O tempo de execução do Amazon EMR para Apache Spark é um tempo de execução com desempenho otimizado para Apache Spark que é 100% compatível com API com Apache Spark de código aberto. Com Amazon EMR versão 6.9.0, o tempo de execução do EMR para Apache Spark oferece suporte ao Spark equivalente versão 3.3.0.
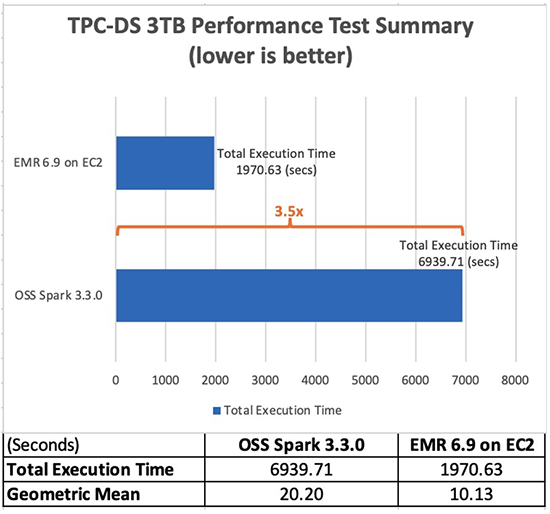
Com o Amazon EMR 6.9.0, agora você pode executar aplicativos Apache Spark 3.x com mais rapidez e custo menor, sem exigir alterações em seus aplicativos. Em nossos testes de benchmark de desempenho, derivados de testes de desempenho TPC-DS em escala de 3 TB, descobrimos que o tempo de execução do EMR para Apache Spark 3.3.0 fornece uma melhoria de desempenho de 3.5 vezes (usando o tempo de execução total), em média, em relação ao Apache Spark 3.3.0 de código aberto. XNUMX.
Neste post, analisamos os resultados dos nossos testes de benchmark executando uma aplicação TPC-DS em Apache Spark de código aberto e depois no Amazon EMR 6.9, que vem com um tempo de execução otimizado do Spark compatível com o Spark de código aberto. Passamos por uma análise de custos detalhada e, finalmente, fornecemos instruções passo a passo para executar o benchmark.
Resultados observados
Para avaliar as melhorias de desempenho, usamos um utilitário de teste de desempenho Spark de código aberto derivado do kit de ferramentas de teste de desempenho TPC-DS. Executamos os testes em um cluster EMR c5d.9xlarge de sete nós (seis nós principais e um nó primário) com o tempo de execução EMR para Apache Spark e um segundo cluster autogerenciado de sete nós em Amazon Elastic Compute Nuvem (Amazon EC2) com a versão de código aberto equivalente do Spark. Executamos ambos os testes com dados em Serviço de armazenamento simples da Amazon (Amazônia S3).
A alocação dinâmica de recursos (DRA) é um ótimo recurso para usar em diversas cargas de trabalho. No entanto, para um exercício de benchmarking onde comparamos duas plataformas puramente em termos de desempenho, e os volumes de dados de teste não mudam (3 TB no nosso caso), acreditamos que é melhor evitar a variabilidade para realizar uma comparação comparativa. Em nossos testes no Spark de código aberto e no Amazon EMR, desabilitamos o DRA durante a execução do aplicativo de benchmarking.
A tabela a seguir mostra o tempo total de execução do trabalho para todas as consultas (em segundos) no conjunto de dados de consulta de 3 TB entre o Amazon EMR versão 6.9.0 e o Spark versão 3.3.0 de código aberto. Observamos que nossos testes TPC-DS tiveram um tempo de execução total de trabalho no Amazon EMR no Amazon EC2 que foi 3.5 vezes mais rápido do que usando um cluster Spark de código aberto com a mesma configuração.
A aceleração por consulta no Amazon EMR 6.9 com e sem o tempo de execução do EMR para Apache Spark é ilustrada no gráfico a seguir. O eixo horizontal mostra cada consulta no benchmark de 3 TB. O eixo vertical mostra a aceleração de cada consulta devido ao tempo de execução do EMR. Ganhos notáveis de desempenho são 10 vezes mais rápidos para consultas TPC-DS 24b, 72, 95 e 96.

