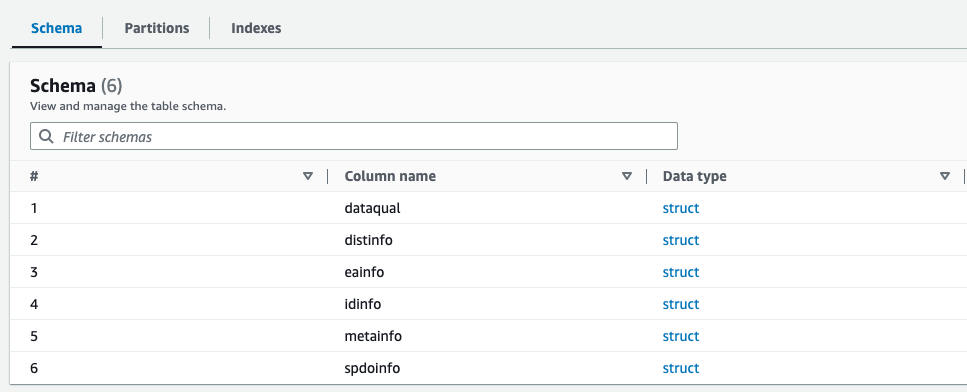
Na era digital de hoje, os dados estão no centro do sucesso de qualquer organização. Um dos formatos mais comumente usados para troca de dados é XML. A análise de arquivos XML é crucial por vários motivos. Em primeiro lugar, os arquivos XML são usados em muitos setores, incluindo finanças, saúde e governo. A análise de arquivos XML pode ajudar as organizações a obter insights sobre seus dados, permitindo-lhes tomar melhores decisões e melhorar suas operações. A análise de arquivos XML também pode ajudar na integração de dados, pois muitos aplicativos e sistemas usam XML como formato de dados padrão. Ao analisar arquivos XML, as organizações podem integrar facilmente dados de diferentes fontes e garantir a consistência em seus sistemas. No entanto, os arquivos XML contêm dados semiestruturados e altamente aninhados, dificultando o acesso e a análise das informações, especialmente se o arquivo for grande e tiver esquema complexo e altamente aninhado.
Os arquivos XML são adequados para aplicativos, mas podem não ser ideais para mecanismos de análise. Para melhorar o desempenho da consulta e permitir acesso fácil em mecanismos de análise downstream, como Amazona atena, é crucial pré-processar arquivos XML em um formato colunar como o Parquet. Essa transformação permite maior eficiência e usabilidade em fluxos de trabalho analíticos. Neste post, mostramos como processar dados XML usando Cola AWS e Atena.
Visão geral da solução
Exploramos duas técnicas distintas que podem agilizar seu fluxo de trabalho de processamento de arquivos XML:
- Técnica 1: use um rastreador AWS Glue e o editor visual AWS Glue – Você pode usar a interface do usuário do AWS Glue em conjunto com um rastreador para definir a estrutura da tabela para seus arquivos XML. Esta abordagem fornece uma interface amigável e é particularmente adequada para indivíduos que preferem uma abordagem gráfica para gerenciar seus dados.
- Técnica 2: use AWS Glue DynamicFrames com esquemas inferidos e fixos – O rastreador tem uma limitação quando se trata de processar uma única linha em arquivos XML maiores que 1 MB. Para superar essa restrição, usamos um notebook AWS Glue para construir o AWS Glue
DynamicFrames, utilizando esquemas inferidos e fixos. Este método garante o manuseio eficiente de arquivos XML com linhas com tamanho superior a 1 MB.
Em ambas as abordagens, nosso objetivo final é converter arquivos XML para o formato Apache Parquet, tornando-os prontamente disponíveis para consulta usando o Athena. Com essas técnicas, você pode aprimorar a velocidade de processamento e a acessibilidade dos seus dados XML, permitindo obter insights valiosos com facilidade.
Pré-requisitos
Antes de começar este tutorial, preencha os seguintes pré-requisitos (aplicam-se a ambas as técnicas):
- Baixe os arquivos XML técnica1.xml e técnica2.xml.
- Carregue os arquivos em um Serviço de armazenamento simples da Amazon (Amazon S3) balde. Você pode carregá-los para o mesmo bucket S3 em pastas diferentes ou para buckets S3 diferentes.
- Crie uma Gerenciamento de acesso e identidade da AWS (IAM) para seu trabalho ou notebook ETL, conforme instruído em Configurar permissões do IAM para o AWS Glue Studio.
- Adicione uma política em linha à sua função com o eu:PassRole açao:
- Adicione uma política de permissões à função com acesso ao seu bucket S3.
Agora que concluímos os pré-requisitos, vamos prosseguir para a implementação da primeira técnica.
Técnica 1: use um rastreador AWS Glue e o editor visual
O diagrama a seguir ilustra a arquitetura simples que você pode usar para implementar a solução.
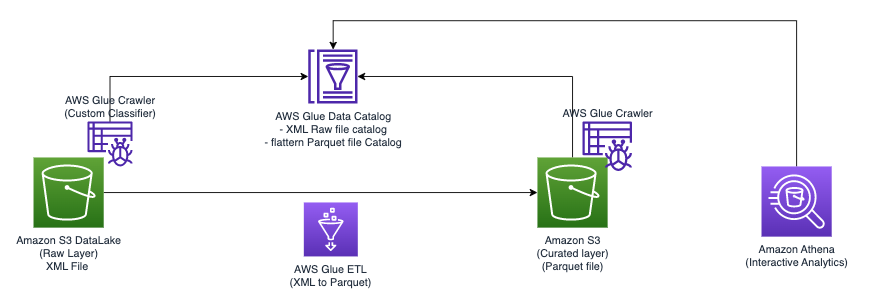
Para analisar arquivos XML armazenados no Amazon S3 usando AWS Glue e Athena, concluímos as seguintes etapas de alto nível:
- Crie um rastreador do AWS Glue para extrair metadados XML e criar uma tabela no AWS Glue Data Catalog.
- Processe e transforme dados XML em um formato (como Parquet) adequado para Athena usando um trabalho de extração, transformação e carregamento (ETL) do AWS Glue.
- Configure e execute um trabalho do AWS Glue por meio do console do AWS Glue ou do Interface de linha de comando da AWS (AWSCL).
- Utilize os dados processados (em formato Parquet) com tabelas do Athena, habilitando consultas SQL.
- Use a interface amigável do Athena para analisar os dados XML com consultas SQL nos dados armazenados no Amazon S3.
Essa arquitetura é uma solução escalável e econômica para analisar dados XML no Amazon S3 usando AWS Glue e Athena. Você pode analisar grandes conjuntos de dados sem gerenciamento complexo de infraestrutura.
Usamos o rastreador AWS Glue para extrair metadados de arquivos XML. Você pode escolher o classificador padrão do AWS Glue para classificação XML de uso geral. Ele detecta automaticamente a estrutura e o esquema de dados XML, o que é útil para formatos comuns.
Também usamos um classificador XML personalizado nesta solução. Ele foi projetado para esquemas ou formatos XML específicos, permitindo extração precisa de metadados. Isto é ideal para formatos XML não padrão ou quando você precisa de controle detalhado sobre a classificação. Um classificador personalizado garante que apenas os metadados necessários sejam extraídos, simplificando as tarefas de processamento e análise downstream. Essa abordagem otimiza o uso de seus arquivos XML.
A captura de tela a seguir mostra um exemplo de arquivo XML com tags.
