Imagem do autor
Se você estiver familiarizado com o paradigma de aprendizado não supervisionado, deve ter encontrado a redução de dimensionalidade e os algoritmos usados para redução de dimensionalidade, como o análise do componente principal (PCA). Os conjuntos de dados para aprendizado de máquina geralmente contêm um grande número de recursos, mas esses espaços de recursos de alta dimensão nem sempre são úteis.
Em geral, todos os recursos são não igualmente importantes e há certos recursos que respondem por uma grande porcentagem de variação no conjunto de dados. Algoritmos de redução de dimensionalidade visam reduzir a dimensão do espaço de recursos a uma fração do número original de dimensões. Ao fazer isso, os recursos com alta variância ainda são retidos, mas estão no espaço de recursos transformado. E a análise de componentes principais (PCA) é um dos algoritmos de redução de dimensionalidade mais populares.
Neste tutorial, aprenderemos como a análise de componentes principais (PCA) funciona e como implementá-la usando a biblioteca scikit-learn.
Antes de prosseguirmos e implementarmos a análise de componentes principais (PCA) no scikit-learn, é útil entender como o PCA funciona.
Como mencionado, a análise de componentes principais é um algoritmo de redução de dimensionalidade. O que significa que reduz a dimensionalidade do espaço de recursos. Mas como ele consegue essa redução?
A motivação por trás do algoritmo é que existem certos recursos que capturam uma grande porcentagem de variação no conjunto de dados original. Então é importante encontrar o direções de variância máxima no conjunto de dados. Essas direções são chamadas componentes principais. E o PCA é essencialmente uma projeção do conjunto de dados nos componentes principais.
Então, como encontramos os componentes principais?
Suponha que a matriz de dados X seja de dimensões num_observações x num_features, executamos decomposição de autovalor na matriz de covariância de X.
Se todas as características tiverem média zero, então a matriz de covariância é dada por XT X. Aqui, XT é a transposta da matriz X. Se as características não tiverem média zero inicialmente, podemos subtrair a média da coluna i de cada entrada nessa coluna e calcule a matriz de covariância. É simples ver que a matriz de covariância é uma matriz quadrada de ordem num_features.
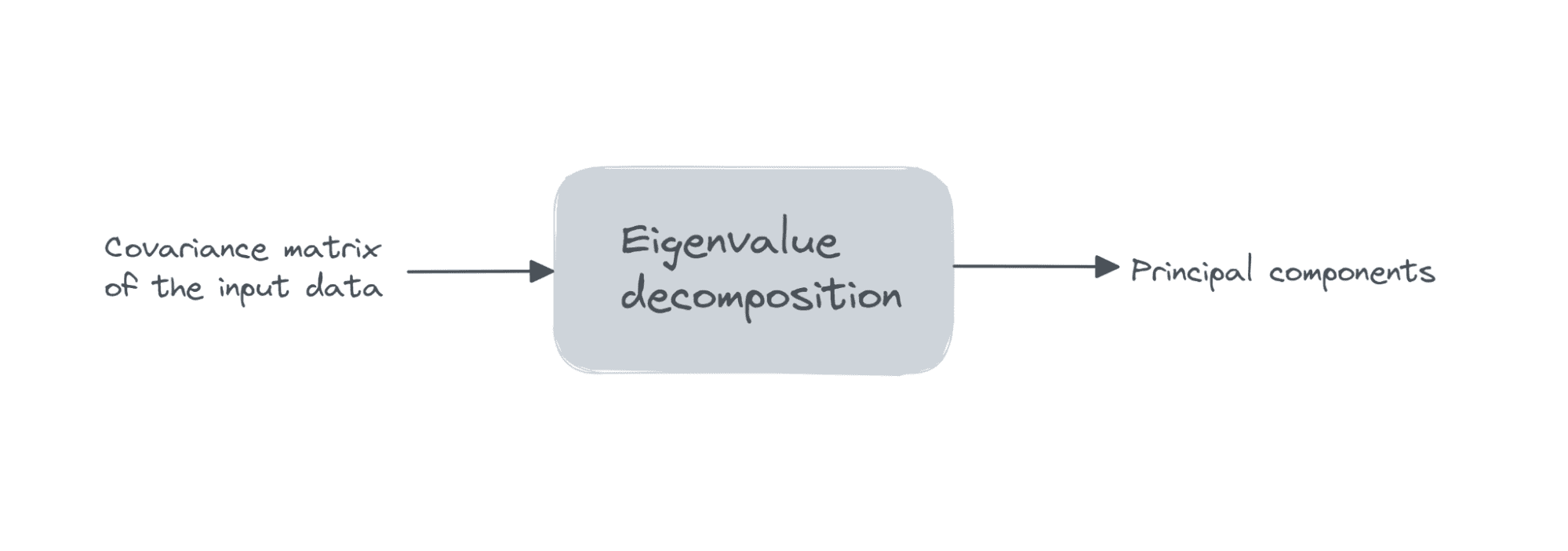
Imagem do autor
Os primeiros k componentes principais são os autovetores correspondente ao k maiores autovalores.
