Estúdio do AWS Glue é uma interface gráfica que facilita a criação, execução e monitoramento de trabalhos de extração, transformação e carregamento (ETL) em Cola AWS. Ele permite compor visualmente fluxos de trabalho de transformação de dados usando nós que representam diferentes etapas de manipulação de dados, que posteriormente são convertidos automaticamente em código para execução.
Estúdio do AWS Glue lançado recentemente Mais 10 transformações visuais para permitir a criação de trabalhos mais avançados de maneira visual sem habilidades de codificação. Nesta postagem, discutimos possíveis casos de uso que refletem necessidades comuns de ETL.
As novas transformações que serão demonstradas neste post são: Concatenar, Dividir String, Array para Colunas, Adicionar Timestamp Atual, Girar Linhas para Colunas, Desarticular Colunas para Linhas, Pesquisar, Explodir Array ou Mapear em Colunas, Coluna Derivada e Processamento de Autobalanceamento .
Visão geral da solução
Neste caso de uso, temos alguns arquivos JSON com operações de opções de ações. Queremos fazer algumas transformações antes de armazenar os dados para facilitar a análise e também queremos produzir um resumo do conjunto de dados separado.
Neste conjunto de dados, cada linha representa uma negociação de contratos de opção. As opções são instrumentos financeiros que fornecem o direito, mas não a obrigação, de comprar ou vender ações a um preço fixo (chamado preço de exercício) antes de uma data de vencimento definida.
Dados de entrada
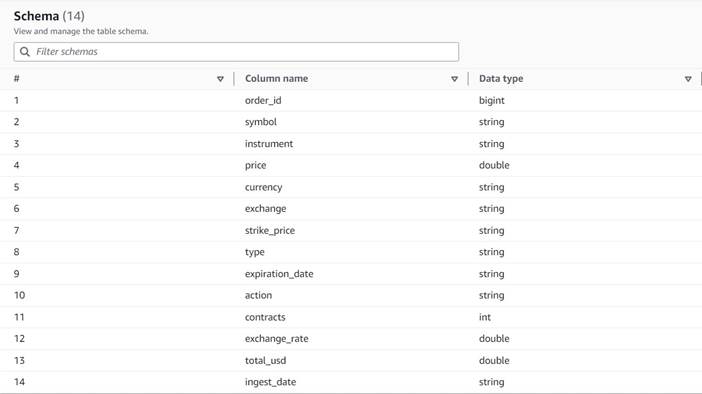
Os dados seguem o seguinte esquema:
- order_id – Um ID único
- símbolo – Um código geralmente baseado em algumas letras para identificar a corporação que emite as ações subjacentes
- instrumento – O nome que identifica a opção específica que está sendo comprada ou vendida
- moeda – O código de moeda ISO no qual o preço é expresso
- preço – O valor que foi pago pela compra de cada contrato de opção (na maioria das bolsas, um contrato permite comprar ou vender 100 ações)
- exchange – O código da central de câmbio ou local onde a opção foi negociada
- vendido – Uma lista do número de contratos que foram alocados para preencher a ordem de venda quando esta é uma negociação de venda
- comprou – Uma lista do número de contratos que foram alocados para preencher a ordem de compra quando esta é uma negociação de compra
A seguir, uma amostra dos dados sintéticos gerados para esta postagem:
Requisitos de ETL
Esses dados têm várias características exclusivas, como frequentemente encontradas em sistemas mais antigos, que tornam os dados mais difíceis de usar.
A seguir estão os requisitos de ETL:
- O nome do instrumento contém informações valiosas que devem ser entendidas por humanos; queremos normalizá-lo em colunas separadas para facilitar a análise.
- Os atributos
boughtesoldsão mutuamente exclusivos; podemos consolidá-los em uma única coluna com os números dos contratos e ter outra coluna indicando se os contratos foram comprados ou vendidos nesta ordem. - Queremos manter as informações sobre as alocações de contratos individuais, mas como linhas individuais, em vez de forçar os usuários a lidar com uma matriz de números. Poderíamos somar os números, mas perderíamos informações sobre como a ordem foi executada (indicando a liquidez do mercado). Em vez disso, optamos por desnormalizar a tabela para que cada linha tenha um único número de contratos, dividindo os pedidos com vários números em linhas separadas. Em um formato colunar compactado, o tamanho extra do conjunto de dados dessa repetição geralmente é pequeno quando a compactação é aplicada, portanto, é aceitável facilitar a consulta do conjunto de dados.
- Queremos gerar uma tabela resumo de volume para cada tipo de opção (call e put) para cada ação. Isso fornece uma indicação do sentimento do mercado para cada ação e o mercado em geral (ganância x medo).
