Análise automatizada de dados (ADA) na AWS é uma solução da AWS que permite obter insights significativos de dados em questão de minutos por meio de uma interface de usuário simples e intuitiva. ADA oferece uma plataforma de análise de dados nativa da AWS que está pronta para uso imediato por analistas de dados em uma variedade de casos de uso. Com o ADA, as equipes podem ingerir, transformar, controlar e consultar diversos conjuntos de dados de diversas fontes de dados sem a necessidade de habilidades técnicas especializadas. ADA fornece um conjunto de conectores pré-fabricados para ingerir dados de uma ampla variedade de fontes, incluindo Serviço de armazenamento simples da Amazon (Amazon S3), Fluxos de dados do Amazon Kinesis, Amazon CloudWatch, Amazon CloudTrail e Amazon DynamoDB assim como muitos outros.
A ADA fornece uma plataforma básica que pode ser usada por analistas de dados em um conjunto diversificado de casos de uso, incluindo TI, finanças, marketing, vendas e segurança. O conector de dados CloudWatch pronto para uso do ADA permite a ingestão de dados de logs do CloudWatch na mesma conta da AWS na qual o ADA foi implantado ou de uma conta da AWS diferente.
Nesta postagem, demonstramos como um desenvolvedor ou testador de aplicativos é capaz de usar ADA para obter insights operacionais de aplicativos em execução na AWS. Também demonstramos como você pode usar a solução ADA para se conectar a diferentes fontes de dados na AWS. Nós primeiro implantar a solução ADA em uma conta AWS e configurar a solução ADA criando produtos de dados usando conectores de dados. Em seguida, usamos o ADA Query Workbench para unir os conjuntos de dados separados e consultar os dados correlacionados, usando a familiar Linguagem de Consulta Estruturada (SQL), para obter insights. Também demonstramos como o ADA pode ser integrado a ferramentas de business intelligence (BI), como o Tableau, para visualizar os dados e construir relatórios.
Visão geral da solução
Nesta seção, apresentamos a arquitetura da solução para a demonstração e explicamos o fluxo de trabalho. Para efeitos de demonstração, a aplicação personalizada é simulada utilizando um AWS Lambda função que emite logs em Formato de registro Apache em um intervalo predefinido usando Amazon Event Bridge. Este formato padrão pode ser produzido por diversos servidores web e lido por diversos programas de análise de log. Os logs do aplicativo (função Lambda) são enviados para um grupo de logs do CloudWatch. Os logs históricos do aplicativo são armazenados em um bucket S3 para referência e para fins de consulta. Uma tabela de consulta com uma lista de Códigos de status HTTP junto com as descrições são armazenados em uma tabela do DynamoDB. Esses três servem como fontes das quais os dados são ingeridos no ADA para correlação, consulta e análise. Nós implantar a solução ADA em uma conta AWS e configurar ADA. Criamos então o produtos de dados dentro da ADA para o Grupo de logs do CloudWatch, Caçamba S3 e DynamoDB. À medida que os produtos de dados são configurados, o ADA provisiona pipelines de dados para ingerir os dados das fontes. Com o ADA Query Workbench, você pode consultar os dados ingeridos usando SQL simples para solução de problemas de aplicativos ou diagnóstico de problemas.
O diagrama a seguir fornece uma visão geral da arquitetura e do fluxo de trabalho de uso do ADA para obter insights sobre logs de aplicativos.
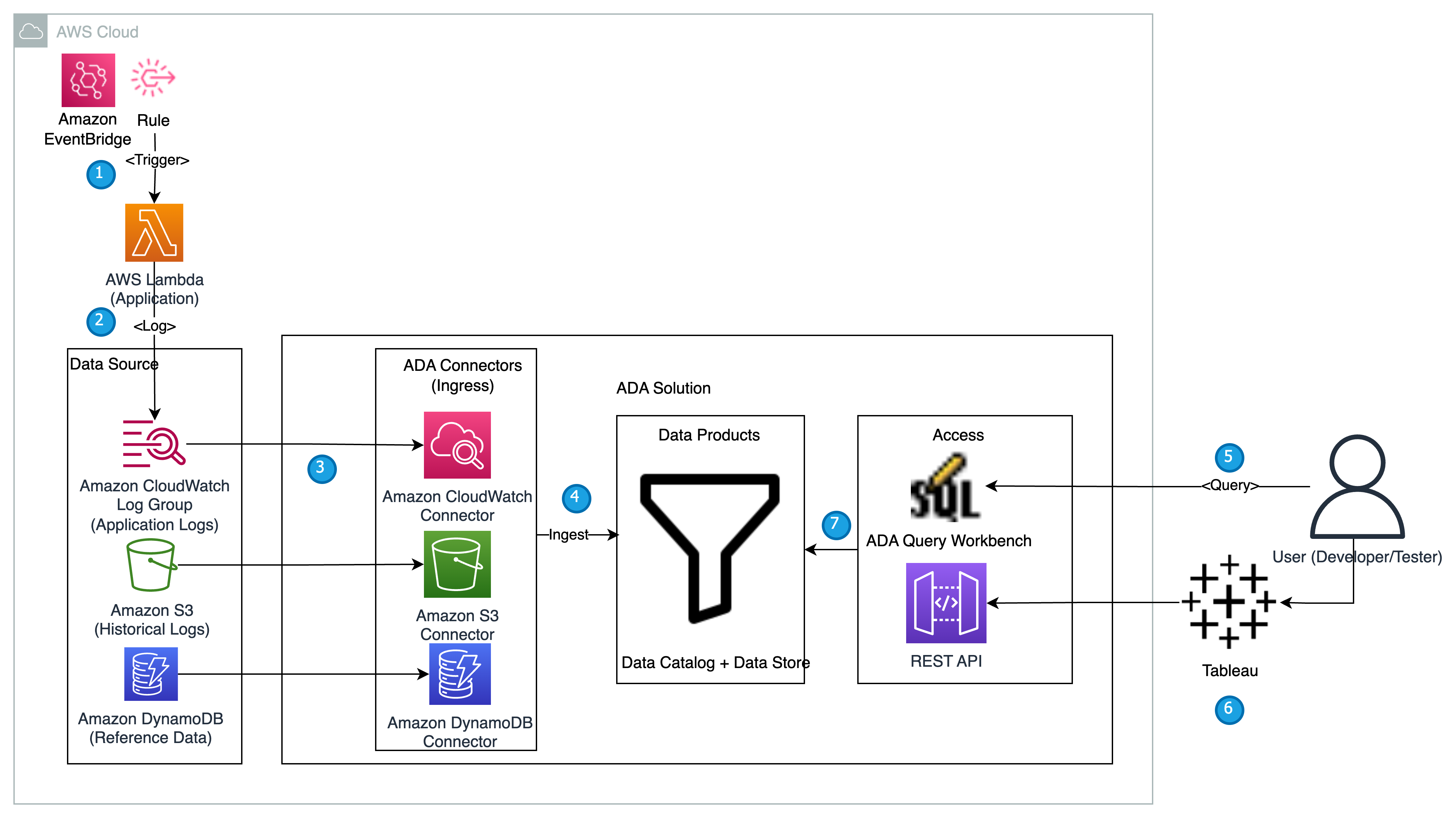
O fluxo de trabalho inclui as seguintes etapas:
- Uma função Lambda está programada para ser acionada em intervalos de 2 minutos usando EventBridge.
- A função Lambda emite logs armazenados em um grupo de logs especificado do CloudWatch em
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Os logs do aplicativo são gerados usando o esquema Apache Log Format, mas armazenados no grupo de logs do CloudWatch no formato JSON. - Os produtos de dados para CloudWatch, Amazon S3 e DynamoDB são criados em ADA. O produto de dados do CloudWatch se conecta ao grupo de logs do CloudWatch onde os logs do aplicativo (função Lambda) são armazenados. O conector do Amazon S3 se conecta a uma pasta de bucket do S3 onde os logs históricos são armazenados. O conector DynamoDB se conecta a uma tabela DynamoDB onde os códigos de status referidos pelo aplicativo e pelos logs históricos são armazenados.
- Para cada um dos produtos de dados, a ADA implanta a infraestrutura de pipeline de dados para ingerir dados das fontes. Quando a ingestão de dados for concluída, você poderá escrever consultas usando SQL por meio do ADA Query Workbench.
- Você pode fazer login no portal ADA e redigir consultas SQL no Query Workbench para obter insights sobre os logs do aplicativo. Opcionalmente, você pode salvar a consulta e compartilhá-la com outros usuários ADA no mesmo domínio. O recurso de consulta ADA é desenvolvido por Amazona atena, que é um serviço analítico interativo e sem servidor que fornece uma maneira simplificada e flexível de analisar petabytes de dados.
- O Tableau está configurado para acessar os produtos de dados ADA por meio de endpoints de saída ADA. Em seguida, você cria um painel com dois gráficos. O primeiro gráfico é um mapa de calor que mostra a prevalência de códigos de erro HTTP correlacionados com os endpoints da API do aplicativo. O segundo gráfico é um gráfico de barras que mostra as 10 principais APIs de aplicativos com uma contagem total de códigos de erro HTTP dos dados históricos.
Pré-requisitos
Para esta postagem, você precisa preencher os seguintes pré-requisitos:
- Instale o Interface de linha de comando da AWS (AWSCLI), Kit de desenvolvimento em nuvem da AWS (AWSCDK) pré-requisitos, específico do TypeScript pré-requisitos e git.
- Implantação a solução ADA em sua conta AWS no
us-east-1Região.- Forneça um e-mail de administrador ao iniciar o ADA Formação da Nuvem AWS pilha. Isso é necessário para que o ADA envie a senha do usuário root. Um número de telefone de administrador é necessário para receber uma mensagem de senha única se a autenticação multifator (MFA) estiver habilitada. Para esta demonstração, o MFA não está habilitado.
- Crie e implante o aplicativo de exemplo (disponível no site GitHub repo) para que os recursos a seguir possam ser provisionados em sua conta no
us-east-1Região:- Uma função Lambda que simula o aplicativo de registro em log e uma regra do EventBridge que invoca a função do aplicativo em intervalos de 2 minutos.
- Um bucket S3 com as políticas de bucket relevantes e um arquivo CSV que contém os logs históricos do aplicativo.
- Uma tabela do DynamoDB com os dados de pesquisa.
- Relevante Gerenciamento de acesso e identidade da AWS (IAM) e permissões necessárias para os serviços.
- Opcionalmente, instale Tableau Desktop, um provedor de BI terceirizado. Para esta postagem, usamos o Tableau Desktop versão 2021.2. Há um custo envolvido no uso de uma versão licenciada do aplicativo Tableau Desktop. Para obter detalhes adicionais, consulte o Licenciamento do Tableau informações.
