No mundo de hoje, os clientes gerenciam grandes quantidades de dados em seus Serviço de armazenamento simples da Amazon (Amazon S3) data lakes, que exigem pipelines de dados complicados para entender continuamente as alterações no layout de dados e disponibilizá-los aos sistemas de consumo. Cola AWS os crawlers fornecem uma maneira direta de catalogar dados no Catálogo de dados do AWS Glue, que remove o trabalho pesado quando se trata de gerenciamento de esquema e classificação de dados. Os rastreadores do AWS Glue extraem o esquema de dados e as partições do Amazon S3 para preencher automaticamente o Catálogo de dados, mantendo os metadados atualizados.
Mas com os dados crescendo exponencialmente ao longo do tempo, o número de partições em uma determinada tabela pode crescer significativamente. Porque serviços analíticos como Amazona atena consultar uma tabela contendo milhões de partições, o tempo necessário para recuperar a partição aumenta e pode aumentar o tempo de execução da consulta.
Hoje, o suporte ao crawler do AWS Glue foi expandido para adicionar automaticamente índices de partição para tabelas recém-descobertas para otimizar o processamento de consultas no conjunto de dados particionado. Agora, quando o crawler cria uma nova tabela do Catálogo de Dados durante a execução do crawler, ele também cria um índice de partição por padrão, com a maior permutação de todas as colunas de partição de tipo numérico e string como chaves. O Catálogo de Dados cria um índice pesquisável com base nessas chaves, reduzindo o tempo necessário para recuperar e filtrar metadados de partição em tabelas com milhões de partições. A criação de índices de partição beneficia as cargas de trabalho analíticas em execução no Athena, Amazon EMR, Espectro Amazon Redshifte AWS Glue.
Nesta postagem, descrevemos como criar índices de partição com um rastreador do AWS Glue e comparamos a melhoria do desempenho da consulta ao acessar os dados rastreados com e sem um índice de partição do Athena.
Visão geral da solução
Nós usamos um Formação da Nuvem AWS modelo para criar nossos recursos de solução. Nas etapas a seguir, demonstramos como configurar o crawler do AWS Glue para criar um índice de partição usando o console do AWS Glue ou o Interface de linha de comando da AWS (AWS CLI). Em seguida, comparamos as melhorias de desempenho da consulta usando o Athena.
Pré-requisitos
Para acompanhar este post, você deve ter acesso a um Gerenciamento de acesso e identidade da AWS Função de administrador (IAM) para criar recursos usando o AWS CloudFormation.
Configure seus recursos de solução
O modelo CloudFormation gera os seguintes recursos:
- Funções e políticas do IAM
- Um banco de dados do AWS Glue para manter o esquema
- Um rastreador do AWS Glue apontando para um conjunto de dados altamente particionado
- Um grupo de trabalho e bucket do Athena para armazenar os resultados da consulta
Conclua as etapas a seguir para configurar os recursos da solução:
- Faça o login no Console de gerenciamento da AWS como administrador do IAM.
- Escolha Pilha de Lançamento para implantar o modelo CloudFormation:

- Escolha Nome do banco de dados, mantenha o padrão
blog_partition_index_crawlerdb.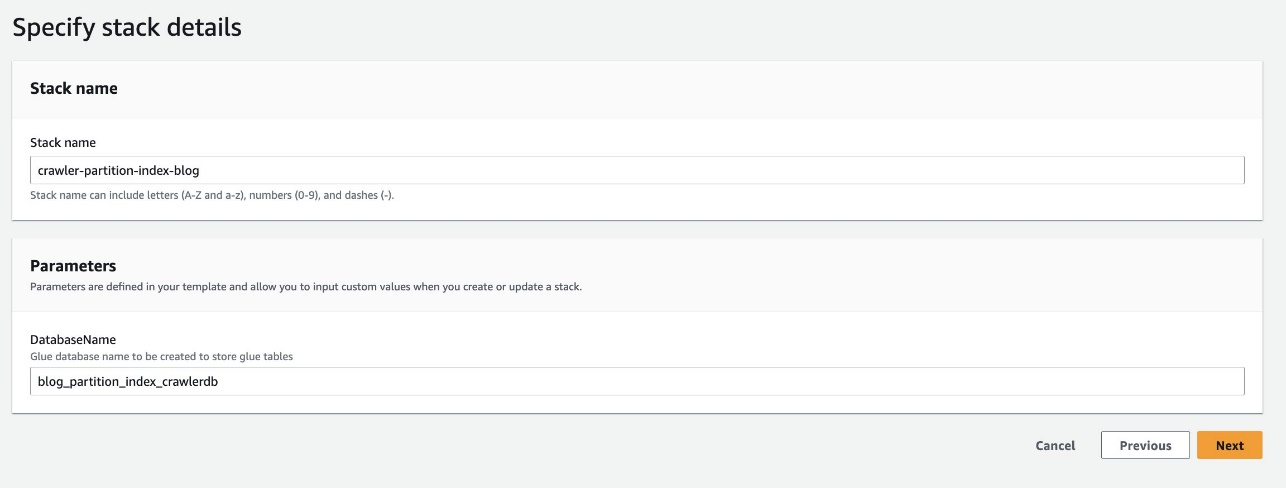
- Escolha Próximo.
