Amazon RedShift, um data warehouse em nuvem amplamente utilizado, evoluiu significativamente para atender aos requisitos de desempenho das cargas de trabalho mais exigentes. Esta postagem aborda um desses novos recursos: a chave de classificação de layout de dados multidimensionais.
O Amazon Redshift agora melhora o desempenho da consulta com suporte a chaves de classificação de layout de dados multidimensionais, que é um novo tipo de chave de classificação que classifica os dados de uma tabela por predicados de filtro em vez de colunas físicas da tabela. As chaves de classificação de layout de dados multidimensionais melhorarão significativamente o desempenho das verificações de tabela, especialmente quando sua carga de trabalho de consulta contém filtros de verificação repetitivos.
O Amazon Redshift já oferece a capacidade de otimização automática de mesa (ATO), que otimiza automaticamente o design de tabelas aplicando chaves de classificação e distribuição sem a necessidade de intervenção do administrador. Nesta postagem, apresentamos chaves de classificação de layout de dados multidimensionais como um recurso adicional oferecido pelo ATO e fortalecido pelo algoritmo de aconselhamento de chave de classificação do Amazon Redshift.
Chaves de classificação de layout de dados multidimensionais
Quando você define uma tabela com a chave de classificação AUTO, o Amazon Redshift ATO analisará seu histórico de consultas e selecionará automaticamente uma chave de classificação de coluna única ou uma chave de classificação de layout de dados multidimensional para sua tabela, com base na opção melhor para sua carga de trabalho. Quando o layout de dados multidimensionais for selecionado, o Amazon Redshift construirá uma função de classificação multidimensional que coloca linhas que normalmente são acessadas pelas mesmas consultas, e a função de classificação é posteriormente usada durante as execuções de consulta para ignorar blocos de dados e até mesmo ignorar a verificação do predicado individual colunas.
Considere a seguinte consulta do usuário, que é um padrão de consulta dominante na carga de trabalho do usuário:
O Amazon Redshift armazena dados de cada coluna em blocos de disco de 1 MB e armazena os valores mínimo e máximo em cada bloco como parte dos metadados da tabela. Se uma consulta usar um predicado com restrição de intervalo, o Amazon Redshift pode usar os valores mínimo e máximo para ignorar rapidamente um grande número de blocos durante verificações de tabela. No entanto, o filtro desta consulta na coluna da sub-região não pode ser usado para determinar quais blocos ignorar com base nos valores mínimo e máximo e, como resultado, o Amazon Redshift verifica todas as linhas da tabela de títulos:
Quando a consulta do usuário foi executada com titles usando uma chave de classificação de coluna única em subregion, o resultado da consulta anterior é o seguinte:
Isso mostra que a varredura da tabela leu 2,164,081,640 linhas.
Para melhorar as varreduras no titles tabela, o Amazon Redshift poderá decidir automaticamente usar uma chave de classificação de layout de dados multidimensional. Todas as linhas que satisfazem o lower(subregion) like '%United States%' O predicado seria co-localizado em uma região dedicada da tabela e, portanto, o Amazon Redshift verificará apenas blocos de dados que satisfaçam o predicado.
Quando a consulta do usuário é executada com titles usando uma chave de classificação de layout de dados multidimensional que inclui lower(subregion) like '%United States%' como um predicado, o resultado do sys_query_detail consulta é a seguinte:
Isso mostra que a varredura da tabela leu 152,324,046 linhas, o que representa apenas 7% do original, e usou a chave de classificação de layout de dados multidimensionais.
Observe que este exemplo usa uma única consulta para mostrar o recurso de layout de dados multidimensionais, mas o Amazon Redshift considerará todas as consultas executadas na tabela e poderá criar várias regiões para satisfazer os predicados executados com mais frequência.
Vejamos outro exemplo, desta vez com predicados mais complexos e múltiplas consultas.
