Neste artigo vamos aprender como implantar e usar o modelo GPT4All em seu computador somente com CPU (estou usando um Macbook Pro sem GPU!)

Use GPT4All no seu computador — Foto do autor
Neste artigo vamos instalar em nosso computador local o GPT4All (um poderoso LLM) e descobriremos como interagir com nossos documentos com python. Uma coleção de PDFs ou artigos online será a base de conhecimento para nossas perguntas/respostas.
De site oficial GPT4All é descrito como um chatbot de uso gratuito, executado localmente e com reconhecimento de privacidade. Não requer GPU ou internet.
GTP4All é um ecossistema para treinar e implantar poderoso e personalizado grandes modelos de linguagem que executam localmente em CPUs de nível de consumidor.
Nosso modelo GPT4All é um arquivo de 4 GB que você pode baixar e conectar ao software de ecossistema de código aberto GPT4All. IA nômica facilita ecossistemas de software seguros e de alta qualidade, impulsionando o esforço para permitir que indivíduos e organizações treinem e implementem facilmente seus próprios modelos de linguagem grandes localmente.
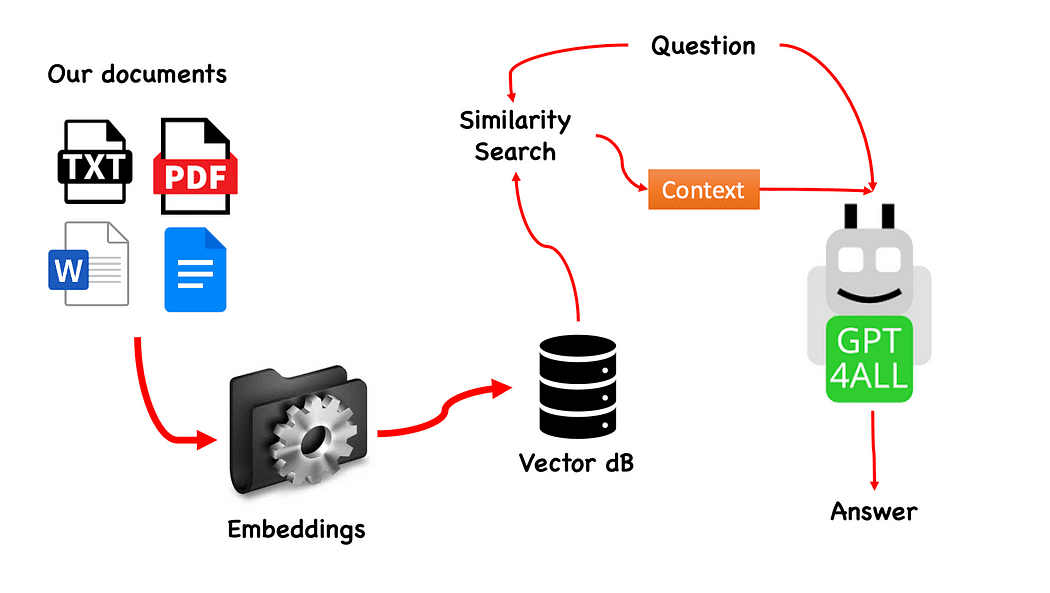
Fluxo de trabalho do QnA com GPT4All — criado pelo autor
O processo é bem simples (quando você conhece) e pode ser repetido com outros modelos também. As etapas são as seguintes:
- carregar o modelo GPT4All
- usar Langchain para recuperar nossos documentos e carregá-los
- dividir os documentos em pequenos pedaços digeríveis por Embeddings
- Use FAISS para criar nosso banco de dados de vetores com os embeddings
- Faça uma busca por similaridade (pesquisa semântica) em nosso banco de dados de vetores com base na pergunta que queremos passar para GPT4All: isso será usado como um contexto para nossa pergunta
- Alimente a pergunta e o contexto para GPT4All com Langchain e aguarde a resposta.
Então, o que precisamos é de Embeddings. Uma incorporação é uma representação numérica de uma informação, por exemplo, texto, documentos, imagens, áudio, etc. A representação captura o significado semântico do que está sendo incorporado, e é exatamente disso que precisamos. Para este projeto não podemos contar com modelos pesados de GPU: então vamos baixar o modelo nativo Alpaca e usar de Langchain que o LlamaCppEmbeddings. Não se preocupe! Tudo é explicado passo a passo
Crie um ambiente virtual
Crie uma nova pasta para seu novo projeto Python, por exemplo GPT4ALL_Fabio (coloque seu nome…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioEm seguida, crie um novo ambiente virtual Python. Se você tiver mais de uma versão do python instalada, especifique a versão desejada: neste caso usarei minha instalação principal, associada ao python 3.10.
python3 -m venv .venvO comando python3 -m venv .venv cria um novo ambiente virtual chamado .venv (o ponto criará um diretório oculto chamado venv).
