
Imagem do Adobe Firefly
“Éramos muitos. Tínhamos acesso a muito dinheiro, a muitos equipamentos e, aos poucos, enlouquecemos.”
Francis Ford Coppola não estava a fazer uma metáfora para as empresas de IA que gastam demasiado e se perdem, mas poderia ter feito. Apocalypse Now foi épico, mas também um projeto longo, difícil e caro de ser feito, assim como o GPT-4. Eu sugeriria que o desenvolvimento de LLMs gravitou em torno de muito dinheiro e muito equipamento. E parte do hype “acabamos de inventar a inteligência geral” é um pouco insana. Mas agora é a vez das comunidades de código aberto fazerem o que fazem de melhor: fornecer software concorrente gratuito usando muito menos dinheiro e equipamento.
A OpenAI recebeu mais de US$ 11 bilhões em financiamento e estima-se que o GPT-3.5 custe entre US$ 5 e US$ 6 milhões por treinamento. Sabemos muito pouco sobre o GPT-4 porque o OpenAI não diz nada, mas acho que é seguro assumir que não é menor que o GPT-3.5. Atualmente há uma escassez mundial de GPU e – para variar – não é por causa da criptomoeda mais recente. Start-ups de IA generativa estão conseguindo rodadas de Série A de mais de US$ 100 milhões com avaliações enormes quando não possuem nenhuma propriedade intelectual do LLM que usam para impulsionar seu produto. O movimento LLM está em alta velocidade e o dinheiro está fluindo.
Parecia que a sorte estava lançada: apenas empresas com grandes recursos como Microsoft/OpenAI, Amazon e Google poderiam se dar ao luxo de treinar modelos de centenas de bilhões de parâmetros. Supunha-se que modelos maiores eram modelos melhores. GPT-3 tem algo errado? Espere até que haja uma versão maior e tudo ficará bem! As empresas menores que buscavam competir tiveram que levantar muito mais capital ou ficariam construindo integrações de commodities no mercado ChatGPT. A academia, com orçamentos de investigação ainda mais limitados, foi relegada para segundo plano.
Felizmente, um grupo de pessoas inteligentes e projetos de código aberto consideraram isso um desafio e não uma restrição. Pesquisadores de Stanford lançaram o Alpaca, um modelo de 7 bilhões de parâmetros cujo desempenho se aproxima do modelo de 3.5 bilhões de parâmetros do GPT-175. Na falta de recursos para construir um conjunto de treinamento do tamanho usado pelo OpenAI, eles escolheram inteligentemente pegar um LLM, LLaMA de código aberto treinado e ajustá-lo em uma série de prompts e resultados do GPT-3.5. Essencialmente o modelo aprendeu o que o GPT-3.5 faz, o que acaba por ser uma estratégia muito eficaz para replicar o seu comportamento.
Alpaca é licenciado para uso não comercial apenas em código e dados, pois usa o modelo LLaMA não comercial de código aberto, e a OpenAI proíbe explicitamente qualquer uso de suas APIs para criar produtos concorrentes. Isso cria a perspectiva tentadora de ajustar um LLM de código aberto diferente nas solicitações e resultados do Alpaca… criando um terceiro modelo semelhante ao GPT-3.5 com diferentes possibilidades de licenciamento.
Há outra camada de ironia aqui, pois todos os principais LLMs foram treinados em textos e imagens protegidos por direitos autorais disponíveis na Internet e não pagaram um centavo aos detentores dos direitos. As empresas reivindicam a isenção de “uso justo” sob a lei de direitos autorais dos EUA, com o argumento de que o uso é “transformador”. No entanto, quando se trata do resultado dos modelos que constroem com dados gratuitos, eles realmente não querem que ninguém faça a mesma coisa com eles. Espero que isto mude à medida que os detentores de direitos se apercebam e que possa acabar em tribunal em algum momento.
Este é um ponto separado e distinto daquele levantado por autores de código aberto com licença restritiva que, para IA generativa para produtos de código como o CoPilot, se opõem ao uso de seu código para treinamento, alegando que a licença não está sendo seguida. O problema para os autores individuais de código aberto é que eles precisam demonstrar legitimidade – cópia substantiva – e que sofreram danos. E como os modelos dificultam a vinculação do código de saída à entrada (as linhas do código-fonte do autor) e não há perda econômica (deveria ser gratuito), é muito mais difícil defender um caso. Isto é diferente dos criadores com fins lucrativos (por exemplo, fotógrafos) cujo modelo de negócio consiste em licenciar/vender o seu trabalho e que são representados por agregadores como a Getty Images, que podem mostrar cópias substanciais.
Outra coisa interessante sobre o LLaMA é que ele saiu do Meta. Foi originalmente lançado apenas para pesquisadores e depois vazou via BitTorrent para o mundo. A Meta está em um negócio fundamentalmente diferente da OpenAI, Microsoft, Google e Amazon, pois não está tentando vender serviços ou software em nuvem e, portanto, tem incentivos muito diferentes. Ela abriu o código-fonte de seus projetos de computação no passado (OpenCompute) e viu a comunidade aprimorá-los – ela entende o valor do código aberto.
