
Imagine de la Bing Image Creator
Analiza exploratorie a datelor (EDA) este sarcina cea mai importantă de efectuat la începutul fiecărui proiect de știință a datelor.
În esență, implică examinarea amănunțită și caracterizarea datelor dvs. pentru a le găsi subiacente Caracteristici, posibil anomalii, și ascuns modele și relaţii.
Această înțelegere a datelor dvs. este ceea ce va fi în cele din urmă ghidează-te prin următorii pași dintre dvs. pipeline de învățare automată, de la preprocesarea datelor până la construirea de modele și analiza rezultatelor.
Procesul EDA cuprinde în mod fundamental trei sarcini principale:
- Pasul 1: Prezentare generală a setului de date și statistici descriptive
- Pasul 2: Evaluarea și vizualizarea caracteristicilor, și
- Pasul 3: Evaluarea calității datelor
După cum probabil ați ghicit, fiecare dintre aceste sarcini poate implica o cantitate destul de cuprinzătoare de analize, care vă vor duce cu ușurință tăierea, tipărirea și trasarea cadrelor de date ale pandalor dvs. ca un nebun.
Cu excepția cazului în care alegeți unealta potrivită pentru muncă.
În acest articol, ne vom scufunda în fiecare pas al unui proces EDA eficient, și discutați de ce ar trebui să vă întoarceți ydata-profiling în ghișeul tău unic pentru a-l stăpâni.
La să demonstreze cele mai bune practici și să investigheze perspectivele, vom folosi Set de date privind veniturile recensământului adulților, disponibil gratuit pe Kaggle sau UCI Repository (Licență: CC0: Domeniu Public).
Când punem mâna pentru prima dată pe un set de date necunoscut, apare un gând automat care apare imediat: Cu ce lucrez?
Trebuie să avem o înțelegere profundă a datelor noastre pentru a le gestiona eficient în viitoarele sarcini de învățare automată
Ca regulă generală, în mod tradițional începem prin a caracteriza datele relativ la numărul de observații, numărul și tipuri de caracteristici, per total rata lipsă, și procentul de duplicat observații.
Cu unele manipulări panda și cu foaia corectă, am putea în cele din urmă să tipărim informațiile de mai sus cu câteva fragmente scurte de cod:
Prezentare generală a setului de date: set de date pentru recensământul adulților. Numărul de observații, caracteristici, tipuri de caracteristici, rânduri duplicate și valori lipsă. Fragment după autor.
Una peste alta, formatul de ieșire nu este ideal... Dacă ești familiarizat cu panda, vei cunoaște și standardul modus operandi de începere a unui proces EDA - df.describe():
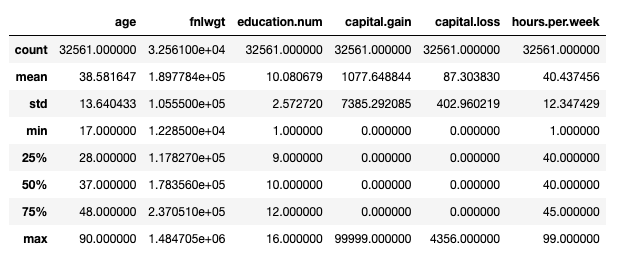
Set de date pentru adulți: statistici principale prezentate cu df.describe(). Imagine de autor.
Acest lucru, însă, ia în considerare doar caracteristici numerice. Am putea folosi un df.describe(include='object') pentru a imprima câteva informații suplimentare despre caracteristici categoriale (număr, unic, mod, frecvență), dar o simplă verificare a categoriilor existente ar implica ceva puțin mai detaliat:
Prezentare generală a setului de date: set de date pentru recensământul adulților. Imprimarea categoriilor existente și a frecvențelor respective pentru fiecare caracteristică categorială din date. Fragment după autor.
Cu toate acestea, putem face asta - și ghiciți ce, toate sarcinile ulterioare EDA! - într-o singură linie de cod, Folosind ydata-profiling:
Raportul de profilare al setului de date pentru recensământul adulților, folosind ydata-profiling. Fragment după autor.
Codul de mai sus generează un raport complet de profilare a datelor, pe care îl putem folosi pentru a muta în continuare procesul nostru EDA, fără a fi nevoie să mai scriem cod!
Vom parcurge diferitele secțiuni ale raportului în secțiunile următoare. În ceea ce privește caracteristicile generale ale datelor, toate informațiile pe care le căutam sunt incluse în Descriere secțiune:
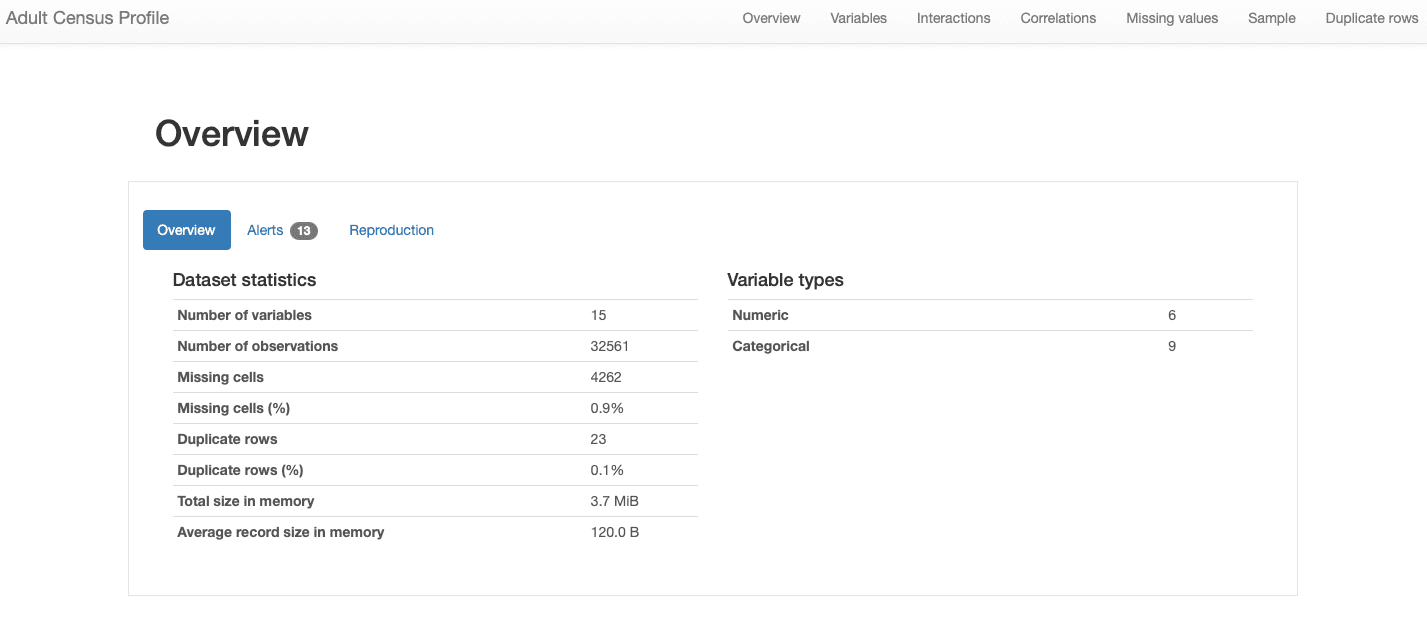
ydata-profiling: Raport de profilare a datelor — Prezentare generală a setului de date. Imagine de autor.
