
À medida que a IA migra da nuvem para o Edge, vemos a tecnologia sendo usada em uma variedade cada vez maior de casos de uso – desde detecção de anomalias até aplicações que incluem compras inteligentes, vigilância, robótica e automação de fábrica. Portanto, não existe uma solução única para todos. Mas com o rápido crescimento dos dispositivos habilitados para câmeras, a IA tem sido mais amplamente adotada para analisar dados de vídeo em tempo real para automatizar o monitoramento de vídeo para aumentar a segurança, melhorar a eficiência operacional e fornecer melhores experiências aos clientes, ganhando, em última análise, uma vantagem competitiva em seus setores. . Para oferecer melhor suporte à análise de vídeo, você deve compreender as estratégias para otimizar o desempenho do sistema em implantações de IA de borda.
- Selecionar os mecanismos de computação do tamanho certo para atender ou exceder os níveis de desempenho exigidos. Para uma aplicação de IA, esses mecanismos de computação devem executar as funções de todo o pipeline de visão (ou seja, pré e pós-processamento de vídeo, inferência de rede neural).
Pode ser necessário um acelerador de IA dedicado, seja ele discreto ou integrado a um SoC (em vez de executar a inferência de IA em uma CPU ou GPU).
- Compreender a diferença entre taxa de transferência e latência; em que a taxa de transferência é a taxa com que os dados podem ser processados em um sistema e a latência mede o atraso no processamento de dados através do sistema e é frequentemente associada à capacidade de resposta em tempo real. Por exemplo, um sistema pode gerar dados de imagem a 100 quadros por segundo (taxa de transferência), mas são necessários 100 ms (latência) para que uma imagem passe pelo sistema.
- Considerando a capacidade de dimensionar facilmente o desempenho da IA no futuro para acomodar necessidades crescentes, requisitos em mudança e tecnologias em evolução (por exemplo, modelos de IA mais avançados para maior funcionalidade e precisão). Você pode realizar o dimensionamento de desempenho usando aceleradores de IA em formato de módulo ou com chips aceleradores de IA adicionais.
Os requisitos reais de desempenho dependem da aplicação. Normalmente, pode-se esperar que, para análise de vídeo, o sistema processe fluxos de dados provenientes de câmeras a 30-60 quadros por segundo e com resolução de 1080p ou 4k. Uma câmera habilitada para IA processaria um único fluxo; um dispositivo de borda processaria vários fluxos em paralelo. Em ambos os casos, o sistema de IA de ponta deve suportar as funções de pré-processamento para transformar os dados do sensor da câmera em um formato que corresponda aos requisitos de entrada da seção de inferência de IA (Figura 1).
As funções de pré-processamento absorvem os dados brutos e executam tarefas como redimensionamento, normalização e conversão do espaço de cores, antes de alimentar o modelo em execução no acelerador de IA. O pré-processamento pode usar bibliotecas eficientes de processamento de imagens como OpenCV para reduzir os tempos de pré-processamento. O pós-processamento envolve a análise da saída da inferência. Ele usa tarefas como supressão não máxima (o NMS interpreta a saída da maioria dos modelos de detecção de objetos) e exibição de imagens para gerar insights acionáveis, como caixas delimitadoras, rótulos de classe ou pontuações de confiança.

Figura 1. Para inferência de modelo de IA, as funções de pré e pós-processamento são normalmente executadas em um processador de aplicativos.
A inferência do modelo de IA pode ter o desafio adicional de processar vários modelos de redes neurais por quadro, dependendo dos recursos do aplicativo. Os aplicativos de visão computacional geralmente envolvem várias tarefas de IA que exigem um pipeline de vários modelos. Além disso, a saída de um modelo é frequentemente a entrada do modelo seguinte. Em outras palavras, os modelos de uma aplicação geralmente dependem uns dos outros e devem ser executados sequencialmente. O conjunto exato de modelos a serem executados pode não ser estático e pode variar dinamicamente, mesmo quadro a quadro.