- Para permitir resumos comerciais gerais, queremos fornecer para cada operação o total geral e padronizar a moeda para dólares americanos, usando uma referência de conversão aproximada.
- Queremos adicionar a data em que essas transformações ocorreram. Isso pode ser útil, por exemplo, para ter uma referência de quando foi feita a conversão de moeda.
Com base nesses requisitos, o trabalho produzirá duas saídas:
- Um arquivo CSV com um resumo do número de contratos para cada símbolo e tipo
- Uma tabela de catálogo para manter um histórico do pedido, depois de fazer as transformações indicadas
Pré-requisitos
Você precisará de seu próprio bucket S3 para acompanhar este caso de uso. Para criar um novo balde, consulte Criação de um balde.
Gerar dados sintéticos
Para acompanhar esta postagem (ou experimentar esse tipo de dados por conta própria), você pode gerar esse conjunto de dados sinteticamente. O script Python a seguir pode ser executado em um ambiente Python com o Boto3 instalado e acesso a Serviço de armazenamento simples da Amazon (Amazônia S3).
Para gerar os dados, conclua as seguintes etapas:
- No AWS Glue Studio, crie um novo trabalho com a opção Editor de script de shell Python.
- Dê um nome ao trabalho e no Detalhes do trabalho guia, selecione um papel adequado e um nome para o script Python.
- No Detalhes do trabalho seção, expandir Propriedades avançadas e role para baixo até Parâmetros de trabalho.
- Digite um parâmetro chamado
--buckete atribua como valor o nome do depósito que deseja usar para armazenar os dados de amostra. - Insira o seguinte script no editor de shell do AWS Glue:
- Execute o trabalho e aguarde até que ele apareça como concluído com êxito na guia Execuções (deve levar apenas alguns segundos).
Cada execução gerará um arquivo JSON com 1,000 linhas no bucket especificado e no prefixo transformsblog/inputdata/. Você pode executar o trabalho várias vezes se quiser testar com mais arquivos de entrada.
Cada linha nos dados sintéticos é uma linha de dados que representa um objeto JSON como o seguinte:
Criar o trabalho visual do AWS Glue
Para criar o trabalho visual do AWS Glue, conclua as seguintes etapas:
- Acesse o AWS Glue Studio e crie um trabalho usando a opção Visual com uma tela em branco.
- Editar
Untitled jobdar-lhe um nome e atribuir uma função adequada para o AWS Glue na Detalhes do trabalho aba. - Adicione uma fonte de dados S3 (você pode nomeá-la
JSON files source) e insira a URL do S3 na qual os arquivos são armazenados (por exemplo,s3://<your bucket name>/transformsblog/inputdata/), em seguida, selecione JSON como o formato de dados. - Selecionar Inferir esquema portanto, define o esquema de saída com base nos dados.
A partir desse nó de origem, você continuará encadeando as transformações. Ao adicionar cada transformação, certifique-se de que o nó selecionado seja o último adicionado para que seja atribuído como pai, a menos que indicado de outra forma nas instruções.
Se você não selecionou o pai certo, você sempre pode editar o pai selecionando-o e escolhendo outro pai no painel de configuração.
Para cada nó adicionado, você dará a ele um nome específico (para que a finalidade do nó apareça no gráfico) e a configuração no Transformar aba.
Sempre que uma transformação altera o esquema (por exemplo, adiciona uma nova coluna), o esquema de saída precisa ser atualizado para que fique visível para as transformações downstream. Você pode editar manualmente o esquema de saída, mas é mais prático e seguro fazê-lo usando a visualização de dados.
Além disso, dessa forma, você pode verificar se a transformação está funcionando conforme o esperado. Para isso, abra o Visualização de dados guia com a transformação selecionada e inicie uma sessão de visualização. Depois de verificar se os dados transformados estão conforme o esperado, vá para o Esquema de saída aba e escolha Usar esquema de visualização de dados para atualizar o esquema automaticamente.
Conforme você adiciona novos tipos de transformações, a visualização pode mostrar uma mensagem sobre uma dependência ausente. Quando isso acontecer, escolha Terminar Sessão e iniciar um novo, para que a visualização selecione o novo tipo de nó.
Extrair informações do instrumento
Vamos começar lidando com as informações do nome do instrumento para normalizá-lo em colunas mais fáceis de acessar na tabela de saída resultante.
- Adicionar uma Dividir String nó e nomeá-lo
Split instrument, que irá tokenizar a coluna do instrumento usando um regex de espaço em branco:s+(um único espaço serviria neste caso, mas desta forma é mais flexível e visualmente mais claro). - Queremos manter as informações originais do instrumento como estão, então insira um novo nome de coluna para a matriz dividida:
instrument_arr.