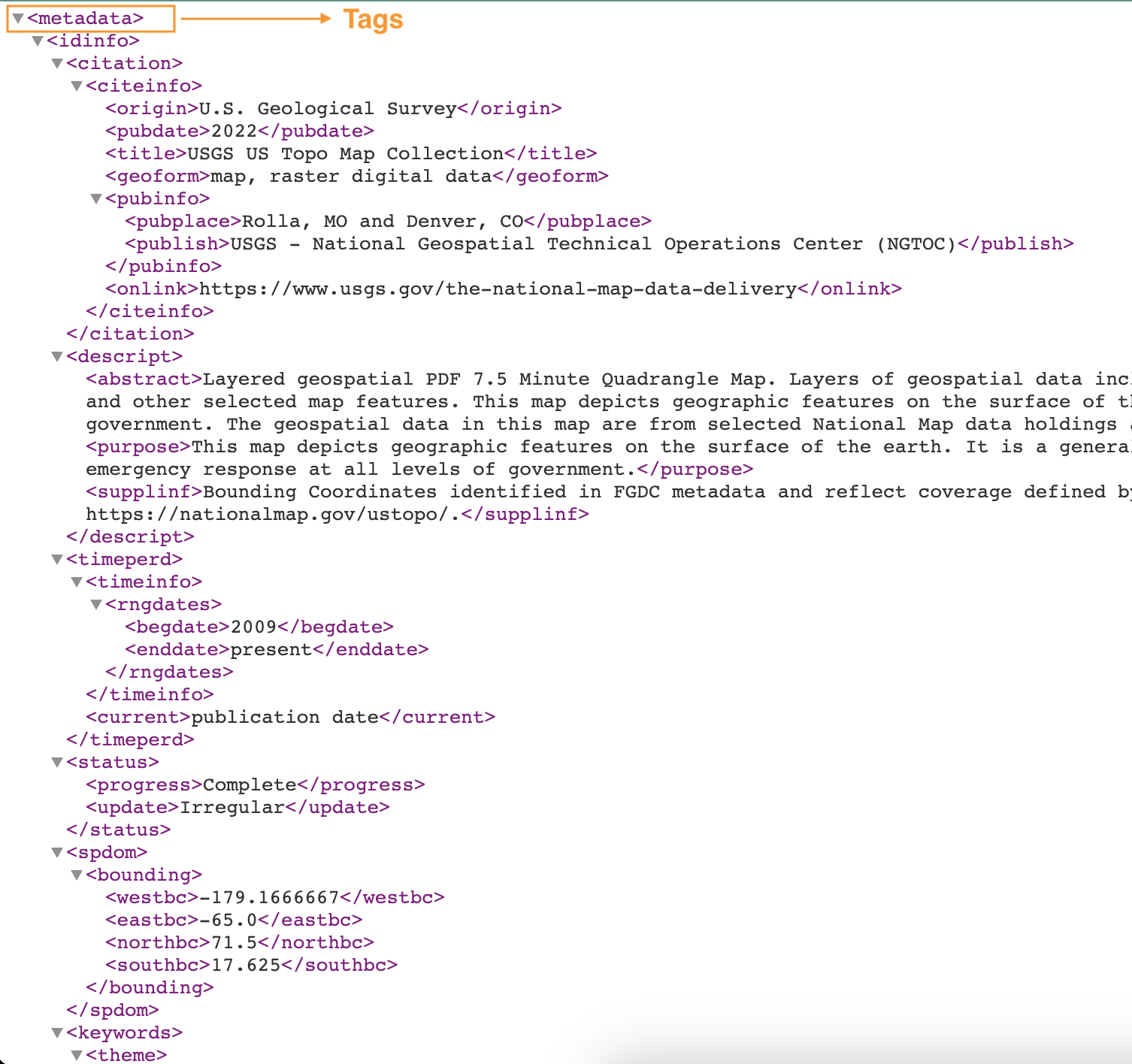
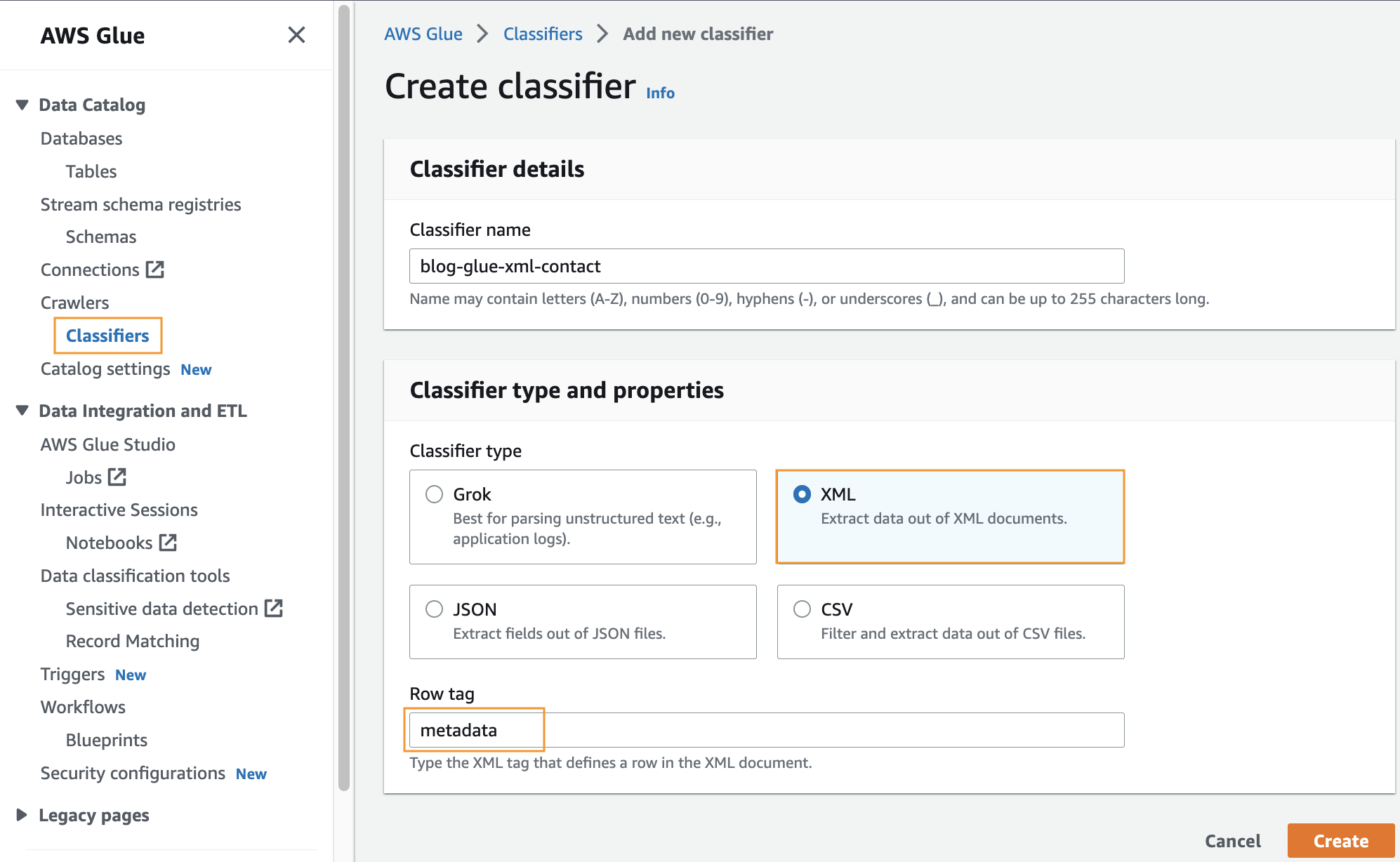
Crie um classificador personalizado
Nesta etapa, você cria um classificador personalizado do AWS Glue para extrair metadados de um arquivo XML. Conclua as seguintes etapas:
- No console AWS Glue, em Rastreadores no painel de navegação, escolha Classificadores.