O desafio de executar vários modelos dinamicamente requer um acelerador de IA externo com memória dedicada e suficientemente grande para armazenar os modelos. Muitas vezes, o acelerador de IA integrado dentro de um SoC não consegue gerenciar a carga de trabalho multimodelo devido a restrições impostas pelo subsistema de memória compartilhada e outros recursos no SoC.
Por exemplo, o rastreamento de objetos baseado em previsão de movimento depende de detecções contínuas para determinar um vetor que é usado para identificar o objeto rastreado em uma posição futura. A eficácia desta abordagem é limitada porque carece de uma verdadeira capacidade de reidentificação. Com a previsão de movimento, o rastreamento de um objeto pode ser perdido devido a detecções perdidas, oclusões ou à saída do objeto do campo de visão, mesmo que momentaneamente. Uma vez perdido, não há como reassociar o rastro do objeto. Adicionar reidentificação resolve esta limitação, mas requer uma incorporação de aparência visual (ou seja, uma impressão digital de imagem). Os embeddings de aparência requerem uma segunda rede para gerar um vetor de características processando a imagem contida dentro da caixa delimitadora do objeto detectado pela primeira rede. Esta incorporação pode ser usada para reidentificar o objeto novamente, independentemente do tempo ou espaço. Como os embeddings devem ser gerados para cada objeto detectado no campo de visão, os requisitos de processamento aumentam à medida que a cena fica mais ocupada. O rastreamento de objetos com reidentificação requer uma consideração cuidadosa entre a execução de detecção de alta precisão/alta resolução/alta taxa de quadros e a reserva de sobrecarga suficiente para escalabilidade de incorporações. Uma maneira de resolver o requisito de processamento é usar um acelerador de IA dedicado. Conforme mencionado anteriormente, o mecanismo de IA do SoC pode sofrer com a falta de recursos de memória compartilhada. A otimização do modelo também pode ser usada para reduzir os requisitos de processamento, mas pode afetar o desempenho e/ou a precisão.
Em uma câmera inteligente ou dispositivo de borda, o SoC integrado (ou seja, processador host) adquire os quadros de vídeo e executa as etapas de pré-processamento descritas anteriormente. Essas funções podem ser executadas com os núcleos de CPU ou GPU do SoC (se houver), mas também podem ser executadas por aceleradores de hardware dedicados no SoC (por exemplo, processador de sinal de imagem). Após a conclusão dessas etapas de pré-processamento, o acelerador de IA integrado ao SoC pode acessar diretamente essa entrada quantizada da memória do sistema ou, no caso de um acelerador de IA discreto, a entrada é então entregue para inferência, normalmente através do Interface USB ou PCIe.
Um SoC integrado pode conter uma variedade de unidades de computação, incluindo CPUs, GPUs, acelerador de IA, processadores de visão, codificadores/decodificadores de vídeo, processador de sinal de imagem (ISP) e muito mais. Todas essas unidades de computação compartilham o mesmo barramento de memória e, consequentemente, acessam a mesma memória. Além disso, a CPU e a GPU também podem desempenhar um papel na inferência e essas unidades estarão ocupadas executando outras tarefas em um sistema implantado. Isto é o que queremos dizer com sobrecarga no nível do sistema (Figura 2).
Muitos desenvolvedores avaliam erroneamente o desempenho do acelerador de IA integrado no SoC sem considerar o efeito da sobrecarga no nível do sistema no desempenho total. Como exemplo, considere executar um benchmark YOLO em um acelerador de IA de 50 TOPS integrado em um SoC, que pode obter um resultado de benchmark de 100 inferências/segundo (IPS). Mas num sistema implantado com todas as suas outras unidades computacionais ativas, esses 50 TOPS poderiam ser reduzidos para algo como 12 TOPS e o desempenho geral renderia apenas 25 IPS, assumindo um generoso fator de utilização de 25%. A sobrecarga do sistema é sempre um fator se a plataforma processa continuamente fluxos de vídeo. Alternativamente, com um acelerador de IA discreto (por exemplo, Kinara Ara-1, Hailo-8, Intel Myriad X), a utilização no nível do sistema pode ser superior a 90% porque uma vez que o SoC host inicia a função de inferência e transfere a entrada do modelo de IA dados, o acelerador funciona de forma autônoma utilizando sua memória dedicada para acessar pesos e parâmetros do modelo.
