In 2021 e 2020, falamos sobre os novos recursos em Amazon RedShift que tornam mais fácil, rápido e econômico analisar todos os seus dados e encontrar informações valiosas e poderosas. Em 2022, temos o prazer de informar que a equipe do Amazon Redshift trabalhou arduamente. Trabalhamos para trás a partir dos requisitos do cliente e anunciamos vários novos recursos para tornar mais fácil, rápido e econômico analisar todos os seus dados. Esta postagem aborda alguns desses novos recursos.
Na AWS, para dados e análises, nossa estratégia é dar a você uma arquitetura de dados moderna que ajuda você a se livrar dos silos de dados; ter dados, análises, aprendizado de máquina (ML) e serviços de inteligência artificial criados especificamente para usar a ferramenta certa para o trabalho certo; e ter serviços abertos, controlados, seguros e totalmente gerenciados para tornar a análise disponível para todos. Dentro da arquitetura de dados moderna da AWS, o Amazon Redshift como data warehouse na nuvem continua sendo um componente chave, permitindo que você execute análises complexas de SQL em escala e desempenho de terabytes a petabytes de dados estruturados e não estruturados e disponibilize amplamente os insights por meio de inteligência de negócios popular ( BI) e ferramentas de análise. Continuamos a trabalhar de acordo com os requisitos dos clientes e, em 2022, lançamos mais de 40 recursos no Amazon Redshift para ajudar os clientes com seus principais casos de uso de armazenamento de dados, incluindo:
- Análise de autoatendimento
- Fácil ingestão de dados
- Compartilhamento de dados e colaboração
- Ciência de dados e aprendizado de máquina
- Análise segura e confiável
- Melhor análise de desempenho de preço
Vamos nos aprofundar e discutir os novos recursos do Amazon Redshift nessas áreas.
Análise de autoatendimento
Os clientes continuam a nos dizer que dados e análises estão se tornando onipresentes e todos em suas organizações precisam de análises. nós anunciamos Sem servidor Amazon Redshift (em versão prévia) em 2021 para facilitar a execução e dimensionamento de análises em segundos, sem a necessidade de provisionar e gerenciar a infraestrutura de data warehouse. Em julho de 2022, anunciamos o disponibilidade geral do Redshift Serverless, e desde então milhares de clientes, incluindo Peloton, Broadridge Financials e NextGen Healthcare, o usaram para analisar seus dados de maneira rápida e fácil. O Amazon Redshift Serverless provisiona automaticamente e dimensiona de forma inteligente a capacidade do data warehouse para oferecer alto desempenho para todas as suas análises, e você paga apenas pela computação usada durante as cargas de trabalho por segundo. Desde o GA, adicionamos recursos como marcação de recursos, monitoramento simplificado e disponibilidade em regiões adicionais da AWS para simplificar ainda mais o faturamento e expandir o alcance em mais regiões em todo o mundo.
Em 2021, lançamos o Amazon Redshift Query Editor V2, uma ferramenta gratuita baseada na Web para analistas de dados, cientistas de dados e desenvolvedores explorarem, analisarem e colaborarem com dados em data warehouses e data lakes do Amazon Redshift. Em 2022, o Query Editor V2 recebeu aprimoramentos adicionais, como suporte para notebook para colaboração aprimorada para criar, organizar e anotar consultas; acesso do usuário através credenciais do provedor de identidade (IdP) para logon único; e a capacidade de executar várias consultas simultaneamente para melhorar a produtividade do desenvolvedor.
Autonomics é outra área em que estamos trabalhando ativamente para usar otimizações baseadas em ML e oferecer aos clientes um data warehouse de autoaprendizagem e autootimização. Em 2022, anunciamos a disponibilidade geral de Visualizações Materializadas Automatizadas (AutoMVs) para melhorar o desempenho das consultas (reduzir o tempo de execução total) sem nenhum esforço do usuário, criando e mantendo visualizações materializadas automaticamente. Os AutoMVs, combinados com atualização automática, atualização incremental e regravação automática de consulta para visualizações materializadas, tornaram as visualizações materializadas livres de manutenção, proporcionando desempenho mais rápido automaticamente. Além disso, o otimização automática de mesa (ATO) para otimização de esquema e gerenciamento automático de carga de trabalho (auto WLM) capacidade para otimização de carga de trabalho obteve melhorias adicionais para melhor desempenho de consulta.