Análise de custos
As melhorias de desempenho do tempo de execução do EMR para Apache Spark se traduzem diretamente em custos mais baixos. Conseguimos obter uma economia de custos de 67% executando o aplicativo de benchmark no Amazon EMR em comparação com o custo incorrido para executar o mesmo aplicativo no Spark de código aberto no Amazon EC2 com o mesmo tamanho de cluster devido às horas reduzidas de Amazon EMR e Amazon Uso de EC2. A definição de preço do Amazon EMR é para aplicativos EMR executados em clusters EMR com instâncias EC2. O preço do Amazon EMR é adicionado aos preços subjacentes de computação e armazenamento, como preço da instância do EC2 e Loja de blocos elásticos da Amazon Custo (Amazon EBS) (se anexar volumes EBS). No geral, o custo de referência estimado na região Leste dos EUA (Norte da Virgínia) é de US$ 27.01 por execução para o Spark de código aberto no Amazon EC2 e de US$ 8.82 por execução para o Amazon EMR.
| Trabalho de referência | Tempo de execução (hora) | Custo estimado | Instância total do EC2 | vCPU total | Memória Total (GiB) | Dispositivo raiz (Amazon EBS) |
|
Spark de código aberto no Amazon EC2 (1 nó principal e 6 nós principais) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR no Amazon EC2 (1 nó principal e 6 nós principais) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Repartição de custos
A seguir está o detalhamento dos custos do trabalho de código aberto Spark no Amazon EC2 (US$ 27.01):
- Custo total do Amazon EC2 – (7 * $ 1.728 * 2.23) = (número de instâncias * c5d.9xlarge taxa horária * tempo de execução do job em hora) = $ 26.97
- Custo do Amazon EBS – (US$ 0.1/730 * 20 * 7 * 2.23) = (taxa horária do Amazon EBS por GB * tamanho raiz do EBS * número de instâncias * tempo de execução do trabalho em hora) = US$ 0.042
A seguir está o detalhamento dos custos do trabalho do Amazon EMR no Amazon EC2 (US$ 8.82):
- Custo total do Amazon EMR – (7 * US$ 0.27 * 0.63) = ((número de nós principais + número de nós primários)* c5d.9xlarge Preço do Amazon EMR * tempo de execução do trabalho em hora) = US$ 1.19
- Custo total do Amazon EC2 – (7 * US$ 1.728 * 0.63) = ((número de nós principais + número de nós primários)* preço da instância c5d.9xlarge * tempo de execução do trabalho em hora) = US$ 7.62
- Custo do Amazon EBS – (US$ 0.1/730 * 20 GiB * 7 * 0.63) = (taxa horária do Amazon EBS por GB * tamanho do EBS * número de instâncias * tempo de execução do trabalho em hora) = US$ 0.012
Configurar benchmarking do OSS Spark
Nas seções a seguir, fornecemos um breve resumo das etapas envolvidas na configuração do benchmarking. Para obter instruções detalhadas com exemplos, consulte o GitHub repo.
Para nosso benchmarking OSS Spark, usamos a ferramenta de código aberto Pedra de pederneira para lançar nosso Amazon EC2 baseado Apache Spark conjunto. O Flintrock oferece uma maneira rápida de executar um cluster Apache Spark no Amazon EC2 usando a linha de comando.
Pré-requisitos
Conclua as seguintes etapas de pré-requisito:
- Tenha Python 3.7.x ou superior.
- Tenha Pip3 22.2.2 ou superior.
- Adicione o diretório bin do Python ao caminho do seu ambiente. O binário Flintrock será instalado neste caminho.
- Execute
aws configurepara configurar o seu Interface de linha de comando da AWS (AWS CLI) para apontar para a conta de benchmarking. Referir-se Configuração rápida com aws configure para obter instruções. - Tenha um par de chaves com permissões de arquivo restritivas para acessar o nó primário do OSS Spark.
- Crie um novo bucket S3 em sua conta de teste, se necessário.
- Copie os dados de origem TPC-DS como entrada para seu bucket S3.