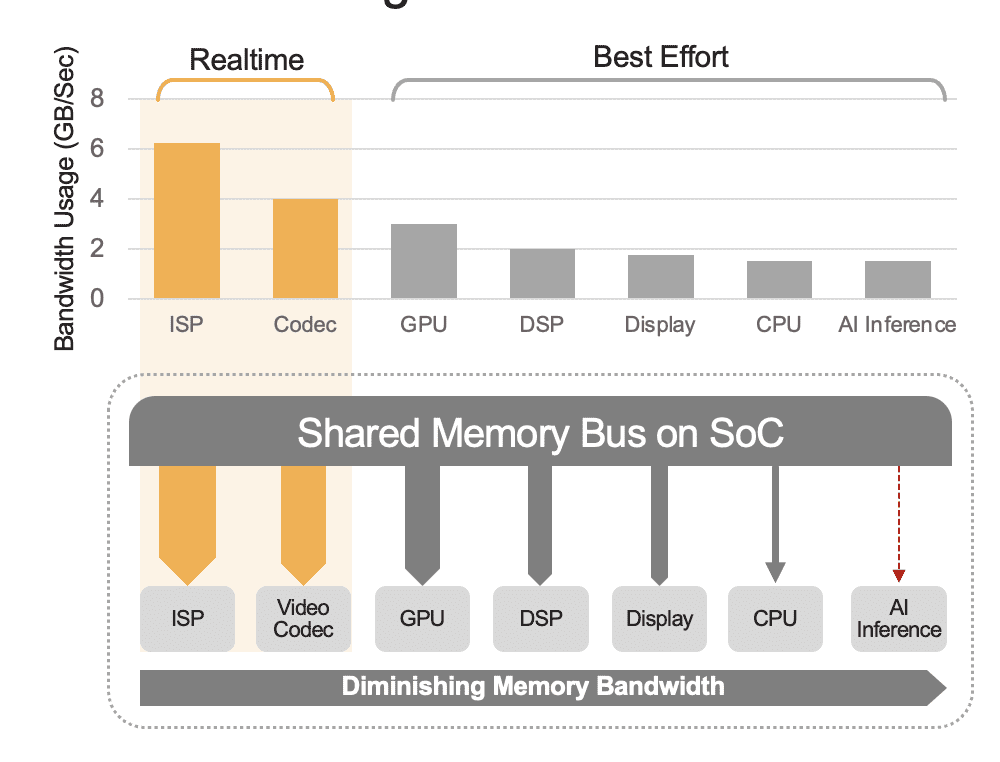
Figura 2. O barramento de memória compartilhada controlará o desempenho no nível do sistema, mostrado aqui com valores estimados. Os valores reais variarão com base no modelo de uso do seu aplicativo e na configuração da unidade de computação do SoC.
Até este ponto, discutimos o desempenho da IA em termos de frames por segundo e TOPS. Mas a baixa latência é outro requisito importante para fornecer capacidade de resposta em tempo real de um sistema. Por exemplo, em jogos, a baixa latência é crítica para uma experiência de jogo contínua e responsiva, especialmente em jogos controlados por movimento e sistemas de realidade virtual (VR). Em sistemas de direção autônoma, a baixa latência é vital para detecção de objetos em tempo real, reconhecimento de pedestres, detecção de faixa e reconhecimento de sinais de trânsito para evitar comprometer a segurança. Os sistemas de direção autônoma normalmente exigem latência de ponta a ponta inferior a 150 ms, desde a detecção até a ação real. Da mesma forma, na fabricação, a baixa latência é essencial para a detecção de defeitos em tempo real, o reconhecimento de anomalias e a orientação robótica dependem da análise de vídeo de baixa latência para garantir uma operação eficiente e minimizar o tempo de inatividade da produção.
Em geral, existem três componentes de latência em um aplicativo de análise de vídeo (Figura 3):
- A latência de captura de dados é o tempo desde a captura de um quadro de vídeo pelo sensor da câmera até a disponibilidade do quadro para processamento no sistema analítico. Você pode otimizar essa latência escolhendo uma câmera com sensor rápido e processador de baixa latência, selecionando taxas de quadros ideais e usando formatos de compactação de vídeo eficientes.