- Escolha Adicionar classificador.
- Selecionar XML como o tipo de classificador.
- Insira um nome para o classificador, como
blog-glue-xml-contact. - Escolha Marca de linha, insira o nome da tag raiz que contém os metadados (por exemplo,
metadata). - Escolha Crie.
Crie um AWS Glue Crawler para rastrear o arquivo xml
Nesta seção, estamos criando um Glue Crawler para extrair os metadados do arquivo XML usando o classificador de cliente criado na etapa anterior.
Crie um banco de dados
- Vou ao Console AWS Glue, escolha Bases de dados no painel de navegação.
- Clique em Adicione banco de dados.
- Forneça um nome como
blog_glue_xml - Escolha Crie banco de dados
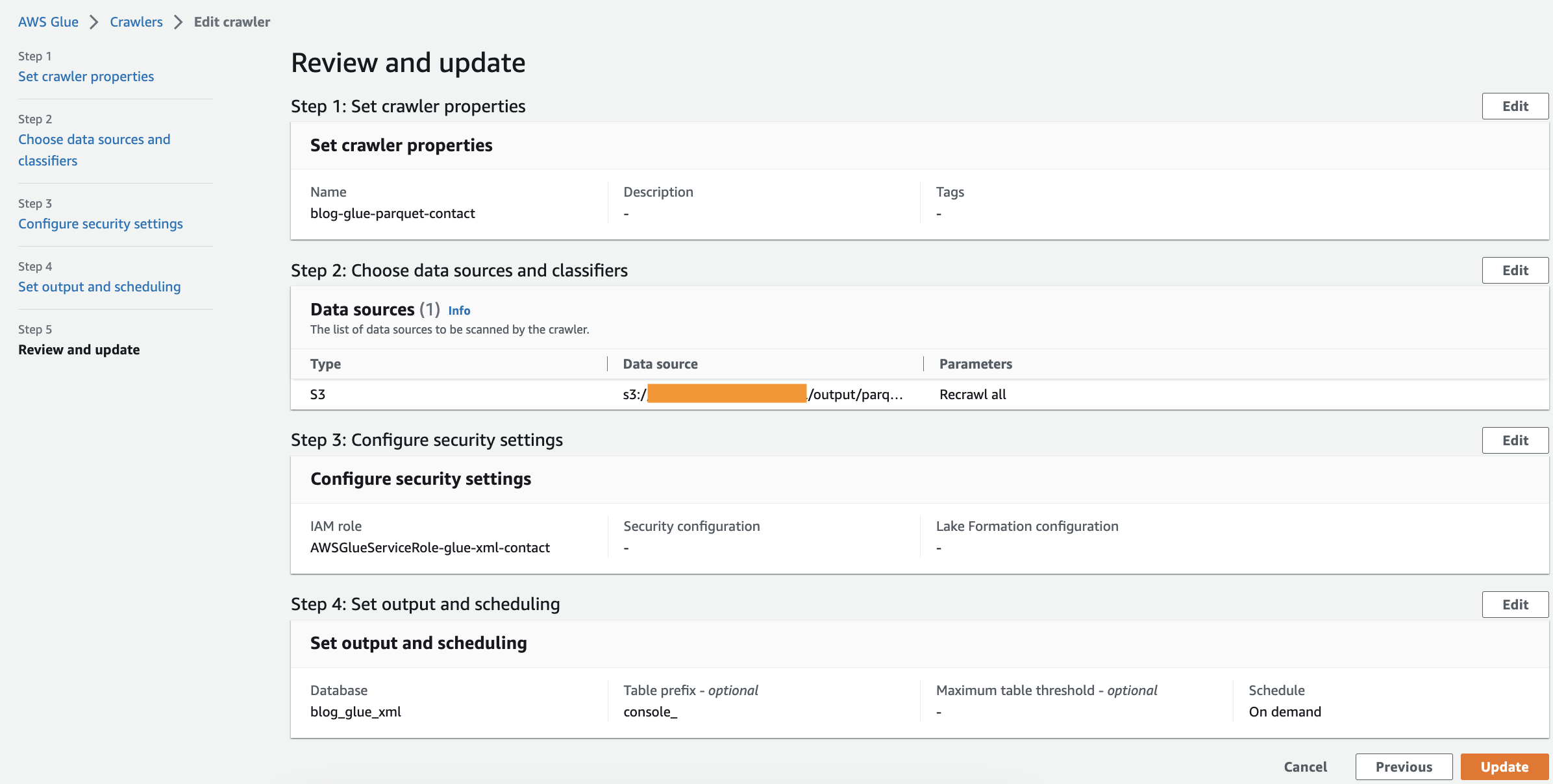
Crie um rastreador
Conclua as etapas a seguir para criar seu primeiro rastreador:
- No console AWS Glue, escolha Rastreadores no painel de navegação.
- Escolha Criar rastreador.
- No Definir propriedades do rastreador página, forneça um nome para o novo rastreador (como
blog-glue-parquet), então escolha Próximo. - No Escolha fontes de dados e classificadores página, selecione Ainda não para Configuração da fonte de dados.
- Escolha Adicionar um armazenamento de dados.
- Escolha caminho S3, navegue até
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Certifique-se de escolher a pasta XML em vez do arquivo dentro da pasta.
- Deixe o restante das opções como padrão e escolha Adicionar uma fonte de dados S3.
- Expandir Classificadores personalizados – opcional, escolha blog-glue-xml-contact e escolha Próximo e mantenha o restante das opções como padrão.
- Escolha sua função do IAM ou escolha Criar nova função IAM, adicione o sufixo
glue-xml-contact(por exemplo,AWSGlueServiceNotebookRoleBlog) e escolha Próximo. - No Definir saída e agendamento página, sob Configuração de saída, escolha
blog_glue_xmlpara Banco de dados de destino. - Entrar
console_como o prefixo adicionado às tabelas (opcional) e sob Programação do rastreador, mantenha a frequência definida para Sobre a demanda. - Escolha Próximo.
- Revise todos os parâmetros e escolha Criar rastreador.
Execute o rastreador
Depois de criar o rastreador, conclua as etapas a seguir para executá-lo:
- No console AWS Glue, escolha Rastreadores no painel de navegação.
- Abra o rastreador que você criou e escolha Execute.
O rastreador levará de 1 a 2 minutos para ser concluído.