Implantar e configurar o ADA
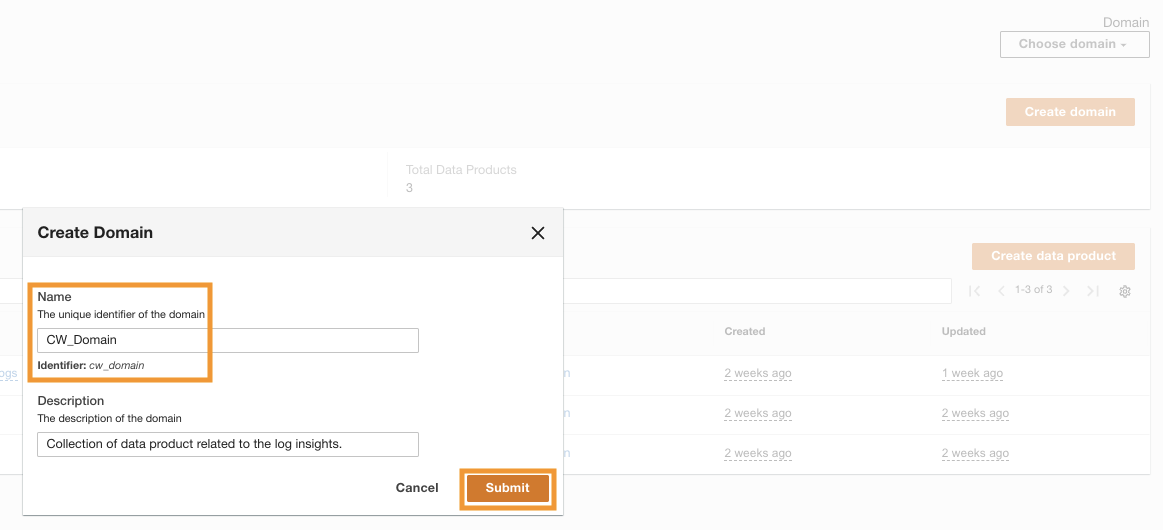
Depois que o ADA for implantado com êxito, você poderá login na sua conta MXNUMX usando o e-mail de administrador fornecido durante a instalação. Você então cria um domínio nomeado CW_Domain. Um domínio é uma coleção de produtos de dados definida pelo usuário. Por exemplo, um domínio pode ser uma equipe ou um projeto. Os domínios fornecem uma maneira estruturada para os usuários organizarem seus produtos de dados e gerenciarem permissões de acesso.
- No console ADA, escolha domínios no painel de navegação.
- Escolha Criar domínio.
- Insira o nome (
CW_Domain) e descrição e escolha Submeter.
Configure a infraestrutura de aplicativos de exemplo usando o AWS CDK
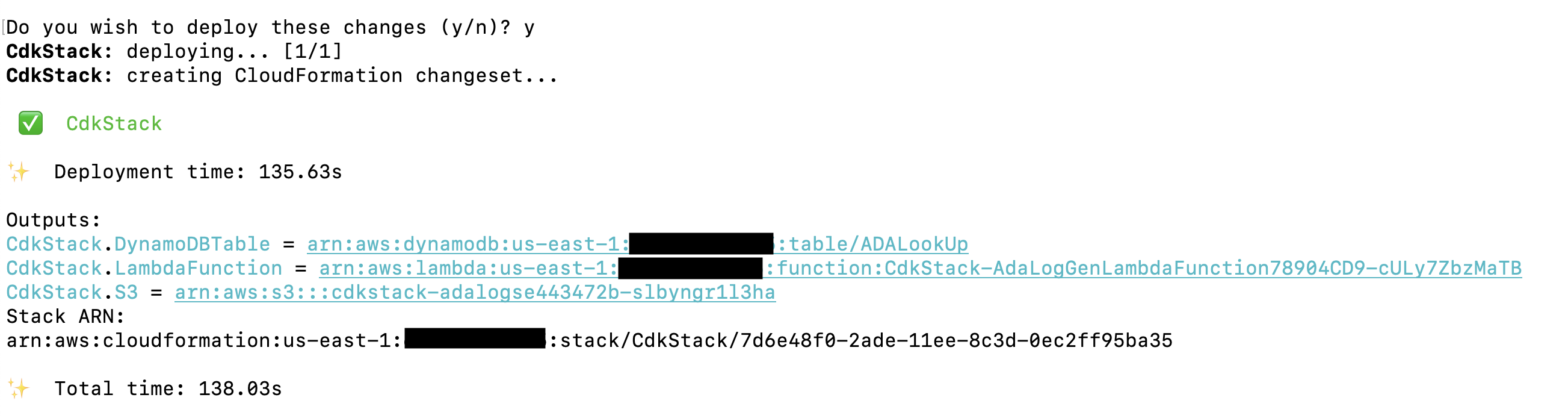
A solução AWS CDK que implanta o aplicativo de demonstração está hospedada em GitHub. As etapas para clonar o repositório e configurar o projeto AWS CDK são detalhadas nesta seção. Antes de executar esses comandos, certifique-se de configurar suas credenciais da AWS. Crie uma pasta, abra o terminal e navegue até a pasta onde a solução AWS CDK precisa ser instalada. Execute o seguinte código:
Essas etapas executam as seguintes ações:
- Instale as dependências da biblioteca
- Construir o projeto
- Gere um modelo válido do CloudFormation
- Implante a pilha usando AWS CloudFormation em sua conta AWS
A implantação leva cerca de 1 a 2 minutos e cria a tabela de pesquisa do DynamoDB, a função Lambda e o bucket S3 contendo os arquivos de log históricos como saídas. Copie esses valores para um aplicativo de edição de texto, como o Bloco de Notas.
Crie produtos de dados ADA
Criamos três produtos de dados diferentes para esta demonstração, um para cada fonte de dados que você consultará para obter insights operacionais. Um produto de dados é um conjunto de dados (uma coleção de dados, como uma tabela ou um arquivo CSV) que foi importado com sucesso para o ADA e que pode ser consultado.
Crie um produto de dados do CloudWatch
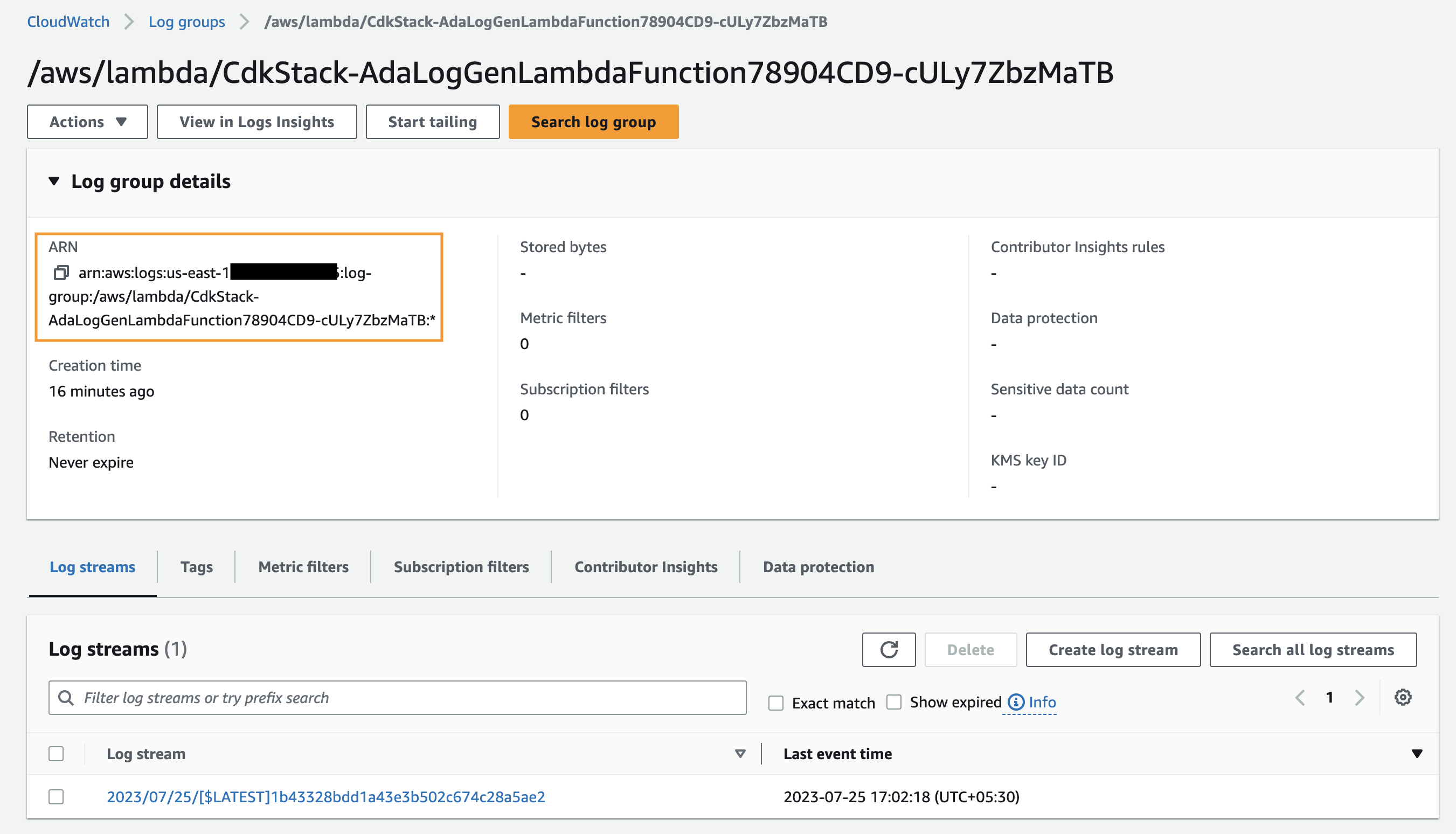
Primeiro, criamos um produto de dados para os logs do aplicativo configurando o ADA para ingerir o grupo de logs do CloudWatch para o aplicativo de amostra (função Lambda). Use o CdkStack.LambdaFunction saída para obter o ARN da função Lambda e localizar o ARN do grupo de logs do CloudWatch correspondente no console do CloudWatch.
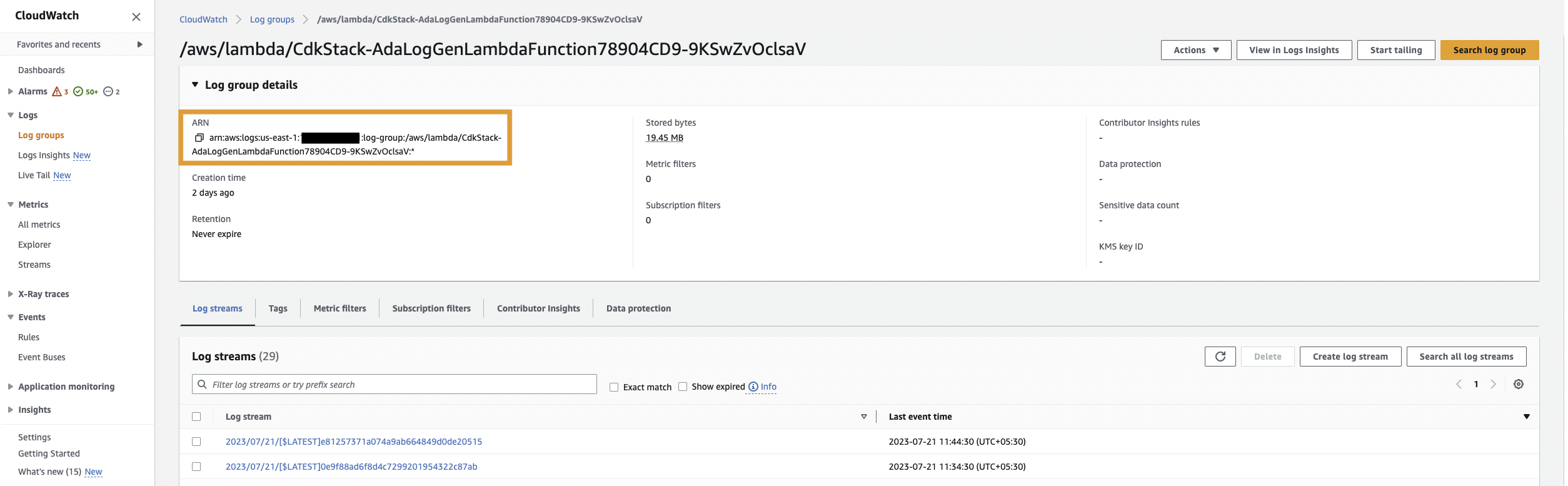
Em seguida, conclua as seguintes etapas:
- No console do ADA, navegue até o domínio do ADA e crie um produto de dados do CloudWatch.