Putem vedea că setul nostru de date cuprinde 15 caracteristici și 32561 observații, cu 23 de înregistrări duplicat și o rată totală de lipsuri de 0.9%.
În plus, setul de date a fost identificat corect ca a set de date tabelar, și destul de eterogene, prezentându-le pe amândouă caracteristici numerice și categoriale. Pentru date din serii temporale, care are dependență de timp și prezintă diferite tipuri de modele, ydata-profiling ar încorpora alte statistici și analize din raport.
Putem inspecta în continuare date brute și înregistrări duplicate existente pentru a avea o înțelegere generală a caracteristicilor, înainte de a intra într-o analiză mai complexă:
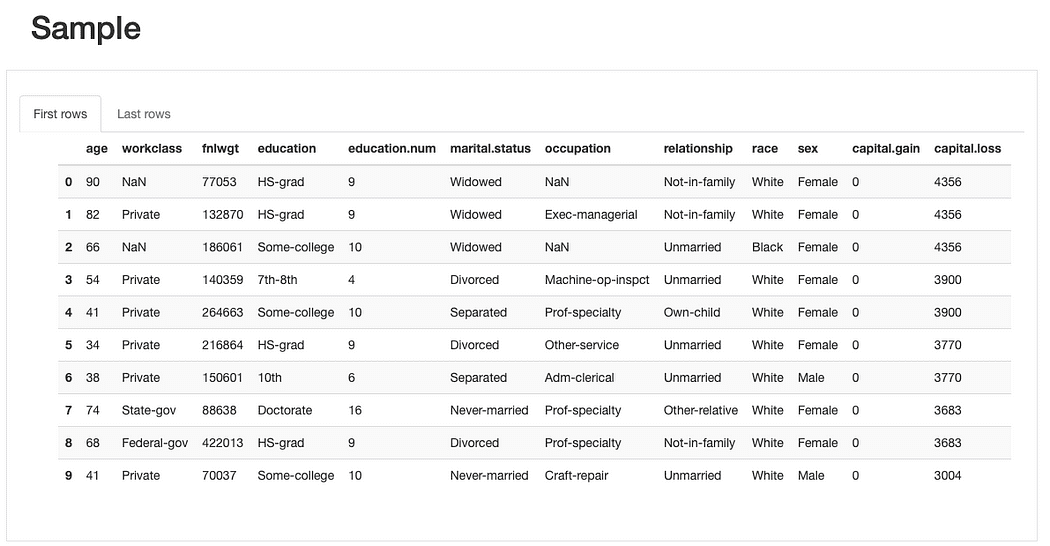
ydata-profiling: Raport de profilare a datelor — Exemplu de previzualizare. Imagine de autor.
Din scurtul exemplu de previzualizare din eșantionul de date, putem vedea imediat că, deși setul de date are un procent mic de date lipsă în general, unele caracteristici ar putea fi afectate de acesta mai mult decât altele. Putem identifica, de asemenea, un mai degrabă număr considerabil de categorii pentru unele caracteristici și caracteristici cu valoare 0 (sau cel puțin cu o cantitate semnificativă de 0).
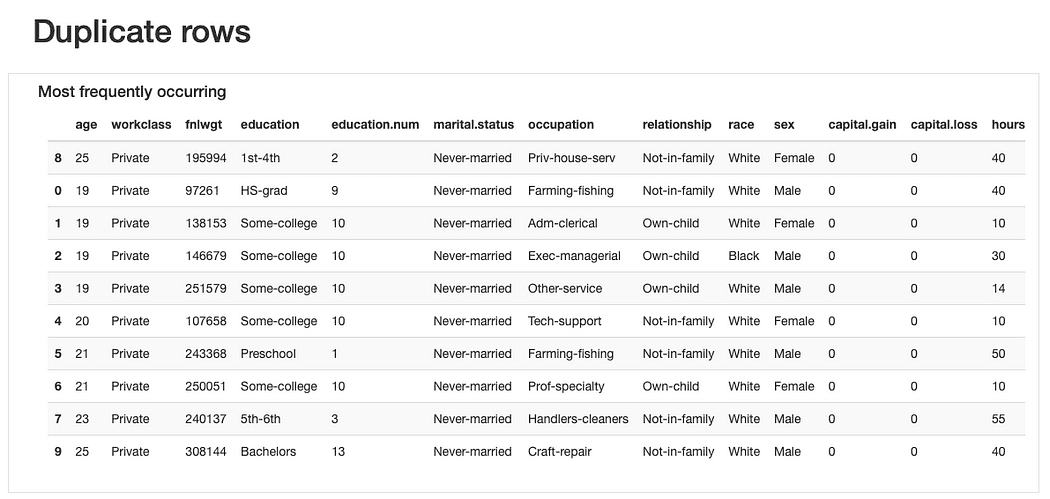
ydata-profiling: Raport de profilare a datelor — Previzualizare rânduri duplicate. Imagine de autor.
În ceea ce privește rândurile duplicate, nu ar fi ciudat să găsim observații „repetate”, având în vedere că majoritatea caracteristicilor reprezintă categorii în care mai multe persoane s-ar putea „încadra” simultan.
Totuși, poate că a „miros de date” ar putea fi că aceste observații împărtășesc același lucru age valori (ceea ce este plauzibil) și exact la fel fnlwgt ceea ce, având în vedere valorile prezentate, pare mai greu de crezut. Deci ar fi necesare analize suplimentare, dar ar trebui cel mai probabil să renunțe la aceste duplicate mai târziu.
În general, prezentarea generală a datelor ar putea fi o analiză simplă, dar una extrem de impactant, deoarece ne va ajuta să definim sarcinile viitoare din conducta noastră.
După ce aruncăm o privire asupra descriptorilor generali ai datelor, trebuie să facem acest lucru măriți funcțiile setului nostru de date, pentru a obține câteva informații despre proprietățile lor individuale — Analiza univariată - precum și interacțiunile și relațiile lor - Analiza multivariată.
Pe ambele sarcini se bazează foarte mult investigarea statisticilor și vizualizărilor adecvate, care trebuie să fie adaptate tipului de caracteristică la îndemână (de exemplu, numeric, categoric), si comportamentul căutăm să disecăm (de exemplu, interacțiuni, corelații).
Să aruncăm o privire la cele mai bune practici pentru fiecare sarcină.
Analiza univariată
Analizarea caracteristicilor individuale ale fiecărei caracteristici este crucială, deoarece ne va ajuta să decidem asupra lor relevanță pentru analiză si tipul de pregătire a datelor pot avea nevoie pentru a obține rezultate optime.