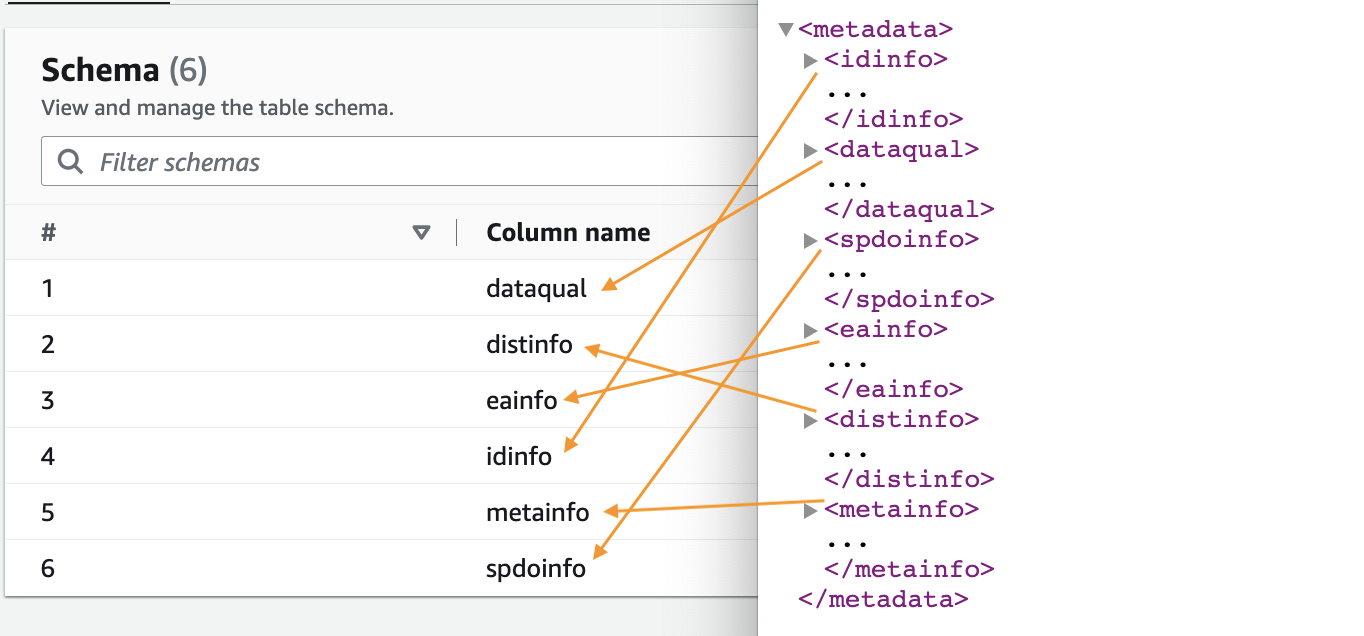
- Quando o rastreador estiver concluído, escolha Bases de dados no painel de navegação.
- Escolha o banco de dados que você criou e escolha o nome da tabela para ver o esquema extraído pelo rastreador.
Crie um trabalho do AWS Glue para converter o formato XML para Parquet
Nesta etapa, você cria um trabalho do AWS Glue Studio para converter o arquivo XML em um arquivo Parquet. Conclua as seguintes etapas:
- No console AWS Glue, escolha Empregos no painel de navegação.
- Debaixo Criar emprego, selecione Visual com uma tela em branco.
- Escolha Crie.
- Renomeie o trabalho para
blog_glue_xml_job.
Agora você tem um editor visual de trabalhos do AWS Glue Studio em branco. Na parte superior do editor estão as guias para diferentes visualizações.
- Escolha o Script para ver um shell vazio do script ETL do AWS Glue.
À medida que adicionamos novas etapas no editor visual, o script será atualizado automaticamente.
- Escolha o Detalhes do trabalho guia para ver todas as configurações do trabalho.
- Escolha Papel do IAM, escolha
AWSGlueServiceNotebookRoleBlog. - Escolha Versão de cola, escolha Cola 4.0 – Suporte Spark 3.3, Scala 2, Python 3.
- Conjunto Número de trabalhadores solicitados para 2.
- Conjunto Número de tentativas para 0.
- Escolha o visual guia para voltar ao editor visual.
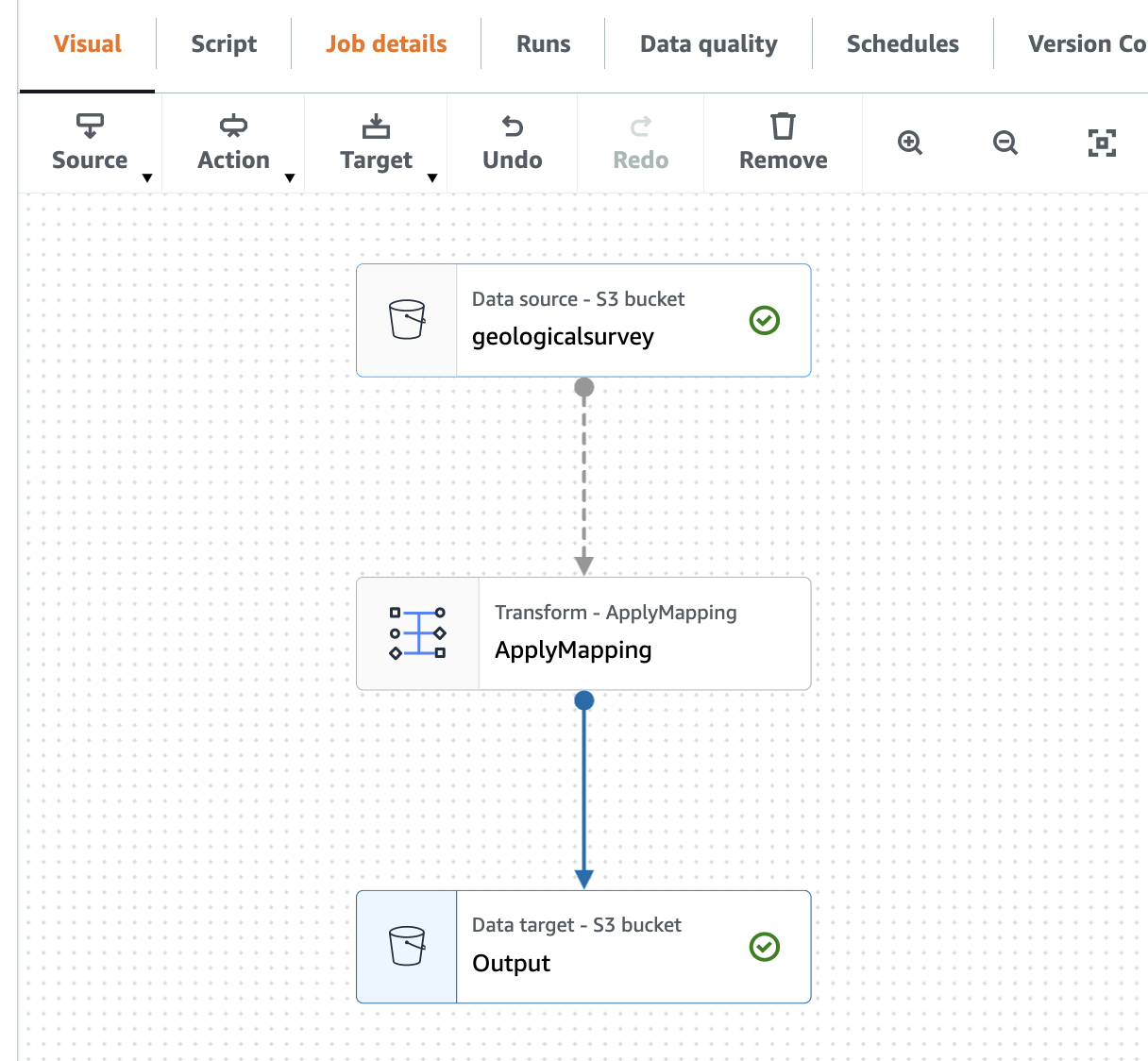
- No fonte menu suspenso, escolha Catálogo de dados do AWS Glue.
- No Propriedades da fonte de dados – Catálogo de dados guia, forneça as seguintes informações:
- Escolha banco de dados, escolha
blog_glue_xml. - Escolha mesa, escolha a tabela que começa com o nome console_ que o rastreador criou (por exemplo,
console_geologicalsurvey).
