Găsirea coloanelor similare în a lac de date are aplicații importante în curățarea și adnotarea datelor, potrivirea schemelor, descoperirea datelor și analiză în mai multe surse de date. Incapacitatea de a găsi și analiza cu acuratețe date din surse disparate reprezintă un potențial ucigaș al eficienței pentru toată lumea, de la oamenii de știință ai datelor, cercetătorii medicali, cadrele universitare, până la analiștii financiari și guvernamentali.
Soluțiile convenționale implică căutarea lexicală a cuvintelor cheie sau potrivirea expresiilor regulate, care sunt susceptibile la probleme de calitate a datelor, cum ar fi nume de coloane absente sau convenții diferite de denumire a coloanelor din diverse seturi de date (de exemplu, zip_code, zcode, postalcode).
În această postare, demonstrăm o soluție pentru căutarea coloanelor similare bazate pe numele coloanei, conținutul coloanei sau ambele. Soluția folosește algoritmi aproximativi ai vecinilor cei mai apropiati disponibil in Serviciul Amazon OpenSearch pentru a căuta coloane similare din punct de vedere semantic. Pentru a facilita căutarea, creăm reprezentări de caracteristici (înglobări) pentru coloanele individuale în lacul de date folosind modele Transformer pre-antrenate din biblioteca de transformatoare de propoziții in Amazon SageMaker. În cele din urmă, pentru a interacționa cu și a vizualiza rezultatele din soluția noastră, construim un interactiv Iluminat în flux aplicația web care rulează AWS Fargate.
Includem un tutorial de cod pentru ca dvs. să implementați resursele pentru a rula soluția pe date eșantion sau pe propriile date.
Prezentare generală a soluțiilor
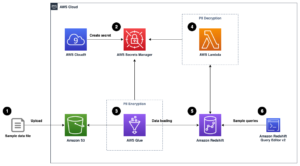
Următoarea diagramă de arhitectură ilustrează fluxul de lucru în două etape pentru găsirea coloanelor similare din punct de vedere semantic. Prima etapă rulează un Funcții pas AWS flux de lucru care creează înglobări din coloane tabulare și construiește indexul de căutare OpenSearch Service. A doua etapă, sau etapa de inferență online, rulează o aplicație Streamlit prin Fargate. Aplicația web colectează interogări de căutare de intrare și preia din indexul Serviciului OpenSearch coloanele aproximative cele mai asemănătoare cu interogarea.

Figura 1. Arhitectura soluției
Fluxul de lucru automat decurge în următorii pași:
- Utilizatorul încarcă seturi de date tabelare într-un Serviciul Amazon de stocare simplă (Amazon S3), care invocă un AWS Lambdas funcția care inițiază fluxul de lucru Step Functions.
- Fluxul de lucru începe cu un AWS Adeziv job care convertește fișierele CSV în Parchet Apache format de date.
- O lucrare de procesare SageMaker creează înglobări pentru fiecare coloană folosind modele pre-antrenate sau modele personalizate de încorporare a coloanei. Lucrarea de procesare SageMaker salvează încorporarea coloanelor pentru fiecare tabel în Amazon S3.
- O funcție Lambda creează domeniul și clusterul OpenSearch Service pentru a indexa înglobările coloanelor produse în pasul anterior.
- În cele din urmă, o aplicație web interactivă Streamlit este implementată cu Fargate. Aplicația web oferă utilizatorului o interfață pentru a introduce interogări pentru a căuta în domeniul OpenSearch Service coloane similare.
Puteți descărca tutorialul de cod de la GitHub pentru a încerca această soluție pe date eșantion sau propriile dvs. date. Instrucțiunile despre cum să implementați resursele necesare pentru acest tutorial sunt disponibile pe Github.
Precondiții
Pentru a implementa această soluție, aveți nevoie de următoarele:
- An Cont AWS.
- Familiaritate de bază cu serviciile AWS, cum ar fi Kit AWS Cloud Development (AWS CDK), Lambda, OpenSearch Service și SageMaker Processing.
- Un set de date tabelar pentru a crea indexul de căutare. Puteți aduce propriile date tabelare sau puteți descărca seturile de date eșantion de pe GitHub.
Creați un index de căutare
Prima etapă construiește indexul motorului de căutare a coloanei. Următoarea figură ilustrează fluxul de lucru Step Functions care rulează această etapă.

Figura 2 – Flux de lucru pentru funcțiile pas – mai multe modele de încorporare
Datasets
În această postare, construim un index de căutare pentru a include peste 400 de coloane din peste 25 de seturi de date tabulare. Seturile de date provin din următoarele surse publice:
Pentru lista completă a tabelelor incluse în index, consultați tutorialul de cod GitHub.
Puteți aduce propriul set de date tabelar pentru a mări datele eșantionului sau pentru a crea propriul index de căutare. Includem două funcții Lambda care inițiază fluxul de lucru Step Functions pentru a construi indexul de căutare pentru fișiere CSV individuale sau, respectiv, un lot de fișiere CSV.
