Imagem criada com DALL-E3
A Inteligência Artificial foi uma revolução completa no mundo da tecnologia.
Sua capacidade de imitar a inteligência humana e realizar tarefas que antes eram consideradas domínios exclusivamente humanos ainda surpreende a maioria de nós.
No entanto, não importa quão bons tenham sido esses avanços tardios da IA, sempre há espaço para melhorias.
E é precisamente aqui que entra a engenharia imediata!
Entre neste campo que pode aumentar significativamente a produtividade dos modelos de IA.
Vamos descobrir tudo juntos!
A engenharia imediata é um domínio de rápido crescimento dentro da IA que se concentra em melhorar a eficiência e a eficácia dos modelos de linguagem. É tudo uma questão de criar prompts perfeitos para guiar os modelos de IA para produzir os resultados desejados.
Pense nisso como aprender como dar instruções melhores a alguém para garantir que ele entenda e execute uma tarefa corretamente.
Por que a Prompt Engineering é importante
- Produtividade Aprimorada: Ao usar prompts de alta qualidade, os modelos de IA podem gerar respostas mais precisas e relevantes. Isso significa menos tempo gasto em correções e mais tempo aproveitando os recursos da IA.
- Eficiência de custos: O treinamento de modelos de IA consome muitos recursos. A engenharia de prompts pode reduzir a necessidade de reciclagem, otimizando o desempenho do modelo por meio de prompts melhores.
- Versatilidade: Um prompt bem elaborado pode tornar os modelos de IA mais versáteis, permitindo-lhes enfrentar uma gama mais ampla de tarefas e desafios.
Antes de mergulhar nas técnicas mais avançadas, vamos relembrar duas das técnicas de engenharia imediata mais úteis (e básicas).
Pensamento Sequencial com “Vamos pensar passo a passo”
Hoje é sabido que a precisão dos modelos LLM é significativamente melhorada ao adicionar a sequência de palavras “Vamos pensar passo a passo”.
Por que… você pode perguntar?
Bem, isso ocorre porque estamos forçando o modelo a dividir qualquer tarefa em várias etapas, garantindo assim que o modelo tenha tempo suficiente para processar cada uma delas.
Por exemplo, eu poderia desafiar o GPT3.5 com o seguinte prompt:
Se João tem 5 peras, come 2, compra mais 5 e dá 3 ao amigo, quantas peras ele tem?
O modelo me dará uma resposta imediatamente. Porém, se eu adicionar o final “Vamos pensar passo a passo”, estou forçando o modelo a gerar um processo de pensamento com múltiplas etapas.
Solicitação de poucos tiros
Embora o prompt Zero-shot se refira a pedir ao modelo para executar uma tarefa sem fornecer qualquer contexto ou conhecimento prévio, a técnica de prompt de poucos disparos implica que apresentemos ao LLM alguns exemplos de nossa saída desejada junto com alguma pergunta específica.
Por exemplo, se quisermos criar um modelo que defina qualquer termo usando um tom poético, pode ser muito difícil de explicar. Certo?
No entanto, poderíamos usar os seguintes prompts de poucos disparos para orientar o modelo na direção que desejamos.
Sua tarefa é responder em um estilo consistente e alinhado com o estilo a seguir.
: Ensine-me sobre resiliência.
: A resiliência é como uma árvore que se curva com o vento, mas nunca se quebra.
É a capacidade de se recuperar das adversidades e seguir em frente.
: Sua opinião aqui.
Se você ainda não experimentou, pode desafiar o GPT.
Porém, como tenho certeza que a maioria de vocês já conhece essas técnicas básicas, tentarei desafiá-los com algumas técnicas avançadas.
1. Solicitação de Cadeia de Pensamento (CoT)
Introduzido pela Google em 2022, este método envolve instruir o modelo a passar por vários estágios de raciocínio antes de entregar a resposta final.
Parece familiar, certo? Se sim, você está totalmente certo.
É como fundir o pensamento sequencial e a solicitação de poucos disparos.
Como?
Essencialmente, a solicitação do CoT direciona o LLM para processar informações sequencialmente. Isso significa que exemplificamos como resolver um primeiro problema com raciocínio em múltiplas etapas e depois enviamos ao modelo nossa tarefa real, esperando que ele emule uma cadeia de pensamento comparável ao responder à consulta real que queremos que ele resolva.