- Escolha banco de dados, escolha
- No Propriedades do nó guia, forneça as seguintes informações:
- Mudar Nome para
geologicalsurveyconjunto de dados. - Escolha Açao Social e a transformação Alterar esquema (aplicar mapeamento).
- Escolha Propriedades do nó e altere o nome da transformação de Change Schema (Apply Mapping) para
ApplyMapping. - No Target menu, escolha S3.
- Mudar Nome para
- No Propriedades da fonte de dados - S3 guia, forneça as seguintes informações:
- Escolha Formato, selecione Parquete.
- Escolha Tipo de compressão, selecione Descomprimido.
- Escolha Tipo de fonte S3, selecione Localização S3.
- Escolha URL do S3, entrar
s3://${BUCKET_NAME}/output/parquet/. - Escolha Propriedades do Nó e mude o nome para
Output.
- Escolha Salvar para salvar o trabalho.
- Escolha Execute para executar o trabalho.
A captura de tela a seguir mostra o trabalho no editor visual.
Crie um AWS Gue Crawler para rastrear o arquivo Parquet
Nesta etapa, você cria um rastreador do AWS Glue para extrair metadados do arquivo Parquet criado usando um trabalho do AWS Glue Studio. Desta vez, você usa o classificador padrão. Conclua as seguintes etapas:
- No console AWS Glue, escolha Rastreadores no painel de navegação.
- Escolha Criar rastreador.
- No Definir propriedades do rastreador página, forneça um nome para o novo rastreador, como blog-glue-parquet-contact, e escolha Próximo.
- No Escolha fontes de dados e classificadores página, selecione Ainda não para Configuração da fonte de dados.
- Escolha Adicionar um armazenamento de dados.
- Escolha caminho S3, navegue até
s3://${BUCKET_NAME}/output/parquet/.
Certifique-se de escolher o parquet pasta em vez do arquivo dentro da pasta.
- Escolha sua função do IAM criada durante a seção de pré-requisitos ou escolha Criar nova função IAM (por exemplo,
AWSGlueServiceNotebookRoleBlog) e escolha Próximo. - No Definir saída e agendamento página, sob Configuração de saída, escolha
blog_glue_xmlpara banco de dados. - Entrar
parquet_como o prefixo adicionado às tabelas (opcional) e sob Programação do rastreador, mantenha a frequência definida para Sobre a demanda. - Escolha Próximo.
- Revise todos os parâmetros e escolha Criar rastreador.
Agora você pode executar o rastreador, que leva de 1 a 2 minutos para ser concluído.

Você pode visualizar o esquema recém-criado para o arquivo Parquet no AWS Glue Data Catalog, que é semelhante ao esquema do arquivo XML.
Agora possuímos dados adequados para uso com o Athena. Na próxima seção, realizamos consultas de dados usando Athena.
Consultar o arquivo Parquet usando Athena
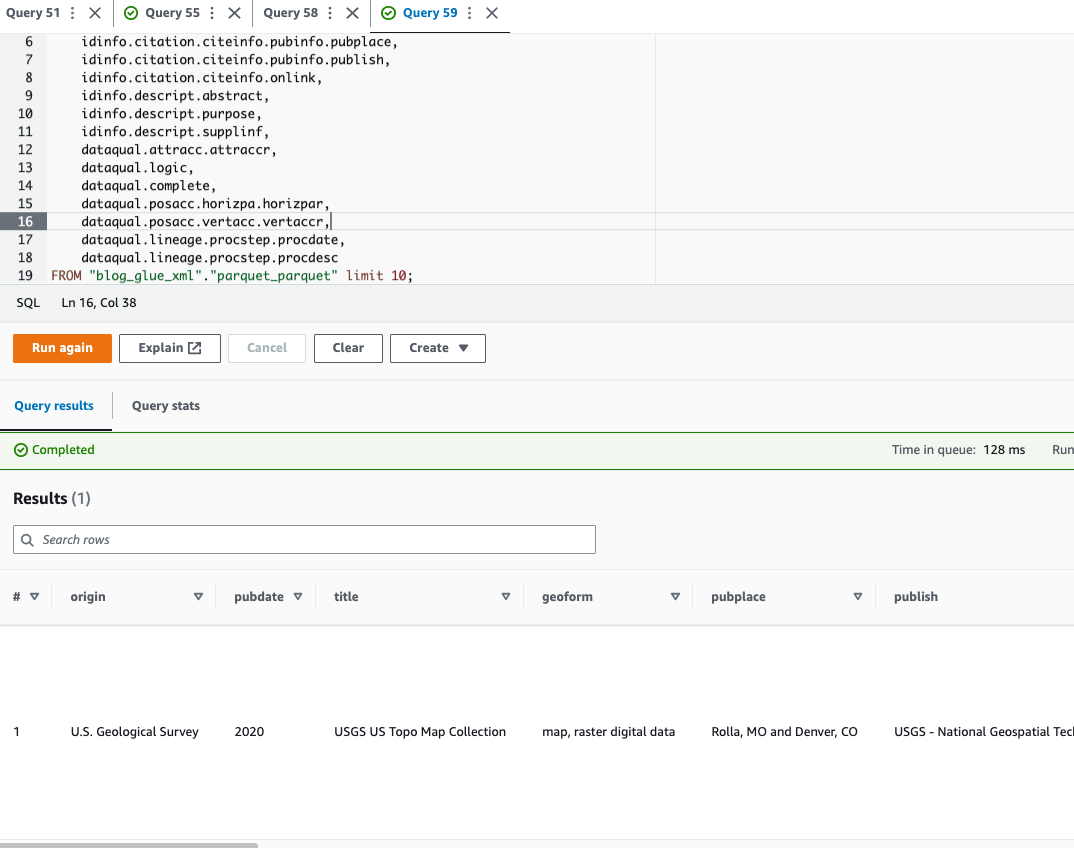
O Athena não oferece suporte à consulta do formato de arquivo XML, e é por isso que você converteu o arquivo XML em Parquet para consulta e uso de dados mais eficientes notação de ponto para consultar tipos complexos e estruturas aninhadas.
O código de exemplo a seguir usa notação de ponto para consultar dados aninhados:
Agora que concluímos a técnica 1, vamos aprender sobre a técnica 2.
Técnica 2: use AWS Glue DynamicFrames com esquemas inferidos e fixos
Na seção anterior, abordamos o processo de manipulação de um pequeno arquivo XML usando um rastreador AWS Glue para gerar uma tabela, um trabalho AWS Glue para converter o arquivo no formato Parquet e Athena para acessar os dados Parquet. No entanto, o rastreador encontra limitações quando se trata de processar arquivos XML que excedem 1 MB de tamanho. Nesta seção, nos aprofundamos no tópico de processamento em lote de arquivos XML maiores, necessitando de análise adicional para extrair eventos individuais e conduzir análises usando o Athena.
Nossa abordagem envolve a leitura dos arquivos XML por meio do AWS Glue Quadros Dinâmicos, empregando esquemas inferidos e fixos. Em seguida, extraímos os eventos individuais no formato Parquet usando o relacionar transformação, permitindo-nos consultá-los e analisá-los perfeitamente usando o Athena.
Para implementar esta solução, você conclui as seguintes etapas de alto nível:
- Crie um notebook AWS Glue para ler e analisar o arquivo XML.
- Use
DynamicFramesdeInferSchemapara ler o arquivo XML. - Use a função relacionalizar para desaninhar quaisquer matrizes.
- Converta os dados para o formato Parquet.