Um ambiente virtual fornece uma instalação isolada do Python, que permite instalar pacotes e dependências apenas para um projeto específico sem afetar a instalação do Python em todo o sistema ou outros projetos. Esse isolamento ajuda a manter a consistência e evitar possíveis conflitos entre diferentes requisitos do projeto.
Uma vez criado o ambiente virtual, você pode ativá-lo usando o seguinte comando:
source .venv/bin/activate 
Ambiente virtual ativado
As bibliotecas a instalar
Para o projeto que estamos construindo, não precisamos de muitos pacotes. Precisamos apenas:
- ligações python para GPT4All
- Langchain para interagir com nossos documentos
LangChain é uma estrutura para desenvolver aplicativos alimentados por modelos de linguagem. Ele permite não apenas chamar um modelo de linguagem por meio de uma API, mas também conectar um modelo de linguagem a outras fontes de dados e permitir que um modelo de linguagem interaja com seu ambiente.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Para LangChain, você vê que também especificamos a versão. Esta biblioteca está recebendo muitas atualizações recentemente, portanto, para ter certeza de que nossa configuração funcionará também amanhã, é melhor especificar uma versão que sabemos que está funcionando bem. Não estruturado é uma dependência necessária para o carregador de PDF e Pytesseract e pdf2imagem tão bem.
NOTA: no repositório GitHub há um arquivo requirements.txt (sugerido por jl adcr) com todas as versões associadas a este projeto. Você pode fazer a instalação de uma só vez, depois de baixá-lo no diretório principal do arquivo do projeto com o seguinte comando:
pip install -r requirements.txtNo final do artigo criei um seção para solução de problemas. O repositório do GitHub também possui um READ.ME atualizado com todas essas informações.
Tenha em mente que alguns as bibliotecas têm versões disponíveis dependendo da versão do python você está executando em seu ambiente virtual.
Baixe no seu PC os modelos
Este é um passo realmente importante.
Para o projeto, certamente precisamos do GPT4All. O processo descrito no Nomic AI é realmente complicado e requer um hardware que nem todos nós temos (como eu). Então aqui está o link do modelo já convertido e pronto para ser usado. Basta clicar em baixar.
Baixe o modelo GPT4All
Conforme descrito brevemente na introdução, precisamos também do modelo para os embeddings, um modelo que podemos executar em nossa CPU sem esmagar. Clique no link aqui para baixar o alpaca-native-7B-ggml já convertido para 4 bits e pronto para usar como nosso modelo para a incorporação.

Clique na seta de download ao lado de ggml-model-q4_0.bin
Por que precisamos de incorporações? Se você se lembra do diagrama de fluxo, a primeira etapa necessária, depois de coletarmos os documentos para nossa base de conhecimento, é embutir eles. As incorporações LLamaCPP deste modelo Alpaca se encaixam perfeitamente no trabalho e este modelo também é bastante pequeno (4 Gb). A propósito, você também pode usar o modelo Alpaca para o seu QnA!
Atualização 2023.05.25: Os usuários do Mani Windows estão enfrentando problemas para usar os embeddings llamaCPP. Isso acontece principalmente porque durante a instalação do pacote python llama-cpp-python com:
pip install llama-cpp-pythono pacote pip vai compilar a partir da fonte da biblioteca. O Windows geralmente não possui o compilador CMake ou C instalado por padrão na máquina. Mas não se preocupe, há uma solução
Executar a instalação do llama-cpp-python, exigido pelo LangChain com o llamaEmbeddings, no compilador CMake C do Windows não é instalado por padrão, portanto, você não pode compilar a partir do código-fonte.
Em usuários de Mac com Xtools e no Linux, geralmente o compilador C já está disponível no sistema operacional.
Para evitar o problema você DEVE usar a roda pré-cumprida.
Clique aqui https://github.com/abetlen/llama-cpp-python/releases
e procure a roda compatível para sua arquitetura e versão python — você DEVE usar o Weels versão 0.1.49 porque as versões superiores não são compatíveis.