De exemplu, putem găsi valori care sunt extrem de în afara intervalului și se pot referi la incoerențe or valorile extreme. S-ar putea să avem nevoie standardiza numeric de date sau efectuați o codificare one-hot de categoric caracteristici, în funcție de numărul de categorii existente. Sau poate fi necesar să efectuăm pregătirea suplimentară a datelor pentru a gestiona caracteristicile numerice care sunt deplasat sau deformat, dacă algoritmul de învățare automată pe care intenționăm să-l folosim se așteaptă la o anumită distribuție (în mod normal gaussiană).
Prin urmare, cele mai bune practici necesită o investigare amănunțită a proprietăților individuale, cum ar fi statisticile descriptive și distribuția datelor.
Acestea vor evidenția necesitatea unor sarcini ulterioare de eliminare a valorii aberante, standardizare, codificare a etichetelor, imputarea datelor, creșterea datelor și alte tipuri de preprocesare.
Să investigăm race și capital.gain in detaliu. Ce putem observa imediat?
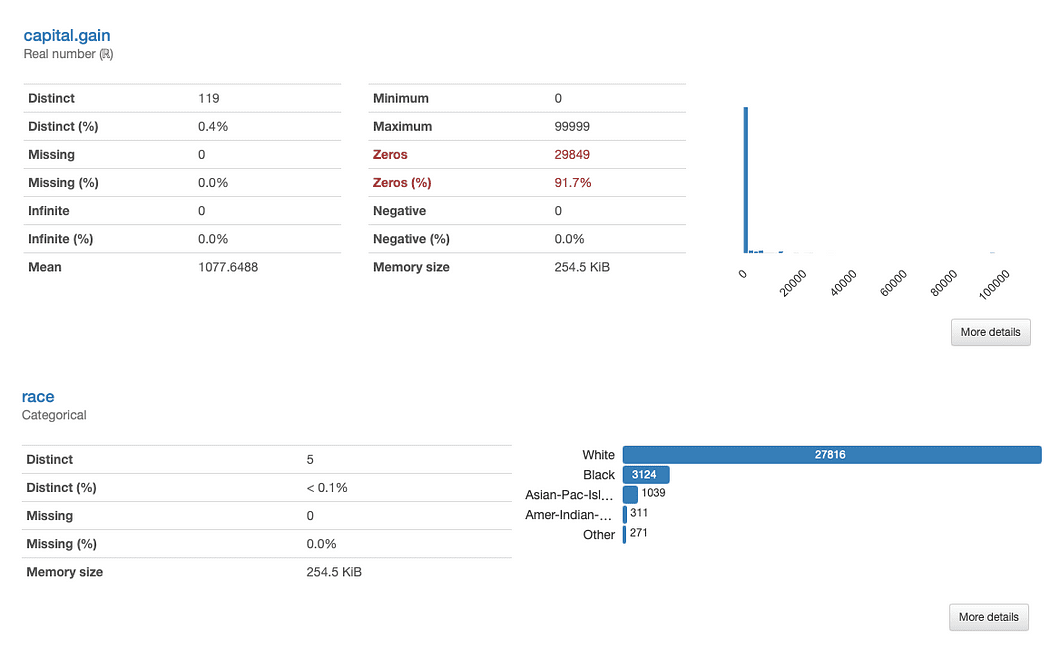
ydata-profiling: Raport de profilare (cursă și câștig.capital). Imagine de autor.
Evaluarea câștig de capital este simplu:
Având în vedere distribuția datelor, ne-am putea întreba dacă caracteristica adaugă vreo valoare analizei noastre, deoarece 91.7% dintre valori sunt „0”.
analiza rasă este putin mai complex:
Există o subreprezentare clară a altor rase decât White. Acest lucru aduce în minte două probleme principale:
- Una este tendința generală a algoritmilor de învățare automată trece cu vederea conceptele mai puțin reprezentate, cunoscut sub numele de problema de mici disjuncturi, care duce la o performanță redusă de învățare;
- Cealaltă este oarecum derivată din această problemă: întrucât avem de-a face cu o trăsătură sensibilă, această „tendință de ignorare” poate avea consecințe care se referă direct la părtinire și cinste probleme de. Ceva pe care cu siguranță nu vrem să ne strecuram în modelele noastre.
Ținând cont de asta, poate că ar trebui luați în considerare efectuarea creșterii datelor conditionat de categoriile subreprezentate, precum si considerand metrici conștiente de corectitudine pentru evaluarea modelului, pentru a verifica eventualele discrepanțe de performanță care se referă la race valori.
Vom detalia în continuare alte caracteristici ale datelor care trebuie abordate atunci când discutăm despre cele mai bune practici privind calitatea datelor (Pasul 3). Acest exemplu arată doar câte informații putem obține doar evaluând fiecare caracteristică individuală proprietăţi.
În cele din urmă, rețineți că, așa cum sa menționat anterior, diferite tipuri de caracteristici necesită statistici și strategii de vizualizare diferite:
- Caracteristici numerice cel mai adesea cuprind informații despre medie, abatere standard, asimetrie, curtoză și alte statistici cuantile și sunt cel mai bine reprezentate folosind diagrame histograme;
- Caracteristici categorice sunt de obicei descrise folosind tabelele de mod, mediană și frecvență și reprezentate folosind diagrame cu bare pentru analiza categoriei.