- Consulte os dados do Parquet usando o Athena.
- Repita as etapas anteriores, mas desta vez passe um esquema para
DynamicFramesao invés de usarInferSchema.
O arquivo XML de dados de população de veículos elétricos tem um response tag em seu nível raiz. Esta tag contém uma matriz de row tags, que estão aninhadas dentro dele. A tag de linha é uma matriz que contém um conjunto de outras tags de linha, que fornecem informações sobre um veículo, incluindo sua marca, modelo e outros detalhes relevantes. A captura de tela a seguir mostra um exemplo.

Crie um caderno AWS Glue
Para criar um notebook AWS Glue, execute as seguintes etapas:
- Abra o Estúdio do AWS Glue console, escolha Empregos no painel de navegação.
- Selecionar Caderno Jupyter e escolha Crie.
- Insira um nome para o trabalho do AWS Glue, como
blog_glue_xml_job_Jupyter. - Escolha a função que você criou nos pré-requisitos (
AWSGlueServiceNotebookRoleBlog).
O notebook AWS Glue vem com um exemplo preexistente que demonstra como consultar um banco de dados e gravar a saída no Amazon S3.
- Ajuste o tempo limite (em minutos) conforme mostrado na captura de tela a seguir e execute a célula para criar a sessão interativa do AWS Glue.
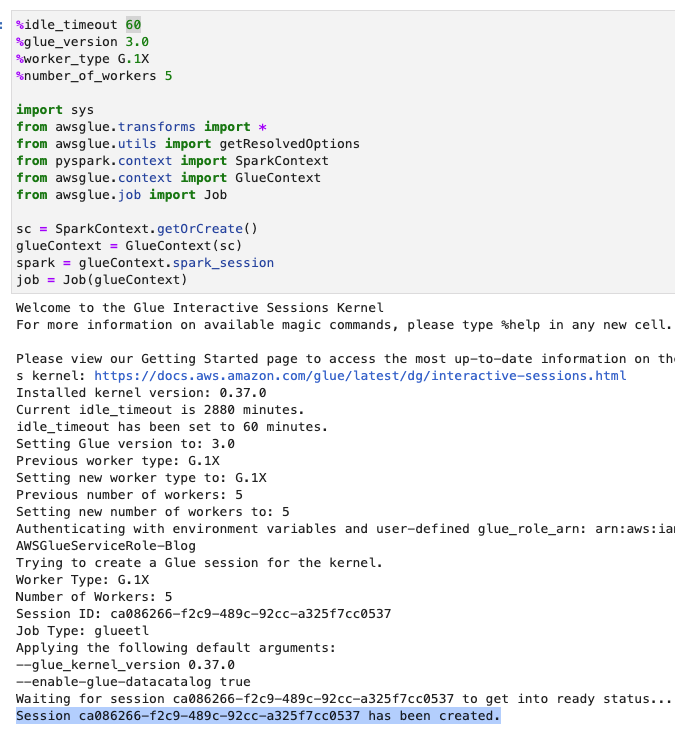
Crie variáveis básicas
Depois de criar a sessão interativa, no final do notebook, crie uma nova célula com as seguintes variáveis (forneça seu próprio nome de bucket):
Leia o arquivo XML inferindo o esquema
Se você não passar um esquema para o DynamicFrame, ele inferirá o esquema dos arquivos. Para ler os dados usando um quadro dinâmico, você pode usar o seguinte comando:
Imprimir o esquema DynamicFrame
Imprima o esquema com o seguinte código:
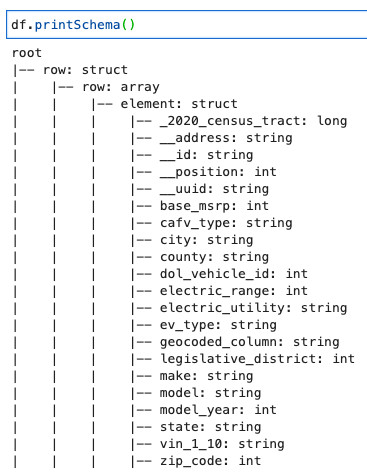
O esquema mostra uma estrutura aninhada com um row matriz contendo vários elementos. Para desaninhar essa estrutura em linhas, você pode usar o AWS Glue relacionar transformação:
Estamos interessados apenas nas informações contidas na matriz de linhas e podemos visualizar o esquema usando o seguinte comando:
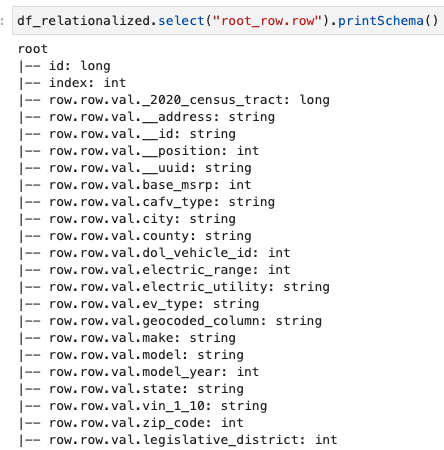
Os nomes das colunas contêm row.row, que correspondem à estrutura da matriz e à coluna da matriz no conjunto de dados. Não renomeamos as colunas nesta postagem; para obter instruções sobre como fazer isso, consulte Automatize o mapeamento dinâmico e a renomeação de nomes de colunas em arquivos de dados usando AWS Glue: Parte 1. Em seguida, você pode converter os dados para o formato Parquet e criar a tabela AWS Glue usando o seguinte comando:
Cola AWS DynamicFrame fornece recursos que você pode usar em seu script ETL para criar e atualizar um esquema no Catálogo de Dados. Nós usamos o updateBehavior parâmetro para criar a tabela diretamente no Catálogo de Dados. Com essa abordagem, não precisamos executar um rastreador do AWS Glue após a conclusão do trabalho do AWS Glue.

Leia o arquivo XML definindo um esquema
Uma forma alternativa de ler o arquivo é predefinir um esquema. Para fazer isso, conclua as seguintes etapas:
- Importe os tipos de dados do AWS Glue:
- Crie um esquema para o arquivo XML:
- Passe o esquema ao ler o arquivo XML:
- Desaninhe o conjunto de dados como antes:
- Converta o conjunto de dados em Parquet e crie a tabela AWS Glue:
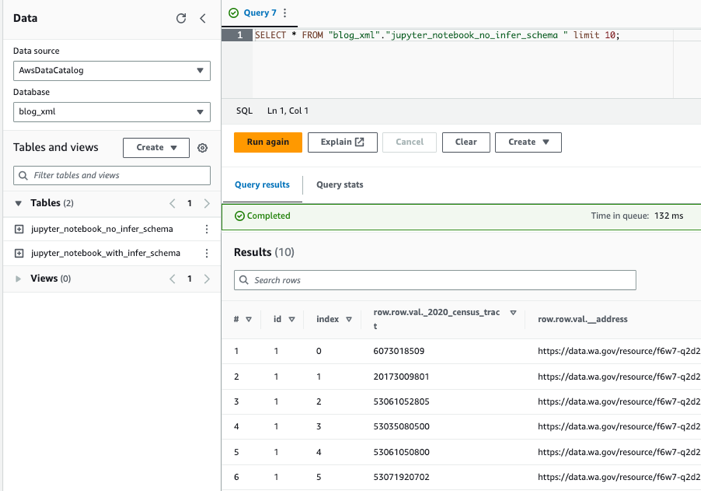
Consultar as tabelas usando Athena
Agora que criamos as duas tabelas, podemos consultá-las usando o Athena. Por exemplo, podemos usar a seguinte consulta:
Clean Up
Nesta postagem, criamos uma função IAM, um notebook AWS Glue Jupyter e duas tabelas no AWS Glue Data Catalog. Também carregamos alguns arquivos em um bucket S3. Para limpar esses objetos, conclua as etapas a seguir:
- No console do IAM, exclua a função que você criou.