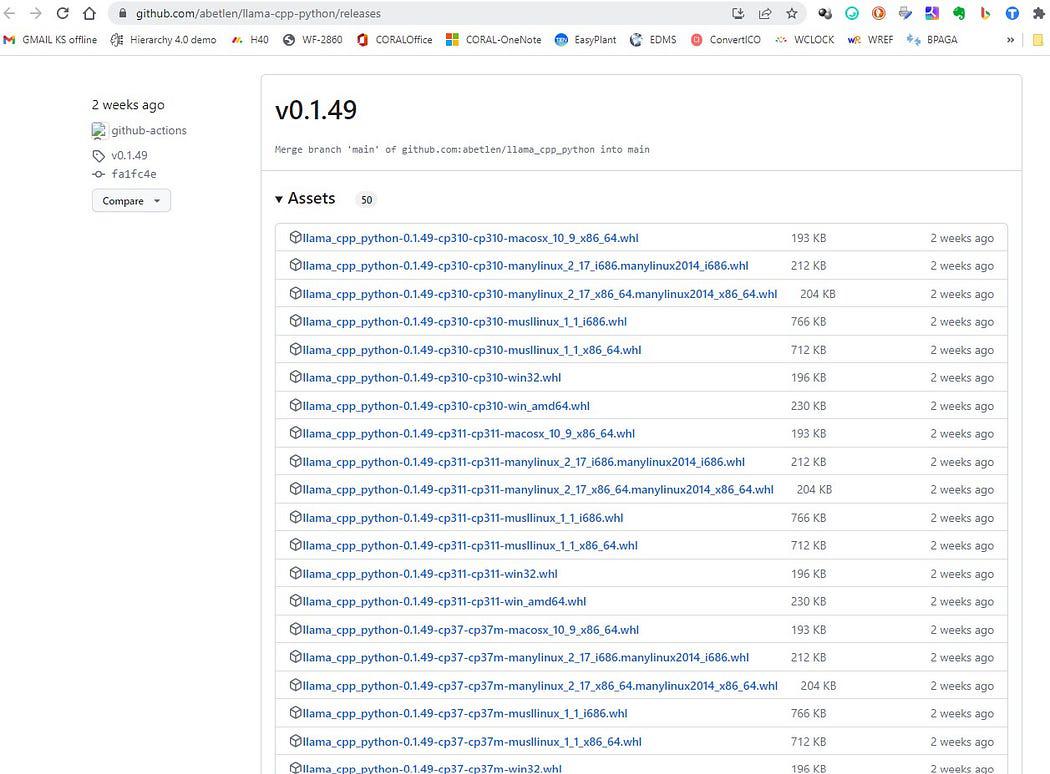
Captura de tela de https://github.com/abetlen/llama-cpp-python/releases
No meu caso tenho Windows 10, 64 bits, python 3.10
então meu arquivo é llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Esta problema é rastreado no repositório GitHub
Após o download você precisa colocar os dois modelos no diretório models, conforme imagem abaixo.

Estrutura de diretórios e onde colocar os arquivos de modelo
Como queremos ter o controle de nossa interação com o modelo GPT, temos que criar um arquivo python (vamos chamá-lo pygpt4all_test.py), importe as dependências e dê a instrução para o modelo. Você verá que é bem fácil.
from pygpt4all.models.gpt4all import GPT4AllEsta é a ligação python para o nosso modelo. Agora podemos chamá-lo e começar a perguntar. Vamos tentar um criativo.
Criamos uma função que lê o callback do modelo e pedimos ao GPT4All para completar nossa frase.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)A primeira instrução está dizendo ao nosso programa onde encontrar o modelo (lembre-se do que fizemos na seção acima)
A segunda declaração é pedir ao modelo para gerar uma resposta e completar nosso prompt “Era uma vez”.
Para executá-lo, verifique se o ambiente virtual ainda está ativado e simplesmente execute:
python3 pygpt4all_test.pyVocê deve ver um texto de carregamento do modelo e a conclusão da frase. Dependendo dos seus recursos de hardware, pode demorar um pouco.
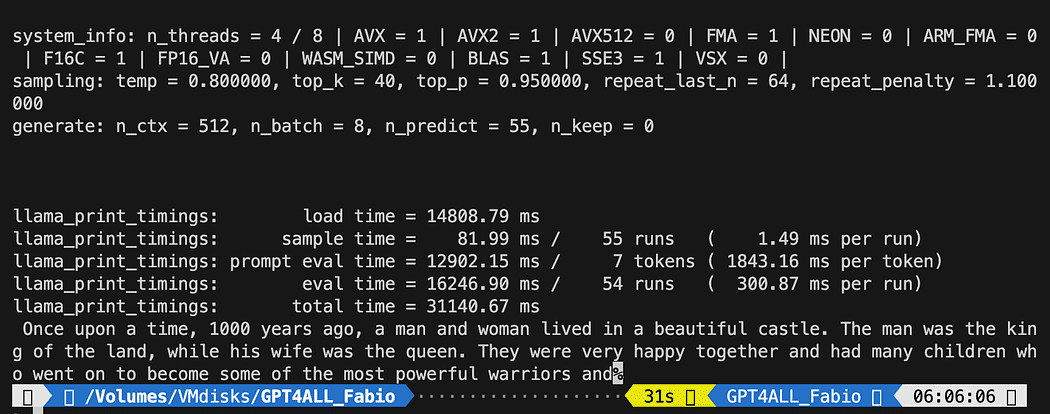
O resultado pode ser diferente do seu… Mas para nós o importante é que está funcionando e podemos prosseguir com o LangChain para criar algumas coisas avançadas.