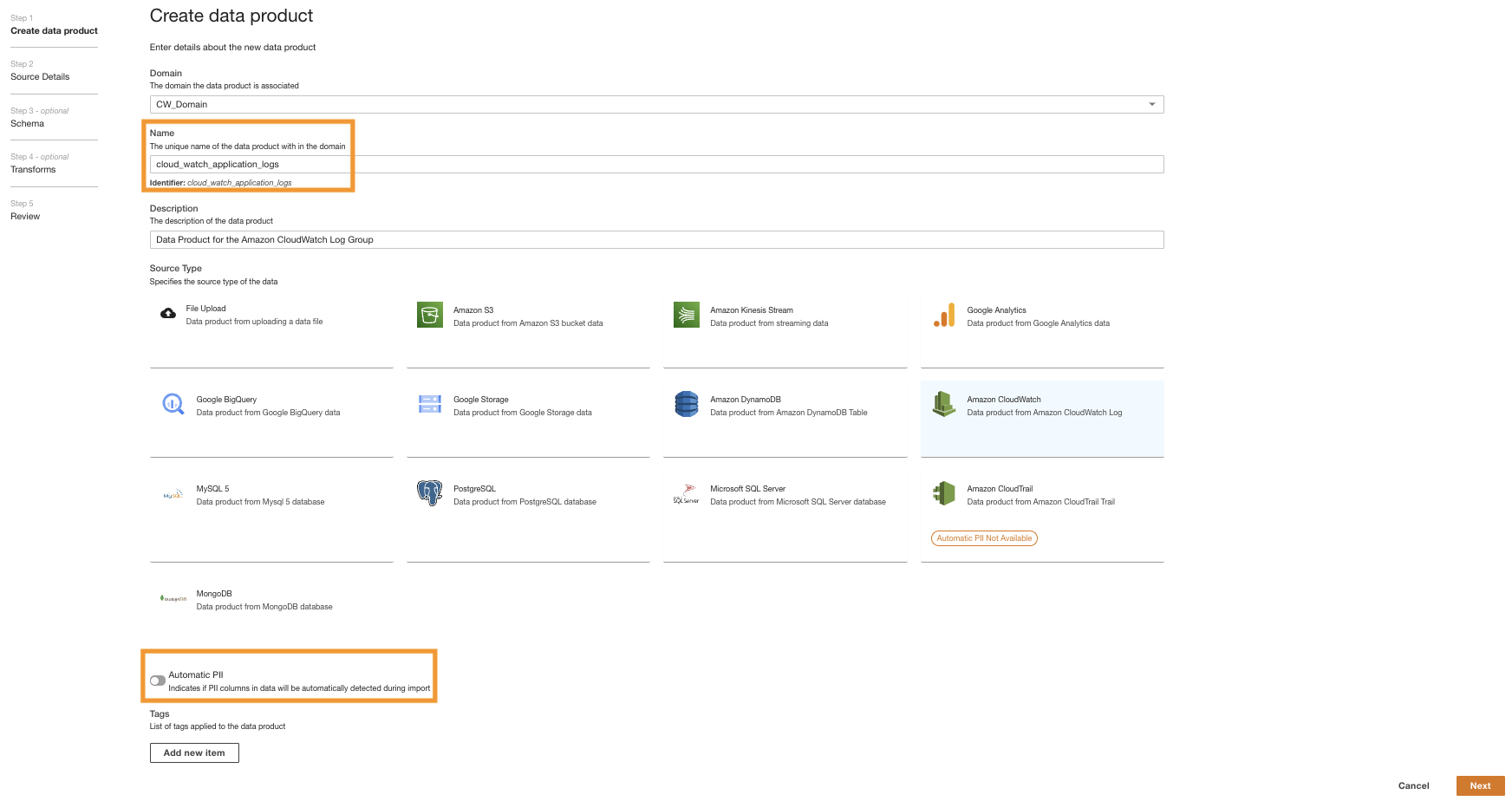
- Escolha NomeInsira o nome.
- Escolha Tipo de fonte, escolher Amazon CloudWatch.
- Desabilitar Informações de identificação pessoal automáticas.
O ADA possui um recurso que detecta automaticamente dados de informações de identificação pessoal (PII) durante a importação, que é habilitado por padrão. Para esta demonstração, desabilitamos esta opção para o produto de dados porque a descoberta de dados PII não está no escopo desta demonstração.
- Escolha Próximo.
- Procure e escolha o ARN do grupo de logs do CloudWatch copiado da etapa anterior.

- Copie o ARN do grupo de logs.
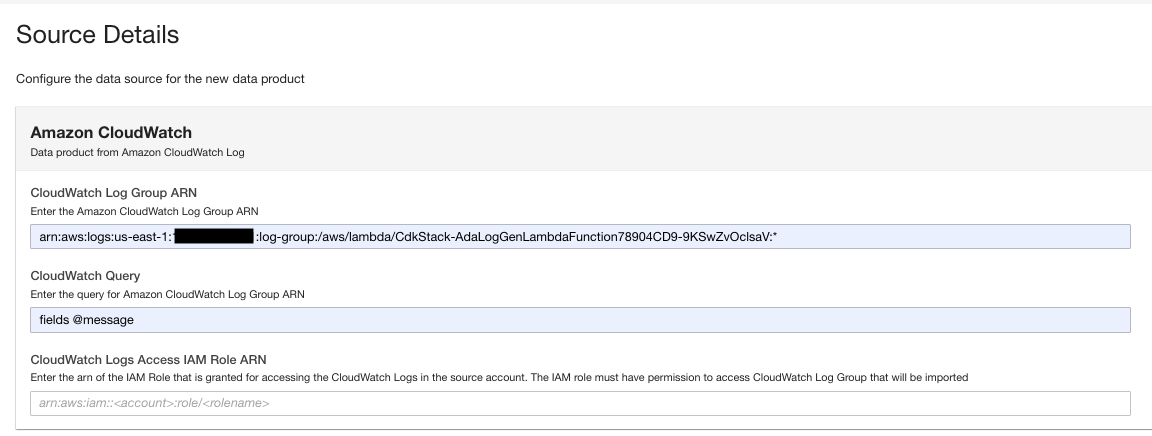
- Na página do produto de dados, insira o ARN do grupo de logs.
- Escolha Consulta do CloudWatch, insira uma consulta que você deseja que o ADA obtenha do grupo de logs.
Nesta demonstração, consultamos o campo @message porque estamos interessados em obter os logs do aplicativo do grupo de logs.
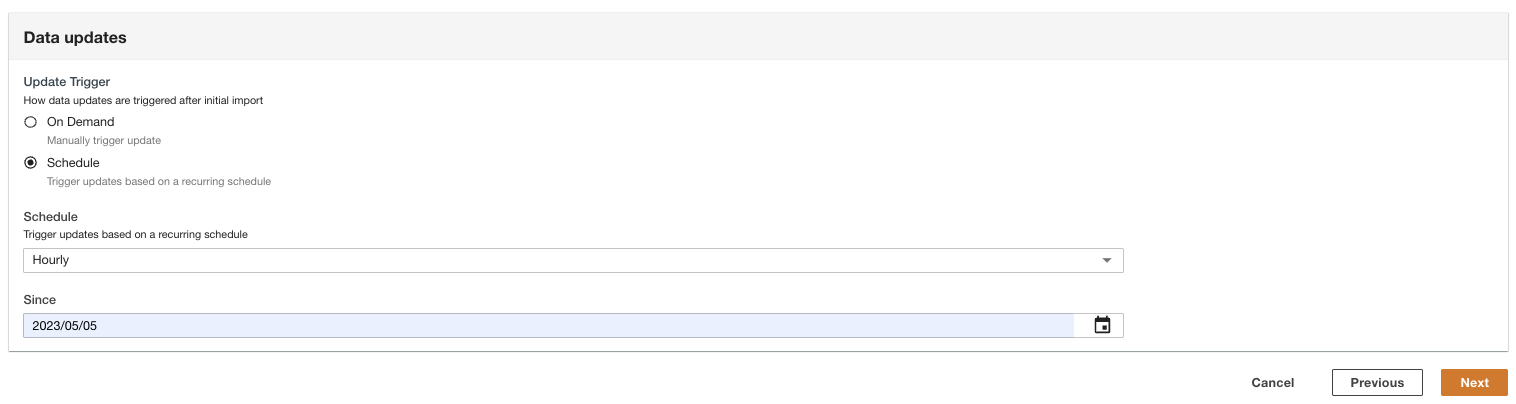
- Selecione como as atualizações de dados serão acionadas após a importação inicial.
O ADA pode ser configurado para consumir os dados da fonte em intervalos flexíveis (até 15 minutos ou mais) ou sob demanda. Para a demonstração, configuramos as atualizações de dados para serem executadas de hora em hora.
- Escolha Próximo.
Em seguida, o ADA se conectará ao grupo de logs e consultará o esquema. Como os logs estão no formato Apache Log, transformamos os logs em campos separados para que possamos executar consultas nos campos de log específicos. ADA fornece quatro omissão transformações e oferece suporte à transformação personalizada por meio de um script Python. Nesta demonstração, executamos um script Python personalizado para transformar o campo de mensagem JSON em campos Apache Log Format.
- Escolha Esquema de transformação.
- Escolha Criar nova transformação.
- Nos envie os
apache-log-extractor-transform.pyroteiro do/asset/transform_logs/pasta. - Escolha Submeter.
O ADA transformará os logs do CloudWatch usando o script e apresentará o esquema processado.
- Escolha Próximo.