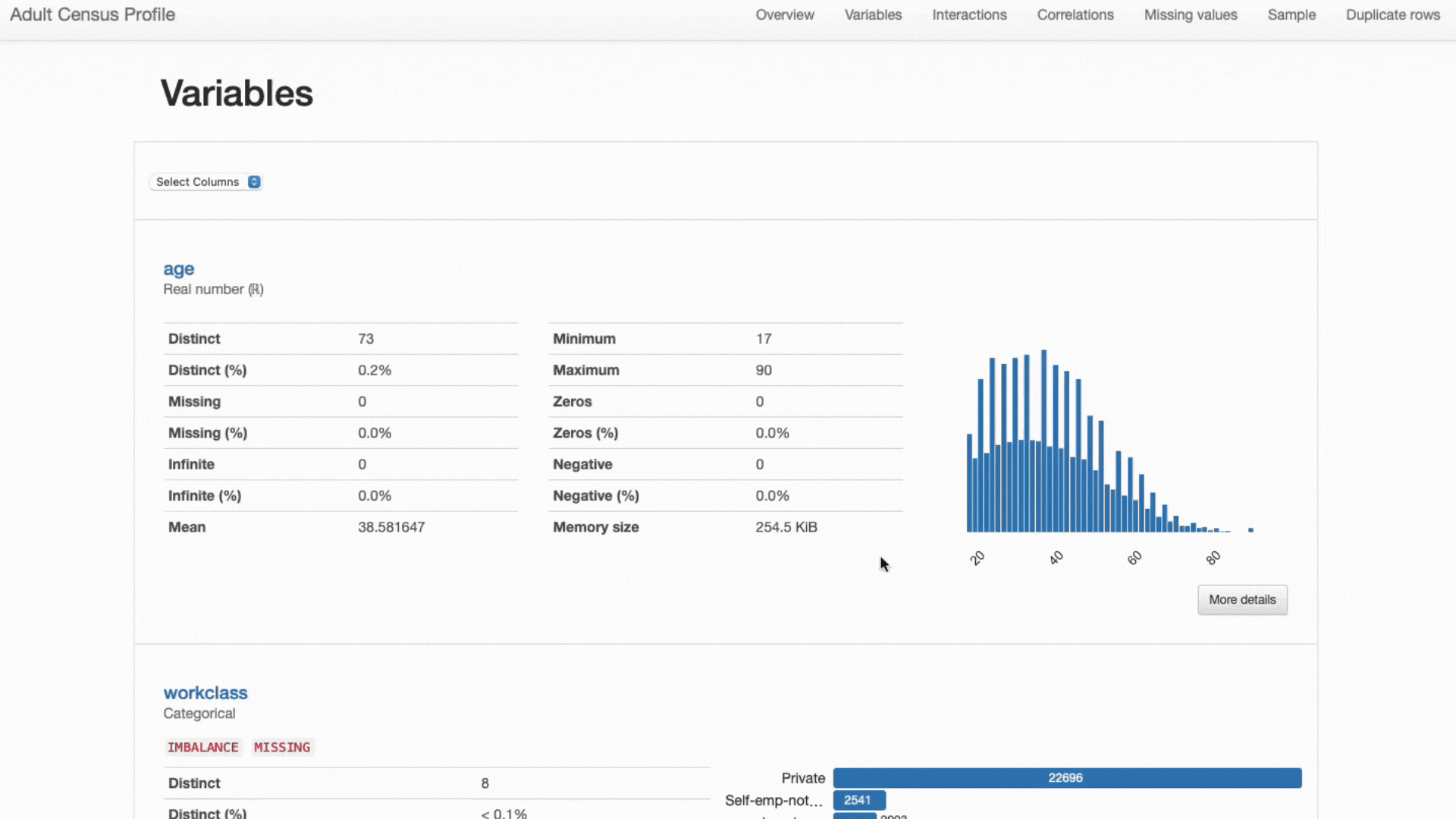
ydata-profiling: Raport de profilare. Statisticile și vizualizările prezentate sunt ajustate la fiecare tip de caracteristică. Screencast de autor.
O astfel de analiză detaliată ar fi greoaie de realizat cu manipularea generală a pandalor, dar din fericire ydata-profiling are toate aceste funcționalități încorporate în ProfileReport pentru comoditatea noastră: nu au fost adăugate linii suplimentare de cod la fragment!
Analiza multivariată
Pentru analiza multivariată, cele mai bune practici se concentrează în principal pe două strategii: analiza interacţiuni între caracteristici și analiza lor corelații.
Analizarea interacțiunilor
Interacțiunile ne permit explorați vizual modul în care se comportă fiecare pereche de caracteristici, adică modul în care valorile unei caracteristici se raportează la valorile celeilalte.
De exemplu, ei pot expune pozitiv or negativ relații, în funcție de faptul că creșterea valorilor cuiva este asociată cu o creștere sau, respectiv, cu o scădere a valorilor celuilalt.
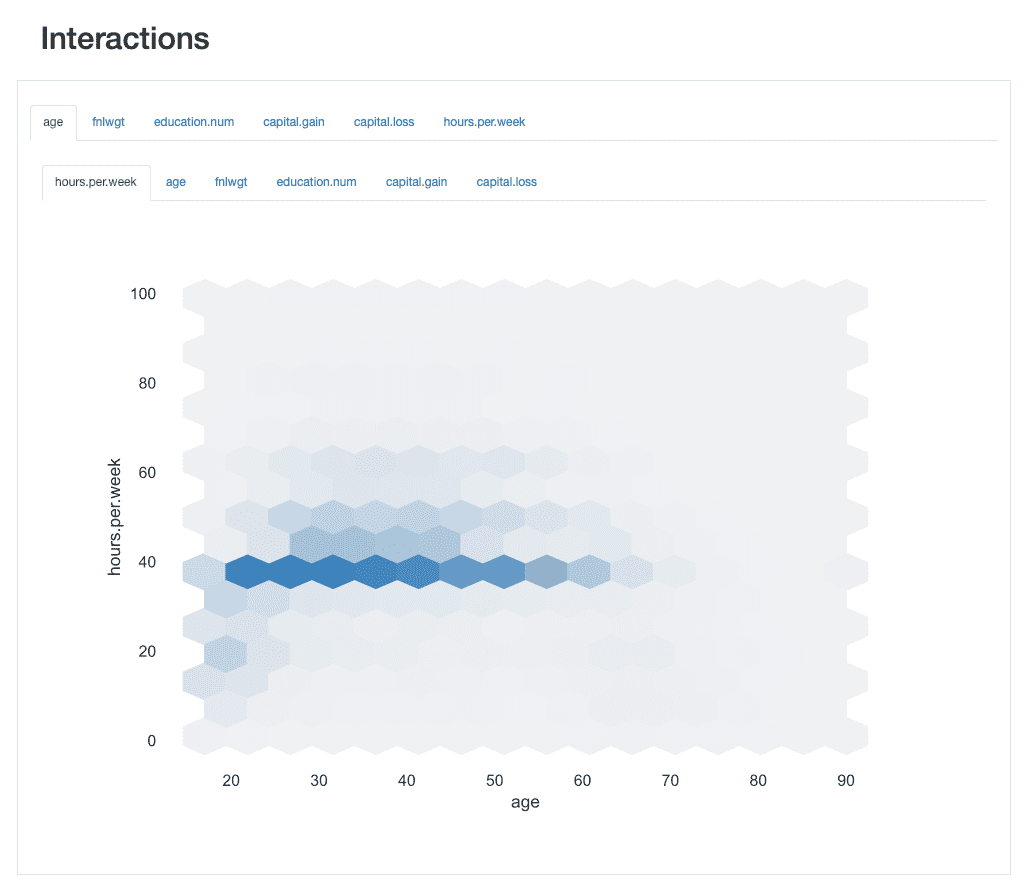
ydata-profiling: Raport de profilare — Interacțiuni. Imagine de autor.
Luând interacțiunea dintre age și hours.per.weekde exemplu, putem observa că marea majoritate a forței de muncă lucrează un standard de 40 de ore. Cu toate acestea, există unele „albine ocupate” care lucrează peste aceasta (până la 60 sau chiar 65 de ore) între 30 și 45 de ani. Oamenii în vârstă de 20 de ani sunt mai puțin susceptibili de a suprasolicita și pot avea un program de lucru mai ușor în unele cazuri. săptămâni.
Analizarea corelațiilor
Similar interacțiunilor, corelațiile ne lasă analiza relația între caracteristici. Corelațiile, însă, îi „pun valoare”, astfel încât ne este mai ușor să determinăm „puterea” acelei relații.