Fácil ingestão de dados
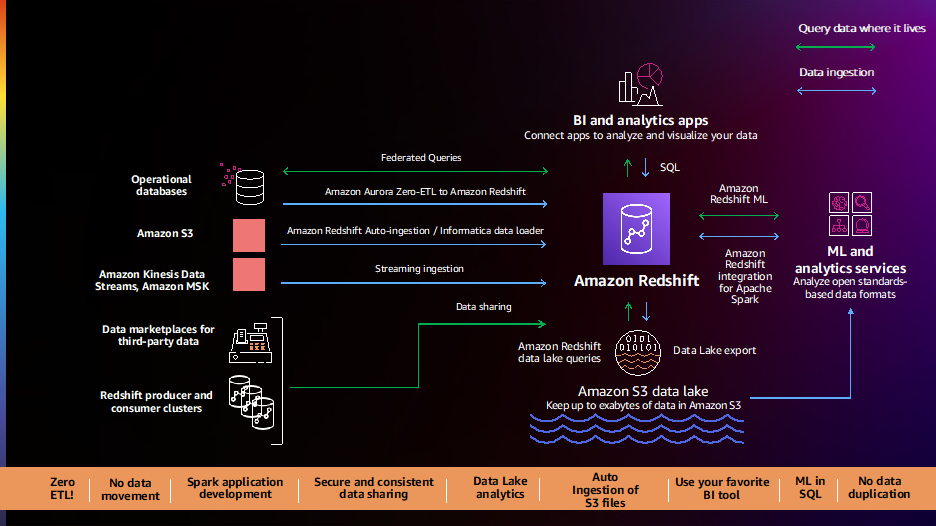
Os clientes nos dizem que têm seus dados distribuídos em várias fontes de dados, como bancos de dados transacionais, data warehouses, data lakes e sistemas de big data. Eles querem flexibilidade para integrar esses dados com pipelines de dados sem código/baixo código, zero ETL ou analisar esses dados no local sem movê-los. Os clientes nos dizem que seus pipelines de dados atuais são complexos, manuais, rígidos e lentos, resultando em visualizações de dados incompletas, inconsistentes e obsoletas, limitando os insights. Os clientes nos pediram um melhor caminho a seguir e temos o prazer de anunciar uma série de novos recursos para simplificar e automatizar os pipelines de dados.
Integração zero-ETL do Amazon Aurora com o Amazon Redshift (visualização) permite que você execute análises e ML quase em tempo real em petabytes de dados transacionais. Ele oferece uma solução sem código para criar dados transacionais de vários Aurora Amazônica bancos de dados disponíveis em data warehouses do Amazon Redshift segundos após serem gravados no Aurora, eliminando a necessidade de criar e manter pipelines de dados complexos. Com esse recurso, os clientes do Aurora também podem acessar os recursos do Amazon Redshift, como análise SQL complexa, ML integrado, compartilhamento de dados e acesso federado a vários armazenamentos de dados e data lakes. Este recurso está agora disponível em pré-visualização para Edição compatível com o Amazon Aurora MySQL versão 3 (com compatibilidade com MySQL 8.0), e você pode solicitar acesso à visualização.
O Amazon Redshift agora oferece suporte cópia automática do Amazon S3 (visualização) para simplificar o carregamento de dados de Serviço de armazenamento simples da Amazon (Amazon S3) no Amazon Redshift. Agora você pode configurar regras de ingestão contínua de arquivos (tarefas de cópia) para rastrear seus caminhos do Amazon S3 e carregar automaticamente novos arquivos sem a necessidade de ferramentas adicionais ou soluções personalizadas. Os trabalhos de cópia podem ser monitorados por meio de tabelas do sistema e eles acompanham automaticamente os arquivos carregados anteriormente e os excluem do processo de ingestão para evitar a duplicação de dados. Esse recurso agora está disponível em visualização; você pode experimentar esse recurso criando um novo cluster usando a faixa de visualização.