- Adicione um Matriz Para Colunas nó e nomeá-lo
Instrument columnspara converter a coluna da matriz recém-criada em novos campos, exceto parasymbol, para o qual já temos uma coluna. - Selecione a coluna
instrument_arr, pule o primeiro token e diga a ele para extrair as colunas de saídamonth, day, year, strike_price, typeusando índices2, 3, 4, 5, 6(os espaços após as vírgulas são para facilitar a leitura, não afetam a configuração).
O ano extraído é expresso apenas com dois dígitos; vamos colocar um paliativo para assumir que é neste século se eles usarem apenas dois dígitos.
- Adicionar uma Coluna Derivada nó e nomeá-lo
Four digits year. - Entrar
yearcomo a coluna derivada para que ela a substitua e insira a seguinte expressão SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Por conveniência, construímos um expiration_date campo que o usuário pode ter como referência da última data em que a opção pode ser exercida.
- Adicionar uma Concatenar colunas nó e nomeá-lo
Build expiration date. - Nomeie a nova coluna
expiration_date, selecione as colunasyear,montheday(nessa ordem) e um hífen como espaçador.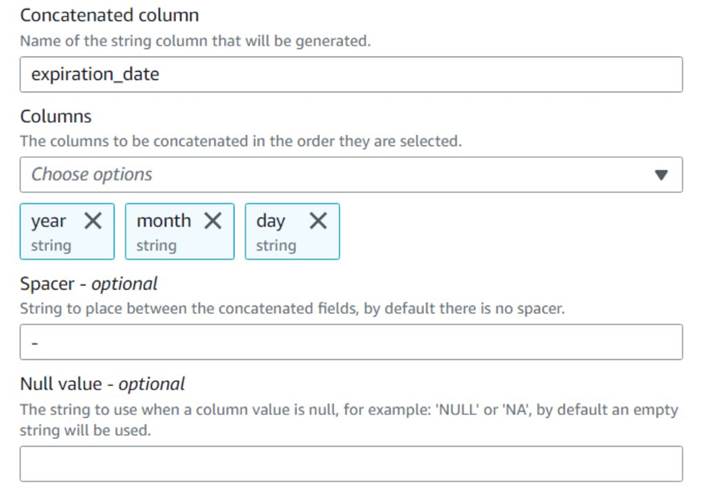
O diagrama até agora deve se parecer com o exemplo a seguir.
![]()
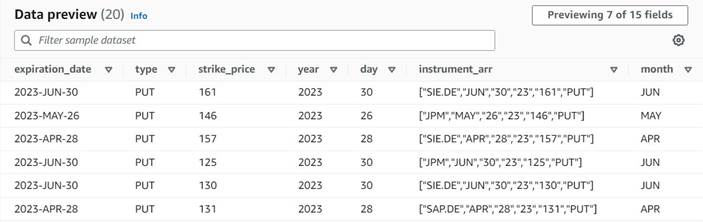
A visualização dos dados das novas colunas até agora deve se parecer com a captura de tela a seguir.
Normalizar o número de contratos
Cada uma das linhas nos dados indica o número de contratos de cada opção que foram comprados ou vendidos e os lotes nos quais os pedidos foram atendidos. Sem perder as informações sobre os lotes individuais, queremos ter cada quantidade em uma linha individual com um único valor de quantidade, enquanto o restante da informação é replicado em cada linha produzida.
Primeiro, vamos mesclar os valores em uma única coluna.
- Adicione um Não dinamizar colunas em linhas nó e nomeá-lo
Unpivot actions. - Escolha as colunas
boughtesoldpara não dinamizar e armazenar os nomes e valores em colunas chamadasactionecontracts, Respectivamente.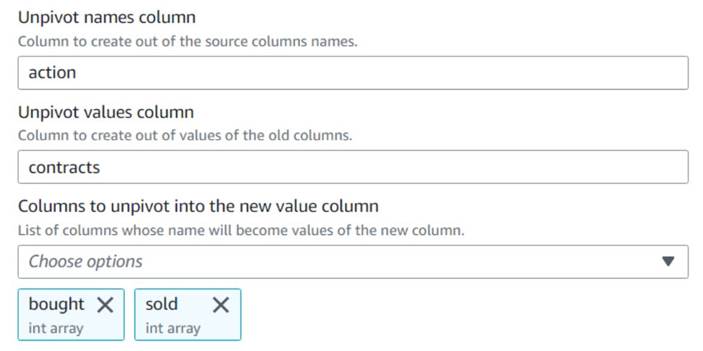
Observe na visualização que a nova colunacontractsainda é uma matriz de números após essa transformação.
