Imagem do autor
Neste post, exploraremos o novo modelo de código aberto de última geração chamado Mixtral 8x7b. Também aprenderemos como acessá-lo usando a biblioteca LLaMA C++ e como executar grandes modelos de linguagem em computação e memória reduzidas.
Mixtral 8x7b é um modelo de mistura esparsa de especialistas (SMoE) de alta qualidade com pesos abertos, criado pela Mistral AI. Ele é licenciado sob Apache 2.0 e supera o Llama 2 70B na maioria dos benchmarks, ao mesmo tempo que possui inferência 6x mais rápida. Mixtral corresponde ou supera GPT3.5 na maioria dos benchmarks padrão e é o melhor modelo aberto em relação custo/desempenho.
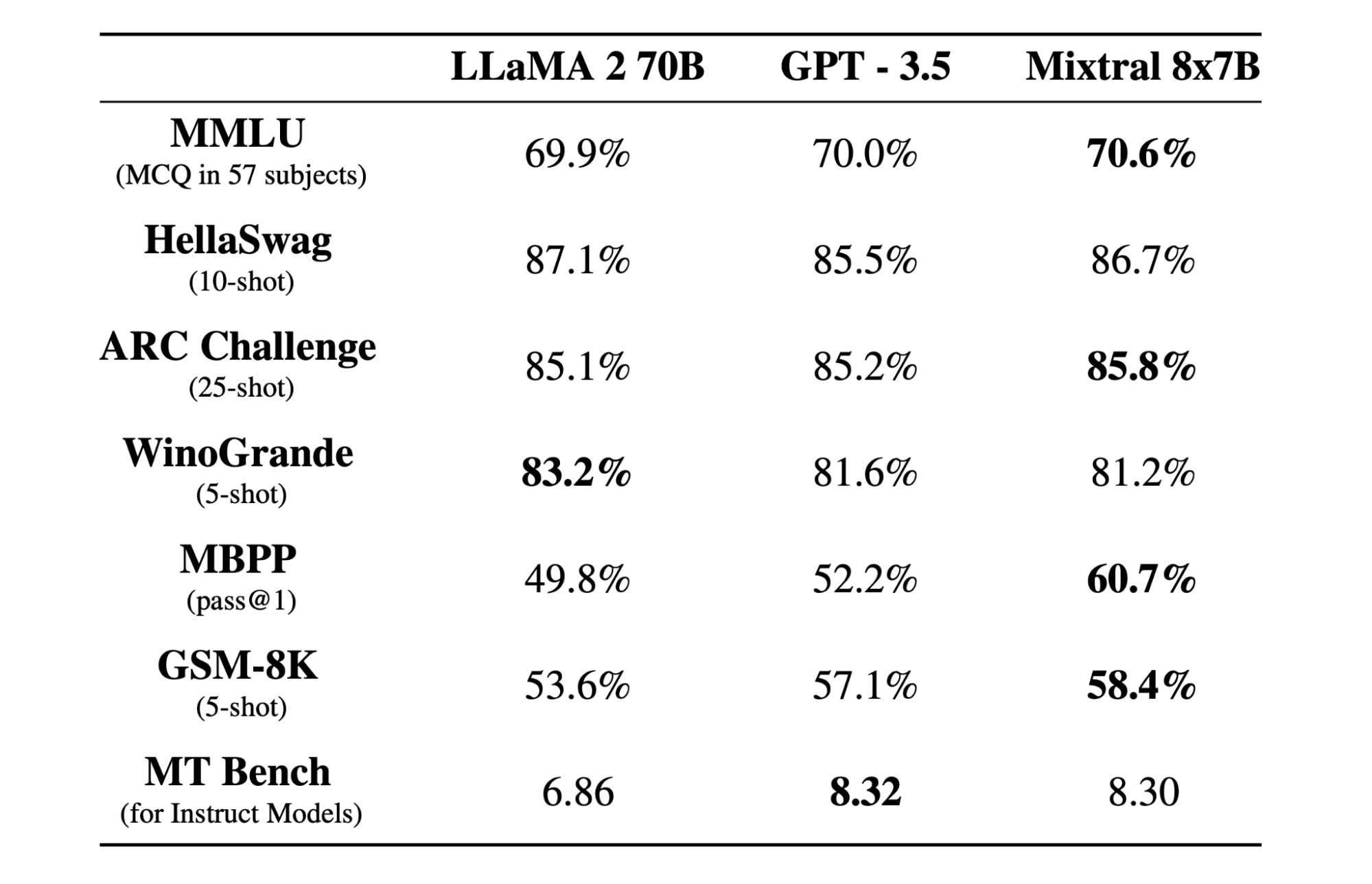
Imagem da Mixtral de especialistas
Mixtral 8x7B usa uma rede esparsa de mistura de especialistas apenas para decodificadores. Isso envolve um bloco feedforward selecionando entre 8 grupos de parâmetros, com uma rede de roteador escolhendo dois desses grupos para cada token, combinando suas saídas de forma aditiva. Este método melhora a contagem de parâmetros do modelo enquanto gerencia custos e latência, tornando-o tão eficiente quanto um modelo de 12.9B, apesar de ter um total de 46.7B de parâmetros.