- A latência de transferência de dados é o tempo que os dados de vídeo capturados e compactados levam para viajar da câmera até os dispositivos de borda ou servidores locais. Isto inclui atrasos de processamento de rede que ocorrem em cada ponto final.
- A latência de processamento de dados refere-se ao tempo que os dispositivos de borda levam para executar tarefas de processamento de vídeo, como descompressão de quadros e algoritmos analíticos (por exemplo, rastreamento de objetos baseado em previsão de movimento, reconhecimento facial). Conforme apontado anteriormente, a latência de processamento é ainda mais importante para aplicações que devem executar vários modelos de IA para cada quadro de vídeo.
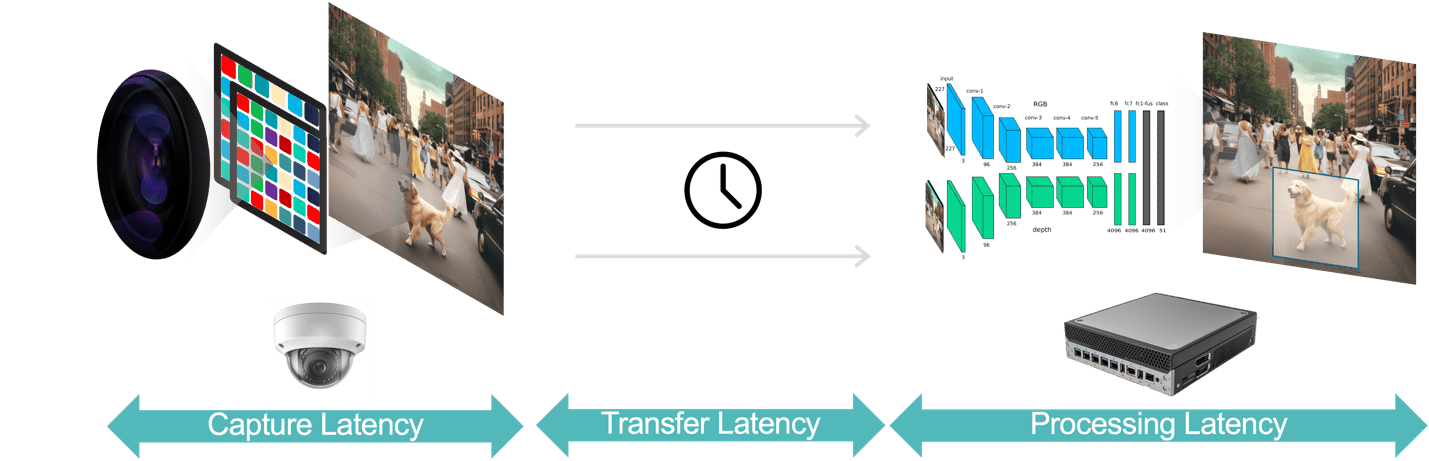
Figura 3. O pipeline de análise de vídeo consiste em captura, transferência e processamento de dados.
A latência do processamento de dados pode ser otimizada usando um acelerador de IA com uma arquitetura projetada para minimizar a movimentação de dados através do chip e entre a computação e vários níveis da hierarquia de memória. Além disso, para melhorar a latência e a eficiência no nível do sistema, a arquitetura deve suportar tempo de comutação zero (ou próximo de zero) entre modelos, para melhor suportar os aplicativos multimodelos que discutimos anteriormente. Outro fator para melhorar o desempenho e a latência está relacionado à flexibilidade algorítmica. Em outras palavras, algumas arquiteturas são projetadas para um comportamento ideal apenas em modelos específicos de IA, mas com o ambiente de IA em rápida mudança, novos modelos para maior desempenho e melhor precisão estão aparecendo no que parece ser dia sim, dia não. Portanto, selecione um processador de IA de borda sem restrições práticas de topologia, operadores e tamanho do modelo.