Imagine ter uma mesa items (cost int, available int, demand int) com quatro linhas, conforme mostrado no exemplo a seguir.
| #Eu iria | custo | disponível | demanda |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Sua carga de trabalho dominante consiste em duas consultas:
- Padrão de consultas de 70%:
- Padrão de consultas de 20%:
Com técnicas de classificação tradicionais, você pode optar por classificar a tabela na coluna de custo, de modo que a avaliação de cost > 3 se beneficiará com o tipo. Então, a tabela de itens após a classificação usando um único cost coluna será semelhante à seguinte.
| #Eu iria | custo | disponível | demanda |
| Região nº 1, com custo <= 3 | |||
| Região nº 2, com custo > 3 | |||
| #Eu iria | custo | disponível | demanda |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Ao usar essa classificação tradicional, podemos excluir imediatamente as duas primeiras linhas (azuis) com ID 4 e ID 2, porque elas não satisfazem cost > 3.
Por outro lado, com uma chave de classificação de layout de dados multidimensional, a tabela será classificada com base em uma combinação dos dois predicados que ocorrem comumente na carga de trabalho do usuário, que são cost > 3 e available < demand. Como resultado, as linhas da tabela são classificadas em quatro regiões.
| #Eu iria | custo | disponível | demanda |
| Região nº 1, com custo <= 3 e disponibilidade < demanda | |||
| Região nº 2, com custo <= 3 e disponibilidade >= demanda | |||
| Região nº 3, com custo > 3 e disponibilidade < demanda | |||
| Região nº 4, com custo > 3 e disponibilidade >= demanda | |||
| #Eu iria | custo | disponível | demanda |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Este conceito é ainda mais poderoso quando aplicado a blocos inteiros em vez de linhas únicas, quando aplicado a predicados complexos que usam operadores não adequados para técnicas tradicionais de classificação (como like) e quando aplicado a mais de dois predicados.
Tabelas do sistema
As tabelas de sistema do Amazon Redshift a seguir mostrarão aos usuários se layouts de dados multidimensionais são usados em suas tabelas e consultas:
- Para determinar se uma tabela específica está usando uma chave de classificação de layout de dados multidimensional, você pode verificar se
sortkey1in svv_table_info é igual aAUTO(SORTKEY(padb_internal_mddl_key_col)). - Para determinar se uma consulta específica usa layout de dados multidimensionais para acelerar varreduras de tabela, você pode verificar
step_attributeno sys_query_detail visualizar. O valor será igual amulti-dimensionalse a chave de classificação do layout de dados multidimensionais da tabela foi usada durante a verificação.