Meta pode acabar sendo um dos mais importantes contribuidores de IA de código aberto. Não só dispõe de recursos enormes, como beneficia se houver uma proliferação de grande tecnologia de IA generativa: haverá mais conteúdo para rentabilizar nas redes sociais. A Meta lançou três outros modelos de IA de código aberto: ImageBind (indexação de dados multidimensionais), DINOv2 (visão computacional) e Segment Anything. Este último identifica objetos únicos em imagens e é lançado sob a licença Apache altamente permissiva.
Por fim, também tivemos o suposto vazamento de um documento interno do Google “Não temos fosso e o OpenAI também não”, que tem uma visão negativa dos modelos fechados versus a inovação de comunidades que produzem modelos muito menores e mais baratos com desempenho próximo ou melhor do que suas contrapartes de código fechado. Digo supostamente porque não há como verificar se a fonte do artigo é interna do Google. No entanto, ele contém este gráfico atraente:
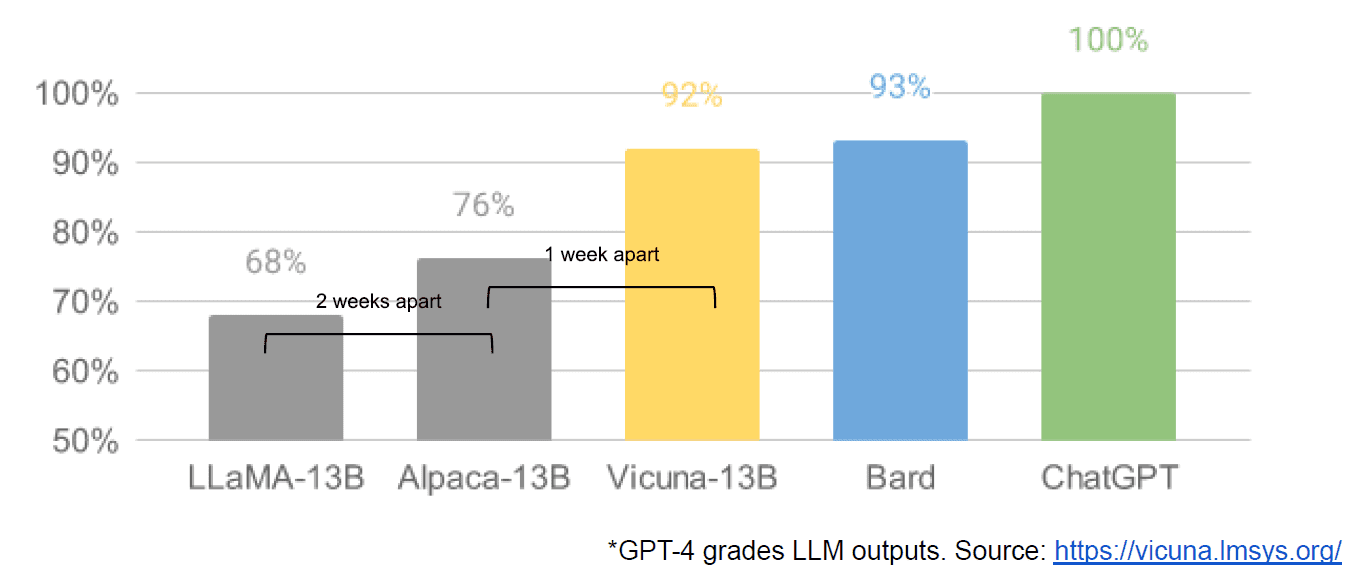
O eixo vertical é a classificação das saídas do LLM pelo GPT-4, para ficar claro.
A difusão estável, que sintetiza imagens a partir de texto, é outro exemplo de onde a IA generativa de código aberto conseguiu avançar mais rapidamente do que os modelos proprietários. Uma iteração recente desse projeto (ControlNet) melhorou-o de tal forma que ultrapassou as capacidades do Dall-E2. Isto resultou de muitos ajustes em todo o mundo, resultando num ritmo de avanço difícil de ser igualado por qualquer instituição. Alguns desses consertadores descobriram como tornar o Stable Diffusion mais rápido para treinar e executar em hardware mais barato, permitindo ciclos de iteração mais curtos para mais pessoas.
E assim fechamos o círculo. Não ter muito dinheiro e muito equipamento inspirou um nível astuto de inovação por parte de toda uma comunidade de pessoas comuns. Que hora para ser um desenvolvedor de IA.
