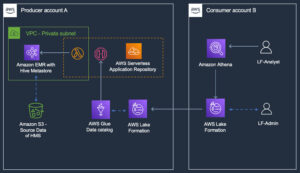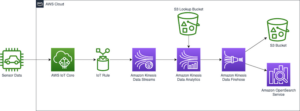
Amazon Atena este un serviciu interactiv de interogări care facilitează analiza datelor Serviciul Amazon de stocare simplă (Amazon S3) și surse de date care locuiesc în AWS, on-premises sau alte sisteme cloud care utilizează SQL sau Python. Athena este construit pe motoarele Trino și Presto open-source și cadre Apache Spark, fără a fi necesar niciun efort de configurare sau de aprovizionare. Athena este fără server, deci nu există nicio infrastructură de gestionat și plătiți doar pentru interogările pe care le executați.
Apache Iceberg este un format de tabel deschis pentru seturi de date analitice foarte mari. Gestionează colecții mari de fișiere sub formă de tabele și acceptă operațiuni moderne de lac de date analitice, cum ar fi interogări de inserare, actualizare, ștergere și călătorie în timp la nivel de înregistrare. Athena acceptă interogări de citire, călătorie în timp, scriere și DDL pentru tabelele Apache Iceberg care utilizează formatul Apache Parquet pentru date și Catalogul de date AWS Glue pentru metamagazinul lor.
Ingineria caracteristicilor este un proces de identificare și transformare a datelor brute (imagini, fișiere text, videoclipuri și așa mai departe), completarea datelor lipsă și adăugarea unuia sau mai multor elemente de date semnificative pentru a oferi context, astfel încât un model de învățare automată (ML) să poată învăța din acestea. Etichetarea datelor este necesară pentru diferite cazuri de utilizare, inclusiv prognoza, viziunea computerizată, procesarea limbajului natural și recunoașterea vorbirii.
Combinat cu capabilitățile Athena, Apache Iceberg oferă un flux de lucru simplificat pentru oamenii de știință de date pentru a crea noi caracteristici de date fără a fi nevoie să copieze sau să recreeze întregul set de date. Puteți crea funcții folosind SQL standard pe Athena fără a utiliza niciun alt serviciu pentru inginerie de caracteristici. Oamenii de știință de date pot reduce timpul petrecut cu pregătirea și copierea seturilor de date și, în schimb, se pot concentra pe ingineria caracteristicilor datelor, experimentarea și analiza datelor la scară.
În această postare, trecem în revistă beneficiile utilizării Athena cu formatul de tabel deschis Apache Iceberg și modul în care simplifică sarcinile comune de inginerie a caracteristicilor pentru oamenii de știință de date. Demonstrăm cum Athena poate converti un tabel existent în format Apache Iceberg, apoi poate adăuga coloane, șterge coloane și modifica datele din tabel fără a recrea sau copia setul de date și poate folosi aceste capabilități pentru a crea noi caracteristici pe tabelele Apache Iceberg.
Prezentare generală a soluțiilor
Oamenii de știință de date sunt, în general, obișnuiți să lucreze cu seturi de date mari. Seturile de date sunt de obicei stocate în JSON, CSV, ORC sau Parchet Apache format sau formate similare optimizate pentru citire pentru performanță de citire rapidă. Oamenii de știință de date creează adesea noi caracteristici de date și completează astfel de caracteristici de date cu date agregate și auxiliare. Din punct de vedere istoric, această sarcină a fost realizată prin crearea unei vizualizări deasupra tabelului cu datele de bază în format Apache Parquet, unde astfel de coloane și date au fost adăugate în timpul execuției sau prin crearea unui nou tabel cu coloane suplimentare. Deși acest flux de lucru este potrivit pentru multe cazuri de utilizare, este ineficient pentru seturi de date mari, deoarece datele ar trebui generate în timpul rulării sau seturile de date ar trebui copiate și transformate.