Această „putere” este măsurată prin coeficienți de corelație și pot fi analizate fie numeric (de exemplu, inspectarea a matricea de corelare) sau cu a Heatmap, care folosește culoarea și umbrirea pentru a evidenția vizual modele interesante:
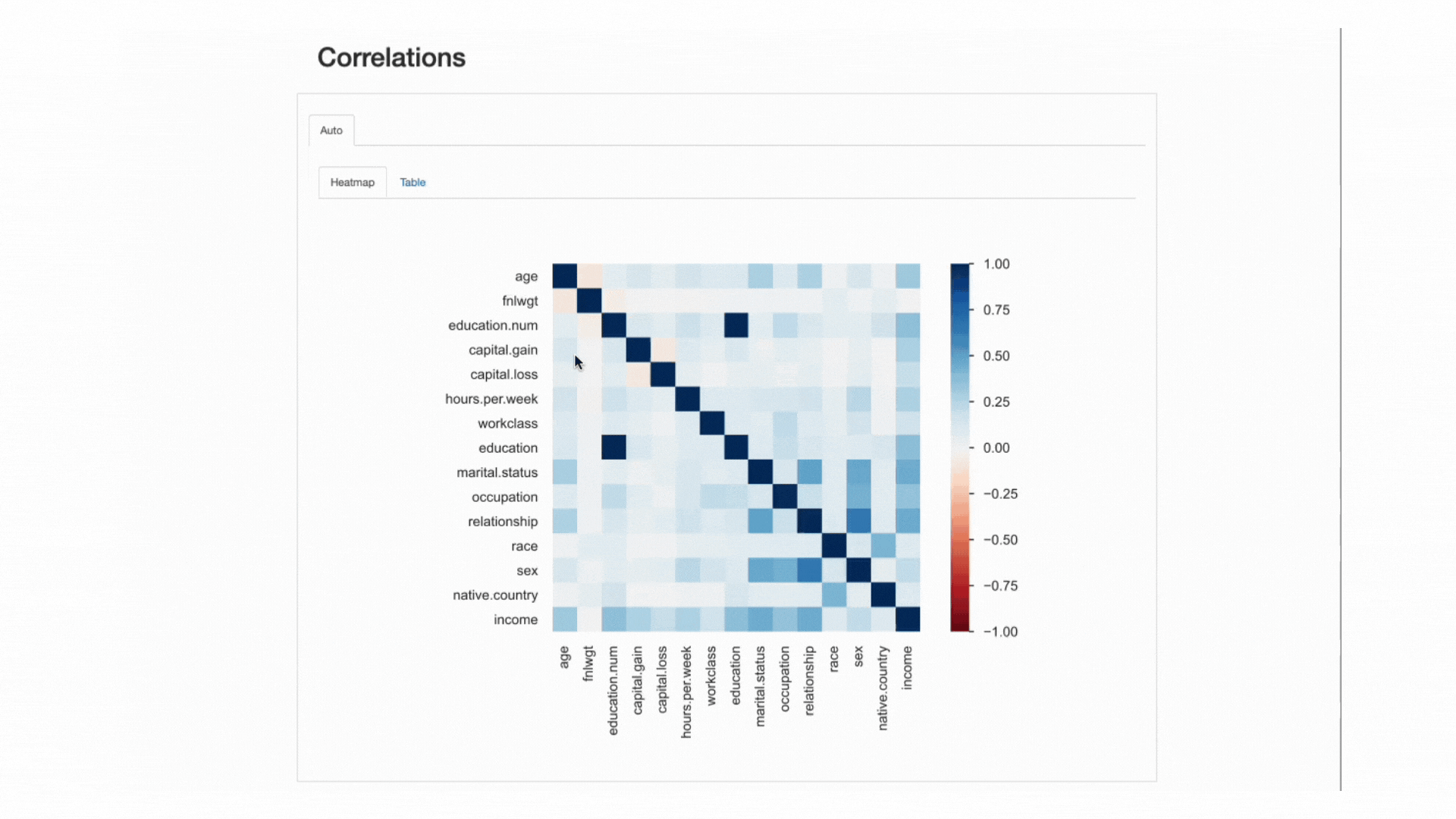
ydata-profiling: Raport de profilare — Hartă termică și matrice de corelație. Screencast de autor.
În ceea ce privește setul nostru de date, observați cum este corelația dintre education și education.num iese în evidență. De fapt, detin aceleasi informatii, și education.num este doar un binning al education valori.
Un alt model care atrage atenția este corelația dintre sex și relationship deși din nou nu foarte informativ: privind valorile ambelor caracteristici, ne-am da seama că aceste caracteristici sunt cel mai probabil legate deoarece male și female va corespunde husband și wife, respectiv.
Acest tip de redundanțe pot fi verificate pentru a vedea dacă putem elimina unele dintre aceste caracteristici din analiză (marital.status este legat și de relationship și sex; native.country și race de exemplu, printre altele).
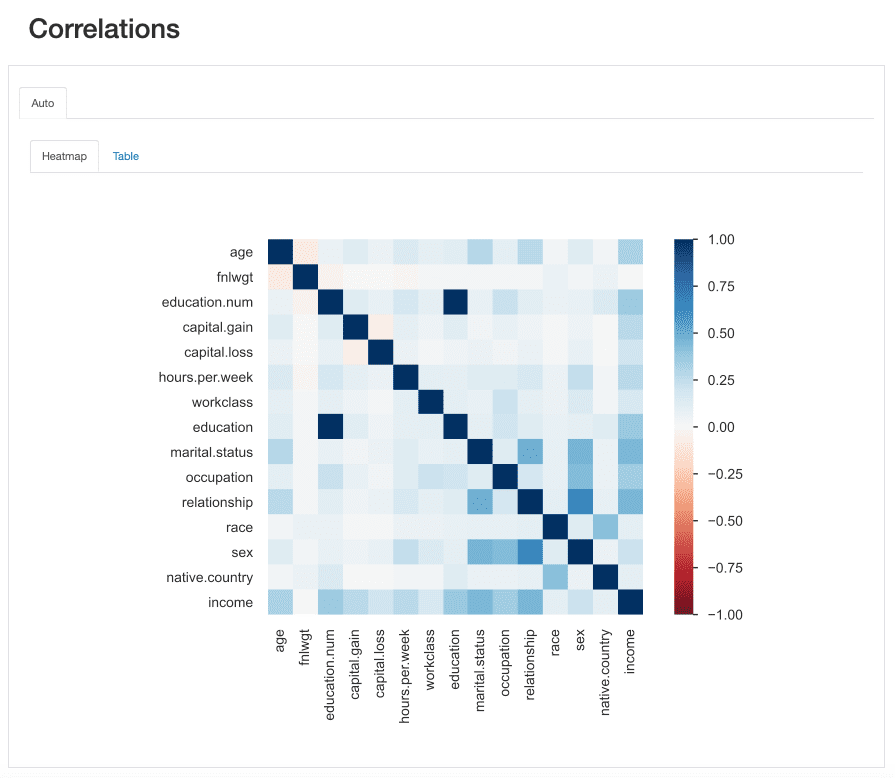
ydata-profiling: Raport de profilare — Corelații. Imagine de autor.
Cu toate acestea, există și alte corelații care ies în evidență și ar putea fi interesante în scopul analizei noastre.