O modelo Mixtral 8x7B se destaca no manuseio de um amplo contexto de tokens de 32 mil e oferece suporte a vários idiomas, incluindo inglês, francês, italiano, alemão e espanhol. Ele demonstra forte desempenho na geração de código e pode ser ajustado em um modelo de seguimento de instruções, alcançando altas pontuações em benchmarks como o MT-Bench.
LLaMA.cpp é uma biblioteca C/C++ que fornece uma interface de alto desempenho para grandes modelos de linguagem (LLMs) baseados na arquitetura LLM do Facebook. É uma biblioteca leve e eficiente que pode ser usada para diversas tarefas, incluindo geração de texto, tradução e resposta a perguntas. LLaMA.cpp oferece suporte a uma ampla variedade de LLMs, incluindo LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B e GPT4ALL. É compatível com todos os sistemas operacionais e pode funcionar tanto em CPUs quanto em GPUs.
Nesta seção, executaremos o aplicativo da web llama.cpp no Colab. Ao escrever algumas linhas de código, você poderá experimentar o desempenho do novo modelo de última geração em seu PC ou no Google Colab.
Iniciando
Primeiro, baixaremos o repositório GitHub llama.cpp usando a linha de comando abaixo:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDepois disso, mudaremos o diretório para o repositório e instalaremos o llama.cpp usando o comando `make`. Estamos instalando o llama.cpp para a GPU NVidia com CUDA instalado.