- Adicione um Explodir matriz ou mapa em linhas linha nomeada
Explode contracts. - Escolha o
contractscoluna e digitecontractscomo a nova coluna para substituí-la (não precisamos manter a matriz original).
A visualização agora mostra que cada linha tem um único contracts montante, e o resto dos campos são os mesmos.
Isso também significa que order_id não é mais uma chave exclusiva. Para seus próprios casos de uso, você precisa decidir como modelar seus dados e se deseja desnormalizar ou não.
A captura de tela a seguir é um exemplo de como as novas colunas se parecem após as transformações até agora.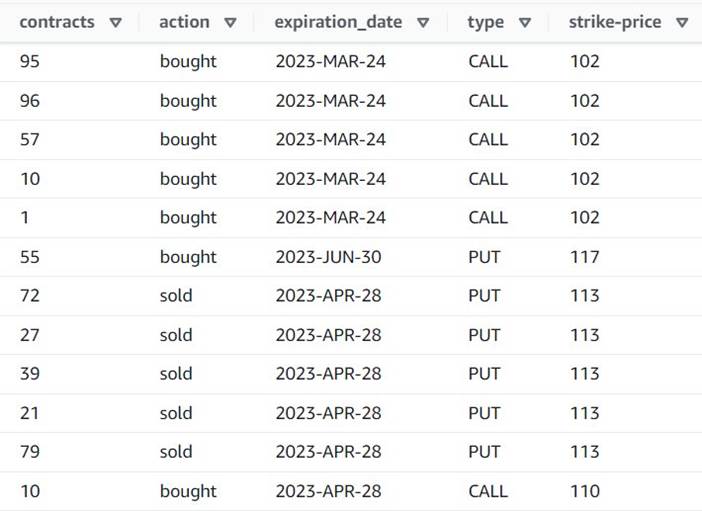
Criar uma tabela de resumo
Agora você cria uma tabela de resumo com o número de contratos negociados para cada tipo e cada símbolo de ação.
Vamos supor, para fins de ilustração, que os arquivos processados pertencem a um único dia, portanto, este resumo fornece aos usuários comerciais informações sobre o interesse e o sentimento do mercado naquele dia.
- Adicionar uma Selecione os campos nó e selecione as seguintes colunas para manter o resumo:
symbol,typeecontracts.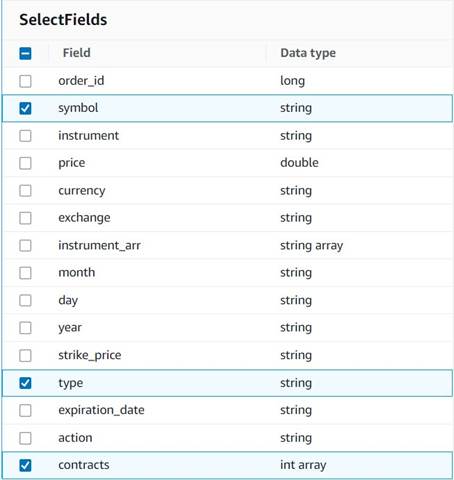
- Adicionar uma Girar Linhas em Colunas nó e nomeá-lo
Pivot summary. - Agregar no
contractscoluna usandosume escolha converter otypecoluna.
Normalmente, você o armazenaria em algum banco de dados ou arquivo externo para referência; neste exemplo, nós o salvamos como um arquivo CSV no Amazon S3.
- Adicione um Processamento de balanço automático nó e nomeá-lo
Single output file. - Embora esse tipo de transformação seja normalmente usado para otimizar o paralelismo, aqui o usamos para reduzir a saída a um único arquivo. Portanto, entre
1na configuração do número de partições.
- Adicionar um destino S3 e nomeá-lo
CSV Contract summary. - Escolha CSV como o formato de dados e insira um caminho S3 onde a função de trabalho tem permissão para armazenar arquivos.
A última parte do trabalho agora deve se parecer com o exemplo a seguir.![]()
- Salve e execute o trabalho. Use o Runs guia para verificar quando ele foi concluído com sucesso.
Você encontrará um arquivo nesse caminho que é um CSV, apesar de não ter essa extensão. Você provavelmente precisará adicionar a extensão depois de baixá-la para abri-la.
Em uma ferramenta que pode ler o CSV, o resumo deve se parecer com o exemplo a seguir.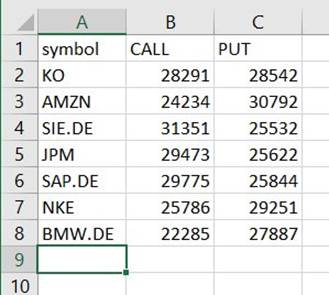
Limpar colunas temporárias
Em preparação para salvar os pedidos em uma tabela histórica para análise futura, vamos limpar algumas colunas temporárias criadas ao longo do caminho.