- Revise os detalhes na página final e selecione Reconheço que o AWS CloudFormation pode criar recursos do IAM.
- Escolha Criar pilha.
- Quando a pilha estiver concluída, no console do AWS CloudFormation, navegue até o Saídas guia da pilha.
- Anote os valores de
DatabaseNameeGlueCrawlerName.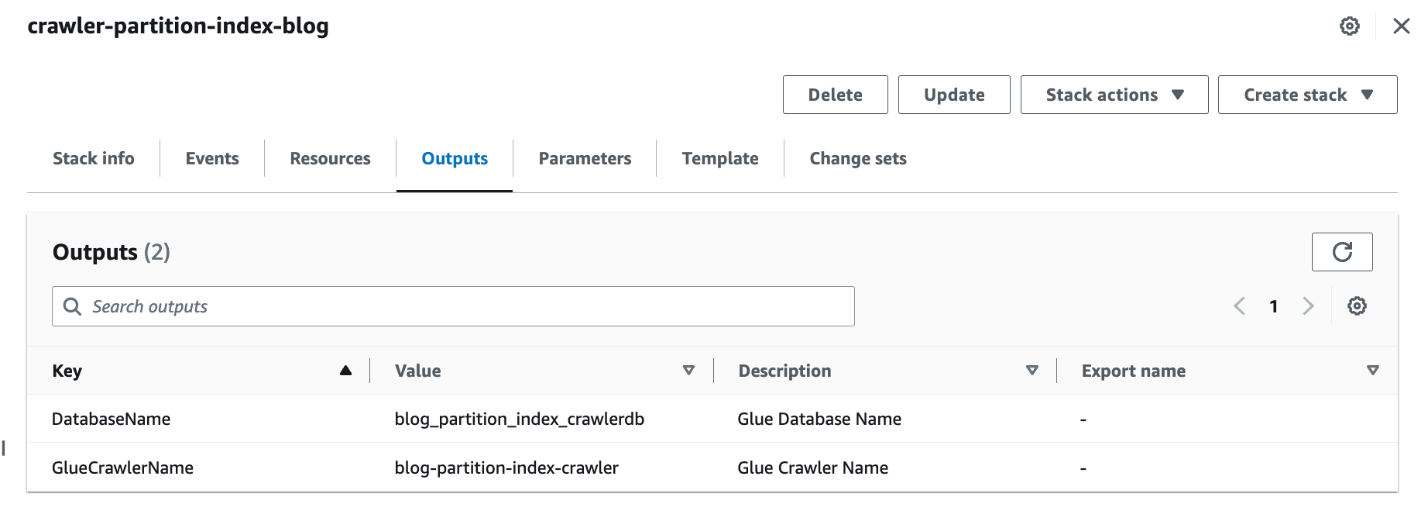
Alguns dos recursos que esta pilha implementa incorrem em custos quando em uso.
Edite e execute o crawler do AWS Glue
Para configurar e executar o crawler do AWS Glue, conclua as seguintes etapas:
- No console AWS Glue, escolha Rastreadores no painel de navegação.
- Localize o
crawler blog-partition-index-crawlere escolha Editar.
- No Definir saída e agendamento seção, sob opções avançadas, selecione Crie índices de partição automaticamente.