%cd llama.cpp
!make LLAMA_CUBLAS=1Baixe o modelo
Podemos baixar o modelo do Hugging Face Hub selecionando a versão apropriada do arquivo de modelo `.gguf`. Mais informações sobre várias versões podem ser encontradas em TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
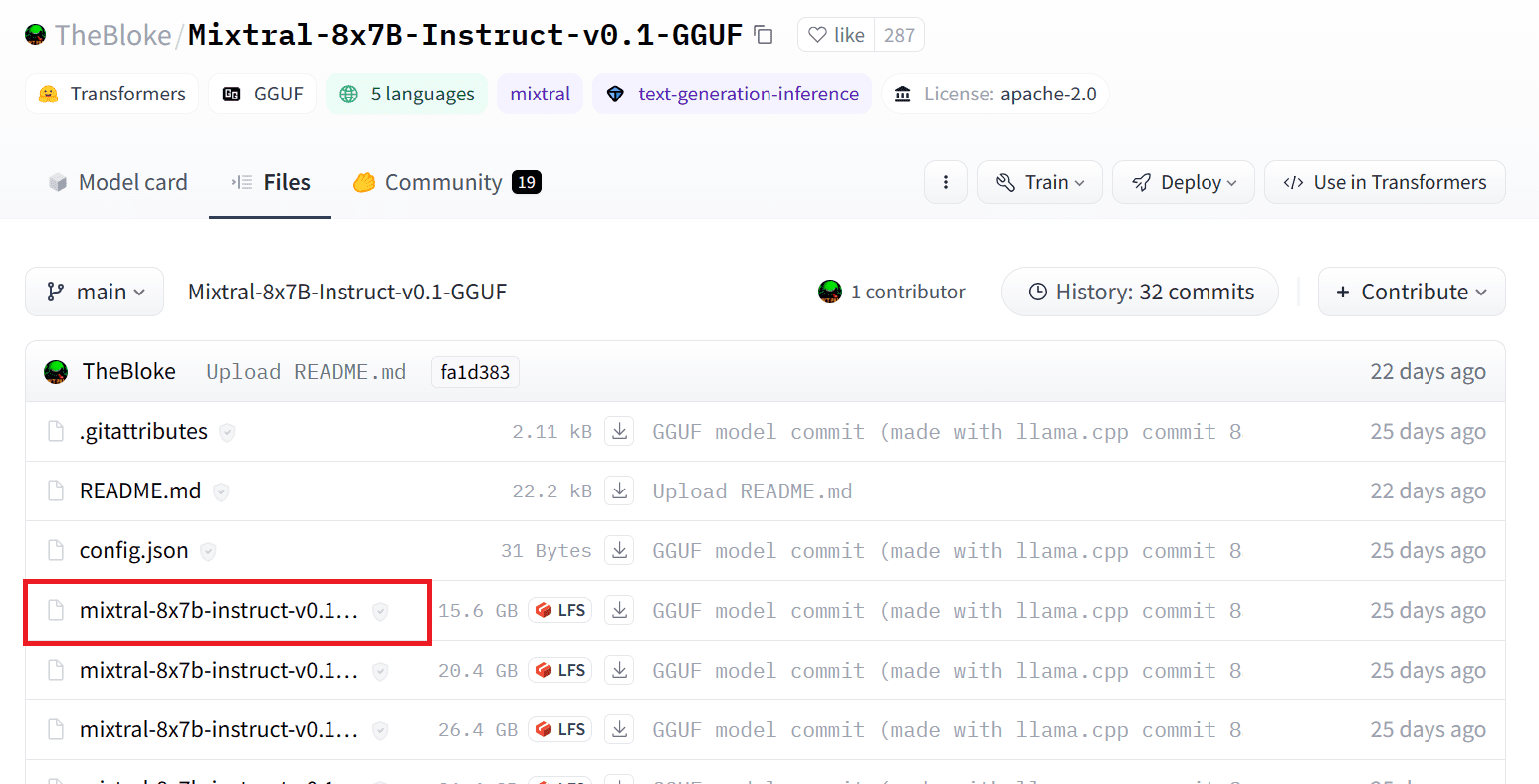
Imagem da TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Você pode usar o comando `wget` para baixar o modelo no diretório atual.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufEndereço Externo para Servidor LLaMA
Quando executamos o servidor LLaMA ele nos fornecerá um IP localhost que é inútil para nós no Colab. Precisamos da conexão com o proxy localhost usando a porta proxy do kernel Colab.
Após executar o código abaixo, você obterá o hiperlink global. Usaremos este link para acessar nosso webapp posteriormente.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Executando o servidor
Para executar o servidor LLaMA C++, você precisa fornecer ao comando do servidor a localização do arquivo de modelo e o número da porta correto. É importante certificar-se de que o número da porta corresponde ao que iniciamos na etapa anterior para a porta proxy.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
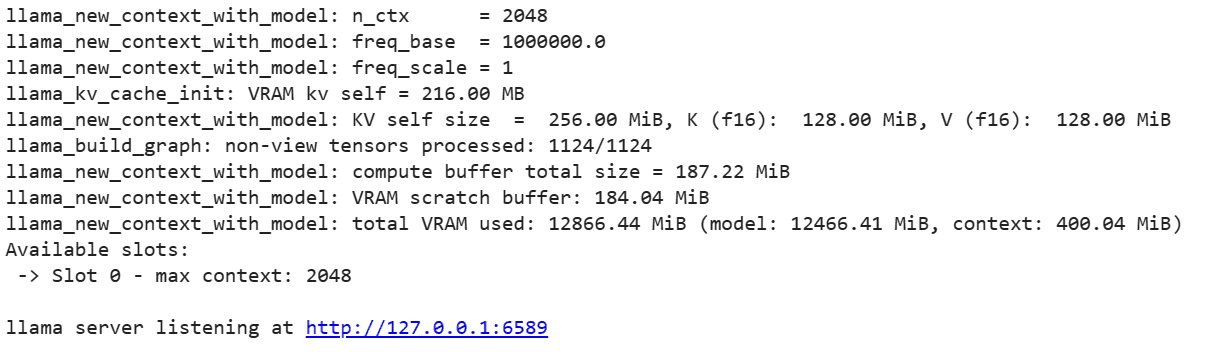
O webapp de chat pode ser acessado clicando no hiperlink da porta proxy na etapa anterior, pois o servidor não está rodando localmente.