NOTA (atualizado em 2023.05.23): se você enfrentar um erro relacionado ao pygpt4all, verifique a seção de solução de problemas neste tópico com a solução fornecida por Rajneesh Aggarwal or por Oscar Jung.
A estrutura LangChain é uma biblioteca realmente incrível. Ele fornece Componentes para trabalhar com modelos de linguagem de forma fácil de usar, e também fornece Correntes. As cadeias podem ser pensadas como montando esses componentes de maneiras específicas para melhor realizar um caso de uso específico. Eles devem ser uma interface de nível superior por meio da qual as pessoas podem começar facilmente com um caso de uso específico. Essas correntes também são projetadas para serem personalizáveis.
Em nosso próximo teste de python, usaremos um Modelo de solicitação. Os modelos de linguagem aceitam texto como entrada — esse texto é comumente chamado de prompt. Normalmente, isso não é simplesmente uma string codificada, mas sim uma combinação de um modelo, alguns exemplos e entrada do usuário. LangChain fornece várias classes e funções para facilitar a construção e o trabalho com prompts. Vamos ver como podemos fazer isso também.
Crie um novo arquivo python e chame-o meu_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Importamos do LangChain o Prompt Template and Chain e a classe GPT4All llm para poder interagir diretamente com nosso modelo GPT.
Então, depois de definir nosso caminho llm (como fizemos antes), instanciamos os gerenciadores de retorno de chamada para que possamos capturar as respostas à nossa consulta.
Para criar um modelo é muito fácil: seguindo o tutorial de documentação podemos usar algo assim...
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])A modelo variável é uma string de várias linhas que contém nossa estrutura de interação com o modelo: entre chaves inserimos as variáveis externas ao modelo, em nosso cenário é nosso questão.
Como é uma variável, você pode decidir se é uma pergunta codificada ou uma pergunta de entrada do usuário: aqui estão os dois exemplos.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Para nossa execução de teste, comentaremos a entrada do usuário. Agora só precisamos vincular nosso modelo, a pergunta e o modelo de idioma.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Lembre-se de verificar se seu ambiente virtual ainda está ativado e execute o comando:
python3 my_langchain.pyVocê pode obter resultados diferentes dos meus. O que é incrível é que você pode ver todo o raciocínio seguido pelo GPT4All tentando obter uma resposta para você. Ajustar a pergunta também pode fornecer melhores resultados.
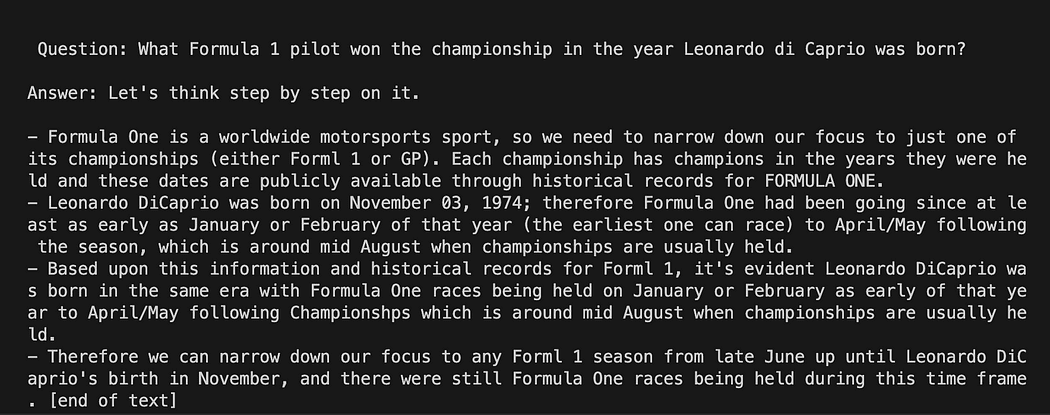
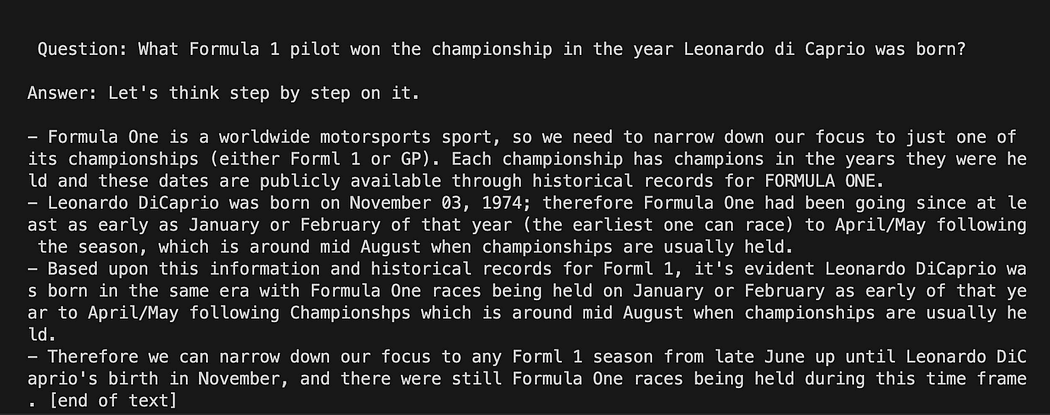
Langchain com modelo de prompt no GPT4All
Aqui começamos a parte incrível, porque vamos conversar com nossos documentos usando o GPT4All como um chatbot que responde às nossas perguntas.
A sequência de passos, referindo-se a Fluxo de trabalho do QnA com GPT4All, é carregar nossos arquivos PDF, transformá-los em pedaços. Depois disso, precisaremos de um Vector Store para nossos embeddings. Precisamos alimentar nossos documentos fragmentados em um armazenamento vetorial para recuperação de informações e, em seguida, vamos incorporá-los junto com a pesquisa de similaridade neste banco de dados como um contexto para nossa consulta LLM.