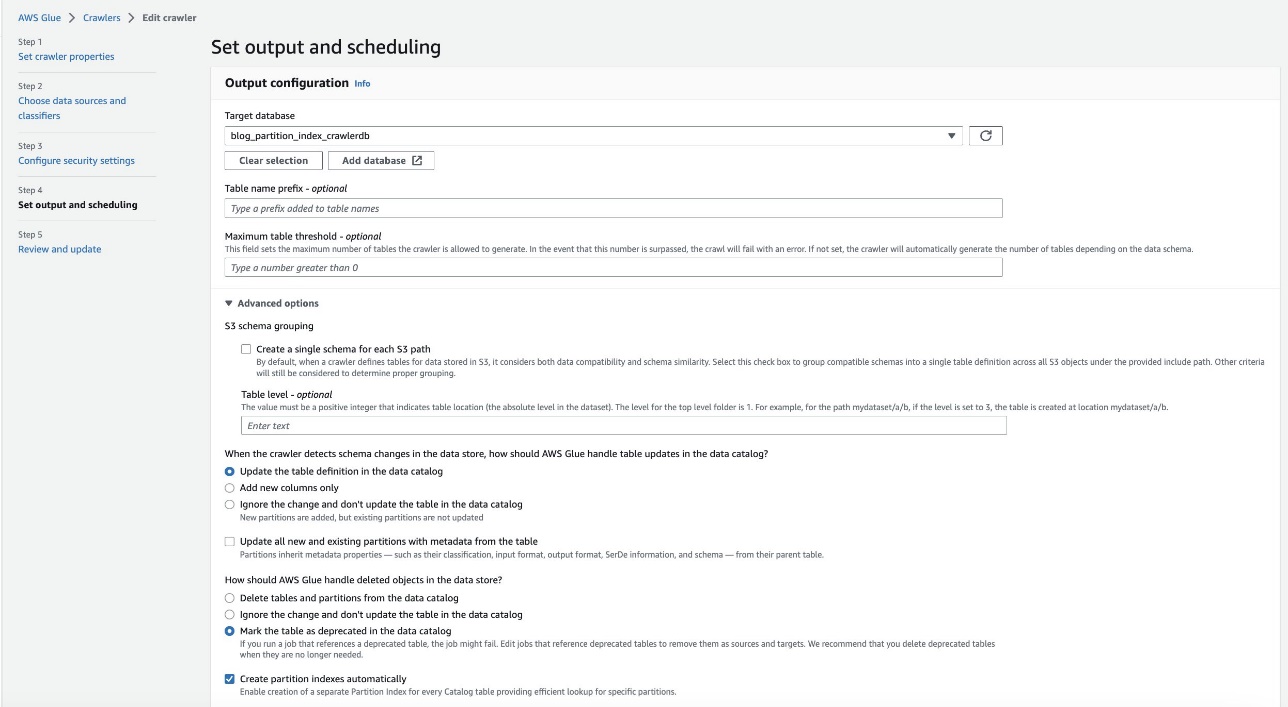
- Revise e atualize as configurações do rastreador.
Como alternativa, você pode configurar seu rastreador usando a AWS CLI (forneça sua função e região do IAM):
- Agora execute o rastreador e verifique se a execução do rastreador foi concluída.
Este é um conjunto de dados altamente particionado e levará aproximadamente 90 minutos para ser concluído.
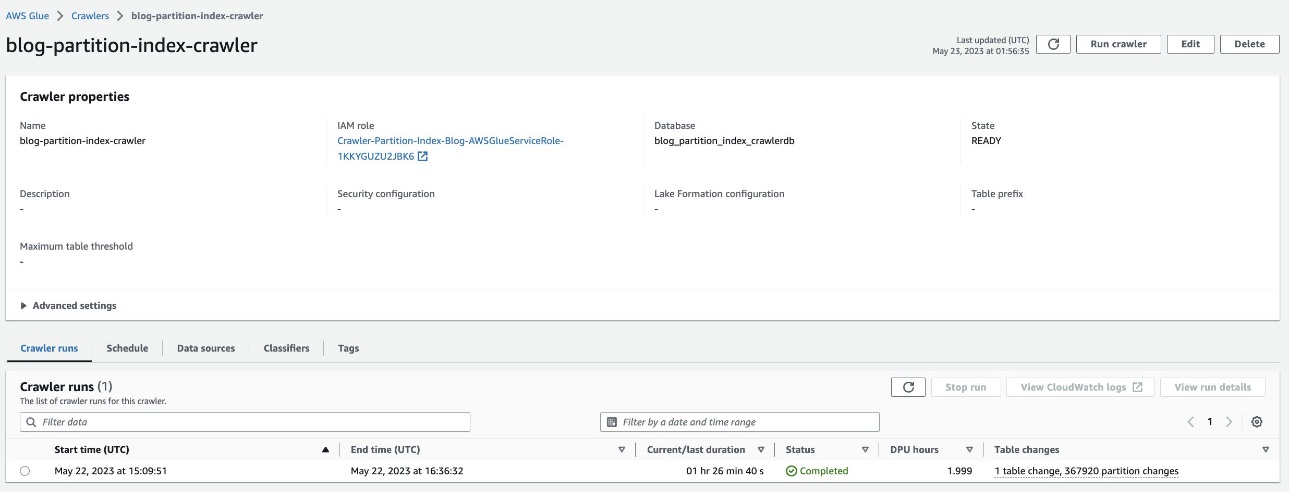
Verifique a tabela particionada
No banco de dados do AWS Glue blog_partition_index_crawlerdb, verifique se a tabela highly_partitioned_table é criado.
