Serviço Amazon OpenSearch é um serviço gerenciado que simplifica a proteção, implantação e operação de clusters OpenSearch em escala na Nuvem AWS. No ano passado, introduzimos Contrapressão de indexação de estilhaços e Controle de admissao, que monitora recursos de cluster e tráfego de entrada para rejeitar seletivamente solicitações que, de outra forma, representariam riscos de estabilidade, como falta de memória e afetariam o desempenho do cluster devido a contenções de memória, saturação de CPU e sobrecarga de GC e muito mais.
Agora temos o prazer de apresentar o Search Backpressure e o controle de admissão baseado em CPU para o OpenSearch Service, que aprimora ainda mais a resiliência dos clusters. Essas melhorias estão disponíveis para todas as versões 1.3 ou superiores do OpenSearch.
Procurar Contrapressão
A contrapressão evita que um sistema seja sobrecarregado com trabalho. Ele faz isso controlando a taxa de tráfego ou descartando carga excessiva para evitar travamentos e perda de dados, melhorar o desempenho e evitar a falha total do sistema.
A contrapressão de pesquisa é um mecanismo para identificar e cancelar solicitações de pesquisa com uso intensivo de recursos em andamento quando um nó está sob pressão. É eficaz contra cargas de trabalho de pesquisa com uso anormalmente alto de recursos (como consultas complexas, consultas lentas, muitas ocorrências ou agregações pesadas), o que poderia causar falhas no nó e afetar a integridade do cluster.