Athena a prezentat Tranzacție ACID (atomicitate, consistență, izolare, durabilitate). capabilități care adaugă operațiuni de INSERT, UPDATE, DELETE, MERGE și de călătorie în timp Mesele Apache Iceberg. Aceste capabilități le permit oamenilor de știință de date să creeze noi caracteristici de date și să renunțe la caracteristicile de date existente pe seturile de date existente fără a-și face griji cu privire la copierea sau transformarea setului de date sau la abstracția acestuia cu o vizualizare. Oamenii de știință de date se pot concentra pe munca de inginerie a caracteristicilor și pot evita copierea și transformarea seturilor de date.
Operația Athena Iceberg UPDATE scrie fișierele de ștergere a poziției Apache Iceberg și rândurile nou actualizate ca fișiere de date în aceeași tranzacție. Puteți face corecturi ale înregistrărilor printr-o singură instrucțiune UPDATE.
Odată cu lansarea versiunii 3 a motorului Athena, capacitățile pentru tabelele Apache Iceberg sunt îmbunătățite cu suport pentru operațiuni precum CREATE TABLE AS SELECT (CTAS) și comenzi MERGE care simplifică gestionarea ciclului de viață al datelor tale Iceberg. CTAS face rapid și eficient crearea de tabele din alte formate, cum ar fi Apache Paquet și FUSIONAȚI ÎN actualizează, șterge sau inserează rânduri condiționate într-un tabel Iceberg. O singură instrucțiune poate combina acțiuni de actualizare, ștergere și inserare.
Cerințe preliminare
Configurați un grup de lucru Athena cu motorul Athena versiunea 3 pentru a utiliza comenzile CTAS și MERGE cu un tabel Apache Iceberg. Pentru a actualiza motorul Athena existent la versiunea 3 în grupul de lucru Athena, urmați instrucțiunile din Faceți upgrade la versiunea 3 a motorului Athena pentru a crește performanța interogărilor și a accesa mai multe funcții de analiză sau se referă la Schimbarea versiunii motorului în consola Athena.
Setul de date
Pentru demonstrație, folosim un tabel Apache Parquet care conține câteva milioane de înregistrări de date de vânzări fictive distribuite aleatoriu din ultimii câțiva ani stocate într-o găleată S3. Descarcă setul de date, dezarhivați-l pe computerul local și încărcați-l în bucket-ul S3. În această postare, ne-am încărcat setul de date în s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