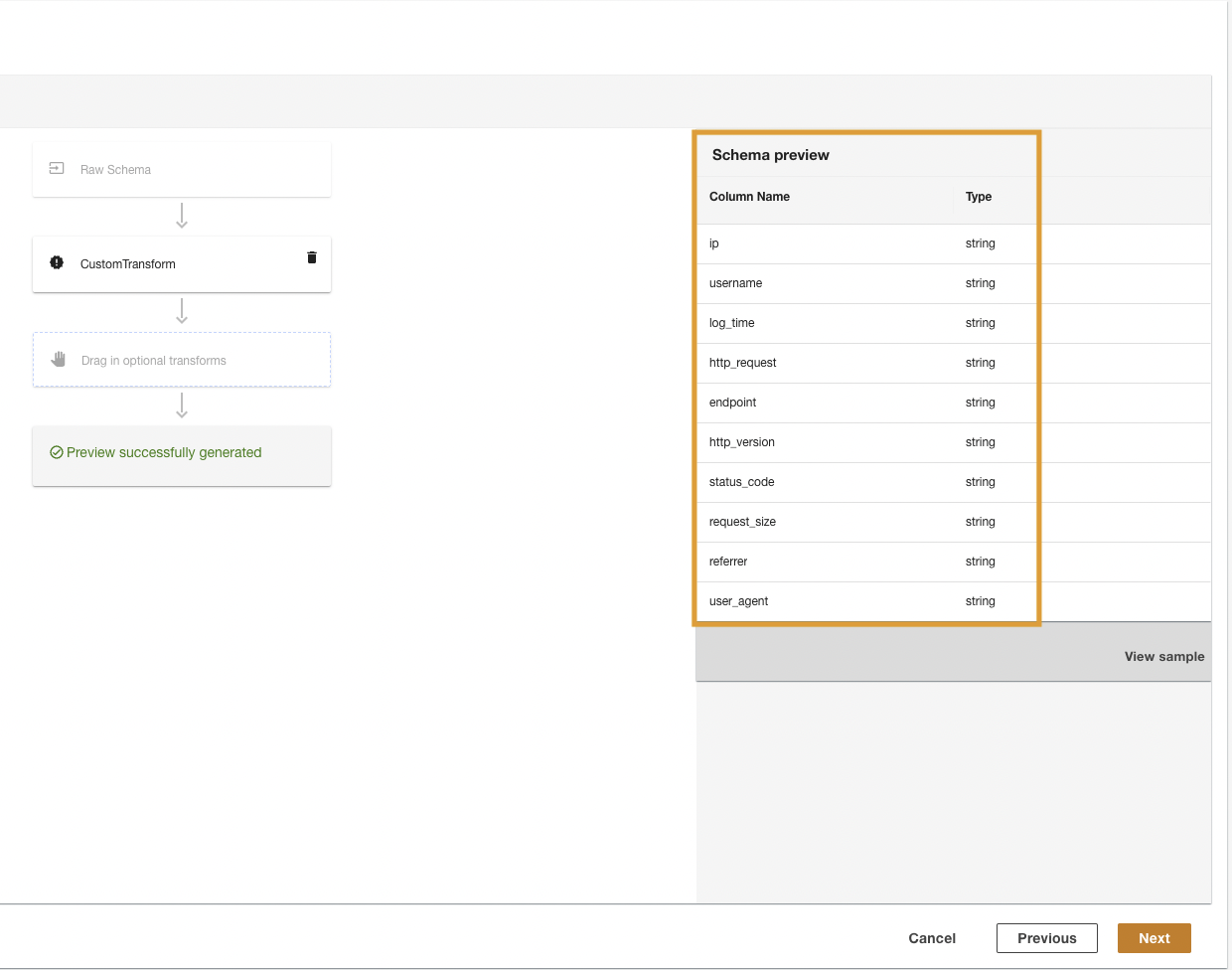
- Na última etapa, revise as etapas e escolha Submeter.
O ADA iniciará o processamento de dados, criará os pipelines de dados e preparará os grupos de logs do CloudWatch para serem consultados no Query Workbench. Este processo levará alguns minutos para ser concluído e será mostrado no console ADA em Produtos de Dados.
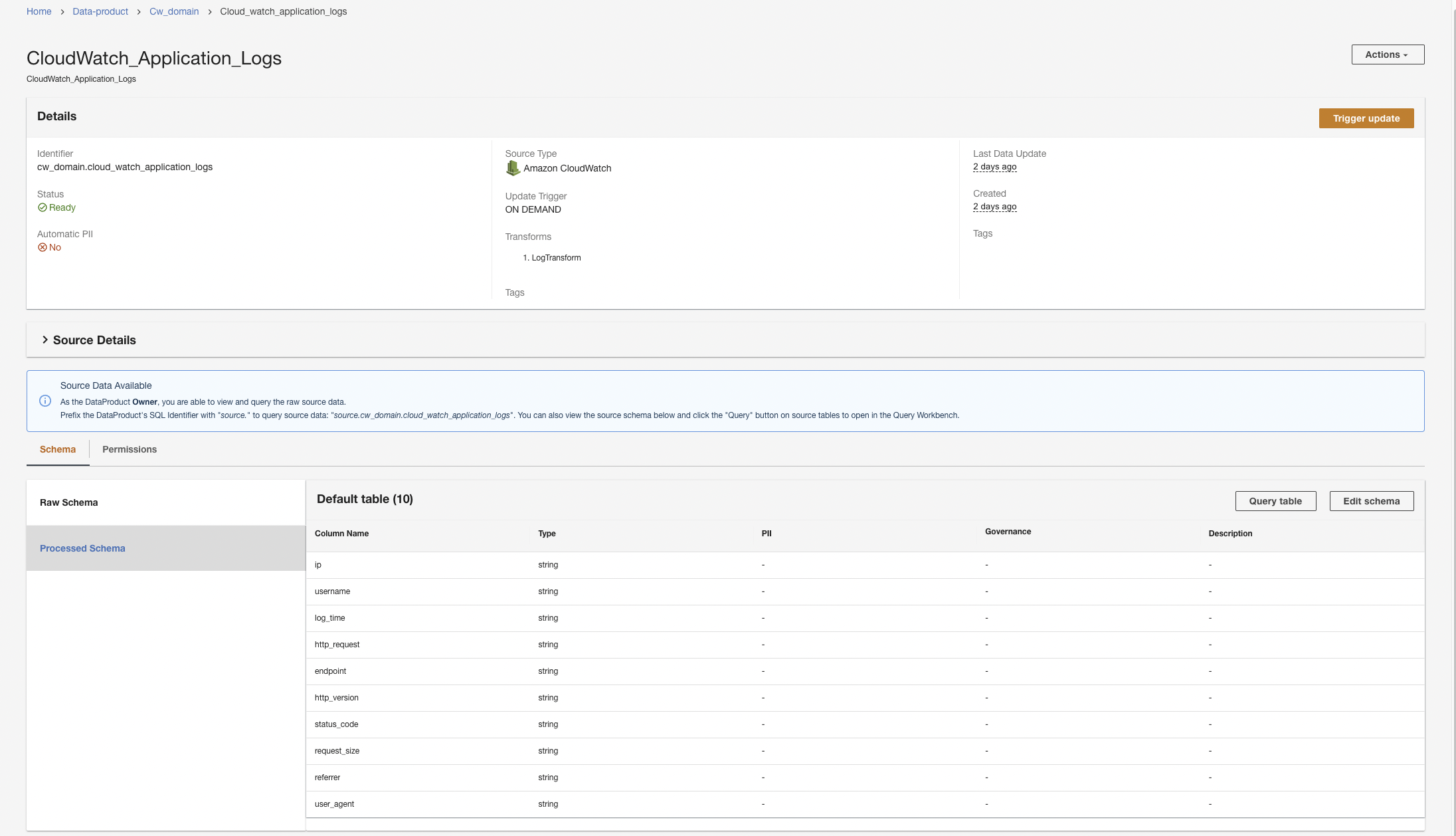
Crie um produto de dados do Amazon S3
Repetimos as etapas para adicionar os logs históricos da fonte de dados do Amazon S3 e procurar dados de referência na tabela do DynamoDB. Para essas duas fontes de dados, não criamos transformações personalizadas porque os formatos de dados estão em CSV (para logs históricos) e atributos-chave (para dados de pesquisa de referência).
- No console do ADA, crie um novo produto de dados.
- Insira o nome (
hist_logs) e escolha Amazon S3.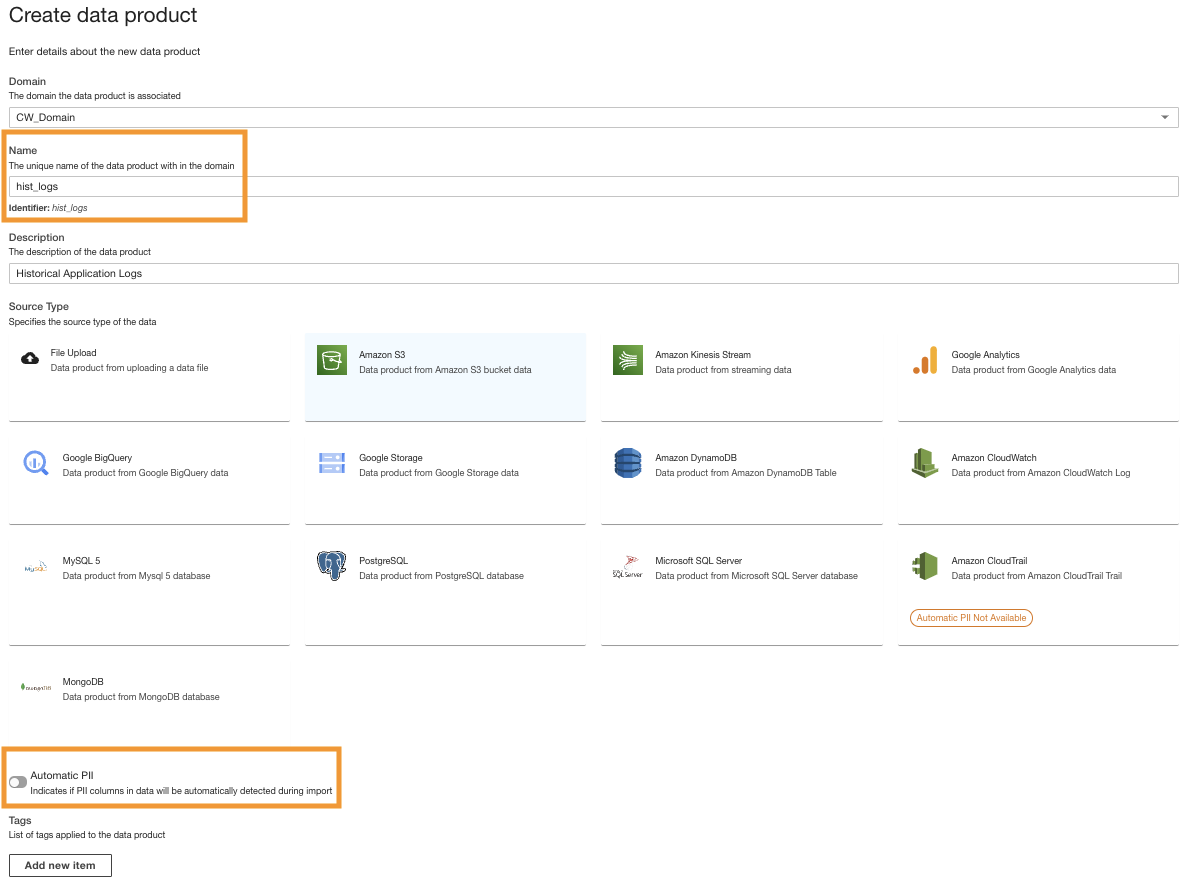
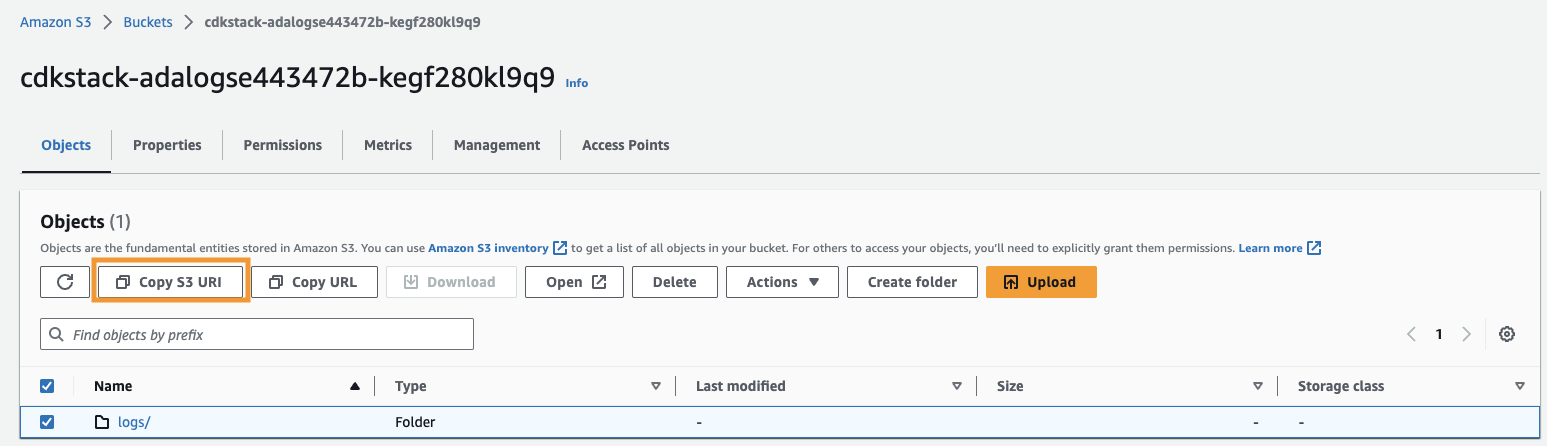
- Copie o URI do Amazon S3 (o texto após
arn:aws:s3:::) deCdkStack.S3variável de saída e navegue até o console do Amazon S3. - Na caixa de pesquisa, insira o texto copiado, abra o bucket S3, selecione o
/logspasta e escolha Copiar URI do S3.