- Crie o aplicativo de benchmark seguindo as etapas fornecidas em Etapas para construir um aplicativo spark-benchmark-assembly. Alternativamente, você pode baixar um pré-construído spark-benchmark-assembly-3.3.0.jar se você deseja um aplicativo baseado no Spark 3.3.0.
Implante o cluster Spark e execute o trabalho de benchmark
Conclua as seguintes etapas:
- Instale a ferramenta Flintrock via pip conforme mostrado em Etapas para configurar o OSS Spark Benchmarking.
- Execute o comando flintrock configure, que exibe um arquivo de configuração padrão.
- Modifique o padrão
config.yamlarquivo com base em suas necessidades. Alternativamente, copie e cole o arquivo config.yaml conteúdo para o arquivo de configuração padrão. Em seguida, salve o arquivo onde ele estava. - Por fim, inicie o cluster Spark de 7 nós no Amazon EC2 via Flintrock.
Isso deve criar um cluster Spark com um nó primário e seis nós de trabalho. Se você vir alguma mensagem de erro, verifique novamente os valores do arquivo de configuração, especialmente as versões Spark e Hadoop e os atributos de download-source e AMI.
O cluster OSS Spark não vem com gerenciador de recursos YARN. Para habilitá-lo, precisamos configurar o cluster.
- Faça o download do fio-site.xml e habilitar-yarn.sh arquivos do repositório GitHub.
- Substitua pelo endereço IP do nó primário em seu cluster Flintrock.
Você pode recuperar o endereço IP do console do Amazon EC2.
- Faça upload dos arquivos para todos os nós do cluster Spark.
- Execute o script enable-yarn.
- Habilite o suporte ao Snappy no Hadoop (o trabalho de benchmark lê dados compactados do Snappy).
- Baixe o arquivo JAR do aplicativo utilitário de benchmark spark-benchmark-assembly-3.3.0.jar para sua máquina local.
- Copie esse arquivo para o cluster.
- Faça login no nó primário e inicie o YARN.
- Envie o trabalho de benchmark no cluster Spark de código aberto, conforme mostrado em Envie o trabalho de referência.
Resumir os resultados
Baixe o arquivo de resultado do teste do bucket S3 de saída s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Substituir $YOUR_S3_BUCKET pelo nome do bucket do S3.) Você pode usar o console do Amazon S3 e navegar até o local de saída do S3 ou usar a AWS CLI.
O aplicativo de benchmark Spark cria uma pasta de carimbo de data/hora e grava um arquivo de resumo dentro de um prefixo summary.csv. Seu carimbo de data/hora e nome de arquivo serão diferentes daqueles mostrados no exemplo anterior.
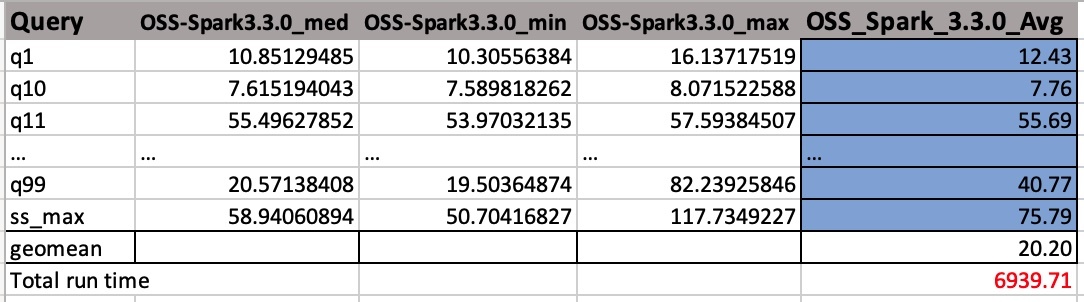
Os arquivos CSV de saída possuem quatro colunas sem nomes de cabeçalho. Eles são:
- Nome da consulta
- Tempo médio
- Tempo mínimo
- Tempo máximo
A captura de tela a seguir mostra um exemplo de saída. Adicionamos nomes de colunas manualmente. A forma como calculamos a média geográfica e o tempo total de execução do trabalho é baseada em médias aritméticas. Primeiro, calculamos a média dos valores médio, mínimo e máximo usando a fórmula AVERAGE(B2:D2). Em seguida, tomamos uma média geométrica da coluna Avg usando a fórmula GEOMEAN(E2:E105).