Următorul tabel prezintă aspectul tabelului customer_orders.
| Nume coloană | Tipul de date | Descriere |
| cheie de comandă | şir | Numărul de comandă pentru comandă |
| custkey | şir | Numărul de identificare a clientului |
| starea comenzii | şir | Starea comenzii |
| pretul total | şir | Pretul total al comenzii |
| Data comandă | şir | Data comenzii |
| prioritate de ordine | şir | Prioritatea comenzii |
| funcționar | şir | Numele funcționarului care a procesat comanda |
| prioritatea navei | şir | Prioritate la transport |
| nume | şir | Numele clientului |
| adresa | şir | Adresa clientului |
| cheie națională | şir | Cheie de națiune client |
| telefon | şir | Numărul de telefon al clientului |
| acctbal | şir | Soldul contului clientului |
| mktsegment | şir | Segment de piață de clienți |
Efectuați ingineria caracteristicilor
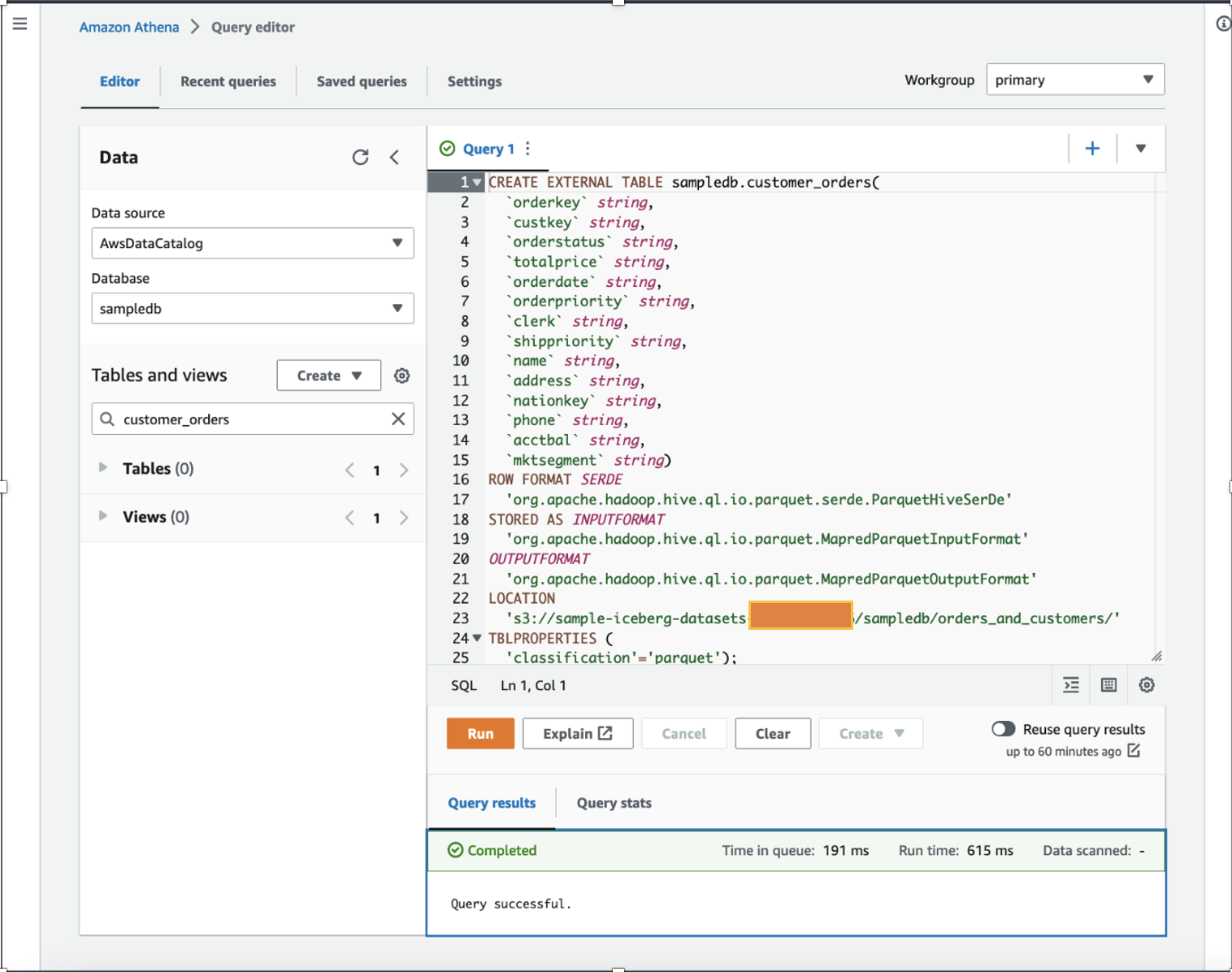
În calitate de cercetător de date, vrem să performam inginerie de caracteristici pe datele comenzilor clienților adăugând achiziții totale calculate pe un an și achiziții medii pe un an pentru fiecare client din setul de date existent. În scopuri demonstrative, am creat customer_orders masa în sampledb baza de date folosind Athena, așa cum se arată în următoarea comandă DDL. (Puteți folosi oricare dintre seturile de date existente și urmați pașii menționați în această postare.) customer_orders setul de date a fost generat și stocat în locația compartimentului S3 s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ în format parchet. Acest tabel nu este un tabel Apache Iceberg.
![]()
Validați datele din tabel rulând o interogare:
![]()
Dorim să adăugăm noi funcții la acest tabel pentru a obține o înțelegere mai profundă a vânzărilor clienților, ceea ce poate duce la o instruire mai rapidă a modelului și informații mai valoroase. Pentru a adăuga caracteristici noi la setul de date, convertiți customer_orders Masa Athena la masa Apache Iceberg pe Athena. Problema a CTAS declarație de interogare pentru a crea un tabel nou cu formatul Apache Iceberg din customer_orders masa. În timp ce faceți acest lucru, o nouă funcție este adăugată pentru a obține suma totală de achiziție din ultimul an (anul maxim al setului de date) de către fiecare client.
