
Imagem do autor | Criador de imagens do Bing
Boneca 2.0 é um modelo de linguagem grande (LLM) de código aberto seguido por instruções que foi ajustado em um conjunto de dados gerado por humanos. Pode ser usado tanto para fins de pesquisa quanto para fins comerciais.
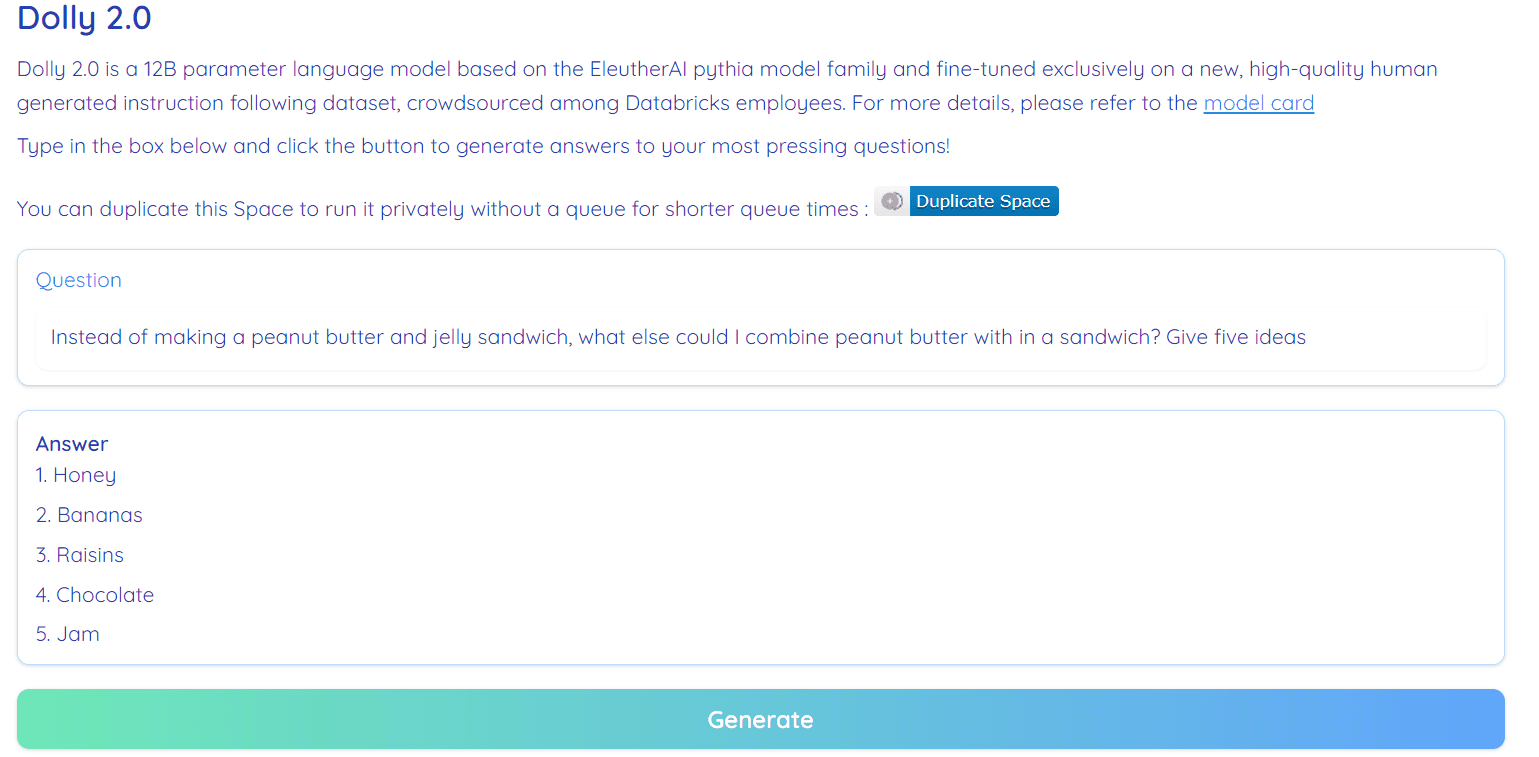
Imagem da Abraçando o Espaço do Rosto por RamAnanth1
Anteriormente, a equipe Databricks lançou Boneca 1.0, LLM, que exibe capacidade de seguir instruções semelhantes ao ChatGPT e custa menos de US$ 30 para treinar. Ele estava usando o conjunto de dados da equipe Stanford Alpaca, que estava sob uma licença restrita (somente pesquisa).
O Dolly 2.0 resolveu esse problema ajustando o modelo de linguagem de parâmetros 12B (Pythia) em uma instrução de alta qualidade gerada por humanos no seguinte conjunto de dados, que foi rotulado por um funcionário da Datbricks. Tanto o modelo quanto o conjunto de dados estão disponíveis para uso comercial.
Dolly 1.0 foi treinado em um conjunto de dados Stanford Alpaca, que foi criado usando OpenAI API. O conjunto de dados contém a saída do ChatGPT e impede que alguém o use para competir com o OpenAI. Resumindo, você não pode criar um chatbot comercial ou um aplicativo de linguagem com base nesse conjunto de dados.
A maioria dos modelos mais recentes lançados nas últimas semanas sofria dos mesmos problemas, modelos como Alpaca, Coala, GPT4Todos e Vicuna. Para contornar, precisamos criar novos conjuntos de dados de alta qualidade que possam ser usados para uso comercial, e foi isso que a equipe do Databricks fez com o conjunto de dados databricks-dolly-15k.