Transformați CSV în parchet
Fișierele CSV brute sunt convertite în format de date Parquet cu AWS Glue. Parquet este un format de fișier cu format orientat pe coloane, preferat în analiza datelor mari, care oferă compresie și codificare eficiente. În experimentele noastre, formatul de date Parquet a oferit o reducere semnificativă a dimensiunii de stocare în comparație cu fișierele CSV brute. De asemenea, am folosit Parquet ca format comun de date pentru a converti alte formate de date (de exemplu JSON și NDJSON), deoarece acceptă structuri de date imbricate avansate.
Creați înglobări de coloane tabelare
Pentru a extrage înglobări pentru coloane individuale de tabel în seturile de date tabelare eșantion din această postare, folosim următoarele modele pre-antrenate din sentence-transformers bibliotecă. Pentru modele suplimentare, vezi Modele preinstruite.
Lucrarea de procesare SageMaker rulează create_embeddings.py(cod) pentru un singur model. Pentru extragerea înglobărilor din mai multe modele, fluxul de lucru rulează lucrări paralele de procesare SageMaker, așa cum se arată în fluxul de lucru Step Functions. Folosim modelul pentru a crea două seturi de înglobări:
- coloană_nume_embeddings – încorporarea numelor de coloane (anteturi)
- column_content_embeddings – Încorporarea medie a tuturor rândurilor din coloană
Pentru mai multe informații despre procesul de încorporare a coloanei, consultați tutorialul de cod GitHub.
O alternativă la pasul de procesare SageMaker este de a crea o transformare batch SageMaker pentru a obține încorporarea coloanelor pe seturi de date mari. Acest lucru ar necesita implementarea modelului la un punct final SageMaker. Pentru mai multe informații, vezi Utilizați Transformarea lotului.
Înglobări de indexare cu serviciul OpenSearch
În pasul final al acestei etape, o funcție Lambda adaugă încorporarea coloanei la un serviciu OpenSearch aproximativ k-Nearest-Neighbor (kNN) index de căutare. Fiecărui model i se atribuie propriul index de căutare. Pentru mai multe informații despre parametrii aproximativi ai indexului de căutare kNN, consultați k-NN.
Inferență online și căutare semantică cu o aplicație web
A doua etapă a fluxului de lucru rulează a Iluminat în flux aplicație web unde puteți furniza intrări și puteți căuta coloane similare din punct de vedere semantic indexate în OpenSearch Service. Stratul de aplicație folosește un Aplicație Load Balancer, Fargate și Lambda. Infrastructura aplicației este implementată automat ca parte a soluției.
Aplicația vă permite să furnizați o intrare și să căutați nume de coloane similare din punct de vedere semantic, conținut de coloane sau ambele. În plus, puteți selecta modelul de încorporare și numărul de vecini cei mai apropiați pentru a reveni din căutare. Aplicația primește intrări, încorporează intrarea cu modelul specificat și folosește Căutare kNN în Serviciul OpenSearch pentru a căuta înglobări de coloane indexate și pentru a găsi coloanele cele mai asemănătoare cu intrarea dată. Rezultatele căutării afișate includ numele tabelelor, numele coloanelor și scorurile de similaritate pentru coloanele identificate, precum și locațiile datelor în Amazon S3 pentru explorare ulterioară.
Figura următoare prezintă un exemplu de aplicație web. În acest exemplu, am căutat coloane în lacul nostru de date care au similare Column Names (tip de sarcină utilă) Pentru a district (sarcină utilă). Aplicația utilizată all-MiniLM-L6-v2 ca model de încorporare și s-a întors 10 (k) cei mai apropiați vecini din indexul nostru OpenSearch Service.
Aplicația a revenit transit_district, city, borough, și location ca cele mai asemănătoare patru coloane bazate pe datele indexate în OpenSearch Service. Acest exemplu demonstrează capacitatea abordării de căutare de a identifica coloane similare din punct de vedere semantic în seturi de date.

Figura 3: Interfața cu utilizatorul aplicației web
A curăța
Pentru a șterge resursele create de AWS CDK în acest tutorial, rulați următoarea comandă:
cdk destroy --allConcluzie
În această postare, am prezentat un flux de lucru end-to-end pentru construirea unui motor de căutare semantică pentru coloanele tabulare.
Începeți astăzi cu propriile date cu ajutorul tutorialului nostru de cod disponibil pe GitHub. Dacă doriți ajutor pentru accelerarea utilizării ML în produsele și procesele dvs., vă rugăm să contactați Laboratorul de soluții Amazon Machine Learning Solutions.
Despre Autori
![]() Kachi Odoemene este un om de știință aplicat la AWS AI. El creează soluții AI/ML pentru a rezolva problemele de afaceri pentru clienții AWS.
Kachi Odoemene este un om de știință aplicat la AWS AI. El creează soluții AI/ML pentru a rezolva problemele de afaceri pentru clienții AWS.
![]() Taylor McNally este arhitect Deep Learning la Amazon Machine Learning Solutions Lab. El ajută clienții din diverse industrii să construiască soluții care folosesc AI/ML pe AWS. Îi bucură o ceașcă bună de cafea, în aer liber și timp cu familia și câinele energic.