Os logs históricos são armazenados neste caminho.
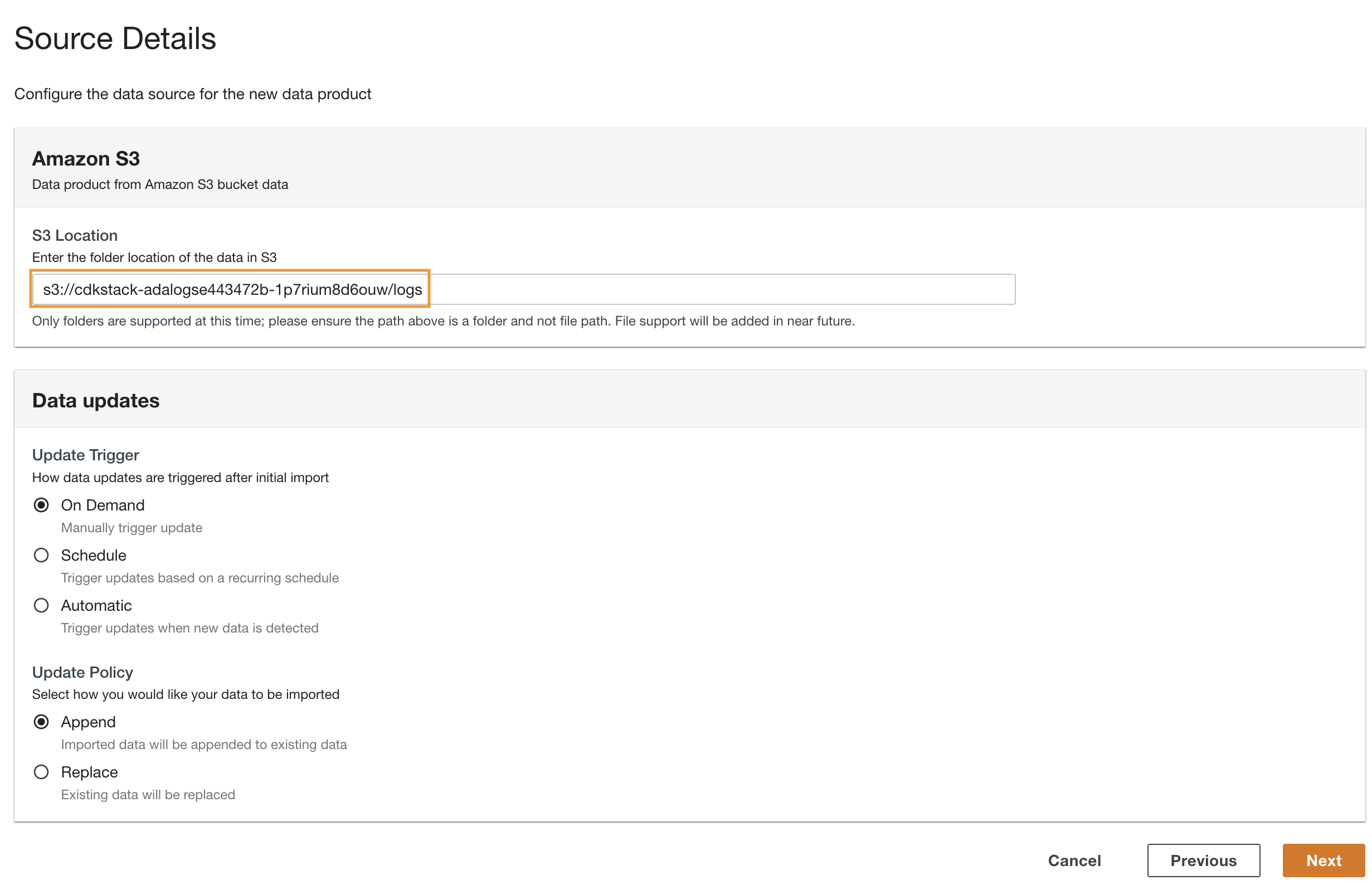
- Navegue de volta para o console do ADA e insira o URI do S3 copiado para Localização S3.
- Escolha Gatilho de atualização, selecione Sob Demanda porque os logs históricos são atualizados com uma frequência não especificada.
- Escolha Política de atualização, selecione Acrescentar para anexar dados recém-importados aos dados existentes.
- Escolha Próximo.
O ADA processa o esquema dos arquivos no caminho da pasta selecionada. Como os logs estão no formato CSV, o ADA é capaz de ler os nomes das colunas sem exigir transformações adicionais. No entanto, as colunas status_code e request_size são inferidos como tipo longo pelo ADA. Queremos manter os tipos de dados da coluna consistentes entre os produtos de dados para que possamos unir as tabelas de dados e consultar os dados. A coluna status_code será usado para criar junções nas tabelas de dados.
- Escolha Esquema de transformação para alterar os tipos de dados das duas colunas para o tipo de dados string.
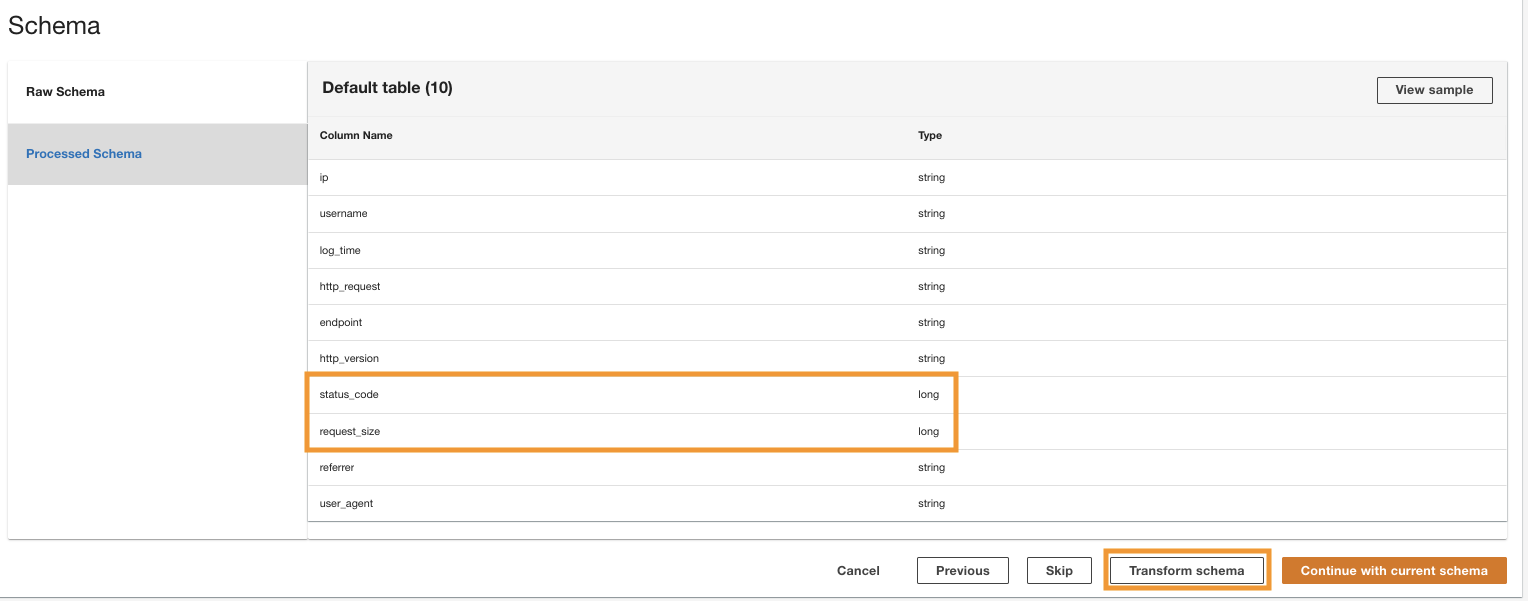
Observe os nomes das colunas destacadas no Visualização do esquema painel antes de aplicar as transformações de tipo de dados.
- No Plano de transformação painel, sob Transformações integradas, escolha Aplicar mapeamento.
Esta opção permite alterar o tipo de dados de um tipo para outro.
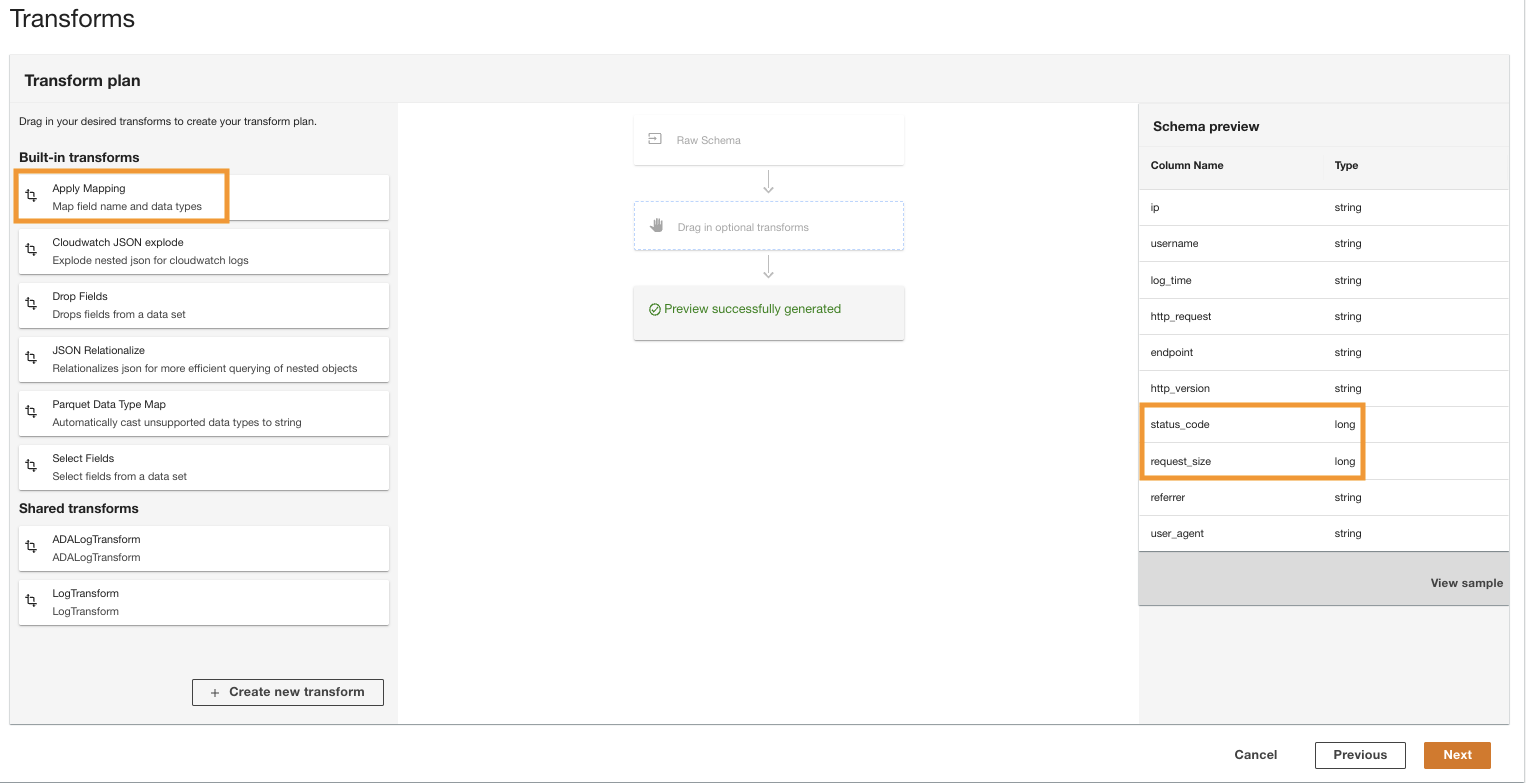
- No Aplicar mapeamento seção, desmarque Eliminar outros campos.