Por padrão, o rastreador determina um índice com base na maior permutação de colunas de partição de tipos de coluna válidos na mesma ordem das colunas de partição, que são numéricas ou de string. Para a tabela criada pelo rastreador (highly_partitioned_table), temos colunas de partição year (fragmento), month (fragmento), day (corda) e hour (corda).
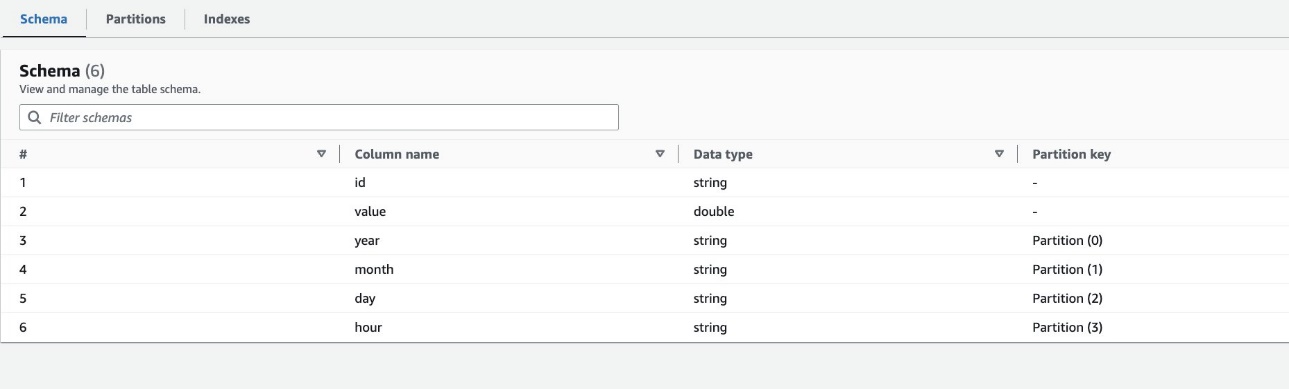
Com base nessa definição, o rastreador criou um índice na permutação de ano, mês, dia e hora. O rastreador criou os índices prefixados com crawler_ em qualquer índice de partição criado por padrão.
Verifique o mesmo navegando até a tabela highly_partitioned_table no console do AWS Glue e escolhendo o Índices aba.
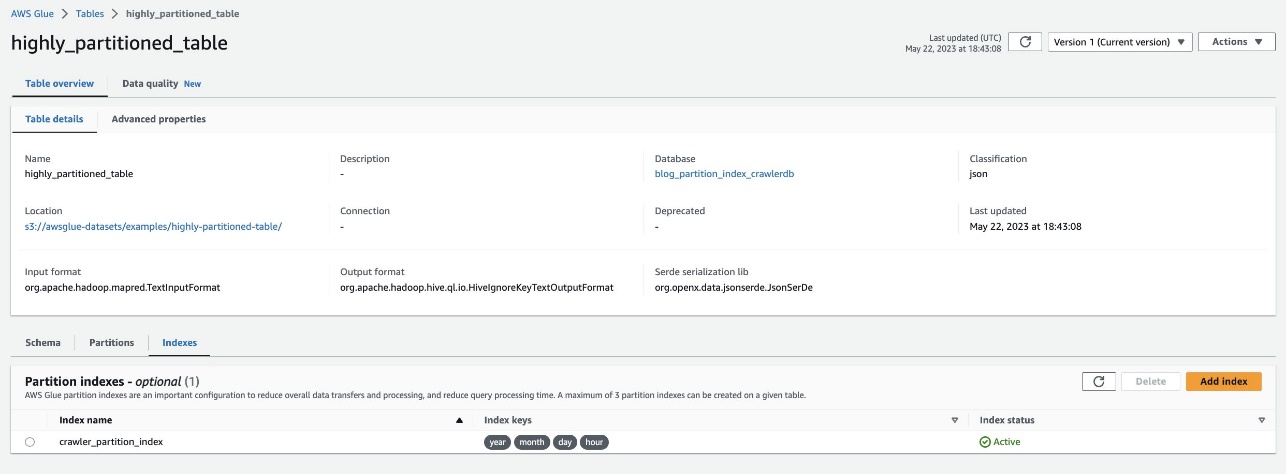
O rastreador conseguiu rastrear a fonte de dados S3 e preencher com êxito os índices de partição da tabela.