O Search Backpressure é construído sobre a estrutura de rastreamento de recursos de tarefas, que fornece uma API fácil de usar para monitorar o uso de recursos de cada tarefa. O Search Backpressure usa um encadeamento em segundo plano que mede periodicamente o uso de recursos do nó e atribui uma pontuação de cancelamento a cada tarefa de pesquisa em andamento com base em fatores como tempo de CPU, alocações de heap e tempo decorrido. Uma pontuação de cancelamento mais alta corresponde a uma solicitação de pesquisa com uso intensivo de recursos. As solicitações de pesquisa são canceladas em ordem decrescente de sua pontuação de cancelamento para recuperar os nós rapidamente, mas o número de cancelamentos é limitado por taxa para evitar desperdício de trabalho.
O diagrama a seguir ilustra o fluxo de trabalho Search Backpressure.
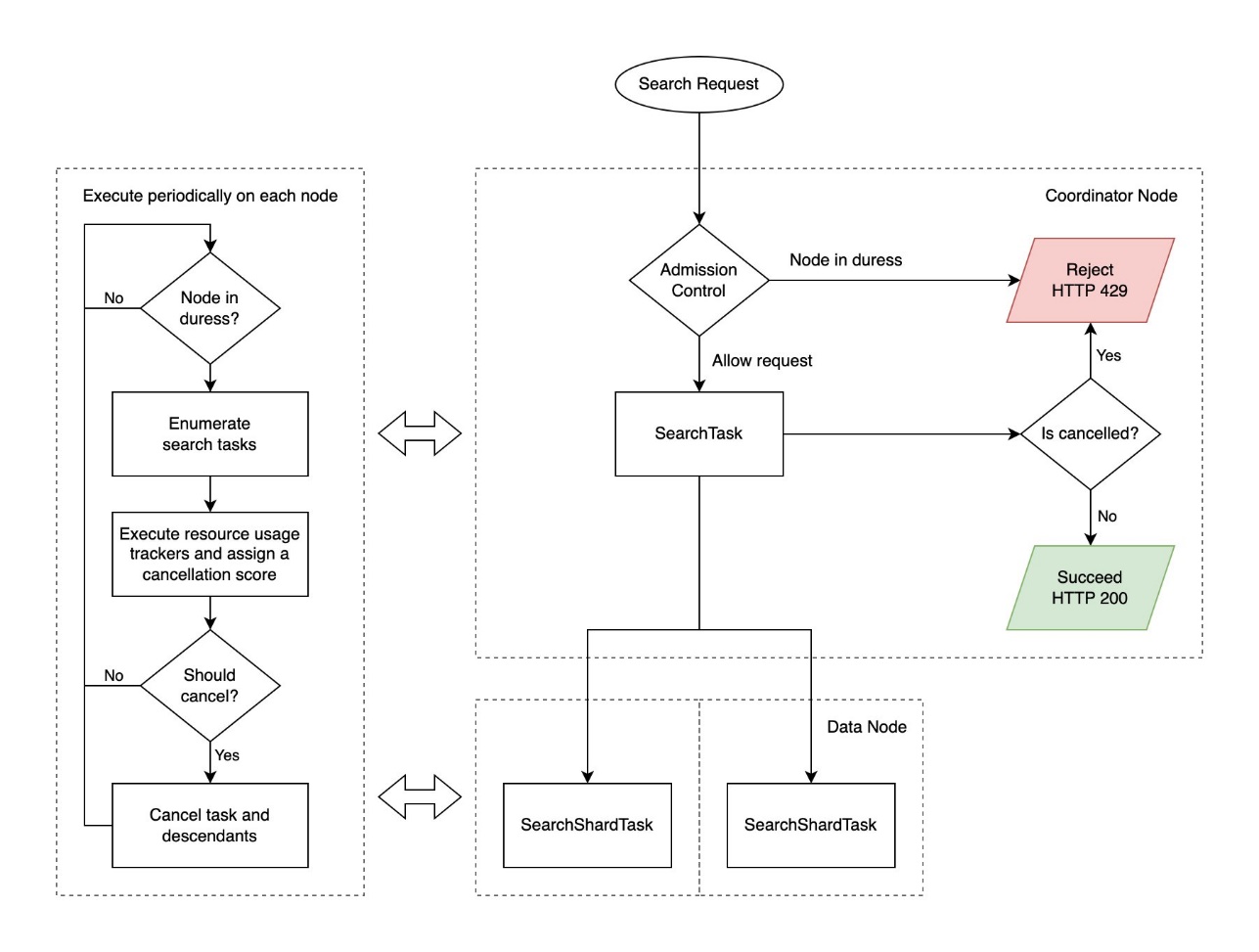
As solicitações de pesquisa retornam um código de status HTTP 429 “Too Many Requests” após o cancelamento. OpenSearch retorna resultados parciais se apenas alguns shards falharem e resultados parciais forem permitidos. Veja o seguinte código:
Monitoramento de contrapressão de pesquisa
Você pode monitorar o estado detalhado de Search Backpressure usando a API de estatísticas do nó:
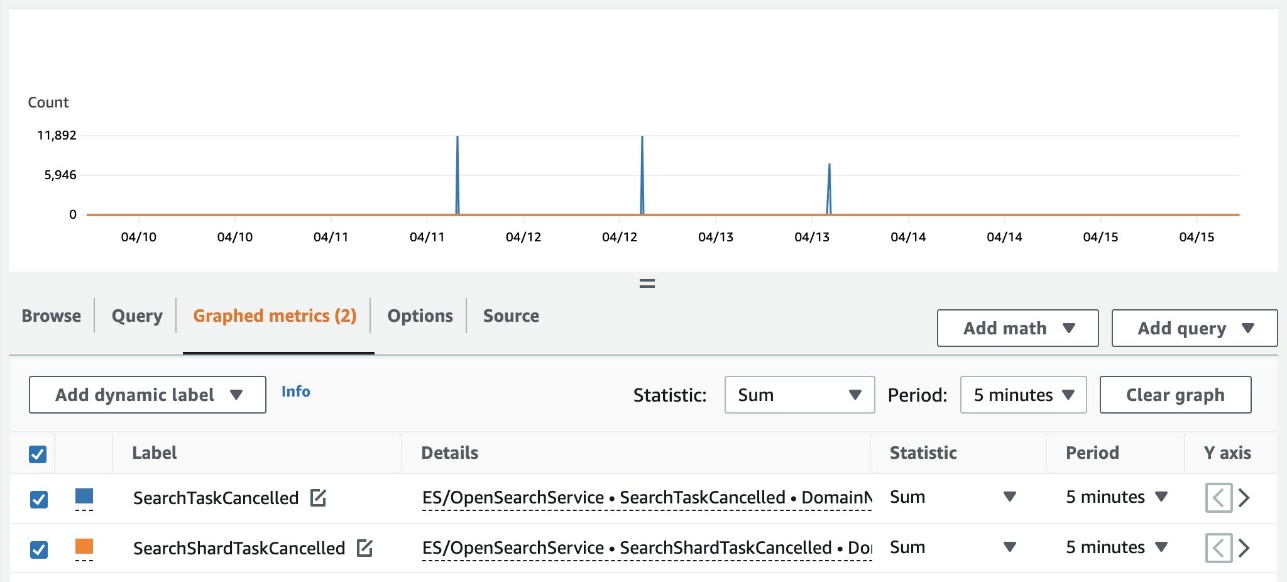
Você também pode visualizar o resumo de cancelamentos em todo o cluster usando Amazon CloudWatch. As seguintes métricas estão agora disponíveis no ES/OpenSearchService espaço de nomes:
- PesquisaTarefaCancelada – O número de cancelamentos de nós coordenadores
- SearchShardTaskCancelado – O número de cancelamentos de nó de dados
A captura de tela a seguir mostra um exemplo de rastreamento dessas métricas no console do CloudWatch.
