosită cu privire la modul în care tehnologia poate continua să evolueze abordările de zi cu zi.
 Chakra Nagarajan este un Principal Machine Learning Prototyping SA cu 21 de ani de experiență în învățarea automată, big data și calculul de înaltă performanță. În rolul său actual, el ajută clienții să rezolve probleme complexe de afaceri din lumea reală prin construirea de prototipuri cu soluții AI/ML end-to-end în cloud și dispozitive edge. Specializarea sa ML include viziunea computerizată, procesarea limbajului natural, prognoza serii temporale și personalizarea.
Chakra Nagarajan este un Principal Machine Learning Prototyping SA cu 21 de ani de experiență în învățarea automată, big data și calculul de înaltă performanță. În rolul său actual, el ajută clienții să rezolve probleme complexe de afaceri din lumea reală prin construirea de prototipuri cu soluții AI/ML end-to-end în cloud și dispozitive edge. Specializarea sa ML include viziunea computerizată, procesarea limbajului natural, prognoza serii temporale și personalizarea.
 Val Cohen este inginer senior de prototipare WWSO cu sediul în Londra. O persoană care rezolvă probleme prin natură, Val îi place să scrie cod pentru a automatiza procesele, a construi instrumente obsedate de clienți și a crea infrastructură pentru diverse aplicații pentru baza sa globală de clienți. Val are experiență într-o mare varietate de tehnologii, cum ar fi dezvoltarea web front-end, munca backend și AI/ML.
Val Cohen este inginer senior de prototipare WWSO cu sediul în Londra. O persoană care rezolvă probleme prin natură, Val îi place să scrie cod pentru a automatiza procesele, a construi instrumente obsedate de clienți și a crea infrastructură pentru diverse aplicații pentru baza sa globală de clienți. Val are experiență într-o mare varietate de tehnologii, cum ar fi dezvoltarea web front-end, munca backend și AI/ML.
 Niall Robinson este șeful departamentului de produse futures la Met Office din Marea Britanie. El și echipa sa explorează noi moduri în care Met Office poate oferi valoare prin inovarea produselor și parteneriate strategice. El a avut o carieră variată, conducând o echipă multidisciplinară de cercetare și dezvoltare în domeniul informaticii, cercetare academică în știința datelor și om de știință pe teren, împreună cu expertiză în modelarea climatică.
Niall Robinson este șeful departamentului de produse futures la Met Office din Marea Britanie. El și echipa sa explorează noi moduri în care Met Office poate oferi valoare prin inovarea produselor și parteneriate strategice. El a avut o carieră variată, conducând o echipă multidisciplinară de cercetare și dezvoltare în domeniul informaticii, cercetare academică în știința datelor și om de știință pe teren, împreună cu expertiză în modelarea climatică.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Mintând viitorul cu Adryenn Ashley. Accesați Aici.
- Cumpărați și vindeți acțiuni în companii PRE-IPO cu PREIPO®. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :are
- :este
- :Unde
- $UP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- capacitate
- Capabil
- Despre Noi
- mai sus
- REZUMAT
- rezumate
- academic
- cercetare academica
- accelera
- accelerarea
- acces
- accesate
- găzdui
- realiza
- Cont
- Realizeaza
- peste
- se adaptează
- adăugat
- adăugare
- Suplimentar
- În plus,
- adresa
- adresare
- Adaugă
- administratori
- adoptată
- Adoptare
- După
- AI / ML
- AIR
- TOATE
- Permiterea
- permite
- de-a lungul
- de asemenea
- Amazon
- Amazon EC2
- an
- analiză
- și
- Orice
- apărea
- aplicație
- aplicatii
- abordare
- abordari