Para isso vamos utilizar o FAISS diretamente do Langchain biblioteca. FAISS é uma biblioteca de código aberto do Facebook AI Research, projetada para encontrar rapidamente itens semelhantes em grandes coleções de dados de alta dimensão. Ele oferece métodos de indexação e pesquisa para facilitar e agilizar a localização dos itens mais semelhantes em um conjunto de dados. É particularmente conveniente para nós porque simplifica recuperação de informação e nos permite salvar localmente o banco de dados criado: isso significa que após a primeira criação ele será carregado muito rapidamente para qualquer uso posterior.
Criação do índice vetorial db
Crie um novo arquivo e chame-o meu_conhecimento_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeAs primeiras bibliotecas são as mesmas que usamos antes: além disso, estamos usando Langchain para a criação do índice de armazenamento de vetores, o LlamaCppEmbeddings para interagir com nosso modelo Alpaca (quantizado em 4 bits e compilado com a biblioteca cpp) e o carregador de PDF.
Vamos também carregar nossos LLMs com caminhos próprios: um para os embeddings e outro para a geração do texto.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Para testar, vamos ver se conseguimos ler todos os arquivos pfd: o primeiro passo é declarar 3 funções a serem usadas em cada documento. A primeira é dividir o texto extraído em pedaços, a segunda é criar o índice vetorial com os metadados (como números de página etc…) e a última é para testar a busca por similaridade (explicarei melhor depois).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesAgora podemos testar a geração do índice para os documentos no docs diretório: precisamos colocar lá todos os nossos pdfs. Langchain tem também um método para carregar a pasta inteira, independente do tipo de arquivo: como é complicado o pós-processo, falarei sobre isso no próximo artigo sobre modelos de LaMini.

meu diretório docs contém 4 arquivos pdf
Aplicaremos nossas funções ao primeiro documento da lista
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)Nas primeiras linhas, usamos a biblioteca os para obter o lista de arquivos pdf dentro do diretório docs. Em seguida, carregamos o primeiro documento (lista_doc[0]) da pasta docs com Langchain, dividimos em pedaços e então criamos o banco de dados de vetores com o Lhama incorporações.
Como você viu, estamos usando o método pyPDF. Este é um pouco mais longo de usar, já que você tem que carregar os arquivos um por um, mas carregar o PDF usando pypdf em array de documentos permite que você tenha um array onde cada documento contém o conteúdo da página e os metadados com page número. Isso é realmente conveniente quando você deseja saber as fontes do contexto que forneceremos ao GPT4All com nossa consulta. Aqui o exemplo do readthedocs:
Captura de tela de Documentação Langchain
Podemos executar o arquivo python com o comando do terminal:
python3 my_knowledge_qna.pyApós o carregamento do modelo para embeddings você verá os tokens funcionando para a indexação: não se desespere porque vai demorar, principalmente se você rodar apenas na CPU, como eu (demorou 8 minutos).
