Hoje, temos o prazer de anunciar a disponibilidade da inferência do Llama 2 e do suporte para ajuste fino no Treinamento AWS e Inferência da AWS instâncias em JumpStart do Amazon SageMaker. O uso de instâncias baseadas em AWS Trainium e Inferentia, por meio do SageMaker, pode ajudar os usuários a reduzir os custos de ajuste fino em até 50% e os custos de implantação em 4.7x, ao mesmo tempo em que reduz a latência por token. Llama 2 é um modelo de linguagem de texto generativo auto-regressivo que usa uma arquitetura de transformador otimizada. Como um modelo disponível publicamente, o Llama 2 foi projetado para muitas tarefas de PNL, como classificação de texto, análise de sentimento, tradução de idiomas, modelagem de linguagem, geração de texto e sistemas de diálogo. O ajuste fino e a implantação de LLMs, como o Llama 2, podem se tornar caros ou desafiadores para atingir o desempenho em tempo real e proporcionar uma boa experiência ao cliente. Trainium e AWS Inferentia, habilitados pelo Neurônio AWS kit de desenvolvimento de software (SDK), oferece uma opção de alto desempenho e econômica para treinamento e inferência de modelos Llama 2.
Nesta postagem, demonstramos como implantar e ajustar o Llama 2 em instâncias Trainium e AWS Inferentia no SageMaker JumpStart.
Visão geral da solução
Neste blog, examinaremos os seguintes cenários:
- Implante o Llama 2 em instâncias do AWS Inferentia tanto no Estúdio Amazon SageMaker UI, com uma experiência de implantação com um clique, e o SageMaker Python SDK.
- Ajuste o Llama 2 em instâncias do Trainium na UI do SageMaker Studio e no SageMaker Python SDK.
- Compare o desempenho do modelo Llama 2 ajustado com o do modelo pré-treinado para mostrar a eficácia do ajuste fino.
Para colocar a mão na massa, veja o Caderno de exemplo do GitHub.
Implante o Llama 2 em instâncias do AWS Inferentia usando a UI do SageMaker Studio e o Python SDK
Nesta seção, demonstramos como implantar o Llama 2 em instâncias do AWS Inferentia usando a UI do SageMaker Studio para uma implantação com um clique e o Python SDK.
Descubra o modelo Llama 2 na UI do SageMaker Studio
O SageMaker JumpStart fornece acesso a recursos disponíveis publicamente e proprietários modelos de fundação. Os modelos básicos são integrados e mantidos por fornecedores terceirizados e proprietários. Como tal, eles são lançados sob licenças diferentes, conforme designado pela fonte do modelo. Certifique-se de revisar a licença de qualquer modelo de base que você usar. Você é responsável por revisar e cumprir quaisquer termos de licença aplicáveis e garantir que eles sejam aceitáveis para seu caso de uso antes de baixar ou usar o conteúdo.
Você pode acessar os modelos básicos do Llama 2 por meio do SageMaker JumpStart na IU do SageMaker Studio e do SageMaker Python SDK. Nesta seção, veremos como descobrir os modelos no SageMaker Studio.
SageMaker Studio é um ambiente de desenvolvimento integrado (IDE) que fornece uma única interface visual baseada na web onde você pode acessar ferramentas específicas para executar todas as etapas de desenvolvimento de aprendizado de máquina (ML), desde a preparação de dados até a construção, treinamento e implantação de seu ML modelos. Para obter mais detalhes sobre como começar e configurar o SageMaker Studio, consulte Estúdio Amazon SageMaker.
Depois de entrar no SageMaker Studio, você pode acessar o SageMaker JumpStart, que contém modelos pré-treinados, notebooks e soluções pré-construídas, em Soluções pré-construídas e automatizadas. Para obter informações mais detalhadas sobre como acessar modelos proprietários, consulte Use modelos básicos proprietários do Amazon SageMaker JumpStart no Amazon SageMaker Studio.
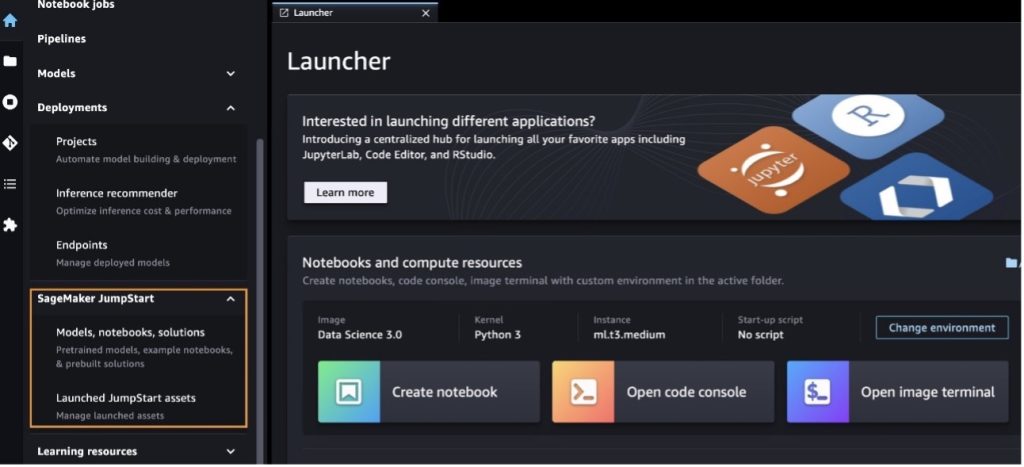
Na página inicial do SageMaker JumpStart, você pode procurar soluções, modelos, notebooks e outros recursos.
Se você não vir os modelos Llama 2, atualize sua versão do SageMaker Studio desligando e reiniciando. Para obter mais informações sobre atualizações de versão, consulte Encerre e atualize os aplicativos do Studio Classic.

Você também pode encontrar outras variantes de modelo escolhendo Explore todos os modelos de geração de texto ou procurando por llama or neuron na caixa de pesquisa. Você poderá visualizar os modelos Llama 2 Neuron nesta página.