Controle de admissão baseado em CPU
O controle de admissão é um mecanismo de gatekeeping que limita proativamente o número de solicitações a um nó com base em sua capacidade atual, tanto para aumentos orgânicos quanto para picos de tráfego.
Além da pressão de memória da JVM e dos limites de tamanho da solicitação, agora ele também monitora o uso médio contínuo da CPU de cada nó para rejeitar a entrada _search e _bulk solicitações de. Isso evita que os nós sejam sobrecarregados com muitas solicitações que levam a pontos de acesso, problemas de desempenho, tempos limite de solicitação e outras falhas em cascata. Solicitações excessivas retornam um código de status HTTP 429 “Too Many Requests” após a rejeição.
Manipulando erros HTTP 429
Você receberá erros HTTP 429 se enviar tráfego excessivo para um nó. Indica recursos de cluster insuficientes, solicitações de pesquisa com uso intensivo de recursos ou um pico não intencional na carga de trabalho.
A pressão de pesquisa fornece o motivo da rejeição, o que pode ajudar a ajustar as solicitações de pesquisa com uso intensivo de recursos. Para picos de tráfego, recomendamos novas tentativas do lado do cliente com espera e jitter exponenciais.
Você também pode seguir estes guias de solução de problemas para depurar rejeições excessivas:
Conclusão
Search Backpressure é um mecanismo reativo para diminuir a carga excessiva, enquanto o controle de admissão é um mecanismo proativo para limitar o número de solicitações a um nó além de sua capacidade. Ambos trabalham em conjunto para melhorar a resiliência geral de um cluster OpenSearch.
Pesquisar Contrapressão está disponível em Opensearch, e estamos sempre procurando contribuições externas. Você pode consultar o RFC para começar.
Sobre os autores
 Ketan Verma é um SDE Sênior que trabalha no Amazon OpenSearch Service. Ele é apaixonado por construir sistemas distribuídos em grande escala, melhorar o desempenho e simplificar ideias complexas com abstrações simples. Fora do trabalho, ele gosta de ler e melhorar suas habilidades de barista doméstico.
Ketan Verma é um SDE Sênior que trabalha no Amazon OpenSearch Service. Ele é apaixonado por construir sistemas distribuídos em grande escala, melhorar o desempenho e simplificar ideias complexas com abstrações simples. Fora do trabalho, ele gosta de ler e melhorar suas habilidades de barista doméstico.
 Suresh NS é um SDE Sênior que trabalha no Amazon OpenSearch Service. Ele é apaixonado por resolver problemas em sistemas distribuídos de larga escala.
Suresh NS é um SDE Sênior que trabalha no Amazon OpenSearch Service. Ele é apaixonado por resolver problemas em sistemas distribuídos de larga escala.
 Pritkumar Ladani é um SDE-2 trabalhando no Amazon OpenSearch Service. Ele gosta de contribuir para o desenvolvimento de software de código aberto e é apaixonado por sistemas distribuídos. Ele é um jogador amador de badminton e gosta de trekking.
Pritkumar Ladani é um SDE-2 trabalhando no Amazon OpenSearch Service. Ele gosta de contribuir para o desenvolvimento de software de código aberto e é apaixonado por sistemas distribuídos. Ele é um jogador amador de badminton e gosta de trekking.