Conclusão do primeiro vetor db
Como eu estava explicando, o método pyPDF é mais lento, mas nos fornece dados adicionais para a pesquisa de similaridade. Para iterar todos os nossos arquivos, usaremos um método conveniente do FAISS que nos permite mesclar diferentes bancos de dados. O que fazemos agora é usar o código acima para gerar o primeiro db (vamos chamá-lo db0) e com um loop for criamos o índice do próximo arquivo da lista e o mesclamos imediatamente com db0.
Aqui está o código: observe que adicionei alguns logs para fornecer o status do progresso usando datetime.datetime.now() e imprimindo o delta da hora final e hora inicial para calcular quanto tempo a operação levou (você pode removê-lo se não gostar).
As instruções de mesclagem são assim
# merge dbi with the existing db0
db0.merge_from(dbi)Uma das últimas instruções é para salvar nosso banco de dados localmente: a geração inteira pode levar até horas (depende de quantos documentos você tiver), então é muito bom que tenhamos que fazer isso apenas uma vez!
# Save the databasae locally
db0.save_local("my_faiss_index")Aqui o código inteiro. Iremos comentar muitas partes dele quando interagirmos com o GPT4All carregando o índice diretamente de nossa pasta.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  A execução do arquivo python levou 22 minutos
A execução do arquivo python levou 22 minutos
Faça perguntas ao GPT4All sobre seus documentos
Agora estamos aqui. Temos o nosso índice, podemos carregá-lo e com um Prompt Template podemos pedir ao GPT4All para responder às nossas questões. Começamos com uma pergunta codificada e, em seguida, percorremos nossas perguntas de entrada.
Coloque o seguinte código dentro de um arquivo python db_loading.py e execute-o com o comando do terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])O texto impresso é a lista das 3 fontes que melhor correspondem à consulta, dando-nos também o nome do documento e o número da página.
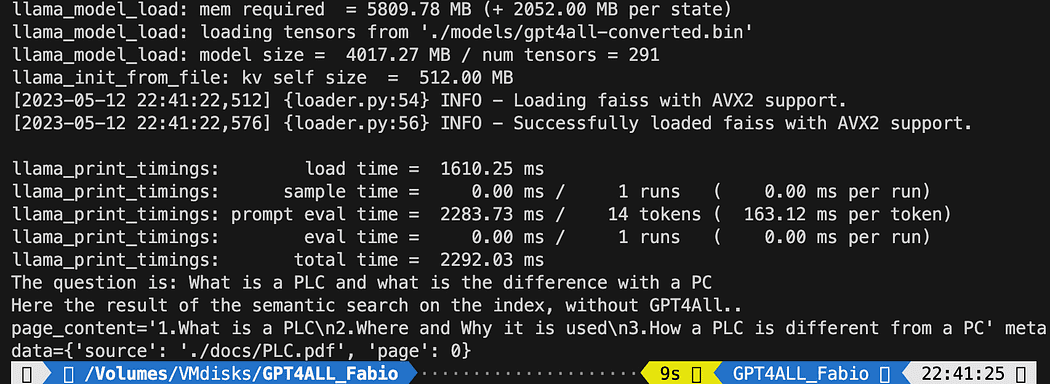
Resultados da pesquisa semântica executando o arquivo db_loading.py
Agora podemos usar a pesquisa de similaridade como contexto para nossa consulta usando o modelo de prompt. Após as 3 funções basta substituir todo o código pelo seguinte:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Após a execução, você obterá um resultado como este (mas pode variar). Incrível não!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Se você deseja que uma pergunta de entrada do usuário substitua a linha
question = "What is a PLC and what is the difference with a PC"com algo assim:
question = input("Your question: ")É hora de você experimentar. Faça diferentes perguntas sobre todos os tópicos relacionados aos seus documentos e veja os resultados. Há muito espaço para melhorias, certamente no prompt e no modelo: você pode dar uma olhada aqui algumas inspirações. Mas Langchain A documentação é realmente incrível (eu poderia acompanhá-la!!).
Você pode seguir o código do artigo ou verificá-lo em meu github repo.