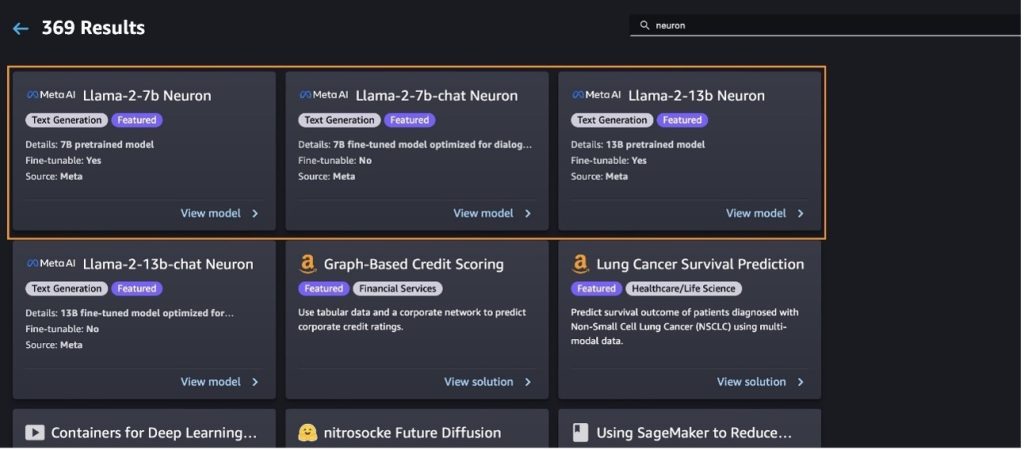
Implante o modelo Llama-2-13b com SageMaker Jumpstart
Você pode escolher o cartão do modelo para visualizar detalhes sobre o modelo, como licença, dados usados para treinar e como usá-lo. Você também pode encontrar dois botões, Implantação e Caderno aberto, que ajuda você a usar o modelo usando este exemplo sem código.
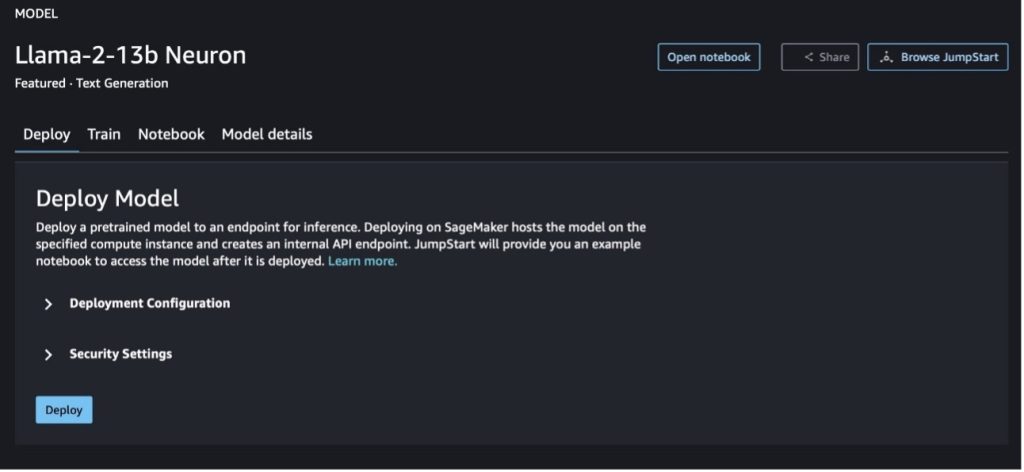
Ao escolher qualquer um dos botões, um pop-up mostrará o Contrato de Licença do Usuário Final e a Política de Uso Aceitável (AUP) para você confirmar.
Depois de reconhecer as políticas, você poderá implantar o ponto final do modelo e usá-lo por meio das etapas da próxima seção.
Implante o modelo Llama 2 Neuron por meio do Python SDK
Quando você escolhe Implantação e reconhecer os termos, a implantação do modelo será iniciada. Como alternativa, você pode implantar por meio do notebook de exemplo escolhendo Caderno aberto. O caderno de exemplo fornece orientação completa sobre como implantar o modelo para inferência e limpeza de recursos.
Para implantar ou ajustar um modelo em instâncias Trainium ou AWS Inferentia, primeiro você precisa chamar PyTorch Neuron (tocha-neuronx) para compilar o modelo em um gráfico específico do Neuron, que irá otimizá-lo para NeuronCores do Inferentia. Os usuários podem instruir o compilador a otimizar para menor latência ou maior rendimento, dependendo dos objetivos do aplicativo. No JumpStart, pré-compilamos os gráficos do Neuron para uma variedade de configurações, para permitir que os usuários realizem etapas de compilação, permitindo ajuste fino e implantação de modelos mais rápidos.
Observe que o gráfico pré-compilado do Neuron é criado com base em uma versão específica da versão do Neuron Compiler.
Existem duas maneiras de implantar o LIama 2 em instâncias baseadas no AWS Inferentia. O primeiro método utiliza a configuração pré-construída e permite implantar o modelo em apenas duas linhas de código. No segundo, você tem maior controle sobre a configuração. Vamos começar com o primeiro método, com a configuração pré-construída, e usar o modelo Llama 2 13B Neuron pré-treinado, como exemplo. O código a seguir mostra como implantar o Llama 13B com apenas duas linhas:
Para realizar inferência nesses modelos, você precisa especificar o argumento accept_eula ser True como parte do model.deploy() chamar. Definir este argumento como verdadeiro reconhece que você leu e aceitou o EULA do modelo. O EULA pode ser encontrado na descrição do cartão do modelo ou no Metasite.
O tipo de instância padrão para Llama 2 13B é ml.inf2.8xlarge. Você também pode tentar outros IDs de modelos suportados:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(modelo de bate-papo)meta-textgenerationneuron-llama-2-13b-f(modelo de bate-papo)
Como alternativa, se você quiser ter mais controle das configurações de implantação, como comprimento do contexto, grau paralelo do tensor e tamanho máximo do lote contínuo, poderá modificá-las por meio de variáveis ambientais, conforme demonstrado nesta seção. O Deep Learning Container (DLC) subjacente da implantação é o Inferência de modelo grande (LMI) NeuronX DLC. As variáveis ambientais são as seguintes:
- OPÇÃO_N_POSIÇÕES – O número máximo de tokens de entrada e saída. Por exemplo, se você compilar o modelo com
OPTION_N_POSITIONScomo 512, então você pode usar um token de entrada de 128 (tamanho do prompt de entrada) com um token de saída máximo de 384 (o total dos tokens de entrada e saída deve ser 512). Para o token de saída máximo, qualquer valor abaixo de 384 é adequado, mas você não pode ir além dele (por exemplo, entrada 256 e saída 512). - OPTION_TENSOR_PARALLEL_DEGREE – O número de NeuronCores para carregar o modelo nas instâncias do AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – O tamanho máximo do lote para solicitações simultâneas.