Há muitos fatores a serem considerados na maximização do desempenho em um dispositivo de IA de ponta, incluindo requisitos de desempenho e latência e sobrecarga do sistema. Uma estratégia bem-sucedida deve considerar um acelerador externo de IA para superar as limitações de memória e desempenho no mecanismo de IA do SoC.
CH. Tchau é um talentoso executivo de marketing e gerenciamento de produtos, Chee tem ampla experiência na promoção de produtos e soluções na indústria de semicondutores, com foco em IA baseada em visão, conectividade e interfaces de vídeo para vários mercados, incluindo empresas e consumidores. Como empresário, Chee foi cofundador de duas start-ups de semicondutores de vídeo que foram adquiridas por uma empresa pública de semicondutores. Chee liderou equipes de marketing de produto e gosta de trabalhar com uma equipe pequena que se concentra em alcançar ótimos resultados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :tem
- :é
- :não
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- habilidade
- acelerador
- aceleradores
- Acesso
- acessando
- acomodar
- realizar
- precisão
- alcançar
- adquirido
- Adquire
- em
- Açao Social
- ativo
- real
- acrescentando
- Adicional
- adotado
- avançado
- Depois de
- novamente
- AI
- Motor AI
- Modelos de IA
- algorítmico
- algoritmos
- Todos os Produtos
- tb
- sempre
- an
- análise
- analítica
- análise
- e
- detecção de anomalia
- Outro
- Aplicação
- aplicações
- abordagem
- arquitetura
- SOMOS
- AS
- associado
- At
- automatizar
- Automação
- Autônomo
- autonomamente
- disponibilidade
- disponível
- evitar
- baseado
- base
- BE
- Porque
- torna-se
- sido
- antes
- ser
- referência
- Melhor
- entre
- ambos
- Caixa
- caixas
- construídas em
- ônibus
- ocupado
- mas a
- by
- Câmera
- câmeras
- CAN
- capacidades
- capacidade
- capturar
- capturados
- Capturar
- cuidadoso
- casas
- casos
- desafiar
- mudança
- lasca
- Chips
- escolha
- classe
- Na nuvem
- cor
- vinda
- Empresa
- competitivo
- Efetuado
- componentes
- comprometendo
- computação
- computacional
- Computar
- computador
- Visão de Computador
- Aplicativos de visão computacional
- confiança
- Configuração
- Conectividade
- Consequentemente
- Considerar
- consideração
- considerado
- considerando
- consiste
- restrições
- consumidor
- não contenho
- contida
- contínuo
- continuamente
- Conversão
- poderia
- CPU
- crítico
- cliente
- dados,
- informática
- dia
- dedicado
- atraso
- atrasos
- entregar
- entregue
- dependente
- Dependendo
- implantado
- Implantações
- descrito
- projetado
- detectou
- Detecção
- Determinar
- desenvolvedores
- Dispositivos/Instrumentos
- diferença
- diretamente
- discutido
- Ecrã
- tempo de inatividade
- condução
- dois
- dinamicamente
- e
- cada
- Mais cedo
- facilmente
- borda
- efeito
- eficácia
- eficiências
- eficiência
- eficiente
- ou
- embutindo
- final
- end-to-end
- Motor
- Motores
- aumentar
- garantir
- Empreendimento
- Todo
- Empreendedor
- Meio Ambiente
- essencial
- estimado
- avaliar
- Mesmo
- Cada
- evolução
- exemplo
- excedem
- executar
- executado
- executivo
- esperar
- vasta experiência
- Experiências
- extenso
- Experiência Extensiva
- externo
- Rosto
- reconhecimento facial
- fator
- fatores
- fábrica
- RÁPIDO
- Característica
- alimentação
- campo
- Figura
- impressão digital
- Primeiro nome
- Flexibilidade
- concentra-se
- focando
- Escolha
- formato
- QUADRO
- da
- função
- funcionalidade
- funções
- Além disso
- futuro
- ganhando
- Games
- jogos
- experiência de jogo
- Geral
- gerar
- gerado
- generoso
- Go
- GPU
- GPUs
- ótimo
- maior
- Crescente
- Growth
- orientações
- Hardware
- Ter
- conseqüentemente
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- hierarquia
- Alta
- superior
- hospedeiro
- HTTPS
- i
- identificar
- if
- imagem
- Impacto
- importante
- Imposta
- melhorar
- melhorado
- in
- Em outra
- inclui
- Incluindo
- Crescimento
- aumentou
- indústrias
- indústria
- Inicia
- entrada
- dentro
- insights
- integrado
- Intel
- Interface
- interfaces de
- para dentro
- envolver
- envolve
- independentemente
- ISP
- IT
- ESTÁ
- KDnuggetsGenericName
- Rótulos
- Falta
- Pista
- grande
- Latência
- partida
- levou
- menos
- níveis
- bibliotecas
- como
- limitação
- limitações
- Limitado
- local
- perdido
- Baixo
- diminuir
- gerencia
- de grupos
- fabrica
- muitos
- Marketing
- Mercados
- Maximizar
- maximizando
- Posso..