O novo conjunto de dados contém 15,000 pares de prompt/resposta rotulados por humanos de alta qualidade que podem ser usados para projetar instruções que ajustam modelos de linguagem grandes. O databricks-dolly-15k conjunto de dados vem com Licença Creative Commons Attribution-ShareAlike 3.0 Unported, que permite a qualquer pessoa usá-lo, modificá-lo e criar um aplicativo comercial nele.
Como eles criaram o conjunto de dados databricks-dolly-15k?
A pesquisa OpenAI papel afirma que o modelo InstructGPT original foi treinado em 13,000 prompts e respostas. Ao usar essas informações, a equipe do Databricks começou a trabalhar nisso e descobriu que gerar 13 mil perguntas e respostas era uma tarefa difícil. Eles não podem usar dados sintéticos ou dados geradores de IA e precisam gerar respostas originais para todas as perguntas. É aqui que eles decidiram usar 5,000 funcionários da Databricks para criar dados gerados por humanos.
Os Databricks criaram um concurso, no qual os 20 melhores rotuladores receberiam um grande prêmio. Neste concurso, participaram 5,000 funcionários da Databricks muito interessados em LLMs
O dolly-v2-12b não é um modelo de última geração. Ele tem um desempenho inferior ao dolly-v1-6b em alguns benchmarks de avaliação. Pode ser devido à composição e tamanho dos conjuntos de dados de ajuste fino subjacentes. A família de modelos Dolly está em desenvolvimento ativo, então você pode ver uma versão atualizada com melhor desempenho no futuro.
Em suma, o modelo dolly-v2-12b teve um desempenho melhor do que EleutherAI/gpt-neox-20b e EleutherAI/pythia-6.9b.

Imagem da Dolly grátis
Dolly 2.0 é 100% de código aberto. Ele vem com código de treinamento, conjunto de dados, pesos de modelo e pipeline de inferência. Todos os componentes são adequados para uso comercial. Você pode experimentar o modelo em Hugging Face Spaces Dolly V2 por RamAnanth1.
Imagem da Abraçando o rosto
Recursos:
Demonstração do Dolly 2.0: Dolly V2 por RamAnanth1
Abid Ali Awan (@ 1abidaliawan) é um profissional de cientista de dados certificado que adora criar modelos de aprendizado de máquina. Atualmente, ele está se concentrando na criação de conteúdo e escrevendo blogs técnicos sobre tecnologias de aprendizado de máquina e ciência de dados. Abid é mestre em Gestão de Tecnologia e bacharel em Engenharia de Telecomunicações. Sua visão é construir um produto de IA usando uma rede neural gráfica para estudantes que lutam contra doenças mentais.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :tem
- :é
- :não
- $UP
- 000
- 1
- 20
- a
- habilidade
- ativo
- AI
- Todos os Produtos
- permite
- alternativa
- an
- e
- respostas
- qualquer um
- api
- Aplicação
- SOMOS
- por aí
- autor
- disponível
- prêmio
- baseado
- BE
- benchmarks
- Berkeley
- Melhor
- Grande
- Bing
- Blogs
- ambos
- construir
- Prédio
- by
- CAN
- não podes
- Non-GMO
- chatbot
- ChatGPT
- código
- comercial
- Commons
- competir
- componentes
- contém
- conteúdo
- Criação de conteúdo
- competição
- custos
- crio
- criado
- criação
- Atualmente
- dados,
- ciência de dados
- cientista de dados
- Bancos de dados
- conjuntos de dados
- decidido
- Grau
- Demo
- Design
- Desenvolvimento
- DID
- difícil
- Boneca
- Empregado
- colaboradores
- Engenharia
- avaliação
- Cada
- exposições
- Rosto
- família
- poucos
- focando
- seguinte
- Escolha
- da
- futuro
- gerar
- gerando
- generativo
- ter
- gráfico
- Rede Neural do Gráfico
- Ter
- he
- alta qualidade
- detém
- HTML
- HTTPS
- doença
- imagem
- in
- INFORMAÇÕES
- interessado
- emitem
- questões
- IT
- jpg
- KDnuggetsGenericName
- língua
- grande
- Sobrenome
- mais recente
- aprendizagem
- Licença
- como
- máquina
- aprendizado de máquina
- de grupos
- dominar
- mental
- Doença mental
- poder
- modelo
- modelos
- modificar
- você merece...
- rede
- Neural
- rede neural
- Novo
- of
- on
- só
- aberto
- open source
- OpenAI
- or
- original
- saída
- pares
- parâmetro
- Participou
- atuação
- oleoduto
- platão
- Inteligência de Dados Platão
- PlatãoData
- Produto
- profissional
- fins
- questão
- Frequentes
- liberado
- pesquisa
- resolvidas
- restringido
- s
- mesmo
- Ciência
- Cientista
- conjunto
- Baixo
- Tamanho
- So
- alguns
- fonte
- Espaço
- espaços
- Stanford
- começado
- estado-da-arte
- Unidos
- Lutando
- Estudantes
- adequado
- sintético
- dados sintéticos
- Tarefa
- Profissionais
- Dados Técnicos:
- Tecnologias
- Equipar
- telecomunicação
- do que
- que
- A
- O Futuro
- deles
- isto
- para
- topo
- Trem
- treinado
- Training
- para
- subjacente
- Atualizada
- usar
- usava
- utilização
- versão
- visão
- foi
- we
- semanas
- foram
- O Quê
- qual
- QUEM
- de
- Atividades:
- seria
- escrita
- Você
- zefirnet