Benchmarks de desempenho
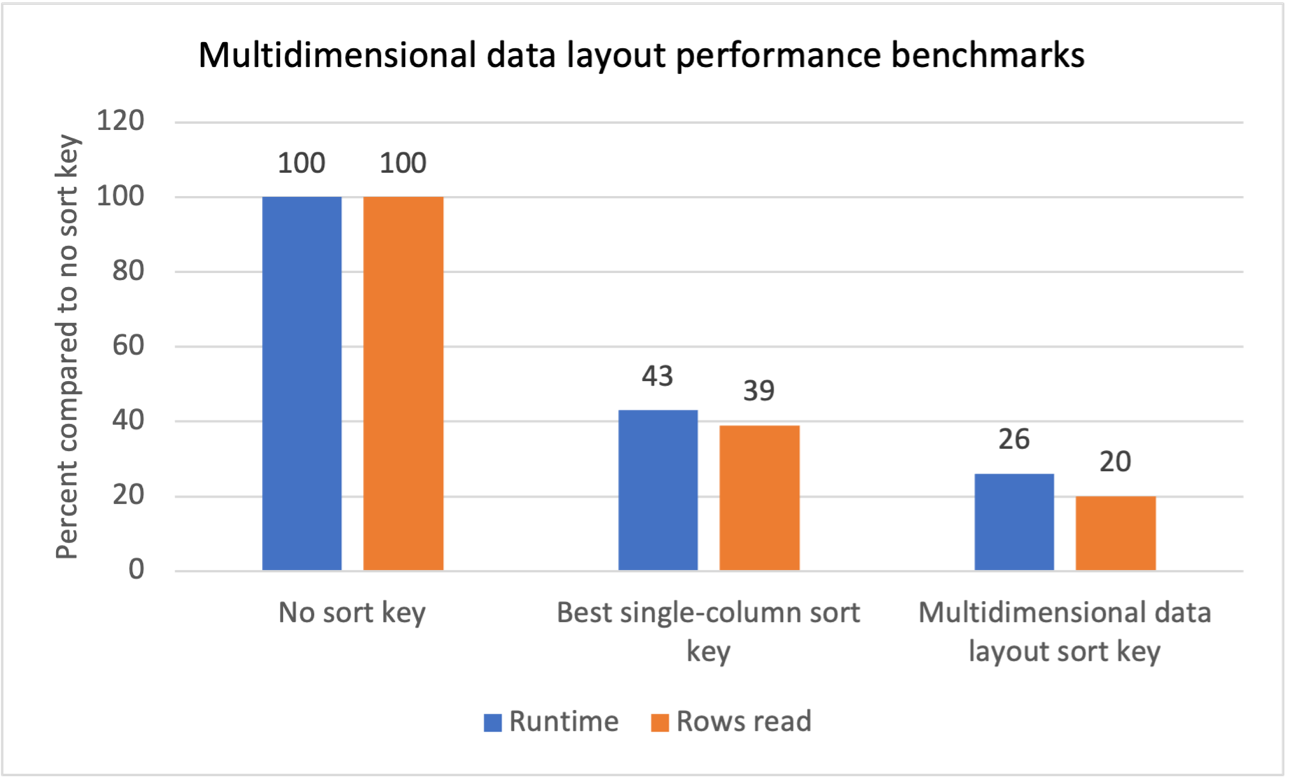
Realizamos testes de benchmark internos para diversas cargas de trabalho com filtros de varredura repetitivos e observamos que a introdução de chaves de classificação de layout de dados multidimensionais produziu os seguintes resultados:
- Uma redução total de 74% no tempo de execução em comparação com a ausência de chave de classificação.
- Uma redução total de 40% no tempo de execução em comparação com a melhor chave de classificação de coluna única em cada tabela.
- Uma redução de 80% no total de linhas lidas nas tabelas em comparação com a ausência de chave de classificação.
- Uma redução de 47% no total de linhas lidas nas tabelas em comparação com a melhor chave de classificação de coluna única em cada tabela.
Comparação de recursos
Com a introdução de chaves de classificação de layout de dados multidimensionais, suas tabelas agora podem ser classificadas por expressões baseadas nos predicados de filtro que ocorrem comumente em sua carga de trabalho. A tabela a seguir fornece uma comparação de recursos do Amazon Redshift em relação a dois concorrentes.
| Característica | Amazon RedShift | Concorrente A | Concorrente B |
| Suporte para classificação em colunas | Sim | Sim | Sim |
| Suporte para classificação por expressão | Sim | Sim | Não |
| Seleção automática de colunas para classificação | Sim | Não | Sim |
| Seleção automática de expressões para classificação | Sim | Não | Não |
| Seleção automática entre classificação de colunas ou classificação de expressões | Sim | Não | Não |
| Uso automático de propriedades de classificação para expressões durante varreduras | Sim | Não | Não |
Considerações
Tenha em mente o seguinte ao usar um layout de dados multidimensional:
- O layout de dados multidimensionais é ativado quando você define sua tabela como SORTKEY AUTO.
- O Amazon Redshift Advisor escolherá automaticamente uma chave de classificação de coluna única ou um layout de dados multidimensional para a tabela, analisando sua carga de trabalho histórica.
- O Amazon Redshift ATO ajusta os resultados da classificação do layout de dados multidimensionais com base na maneira como as consultas em andamento interagem com a carga de trabalho.
- O Amazon Redshift ATO mantém chaves de classificação de layout de dados multidimensionais da mesma forma que faz atualmente para chaves de classificação existentes. Referir-se Trabalhando com otimização automática de tabelas para obter mais detalhes sobre ATO.