 Bukhtawar Khan é um engenheiro principal que trabalha no Amazon OpenSearch Service. Ele está interessado em construir sistemas distribuídos e autônomos. Ele é um mantenedor e colaborador ativo do OpenSearch.
Bukhtawar Khan é um engenheiro principal que trabalha no Amazon OpenSearch Service. Ele está interessado em construir sistemas distribuídos e autônomos. Ele é um mantenedor e colaborador ativo do OpenSearch.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- EVM Finanças. Interface unificada para finanças descentralizadas. Acesse aqui.
- Grupo de Mídia Quântica. IR/PR Amplificado. Acesse aqui.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/improved-resiliency-with-backpressure-and-admission-control-for-amazon-opensearch-service/
- :é
- 1
- 1.3
- 100
- 26
- 7
- 77
- a
- Sobre
- ativo
- Adição
- contra
- Todos os Produtos
- alocações
- tb
- sempre
- amador
- Amazon
- Amazon Web Services
- an
- e
- api
- SOMOS
- AS
- At
- Autônomo
- sistemas autônomos
- disponível
- média
- evitar
- AWS
- fundo
- barista
- baseado
- ser
- Pós
- ambos
- Prédio
- construído
- mas a
- by
- CAN
- Capacidade
- Causar
- Na nuvem
- Agrupar
- código
- integrações
- cônsul
- contribuir
- contribuinte
- ao controle
- controle
- Coordenador
- corresponde
- poderia
- CPU
- Atual
- dados,
- Perda de Dados
- implantar
- detalhado
- Desenvolvimento
- distribuído
- Sistemas distribuídos
- parece
- dois
- cada
- fácil de usar
- Eficaz
- ou
- engenheiro
- Melhora
- erro
- erros
- Éter (ETH)
- exemplo
- excedido
- animado
- exponencial
- fatores
- FALHA
- Falha
- seguir
- seguinte
- Escolha
- Quadro
- da
- mais distante
- porteiro
- ter
- Guias
- he
- Saúde
- pesado
- ajudar
- Alta
- superior
- sua
- acessos
- Início
- HOT
- http
- HTTPS
- idéias
- identificar
- if
- ilustra
- Impacto
- melhorar
- melhorado
- melhorias
- melhorar
- in
- Entrada
- Aumenta
- índice
- indicam
- interessado
- introduzir
- introduzido
- IT
- ESTÁ
- jpg
- grande
- em grande escala
- Sobrenome
- Ano passado
- principal
- como
- LIMITE
- limites
- carregar
- procurando
- fora
- FAZ
- gerenciados
- muitos
- medidas
- mecanismo
- Memória
- Métrica
- Monitore
- monitores
- mais
- nó
- nós
- agora
- número
- of
- on
- só
- aberto
- open source
- operar
- or
- ordem
- orgânico
- Outros
- de outra forma
- Fora
- lado de fora
- global
- sobrecarregado
- apaixonado
- atuação
- fase
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogador
- pressão
- evitar
- impede
- Diretor
- Proactive
- problemas
- fornece
- consultas
- rapidamente
- Taxa
- Leia
- razão
- receber
- recomendar
- Recuperar
- solicitar
- pedidos
- recurso
- uso intensivo de recursos
- Recursos
- Resultados
- retorno
- Retorna
- riscos
- rolando
- Escala
- Ponto
- Pesquisar
- seguro
- Vejo
- enviar
- senior
- serviço
- Serviços
- derramar
- Shows
- simples
- simplificando
- Tamanho
- Habilidades
- lento
- So
- Software
- desenvolvimento de software
- Resolvendo
- alguns
- fonte
- espigão
- picos
- Estabilidade
- começado
- Estado
- stats
- Status
- tal
- RESUMO
- .
- sistemas
- Tandem
- Tarefa
- que
- A
- deles
- Este
- tempo
- para
- também
- topo
- Total
- para
- Rastreamento
- tráfego
- verdadeiro
- tipo
- para
- sobre
- Uso
- usos
- utilização
- Ver
- foi
- we
- web
- serviços web
- quando
- qual
- enquanto
- de
- Atividades:
- de gestão de documentos
- trabalhar
- seria
- ano
- Você
- zefirnet