- OPTION_DTYPE – O tipo de data para carregar o modelo.
A compilação do gráfico Neuron depende do comprimento do contexto (OPTION_N_POSITIONS), grau paralelo do tensor (OPTION_TENSOR_PARALLEL_DEGREE), tamanho máximo do lote (OPTION_MAX_ROLLING_BATCH_SIZE) e tipo de dados (OPTION_DTYPE) para carregar o modelo. O SageMaker JumpStart possui gráficos Neuron pré-compilados para uma variedade de configurações dos parâmetros anteriores para evitar a compilação em tempo de execução. As configurações dos gráficos pré-compilados estão listadas na tabela a seguir. Contanto que as variáveis ambientais se enquadrem em uma das categorias a seguir, a compilação dos gráficos do Neuron será ignorada.
| Bate-papo LIama-2 7B e LIama-2 7B | ||||
| Tipo de instância | OPÇÃO_N_POSIÇÕES | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xgrande | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xgrande | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xgrande | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xgrande | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 24 | fp16 |
| Bate-papo LIama-2 13B e LIama-2 13B | ||||
| ml.inf2.8xgrande | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xgrande | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xgrande | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xgrande | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xgrande | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xgrande | 4096 | 4 | 24 | fp16 |
A seguir está um exemplo de implantação do Llama 2 13B e definição de todas as configurações disponíveis.
Agora que implantamos o modelo Llama-2-13b, podemos executar inferência com ele invocando o endpoint. O trecho de código a seguir demonstra o uso dos parâmetros de inferência compatíveis para controlar a geração de texto:
- comprimento máximo – O modelo gera texto até que o comprimento de saída (que inclui o comprimento do contexto de entrada) atinja
max_length. Se especificado, deve ser um número inteiro positivo. - max_new_tokens – O modelo gera texto até que o comprimento de saída (excluindo o comprimento do contexto de entrada) atinja
max_new_tokens. Se especificado, deve ser um número inteiro positivo. - num_beams – Indica o número de feixes utilizados na busca gananciosa. Se especificado, deve ser um número inteiro maior ou igual a
num_return_sequences. - no_repeat_ngram_size – O modelo garante que uma sequência de palavras de
no_repeat_ngram_sizenão é repetido na sequência de saída. Se especificado, deve ser um número inteiro positivo maior que 1. - temperatura – Isso controla a aleatoriedade na saída. Uma temperatura mais alta resulta em uma sequência de saída com palavras de baixa probabilidade; uma temperatura mais baixa resulta em uma sequência de saída com palavras de alta probabilidade. Se
temperatureigual a 0, resulta em decodificação gulosa. Se especificado, deve ser um float positivo. - Early_stopping - Se
True, a geração do texto termina quando todas as hipóteses de feixe atingem o final do token da frase. Se especificado, deve ser booleano. - do_sample - Se
True, o modelo amostra a próxima palavra de acordo com a probabilidade. Se especificado, deve ser booleano. - topo_k – Em cada etapa da geração de texto, o modelo faz amostras apenas do
top_kpalavras mais prováveis. Se especificado, deve ser um número inteiro positivo. - topo_p – Em cada etapa da geração de texto, o modelo amostra o menor conjunto possível de palavras com uma probabilidade cumulativa de
top_p. Se especificado, deve ser um float entre 0–1. - Pare – Se especificado, deve ser uma lista de strings. A geração de texto é interrompida se qualquer uma das strings especificadas for gerada.
O código a seguir mostra um exemplo:
saída:
Para obter mais informações sobre os parâmetros na carga útil, consulte Parâmetros detalhados.
Você também pode explorar a implementação dos parâmetros no caderno para adicionar mais informações sobre o link do notebook.
Ajuste modelos Llama 2 em instâncias Trainium usando a UI do SageMaker Studio e o SageMaker Python SDK
Os modelos de base de IA generativa tornaram-se o foco principal em ML e IA; no entanto, a sua ampla generalização pode ser insuficiente em domínios específicos, como cuidados de saúde ou serviços financeiros, onde estão envolvidos conjuntos de dados únicos. Esta limitação destaca a necessidade de ajustar estes modelos generativos de IA com dados específicos de domínio para melhorar o seu desempenho nestas áreas especializadas.
Agora que implantamos a versão pré-treinada do modelo Llama 2, vamos ver como podemos ajustar isso para dados específicos do domínio para aumentar a precisão, melhorar o modelo em termos de conclusões imediatas e adaptar o modelo para seu caso de uso e dados de negócios específicos. Você pode ajustar os modelos usando a UI do SageMaker Studio ou o SageMaker Python SDK. Discutimos ambos os métodos nesta seção.
Ajuste o modelo Llama-2-13b Neuron com SageMaker Studio
No SageMaker Studio, navegue até o modelo Llama-2-13b Neuron. No Implantação guia, você pode apontar para a guia Serviço de armazenamento simples da Amazon (Amazon S3) que contém os conjuntos de dados de treinamento e validação para ajuste fino. Além disso, você pode definir a configuração de implantação, hiperparâmetros e configurações de segurança para ajuste fino. Então escolha Trem para iniciar o trabalho de treinamento em uma instância do SageMaker ML.

Para usar os modelos Llama 2, você precisa aceitar o EULA e o AUP. Ele aparecerá quando você escolher Trem. Escolher Li e aceito o EULA e AUP para iniciar o trabalho de ajuste fino.
Você pode visualizar o status do seu trabalho de treinamento para o modelo ajustado no console do SageMaker escolhendo Trabalhos de treinamento no painel de navegação.
Você pode ajustar seu modelo Llama 2 Neuron usando este exemplo sem código ou fazer o ajuste fino por meio do Python SDK, conforme demonstrado na próxima seção.