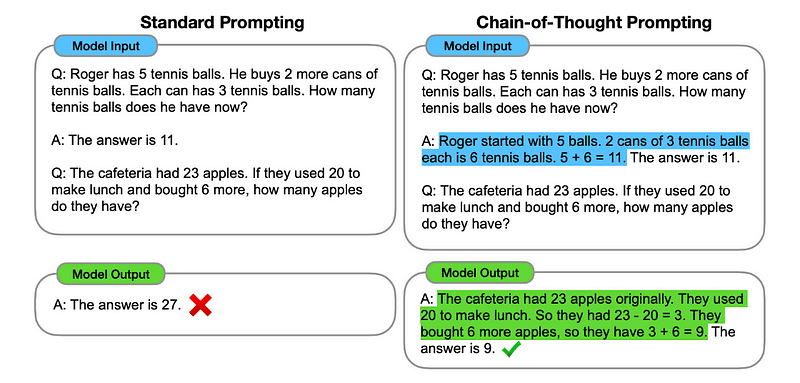
Imagem retirada do papel.
Assim, seguindo o primeiro exemplo, poderíamos fornecer um prompt com o primeiro problema e uma explicação sequencial de como resolvê-lo. Então, podemos enviar nossa opinião e ver como a mágica acontece!
Se João tem 5 peras, come 2, compra mais 5 e dá 3 ao amigo, quantas peras ele tem? Vamos pensar passo a passo.
Vamos passo a passo. John começa com 5 peras. Ele come 2 peras, então sobra 5–2 = 3 peras. Então, ele compra mais 5 peras. Então ele agora tem 3 + 5 = 8 peras. Finalmente, ele dá 3 peras ao amigo. Portanto, ele tem 8–3 = 5 peras restantes. Então, depois de todos esses passos, John tem 5 peras.
Sua opinião aqui.
Porém, a maioria de vocês deve estar pensando… Devo pensar em uma forma sequencial de resolver algum problema sempre que quiser perguntar algo no ChatGPT?
Bem… você não é o primeiro! E isso nos leva a…
2. Cadeia de Pensamento Automática (Auto-CoT)
Em 2022, Zhang e colegas introduziram um método para evitar este processo manual. Existem dois motivos principais para evitar qualquer tarefa manual:
- Pode ser chato.
- It can yield bad results – for instance, when our mental process is wrong.
They suggested using LLMs combined with the “Let’s think step by step” prompt to sequentially produce reasoning chains for each demonstration.
Isso significa perguntar ao ChatGPT como resolver qualquer problema sequencialmente e então usar este mesmo exemplo para treiná-lo como resolver qualquer outro problema.
3. Autoconsistência
A autoconsistência é outra técnica interessante de estímulo que visa melhorar a cadeia de pensamento que solicita problemas de raciocínio mais complexos.
Então… qual é a principal diferença?
A ideia principal da Autoconsistência é estar ciente de que podemos treinar o modelo com um exemplo errado. Imagine que eu resolvo o problema anterior com um processo mental errado:
Se João tem 5 peras, come 2, compra mais 5 e dá 3 ao amigo, quantas peras ele tem? Vamos pensar passo a passo.
Start with 5 pears. John eats 2 pears. Then, he gives 3 pears to his friend. These actions can be combined: 2 (eaten) + 3 (given) = 5 pears in total affected. Now, subtract the total pears affected from the initial 5 pears: 5 (initial) – 5 (affected) = 0 pears left.
Então, qualquer outra tarefa que eu enviar para o modelo estará errada.
É por isso que a Autoconsistência envolve amostragem de vários caminhos de raciocínio, cada um deles contendo uma cadeia de pensamento, e então deixar o LLM escolher o melhor e mais consistente caminho para resolver o problema.
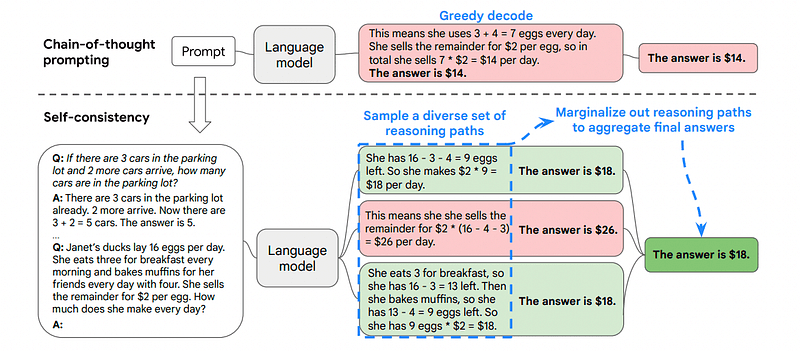
Imagem retirada do papel
Neste caso, e seguindo novamente o primeiro exemplo, podemos mostrar ao modelo diferentes formas de resolver o problema.
Se João tem 5 peras, come 2, compra mais 5 e dá 3 ao amigo, quantas peras ele tem?
Comece com 5 peras. João come 2 peras, ficando com 5–2 = 3 peras. Ele compra mais 5 peras, o que totaliza 3 + 5 = 8 peras. Finalmente, ele dá 3 peras ao amigo, então ele tem 8–3 = 5 peras restantes.
Se João tem 5 peras, come 2, compra mais 5 e dá 3 ao amigo, quantas peras ele tem?