- Adicionar uma Soltar campos nó com o
Explode contractsnó selecionado como seu pai (estamos ramificando o pipeline de dados para gerar uma saída separada). - Selecione os campos a serem descartados:
instrument_arr,month,dayeyear.
O restante queremos manter para que fiquem salvos na tabela histórica que criaremos posteriormente.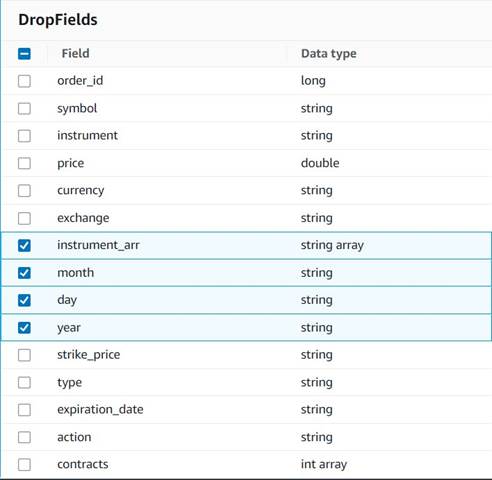
Padronização de moeda
Esses dados sintéticos contêm operações fictícias em duas moedas, mas em um sistema real você pode obter moedas de mercados de todo o mundo. É útil padronizar as moedas tratadas em uma única moeda de referência para que possam ser facilmente comparadas e agregadas para relatórios e análises.
Usamos Amazona atena para simular uma tabela com conversões de moeda aproximadas que são atualizadas periodicamente (aqui assumimos que processamos os pedidos em tempo hábil o suficiente para que a conversão seja uma representação razoável para fins de comparação).
- Abra o console do Athena na mesma região em que você está usando o AWS Glue.
- Execute a consulta a seguir para criar a tabela definindo um local do S3 onde as funções do Athena e do AWS Glue podem ler e gravar. Além disso, você pode querer armazenar a tabela em um banco de dados diferente daquele
default(se você fizer isso, atualize o nome qualificado da tabela de acordo com os exemplos fornecidos). - Insira algumas conversões de amostra na tabela:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Agora você deve conseguir visualizar a tabela com a seguinte consulta:
SELECT * FROM default.exchange_rates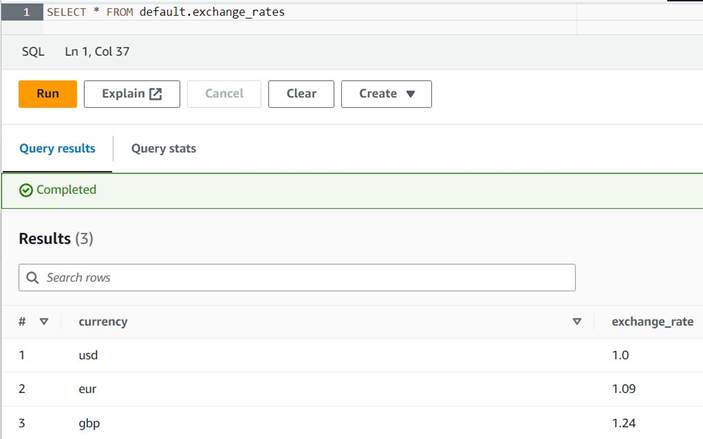
- De volta ao trabalho visual do AWS Glue, adicione um Lookup nó (como filho de
Drop Fields) e nomeieExchange rate. - Digite o nome qualificado da tabela que você acabou de criar, usando
currencycomo a chave e selecione oexchange_ratecampo a ser usado.