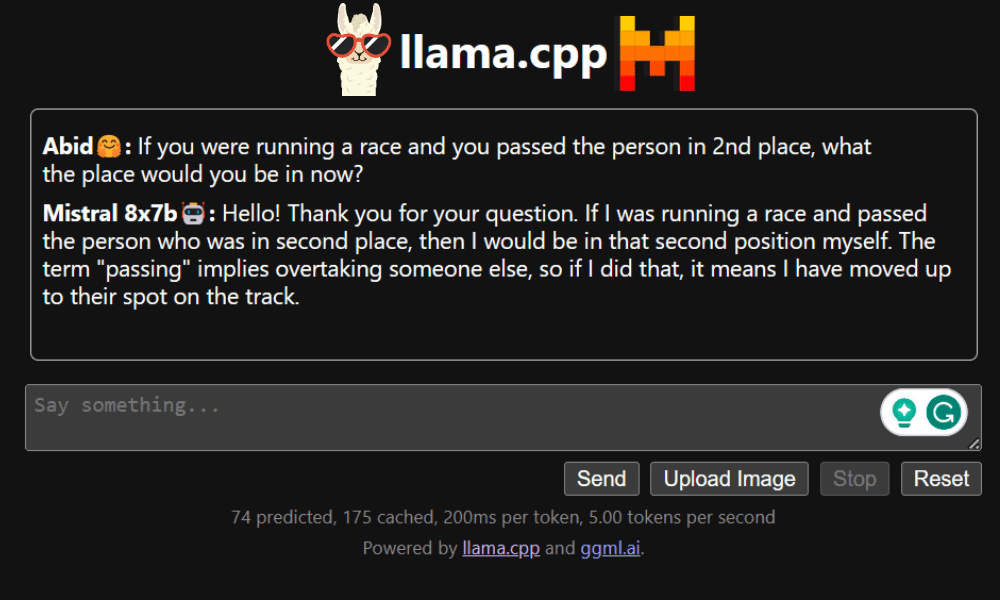
Aplicativo Web LLaMA C++
Antes de começarmos a usar o chatbot, precisamos personalizá-lo. Substitua “LLaMA” pelo nome do seu modelo na seção de prompt. Além disso, modifique o nome do usuário e o nome do bot para distinguir entre as respostas geradas.
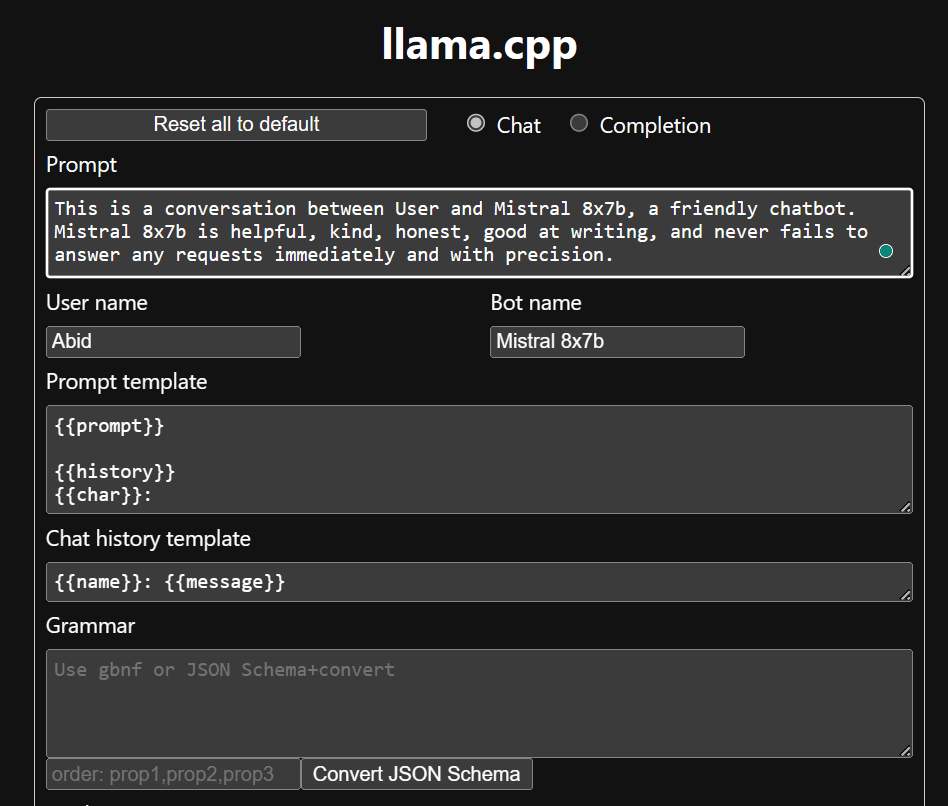
Comece a conversar rolando para baixo e digitando na seção de bate-papo. Sinta-se à vontade para fazer perguntas técnicas que outros modelos de código aberto não conseguiram responder adequadamente.