Taylor McNally este arhitect Deep Learning la Amazon Machine Learning Solutions Lab. El ajută clienții din diverse industrii să construiască soluții care folosesc AI/ML pe AWS. Îi bucură o ceașcă bună de cafea, în aer liber și timp cu familia și câinele energic.
![]() Austin Welch este Data Scientist în Amazon ML Solutions Lab. El dezvoltă modele personalizate de învățare profundă pentru a ajuta clienții din sectorul public AWS să-și accelereze adoptarea AI și a cloud-ului. În timpul liber, îi place să citească, să călătorească și să fie jiu-jitsu.
Austin Welch este Data Scientist în Amazon ML Solutions Lab. El dezvoltă modele personalizate de învățare profundă pentru a ajuta clienții din sectorul public AWS să-și accelereze adoptarea AI și a cloud-ului. În timpul liber, îi place să citească, să călătorească și să fie jiu-jitsu.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- capacitate
- Despre Noi
- absent
- accelera
- accelerarea
- precis
- peste
- Suplimentar
- În plus,
- Adaugă
- Adoptare
- avansat
- AI
- AI / ML
- TOATE
- permite
- alternativă
- Amazon
- Învățare automată Amazon
- Laboratorul Amazon ML Solutions
- analiști
- Google Analytics
- analiza
- și
- Apache
- aplicație
- aplicatii
- aplicat
- abordare
- arhitectură
- alocate
- Automata
- în mod automat
- disponibil
- in medie
- AWS
- AWS Adeziv
- bazat
- deoarece
- Mare
- Datele mari
- aduce
- construi
- Clădire
- construiește
- afaceri
- Curățenie
- Cloud
- adoptarea norului
- Grup
- cod
- Cafea
- colecte
- Coloană
- Coloane
- Comun
- comparație
- contactați-ne
- conţinut
- Convenții
- converti
- convertit
- crea
- a creat
- creează
- Ceaşcă
- personalizat
- clienţii care
- de date
- Analiza datelor
- Lacul de date
- calitatea datelor
- om de știință de date
- seturi de date
- adânc
- învățare profundă
- demonstra
- demonstrează
- implementa
- dislocate
- Implementarea
- distruge
- Dezvoltare
- dezvoltă
- diferit
- descoperire
- nebunie
- diferit
- Câine
- domeniu
- Descarca
- fiecare
- eficiență
- eficient
- un capăt la altul
- Punct final
- Motor
- Eter (ETH)
- toată lumea
- exemplu
- explorare
- extrage
- facilita
- Familiaritate
- familie
- DESCRIERE
- Figura
- Fișier
- Fişiere
- final
- În cele din urmă
- financiar
- Găsi
- descoperire
- First
- următor
- format
- din
- Complet
- funcţie
- funcții
- mai mult
- obține
- dat
- bine
- Guvern
- anteturile
- ajutor
- ajută
- Cum
- Cum Pentru a
- HTML
- HTTPS
- identificat
- identifica
- punerea în aplicare a
- important
- in
- incapacitate
- include
- inclus
- index
- individ
- industrii
- informații
- Infrastructură
- iniția
- Initiaza
- intrare
- instrucțiuni
- interacţiona
- interactiv
- interfaţă
- invocă
- implica
- probleme de
- IT
- Loc de munca
- Locuri de munca
- JSON
- de laborator
- lac
- mare
- strat
- învăţare
- efectului de pârghie
- Bibliotecă
- Listă
- încărca
- Locații
- maşină
- masina de învățare
- potrivire
- medical
- ML
- model
- Modele
- mai mult
- cele mai multe
- multiplu
- nume
- nume
- denumire
- Nevoie
- vecini
- număr
- oferit
- on-line
- Altele
- în aer liber
- propriu
- Paralel
- parametrii
- parte
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- Post
- potenţial
- preferat
- prezentat
- precedent
- probleme
- venituri
- proces
- procese
- prelucrare
- Produs
- Produse
- furniza
- furnizează
- public
- calitate
- Crud
- Citind
- primește
- regulat
- reprezintă
- necesita
- necesar
- cercetători
- Resurse
- respectiv
- REZULTATE
- reveni
- Alerga
- funcţionare
- sagemaker
- Om de stiinta
- oamenii de stiinta
- Caută
- motor de cautare
- căutare
- Al doilea
- sector
- serviciu
- Servicii
- Seturi
- indicat
- Emisiuni
- semnificativ
- asemănător
- simplu
- singur
- Mărimea
- soluţie
- soluţii
- REZOLVAREA
- Surse
- specificată
- Etapă
- început
- Pas
- paşi
- depozitare
- astfel de
- Sprijină
- susceptibil
- tabel
- lor
- Prin
- timp
- la
- astăzi
- Transforma
- transformatoare
- Traveling
- tutorial
- utilizare
- Utilizator
- User Interface
- diverse
- web
- aplicatie web
- care
- flux de lucru
- ar
- Ta
- zephyrnet