- adecvat
- arhitectură
- SUNT
- AS
- At
- Atmosfera
- atmosferic
- automatizarea
- evita
- AWS
- Client AWS
- Șira spinării
- sprijinit
- Backend
- fundal
- Sold
- de bază
- bazat
- BE
- deveni
- fost
- înainte
- fiind
- de mai jos
- Benchmark
- Mai bine
- între
- Mare
- Datele mari
- Bootstrap
- atât
- Aducere
- Spart
- construi
- Clădire
- construit
- construit-in
- afaceri
- dar
- by
- calcula
- apel
- denumit
- apel
- apeluri
- CAN
- capacități
- capabil
- Carieră
- catalog
- CD
- Celule
- contesta
- provocare
- Schimbare
- schimbarea
- taxă
- taxe
- alegeri
- Circulație
- client
- Climat
- mai aproape
- Cloud
- Grup
- CO
- cod
- baza codului
- colaborare
- Colectare
- cum
- vine
- venire
- comentariu
- comunitate
- Companii
- Completă
- complex
- componente
- Compus
- calcul
- Calcula
- calculator
- Computer Vision
- tehnica de calcul
- Configuraţie
- Conectați
- legat
- Conectarea
- conexiune
- Consumatorii
- consum
- Recipient
- conține
- continua
- continuă
- copii
- Nucleu
- corecta
- A costat
- cost-eficiente
- ar putea
- cuplat
- Procesor
- crea
- creează
- Creator
- critic
- cultură
- Trece
- curiozitate
- Curent
- personalizat
- client
- clienţii care
- personalizabil
- personaliza
- zilnic
- tablou de bord
- de date
- știința datelor
- strategie de date
- seturi de date
- zi
- deceniu
- Deciziile
- Mod implicit
- Cerere
- demonstrează
- implementa
- dislocate
- desfășurarea
- implementează
- proiectat
- distruge
- detaliat
- detalii
- Determina
- dezvolta
- Dezvoltator
- Dezvoltare
- Dispozitive
- diferenţă
- invalid
- descoperire
- Afişa
- distribuite
- calcul distribuit
- dns
- Docher
- domeniu
- jos
- dinamic
- dinamic
- fiecare
- uşura
- cu ușurință
- Margine
- editare
- eficient
- în altă parte
- permite
- un capăt la altul
- energie
- angajament
- inginer
- intrare
- Mediu inconjurator
- Echivalent
- Eră
- estimativ
- Eter (ETH)
- Fiecare
- in fiecare zi
- de fiecare zi
- evolua
- exemplu
- exemple
- experienţă
- experiment
- expertiză
- explora
- exporturile
- expus
- extensie
- mai repede
- Caracteristică
- DESCRIERE
- camp
- Domenii
- Fișier
- Fişiere
- Găsi
- First
- se concentrează
- urma
- următor
- alimente
- Pentru
- formă
- format
- formulare
- găsit
- Fondat
- Cadru
- cadre
- Gratuit
- din
- rodire
- Complet
- funcționalitate
- mai mult
- viitor
- Futures
- General
- generaţie
- obține
- obtinerea
- merge
- Caritate
- retea globala
- La nivel global
- glob
- merge
- grafic
- mai mare
- Grilă
- Crește
- În creştere
- HAD
- Jumătate
- redus la jumătate
- Avea
- he
- cap
- ajutor
- ajută
- ei
- Înalt
- performanta ridicata
- highlights-uri
- lui
- istoric
- gazdă
- găzduit
- oră
- Cum
- Cum Pentru a
- Totuși
- HTML
- HTTPS
- uman poate fi citit
- sute
- Idle
- ID-uri
- if
- ilustrează
- import
- importatoare
- îmbunătăţi
- îmbunătățire
- in
- include
- include
- a crescut
- index
- indica
- Informa
- informații
- Infrastructură
- inerent
- Inovaţie
- intrare
- nesiguranţă
- înţelegere
- inspirat
- instala
- instanță
- in schimb
- instrucțiuni
- integrare
- Intenționat
- interacţiona
- interacționând
- interfaţă
- intern
- Internet
- în
- invita
- IoT
- IP
- Adresa IP
- probleme de
- IT
- ESTE
- Loc de munca
- călătorie
- jpg
- Jupiter Notebook
- A pastra
- Cheie
- Cunoaște
- limbă
- mare
- Nume
- Latență
- lansa
- conducere
- AFLAȚI
- învăţare
- Bibliotecă
- ciclu de viață
- ca
- legarea
- Listă
- încărca
- local
- la nivel local
- situat
- locaţie
- Londra
- maşină
- masina de învățare
- major
- face
- administra
- manager
- gestionează
- Hartă
- cartografiere
- Masa
- Adopție în masă
- material
- Mai..