Matheus Lodge é CEO da Diffblue, uma startup AI For Code. Ele tem mais de 25 anos de experiência diversificada em liderança de produtos em empresas como Anaconda e VMware. Lodge atualmente faz parte do conselho do Good Law Project e é vice-presidente do conselho de curadores da Royal Photographic Society.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :tem
- :é
- :não
- :onde
- $UP
- 9
- a
- Capaz
- Sobre
- Academia
- Acesso
- adobe
- avançar
- Agregadores
- AI
- Todos os Produtos
- alegado
- alegadamente
- tb
- Amazon
- an
- e
- Outro
- qualquer
- qualquer um
- nada
- apache
- APIs
- SOMOS
- argumento
- artigo
- AS
- assumiu
- At
- autor
- autores
- disponível
- eixo
- BE
- Porque
- sido
- ser
- Benefícios
- MELHOR
- Melhor
- maior
- BitTorrent
- borda
- ambos
- Orçamentos
- construir
- Prédio
- Monte
- negócio
- modelo de negócio
- mas a
- by
- veio
- CAN
- capacidades
- capital
- casas
- Chefe executivo
- Cadeira
- desafiar
- alterar
- ChatGPT
- mais barato
- escolheu
- Círculo
- reivindicar
- remover filtragem
- Fechar
- fechado
- Na nuvem
- serviços na nuvem
- código
- como
- vem
- mercadoria
- Comunidades
- comunidade
- Empresas
- atraente
- competir
- competindo
- Computar
- computador
- Visão de Computador
- conteúdo
- contribuintes
- copiando
- direitos autorais
- custos
- poderia
- Tribunal de
- crio
- Criar
- criadores
- criptomoeda
- Atualmente
- ciclos
- dados,
- entregando
- deputado
- projetos
- Developer
- Desenvolvimento
- morrem
- diferente
- difícil
- Distribuição
- distinto
- diferente
- do
- documento
- parece
- não
- e
- Econômico
- Eficaz
- permitindo
- final
- Todo
- ÉPICO
- equipamento
- essencialmente
- estimado
- Mesmo
- exemplo
- esperar
- caro
- vasta experiência
- longe
- mais rápido
- figurado
- Fluindo
- seguido
- Escolha
- Ford
- Gratuito
- da
- cheio
- fundamentalmente
- financiamento
- Acessorios
- Geral
- generativo
- IA generativa
- Bom estado, com sinais de uso
- GPU
- gráfico
- ótimo
- tinha
- Queijos duros
- Hardware
- Ter
- ter
- he
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- altamente
- titulares
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- enorme
- Hype
- i
- identifica
- if
- imagens
- importante
- melhorar
- melhorado
- in
- incentivos
- Individual
- Inovação
- entrada
- INSANO
- inspirado
- em vez disso
- Instituição
- integrações
- interessante
- interno
- Internet
- Inventado
- IP
- ironia
- IT
- iteração
- ESTÁ
- apenas por
- KDnuggetsGenericName
- Saber
- aterrissagem
- mais recente
- Escritórios de
- camada
- Liderança
- aprendido
- esquerda
- menos
- Nível
- Licença
- Licenciado
- Licenciamento
- como
- linhas
- LINK
- pequeno
- lhama
- longo
- olhou
- procurando
- perder
- fora
- lote
- principal
- fazer
- Fazendo
- muitos
- marketplace
- maciço
- Match
- Posso..
- Mídia
- Meta
- Microsoft
- modelo
- modelos
- Monetizar
- dinheiro
- mais
- a maioria
- muito
- você merece...
- Nem
- não
- não comercial
- agora
- objeto
- objetos
- of
- on
- ONE
- só
- aberto
- open source
- projetos de código aberto
- OpenAI
- or
- comum
- originalmente
- Outros
- Fora
- saída
- Acima de
- próprio
- Paz
- parâmetro
- passado
- Pagar
- Pessoas
- realizar
- atuação
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- possibilidades
- poder
- Problema
- Produto
- Produtos
- projeto
- projetos
- proprietário
- prospecto
- aumentar
- angariado
- em vez
- clientes
- recentemente
- liberado
- representado
- pesquisa
- pesquisadores
- Recursos
- restrição
- resultando
- direitos
- rodadas
- real
- Execute
- s
- seguro
- mesmo
- dizer
- visto
- segmento
- vender
- separado
- Série
- Série A
- serve
- Serviços
- conjunto
- escassez
- mostrar
- desde
- solteiro
- Tamanho
- menor
- smart
- So
- Redes Sociais
- meios de comunicação social
- Sociedade
- Software
- alguns
- algo
- fonte
- código fonte
- gastar
- estável
- Stanford
- start-ups
- inicialização
- Estratégia
- tal
- sugerir
- suposto
- ultrapassado
- Tire
- tomado
- toma
- Equipar
- do que
- que
- A
- A fonte
- o mundo
- deles
- Eles
- então
- Lá.
- deles
- coisa
- think
- Terceiro
- isto
- aqueles
- três
- tempo
- para
- também
- levou
- Trem
- treinado
- Training
- VIRAR
- voltas
- para
- entende
- único
- ao contrário
- até
- us
- usar
- usava
- usos
- utilização
- Avaliações
- valor
- verificar
- versão
- vertical
- muito
- via
- Ver
- visão
- vmware
- vs
- esperar
- queremos
- foi
- Caminho..
- we
- fui
- foram
- O Quê
- quando
- qual
- QUEM
- inteiro
- de quem
- precisarão
- SENSATO
- com
- Atividades:
- mundo
- Errado
- Você
- zefirnet