Portanto, as etapas do PCA podem ser resumidas da seguinte forma:
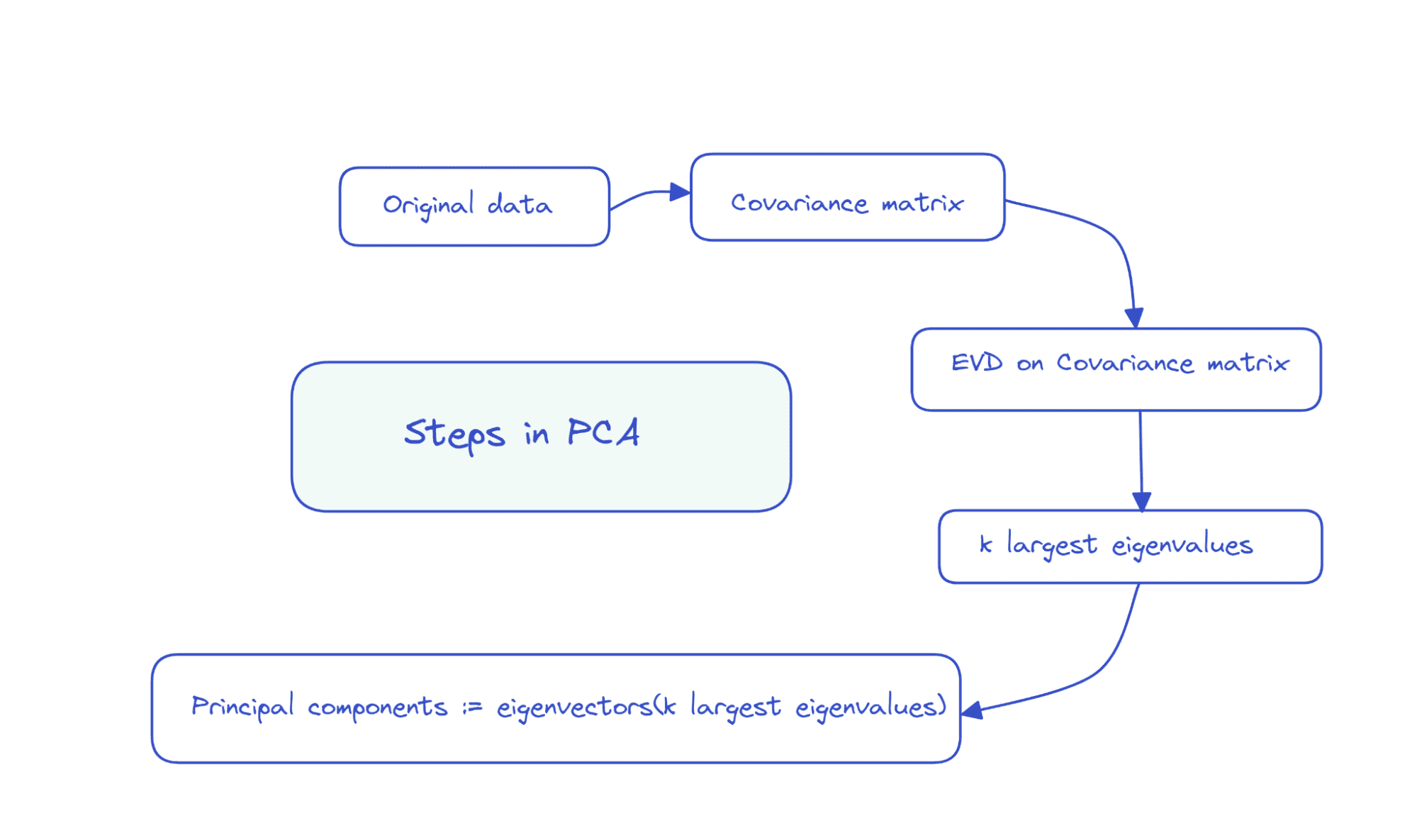
Imagem do autor
Como a matriz de covariância é uma semidefinida simétrica e positiva, a autodecomposição assume a seguinte forma:
XT X = D Λ DT
Onde, D é a matriz de autovetores e Λ é uma matriz diagonal de autovalores.