În următoarea interogare CTAS, o nouă coloană numită one_year_sales_aggregate cu valoarea implicită ca 0.0 de tip de date double se adaugă şi table_type este setat la ICEBERG:
![]()
Emite următoarea interogare pentru a verifica datele din tabelul Apache Iceberg cu noua coloană one_year_sales_aggregate valori ca 0.0:
![]()
Dorim să populăm valorile pentru noua caracteristică one_year_sales_aggregate în setul de date pentru a obține suma totală de achiziție pentru fiecare client pe baza achizițiilor efectuate în ultimul an (anul maxim al setului de date). Emiteți o instrucțiune de interogare MERGE în tabelul Apache Iceberg folosind Athena pentru a popula valorile pentru one_year_sales_aggregate Caracteristica:
![]()
Emite următoarea interogare pentru a valida valoarea actualizată a cheltuielilor totale de către fiecare client în ultimul an:
![]()
Decidem să adăugăm o altă caracteristică pe un tabel Apache Iceberg existent pentru a calcula și stoca suma medie de achiziție din ultimul an de către fiecare client. Emiteți o instrucțiune de interogare ALTER pentru a adăuga o nouă coloană la un tabel existent pentru caracteristică one_year_sales_average:
![]()
Înainte de a completa valorile acestei noi caracteristici, puteți seta valoarea implicită pentru caracteristică one_year_sales_average la 0.0. Folosind același tabel Apache Iceberg pe Athena, emiteți o instrucțiune de interogare UPDATE pentru a completa valoarea pentru noua caracteristică ca 0.0:
![]()
Emite următoarea interogare pentru a verifica valoarea actualizată pentru cheltuielile medii ale fiecărui client în ultimul an 0.0:
![]()
Acum dorim să populăm valorile pentru noua caracteristică one_year_sales_average în setul de date pentru a obține suma medie de achiziție pentru fiecare client pe baza achizițiilor efectuate în ultimul an (anul maxim al setului de date). Emiteți o instrucțiune de interogare MERGE în tabelul Apache Iceberg existent pe Athena folosind motorul Athena pentru a popula valorile pentru caracteristică one_year_sales_average:
![]()
Emite următoarea interogare pentru a verifica valorile actualizate pentru cheltuielile medii ale fiecărui client:
![]()
Odată ce caracteristici suplimentare de date au fost adăugate la setul de date, oamenii de știință de date continuă, în general, să antreneze modele ML și să facă inferențe folosind Amazon Sagemaker sau un set de instrumente echivalent.
Concluzie
În această postare, am demonstrat cum să realizați ingineria caracteristicilor folosind Athena cu Apache Iceberg. De asemenea, am demonstrat utilizarea interogării CTAS pentru a crea un tabel Apache Iceberg pe Athena dintr-un set de date existent în format Apache Parquet, adăugând noi caracteristici într-un tabel Apache Iceberg existent pe Athena utilizând interogarea ALTER și utilizând instrucțiunile de interogare UPDATE și MERGE pentru a actualiza valorile caracteristice ale coloanelor existente.
Vă încurajăm să utilizați interogări CTAS pentru a crea tabele rapid și eficient și să utilizați instrucțiunea de interogare MERGE pentru a sincroniza tabelele într-un singur pas pentru a simplifica pregătirea datelor și sarcinile de actualizare atunci când transformați caracteristicile folosind Athena cu Apache Iceberg. Dacă aveți comentarii sau feedback, vă rugăm să le lăsați în secțiunea de comentarii.
Despre Autori
![]() Vivek Gautam este arhitect de date cu specializare în lacuri de date la AWS Professional Services. Lucrează cu clienții întreprinderi, creând produse de date, platforme de analiză și soluții pe AWS. Când nu construiește și proiectează platforme moderne de date, Vivek este un pasionat de mâncare căruia îi place, de asemenea, să exploreze noi destinații de călătorie și să facă drumeții.
Vivek Gautam este arhitect de date cu specializare în lacuri de date la AWS Professional Services. Lucrează cu clienții întreprinderi, creând produse de date, platforme de analiză și soluții pe AWS. Când nu construiește și proiectează platforme moderne de date, Vivek este un pasionat de mâncare căruia îi place, de asemenea, să exploreze noi destinații de călătorie și să facă drumeții.