Start with 5 pears. He then buys 5 more pears. John eats 2 pears now. These actions can be combined: 2 (eaten) + 5 (bought) = 7 pears in total. Subtract the pear that Jon has eaten from the total amount of pears 7 (total amount) – 2 (eaten) = 5 pears left.
Sua opinião aqui.
E aí vem a última técnica.
4. Solicitação de conhecimento geral
Uma prática comum de engenharia imediata é aumentar uma consulta com conhecimento adicional antes de enviar a chamada final da API para GPT-3 ou GPT-4.
De acordo com o Jiacheng Liu e companhia, sempre podemos agregar algum conhecimento a qualquer solicitação para que o LLM conheça melhor a questão.
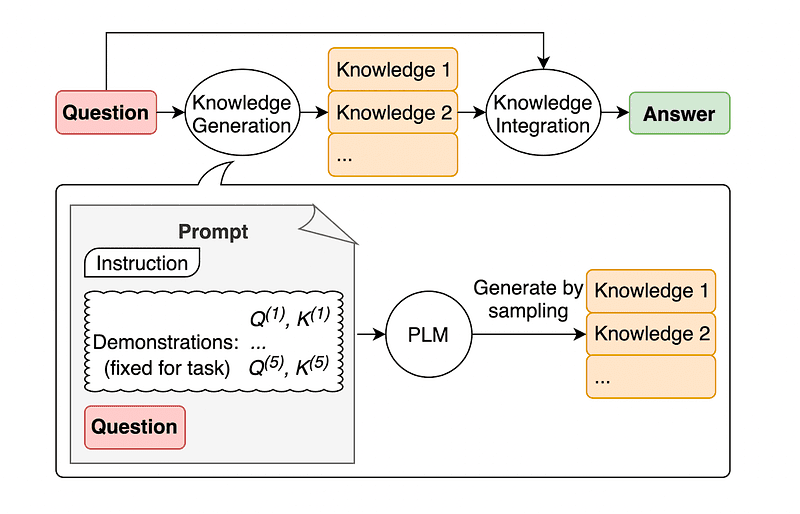
Imagem retirada do papel.
Assim, por exemplo, ao perguntar ao ChatGPT se parte do golfe está tentando obter um total de pontos maior do que outros, isso nos validará. Mas o objetivo principal do golfe é exatamente o oposto. É por isso que podemos agregar algum conhecimento prévio dizendo “O jogador com menor pontuação vence”.

Então... qual é a parte engraçada se estamos dizendo ao modelo exatamente a resposta?
Neste caso, esta técnica é utilizada para melhorar a forma como o LLM interage conosco.
So rather than pulling supplementary context from an outside database, the paper’s authors recommend having the LLM produce its own knowledge. This self-generated knowledge is then integrated into the prompt to bolster commonsense reasoning and give better outputs.
Então é assim que os LLMs podem ser melhorados sem aumentar seu conjunto de dados de treinamento!
A engenharia imediata emergiu como uma técnica fundamental para aprimorar os recursos do LLM. Ao iterar e melhorar os prompts, podemos comunicar de forma mais direta com os modelos de IA e, assim, obter resultados mais precisos e contextualmente relevantes, economizando tempo e recursos.
Para entusiastas de tecnologia, cientistas de dados e criadores de conteúdo, compreender e dominar a engenharia imediata pode ser um recurso valioso para aproveitar todo o potencial da IA.
Ao combinar prompts de entrada cuidadosamente projetados com essas técnicas mais avançadas, ter o conjunto de habilidades de engenharia de prompts sem dúvida lhe dará uma vantagem nos próximos anos.