Outra técnica de fatoração de matriz que pode ser usada para calcular componentes principais é a decomposição de valor singular ou SVD.
A decomposição de valor singular (SVD) é definida para todas as matrizes. Dada uma matriz X, SVD de X dá: X = U Σ VT Aqui, U, Σ e V são as matrizes de vetores singulares esquerdos, valores singulares e vetores singulares direitos, respectivamente. VT é a transposta de V.
Assim, o SVD da matriz de covariância de X é dado por:

Comparando a equivalência das duas decomposições de matrizes:

Nós temos o seguinte:
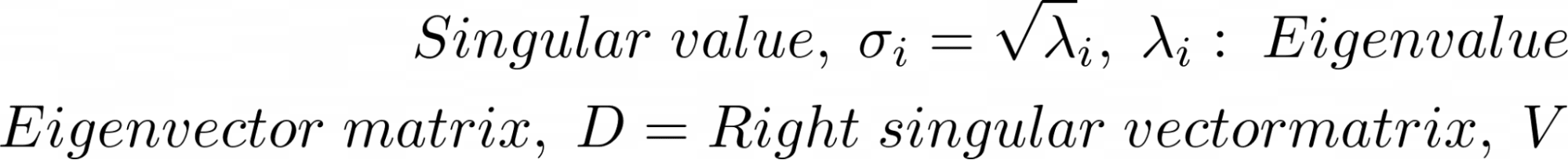
Existem algoritmos computacionalmente eficientes para calcular o SVD de uma matriz. A implementação scikit-learn do PCA também usa SVD sob o capô para calcular os componentes principais.
Agora que aprendemos o básico da análise de componentes principais, vamos prosseguir com a implementação do scikit-learn.
Etapa 1 - Carregar o conjunto de dados
Para entender como implementar a análise de componentes principais, vamos usar um conjunto de dados simples. Neste tutorial, usaremos o conjunto de dados wine disponível como parte do scikit-learn's conjuntos de dados módulo.
Vamos começar carregando e pré-processando o conjunto de dados:
from sklearn import datasets
wine_data = datasets.load_wine(as_frame=True)
df = wine_data.data
Possui 13 recursos e 178 registros ao todo.
print(df.shape)
Output >> (178, 13)
print(df.info())
Output >>
RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 alcohol 178 non-null float64 1 malic_acid 178 non-null float64 2 ash 178 non-null float64 3 alcalinity_of_ash 178 non-null float64 4 magnesium 178 non-null float64 5 total_phenols 178 non-null float64 6 flavanoids 178 non-null float64 7 nonflavanoid_phenols 178 non-null float64 8 proanthocyanins 178 non-null float64 9 color_intensity 178 non-null float64 10 hue 178 non-null float64 11 od280/od315_of_diluted_wines 178 non-null float64 12 proline 178 non-null float64
dtypes: float64(13)
memory usage: 18.2 KB
NoneEtapa 2 - Pré-processar o conjunto de dados
Como próxima etapa, vamos pré-processar o conjunto de dados. Os recursos estão todos em escalas diferentes. Para trazê-los todos para uma escala comum, usaremos o StandardScaler que transforma os recursos para ter média zero e variância unitária:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scaled_df = std_scaler.fit_transform(df)Etapa 3 - Execute o PCA no conjunto de dados pré-processado
Para encontrar os componentes principais, podemos usar a classe PCA do scikit-learn's decomposição módulo.
Vamos instanciar um objeto PCA passando o número de componentes principais n_components para o construtor.