De exemplu, corelația dintresex și occupation, Sau sex și hours.per.week.
În sfârșit, corelațiile dintre income iar caracteristicile rămase sunt cu adevărat informative, mai ales în cazul în care încercăm să identificăm o problemă de clasificare. Știind care sunt cele mai corelate caracteristicile clasei noastre țintă ne ajută să identificăm cel mai discriminatoriu caracteristici și, de asemenea, găsiți posibile scurgeri de date care ar putea afecta modelul nostru.
Din harta termică, se pare că marital.status or relationship sunt printre cei mai importanți predictori, în timp ce fnlwgt de exemplu, nu pare să aibă un impact mare asupra rezultatului.
Similar descriptorilor și vizualizărilor de date, interacțiunile și corelațiile trebuie să se ocupe de tipurile de caracteristici disponibile.
Cu alte cuvinte, diferite combinații vor fi măsurate cu diferiți coeficienți de corelație. În mod implicit, ydata-profiling rulează corelații pe auto, ceea ce înseamnă că:
- Numeric versus numeric corelațiile se măsoară folosind rangul de Spearman coeficient de corelație;
- Categoric versus categoric corelațiile se măsoară folosind V-ul lui Cramer;
- Numeric versus categorial corelațiile folosesc și V-ul lui Cramer, unde caracteristica numerică este mai întâi discretizată;
Și dacă vrei să verifici alți coeficienți de corelație (de ex., Pearson, Kendall, Phi) puteți cu ușurință configurați parametrii raportului.
Pe măsură ce navigăm către a paradigma centrată pe date de dezvoltare AI, fiind în vârful posibili factori de complicare care apar în datele noastre este esențială.
Cu „factori complicanți”, ne referim la Erori care poate avea loc în timpul colectării datelor de prelucrare, sau caracteristicile intrinseci ale datelor care sunt pur și simplu o reflectare a natură a datelor.
Acestea includ dispărut date, dezechilibrat date, constant valori, duplicate, foarte corelat or redundant caracteristici, zgomotos date, printre altele.
Probleme de calitate a datelor: erori și caracteristici intrinseci a datelor. Imagine de autor.
Găsirea acestor probleme de calitate a datelor la începutul unui proiect (și monitorizarea lor continuă în timpul dezvoltării) este esențială.
Dacă nu sunt identificate și abordate înainte de etapa de construire a modelului, ele pot pune în pericol întreaga conductă ML și analizele și concluziile ulterioare care pot decurge din aceasta.
Fără un proces automatizat, capacitatea de a identifica și aborda aceste probleme ar fi lăsată în întregime la experiența și expertiza personală a persoanei care efectuează analiza EDA, ceea ce este evident că nu este ideal. În plus, ce greutate să ai pe umeri, mai ales având în vedere seturile de date cu dimensiuni mari. Sosire alertă de coșmar!
Aceasta este una dintre cele mai apreciate caracteristici ale ydata-profiling, generarea automată de alerte de calitate a datelor:
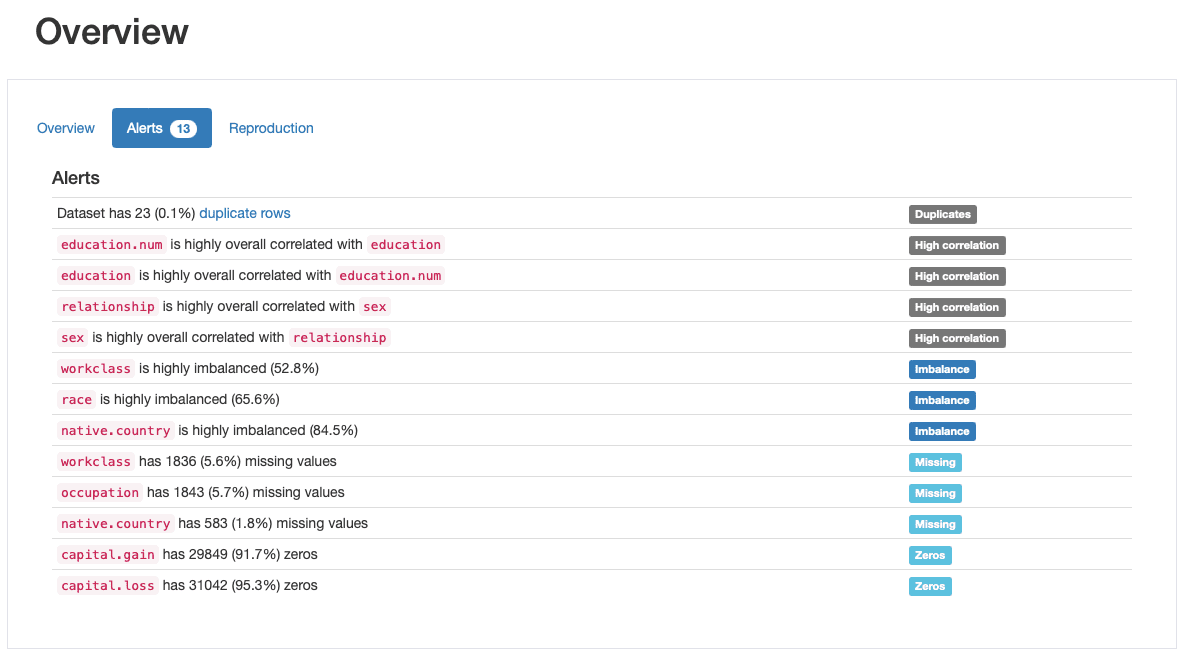
ydata-profiling: Raport de profilare — Alerte privind calitatea datelor. Imagine de autor.
Profilul generează cel puțin 5 tipuri diferite de probleme de calitate a datelor, și anume duplicates, high correlation, imbalance, missing, și zeros.
Într-adevăr, identificasem deja unele dintre acestea înainte, pe măsură ce am trecut prin pasul 2: race este o caracteristică foarte dezechilibrată și capital.gain este populat predominant de 0. Am văzut, de asemenea, strânsa corelație între education și education.num, și relationship și sex.
Analizarea modelelor de date lipsă
Printre domeniul de aplicare cuprinzător al alertelor luate în considerare, ydata-profiling este deosebit de util în analiza modelelor de date lipsă.