Joseph Ferrer é um engenheiro analítico de Barcelona. Formou-se em engenharia física e atualmente trabalha na área de Data Science aplicada à mobilidade humana. Ele é um criador de conteúdo em tempo parcial focado em ciência e tecnologia de dados. Você pode contatá-lo em LinkedIn, Twitter or Médio.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :tem
- :é
- :não
- :onde
- $UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- habilidade
- Sobre
- precisão
- preciso
- ações
- real
- adicionar
- acrescentando
- Adicional
- avançado
- Depois de
- novamente
- AI
- Modelos de IA
- visa
- alinhado
- muito parecido
- Todos os Produtos
- Permitindo
- juntamente
- já
- sempre
- am
- quantidade
- an
- analítica
- e
- Outro
- responder
- qualquer
- api
- aplicado
- SOMOS
- AS
- perguntar
- pergunta
- ativo
- autores
- Automático
- evitar
- consciente
- longe
- em caminho duplo
- Mau
- Barcelona
- basic
- BE
- Porque
- sido
- antes
- ser
- MELHOR
- Melhor
- reforçar
- impulsionar
- Chato
- ambos
- comprou
- ressalto
- Break
- quebra
- Traz
- mais amplo
- mas a
- Compra
- by
- chamada
- CAN
- capacidades
- cuidadosamente
- casas
- cadeia
- correntes
- desafiar
- desafios
- ChatGPT
- Escolha
- colegas
- combinado
- combinando
- como
- vem
- vinda
- comum
- comunicar
- comparável
- completar
- integrações
- considerado
- consistente
- Contacto
- conteúdo
- criadores de conteúdo
- contexto
- Correções
- corretamente
- poderia
- criado
- criador
- criadores
- Atualmente
- dados,
- ciência de dados
- banco de dados
- Define
- entregando
- projetado
- desejado
- diferença
- diferente
- diretamente
- direção
- descobrir
- mergulho
- do
- parece
- domínio
- domínios
- down
- cada
- borda
- eficácia
- eficiência
- emergiu
- engenheiro
- Engenharia
- aumentar
- aprimorando
- suficiente
- garantir
- entusiastas
- exatamente
- exemplo
- exemplos
- executar
- esperando
- Explicação
- explicação
- familiar
- poucos
- campo
- final
- Finalmente
- Primeiro nome
- focado
- concentra-se
- seguinte
- Escolha
- forçando
- para a frente
- amigos
- da
- cheio
- engraçado
- Geral
- gerar
- ter
- OFERTE
- dado
- dá
- Go
- meta
- golfe
- Bom estado, com sinais de uso
- guia
- Queijos duros
- Aproveitamento
- Ter
- ter
- he
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- alta qualidade
- superior
- ele
- sua
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- humano
- inteligência humana
- i
- idéia
- if
- fotografia
- melhorar
- melhorado
- melhoria
- melhorar
- in
- aumentando
- INFORMAÇÕES
- do estado inicial,
- entrada
- instância
- instruções
- integrado
- Inteligência
- interage
- interessante
- para dentro
- introduzido
- envolve
- IT
- ESTÁ
- banheiro
- jon
- apenas por
- KDnuggetsGenericName
- Guarda
- chutar
- Kicks
- Saber
- Conhecimento
- sabe
- língua
- Sobrenome
- Atrasado
- Leads
- Saltar
- aprendizagem
- partida
- esquerda
- menos
- deixar
- de locação
- aproveitando
- como
- diminuir
- mágica
- a Principal
- fazer
- Fazendo
- maneira
- manual
- muitos
- Dominar
- Importância
- me
- significa
- mental
- fusão
- método
- poder
- mobilidade
- modelo
- modelos
- mais
- a maioria
- em movimento
- múltiplo
- devo
- você merece...
- nunca
- não
- agora
- obter
- of
- on
- uma vez
- oposto
- otimizando
- or
- Outros
- Outros
- A Nossa
- Fora
- saída
- outputs
- lado de fora
- próprio
- Papel
- parte
- caminho
- perfeita
- realizar
- atuação
- Física
- essencial
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogador
- ponto
- potencial
- prática
- justamente
- presente
- bastante
- anterior
- Problema
- problemas
- processo
- produzir
- produtividade
- fornecer
- fornecendo
- puxando
- questão
- bastante
- alcance
- em vez
- reais
- razões
- recomendar
- reduzir
- refere-se
- relevante
- solicitar
- resiliência
- uso intensivo de recursos
- Recursos
- responder
- resposta
- respostas
- Resultados
- reciclagem
- Revolução
- certo
- Quarto
- s
- mesmo
- poupança
- Ciência
- Ciência e Tecnologia
- cientistas
- Ponto
- Vejo
- enviar
- envio
- Seqüência
- conjunto
- vários
- mostrar
- de forma considerável
- habilidade
- So
- unicamente
- RESOLVER
- Resolvendo
- alguns
- Alguém
- algo
- específico
- gasto
- Estágio
- começo
- começa
- dirigir
- Passo
- Passos
- Ainda
- estilo
- certo
- equipamento
- tomado
- Tarefa
- tarefas
- tecnologia
- técnica
- técnicas
- Tecnologia
- dizendo
- prazo
- do que
- que
- A
- Eles
- então
- Lá.
- assim sendo
- Este
- deles
- think
- Pensando
- isto
- pensamento
- Através da
- Assim
- tempo
- para
- TOM
- Total
- TOTALMENTE
- Trem
- Training
- árvore
- experimentado
- tentar
- tentando
- dois
- final
- para
- sofrer
- compreender
- compreensão
- sem dúvida
- us
- usar
- usava
- utilização
- VALIDAR
- Valioso
- vário
- versátil
- muito
- queremos
- Caminho..
- maneiras
- we
- bem conhecido
- foram
- quando
- qual
- porque
- precisarão
- vento
- de
- dentro
- sem
- Word
- trabalhar
- mundo
- Errado
- anos
- ainda
- Produção
- Você
- investimentos
- zefirnet