O número de componentes principais é o número de dimensões para as quais você gostaria de reduzir o espaço de recursos. Aqui, definimos o número de componentes como 3.
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
pca.fit_transform(scaled_df)
Em vez de chamar o fit_transform() método, você também pode chamar fit() seguido pelo transform() método.
Observe como as etapas da análise de componentes principais, como calcular a matriz de covariância, realizar autodecomposição ou decomposição de valor singular na matriz de covariância para obter os componentes principais, foram todas abstraídas quando usamos a implementação do PCA do scikit-learn.
Etapa 4 – Examinando alguns atributos úteis do objeto PCA
A instância do PCA pca que criamos tem vários atributos úteis que nos ajudam a entender o que está acontecendo nos bastidores.
O atributo components_ armazena as direções de variância máxima (os componentes principais).
print(pca.components_)
Output >>
[[ 0.1443294 -0.24518758 -0.00205106 -0.23932041 0.14199204 0.39466085 0.4229343 -0.2985331 0.31342949 -0.0886167 0.29671456 0.37616741 0.28675223] [-0.48365155 -0.22493093 -0.31606881 0.0105905 -0.299634 -0.06503951 0.00335981 -0.02877949 -0.03930172 -0.52999567 0.27923515 0.16449619 -0.36490283] [-0.20738262 0.08901289 0.6262239 0.61208035 0.13075693 0.14617896 0.1506819 0.17036816 0.14945431 -0.13730621 0.08522192 0.16600459 -0.12674592]]
Mencionamos que os componentes principais são direções de variância máxima no conjunto de dados. Mas como medimos quanto da variância total é capturado no número de componentes principais que acabamos de escolher?
A explained_variance_ratio_ O atributo captura a proporção da variância total que cada componente principal captura. Assim, podemos somar as proporções para obter a variância total no número de componentes escolhido.
print(sum(pca.explained_variance_ratio_))
Output >> 0.6652996889318527
Aqui, vemos que três componentes principais capturam mais de 66.5% da variância total no conjunto de dados.
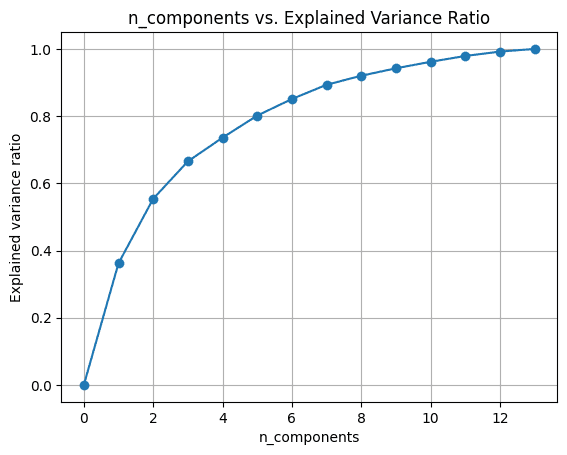
Passo 5 - Analisando a Mudança na Razão de Variância Explicada
Podemos tentar executar a análise de componentes principais variando o número de componentes n_components.