Deoarece lipsa datelor este o problemă foarte comună în domeniile din lumea reală și poate compromite în totalitate aplicarea anumitor clasificatori sau poate modifica grav predicțiile acestora, o altă bună practică este analizarea cu atenție a datelor lipsă procentul și comportamentul pe care funcțiile noastre le pot afișa:
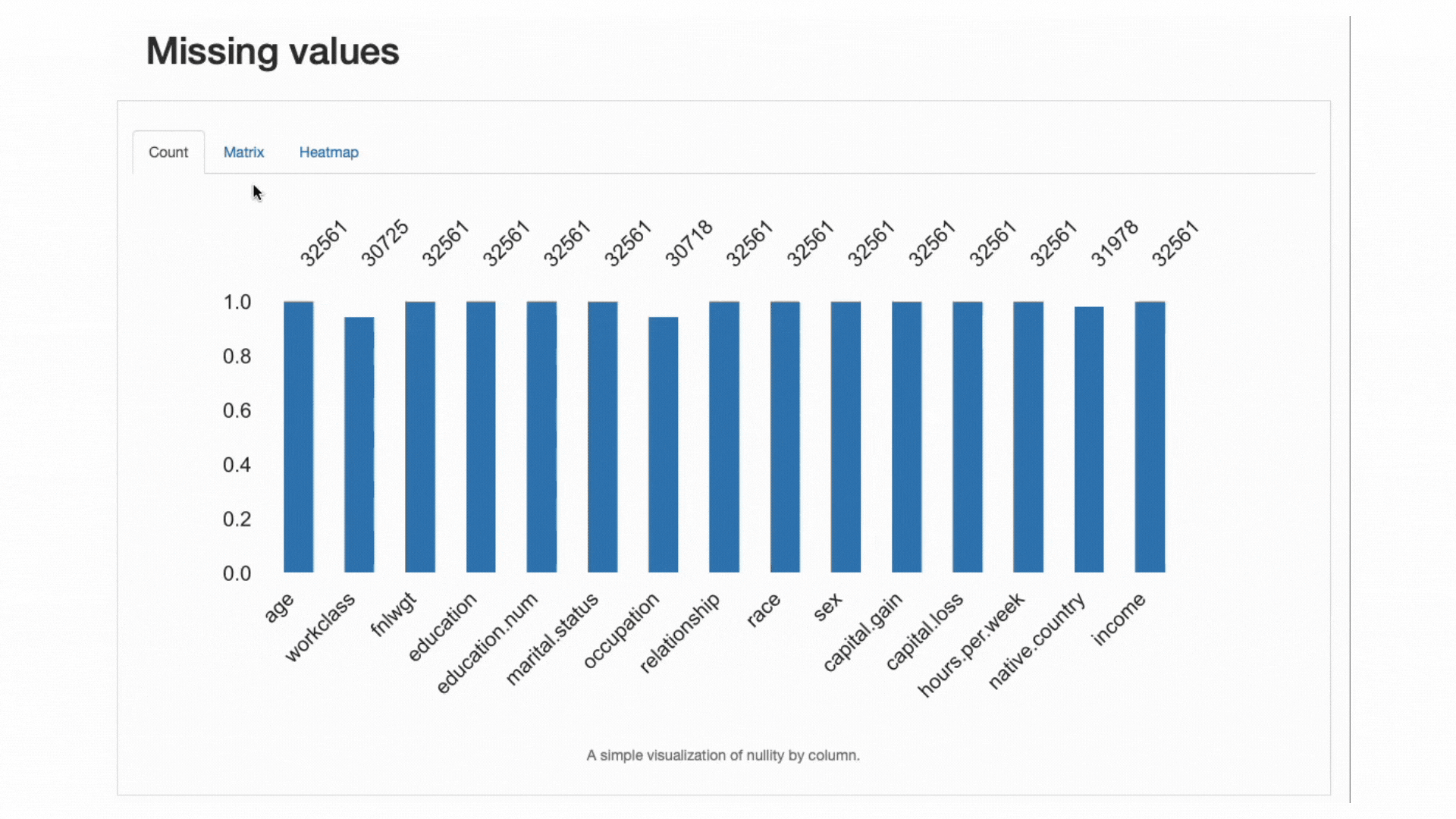
ydata-profiling: Raport de profilare — Analizarea valorilor lipsă. Screencast de autor.
Din secțiunea de alerte de date, știam deja asta workclass, occupation, și native.country a avut observații absente. Harta termică ne spune în continuare că există o relație directă cu modelul lipsă in occupation și workclass: când lipsește o valoare într-o caracteristică, va lipsi și cealaltă.
Perspectivă cheie: Profilarea datelor depășește EDA!
Până acum, am discutat despre sarcinile care compun un proces amănunțit EDA și despre cum evaluarea aspectelor și caracteristicilor calității datelor - un proces la care ne putem referi ca Data Profiling - este cu siguranță o bună practică.
Cu toate acestea, este important să clarificați acest lucru profilarea datelor depășește EDA. Întrucât definim în general EDA ca pasul exploratoriu, interactiv înainte de a dezvolta orice tip de conductă de date, profilarea datelor este un proces iterativ care ar trebui să apară la fiecare pas de preprocesare a datelor și construirea de modele.
Un EDA eficient pune bazele unui pipeline de învățare automată de succes.
Este ca și cum rulați un diagnostic asupra datelor dvs., învățați tot ce trebuie să știți despre ceea ce implică ele - ei proprietăţi, relaţii, probleme de — astfel încât să le puteți aborda ulterior în cel mai bun mod posibil.
Este și începutul fazei noastre de inspirație: de la EDA încep să apară întrebări și ipoteze, iar analizele sunt planificate pentru a le valida sau respinge pe parcurs.
Pe parcursul articolului, am acoperit cei 3 pași principali care vă vor ghida printr-o EDA eficientă, și a discutat despre impactul de a avea un instrument de top - ydata-profiling — să ne îndrepte în direcția corectă și economisiți-ne o cantitate enormă de timp și povara mentală.
Sper că acest ghid vă va ajuta să stăpâniți arta „de a juca detectiv de date” și, ca întotdeauna, feedback-ul, întrebările și sugestiile sunt foarte apreciate. Spune-mi despre ce alte subiecte aș vrea să scriu, sau mai bine zis, vino să mă cunoști la Comunitatea AI centrată pe date si hai sa colaboram!
Miriam Santos concentrați-vă pe educarea comunităților Data Science și Machine Learning cu privire la modul de a trece de la date brute, murdare, „rele” sau imperfecte la date inteligente, inteligente, de înaltă calitate, permițând clasificatorilor de învățare automată să tragă inferențe precise și de încredere în mai multe industrii (Fintech , Healthcare & Pharma, Telecomm și Retail).
Original. Repostat cu permisiunea.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- EVM Finance. Interfață unificată pentru finanțare descentralizată. Accesați Aici.