Fábio Matricardi um educador, professor, engenheiro e entusiasta da aprendizagem. Ele leciona há 15 anos para jovens estudantes e agora treina novos funcionários na Key Solution Srl. Ele iniciou minha carreira como Engenheiro de Automação Industrial em 2010. Apaixonado por programação desde a adolescência, descobriu a beleza de construir softwares e Interfaces Homem-Máquina para dar vida a algo. Ensinar e treinar faz parte da minha rotina diária, assim como estudar e aprender a ser um líder apaixonado com habilidades de gestão atualizadas. Junte-se a mim na jornada em direção a um design melhor, uma integração de sistema preditivo usando Machine Learning e Inteligência Artificial durante todo o ciclo de vida da engenharia.
Óptimo estado. Original. Republicado com permissão.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- EVM Finanças. Interface unificada para finanças descentralizadas. Acesse aqui.
- Grupo de Mídia Quântica. IR/PR Amplificado. Acesse aqui.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15 anos
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- habilidade
- Capaz
- Sobre
- acima
- realizar
- Aja
- ativado
- adicionado
- Adição
- Adicional
- avançado
- afetando
- Depois de
- AI
- ai pesquisa
- Todos os Produtos
- permitir
- permite
- já
- tb
- am
- surpreendente
- an
- análise
- e
- responder
- qualquer
- api
- aplicações
- Aplicar
- arquitetura
- SOMOS
- Ordem
- artigo
- artigos
- artificial
- inteligência artificial
- AS
- associado
- At
- auditivo
- Automatizado
- automaticamente
- Automação
- disponível
- evitar
- base
- baseado
- BE
- Beleza
- Porque
- sido
- antes
- ser
- abaixo
- MELHOR
- Melhor
- entre
- Pós
- Grande
- BIN
- obrigatório
- Pouco
- nascido
- brevemente
- trazer
- construir
- Prédio
- construídas em
- ônibus
- mas a
- by
- calcular
- chamada
- chamado
- chamadas
- CAN
- não podes
- Capacidade
- capturas
- Oportunidades
- transportar
- casas
- luta
- CD
- certo
- certamente
- cadeia
- correntes
- campeonato
- chatbot
- ChatGPT
- verificar
- químico
- classe
- aulas
- clique
- treinamento
- código
- códigos
- coletar
- coleção
- coleções
- combinação
- comentar
- geralmente
- comunicar
- Comunicação
- compatível
- completar
- Efetuado
- realização
- integrações
- complicado
- componentes
- computador
- computadores
- Contato
- conectado
- construção
- consumidor
- contém
- conteúdo
- contexto
- ao controle
- controlador
- controles
- Conveniente
- convertido
- poderia
- cobrir
- CPU
- crio
- criado
- cria
- Criar
- criação
- Criatividade
- crítico
- personalizável
- diariamente
- dados,
- banco de dados
- bases de dados
- Data
- datetime
- decidir
- Padrão
- definido
- Delta
- Dependência
- Dependendo
- depende
- implantar
- descrito
- Design
- projetado
- desejado
- em desenvolvimento
- dispositivo
- Dispositivos/Instrumentos
- DID
- diferença
- diferente
- digestível
- digital
- diretamente
- descobrir
- descoberto
- do
- documento
- documentação
- INSTITUCIONAIS
- parece
- não
- feito
- não
- DOT
- download
- condução
- durante
- cada
- mais fácil
- facilmente
- fácil
- ecossistema
- ecossistemas
- esforço
- embutir
- incorporado
- embutindo
- colaboradores
- permitir
- final
- engenheiro
- Engenharia
- Entrar
- entusiasta
- Todo
- Meio Ambiente
- erro
- especialmente
- etc.
- Éter (ETH)
- Mesmo
- tudo
- exatamente
- exemplo
- exemplos
- execução
- existente
- experimentar
- Explicação
- explicado
- explicando
- externo
- Rosto
- facilita
- enfrentando
- RÁPIDO
- mais rápido
- Envie o
- Arquivos
- Encontre
- final
- Primeiro nome
- caber
- fluxo
- seguir
- seguido
- seguinte
- segue
- Escolha
- formulário
- formato
- Fórmula
- Formula 1
- Quadro
- da
- função
- funções
- mais distante
- gerar
- gerando
- geração
- ter
- GitHub
- OFERTE
- dado
- dá
- Dando
- vai
- Bom estado, com sinais de uso
- GPU
- grau
- Manipulação
- acontece
- Queijos duros
- Hardware
- Ter
- he
- pesado
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- oculto
- Alta
- superior
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- humano
- i
- ICS
- if
- imagens
- imediatamente
- executar
- importar
- importante
- melhoria
- in
- incluir
- índice
- índices
- indivíduos
- industrial
- automação industrial
- indústrias
- INFORMAÇÕES
- entrada
- entrada saída
- inputs
- instalar
- instalação
- instância
- instruções
- integração
- Inteligência
- Pretendido
- interagir
- interação
- Interface
- interfaces de
- Internet
- para dentro
- Introdução
- isolado
- isolamento
- IT
- Unid
- iteração
- ESTÁ
- Trabalho
- juntar
- viagem
- apenas por
- KDnuggetsGenericName
- Chave
- Saber
- Conhecimento
- língua
- grande
- Sobrenome
- mais tarde
- líder
- aprendizagem
- Nível
- bibliotecas
- Biblioteca
- vida
- wifecycwe
- como
- linhas
- LINK
- linux
- Lista
- pequeno
- carregar
- carregador
- carregamento
- local
- localmente
- lógica
- longo
- mais
- olhar
- lote
- mac
- máquina
- aprendizado de máquina
- maquinaria
- a Principal
- principalmente
- a manter
- fazer
- gerenciados
- de grupos
- Gerente
- Gerentes
- fabrica
- muitos
- Posso..