Como o campo tem o mesmo nome nos dados e na tabela de pesquisa, podemos apenas inserir o nomecurrencye não precisa definir um mapeamento.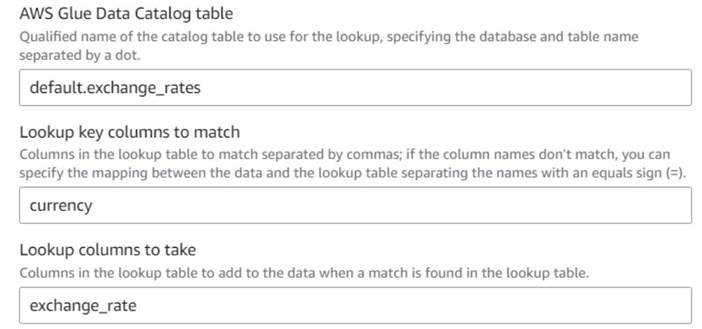
No momento da redação deste artigo, a transformação Lookup não é suportada na visualização de dados e mostrará um erro informando que a tabela não existe. Isso é apenas para a visualização de dados e não impede que o trabalho seja executado corretamente. As poucas etapas restantes da postagem não exigem que você atualize o esquema. Se precisar executar uma visualização de dados em outros nós, você pode remover o nó de pesquisa temporariamente e, em seguida, colocá-lo de volta. - Adicionar uma Coluna Derivada nó e nomeá-lo
Total in usd. - Nomeie a coluna derivada
total_usde use a seguinte expressão SQL:round(contracts * price * exchange_rate, 2)
- Adicionar uma Adicionar carimbo de data/hora atual node e nomeie a coluna
ingest_date. - Use o formato
%Y-%m-%dpara o seu carimbo de data/hora (para fins de demonstração, estamos usando apenas a data; você pode torná-la mais precisa se quiser).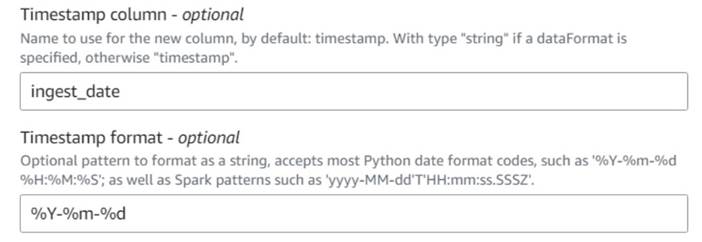
Salve a tabela de pedidos históricos
Para salvar a tabela de pedidos históricos, conclua as seguintes etapas:
- Adicionar um nó de destino do S3 e nomeá-lo
Orders table. - Configure o formato Parquet com compactação rápida e forneça um caminho de destino S3 no qual armazenar os resultados (separado do resumo).
- Selecionar Crie uma tabela no Catálogo de Dados e nas execuções subsequentes, atualize o esquema e adicione novas partições.
- Insira um banco de dados de destino e um nome para a nova tabela, por exemplo:
option_orders.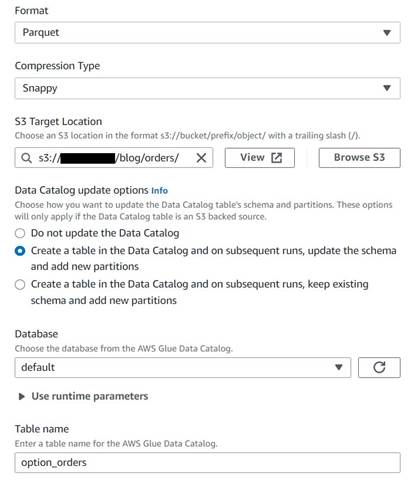
A última parte do diagrama agora deve ser semelhante à seguinte, com duas ramificações para as duas saídas separadas.![]()
Depois de executar o trabalho com êxito, você pode usar uma ferramenta como o Athena para revisar os dados que o trabalho produziu consultando a nova tabela. Você pode encontrar a tabela na lista Athena e escolher Tabela de visualização ou apenas execute uma consulta SELECT (atualizando o nome da tabela para o nome e o catálogo que você usou):
SELECT * FROM default.option_orders limit 10
O conteúdo da tabela deve ser semelhante à captura de tela a seguir.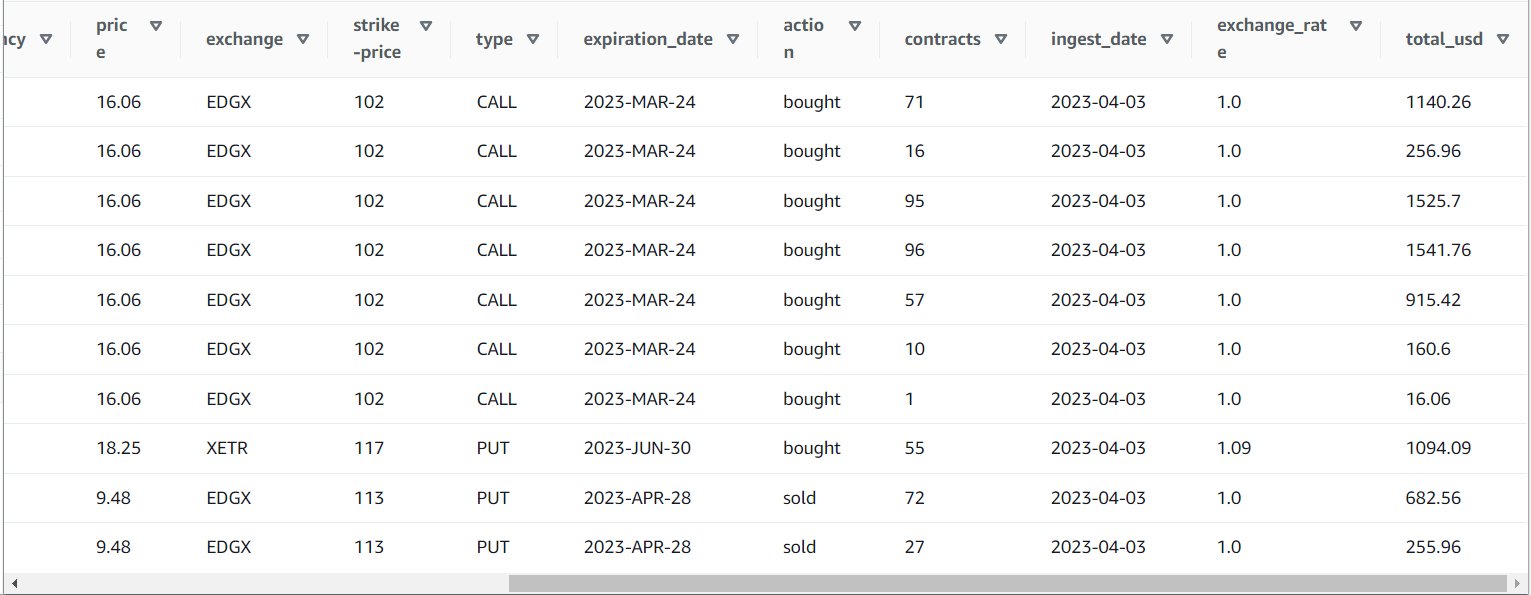
limpar
Se não quiser manter este exemplo, exclua os dois trabalhos que você criou, as duas tabelas no Athena e os caminhos do S3 onde os arquivos de entrada e saída foram armazenados.
Conclusão
Nesta postagem, mostramos como as novas transformações no AWS Glue Studio podem ajudá-lo a fazer transformações mais avançadas com configuração mínima. Isso significa que você pode implementar mais casos de uso de ETL sem precisar escrever e manter nenhum código. As novas transformações já estão disponíveis no AWS Glue Studio, então você pode usar as novas transformações hoje mesmo em seus trabalhos visuais.
Sobre o autor
![]() Gonzalo herreros é arquiteto sênior de Big Data na equipe do AWS Glue.