- Grupul Quantum Media. IR/PR amplificat. Accesați Aici.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=a-data-scientists-essential-guide-to-exploratory-data-analysis
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 30
- 40
- 60
- 65
- 91
- a
- capacitate
- Despre Noi
- mai sus
- absent
- Cont
- precis
- Obține
- peste
- adăugat
- Suplimentar
- informatii suplimentare
- adresa
- Adaugă
- Ajustat
- Adult
- afecta
- din nou
- Evul
- AI
- Alerte
- Algoritmul
- algoritmi
- TOATE
- de-a lungul
- deja
- de asemenea
- Cu toate ca
- întru totul
- mereu
- am
- printre
- între
- sumă
- an
- analiză
- analiza
- analizate
- analiza
- și
- Orice
- aplicație
- SUNT
- Artă
- articol
- AS
- evaluarea
- evaluare
- asociate
- At
- asista la
- autor
- Automata
- Automat
- disponibil
- departe
- Rău
- bar
- BE
- fost
- înainte
- Început
- fiind
- Crede
- CEL MAI BUN
- Cele mai bune practici
- Mai bine
- între
- Dincolo de
- părtinire
- Bing
- atât
- Aduce
- Clădire
- construit
- povară
- dar
- by
- apel
- CAN
- capital
- cu grijă
- transporta
- caz
- categorii
- Categorii
- recensământ
- Caracteristici
- verifica
- verificat
- clasă
- clasificare
- clar
- cod
- colectare
- culoare
- combinaţii
- cum
- Comun
- Comunități
- Completă
- complex
- cuprinzător
- cuprinde
- compromis
- preocupările
- Conduce
- efectuarea
- Consecințele
- luate în considerare
- luand in considerare
- continuu
- comoditate
- Corelație
- coeficient de corelație
- ar putea
- critic
- crucial
- de date
- analiza datelor
- Pregătirea datelor
- calitatea datelor
- știința datelor
- seturi de date
- abuzive
- decide
- scădea
- adânc
- Mod implicit
- categoric
- Dependenţă
- În funcție
- derivat
- descris
- detaliu
- detaliat
- Determina
- în curs de dezvoltare
- Dezvoltare
- deviere
- diagnostic
- diferit
- direcționa
- direcţie
- direct
- discuta
- discutat
- discutarea
- Afişa
- distribuire
- do
- face
- domenii
- Dont
- a desena
- Picătură
- în timpul
- e
- fiecare
- mai ușor
- cu ușurință
- educarea
- Eficace
- eficient
- eficient
- oricare
- permițând
- în întregime
- Erori
- mai ales
- esenţă
- esenţial
- Eter (ETH)
- Chiar
- în cele din urmă
- Fiecare
- tot
- examinator
- exemplu
- existent
- se așteaptă
- experienţă
- expertiză
- Analiza datelor exploratorii
- explora
- suplimentar
- extrem
- ochi
- fapt
- familiar
- departe
- Caracteristică
- DESCRIERE
- feedback-ul
- Găsi
- FinTech
- First
- Concentra
- următor
- Pentru
- Forţarea
- format
- Fundație
- Frecvență
- din
- funcționalitate
- fundamental
- fundamental
- mai mult
- viitor
- Câştig
- General
- în general
- generează
- generaţie
- obține
- gif
- dat
- Go
- Merge
- merge
- mare
- ghicit
- ghida
- HAD
- mână
- manipula
- mâini
- Avea
- având în
- de asistență medicală
- puternic
- ajutor
- util
- ajută
- de înaltă calitate
- Evidențiați
- extrem de
- deţine
- speranţă
- ORE
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- i
- ideal
- identificat
- identifica
- if
- imagine
- imediat
- Impactul
- important
- in
- inclus
- Venituri
- Intrare
- Crește
- individ
- industrii
- informații
- informativ
- înţelegere
- perspective
- Inspiraţie
- instanță
- Inteligent
- intenţionează
- interacţiune
- interacţiuni
- interactiv
- interesant
- în
- intrinsec
- investiga
- investigaţie
- implica
- problema
- probleme de
- IT
- ESTE
- Periclita
- Loc de munca
- jpg
- doar
- KDnuggets
- A lui Kendall
- Cunoaște
- Cunoaștere
- cunoscut
- aplatizării
- Etichetă
- mai tarziu
- Lays
- Conduce
- învăţare
- cel mai puțin
- stânga
- mai puțin
- Licență
- ușoară
- ca
- Probabil
- Linie
- linii
- mic
- Uite
- cautati
- Jos
- maşină
- masina de învățare
- Principal
- mai ales
- Majoritate
- face
- Manipulare
- Hartă
- maestru
- Matrice
- Mai..
- me
- însemna
- mijloace
- măsurat
- Întâlni
- mental
- menționat
- Metrici
- ar putea
- minte
- dispărut
- ML
- mod
- model
- Modele
- Monitorizarea
- mai mult
- cele mai multe
- muta
- mult
- Navigaţi
- Nevoie
- Nu.
- în mod normal
- Înștiințare..
- număr
- obiect
- evident
- avea loc
- of
- de multe ori
- on
- ONE
- afară
- optimă
- or
- comandă
- Altele
- Altele
- al nostru
- afară
- Rezultat
- producție
- global
- Prezentare generală
- pereche
- panda
- special
- trecut
- Model
- modele
- oameni
- procent
- efectua
- performanță
- efectuarea
- poate
- permisiune
- persoană
- personal
- Pharma
- fază
- alege
- conducte
- planificat
- Plato
- Informații despre date Platon
- PlatoData
- plauzibil
- Punct
- pops
- populat
- posibil
- practică
- practicile
- Predictii
- predominant
- pregătire
- prezentat
- cadouri
- Anunţ
- în prealabil
- tipărire
- anterior
- Problemă
- proces
- prelucrare
- Profil
- profilare
- proiect
- proprietăţi
- public
- scop
- calitate
- întrebare
- Întrebări
- Rasă
- gamă
- rată
- mai degraba
- Crud
- lumea reală
- realiza
- înregistrări
- Redus
- reflecţie
- cu privire la
- legate de
- relaţie
- Relaţii
- relativ
- de încredere
- se bazează
- rămas
- îndepărtare
- scoate
- raportează
- depozit
- reprezenta
- reprezentate
- necesita
- necesar
- respectiv
- respectiv
- REZULTATE
- cu amănuntul
- dreapta
- Regula
- funcţionare
- acelaşi
- programa
- Ştiinţă
- domeniu
- Secțiune
- secțiuni
- vedea
- părea
- pare
- văzut
- sensibil
- câteva
- strict
- Distribuie
- Magazin
- Pantaloni scurți
- să
- Arăta
- semnificativ
- simplu
- pur şi simplu
- simultan
- singur
- inteligent
- So
- unele
- ceva
- oarecum
- Loc
- Etapă
- stand
- standard
- Standuri
- Începe
- Pornire
- statistică
- Pas
- paşi
- simplu
- strategii
- ulterior
- de succes
- astfel de
- Lua
- Ţintă
- Sarcină
- sarcini
- spune
- decât
- acea
- informațiile
- lor
- Lor
- Acolo.
- prin urmare
- Acestea
- ei
- acest
- complet
- gândit
- trei
- Prin
- timp
- la
- instrument
- top
- subiecte
- față de
- tradiţional
- extraordinar
- cu adevărat
- Două
- tip
- Tipuri
- subreprezentat
- înţelegere
- unic
- necunoscut
- până la
- viitoare
- us
- utilizare
- utilizări
- folosind
- obișnuit
- VALIDA
- valoare
- Valori
- diverse
- Impotriva
- foarte
- vizualizare
- vrea
- Cale..
- we
- săptămâni
- greutate
- BINE
- a mers
- au fost
- Ce
- cand
- dacă
- care
- întreg
- de ce
- Wikipedia
- voi
- cu
- fără
- cuvinte
- Apartamente
- de lucru
- fabrică
- ar
- scrie
- încă
- tu
- Ta
- zephyrnet
- zoom