Os clientes continuam a nos dizer que precisam de análises instantâneas, no momento e em tempo real, e temos o prazer de anunciar o disponibilidade geral de suporte de ingestão de streaming no Amazon Redshift para Fluxos de dados do Amazon Kinesis e Amazon Managed Streaming para Apache Kafka (Amazônia MSK). Esse recurso elimina a necessidade de preparar dados de streaming no Amazon S3 antes de ingeri-los no Amazon Redshift, permitindo que você obtenha baixa latência, medida em segundos, enquanto ingere centenas de megabytes de dados de streaming por segundo em seus data warehouses. Você pode usar o SQL no Amazon Redshift para se conectar e ingerir dados diretamente de vários streams de dados do Kinesis ou tópicos MSK, criar visualizações materializadas de streaming com atualização automática com transformações sobre streams diretamente para acessar dados de streaming e combinar dados em tempo real com histórico dados para melhores insights. Por exemplo, a Adobe integrou a ingestão de streaming do Amazon Redshift como parte de sua Adobe Experience Platform para ingestão e análise, em tempo real, da Web e do fluxo de cliques de aplicativos e dados de sessão para vários aplicativos, como CRM e aplicativos de suporte ao cliente.
Os clientes nos disseram que desejam uma integração simples e pronta para uso entre Amazon Redshift, ferramentas de BI e ETL (extrair, transformar e carregar) e aplicativos de negócios como Salesforce e Marketo. Temos o prazer de anunciar a disponibilidade geral de Informatica Data Loader para Amazon Redshift, que permite usar o Informatica Data Loader para carregamento de dados de alta velocidade e alto volume no Amazon Redshift gratuitamente. Você pode simplesmente selecionar a opção Informatica Data Loader no console do Amazon Redshift. Uma vez no Informatica Data Loader, você pode se conectar a fontes como Salesforce ou Marketo, escolher Amazon Redshift como destino e começar a carregar seus dados.
Compartilhamento de dados e colaboração
Os clientes continuam nos dizendo que desejam analisar todos os seus dados primários e de terceiros e disponibilizar os insights avançados orientados por dados para seus clientes, parceiros e fornecedores. Lançamos novidades em 2021, como Compartilhamento de dados e Integração de troca de dados da AWS, para facilitar a análise de todos os seus dados e compartilhá-los dentro e fora de suas organizações.
Um ótimo exemplo de cliente que usa o compartilhamento de dados é a Orion. A Orion fornece soluções de dados como serviço (DaaS) em tempo real para clientes no setor de serviços financeiros, como gerenciamento de patrimônio, gerenciamento de ativos e provedores de gerenciamento de investimentos. Eles têm mais de 2,500 fontes de dados que são principalmente bancos de dados do SQL Server instalados no local e na AWS. Os dados são transmitidos usando conectores Kafka para o Amazon Redshift. Eles têm um cluster produtor que recebe todos esses dados e usa o Compartilhamento de dados para compartilhar dados em tempo real para colaboração. Essa é uma arquitetura multilocatário que atende a vários clientes. Dada a confidencialidade de seus dados, o compartilhamento de dados é uma forma de fornecer isolamento de carga de trabalho entre clusters e também compartilhar com segurança esses dados com os usuários finais.
Em 2022, continuamos investindo nessa área para melhorar o desempenho, a governança e a produtividade do desenvolvedor com novos recursos para tornar mais fácil, simples e rápido compartilhar e colaborar em dados.
Como os clientes estão criando configurações de compartilhamento de dados em larga escala, eles solicitaram governança e segurança simplificadas para dados compartilhados, e estamos adicionando controle de acesso centralizado com o AWS Lake Formation para compartilhamentos de dados do Amazon Redshift para permitir o compartilhamento de dados ativos em vários data warehouses do Amazon Redshift. Com esse recurso, o Amazon Redshift agora oferece suporte à governança simplificada de compartilhamentos de dados do Amazon Redshift usando Formação AWS Lake como um único painel de vidro para gerenciar centralmente dados ou permissões em compartilhamentos de dados. Você pode visualizar, modificar e auditar permissões, incluindo segurança em nível de linha e coluna nas tabelas e exibições nos compartilhamentos de dados do Amazon Redshift, usando as APIs Lake Formation e o Console de gerenciamento da AWS, e permite que os compartilhamentos de dados do Amazon Redshift sejam descobertos e consumidos por outros data warehouses do Amazon Redshift.