Se esta opção não estiver desabilitada, apenas as colunas transformadas serão preservadas e todas as outras colunas serão eliminadas. Como queremos manter todas as colunas, desabilitamos esta opção.
- Debaixo Mapeamentos de campopara Antigo nome e Novo nome, entrar
status_codee para Novo tipo, entrarstring.
- Escolha Adicionar Item.
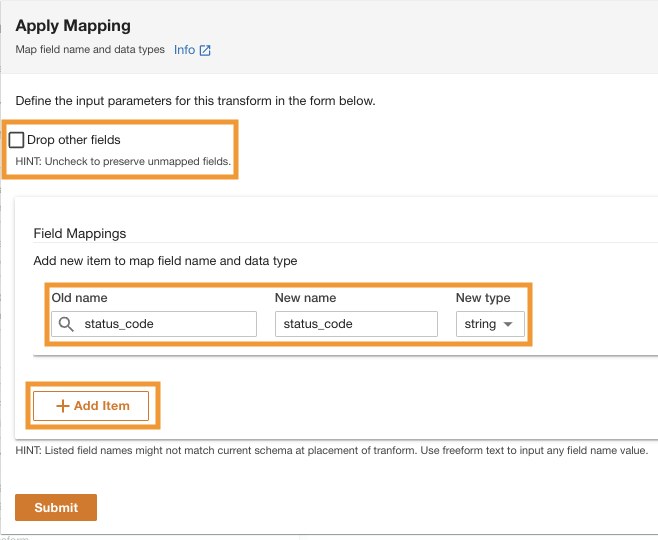
- Escolha Antigo nome e Novo nome¸ insira request_size e para Novo tipo de dados, insira a sequência.
- Escolha Submeter.
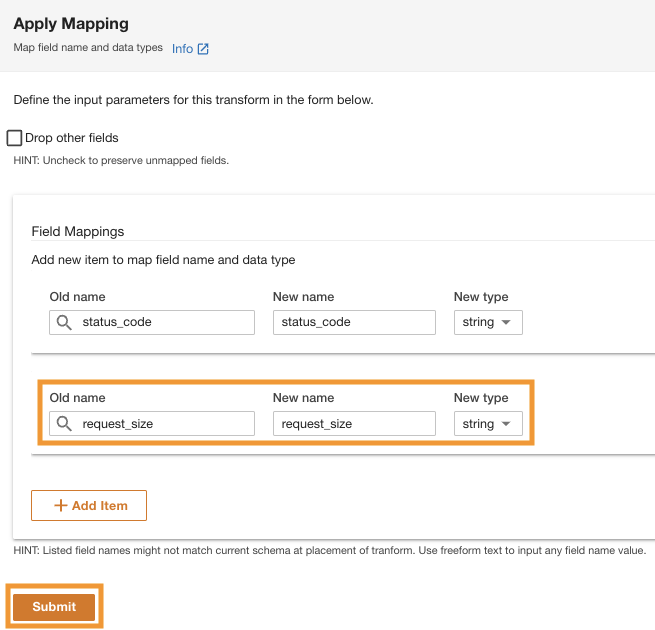
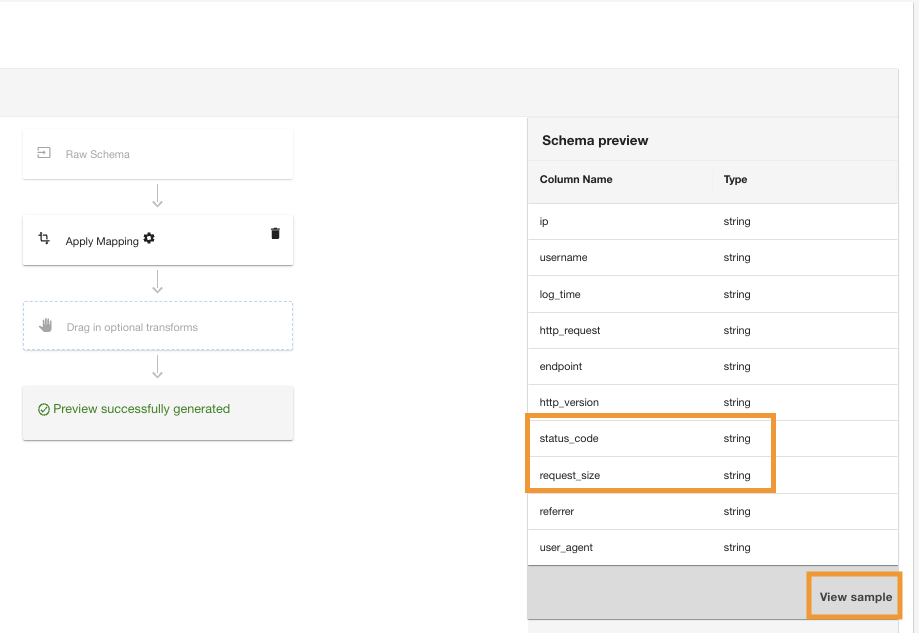
A ADA aplicará a transformação de mapeamento na fonte de dados do Amazon S3. Observe os tipos de coluna no Visualização do esquema painel.
- Escolha Ver amostra para visualizar os dados com a transformação aplicada.
O ADA exibirá a confirmação de dados PII para garantir que apenas usuários autorizados possam visualizar os dados ou que o conjunto de dados não contenha dados PII.
- Escolha concordar para continuar a visualizar os dados de amostra.
Observe que o esquema é idêntico ao esquema do grupo de logs do CloudWatch porque tanto o aplicativo atual quanto os logs históricos do aplicativo estão no formato Apache Log.
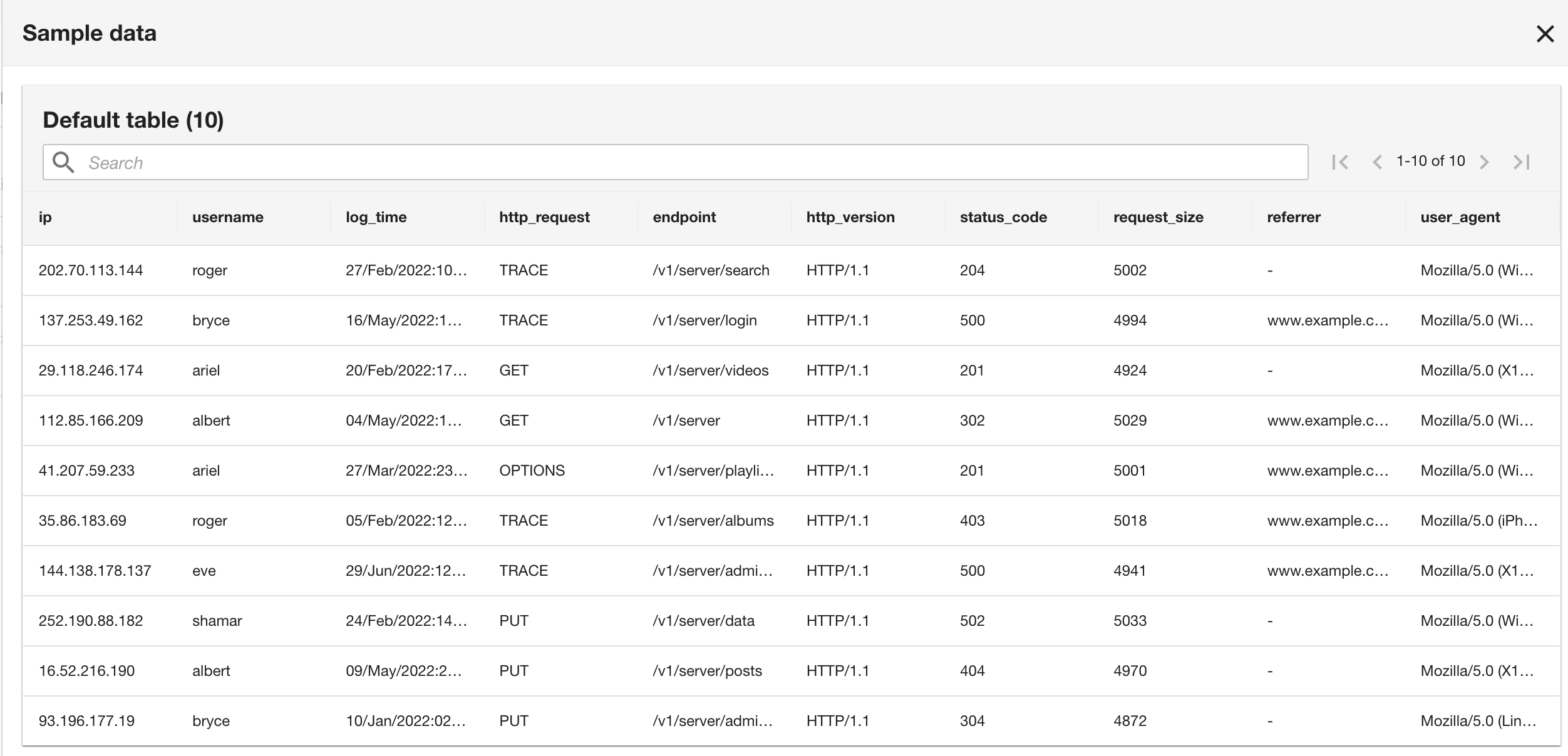
- Na etapa final, revise a configuração e escolha Submeter.