- No console do AWS Glue Studio, exclua o classificador personalizado, o rastreador, os trabalhos de ETL e o notebook Jupyter.
- Navegue até o AWS Glue Data Catalog e exclua as tabelas que você criou.
- No console do Amazon S3, navegue até o bucket que você criou e exclua as pastas nomeadas
temp,infer_schemaeno_infer_schema.
Principais lições
No AWS Glue, há um recurso chamado InferSchema no AWS Glue DynamicFrames. Ele descobre automaticamente a estrutura de um quadro de dados com base nos dados que ele contém. Em contraste, definir um esquema significa declarar explicitamente como deve ser a estrutura do quadro de dados antes de carregar os dados.
XML, sendo um formato baseado em texto, não restringe os tipos de dados de suas colunas. Isto pode causar problemas com a função InferSchema. Por exemplo, na primeira execução, um arquivo com a coluna A com valor 2 resulta em um arquivo Parquet com a coluna A como um número inteiro. Na segunda execução, um novo arquivo possui a coluna A com o valor C, levando a um arquivo Parquet com a coluna A como string. Agora existem dois arquivos no S3, cada um com uma coluna A de diferentes tipos de dados, o que pode criar problemas no downstream.
O mesmo acontece com tipos de dados complexos, como estruturas ou arrays aninhados. Por exemplo, se um arquivo tiver uma entrada de tag chamada transaction, é inferido como uma estrutura. Mas se outro arquivo tiver a mesma tag, ele será inferido como um array
Apesar desses problemas de tipo de dados, InferSchema é útil quando você não conhece o esquema ou definir um manualmente é impraticável. No entanto, não é ideal para conjuntos de dados grandes ou em constante mudança. Definir um esquema é mais preciso, especialmente com tipos de dados complexos, mas tem seus próprios problemas, como exigir esforço manual e ser inflexível às alterações de dados.
InferSchema tem limitações, como inferência incorreta de tipos de dados e problemas com o tratamento de valores nulos. Definir um esquema também tem limitações, como esforço manual e possíveis erros.
A escolha entre inferir e definir um esquema depende das necessidades do projeto. O InferSchema é ótimo para exploração rápida de pequenos conjuntos de dados, enquanto a definição de um esquema é melhor para conjuntos de dados maiores e complexos que exigem precisão e consistência. Considere as vantagens e desvantagens de cada método para escolher o que melhor se adapta ao seu projeto.
Conclusão
Nesta postagem, exploramos duas técnicas para gerenciar dados XML usando AWS Glue, cada uma adaptada para atender às necessidades e desafios específicos que você pode encontrar.
A Técnica 1 oferece um caminho amigável para quem prefere uma interface gráfica. Você pode usar um rastreador do AWS Glue e o editor visual para definir facilmente a estrutura da tabela para seus arquivos XML. Essa abordagem simplifica o processo de gerenciamento de dados e é particularmente atraente para quem procura uma maneira simples de lidar com seus dados.
No entanto, reconhecemos que o rastreador tem suas limitações, especificamente ao lidar com arquivos XML com linhas maiores que 1 MB. É aqui que a técnica 2 vem ao resgate. Aproveitando o AWS Glue DynamicFrames com esquemas inferidos e fixos e empregando um notebook AWS Glue, você pode lidar com arquivos XML de qualquer tamanho com eficiência. Este método fornece uma solução robusta que garante processamento contínuo mesmo para arquivos XML com linhas que excedem a restrição de 1 MB.
À medida que você navega no mundo do gerenciamento de dados, ter essas técnicas em seu kit de ferramentas permite que você tome decisões informadas com base nos requisitos específicos do seu projeto. Quer você prefira a simplicidade da técnica 1 ou a escalabilidade da técnica 2, o AWS Glue oferece a flexibilidade necessária para lidar com dados XML de maneira eficaz.
Sobre os autores
 Navnit Shuklaatua como arquiteto de soluções especialista da AWS com foco em análises. Ele possui um grande entusiasmo em ajudar os clientes a descobrir informações valiosas a partir de seus dados. Através de sua experiência, ele constrói soluções inovadoras que capacitam as empresas a chegarem a escolhas informadas e baseadas em dados. Notavelmente, Navnit Shukla é o autor talentoso do livro intitulado “Data Wrangling on AWS.
Navnit Shuklaatua como arquiteto de soluções especialista da AWS com foco em análises. Ele possui um grande entusiasmo em ajudar os clientes a descobrir informações valiosas a partir de seus dados. Através de sua experiência, ele constrói soluções inovadoras que capacitam as empresas a chegarem a escolhas informadas e baseadas em dados. Notavelmente, Navnit Shukla é o autor talentoso do livro intitulado “Data Wrangling on AWS.
 Patrick Müller trabalha como arquiteto sênior de laboratório de dados na AWS. Sua principal responsabilidade é ajudar os clientes a transformar suas ideias em produtos de dados prontos para produção. Nas horas vagas, Patrick gosta de jogar futebol, assistir filmes e viajar.
Patrick Müller trabalha como arquiteto sênior de laboratório de dados na AWS. Sua principal responsabilidade é ajudar os clientes a transformar suas ideias em produtos de dados prontos para produção. Nas horas vagas, Patrick gosta de jogar futebol, assistir filmes e viajar.
 Amogh Gaikwad é desenvolvedor de soluções sênior na Amazon Web Services. Ele ajuda clientes globais a criar e implantar soluções de IA/ML na AWS. Seu trabalho se concentra principalmente em visão computacional e processamento de linguagem natural e em ajudar os clientes a otimizar suas cargas de trabalho de IA/ML para a sustentabilidade. Amogh possui mestrado em Ciência da Computação com especialização em Aprendizado de Máquina.
Amogh Gaikwad é desenvolvedor de soluções sênior na Amazon Web Services. Ele ajuda clientes globais a criar e implantar soluções de IA/ML na AWS. Seu trabalho se concentra principalmente em visão computacional e processamento de linguagem natural e em ajudar os clientes a otimizar suas cargas de trabalho de IA/ML para a sustentabilidade. Amogh possui mestrado em Ciência da Computação com especialização em Aprendizado de Máquina.
 Sheela Sonone é arquiteto residente sênior na AWS. Ela ajuda os clientes da AWS a fazer escolhas e compensações informadas sobre a aceleração de dados, análises e cargas de trabalho e implementações de IA/ML. Nas horas vagas, ela gosta de passar tempo com a família – geralmente nas quadras de tênis.