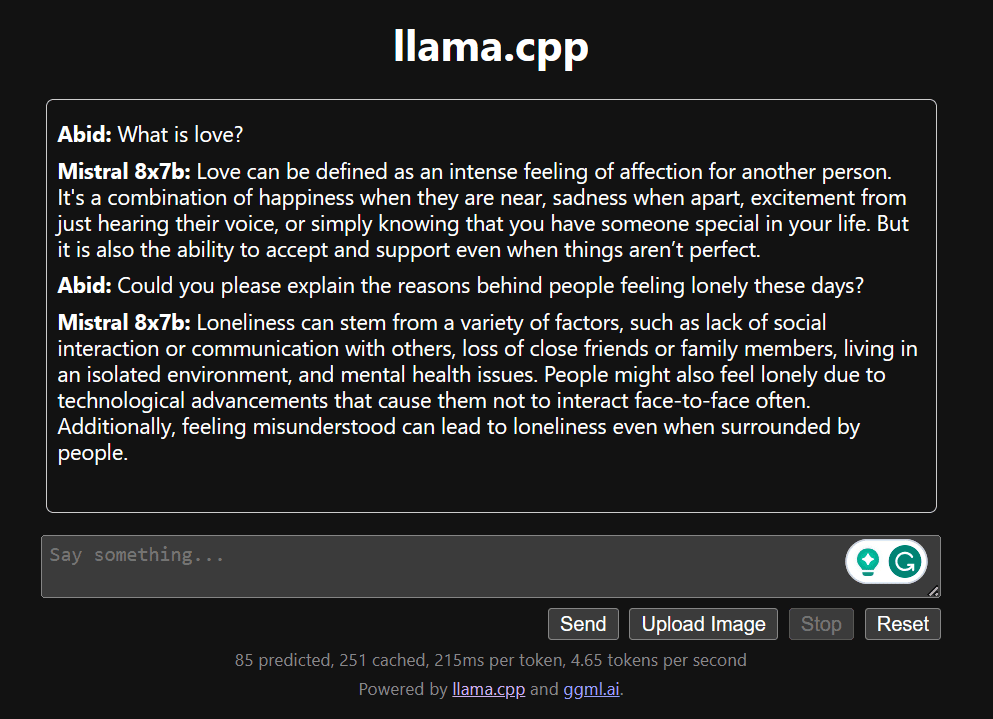
Se você encontrar problemas com o aplicativo, tente executá-lo sozinho usando meu Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Este tutorial fornece um guia completo sobre como executar o modelo avançado de código aberto, Mixtral 8x7b, no Google Colab usando a biblioteca LLaMA C++. Comparado a outros modelos, o Mixtral 8x7b oferece desempenho e eficiência superiores, tornando-o uma excelente solução para quem deseja experimentar grandes modelos de linguagem, mas não possui extensos recursos computacionais. Você pode executá-lo facilmente em seu laptop ou em uma computação em nuvem gratuita. É fácil de usar e você pode até implantar seu aplicativo de bate-papo para que outras pessoas possam usar e experimentar.
Espero que você tenha achado útil esta solução simples para executar o modelo grande. Estou sempre em busca de opções simples e melhores. Se você tiver uma solução ainda melhor, por favor me avise e eu abordarei isso na próxima vez.