- significar
- medidas
- Conheça
- Memória
- mencionado
- poder
- perdido
- modelo
- modelos
- módulo
- monitoração
- mais
- a maioria
- movimento
- movimento
- múltiplo
- devo
- miríade
- Perto
- Cria
- rede
- Neural
- rede neural
- Novo
- Próximo
- não
- objeto
- Detecção de Objetos
- ocorrer
- of
- frequentemente
- on
- uma vez
- ONE
- só
- OpenCV
- operação
- operacional
- operadores
- contrário
- ideal
- otimização
- Otimize
- otimizado
- otimizando
- or
- Outros
- Fora
- saída
- Acima de
- global
- Superar
- Paralelo
- parâmetros
- particularmente
- para
- realizar
- atuação
- realizada
- realização
- executa
- oleoduto
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- ponto
- posição
- pós-processamento
- Prática
- predição
- processo
- processado
- em processamento
- Subcontratante
- processadores
- Produto
- Produção
- Produtos
- Promoção
- fornecer
- público
- alcance
- variando
- rápido
- rapidamente
- Taxa
- Preços
- Cru
- dados não tratados
- reais
- em tempo real
- Realidade
- reconhecimento
- reduzir
- refere-se
- requerer
- requeridos
- requerimento
- Requisitos
- exige
- Resolução
- Recursos
- responsivo
- restrições
- resultar
- Resultados
- robótica
- Tipo
- Execute
- corrida
- é executado
- Segurança
- mesmo
- AMPLIAR
- Escala
- escala ai
- dimensionamento
- cena
- pontuações
- desatado
- Segundo
- Seção
- Vejo
- parece
- selecionando
- Semicondutor
- conjunto
- Partilhar
- compartilhado
- minha
- rede de apoio social
- mostrando
- assinar
- Signal
- Similarmente
- desde
- solteiro
- Tamanho
- pequeno
- smart
- solução
- Soluções
- RESOLVER
- Resolve
- alguns
- algo
- Espaço
- específico
- start-ups
- Passos
- loja
- estratégias
- Estratégia
- transmitir canais
- córregos
- bem sucedido
- tal
- suficiente
- ajuda
- supressão
- vigilância
- .
- sistemas
- Tire
- toma
- tarefas
- Profissionais
- equipes
- Tecnologias
- Tecnologia
- condições
- do que
- que
- A
- O Futuro
- deles
- então
- Lá.
- assim sendo
- Este
- deles
- isto
- aqueles
- três
- Através da
- Taxa de transferência
- tempo
- vezes
- para
- Tops
- Total
- pista
- Rastreamento
- tráfego
- transferência
- fáceis
- Transformar
- viagens
- verdadeiro
- dois
- tipicamente
- Em última análise
- incapaz
- compreender
- unidade
- unidades
- Uso
- usb
- usar
- usava
- usos
- utilização
- geralmente
- Utilizando
- Valores
- variedade
- vário
- Vídeo
- Ver
- Virtual
- A realidade virtual
- visão
- vital
- vr
- Caminho..
- we
- foram
- O Quê
- se
- qual
- largamente
- precisarão
- de
- sem
- palavras
- trabalhar
- seria
- X
- Produção
- Yolo
- Você
- investimentos
- zefirnet
- zero