Ciência de dados e aprendizado de máquina
Os clientes continuam a nos dizer que desejam que seus sistemas de dados e análises os ajudem a responder a uma ampla gama de perguntas, desde o que está acontecendo em seus negócios (análise descritiva) até por que está acontecendo (análise diagnóstica) e o que acontecerá no futuro (análise preditiva). O Amazon Redshift fornece recursos como análise complexa de SQL, análise de data lake e Amazon RedshiftML para que os clientes analisem seus dados e descubram insights poderosos. Redshift ML integra Amazon Redshift com Amazon Sage Maker, um serviço de ML totalmente gerenciado, que permite criar, treinar e implantar modelos de ML usando comandos SQL familiares.
Os clientes também nos pediram uma melhor integração entre o Amazon Redshift e o Apache Spark, por isso temos o prazer de anunciar Integração do Amazon Redshift para Apache Spark para tornar os armazéns de dados facilmente acessíveis para aplicativos baseados em Spark. Agora, os desenvolvedores que usam análises da AWS e serviços de ML, como Amazon EMR, Cola AWS, e o SageMaker pode criar sem esforço aplicativos Apache Spark que leem e gravam em seus data warehouses do Amazon Redshift. O Amazon EMR e o AWS Glue empacotam o conector Redshift-Spark para que você possa se conectar facilmente ao seu data warehouse a partir de seus aplicativos baseados em Spark. Você pode usar vários recursos de empilhamento para operações como classificação, agregação, limite, junção e funções escalares para que apenas os dados relevantes sejam movidos do data warehouse do Amazon Redshift para o aplicativo Spark de consumo. Você também pode tornar seus aplicativos mais seguros utilizando Gerenciamento de acesso e identidade da AWS (IAM) para se conectar ao Amazon Redshift.
Análise segura e confiável
Os clientes continuam a nos dizer que seus data warehouses são sistemas de missão crítica que precisam de alta disponibilidade, confiabilidade e segurança. Lançamos uma série de novidades em 2022 nessa área.
O Amazon Redshift agora oferece suporte Implantações Multi-AZ (em versão prévia) para clusters baseados em instância RA3, que permite a execução de seu data warehouse em várias zonas de disponibilidade da AWS simultaneamente e operação contínua em cenários de falha imprevistos em toda a zona de disponibilidade. O suporte Multi-AZ já está disponível para Redshift Serverless. Uma implantação do Amazon Redshift Multi-AZ permite que você recupere em caso de falhas da zona de disponibilidade sem qualquer intervenção do usuário. Um data warehouse Multi-AZ do Amazon Redshift é acessado como um único data warehouse com um endpoint e ajuda você a maximizar o desempenho distribuindo o processamento da carga de trabalho em várias zonas de disponibilidade automaticamente. Nenhuma alteração de aplicativo é necessária para manter a continuidade dos negócios durante interrupções imprevistas.
Em 2022, lançamos recursos como controle de acesso baseado em função, segurança em nível de linha e mascaramento de dados (em versão prévia) para facilitar o gerenciamento do acesso e a decisão de quem tem acesso a quais dados, incluindo a ofuscação de informações de identificação pessoal (PII ) como números de cartão de crédito.
Você pode usar controle de acesso baseado em função (RBAC) para controlar o acesso do usuário final aos dados em um nível amplo ou granular com base na função e nas permissões de trabalho do usuário final. Com o RBAC, você pode criar uma função usando SQL, conceder uma coleção de permissões granulares à função e, em seguida, atribuir essa função aos usuários finais. As funções podem receber permissões em nível de objeto, nível de coluna e nível de sistema. Além disso, o RBAC apresenta funções de sistema prontas para uso para DBAs, operadores, administradores de segurança ou funções personalizadas.
Segurança em nível de linha (RLS) simplifica o design e a implementação do acesso refinado às linhas nas tabelas. Com o RLS, você pode restringir o acesso a um subconjunto de linhas em uma tabela com base na função de trabalho dos usuários ou nas permissões com SQL.