Ajuste o modelo Llama-2-13b Neuron por meio do SageMaker Python SDK
Você pode ajustar o conjunto de dados com o formato de adaptação de domínio ou o ajuste fino baseado em instruções formatar. A seguir estão as instruções sobre como os dados de treinamento devem ser formatados antes de serem enviados para ajuste fino:
- Entrada - UMA
traindiretório que contém um arquivo formatado em linhas JSON (.jsonl) ou em texto (.txt).- Para o arquivo de linhas JSON (.jsonl), cada linha é um objeto JSON separado. Cada objeto JSON deve ser estruturado como um par chave-valor, onde a chave deve ser
text, e o valor é o conteúdo de um exemplo de treinamento. - O número de arquivos no diretório train deve ser igual a 1.
- Para o arquivo de linhas JSON (.jsonl), cada linha é um objeto JSON separado. Cada objeto JSON deve ser estruturado como um par chave-valor, onde a chave deve ser
- saída – Um modelo treinado que pode ser implantado para inferência.
Neste exemplo, usamos um subconjunto do Conjunto de dados Dolly em um formato de ajuste de instrução. O conjunto de dados Dolly contém aproximadamente 15,000 registros de seguimento de instruções para várias categorias, como resposta a perguntas, resumo e extração de informações. Está disponível sob a licença Apache 2.0. Nós usamos o information_extraction exemplos para ajuste fino.
- Carregue o conjunto de dados Dolly e divida-o em
train(para ajuste fino) etest(para avaliação):
- Use um modelo de prompt para pré-processar os dados em um formato de instrução para o trabalho de treinamento:
- Examine os hiperparâmetros e substitua-os para seu próprio caso de uso:
- Ajuste o modelo e inicie um trabalho de treinamento do SageMaker. Os scripts de ajuste fino são baseados no neuronx-nemo-megatron repositório, que são versões modificadas dos pacotes nemo e ápice que foram adaptados para uso com instâncias Neuron e EC2 Trn1. O neuronx-nemo-megatron repositório tem paralelismo 3D (dados, tensor e pipeline) para permitir que você ajuste LLMs em escala. As instâncias do Trainium suportadas são ml.trn1.32xlarge e ml.trn1n.32xlarge.
- Por fim, implante o modelo ajustado em um endpoint SageMaker:
Compare as respostas entre os modelos Llama 2 Neuron pré-treinados e ajustados
Agora que implantamos a versão pré-treinada do modelo Llama-2-13b e a ajustamos, podemos ver algumas das comparações de desempenho das conclusões de prompt de ambos os modelos, conforme mostrado na tabela a seguir. Também oferecemos um exemplo para ajustar o Llama 2 em um conjunto de dados de arquivamento da SEC em formato .txt. Para obter detalhes, consulte o Caderno de exemplo do GitHub.
| item | entradas | Verdade fundamental | Resposta do modelo não ajustado | Resposta do modelo ajustado |
| 1 | Abaixo está uma instrução que descreve uma tarefa, combinada com uma entrada que fornece contexto adicional. Escreva uma resposta que complete adequadamente a solicitação.nn### Instrução:nExtraia as universidades em que Moret estudou e seu ano de graduação para cada uma, e coloque-as em uma lista com marcadores.nn### Entrada:nMoret nasceu em 1953 em Vevey, Suíça , e fez graduação na École Polytechnique Fédérale de Lausanne (EPFL), graduando-se em 1975. Fez pós-graduação na Universidade do Tennessee, obtendo o doutorado. em 1980. Ingressou então no corpo docente da Universidade do Novo México, onde permaneceu até 2006, quando se mudou para a EPFL. Ele se aposentou da EPFL em dezembro de 2016.nnEm 1996, Moret fundou o ACM Journal of Experimental Algorithmics e permaneceu como editor-chefe da revista até 2003. Em 2001, Moret fundou o Workshop in Algorithms for Bioinformatics (WABI) e permanece no Comitê Diretor da conferência.nnEm 2018, Moret foi eleito Fellow da Sociedade Internacional de Biologia Computacional, por suas excelentes contribuições nas áreas de biologia computacional e bioinformática.nn### Resposta:n | * École Polytechnique Fédérale de Lausanne (EPFL) (formada em 1975)n* Universidade do Tennessee (formada em 1980) | Moret estudou na École Polytechnique Fédérale de Lausanne (EPFL) e na Universidade do Tennessee, graduando-se em 1975 e 1980, respectivamente.nn### Dica:nn- Use a função `split` para dividir a entrada em uma lista de sentenças.n- Use a função `split` para dividir cada frase em uma lista de palavras.n- Use a função `split` para dividir | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexico- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Abaixo está uma instrução que descreve uma tarefa, emparelhada com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente a solicitação.n |
| 2 | Abaixo está uma instrução que descreve uma tarefa, combinada com uma entrada que fornece contexto adicional. Escreva uma resposta que complete adequadamente a solicitação.nn### Instrução:nNa passagem identifique os atributos de Dionísio. Exiba os resultados em um formato separado por vírgula.nn### Entrada:nDionísio (Διόνυσος, Diónusos)/Baco (Βάκχος, Bákkhos)nnDeus do vinho, da fecundidade, das festas, dos festivais, da loucura, do caos, da embriaguez, da vegetação, do êxtase e do teatro. Ele é o filho duas vezes nascido de Zeus e Semele, pois Zeus o arrebatou do ventre de sua mãe e costurou Dionísio em sua própria coxa e o carregou até que ele estivesse pronto para nascer. Na arte, ele é retratado como um deus barbudo mais velho (particularmente antes de 430 aC) ou como um jovem efeminado e de cabelos compridos (particularmente depois de 430 aC). Seus atributos incluem o tirso, um copo, a videira e uma coroa de hera. Ele está frequentemente na companhia de seus thiasos, um grupo de atendentes que inclui sátiros, mênades e seu antigo tutor Silenus. A consorte de Dionísio era Ariadne. Certa vez, afirmou-se que Dionísio foi uma adição posterior ao panteão grego, mas a descoberta de tabuinhas Linear B confirma seu status como uma divindade desde um período inicial. Baco era outro nome para ele em grego e passou a ser de uso comum entre os romanos. Seus animais sagrados incluem golfinhos, serpentes, tigres e burros.nn### Resposta:n | o tirso, um copo, a videira, uma coroa de hera | Dionísio (Διόνυσος, Diónusos)nnDeus do vinho, da fecundidade, das festas, dos festivais, da loucura, do caos, da embriaguez, da vegetação, do êxtase e do teatro. Ele é o filho duas vezes nascido de Zeus e Semele, pois Zeus o arrebatou do ventre de sua mãe e costurou Dionísio em sua própria coxa. | tirso, um copo, a videira, uma coroa de ivynn Abaixo está uma instrução que descreve uma tarefa, combinada com uma entrada que fornece mais contexto. Escreva uma resposta que complete adequadamente a solicitação.nn### Instrução:nQual é a diferença entre o Império Parta e o Império Arsácida?nn### Entrada:nO Império Parta, também conhecido como Império Arsácida, era um |