Configurar benchmarking do Amazon EMR
Para obter instruções detalhadas, consulte Etapas para configurar o benchmarking EMR.
Pré-requisitos
Conclua as seguintes etapas de pré-requisito:
- Execute
aws configurepara configurar o shell da AWS CLI para apontar para a conta de benchmarking. Referir-se Configuração rápida com aws configure para obter instruções. - Carregue o aplicativo de benchmark no Amazon S3.
Implante o cluster do EMR e execute o job de benchmark
Conclua as seguintes etapas:
- Ative o Amazon EMR no shell da AWS CLI usando a linha de comando, conforme mostrado em Implante o cluster EMR e execute o trabalho de benchmark.
- Configure o Amazon EMR com um nó primário (c5d.9xlarge) e seis nós principais (c5d.9xlarge). Referir-se criar-cluster para obter uma descrição detalhada das opções da AWS CLI.
- Armazene o ID do cluster da resposta. Você precisa disso na próxima etapa.
- Envie o trabalho de referência no Amazon EMR usando etapas adicionais na AWS CLI.
Resumir os resultados
Resuma os resultados do intervalo de saída s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT da mesma maneira que fizemos para os resultados do OSS e comparamos.
limpar
Para evitar cobranças futuras, exclua os recursos que você criou usando as instruções no Seção de limpeza do repositório GitHub.
- Pare os clusters EMR e OSS Spark. Você também pode excluí-los se não quiser reter o conteúdo. Você pode excluir esses recursos executando o script limpeza-benchmark-env.sh de um terminal em seu ambiente de benchmark.
- Se você usou Nuvem AWS9 como seu IDE para construir o arquivo JAR do aplicativo de benchmark usando Etapas para construir um aplicativo spark-benchmark-assembly, talvez você queira excluir o ambiente também.
Conclusão
Você pode executar cargas de trabalho do Apache Spark 3.5 vezes (com base no tempo de execução total) mais rápido e com menor custo, sem fazer alterações em seus aplicativos, usando o Amazon EMR 6.9.0.
Para se manter atualizado, assine o Big Data Blog’s feed RSS para saber mais sobre o tempo de execução do EMR para Apache Spark, práticas recomendadas de configuração e conselhos de ajuste.
Para testes de benchmark anteriores, consulte Execute cargas de trabalho do Apache Spark 3.0 1.7 vezes mais rápido com o tempo de execução do Amazon EMR para Apache Spark. Observe que o resultado do benchmark anterior de 1.7 vezes o desempenho foi baseado na média geométrica. Com base na média geométrica, o desempenho no Amazon EMR 6.9 foi duas vezes mais rápido.
Sobre os autores
 Sekar Srinivasan é Arquiteto de Soluções Especialista Sênior na AWS com foco em Big Data e Analytics. Sekar tem mais de 20 anos de experiência trabalhando com dados. Ele é apaixonado por ajudar os clientes a criar soluções escaláveis modernizando sua arquitetura e gerando insights de seus dados. Em seu tempo livre gosta de trabalhar em projetos sem fins lucrativos, especialmente aqueles voltados para a educação de crianças carentes.
Sekar Srinivasan é Arquiteto de Soluções Especialista Sênior na AWS com foco em Big Data e Analytics. Sekar tem mais de 20 anos de experiência trabalhando com dados. Ele é apaixonado por ajudar os clientes a criar soluções escaláveis modernizando sua arquitetura e gerando insights de seus dados. Em seu tempo livre gosta de trabalhar em projetos sem fins lucrativos, especialmente aqueles voltados para a educação de crianças carentes.
 Prabu Ravichandran é arquiteto de dados sênior da Amazon Web Services, com foco em análise, arquitetura e implementação de data lake. Ele ajuda os clientes a arquitetar e criar soluções escaláveis e robustas usando serviços da AWS. Nas horas vagas, Prabu gosta de viajar e passar tempo com a família.