Suporte do Amazon Redshift para mascaramento dinâmico de dados (DDM), que agora está disponível em versão prévia, permite simplificar a proteção de PII, como números de CPF, números de cartão de crédito e números de telefone em seu data warehouse do Amazon Redshift. Com o mascaramento dinâmico de dados, você controla o acesso aos seus dados por meio de políticas simples de mascaramento baseadas em SQL que determinam como o Amazon Redshift retorna dados confidenciais ao usuário no momento da consulta. Você pode criar políticas de mascaramento para definir valores de dados mascarados consistentes, preservadores de formato e irreversíveis. Você pode aplicar uma política de mascaramento em uma coluna específica ou lista de colunas em uma tabela. Além disso, você tem a flexibilidade de escolher como mostrar os dados mascarados. Por exemplo, você pode ocultar completamente os dados, substituir valores reais parciais por caracteres curinga ou definir sua própria maneira de mascarar os dados usando expressões SQL, Python ou AWS Lambda funções definidas pelo usuário. Além disso, você pode aplicar uma política de mascaramento condicional com base em outras colunas, que protege seletivamente os dados da coluna em uma tabela com base nos valores de uma ou mais colunas diferentes.
Também anunciamos melhorias para registro de auditoria, integração nativa com Microsoft Azure Active Directorye suporte para papéis padrão do IAM em regiões adicionais para simplificar ainda mais o gerenciamento de segurança.
Melhor análise de desempenho de preço
Os clientes continuam a nos dizer que precisam de data warehouses rápidos e econômicos que ofereçam alto desempenho em qualquer escala, mantendo os custos baixos. Desde o dia 1 desde Lançamento do Amazon Redshift em 2012, adotamos uma abordagem baseada em dados e usamos telemetria de frota para criar um serviço de armazenamento de dados em nuvem que oferece a você o melhor desempenho de preço em qualquer escala. Ao longo dos anos, evoluímos Arquitetura do Amazon Redshift e lançou recursos como Armazenamento gerenciado do Redshift (RMS) para separação de armazenamento e computação, Espectro Amazon Redshift para consultas de data lake, otimização automática de mesa para otimização de esquema físico, gerenciamento automático de carga de trabalho para priorizar cargas de trabalho e alocar a computação e a memória corretas, redimensionar cluster dimensionar a computação e o armazenamento verticalmente e dimensionamento de simultaneidade escalar dinamicamente a computação. Nosso benchmarks de desempenho continuam a demonstrar a liderança em desempenho de preços do Amazon Redshift.
Em 2022, adicionamos novos recursos, como a disponibilidade geral de escalonamento de simultaneidade para operações de gravação como COPY, INSERT, UPDATE e DELETE para suportar consultas e usuários simultâneos virtualmente ilimitados. Também introduzimos melhorias de desempenho para o processamento de dados baseado em string por meio de varreduras vetorizadas em colunas de string codificadas em dicionário, leves e com eficiência de CPU, o que permite que o mecanismo de banco de dados opere diretamente sobre dados compactados.
Também adicionamos suporte para operadores SQL, como MERGE (operador único para inserções ou atualizações); CONNECY_BY (para consultas hierárquicas); CONJUNTOS DE AGRUPAMENTO, ROLLUP e CUBO (para relatórios multidimensionais); e aumentou o tamanho do tipo de dados SUPER para 16 MB para facilitar a migração de data warehouses legados para o Amazon Redshift.
Conclusão
Nossos clientes continuam a nos dizer que dados e análises continuam sendo uma prioridade para eles e a necessidade de extrair mais valor comercial de seus dados de maneira econômica durante esses tempos é mais pronunciada do que em qualquer outro momento no passado. O Amazon Redshift como seu data warehouse na nuvem permite que você execute análises SQL complexas com escala e desempenho de terabytes a petabytes de dados estruturados e não estruturados e disponibilize amplamente os insights por meio de ferramentas populares de BI e análise.
Embora tenhamos lançado mais de 40 recursos em 2022 e o ritmo da inovação continue a acelerar, ainda é o dia 1 e estamos ansiosos para saber como esses recursos ajudam você a gerar mais valor para suas organizações. Convidamos você a experimentar esses novos recursos e entrar em contato conosco por meio de sua equipe de contas da AWS se tiver mais comentários.