| 3 | Abaixo está uma instrução que descreve uma tarefa, combinada com uma entrada que fornece contexto adicional. Escreva uma resposta que complete adequadamente a solicitação.nn### Instrução:nPor que a capital do Uzbequistão contém a maior comunidade grega?nn### Entrada:nOs gregos no Uzbequistão são aproximadamente 9,000. A comunidade é composta por gregos da Rússia que foram deportados à força daquele país para o Uzbequistão na década de 1940, e por refugiados políticos da Grécia. Cerca de 30,000 gregos viviam no país antes da Segunda Guerra Mundial e outros 11,000 chegaram após a Guerra Civil Grega e a derrota do Exército Democrático da Grécia. O seu número diminuiu de um máximo de cerca de 40,000 na década de 1960. A principal razão é a emigração para a Grécia após o fim da Guerra Fria, quando as leis permitiram o regresso de todos os gregos étnicos que tinham sido exilados por razões políticas após a Guerra Civil Grega. A maior comunidade grega do país fica na capital, Tashkent, onde a maioria dos refugiados políticos gregos foram realocados pelas autoridades soviéticas. Nos tempos antigos, o sul do país fazia parte do Reino Helenístico Selêucida, mas as poucas comunidades gregas ali foram assimiladas desde então. A organização mais importante que representa os gregos étnicos é a Associação Cultural Grega de Tashkent. As atividades desta organização incluem o ensino da língua grega (19 turmas com um total de 571 alunos, turmas para adultos) e o ensino de danças e música gregas.nn### Resposta:n | A maioria dos refugiados políticos gregos no Uzbequistão foram transferidos pelas autoridades soviéticas para a capital, Tashkent. | n“`nA capital do Uzbequistão contém a maior comunidade grega porque os gregos no Uzbequistão são aproximadamente 9,000. A comunidade é composta por gregos da Rússia que foram deportados à força daquele país para o Uzbequistão na década de 1940, e por refugiados políticos da Grécia. Cerca de 30,000 mil gregos viviam no país antes da Segunda Guerra Mundial e mais 11,00 mil | A capital do Uzbequistão contém a maior comunidade grega porque é onde a maioria dos refugiados políticos gregos foram realocados pelas autoridades soviéticas após terem sido deportados da Grécia.nn Abaixo está uma instrução que descreve uma tarefa, juntamente com uma entrada que fornece contexto adicional. Escreva uma resposta que complete adequadamente a solicitação.nn### Instrução:nQual é a diferença entre o Império Parta e o Império Arsácida?nn### Entrada:n |
Podemos ver que as respostas do modelo ajustado demonstram uma melhoria significativa na precisão, relevância e clareza em comparação com as do modelo pré-treinado. Em alguns casos, usar o modelo pré-treinado para o seu caso de uso pode não ser suficiente, portanto, ajustá-lo usando esta técnica tornará a solução mais personalizada para o seu conjunto de dados.
limpar
Depois de concluir seu trabalho de treinamento e não desejar mais usar os recursos existentes, exclua os recursos usando o seguinte código:
Conclusão
A implantação e o ajuste fino dos modelos Llama 2 Neuron no SageMaker demonstram um avanço significativo no gerenciamento e otimização de modelos de IA generativos em grande escala. Esses modelos, incluindo variantes como Llama-2-7b e Llama-2-13b, usam o Neuron para treinamento e inferência eficientes em instâncias baseadas em AWS Inferentia e Trainium, melhorando seu desempenho e escalabilidade.
A capacidade de implantar esses modelos por meio da UI do SageMaker JumpStart e do Python SDK oferece flexibilidade e facilidade de uso. O Neuron SDK, com suporte para estruturas de ML populares e recursos de alto desempenho, permite o manuseio eficiente desses grandes modelos.
O ajuste fino destes modelos em dados específicos de domínio é crucial para aumentar a sua relevância e precisão em campos especializados. O processo, que você pode conduzir por meio da UI do SageMaker Studio ou do Python SDK, permite a personalização de acordo com necessidades específicas, levando a um melhor desempenho do modelo em termos de conclusões imediatas e qualidade de resposta.
Comparativamente, as versões pré-treinadas destes modelos, embora poderosas, podem fornecer respostas mais genéricas ou repetitivas. O ajuste fino adapta o modelo a contextos específicos, resultando em respostas mais precisas, relevantes e diversas. Esta personalização é particularmente evidente quando se comparam respostas de modelos pré-treinados e ajustados, onde este último demonstra uma melhoria notável na qualidade e especificidade do resultado. Concluindo, a implantação e o ajuste fino dos modelos Neuron Llama 2 no SageMaker representam uma estrutura robusta para gerenciar modelos avançados de IA, oferecendo melhorias significativas no desempenho e na aplicabilidade, especialmente quando adaptados a domínios ou tarefas específicas.
Comece hoje mesmo referenciando o exemplo do SageMaker caderno.
Para obter mais informações sobre a implantação e o ajuste fino de modelos Llama 2 pré-treinados em instâncias baseadas em GPU, consulte Ajuste o Llama 2 para geração de texto no Amazon SageMaker JumpStart e Os modelos de base Llama 2 da Meta já estão disponíveis no Amazon SageMaker JumpStart.
Os autores gostariam de agradecer as contribuições técnicas de Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne e Mike James.