![]() Mihail Vaynshteyn este arhitect de soluții cu Amazon Web Services. Mikhail lucrează cu clienții din domeniul sănătății și științele vieții pentru a construi soluții care ajută la îmbunătățirea rezultatelor pacienților. Mikhail este specializat în servicii de analiză a datelor.
Mihail Vaynshteyn este arhitect de soluții cu Amazon Web Services. Mikhail lucrează cu clienții din domeniul sănătății și științele vieții pentru a construi soluții care ajută la îmbunătățirea rezultatelor pacienților. Mikhail este specializat în servicii de analiză a datelor.
![]() Naresh Gautam este un lider în analiza datelor și AI/ML la AWS cu 20 de ani de experiență, căruia îi place să ajute clienții să proiecteze analize de date de înaltă performanță și rentabilitate și soluții AI/ML pentru a oferi clienților posibilitatea de a lua decizii bazate pe date. . În timpul liber, îi place meditația și gătitul.
Naresh Gautam este un lider în analiza datelor și AI/ML la AWS cu 20 de ani de experiență, căruia îi place să ajute clienții să proiecteze analize de date de înaltă performanță și rentabilitate și soluții AI/ML pentru a oferi clienților posibilitatea de a lua decizii bazate pe date. . În timpul liber, îi place meditația și gătitul.
![]() Harsha Tadiparthi este arhitect principal de soluții de specialitate, Analytics la AWS. Îi place să rezolve probleme complexe ale clienților în baze de date și analize și să ofere rezultate de succes. În afara serviciului, îi place să petreacă timp cu familia sa, să se uite la filme și să călătorească ori de câte ori este posibil.
Harsha Tadiparthi este arhitect principal de soluții de specialitate, Analytics la AWS. Îi place să rezolve probleme complexe ale clienților în baze de date și analize și să ofere rezultate de succes. În afara serviciului, îi place să petreacă timp cu familia sa, să se uite la filme și să călătorească ori de câte ori este posibil.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- EVM Finance. Interfață unificată pentru finanțare descentralizată. Accesați Aici.
- Grupul Quantum Media. IR/PR amplificat. Accesați Aici.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :are
- :este
- :nu
- :Unde
- $UP
- 10
- 100
- 12
- 17
- 20
- ani 20
- 23
- 27
- 7
- a
- Despre Noi
- accelera
- acces
- realizat
- Cont
- acțiuni
- adăuga
- adăugat
- adăugare
- Suplimentar
- adresa
- AI / ML
- de asemenea
- Cu toate ca
- Amazon
- Amazon Atena
- Amazon SageMaker
- Amazon Web Services
- sumă
- an
- analitic
- Analitic
- Google Analytics
- analiza
- analiza
- și
- O alta
- Orice
- Apache
- Apache Spark
- SUNT
- AS
- At
- disponibil
- in medie
- evita
- AWS
- Servicii profesionale AWS
- bazat
- BE
- deoarece
- fost
- Beneficiile
- construi
- Clădire
- construit
- by
- calculată
- CAN
- capacități
- cazuri
- clasificare
- Cloud
- colecții
- Coloană
- Coloane
- combina
- comentarii
- Comun
- complex
- Calcula
- calculator
- Computer Vision
- Configuraţie
- conține
- context
- converti
- gătit
- copiere
- Corectarea
- cost-eficiente
- crea
- a creat
- Crearea
- client
- clienţii care
- de date
- Analiza datelor
- Lacul de date
- știința datelor
- om de știință de date
- Pe bază de date
- Baza de date
- baze de date
- seturi de date
- Data
- decide
- Luarea deciziilor
- Mai adânc
- Mod implicit
- livrarea
- Oferă
- demonstra
- demonstrat
- proiect
- destinații
- distribuite
- face
- dubla