Sobre o autor
 Manan Goel é líder de entrada no mercado de produtos para AWS Analytics Services, incluindo Amazon Redshift na AWS. Ele tem mais de 25 anos de experiência e é versado em bancos de dados, armazenamento de dados, inteligência de negócios e análise. Manan possui MBA pela Duke University e bacharelado em engenharia eletrônica e de comunicações.
Manan Goel é líder de entrada no mercado de produtos para AWS Analytics Services, incluindo Amazon Redshift na AWS. Ele tem mais de 25 anos de experiência e é versado em bancos de dados, armazenamento de dados, inteligência de negócios e análise. Manan possui MBA pela Duke University e bacharelado em engenharia eletrônica e de comunicações.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- habilidade
- Sobre
- acelerar
- Acesso
- Acesso a dados
- acessadas
- acessível
- Conta
- Alcançar
- em
- ativo
- ativamente
- adicionado
- Adição
- Adicional
- Adicionalmente
- adobe
- Todos os Produtos
- permite
- já
- Amazon
- Amazon EMR
- Analistas
- analítica
- analisar
- análise
- e
- Anunciar
- anunciou
- Outro
- responder
- apache
- Apache Spark
- APIs
- Aplicação
- aplicações
- Aplicar
- abordagem
- arquitetura
- ÁREA
- áreas
- artificial
- inteligência artificial
- ativo
- gestão de activos
- auditor
- aurora
- autor
- auto
- automatizar
- Automático
- automaticamente
- disponibilidade
- disponível
- AWS
- Cola AWS
- Azul
- baseado
- base
- tornando-se
- antes
- ser
- MELHOR
- Melhor
- entre
- Grande
- Big Data
- morada
- Break
- amplo
- Broadridge
- construir
- Prédio
- construídas em
- negócio
- Aplicações de Negócio
- a continuidade dos negócios
- inteligência de negócios
- capacidades
- Capacidade
- cartão
- casas
- casos
- Alterações
- caracteres
- Escolha
- escolha
- clientes
- Na nuvem
- Agrupar
- colaborar
- colaboração
- coleção
- Coluna
- colunas
- combinar
- combinado
- comentários
- Comunicações
- compatibilidade
- completamente
- integrações
- componente
- Computar
- concorrente
- Contato
- consistente
- cônsul
- consumida
- continuar
- continuou
- continua
- contínuo
- ao controle
- relação custo-benefício
- custos
- cobre
- crio
- Criar
- Credenciais
- crédito
- cartão de crédito
- Créditos
- CRM
- Atual
- personalizadas
- cliente
- Suporte ao cliente
- Clientes
- personalizado
- dados,
- Data Exchange
- lago data
- informática
- compartilhamento de dados
- data warehouse
- armazéns de dados
- orientado por dados
- banco de dados
- bases de dados
- dia
- mais profunda
- entregar
- demonstrar
- implantar
- desenvolvimento
- Design
- Determinar
- Developer
- desenvolvedores
- diferente
- diretamente
- descobrir
- descoberto
- discutir
- distribuído
- distribuindo
- Duque
- Universidade Duke
- durante
- dinâmico
- mais fácil
- facilmente
- editor
- esforço
- Eletrônicos
- elimina
- eliminando
- permitir
- permite
- permitindo
- Ponto final
- Motor
- Engenharia
- Éter (ETH)
- todos
- evoluiu
- exemplo
- exchange
- animado
- Expandir
- vasta experiência
- explorar
- expressões
- extrato
- Falha
- familiar
- RÁPIDO
- mais rápido
- Característica
- Funcionalidades
- Envie o
- Arquivos
- financeiro
- serviços financeiros
- finanças
- Encontre
- ANIMARIS
- Flexibilidade
- treinamento
- para a frente
- Gratuito
- da
- totalmente
- funções
- mais distante
- futuro
- Geral
- ter
- gif
- OFERTE
- dado
- dá
- Dando
- vidro
- Ir ao mercado
- governo
- conceder
- concedido
- ótimo
- acontecer
- feliz
- Queijos duros
- ter
- saúde
- audição
- ajudar
- ajuda
- Esconder
- Alta
- histórico
- detém
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- Centenas
- IAM
- Identidade
- implementação
- melhorar
- melhorado
- melhorias
- in
- Incluindo
- aumentou
- indústria
- INFORMAÇÕES
- Infraestrutura
- Inovação
- Inserções
- insights
- integrar
- integrado
- Integra-se
- integração
- Inteligência
- da intervenção
- introduzido
- Introduz
- Investir
- investimento
- convidar
- isolamento
- IT
- Trabalho
- Empregos
- juntar
- Julho
- Kafka
- Guarda
- manutenção
- Chave
- Streams de dados Kinesis
- lago
- em grande escala
- Latência
- lançamento
- lançado
- líder
- Liderança
- aprendizagem
- Legado
- Nível
- leve
- LIMITE
- Lista
- viver
- dados ao vivo
- carregar
- carregador
- carregamento
- olhar
- Baixo
- máquina
- aprendizado de máquina
- moldadas
- a manter
- manutenção
- fazer
- Fazendo
- gerencia
- gerenciados
- de grupos
- manual
- Marketo
- máscara
- Maximizar
- Memória
- migrado
- ML
- modelos
- EQUIPAMENTOS
- modificar
- monitorados
- monitoração
- mais
- em movimento
- múltiplo
- MySQL
- nativo
- você merece...