- As chaves de classificação de layout de dados multidimensionais funcionarão tanto com clusters provisionados quanto com grupos de trabalho sem servidor.
- As chaves de classificação de layout de dados multidimensionais funcionarão com seus dados existentes, desde que AUTO SORTKEY esteja habilitado em sua tabela e uma carga de trabalho com filtros de varredura repetitivos seja detectada. A tabela será reorganizada com base nos resultados da função de classificação multidimensional.
- Para desabilitar chaves de classificação de layout de dados multidimensionais para uma tabela, use alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Isso desativa o recurso de chave de classificação AUTO na tabela. - As chaves de classificação de layout de dados multidimensionais são preservadas ao restaurar ou migrar seu cluster provisionado para um cluster sem servidor ou vice-versa.
Conclusão
Nesta postagem, mostramos que as chaves de classificação de layout de dados multidimensionais podem melhorar significativamente o desempenho do tempo de execução de consultas para cargas de trabalho em que as consultas dominantes possuem filtros de verificação repetitivos.
Para criar um cluster de visualização no console do Amazon Redshift, navegue até a página Clusters página e escolha Criar cluster de visualização. Você pode criar um cluster nas regiões Leste dos EUA (Ohio), Leste dos EUA (Norte da Virgínia), Oeste dos EUA (Oregon), Ásia-Pacífico (Tóquio), Europa (Irlanda) e Europa (Estocolmo) e testar suas cargas de trabalho.
Gostaríamos muito de ouvir seus comentários sobre esse novo recurso e aguardamos seus comentários nesta postagem.
Sobre os autores
 Milind Oke é um Arquiteto de Soluções Especialista em Data Warehouse baseado em Nova York. Ele desenvolve soluções de data warehouse há mais de 15 anos e é especialista em Amazon Redshift.
Milind Oke é um Arquiteto de Soluções Especialista em Data Warehouse baseado em Nova York. Ele desenvolve soluções de data warehouse há mais de 15 anos e é especialista em Amazon Redshift.
 Jialin Ding é cientista aplicado no Learned Systems Group, especializado na aplicação de técnicas de aprendizado de máquina e otimização para melhorar o desempenho de sistemas de dados como o Amazon Redshift.
Jialin Ding é cientista aplicado no Learned Systems Group, especializado na aplicação de técnicas de aprendizado de máquina e otimização para melhorar o desempenho de sistemas de dados como o Amazon Redshift.
 Yanzhuji é gerente de produto da equipe do Amazon Redshift. Ela tem experiência em visão e estratégia de produtos em plataformas e produtos de dados líderes do setor. Ela tem habilidade notável na construção de produtos de software substanciais usando desenvolvimento web, design de sistema, banco de dados e técnicas de programação distribuída. Em sua vida pessoal, Yanzhu gosta de pintar, fotografar e jogar tênis.