Sheela Sonone é arquiteto residente sênior na AWS. Ela ajuda os clientes da AWS a fazer escolhas e compensações informadas sobre a aceleração de dados, análises e cargas de trabalho e implementações de IA/ML. Nas horas vagas, ela gosta de passar tempo com a família – geralmente nas quadras de tênis.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Sobre
- RESUMO
- acelerando
- Acesso
- acessibilidade
- realizado
- precisão
- em
- Açao Social
- adicionar
- adicionado
- Adicional
- endereço
- Depois de
- idade
- AI / ML
- Todos os Produtos
- permitir
- Permitindo
- permite
- tb
- alternativa
- Amazon
- Amazona atena
- Amazon Web Services
- an
- análise
- analítica
- analisar
- análise
- e
- Outro
- qualquer
- apache
- atraente
- aplicações
- Aplicar
- abordagem
- se aproxima
- arquitetura
- SOMOS
- Ordem
- AS
- auxiliar
- ajudando
- At
- autor
- automaticamente
- disponível
- AWS
- Cola AWS
- em caminho duplo
- baseado
- basic
- BE
- Porque
- antes
- começar
- ser
- MELHOR
- Melhor
- entre
- em branco
- livro
- ambos
- construir
- negócios
- mas a
- by
- chamado
- CAN
- catálogo
- Causar
- célula
- desafios
- alterar
- Alterações
- mudança
- escolhas
- Escolha
- Cidades
- classificação
- clientes
- código
- Coluna
- colunas
- COM
- vem
- comum
- geralmente
- completar
- Efetuado
- integrações
- computador
- Ciência da Computação
- Visão de Computador
- condição
- Conduzir
- conjunção
- Considerar
- cônsul
- constantemente
- restrições
- construir
- não contenho
- contida
- contém
- contraste
- ao controle
- converter
- convertido
- relação custo-benefício
- solução econômica
- condado
- Tribunais
- coberto
- rastreador
- crio
- criado
- Criar
- crucial
- personalizadas
- cliente
- Clientes
- dados,
- integração de dados
- gestão de dados
- orientado por dados
- banco de dados
- conjuntos de dados
- lidar
- decisões
- Padrão
- definir
- definição
- mergulhar
- demonstra
- depende
- implantar
- projetado
- detalhado
- detalhes
- Developer
- diferente
- difícil
- digital
- idade digital
- diretamente
- descobrindo
- distinto
- do
- Não faz
- feito
- não
- DOT
- durante
- dinâmico
- cada
- facilidade
- facilmente
- fácil
- editor
- efeito
- efetivamente
- eficiência
- eficiente
- eficientemente
- esforço
- sem esforço
- Elétrico
- veículo eléctrico
- elementos
- empregando
- autorizar
- empodera
- vazio
- permitir
- permitindo
- encontro
- final
- Motores
- aumentar
- garantir
- garante
- Entrar
- entusiasmo
- entrada
- erros
- especialmente
- Éter (ETH)
- Mesmo
- eventos
- Cada
- exemplo
- excedem
- trocando
- experiência
- exploração
- explorar
- Explorado
- extrato
- Extração
- família
- Característica
- Funcionalidades
- figuras
- Envie o
- Arquivos
- financiar
- Primeiro nome
- fixado
- Flexibilidade
- Foco
- focado
- seguinte
- Escolha
- formato
- QUADRO
- Gratuito
- Frequência
- da
- função
- Ganho
- propósito geral
- gerar
- Global
- Go
- meta
- Governo
- ótimo
- manipular
- Manipulação
- acontece
- Aproveitamento
- Ter
- ter
- he
- saúde
- Coração
- ajudar
- ajuda
- ajuda
- sua experiência
- de alto nível
- altamente
- sua
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- IAM
- ideal
- idéias
- Identidade
- if
- ilustra
- executar
- implementações
- implementação
- importar
- melhorar
- melhorado
- in
- Incluindo
- Individual
- indivíduos
- indústrias
- INFORMAÇÕES
- informado
- Infraestrutura
- inovadores
- dentro
- insights
- em vez disso
- instruções
- integrar
- integração
- interativo
- interessado
- Interface
- para dentro
- envolve
- questões
- IT
- ESTÁ
- Trabalho
- Empregos
- jpg
- json
- Caderno Jupyter
- Guarda
- Saber
- laboratório
- língua
- grande
- Maior
- principal
- APRENDER
- aprendizagem
- Nível
- como
- LIMITE
- limitação
- limitações
- Line
- linhas
- carregar
- carregamento
- lógica
- procurando
- máquina
- aprendizado de máquina
- a Principal
- principalmente
- fazer
- Fazendo
- de grupos
- gestão
- manual
- manualmente
- muitos
- mapeamento
- mestre
- Posso..
- significa
- Menu
- metadados
- método
- minutos
- modelo
- mais
- mais eficiente
- a maioria
- mover
- Filmes
- múltiplo
- nome
- Nomeado
- nomes
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Navegar
- Navegação
- necessário
- você merece...
- Cria
- Novo
- recentemente
- Próximo
- notavelmente
- caderno
- agora
- número
- objetos
- of
- Oferece
- on
- ONE
- só
- Operações
- ideal
- Otimize
- Otimiza
- Opções
- or
- ordem
- organizações
- Origin
- Outros
- A Nossa
- Fora
- saída
- Acima de
- Superar
- próprio
- página
- pão
- parâmetro
- parâmetros
- parte
- particularmente
- passar
- caminho
- patrick
- realizar
- atuação
- permissões
- escolher
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- Privacidade
- população
- possuir
- Publique
- potencial
- preciso
- preferir
- pré-requisitos
- visualização
- anterior
- problemas
- processo
- processado
- em processamento
- Produto
- projeto
- projetos
- Propriedades
- fornecer
- fornece
- publicar
- propósito
- Python
- consultas
- Links
- em vez
- Leia
- prontamente
- Leitura
- razões
- recebido
- reconhecer
- referir
- relevante
- Requisitos
- resgatar
- recurso
- resposta
- responsabilidade
- DESCANSO
- restringir
- restrição
- Resultados
- uma conta de despesas robusta
- Tipo
- raiz
- LINHA
- Execute
- mesmo
- Salvar
- Scala
- AMPLIAR
- escalável
- Ciência
- escrita
- desatado
- sem problemas
- Segundo
- Seção
- Vejo
- senior
- Serviços
- Sessão
- conjunto
- contexto
- vários
- ela
- concha
- rede de apoio social
- mostrar
- mostrando
- Shows
- semelhante
- simples
- simplicidade
- simplificando
- solteiro
- Tamanho
- pequeno
- So
- futebol
- solução
- Soluções
- alguns
- fonte
- Fontes
- Faísca
- especialista
- especializando
- específico
- especificamente
- velocidade
- Passar
- SQL
- padrão
- começa
- Estado
- Declaração
- declarando
- Passo
- Passos
- armazenamento
- armazenadas
- franco
- simplificar
- Tanga
- mais forte,
- estrutura
- estruturas
- estudo
- sucesso
- tal
- adequado
- ajuda
- certo
- Sustentabilidade
- sistemas
- mesa
- TAG
- adaptados
- Tire
- toma
- tarefas
- técnicas
- tênis
- do que
- que
- A
- as informações
- o mundo
- deles
- Eles
- então
- Lá.
- Este
- deles
- isto
- aqueles
- Através da
- tempo
- Título
- intitulado
- para
- hoje
- kit de ferramentas
- topo
- tópico
- Transformar
- Transformação
- Viagens
- Passando
- tutorial
- dois
- tipo
- tipos
- final
- para
- Atualizar
- Atualizada
- carregado
- us
- usabilidade
- usar
- usava
- Utilizador
- Interface de Usuário
- user-friendly
- usos
- utilização
- geralmente
- Utilizando
- Valioso
- valor
- Valores
- veículo
- versão
- via
- Ver
- visualizações
- visão
- assistindo
- Caminho..
- we
- web
- serviços web
- O Quê
- quando
- enquanto que
- se
- qual
- QUEM
- porque
- precisarão
- de
- dentro
- sem
- Atividades:
- de gestão de documentos
- fluxos de trabalho
- trabalho
- mundo
- escrever
- XML
- Você
- investimentos
- zefirnet