- necessário
- Cria
- Novo
- Novos Recursos
- número
- números
- Oferece
- ONE
- aberto
- operar
- operação
- Operações
- operador
- operadores
- otimização
- Opção
- organização
- organizações
- Outros
- Interrupções
- lado de fora
- próprio
- Paz
- pacote
- pão
- parte
- Parceiros
- passado
- Pagar
- pelotão
- atuação
- permissões
- Pessoalmente
- telefone
- físico
- Pii
- Lugar
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- satisfeito
- políticas
- Privacidade
- Popular
- Publique
- poderoso
- Análise Preditiva
- evitar
- visualização
- anteriormente
- preço
- principalmente
- Priorizar
- prioridade
- processo
- em processamento
- produtor
- Produto
- produtividade
- proteger
- fornecer
- provedor
- fornecedores
- fornece
- provisão
- Python
- Frequentes
- rapidamente
- alcance
- alcançar
- Leia
- reais
- em tempo real
- dados em tempo real
- recebe
- Recuperar
- reduzir
- regiões
- relevante
- confiabilidade
- confiável
- permanece
- substituir
- Denunciar
- Relatórios
- Requisitos
- restringir
- resultando
- Retorna
- rever
- reescrevendo
- Rico
- rígido
- Tipo
- papéis
- rolar
- regras
- Execute
- corrida
- sábio
- Salesforce
- Escala
- Escalas
- dimensionamento
- cenários
- Ciência
- cientistas
- Segundo
- segundo
- seguro
- firmemente
- segurança
- sensível
- Sensibilidade
- Serverless
- serve
- serviço
- Serviços
- Sessão
- conjunto
- Conjuntos
- vários
- Partilhar
- compartilhado
- compartilhando
- mostrar
- simples
- simplificada
- simplificar
- simplesmente
- simultaneamente
- desde
- solteiro
- Sentado
- Tamanho
- lento
- So
- Redes Sociais
- solução
- Soluções
- alguns
- Fontes
- Faísca
- específico
- SQL
- Etapa
- armazenamento
- lojas
- Estratégia
- fluídas
- de streaming
- córregos
- estruturada
- dados estruturados e não estruturados
- tal
- super
- fornecedores
- ajuda
- suportes
- .
- sistemas
- mesa
- Target
- Profissionais
- A
- O Futuro
- deles
- De terceiros
- milhares
- Através da
- tempo
- vezes
- para
- ferramenta
- ferramentas
- topo
- Temas
- Total
- tocar
- pista
- Trem
- transacional
- Transformar
- transformações
- onipresente
- imprevisto
- universidade
- ilimitado
- destravar
- Atualizar
- Atualizações
- us
- usar
- Utilizador
- usuários
- Utilizando
- valor
- Valores
- vário
- versão
- Ver
- visualizações
- praticamente
- Armazém
- Armazenagem
- Riqueza
- gestão de riqueza
- web
- Web-Based
- O Quê
- O que é a
- qual
- enquanto
- QUEM
- Largo
- Ampla variedade
- largamente
- precisarão
- dentro
- sem
- Atividades:
- trabalhou
- trabalhar
- no mundo todo
- escrever
- escrito
- ano
- anos
- investimentos
- zefirnet
- zonas