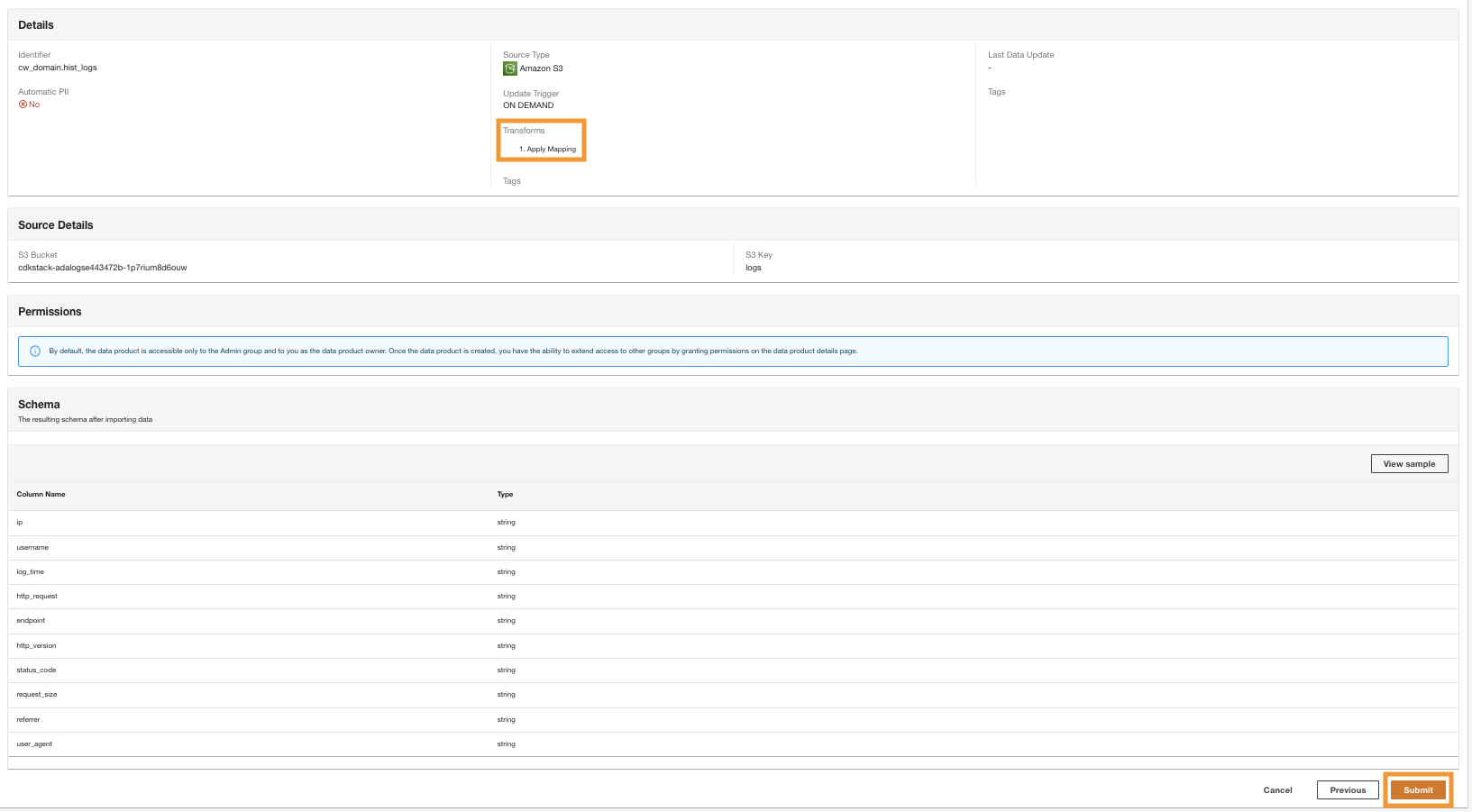
A ADA começa a processar os dados da origem do Amazon S3, cria a infraestrutura de back-end e prepara o produto de dados. Este processo leva alguns minutos dependendo do tamanho dos dados.
Crie um produto de dados do DynamoDB
Por último, criamos um produto de dados DynamoDB. Conclua as seguintes etapas:
- No console do ADA, crie um novo produto de dados.
- Insira o nome (
lookup) e escolha Amazon DynamoDB.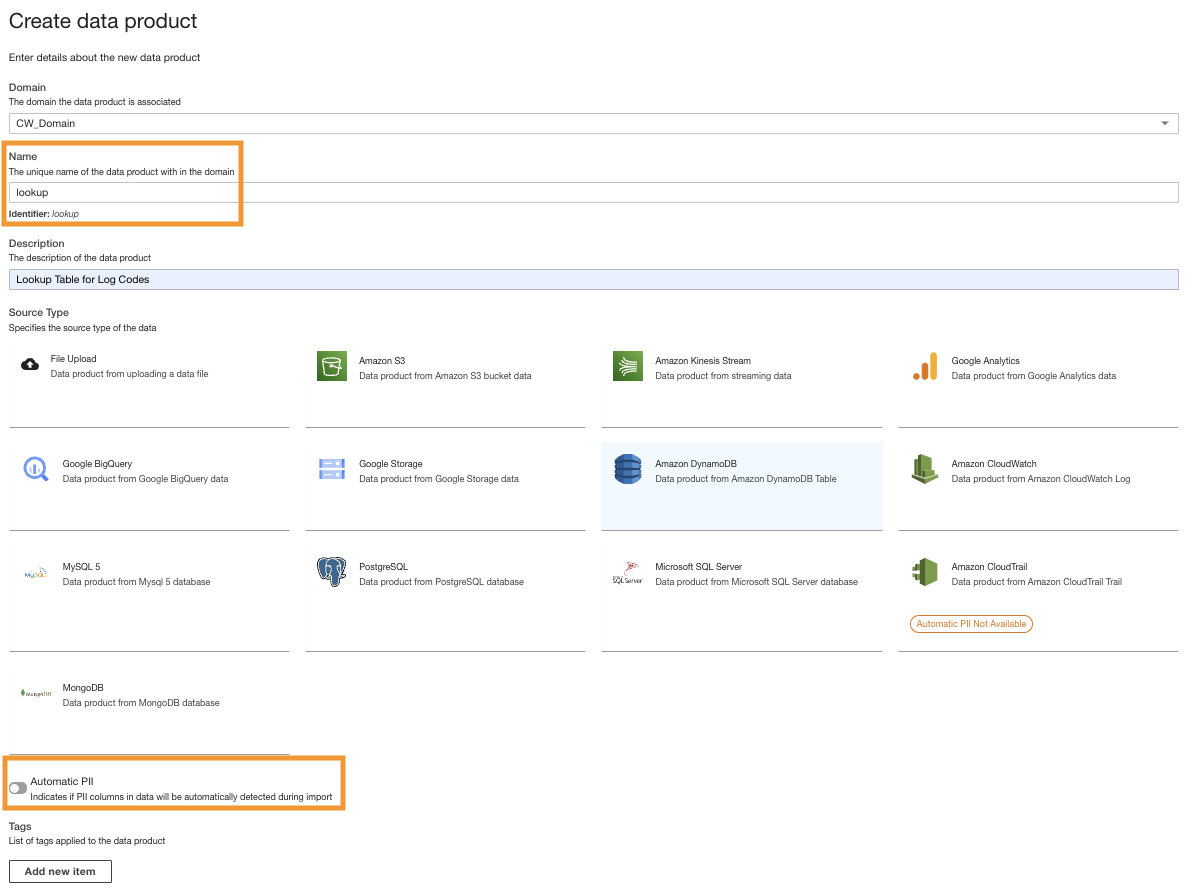
- Introduzir o
Cdk.DynamoDBTablevariável de saída para ARN da tabela DynamoDB.
Esta tabela contém atributos principais que serão usados como tabela de pesquisa nesta demonstração. Para os dados de pesquisa, estamos usando os códigos HTTP e descrições longas e curtas dos códigos. Você também pode usar PostgreSQL, MySQL ou uma fonte de arquivo CSV como alternativa.
- Escolha Gatilho de atualização, selecione Sob demanda.
As atualizações serão sob demanda porque a pesquisa é principalmente para fins de referência durante a consulta e quaisquer atualizações nos dados de pesquisa podem ser atualizadas no ADA usando gatilhos sob demanda.
- Escolha Próximo.
O ADA lê o esquema do esquema subjacente do DynamoDB e apresenta o nome e o tipo da coluna para transformação opcional. Continuaremos com a seleção do esquema padrão porque os tipos de colunas são consistentes com os tipos do grupo de logs do CloudWatch e da fonte de dados CSV do Amazon S3. Ter tipos de dados consistentes em todas as fontes de dados nos permite escrever consultas para buscar registros unindo as tabelas usando os campos de coluna. Por exemplo, a coluna key no esquema do DynamoDB corresponde ao status_code nos produtos de dados Amazon S3 e CloudWatch. Podemos escrever consultas que possam unir as três tabelas usando o nome da coluna key. Um exemplo é mostrado na próxima seção.
- Escolha Continuar com o esquema atual.
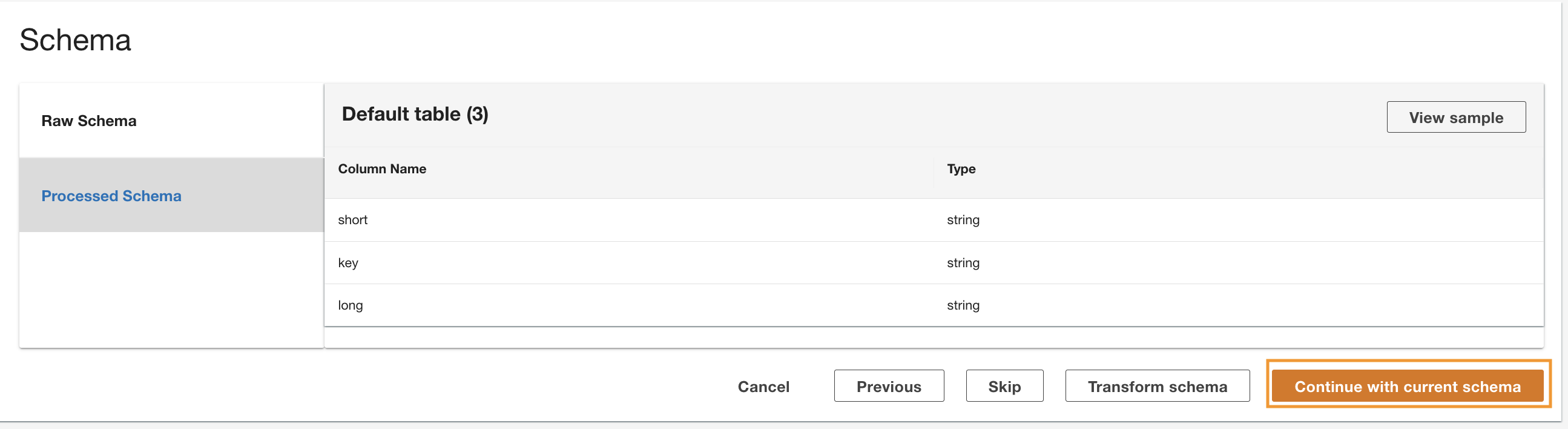
- Revise a configuração e escolha Submeter.