Compare as melhorias de desempenho de consulta usando o Athena
Primeiro, consultamos a tabela no Athena sem usar o índice de partição. Para verificar as tabelas usando o Athena, conclua as seguintes etapas:
- No console Athena, escolha
crawler-primary-workgroupcomo o grupo de trabalho Athena e escolha Reconhecer.
- Execute a seguinte consulta:
A captura de tela a seguir mostra que a consulta levou aproximadamente 32 segundos sem a filtragem habilitada usando o índice de partição.
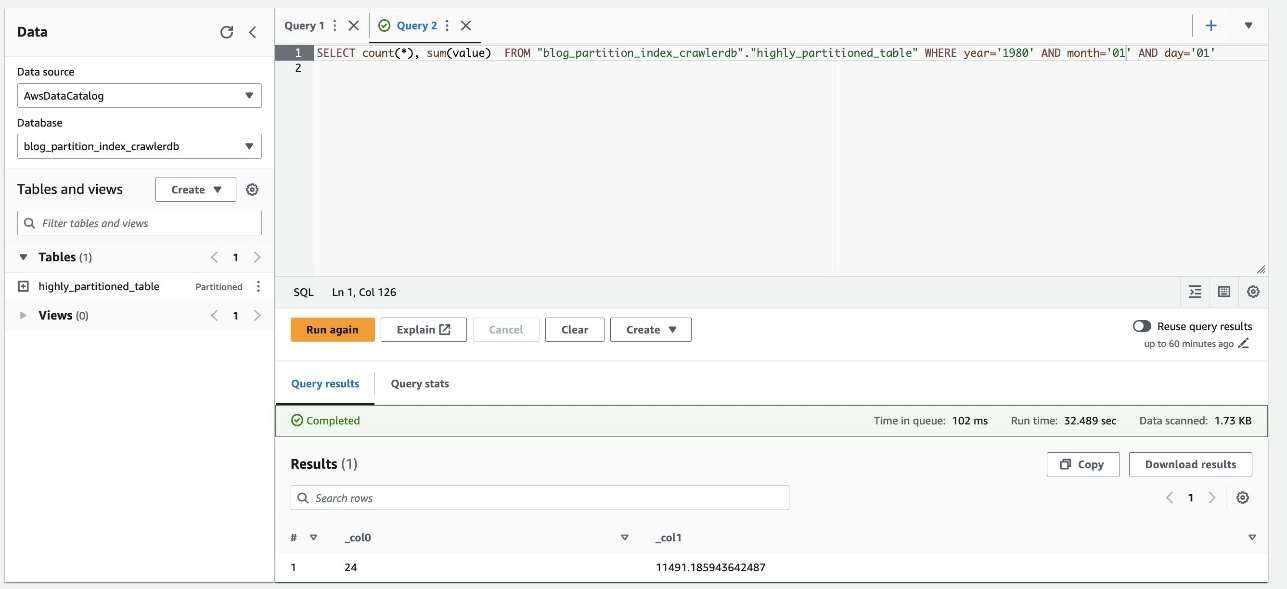
- Agora habilitamos o índice de partição na consulta do Athena:
- Execute a seguinte consulta novamente e observe o tempo de execução:
A captura de tela a seguir mostra que a consulta levou apenas 700 milissegundos, o que é muito mais rápido com a filtragem habilitada usando o índice de partição.