Gonzalo herreros é arquiteto sênior de Big Data na equipe do AWS Glue.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Capaz
- Sobre
- aceitável
- Acesso
- conformemente
- adicionar
- adicionado
- acrescentando
- avançado
- Depois de
- Todos os Produtos
- alocado
- alocações
- permitir
- permite
- juntamente
- já
- tb
- sempre
- Amazon
- quantidade
- quantidades
- an
- análise
- analisar
- e
- Outro
- qualquer
- aplicado
- aproximado
- abril
- SOMOS
- argumento
- Ordem
- AS
- atribuído
- At
- atributos
- automaticamente
- disponível
- AWS
- Cola AWS
- em caminho duplo
- baseado
- BE
- antes
- ser
- Grande
- Big Data
- em branco
- BMW
- ambos
- comprou
- ramos
- construir
- negócio
- mas a
- comprar
- by
- chamada
- CAN
- casas
- casos
- catálogo
- Centralização de
- Century
- Alterações
- características
- verificar
- criança
- Escolha
- escolha
- mais claro
- código
- Codificação
- Coluna
- colunas
- comum
- comparado
- comparação
- completar
- Efetuado
- Configuração
- cônsul
- consolidar
- contém
- conteúdo
- contract
- contratos
- facilidade
- Conversão
- conversões
- converter
- convertido
- CORPORAÇÃO
- poderia
- crio
- criado
- Criar
- moedas
- Moeda
- Atual
- DAG
- dados,
- banco de dados
- Data
- Datas
- datetime
- dia
- acordo
- lidar
- decidir
- Padrão
- definido
- demonstraram
- Dependência
- Derivado
- Apesar de
- detalhes
- diferente
- dígitos
- discutir
- do
- Não faz
- fazer
- dólares
- não
- duplo
- down
- Cair
- desistiu
- cada
- mais fácil
- facilmente
- fácil
- editor
- permitir
- suficiente
- Entrar
- Meio Ambiente
- erro
- Éter (ETH)
- EUR
- exemplo
- exemplos
- Exceto
- exchange
- Trocas
- Exclusivo
- existir
- Expandir
- esperado
- experimentar
- expiração
- expressa
- extensão
- externo
- extra
- extrato
- longe
- medo
- poucos
- fictício
- campo
- Campos
- Envie o
- Arquivos
- preencher
- preenchida
- financeiro
- Instrumentos financeiros
- Encontre
- Primeiro nome
- fixado
- flexível
- seguir
- seguinte
- segue
- Escolha
- formato
- encontrado
- da
- futuro
- GBP
- Geral
- geralmente
- gerar
- gerado
- ter
- OFERTE
- dá
- Go
- gráfico
- Ganância
- Manipulação
- acontece
- Ter
- ter
- ajudar
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- histórico
- história
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- Humanos
- i
- identifica
- identificar
- if
- Impacto
- executar
- importar
- in
- índices
- indicado
- indicam
- indicador
- indicação
- Individual
- INFORMAÇÕES
- entrada
- instância
- em vez disso
- instruções
- instrumento
- instrumentos
- interesse
- Interface
- para dentro
- ISO
- IT
- ESTÁ
- Trabalho
- Empregos
- jpg
- json
- apenas por
- Guarda
- Chave
- Tipo
- Sobrenome
- mais tarde
- como
- LIMITE
- Line
- Liquidez
- Lista
- carregar
- localização
- mais
- olhar
- parece
- OLHARES
- pesquisa
- perder
- perder
- moldadas
- a manter
- fazer
- FAZ
- manualmente
- mapa,
- mapeamento
- mercado
- sentimento do mercado
- Mercados
- Posso..