Sobre os autores
 Xin Huang é um cientista aplicado sênior para Amazon SageMaker JumpStart e algoritmos integrados do Amazon SageMaker. Ele se concentra no desenvolvimento de algoritmos de aprendizado de máquina escalonáveis. Seus interesses de pesquisa estão na área de processamento de linguagem natural, aprendizado profundo explicável em dados tabulares e análise robusta de agrupamento de espaço-tempo não paramétrico. Ele publicou muitos artigos nas conferências ACL, ICDM, KDD e Royal Statistical Society: Series A.
Xin Huang é um cientista aplicado sênior para Amazon SageMaker JumpStart e algoritmos integrados do Amazon SageMaker. Ele se concentra no desenvolvimento de algoritmos de aprendizado de máquina escalonáveis. Seus interesses de pesquisa estão na área de processamento de linguagem natural, aprendizado profundo explicável em dados tabulares e análise robusta de agrupamento de espaço-tempo não paramétrico. Ele publicou muitos artigos nas conferências ACL, ICDM, KDD e Royal Statistical Society: Series A.
 Nitin Eusébio See More é arquiteto sênior de soluções empresariais na AWS, com experiência em engenharia de software, arquitetura empresarial e IA/ML. Ele é profundamente apaixonado por explorar as possibilidades da IA generativa. Ele colabora com os clientes para ajudá-los a criar aplicativos bem arquitetados na plataforma AWS e se dedica a solucionar desafios tecnológicos e auxiliá-los em sua jornada para a nuvem.
Nitin Eusébio See More é arquiteto sênior de soluções empresariais na AWS, com experiência em engenharia de software, arquitetura empresarial e IA/ML. Ele é profundamente apaixonado por explorar as possibilidades da IA generativa. Ele colabora com os clientes para ajudá-los a criar aplicativos bem arquitetados na plataforma AWS e se dedica a solucionar desafios tecnológicos e auxiliá-los em sua jornada para a nuvem.
 Madhur Prashant trabalha no espaço generativo de IA na AWS. Ele é apaixonado pela interseção do pensamento humano e da IA generativa. Seus interesses estão na IA generativa, especificamente na construção de soluções que sejam úteis e inofensivas e, acima de tudo, ideais para os clientes. Fora do trabalho, ele adora fazer ioga, fazer caminhadas, ficar com seu irmão gêmeo e tocar violão.
Madhur Prashant trabalha no espaço generativo de IA na AWS. Ele é apaixonado pela interseção do pensamento humano e da IA generativa. Seus interesses estão na IA generativa, especificamente na construção de soluções que sejam úteis e inofensivas e, acima de tudo, ideais para os clientes. Fora do trabalho, ele adora fazer ioga, fazer caminhadas, ficar com seu irmão gêmeo e tocar violão.
 Dewan Choudhury é um engenheiro de desenvolvimento de software da Amazon Web Services. Ele trabalha nos algoritmos do Amazon SageMaker e nas ofertas do JumpStart. Além de construir infraestruturas AI/ML, ele também é apaixonado por construir sistemas distribuídos escaláveis.
Dewan Choudhury é um engenheiro de desenvolvimento de software da Amazon Web Services. Ele trabalha nos algoritmos do Amazon SageMaker e nas ofertas do JumpStart. Além de construir infraestruturas AI/ML, ele também é apaixonado por construir sistemas distribuídos escaláveis.
 Hao Zhou é cientista pesquisador do Amazon SageMaker. Antes disso, ele trabalhou no desenvolvimento de métodos de aprendizado de máquina para detecção de fraudes no Amazon Fraud Detector. Ele é apaixonado por aplicar técnicas de aprendizado de máquina, otimização e IA generativa a vários problemas do mundo real. Ele possui doutorado em Engenharia Elétrica pela Northwestern University.
Hao Zhou é cientista pesquisador do Amazon SageMaker. Antes disso, ele trabalhou no desenvolvimento de métodos de aprendizado de máquina para detecção de fraudes no Amazon Fraud Detector. Ele é apaixonado por aplicar técnicas de aprendizado de máquina, otimização e IA generativa a vários problemas do mundo real. Ele possui doutorado em Engenharia Elétrica pela Northwestern University.
 Qinglan é engenheiro de desenvolvimento de software na AWS. Ele vem trabalhando em vários produtos desafiadores na Amazon, incluindo soluções de inferência de ML de alto desempenho e sistema de registro de alto desempenho. A equipe de Qing lançou com sucesso o primeiro modelo Billion-parameter no Amazon Advertising com latência muito baixa necessária. Qing possui profundo conhecimento sobre otimização de infraestrutura e aceleração de Deep Learning.
Qinglan é engenheiro de desenvolvimento de software na AWS. Ele vem trabalhando em vários produtos desafiadores na Amazon, incluindo soluções de inferência de ML de alto desempenho e sistema de registro de alto desempenho. A equipe de Qing lançou com sucesso o primeiro modelo Billion-parameter no Amazon Advertising com latência muito baixa necessária. Qing possui profundo conhecimento sobre otimização de infraestrutura e aceleração de Deep Learning.
 Dr. é um cientista aplicado sênior com algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela University of Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dr. é um cientista aplicado sênior com algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela University of Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
 Dr. é gerente técnico de produto principal do Amazon SageMaker JumpStart e algoritmos integrados do Amazon SageMaker, um serviço que ajuda cientistas de dados e profissionais de aprendizado de máquina a começar a treinar e implantar seus modelos e usa aprendizado de reforço com o Amazon SageMaker. Seu trabalho anterior como principal membro da equipe de pesquisa e mestre inventor na IBM Research ganhou o prêmio Test of Time Paper no IEEE INFOCOM.
Dr. é gerente técnico de produto principal do Amazon SageMaker JumpStart e algoritmos integrados do Amazon SageMaker, um serviço que ajuda cientistas de dados e profissionais de aprendizado de máquina a começar a treinar e implantar seus modelos e usa aprendizado de reforço com o Amazon SageMaker. Seu trabalho anterior como principal membro da equipe de pesquisa e mestre inventor na IBM Research ganhou o prêmio Test of Time Paper no IEEE INFOCOM.
 Kamran Khan, Gerente Sênior de Desenvolvimento Técnico de Negócios para AWS Inferentina/Trianium na AWS. Ele tem mais de uma década de experiência ajudando clientes a implantar e otimizar treinamentos de aprendizagem profunda e cargas de trabalho de inferência usando AWS Inferentia e AWS Trainium.