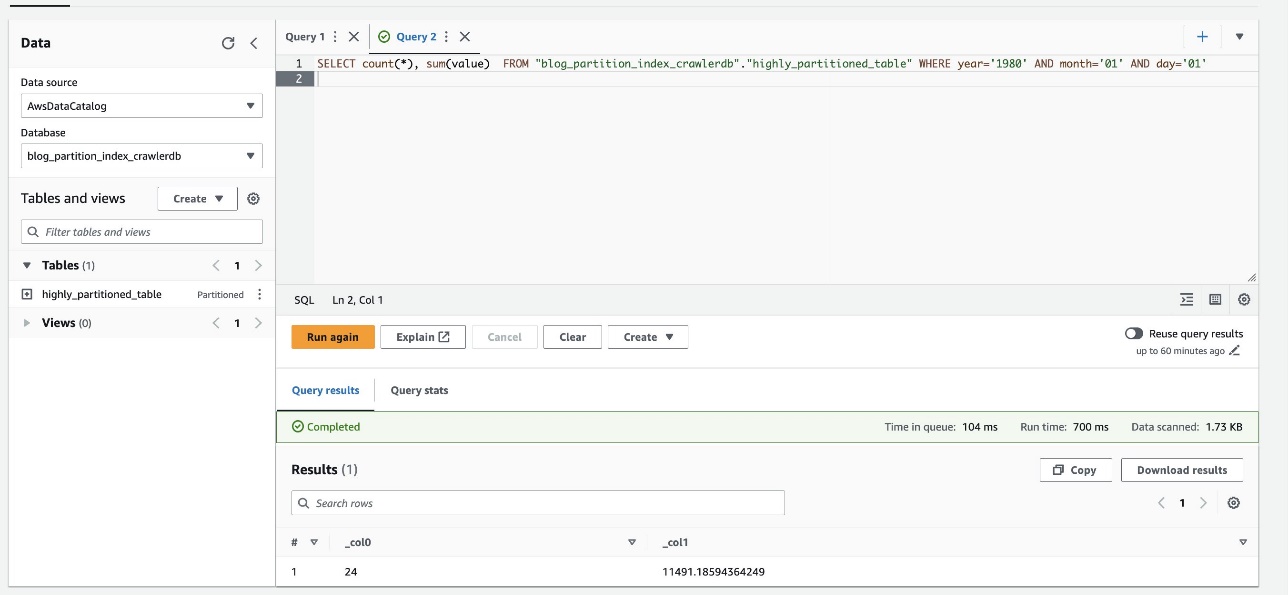
limpar
Para evitar cobranças indesejadas em sua conta da AWS, você pode excluir os recursos da AWS:
- Entre no console do CloudFormation como administrador do IAM usado para criar a pilha do CloudFormation.
- Exclua a pilha do CloudFormation que você criou.
Conclusão
Neste post, explicamos como configurar um crawler da AWS para criar índices de partição e comparamos o desempenho da consulta ao acessar os dados com os índices do Athena.
Se nenhum índice de partição estiver presente na tabela, o AWS Glue carrega todas as partições da tabela e, em seguida, filtra as partições carregadas, o que resulta em recuperação ineficiente de metadados. Serviços analíticos como Redshift Spectrum, Amazon EMR e AWS Glue ETL Spark DataFrames agora podem utilizar índices para buscar partições, resultando em um desempenho de consulta significativo.
Para obter mais informações sobre índices de partição e desempenho de consulta em vários mecanismos analíticos, consulte Melhore o desempenho de consulta do Amazon Athena usando índices de partição do AWS Glue Data Catalog e Melhore o desempenho da consulta usando índices de partição AWS Glue.
Agradecimentos especiais a todos que contribuíram para o lançamento deste recurso de rastreador: Yuhang Chen, Kyle Duong e Mita Gavade.
Sobre os autores
 Srividya Parthasarathy é arquiteto sênior de Big Data na equipe AWS Lake Formation. Ela gosta de criar soluções de malha de dados e compartilhá-las com a comunidade.
Srividya Parthasarathy é arquiteto sênior de Big Data na equipe AWS Lake Formation. Ela gosta de criar soluções de malha de dados e compartilhá-las com a comunidade.
 Sandeep Adwankar é gerente de produto técnico sênior da AWS. Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos comerciais e técnicos em produtos que permitem aos clientes melhorar a forma como gerenciam, protegem e acessam dados.