import numpy as np
nums = np.arange(14)
var_ratio = []
for num in nums: pca = PCA(n_components=num) pca.fit(scaled_df) var_ratio.append(np.sum(pca.explained_variance_ratio_))
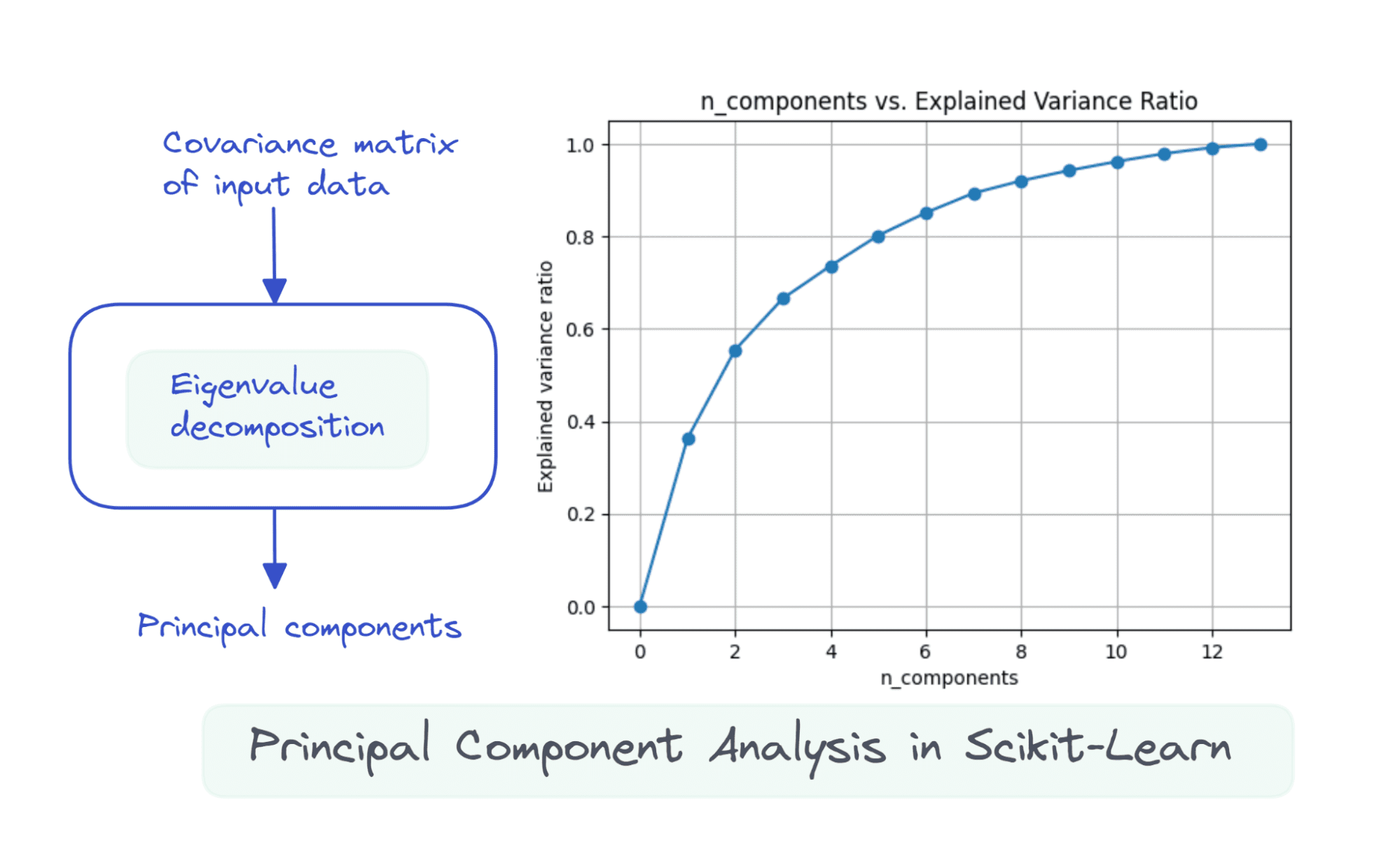
Para visualizar o explained_variance_ratio_ para o número de componentes, vamos traçar as duas quantidades como mostrado:
import matplotlib.pyplot as plt plt.figure(figsize=(4,2),dpi=150)
plt.grid()
plt.plot(nums,var_ratio,marker='o')
plt.xlabel('n_components')
plt.ylabel('Explained variance ratio')
plt.title('n_components vs. Explained Variance Ratio')
Quando usamos todos os 13 componentes, o explained_variance_ratio_ é 1.0 indicando que capturamos 100% da variação no conjunto de dados.
Neste exemplo, vemos que com 6 componentes principais, poderemos capturar mais de 80% da variância no conjunto de dados de entrada.
Espero que você tenha aprendido como realizar a análise de componentes principais usando a funcionalidade integrada na biblioteca scikit-learn. Em seguida, você pode tentar implementar o PCA em um conjunto de dados de sua escolha. Se você está procurando bons conjuntos de dados para trabalhar, confira esta lista de sites para encontrar conjuntos de dados para seus projetos de ciência de dados.