- însemna
- mecanism
- Metadata
- milioane
- ML
- model
- Modern
- Module
- Lună
- lunar
- date lunare
- mai mult
- cele mai multe
- MOUNT
- multidisciplinare
- nume
- național
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Natură
- necesar
- Nevoie
- au nevoie
- reţea
- Nou
- următor
- noapte
- nod
- noduri
- caiet
- notebook-uri
- acum
- număr
- numere
- of
- oferi
- Birou
- on
- ONE
- afară
- deschide
- de date deschise
- open-source
- cod open-source
- operațional
- Opțiune
- Opţiuni
- or
- orchestrație
- organizații
- Altele
- al nostru
- afară
- rezultate
- producție
- peste
- global
- pachet
- parametru
- parte
- special
- în special
- parteneriate
- Trecut
- Care trece
- Model
- performanță
- perioadele
- personalizare
- petabyte
- fază
- plan
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- piscină
- porturi
- posibil
- Post
- potenţial
- putere
- puternic
- practică
- prezicere
- Predictii
- premise
- precedent
- primar
- Principal
- privat
- Problemă
- probleme
- proces
- procese
- prelucrare
- Produs
- Produs
- Inovația produselor
- productiv
- Program
- Programare
- proiect
- prototipuri
- prototipuri
- furniza
- prevăzut
- furnizează
- dispoziţie
- public
- publica
- publicat
- Trage
- interogări
- Întrebări
- C&D
- gamă
- mai degraba
- gata făcute
- lumea reală
- realiza
- reduce
- reducerea
- reducere
- regiune
- regional
- regiuni
- neobosit
- rămășițe
- scoate
- îndepărtat
- depozit
- reprezintă
- cercetare
- Resurse
- respectiv
- REZULTATE
- Rol
- Alerga
- funcţionare
- SA
- sigur
- sagemaker
- acelaşi
- Economisiți
- scalabil
- Scară
- cântare
- scalare
- Ştiinţă
- Om de stiinta
- oamenii de stiinta
- script-uri
- secunde
- Secțiune
- vedea
- văzut
- segmente
- selectate
- selecţie
- senior
- serie
- serverless
- servește
- serviciu
- Servicii
- set
- Distribuie
- comun
- să
- Arăta
- simbolizeazã
- Emisiuni
- simplu
- pur şi simplu
- al șaselea
- încetini
- So
- soluţie
- soluţii
- REZOLVAREA
- unele
- Sursă
- spațial
- specific
- Specificaţii
- specificată
- sponsorizare
- stivui
- Stadiile
- standalone
- Începe
- început
- şedere
- paşi
- depozitare
- stoca
- stocate
- magazine
- simplu
- Strategic
- Parteneriate strategice
- Strategie
- ulterior
- Ulterior
- de succes
- astfel de
- Suprafață
- apare
- Durabilitate
- durabilă
- sistem
- sisteme
- tabel
- Lua
- echipă
- tech
- Tehnologii
- Tehnologia
- test
- decât
- acea
- informațiile
- Sursa
- Marea Britanie
- lumea
- lor
- apoi
- Acolo.
- astfel
- Acestea
- ei
- acest
- aceste
- trei
- Prospera
- Prin
- debit
- timp
- Seria de timp
- ori
- titluri
- la
- astăzi
- împreună
- Unelte
- urmări
- Urmărire
- transfer
- transformare
- tranzit
- declanșând
- ÎNTORCĂ
- Două
- tip
- manuscris dactilografiat
- tipic
- Uk
- în
- deschide
- nesustenabil
- up-to-data
- actualizări
- pe
- URI
- Folosire
- utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- UTC
- Utilizand
- VAL
- valoare
- varietate
- diverse
- de
- viziune
- Vizita
- volum
- vrea
- vrea
- cald
- a fost
- Cale..
- modalități de
- we
- Vreme
- web
- dezvoltare web
- au fost
- dacă
- care
- larg
- Gamă largă
- voi
- dorește
- cu
- fără
- Apartamente
- lucrător
- muncitorii
- lume
- face griji
- ar
- scris
- ani
- încă
- Randament
- tu
- Ta
- zephyrnet