Kamran Khan, Gerente Sênior de Desenvolvimento Técnico de Negócios para AWS Inferentina/Trianium na AWS. Ele tem mais de uma década de experiência ajudando clientes a implantar e otimizar treinamentos de aprendizagem profunda e cargas de trabalho de inferência usando AWS Inferentia e AWS Trainium.
 Joe Senerchia é gerente de produto sênior na AWS. Ele define e cria instâncias do Amazon EC2 para aprendizado profundo, inteligência artificial e cargas de trabalho de computação de alto desempenho.
Joe Senerchia é gerente de produto sênior na AWS. Ele define e cria instâncias do Amazon EC2 para aprendizado profundo, inteligência artificial e cargas de trabalho de computação de alto desempenho.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- habilidade
- Capaz
- Sobre
- aceleração
- ACEITAR
- aceitável
- aceito
- Acesso
- precisão
- preciso
- reconhecer
- ACM
- ativo
- atividades
- Adam
- adaptar
- adaptação
- adaptado
- adicionar
- Adição
- adultos
- avançado
- avanço
- Publicidade
- Depois de
- Acordo
- AI
- Modelos de IA
- AI / ML
- algoritmos
- Todos os Produtos
- permitir
- permitidas
- permite
- tb
- Amazon
- Amazon EC2
- Detector de fraude da Amazon
- Amazon Sage Maker
- JumpStart do Amazon SageMaker
- Amazon Web Services
- entre
- an
- análise
- Antigo
- e
- animais
- Anunciar
- Outro
- qualquer
- mais
- apache
- à parte
- relevante
- Aplicação
- aplicações
- aplicado
- Aplicando
- adequadamente
- aproximadamente
- arquitetura
- SOMOS
- ÁREA
- áreas
- argumento
- Exército
- chegou
- Arte
- artificial
- inteligência artificial
- AS
- ajudando
- Associação
- At
- Atendentes
- atributos
- Autoridades
- autores
- Automatizado
- disponibilidade
- disponível
- evitar
- AWS
- Inferência da AWS
- b
- baseado
- BE
- viga
- Porque
- tornam-se
- sido
- antes
- ser
- Acreditar
- abaixo
- entre
- Pós
- O maior
- biologia
- Blog
- nascido
- ambos
- Caixa
- amplo
- construir
- Prédio
- Constrói
- construídas em
- negócio
- desenvolvimento de negócios
- mas a
- botão
- botões
- by
- chamada
- veio
- CAN
- capacidades
- capital
- cartão
- transportado
- casas
- casos
- Categorias
- Categoria
- desafios
- desafiante
- alterar
- Chaos
- bate-papo
- chefe
- escolha
- Escolha
- escolha
- Christopher
- Cidades
- civil
- clareza
- aulas
- clássico
- classificação
- limpar
- Na nuvem
- agrupamento
- código
- frio
- comitê
- comum
- Comunidades
- comunidade
- Empresa
- comparado
- comparando
- comparações
- Efetuado
- Completa
- computacional
- computação
- conclusão
- concorrente
- Conduzir
- Conferência
- conferências
- Configuração
- Confirmar
- cônsul
- não contenho
- Recipiente
- contém
- conteúdo
- contexto
- Contextos
- contribuições
- ao controle
- controles
- Custo
- dispendioso
- custos
- país
- criado
- Coroa
- crucial
- cultural
- copo
- cliente
- experiência do cliente
- Clientes
- personalização
- dados,
- conjuntos de dados
- Data
- de
- década
- Dezembro
- decodificação
- dedicado
- profundo
- deep learning
- profundamente
- Padrão
- Define
- Grau
- entregar
- democrático
- demonstrar
- demonstraram
- demonstra
- Dependendo
- depende
- implantar
- implantado
- Implantação
- desenvolvimento
- descreve
- descrição
- designado
- projetado
- detalhado
- detalhes
- Detecção
- desenvolver
- em desenvolvimento
- Desenvolvimento
- Diálogo
- DID
- diferença
- diferente
- descobrir
- descoberta
- discutir
- Ecrã
- distribuído
- Sistemas distribuídos
- diferente
- parece
- fazer
- Boneca
- domínio
- domínios
- não
- down
- cada
- Cedo
- Ganhando
- facilidade
- facilidade de utilização
- editor
- Eficaz
- eficácia
- eficiente
- ou
- eleito
- Engenharia elétrica
- império
- habilitado
- permite
- permitindo
- final
- end-to-end
- Ponto final
- engenheiro
- Engenharia
- aumentar
- aprimorando
- suficiente
- garante
- Empreendimento
- Soluções Empresariais
- Meio Ambiente
- ambiental
- igual
- É igual a
- especialmente
- Éter (ETH)
- avaliar
- avaliação
- evidente
- exemplo
- exemplos
- animado
- excluindo
- existente
- vasta experiência
- experiente
- experimental
- explorar
- Explorando
- Extração
- Cair
- falso
- mais rápido
- companheiro
- festivais
- poucos
- Campos
- Envie o
- Arquivos
- Arquivamento
- financeiro
- serviços financeiros
- Encontre
- final
- Primeiro nome
- Flexibilidade
- Flutuador
- Foco
- concentra-se
- seguinte
- segue
- Escolha
- força
- formato
- encontrado
- Foundation
- Fundado
- Quadro
- enquadramentos
- fraude
- detecção de fraude
- da
- função
- mais distante
- gerado
- gera
- geração
- generativo
- IA generativa
- ter
- Go
- Deus
- Bom estado, com sinais de uso
- tem
- pós-graduação
- gráfico
- gráficos
- maior
- Grécia
- Ganancioso
- grego
- Grupo
- orientações
- guitarra
- tinha
- Manipulação
- mãos
- feliz
- Ter
- he
- saúde
- Herói
- ajudar
- útil
- ajuda
- ajuda
- Alta
- alta performance
- superior
- mais
- destaques
- caminhadas
- ele
- sua
- detém
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- humano
- i
- IBM
- ICLR
- identificar
- ids
- IEEE
- if
- ii
- Illinois
- implementação
- importar
- importante
- melhorar
- melhorado
- melhoria
- melhorias
- in
- em profundidade
- incluir
- inclui
- Incluindo
- Crescimento
- indicam
- INFORMAÇÕES
- extração de informação
- Infraestrutura
- infra-estrutura
- entrada
- inputs
- instância
- instâncias
- instruções
- integrado
- Inteligência
- interesses
- Interface
- Internacionais
- interseção
- para dentro
- envolvido
- IT
- ESTÁ
- james
- Trabalho
- Empregos
- ingressou
- jonathan
- revista
- viagem
- jpg
- json
- apenas por
- Chave
- Reino
- de emergência
- Conjunto (SDK)
- Conhecimento
- conhecido
- aterrissagem
- página de destino
- língua
- grande
- em grande escala
- Latência
- mais tarde
- lançado
- Leis
- principal
- aprendizagem
- Comprimento
- li
- Licença
- licenças
- mentira
- vida
- como
- probabilidade
- Provável
- limitação
- Line
- linhas
- LINK
- Lista
- Listado
- lhama
- carregar
- local
- logging
- longo
- olhar
- ama
- Baixo
- diminuir
- baixa
- menor
- máquina
- aprendizado de máquina
- moldadas
- a Principal
- fazer
- Fazendo
- Gerente
- gestão
- Manan Xá
- muitos
- dominar
- máximo
- Posso..