- Picătură
- durabilitate
- fiecare
- uşor
- eficient
- eficient
- efort
- oricare
- element
- împuternici
- permite
- încuraja
- Motor
- Inginerie
- Motoare
- sporită
- Afacere
- clienții întreprinderii
- entuziast
- Întreg
- Echivalent
- Eter (ETH)
- existent
- experienţă
- explora
- extern
- fals
- familie
- FAST
- mai repede
- Caracteristică
- DESCRIERE
- feedback-ul
- Fişiere
- Concentra
- urma
- următor
- alimente
- Pentru
- format
- cadre
- Gratuit
- din
- în general
- generată
- obține
- Go
- grup
- Hadoop
- Avea
- he
- de asistență medicală
- ajutor
- ajutor
- performanta ridicata
- extrem de
- Drumeții
- lui
- istoricește
- Stup
- Cum
- Cum Pentru a
- HTML
- HTTPS
- Identificare
- identificarea
- if
- imagini
- îmbunătăţi
- in
- Inclusiv
- Crește
- ineficace
- Infrastructură
- inserții
- perspective
- in schimb
- instrucțiuni
- interactiv
- în
- introdus
- izolare
- problema
- IT
- jpg
- JSON
- etichetarea
- lac
- limbă
- mare
- Nume
- Aspect
- lider
- AFLAȚI
- învăţare
- Părăsi
- Viaţă
- Life Sciences
- ciclu de viață
- LIMITĂ
- local
- locaţie
- iubeste
- maşină
- masina de învățare
- face
- FACE
- administra
- administrare
- gestionează
- multe
- Piață
- potrivire
- max
- semnificativ
- Meditaţie
- menționat
- Îmbina
- milion
- dispărut
- ML
- model
- Modele
- Modern
- modifica
- mai mult
- Filme
- nume
- Numit
- naţiune
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Nevoie
- au nevoie
- Nou
- optiune noua
- Funcții noi
- recent
- Nu.
- număr
- of
- de multe ori
- on
- ONE
- afară
- deschide
- open-source
- operaţie
- Operațiuni
- or
- comenzilor
- Altele
- al nostru
- rezultate
- exterior
- trecut
- Plătește
- efectua
- performanță
- telefon
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- poziţie
- posibil
- Post
- pregătirea
- preţ
- Principal
- probleme
- proces
- prelucrate
- prelucrare
- Produse
- profesional
- furniza
- cumpărare
- achiziții
- scopuri
- Piton
- interogări
- repede
- Crud
- date neprelucrate
- Citeste
- recunoaştere
- record
- înregistrări
- reduce
- eliberaţi
- necesar
- rezultat
- revizuiască
- RÂND
- Alerga
- funcţionare
- sagemaker
- de vânzări
- acelaşi
- Scară
- Ştiinţă
- ȘTIINȚE
- Om de stiinta
- oamenii de stiinta
- Secțiune
- serverless
- serviciu
- Servicii
- set
- câteva
- indicat
- Emisiuni
- asemănător
- simplu
- simplificată
- simplifica
- singur
- So
- soluţii
- Rezolvarea
- Surse
- Scânteie
- specialist
- specializată
- discurs
- Recunoaștere a vorbirii
- petrece
- uzat
- SQL
- standard
- Declarație
- Declarații
- Pas
- paşi
- depozitare
- stoca
- stocate
- simplifica
- Şir
- de succes
- astfel de
- a sustine
- Sprijină
- sisteme
- tabel
- Sarcină
- sarcini
- acea
- Fuziunea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- acest
- timp
- timp de călătorie
- la
- top
- Total
- Tren
- Pregătire
- tranzacție
- tranzacțional
- transformat
- transformare
- călătorie
- tip
- care stau la baza
- înţelegere
- Actualizează
- actualizat
- actualizări
- upgrade-ul
- încărcat
- utilizare
- folosind
- obișnuit
- VALIDA
- Valoros
- valoare
- Valori
- diverse
- verifica
- versiune
- foarte
- de
- Video
- Vizualizare
- viziune
- vrea
- a fost
- Ceas
- we
- web
- servicii web
- au fost
- cand
- oricând
- care
- în timp ce
- OMS
- cu
- fără
- Apartamente
- flux de lucru
- Grup de lucru
- de lucru
- fabrică
- ar
- scrie
- an
- ani
- tu
- Ta
- zephyrnet
- Zip