Yanzhuji é gerente de produto da equipe do Amazon Redshift. Ela tem experiência em visão e estratégia de produtos em plataformas e produtos de dados líderes do setor. Ela tem habilidade notável na construção de produtos de software substanciais usando desenvolvimento web, design de sistema, banco de dados e técnicas de programação distribuída. Em sua vida pessoal, Yanzhu gosta de pintar, fotografar e jogar tênis.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :tem
- :é
- :não
- :onde
- 1
- 100
- 15 anos
- 15%
- 152
- 7
- 8
- 9
- a
- acelerar
- acessadas
- Adicional
- assessor
- Depois de
- contra
- algoritmo
- Todos os Produtos
- já
- Amazon
- Amazon Web Services
- an
- analisar
- análise
- e
- Outro
- aplicado
- Aplicando
- SOMOS
- AS
- Ásia
- Ásia-Pacífico
- auto
- Automático
- automaticamente
- disponível
- AWS
- baseado
- BE
- Porque
- sido
- referência
- beneficiar
- MELHOR
- Melhor
- entre
- Bloquear
- Blocos
- Azul
- ambos
- Prédio
- mas a
- by
- CAN
- capacidade
- verificar
- Escolha
- Na nuvem
- Agrupar
- Coluna
- colunas
- combinação
- comentários
- geralmente
- comparado
- comparação
- concorrentes
- integrações
- conceito
- Considerar
- consiste
- cônsul
- construir
- contém
- Custo
- cobre
- crio
- Atualmente
- dados,
- data warehouse
- banco de dados
- decidir
- dedicado
- definir
- Demanda
- exigente
- Design
- detalhes
- detectou
- Determinar
- Desenvolvimento
- distribuído
- distribuição
- parece
- dominante
- não
- durante
- cada
- Leste
- ou
- habilitado
- Todo
- igual
- especialmente
- Éter (ETH)
- Europa
- avaliação
- Mesmo
- evoluiu
- exemplo
- existente
- vasta experiência
- expressões
- Característica
- retornos
- filtro
- filtros
- seguinte
- segue
- Escolha
- para a frente
- quatro
- da
- função
- Grupo
- mão
- Ter
- ter
- he
- ouvir
- sua experiência
- histórico
- história
- Contudo
- HTML
- HTTPS
- ID
- if
- imediatamente
- melhorar
- melhora
- in
- inclui
- Individual
- líder da indústria
- em vez disso
- interagir
- interno
- da intervenção
- para dentro
- introduzir
- introduzindo
- Introdução
- Irlanda
- IT
- Unid
- Chave
- chaves
- grande
- traçado
- aprendido
- aprendizagem
- vida
- como
- gostos
- longo
- olhar
- parece
- gosta,
- máquina
- aprendizado de máquina
- mantém
- Gerente
- maneira
- máximo
- Conheça
- metadados
- poder
- migrando
- mente
- mínimo
- mais
- a maioria
- múltiplo
- Navegar
- você merece...
- Novo
- novo recurso
- New York
- não
- agora
- números
- ocorrendo
- of
- WOW!
- oferecido
- Ohio
- on
- ONE
- contínuo
- só
- operadores
- otimização
- Otimiza
- Opção
- or
- ordem
- Oregon
- original
- Outros
- Fora
- marcante
- Acima de
- Pacífico
- pintura
- parte
- particular
- padrão
- atuação
- realizada
- pessoal
- fotografia
- físico
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- Publique
- poderoso
- conservado
- visualização
- Produzido
- Produto
- gerente de produto
- Produtos
- Programação
- Propriedades
- fornece
- consultas
- rapidamente
- Leia
- redução
- referir
- região
- regiões
- repetitivo
- Requisitos
- restauração
- resultar
- Resultados
- Execute
- corrida
- é executado
- mesmo
- digitalização
- exploração
- digitaliza
- Cientista
- Épocas
- Vejo
- selecionar
- selecionado
- doadores,
- Serverless
- Serviços
- conjunto
- ela
- mostrar
- mostrar
- mostrou
- mostrando
- Shows
- de forma considerável
- solteiro
- habilidade
- So
- Software
- Soluções
- especialista
- especializada
- especializando
- lojas
- Estratégia
- Subseqüentemente
- substancial
- tal
- adequado
- Apoiar
- .
- sistemas
- mesa
- Tire
- Profissionais
- técnicas
- tênis
- teste
- ensaio
- do que
- que
- A
- deles
- assim sendo
- deles
- isto
- tempo
- títulos
- para
- Tóquio
- topo
- Total
- tradicional
- dois
- tipo
- tipicamente
- us
- usar
- usava
- Utilizador
- usuários
- usos
- utilização
- valor
- Valores
- vício
- Ver
- Virgínia
- visão
- Armazém
- foi
- Caminho..
- we
- web
- Desenvolvimento web
- serviços web
- Ocidente
- quando
- se
- qual
- largamente
- precisarão
- de
- sem
- Atividades:
- seria
- anos
- Iorque
- Você
- investimentos
- zefirnet