- significado
- Conheça
- membro
- Meta
- método
- métodos
- México
- poder
- Mike
- mente
- ML
- modelo
- modelagem
- modelos
- modificada
- modificar
- mais
- a maioria
- movido
- Música
- devo
- nome
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Navegar
- Navegação
- você merece...
- Cria
- NeuroIPS
- Novo
- Próximo
- PNL
- Northwestern University
- caderno
- laptops
- agora
- número
- números
- objeto
- objetivos
- of
- oferecer
- oferecendo treinamento para distância
- Ofertas
- Oferece
- frequentemente
- Velho
- mais velho
- on
- uma vez
- ONE
- só
- ideal
- otimização
- Otimize
- otimizado
- otimizando
- Opção
- or
- organização
- Outros
- saída
- lado de fora
- marcante
- Acima de
- próprio
- pacotes
- página
- par
- emparelhado
- pão
- Papel
- papéis
- Paralelo
- parâmetros
- parte
- particularmente
- partes
- passagem
- apaixonado
- passado
- para
- realizar
- atuação
- significativo
- Personalizado
- phd
- oleoduto
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- por favor
- ponto
- políticas
- Privacidade
- político
- pop-up
- Popular
- positivo
- possibilidades
- possível
- Publique
- poderoso
- precedente
- Precisão
- preparação
- primário
- Diretor
- probabilidade
- problemas
- processo
- em processamento
- Produto
- gerente de produto
- Produtos
- proprietário
- fornecer
- fornecedores
- fornece
- publicamente
- publicado
- colocar
- Python
- pytorch
- qualidade
- questão
- aleatoriedade
- alcançar
- Chega
- Leia
- pronto
- reais
- mundo real
- em tempo real
- razão
- razões
- registros
- referir
- referência
- refugiados
- liberado
- relevância
- relevante
- Realocados
- permaneceu
- permanece
- repetido
- repetitivo
- substituir
- repositório
- representar
- representando
- solicitar
- pedidos
- requeridos
- pesquisa
- investigador
- Recursos
- respectivamente
- resposta
- respostas
- responsável
- resultando
- Resultados
- retorno
- rever
- revendo
- uma conta de despesas robusta
- rolando
- real
- Execute
- Rússia
- sábio
- AMPLIAR
- escalável
- Escala
- cenários
- Cientista
- cientistas
- Scripts
- Sdk
- Pesquisar
- pesquisar
- SEC
- Arquivo SEC
- Segundo
- Seção
- segurança
- Vejo
- senior
- enviei
- sentença
- sentimento
- separado
- Seqüência
- Série
- Série A
- serviço
- Serviços
- conjunto
- contexto
- Configurações
- vários
- Baixo
- rede de apoio social
- mostrar
- mostrando
- Shows
- periodo
- simples
- desde
- solteiro
- Tamanho
- fragmento
- So
- Sociedade
- Software
- desenvolvimento de software
- kit de desenvolvimento de software
- Engenharia de software
- solução
- Soluções
- Resolvendo
- alguns
- eles são
- fonte
- Sul
- soviético
- Espaço
- especializado
- específico
- especificamente
- especificidade
- especificada
- Passar
- divisão
- Staff
- começo
- começado
- Estado
- estatístico
- Status
- direcção
- Passo
- Passos
- Pára
- armazenamento
- estruturada
- Estudantes
- estudado
- caso
- estudo
- entraram com sucesso
- tal
- ajuda
- Suportado
- certo
- Suíça
- .
- sistemas
- mesa
- adaptados
- Tarefa
- tarefas
- Ensino
- Profissionais
- Dados Técnicos:
- técnica
- técnicas
- Tecnologia
- modelo
- tennessee
- condições
- teste
- texto
- Classificação de Texto
- geração de texto
- do que
- que
- A
- A área
- O capital
- Teatro
- deles
- Eles
- então
- Lá.
- Este
- deles
- Pensando
- De terceiros
- isto
- aqueles
- Através da
- Taxa de transferência
- tigres
- tempo
- vezes
- para
- hoje
- token
- Tokens
- ferramentas
- Total
- Trem
- treinado
- Training
- transformador
- Tradução
- verdadeiro
- tentar
- gêmeo
- dois
- tipo
- ui
- para
- subjacente
- único
- Universidades
- universidade
- até
- Atualizar
- Atualizações
- Uso
- usar
- caso de uso
- usava
- Utilizador
- usuários
- usos
- utilização
- utiliza
- uzbeque
- validação
- valor
- variedade
- vário
- versão
- muito
- via
- Ver
- videira
- visual
- andar
- queremos
- guerra
- foi
- maneiras
- we
- web
- serviços web
- Web-Based
- fui
- foram
- quando
- qual
- enquanto
- QUEM
- precisarão
- VINHO
- de
- Ganhou
- Word
- palavras
- Atividades:
- trabalhou
- trabalhar
- trabalho
- oficina
- mundo
- seria
- escrever
- ano
- Ioga
- Você
- investimentos
- juventude
- zefirnet
- Zeus