- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :este
- 10
- 100
- 15%
- 2023
- 7
- a
- Capabil
- peste
- Adoptarea
- AI
- deopotrivă
- TOATE
- Cu toate ca
- printre
- an
- și
- răspunsuri
- aplicat
- SUNT
- AS
- solicitând
- aspecte
- asistenți
- asociate
- At
- ataca
- Atacuri
- disponibil
- departe
- BE
- fiind
- între
- miliarde
- construi
- întreprinderi
- dar
- by
- CAN
- cu grijă
- CEO
- chatbots
- Chat GPT
- clar
- închis
- Comun
- Companii
- calculator
- Îngrijorare
- referitor la
- Conferință
- ar putea
- crea
- Crearea
- critic
- În prezent
- Cyber
- Data
- demonstra
- demonstrat
- Implementarea
- detaliat
- Detectare
- dezvolta
- diferit
- digital
- a descoperit
- dr
- Companii
- Întreg
- Chiar
- dovadă
- exista
- existent
- Exploata
- extracţie
- extrem
- fascinant
- financiar
- Servicii financiare
- First
- concentrat
- Pentru
- din
- mai mult
- dobândită
- dat
- Oferirea
- Teren
- Avea
- Ascuns
- highlights-uri
- găzduit
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- Față îmbrățișată
- important
- in
- a crescut
- tot mai mult
- industrie
- Informa
- informații
- securitatea informațiilor
- profund
- Internet
- Investi
- investind
- IT
- jpg
- Cheie
- cunoştinţe
- cunoscut
- limbă
- mare
- Întreprinderi mari
- lansa
- conducere
- AFLAȚI
- învăţare
- mai puțin
- mic
- maşină
- masina de învățare
- major
- Mai..
- măsurare
- milioane
- model
- Modele
- mult
- Nou
- of
- on
- deschide
- open-source
- or
- afară
- propriu
- Hârtie
- parte
- Peter
- Locuri
- planificare
- Plato
- Informații despre date Platon
- PlatoData
- posibil
- potenţial
- puternic
- pregătirea
- prezentat
- Principal
- privat
- furniza
- public
- gamă
- rată
- replicat
- cereri de
- cercetare
- cercetători
- dezvălui
- Riscurile
- Said
- Spune
- oamenii de stiinta
- securitate
- Servicii
- set
- să
- Arăta
- mai mici
- inteligent
- So
- unele
- Sursă
- Etapă
- Discovery
- Furtună
- Studiu
- succes
- Reușit
- astfel de
- luate
- vorbesc
- vizate
- direcționare
- sarcini
- echipă
- Tehnologii
- Tehnologia
- Testarea
- decât
- acea
- informațiile
- Marea Britanie
- lumea
- lor
- apoi
- Acolo.
- Acestea
- ei
- crede
- Al treilea
- acest
- în acest an
- ori
- la
- Unelte
- transferat
- transformativă
- Uk
- înţelegere
- întreprinde
- universitate
- utilizare
- utilizat
- utilizări
- prețuit
- foarte
- Vulnerabilitățile
- a fost
- Cale..
- we
- săptămână
- au fost
- care
- larg
- Gamă largă
- voi
- cu
- în
- fără
- Apartamente
- a face exerciţii fizice
- fabrică
- lume
- îngrijorător
- an
- zephyrnet
Mai mult de la Nanowerk
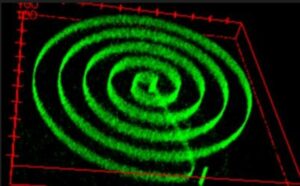
Dezlănțuirea unei noi ere a nano-dispozitivelor reglabile în culori – cea mai mică sursă de lumină cu culori comutabile formate
Nodul sursă: 2801585
Timestamp-ul: August 3, 2023

Solventul „magic” creează pelicule subțiri mai puternice
Nodul sursă: 1957849
Timestamp-ul: Februarie 14, 2023
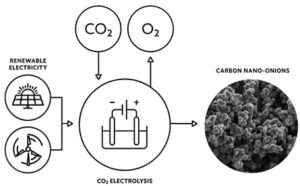
Nanotuburile de carbon pot juca un rol semnificativ în legarea dioxidului de carbon din atmosferă
Nodul sursă: 2836729
Timestamp-ul: August 21, 2023

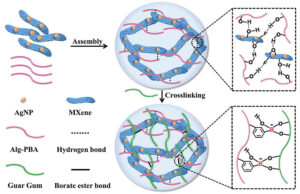
Senzori epidermici antibacterieni pe bază de hidrogel MXene
Nodul sursă: 2661017
Timestamp-ul: 18 Mai, 2023
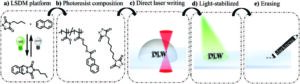
Imprimările 3D se unesc cu partea întunecată și dispar
Nodul sursă: 2903619
Timestamp-ul: Septembrie 27, 2023
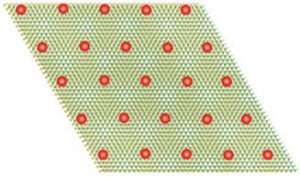
Când materialul devine cuantic, electronii încetinesc și formează un cristal
Nodul sursă: 1975767
Timestamp-ul: Februarie 23, 2023

Inginerii dezvoltă un proces eficient pentru a produce combustibil din dioxid de carbon
Nodul sursă: 2963812
Timestamp-ul: Octombrie 30, 2023