- significa
- ir
- mensagem
- poder
- mínimo
- desaparecido
- modelo
- Monitore
- mais
- a maioria
- múltiplo
- mutuamente
- nome
- Nomeado
- nomes
- você merece...
- Cria
- Novo
- não
- nó
- nós
- normalmente
- agora
- número
- números
- objeto
- of
- frequentemente
- on
- ONE
- só
- aberto
- operação
- Operações
- Otimize
- Opção
- Opções
- or
- ordem
- ordens
- original
- Outros
- de outra forma
- saída
- Acima de
- global
- override
- próprio
- pago
- pão
- parâmetro
- parte
- caminho
- Picks
- oleoduto
- articulação
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- Publique
- potencial
- Prática
- preciso
- evitar
- visualização
- preço
- provavelmente
- processo
- em processamento
- produzir
- Produzido
- fornecer
- fornecido
- fornece
- compra
- propósito
- fins
- colocar
- Python
- qualificado
- aumentar
- acaso
- Leia
- reais
- razoável
- reduzir
- refletir
- região
- remanescente
- remover
- replicado
- Relatórios
- representar
- representante
- representando
- representa
- requerer
- Requisitos
- exige
- respectivamente
- DESCANSO
- resultando
- Resultados
- rever
- Tipo
- papéis
- LINHA
- Execute
- corrida
- mais segura
- mesmo
- seiva
- Salvar
- poupança
- scroll
- segundo
- selecionado
- selecionando
- vender
- senior
- sentimento
- separado
- Sessão
- Conjuntos
- contexto
- ações
- concha
- rede de apoio social
- mostrar
- Shows
- semelhante
- simples
- solteiro
- Tamanho
- Habilidades
- pequeno
- So
- até aqui
- vendido
- alguns
- algo
- fonte
- Espaço
- espaços
- específico
- especificada
- divisão
- Planilha
- SQL
- começo
- Passos
- Ainda
- estoque
- armazenamento
- loja
- armazenadas
- Tanga
- estudo
- subseqüente
- entraram com sucesso
- adequado
- RESUMO
- Suportado
- símbolo
- sintético
- dados sintéticos
- sinteticamente
- .
- sistemas
- mesa
- Tire
- Target
- Profissionais
- dizer
- temporário
- dez
- teste
- do que
- que
- A
- The Graph
- as informações
- o mundo
- Eles
- então
- assim sendo
- Este
- deles
- isto
- aqueles
- tempo
- vezes
- timestamp
- para
- hoje
- token
- tokenize
- levou
- ferramenta
- Total
- comércio
- negociadas
- Transformar
- Transformação
- transformações
- transformado
- dois
- tipo
- para
- subjacente
- compreender
- único
- até
- Atualizar
- Atualizada
- atualização
- URL
- us
- Dólares dos EUA
- USD
- usar
- caso de uso
- usava
- Utilizador
- usuários
- utilização
- Valioso
- Informação valiosa
- valor
- Valores
- Local
- verificado
- verificar
- Ver
- visível
- volume
- vs
- esperar
- queremos
- foi
- Caminho..
- we
- foram
- O Quê
- quando
- qual
- enquanto
- precisarão
- de
- sem
- fluxos de trabalho
- trabalhar
- mundo
- seria
- escrever
- escrita
- ano
- Você
- investimentos
- zefirnet