Prabu Ravichandran é arquiteto de dados sênior da Amazon Web Services, com foco em análise, arquitetura e implementação de data lake. Ele ajuda os clientes a arquitetar e criar soluções escaláveis e robustas usando serviços da AWS. Nas horas vagas, Prabu gosta de viajar e passar tempo com a família.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 anos
- 7
- 9
- a
- Capaz
- Sobre
- acima
- Acesso
- Conta
- adicionado
- endereço
- conselho
- Todos os Produtos
- alocação
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- análise
- analítica
- analisar
- e
- apache
- Apache Spark
- api
- Aplicação
- aplicações
- arquitetura
- atributos
- média
- AVG
- AWS
- eixo
- baseado
- Acreditar
- referência
- MELHOR
- melhores práticas
- entre
- Grande
- Big Data
- Bloquear
- Breakdown
- construir
- Prédio
- casas
- alterar
- Alterações
- acusações
- de cores
- Agrupar
- Coluna
- colunas
- como
- comparar
- comparação
- compatível
- Computar
- Configuração
- cônsul
- conteúdo
- núcleo
- Custo
- economia de custos
- custos
- crio
- criado
- cria
- Clientes
- dados,
- lago data
- Data
- Padrão
- Derivado
- descrição
- detalhado
- dispositivo
- DID
- diferente
- diretamente
- inválido
- Não faz
- não
- download
- cada
- Leste
- ebs
- Educação
- permitir
- Meio Ambiente
- Equivalente
- erro
- especialmente
- estimou
- Éter (ETH)
- avaliar
- exemplo
- exemplos
- Exercício
- vasta experiência
- família
- mais rápido
- Característica
- Envie o
- Arquivos
- Finalmente
- Primeiro nome
- focado
- focalizado
- seguinte
- Fórmula
- encontrado
- Gratuito
- da
- futuro
- Ganhos
- gerando
- GitHub
- ótimo
- Hadoop
- ajuda
- ajuda
- Horizontal
- HORÁRIO
- Contudo
- HTML
- HTTPS
- implementação
- melhoria
- melhorias
- in
- entrada
- insights
- instância
- instruções
- envolvido
- IP
- Endereço IP
- IT
- Trabalho
- Guarda
- lago
- lançamento
- APRENDER
- Line
- local
- localização
- máquina
- Fazendo
- Gerente
- maneira
- manualmente
- max
- significa
- Memória
- mensagens
- mais
- nome
- nomes
- Navegar
- você merece...
- necessário
- Cria
- Novo
- Próximo
- nó
- nós
- sem fins lucrativos,
- notável
- número
- ONE
- open source
- otimizado
- Opções
- ordem
- Oss
- esboço
- global
- apaixonado
- passado
- caminho
- atuação
- permissões
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- Pops
- Publique
- práticas
- preço
- Valores
- preços
- primário
- privado
- projetos
- fornecer
- fornecido
- fornece
- puramente
- Python
- Links
- Taxa
- perceber
- Reduzido
- região
- liberar
- substituir
- recurso
- Recursos
- resposta
- Restritivo
- resultar
- Resultados
- uma conta de despesas robusta
- raiz
- Execute
- corrida
- mesmo
- Salvar
- Poupança
- escalável
- Escala
- Segundo
- segundo
- Seção
- seções
- senior
- Serviços
- contexto
- instalação
- concha
- rede de apoio social
- mostrando
- Shows
- simples
- SIX
- Tamanho
- Soluções
- fonte
- Faísca
- especialista
- Passar
- começo
- Passo
- Passos
- armazenamento
- Inscreva-se
- tal
- RESUMO
- ajuda
- suportes
- mesa
- Tire
- terminal
- teste
- testes
- A
- deles
- Através da
- tempo
- vezes
- timestamp
- para
- ferramenta
- kit de ferramentas
- Total
- traduzir
- Viagens
- subjacente
- desprivilegiado
- us
- Uso
- usar
- utilidade
- Valores
- versão
- via
- Virgínia
- volumes
- web
- serviços web
- qual
- enquanto
- precisarão
- sem
- Atividades:
- trabalhador
- trabalhar
- X
- XML
- yaml
- anos
- investimentos
- zefirnet