[1] Álgebra Linear Computacional, rápido.ai
Bala Priya C é um desenvolvedor e escritor técnico da Índia. Ela gosta de trabalhar na interseção de matemática, programação, ciência de dados e criação de conteúdo. Suas áreas de interesse e especialização incluem DevOps, ciência de dados e processamento de linguagem natural. Ela gosta de ler, escrever, programar e tomar café! Atualmente, ela está trabalhando para aprender e compartilhar seu conhecimento com a comunidade de desenvolvedores criando tutoriais, guias de instruções, artigos de opinião e muito mais.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/05/principal-component-analysis-pca-scikitlearn.html?utm_source=rss&utm_medium=rss&utm_campaign=principal-component-analysis-pca-with-scikit-learn
- :tem
- :é
- :não
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 66
- 7
- 8
- 9
- a
- Capaz
- Conta
- Alcançar
- em
- à frente
- visar
- Álcool
- algoritmo
- algoritmos
- Todos os Produtos
- tb
- sempre
- análise
- análise
- e
- SOMOS
- áreas
- AS
- At
- atributos
- autoria
- disponível
- longe
- fundamentos básicos
- BE
- sido
- atrás
- trazer
- construídas em
- mas a
- by
- cálculo
- chamada
- chamado
- chamada
- CAN
- capturar
- capturas
- certo
- alterar
- verificar
- escolha
- escolheu
- escolhido
- classe
- Codificação
- Coluna
- colunas
- como
- comum
- comunidade
- componente
- componentes
- Computar
- computação
- conteúdo
- Criação de conteúdo
- Correspondente
- criado
- criação
- Atualmente
- dados,
- ciência de dados
- conjuntos de dados
- definido
- Developer
- DevOps
- diferente
- Dimensão
- dimensões
- instruções
- do
- parece
- fazer
- cada
- eficiente
- entrada
- igualmente
- essencialmente
- Examinando
- exemplo
- experiência
- explicado
- familiar
- RÁPIDO
- Característica
- Funcionalidades
- Encontre
- Primeiro nome
- seguido
- seguinte
- segue
- Escolha
- formulário
- fração
- da
- funcionalidade
- Geral
- ter
- dado
- dá
- Go
- vai
- Bom estado, com sinais de uso
- Guias
- Ter
- ajudar
- útil
- sua experiência
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- capuz
- esperança
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- i
- if
- executar
- implementação
- importar
- importante
- in
- incluir
- Índia
- indicador
- inicialmente
- entrada
- instância
- interesse
- interseção
- IT
- apenas por
- KDnuggetsGenericName
- Conhecimento
- língua
- grande
- maior
- APRENDER
- aprendido
- aprendizagem
- esquerda
- Biblioteca
- como
- Lista
- ll
- carregar
- carregamento
- procurando
- máquina
- aprendizado de máquina
- matemática
- matplotlib
- Matriz
- máximo
- significar
- significado
- a medida
- Memória
- mencionado
- método
- módulo
- mais
- a maioria
- Mais populares
- Motivação
- muito
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Próximo
- número
- numpy
- objeto
- of
- on
- ONE
- Opinião
- or
- ordem
- original
- Fora
- saída
- Acima de
- paradigma
- parte
- Passagem
- percentagem
- realizar
- realização
- peças
- platão
- Inteligência de Dados Platão
- PlatãoData
- Popular
- positivo
- Diretor
- em processamento
- Programação
- Projeção
- relação
- Leitura
- registros
- reduzir
- reduz
- redução
- respectivamente
- certo
- corrida
- s
- mesmo
- Escala
- Escalas
- Ciência
- scikit-learn
- Vejo
- conjunto
- vários
- Shape
- compartilhando
- ela
- mostrando
- simples
- singular
- So
- alguns
- Espaço
- espaços
- quadrado
- começo
- Passo
- Passos
- Ainda
- lojas
- tal
- toma
- Dados Técnicos:
- do que
- que
- A
- O Básico
- Eles
- então
- Lá.
- Este
- isto
- três
- para
- Total
- transformado
- tentar
- tutorial
- tutoriais
- dois
- tipicamente
- para
- compreender
- unidade
- aprendizado não supervisionado
- us
- Uso
- usar
- usava
- utilização
- valor
- Valores
- vs
- we
- O Quê
- O que é a
- quando
- Wikipedia
- VINHO
- de
- Atividades:
- trabalhar
- trabalho
- escritor
- escrita
- X
- Você
- investimentos
- zefirnet
- zero