Sandeep Adwankar é gerente de produto técnico sênior da AWS. Com sede na área da baía da Califórnia, ele trabalha com clientes em todo o mundo para traduzir requisitos comerciais e técnicos em produtos que permitem aos clientes melhorar a forma como gerenciam, protegem e acessam dados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- EVM Finanças. Interface unificada para finanças descentralizadas. Acesse aqui.
- Grupo de Mídia Quântica. IR/PR Amplificado. Acesse aqui.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :tem
- :é
- :onde
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Capaz
- Acesso
- acessando
- Conta
- reconhecer
- em
- adicionar
- admin
- novamente
- Todos os Produtos
- juntamente
- tb
- Amazon
- Amazona atena
- Amazon EMR
- Amazon Web Services
- quantidades
- an
- Análises
- analítica
- e
- qualquer
- aproximadamente
- SOMOS
- ÁREA
- por aí
- AS
- At
- automaticamente
- disponível
- evitar
- AWS
- Formação da Nuvem AWS
- Cola AWS
- Formação AWS Lake
- baseado
- Bay
- Porque
- sido
- Benefícios
- Grande
- Big Data
- Prédio
- negócio
- by
- Califórnia
- CAN
- catálogo
- Causar
- Alterações
- acusações
- chen
- Escolha
- escolha
- classificação
- Coluna
- colunas
- vem
- comunidade
- comparar
- comparado
- completar
- cônsul
- continuamente
- contribuiu
- custos
- rastreador
- crio
- criado
- cria
- Criar
- criação
- Atual
- Clientes
- dados,
- acesso a dados
- lago data
- banco de dados
- dia
- Padrão
- demonstrar
- implantar
- implanta
- descreve
- detalhes
- determina
- descoberto
- down
- durante
- eficientemente
- ou
- permitir
- habilitado
- Motores
- Éter (ETH)
- todos
- expandido
- explicado
- exponencialmente
- extrato
- extrair os dados
- mais rápido
- Característica
- filtro
- filtragem
- filtros
- final
- seguir
- seguinte
- Escolha
- treinamento
- da
- gera
- dado
- globo
- Cresça:
- Crescente
- Ter
- he
- pesado
- levantamento pesado
- altamente
- segurar
- hora
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- IAM
- Identidade
- melhorar
- melhoria
- melhorias
- in
- Crescimento
- Aumenta
- índice
- índices
- ineficiente
- INFORMAÇÕES
- para dentro
- IT
- jpg
- Guarda
- manutenção
- chaves
- lago
- maior
- lançamento
- traçado
- facelift
- como
- Line
- cargas
- fazer
- gerencia
- de grupos
- Gerente
- malha
- metadados
- poder
- milhões
- minutos
- Mês
- mais
- muito
- devo
- Navegar
- navegação
- Navegação
- necessário
- Novo
- recentemente
- não
- agora
- número
- of
- on
- só
- Otimize
- or
- ordem
- A Nossa
- saída
- Acima de
- página
- pão
- caminho
- atuação
- platão
- Inteligência de Dados Platão
- PlatãoData
- Publique
- presente
- em processamento
- Produto
- gerente de produto
- Produtos
- fornecer
- redução
- região
- requeridos
- Requisitos
- exige
- Recursos
- resultando
- Resultados
- Tipo
- papéis
- Execute
- corrida
- mesmo
- segundo
- Seção
- seguro
- senior
- Serviços
- conjunto
- Configurações
- compartilhando
- ela
- Shows
- periodo
- de forma considerável
- simples
- solução
- Soluções
- fonte
- Faísca
- Espectro
- pilha
- Passos
- armazenamento
- loja
- franco
- Tanga
- entraram com sucesso
- ajuda
- sistemas
- mesa
- Tire
- Profissionais
- Dados Técnicos:
- modelo
- obrigado
- que
- A
- deles
- Eles
- então
- Este
- deles
- isto
- tempo
- para
- hoje
- levou
- traduzir
- verdadeiro
- tipo
- tipos
- para
- compreender
- não desejado
- Atualizar
- usar
- usava
- utilização
- utilizar
- valor
- Valores
- vário
- Grande
- verificar
- versão
- foi
- Caminho..
- we
- web
- serviços web
- quando
- qual
- QUEM
- precisarão
- de
- sem
- Workgroup
- trabalho
- mundo
- yaml
- ano
- Você
- investimentos
- zefirnet