- significado
- significa
- Memória
- ir
- fusão
- metadados
- método
- métodos
- mente
- minutos
- modelo
- modelos
- mais
- a maioria
- múltiplo
- devo
- my
- nome
- nativo
- você merece...
- redes
- Novo
- Próximo
- agora
- número
- números
- objeto
- of
- Oferece
- on
- uma vez
- ONE
- online
- só
- open source
- operação
- Operações
- or
- ordem
- organizações
- OS
- Outros
- A Nossa
- Fora
- saída
- Acima de
- próprio
- pacote
- pacotes
- página
- Paralelo
- parte
- particular
- particularmente
- passar
- apaixonado
- caminho
- PC
- Pessoas
- realizar
- permissão
- pessoal
- fotografia
- peça
- piloto
- plantas
- platão
- Inteligência de Dados Platão
- PlatãoData
- PLC
- por favor
- plugue
- portas
- posição
- Publique
- potencial
- poder
- usinas de energia
- alimentado
- poderoso
- pré
- evitar
- Impressão
- impressão
- problemas
- processo
- processado
- processos
- Agenda
- programado
- Programação
- Progresso
- projeto
- projetos
- protocolos
- fornece
- fins
- colocar
- Python
- qualidade
- questão
- Frequentes
- rapidamente
- em vez
- Leia
- pronto
- clientes
- receber
- recentemente
- a que se refere
- refere-se
- Independentemente
- registradores
- relacionado
- confiabilidade
- depender
- lembrar
- remover
- repetido
- substituir
- Denunciar
- repositório
- representação
- requeridos
- Requisitos
- exige
- pesquisa
- Recursos
- resposta
- respostas
- resultar
- Resultados
- retorno
- Quarto
- Execute
- corrida
- s
- Segurança
- mesmo
- Salvar
- poupança
- cenário
- Pesquisar
- pesquisar
- Segundo
- Seção
- seguro
- Vejo
- sensor
- sentença
- Seqüência
- serial
- contexto
- instalação
- vários
- tiro
- rede de apoio social
- mostrando
- semelhante
- simples
- simplesmente
- desde
- solteiro
- Habilidades
- pequeno
- So
- Software
- solução
- alguns
- algo
- fonte
- Fontes
- especializado
- especialmente
- específico
- especificada
- divisão
- Spot
- começo
- começado
- Comece
- Declaração
- Status
- Passo
- Passos
- Ainda
- loja
- Tanga
- estrutura
- Estudantes
- Estudando
- tal
- .
- Tire
- Converse
- tarefas
- professor
- Ensino
- adolescente
- modelo
- terminal
- teste
- Execução de teste
- ensaio
- geração de texto
- do que
- que
- A
- deles
- Eles
- então
- Lá.
- Este
- deles
- think
- isto
- pensamento
- Através da
- todo
- tempo
- para
- juntos
- Tokens
- amanhã
- também
- levou
- tópico
- Temas
- para
- Trem
- tentar
- dois
- tipo
- típico
- tipicamente
- Atualizada
- Atualizações
- sobre
- us
- Uso
- usb
- usar
- caso de uso
- usava
- Utilizador
- usuários
- utilização
- geralmente
- utilizado
- vário
- verificar
- versão
- muito
- via
- Virtual
- W3
- esperar
- queremos
- foi
- Caminho..
- maneiras
- we
- Site
- BEM
- O Quê
- O que é a
- Roda
- quando
- qual
- QUEM
- porque
- largamente
- precisarão
- Windows
- Usuários do Windows
- de
- dentro
- sem
- Ganhou
- Atividades:
- trabalhar
- ano
- anos
- Você
- jovem
- investimentos
- zefirnet