Abid Ali Awan (@ 1abidaliawan) é um profissional de cientista de dados certificado que adora criar modelos de aprendizado de máquina. Atualmente, ele está se concentrando na criação de conteúdo e escrevendo blogs técnicos sobre tecnologias de aprendizado de máquina e ciência de dados. Abid é mestre em Gestão de Tecnologia e bacharel em Engenharia de Telecomunicações. Sua visão é construir um produto de IA usando uma rede neural gráfica para estudantes que lutam contra doenças mentais.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :é
- :não
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Capaz
- Acesso
- acessadas
- alcançar
- Adicionalmente
- endereço
- avançado
- AI
- Todos os Produtos
- tb
- sempre
- am
- an
- e
- responder
- apache
- app
- Aplicação
- apropriado
- arquitetura
- SOMOS
- AS
- perguntar
- baseado
- BE
- começar
- abaixo
- benchmarks
- MELHOR
- Melhor
- entre
- Bloquear
- Blogs
- Bot
- ambos
- construir
- Prédio
- mas a
- by
- C + +
- chamado
- CAN
- Non-GMO
- alterar
- bate-papo
- chatbot
- conversando
- escolha
- Na nuvem
- código
- combinando
- comparado
- compatível
- compreensivo
- computacional
- Computar
- computação
- da conexão
- conteúdo
- Criação de conteúdo
- contexto
- correta
- Custo
- cobrir
- criado
- criação
- Atual
- Atualmente
- personalizar
- dados,
- ciência de dados
- cientista de dados
- Grau
- entrega
- demonstra
- implantar
- Apesar de
- distinguir
- do
- down
- download
- cada
- facilmente
- eficiência
- eficiente
- encontro
- Engenharia
- Inglês
- Melhora
- Mesmo
- excelente
- vasta experiência
- experimentar
- especialistas
- explorar
- extenso
- Rosto
- fracassado
- falcão
- mais rápido
- sentir
- poucos
- Envie o
- focando
- Escolha
- encontrado
- Gratuito
- Francês
- da
- função
- gerado
- geração
- Alemão
- ter
- GitHub
- OFERTE
- Global
- GPU
- GPUs
- gráfico
- Rede Neural do Gráfico
- Do grupo
- guia
- Manipulação
- Ter
- ter
- he
- útil
- Alta
- alta performance
- alta qualidade
- sua
- detém
- esperança
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- Hub
- i
- if
- doença
- importar
- importante
- in
- Incluindo
- INFORMAÇÕES
- iniciado
- instalar
- instalando
- Interface
- para dentro
- envolve
- IP
- questões
- IT
- Italiano
- KDnuggetsGenericName
- Saber
- língua
- Idiomas
- laptop
- grande
- Latência
- mais tarde
- APRENDER
- aprendizagem
- deixar
- Biblioteca
- Licenciado
- leve
- como
- Line
- linhas
- LINK
- lhama
- localmente
- localização
- procurando
- ama
- máquina
- aprendizado de máquina
- fazer
- Fazendo
- de grupos
- gestão
- dominar
- fósforos
- me
- Memória
- mental
- Doença mental
- método
- mistura
- modelo
- modelos
- modificar
- mais
- a maioria
- múltiplo
- my
- nome
- você merece...
- rede
- Neural
- rede neural
- Novo
- Próximo
- número
- Nvidia
- of
- on
- ONE
- aberto
- open source
- operando
- sistemas operacionais
- Opções
- or
- Outros
- Outros
- A Nossa
- Supera o desempenho
- saída
- outputs
- próprio
- parâmetro
- parâmetros
- PC
- atuação
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- Publique
- anterior
- Produto
- profissional
- devidamente
- fornecer
- fornece
- procuração
- questão
- Frequentes
- alcance
- Reduzido
- em relação a
- substituir
- repositório
- pesquisa
- Recursos
- respostas
- roteador
- Execute
- corrida
- s
- Ciência
- Cientista
- pontuações
- rolagem
- Seção
- selecionando
- servidor
- simples
- desde
- solução
- fonte
- Espanhol
- padrão
- estado-da-arte
- Passo
- mais forte,
- Lutando
- Estudantes
- topo
- suportes
- certo
- sistemas
- tarefas
- Dados Técnicos:
- Tecnologias
- Tecnologia
- telecomunicação
- texto
- geração de texto
- que
- A
- deles
- Este
- isto
- aqueles
- tempo
- para
- token
- Tokens
- Total
- Tradução
- tentar
- tutorial
- dois
- para
- us
- usar
- usava
- Utilizador
- user-friendly
- usos
- utilização
- variedade
- vário
- versão
- visão
- queremos
- we
- web
- Aplicativo da Web
- qual
- enquanto
- QUEM
- Largo
- Ampla variedade
- precisarão
- de
- escrita
- Você
- investimentos
- zefirnet