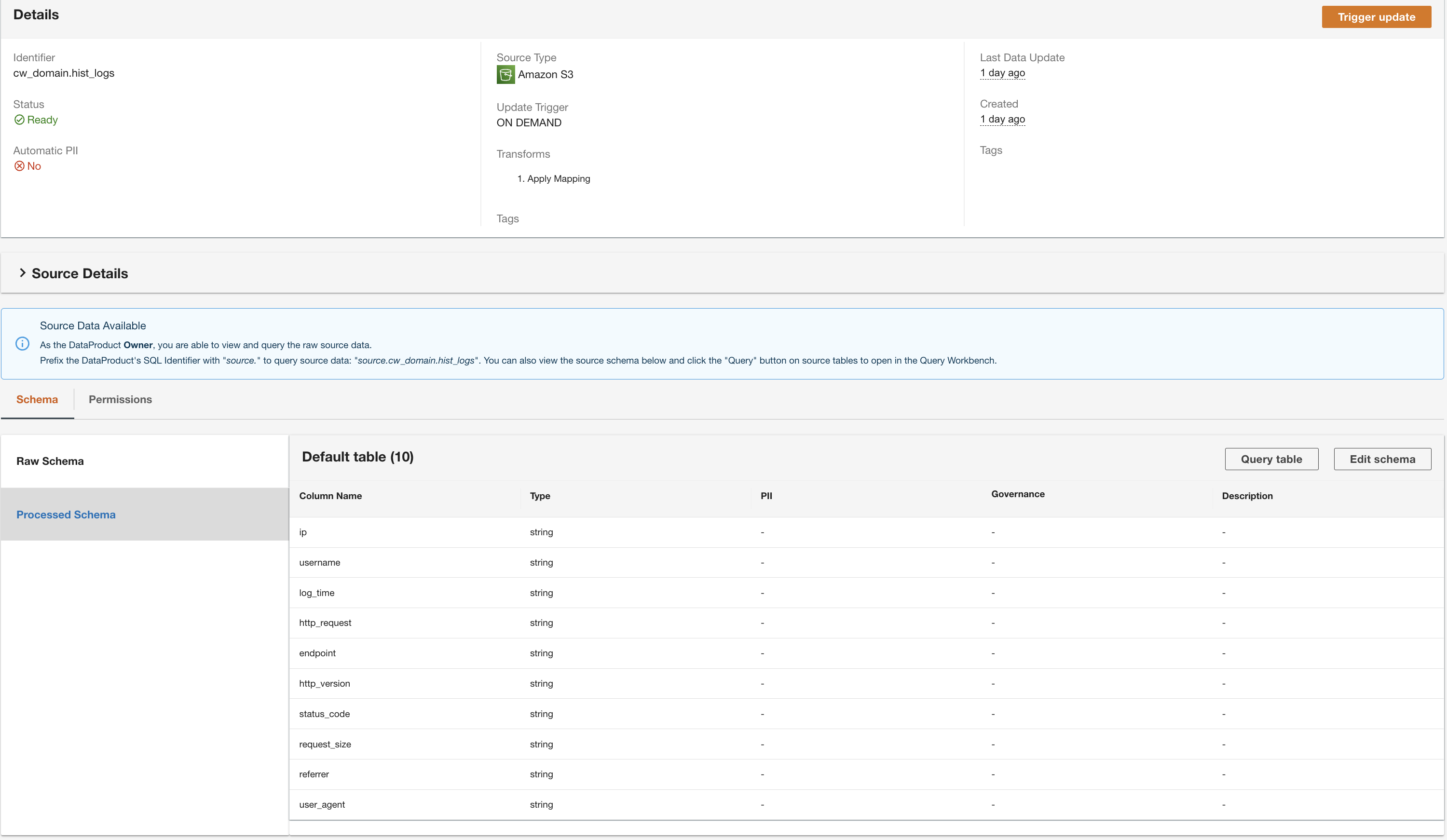
A ADA processará os dados da fonte de dados da tabela DynamoDB e preparará o produto de dados. Dependendo do tamanho dos dados, esse processo leva alguns minutos.
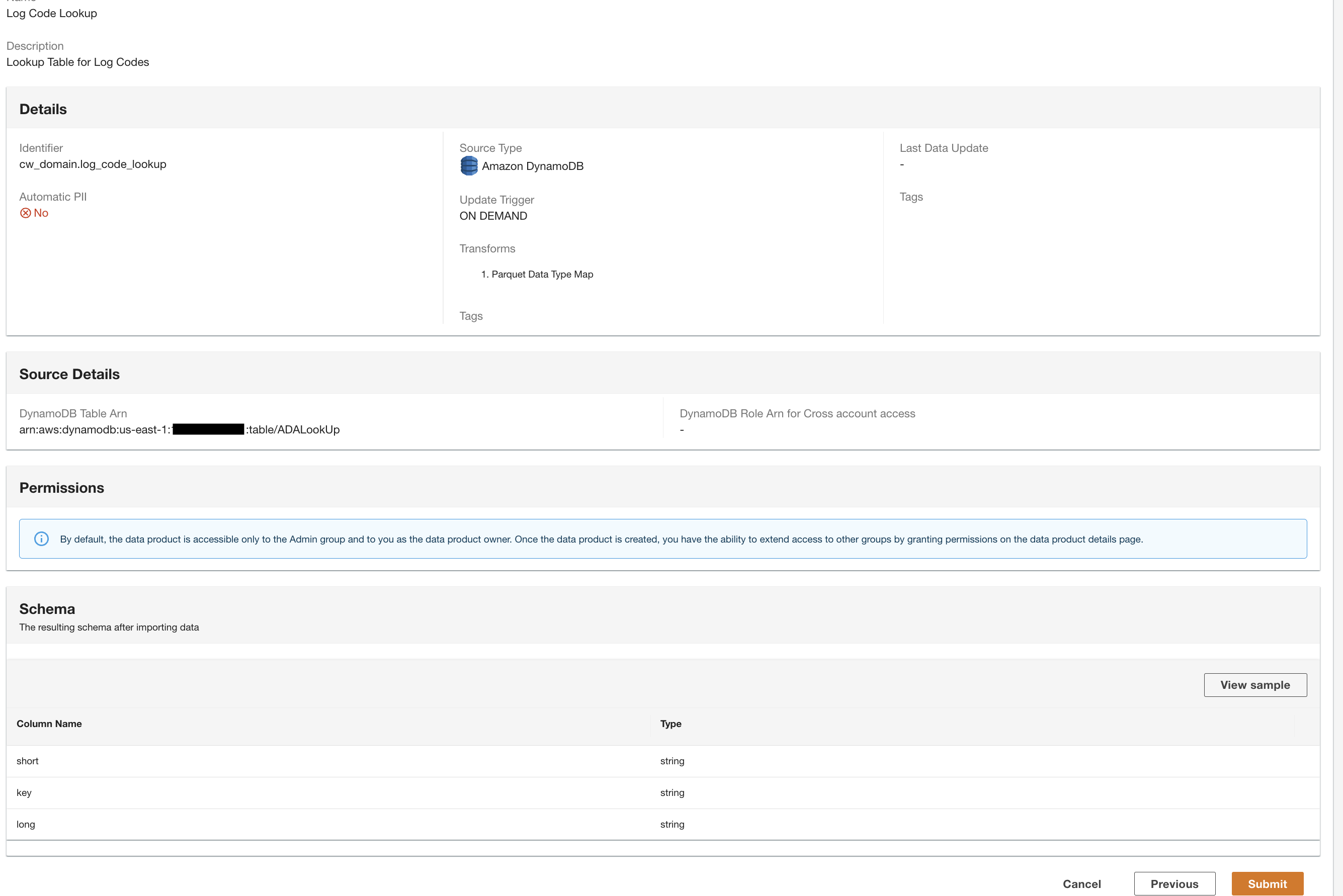
Agora temos todos os três produtos de dados processados pelo ADA e disponíveis para você executar consultas.

Use o Query Workbench para consultar os dados
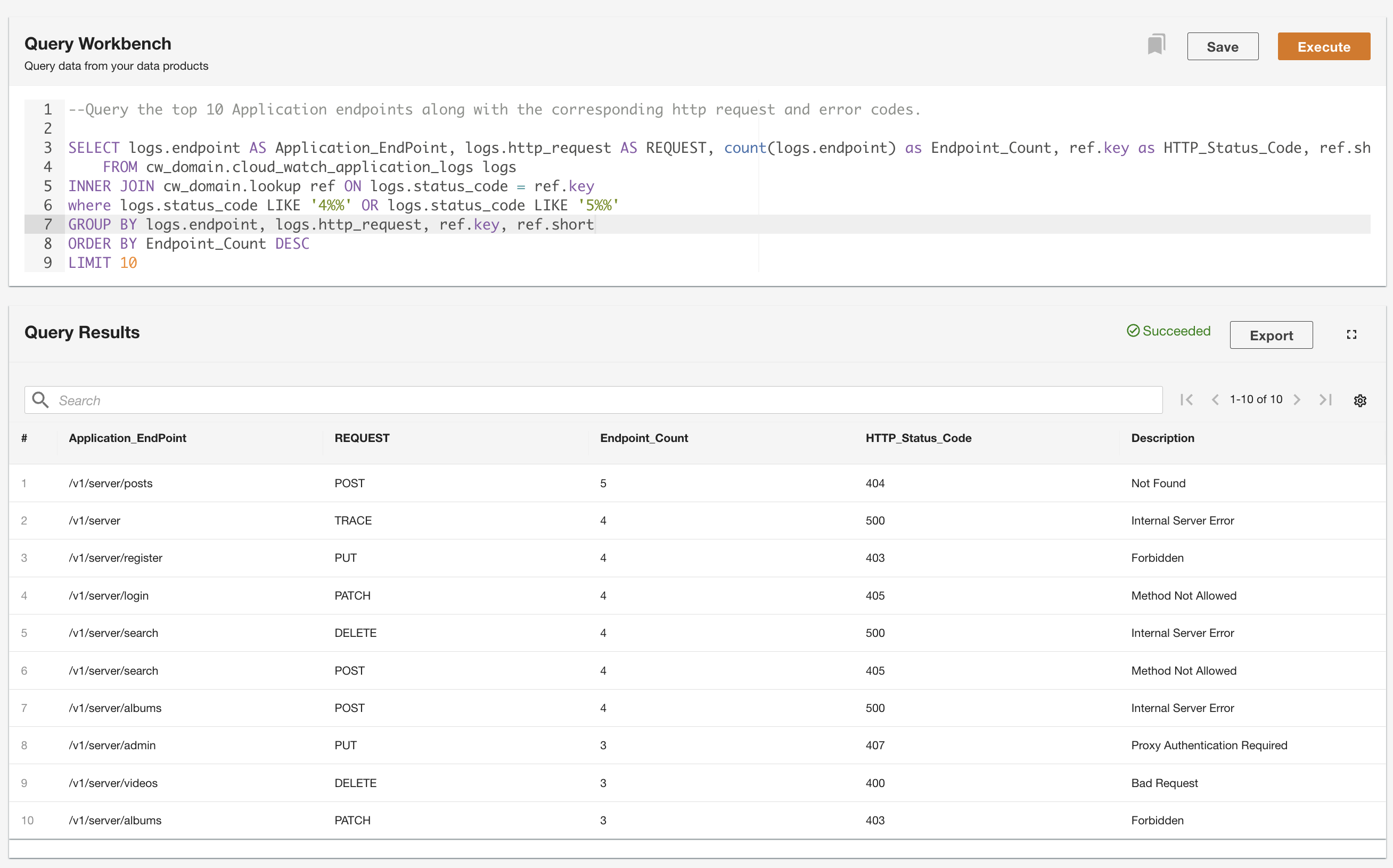
ADA permite que você execute consultas nos produtos de dados enquanto abstrai a fonte de dados e a torna acessível usando SQL (Structured Query Language). Você pode escrever consultas e unir as tabelas da mesma forma que faria consultas em tabelas em um banco de dados relacional. Demonstramos a capacidade de consulta do ADA por meio de dois cenários de usuário. Em ambos os cenários, associamos um conjunto de dados de log do aplicativo à tabela de pesquisa de códigos de erro. No primeiro caso de uso, consultamos os logs atuais do aplicativo para identificar os 10 endpoints de aplicativo mais acessados, juntamente com os códigos de status HTTP correspondentes:
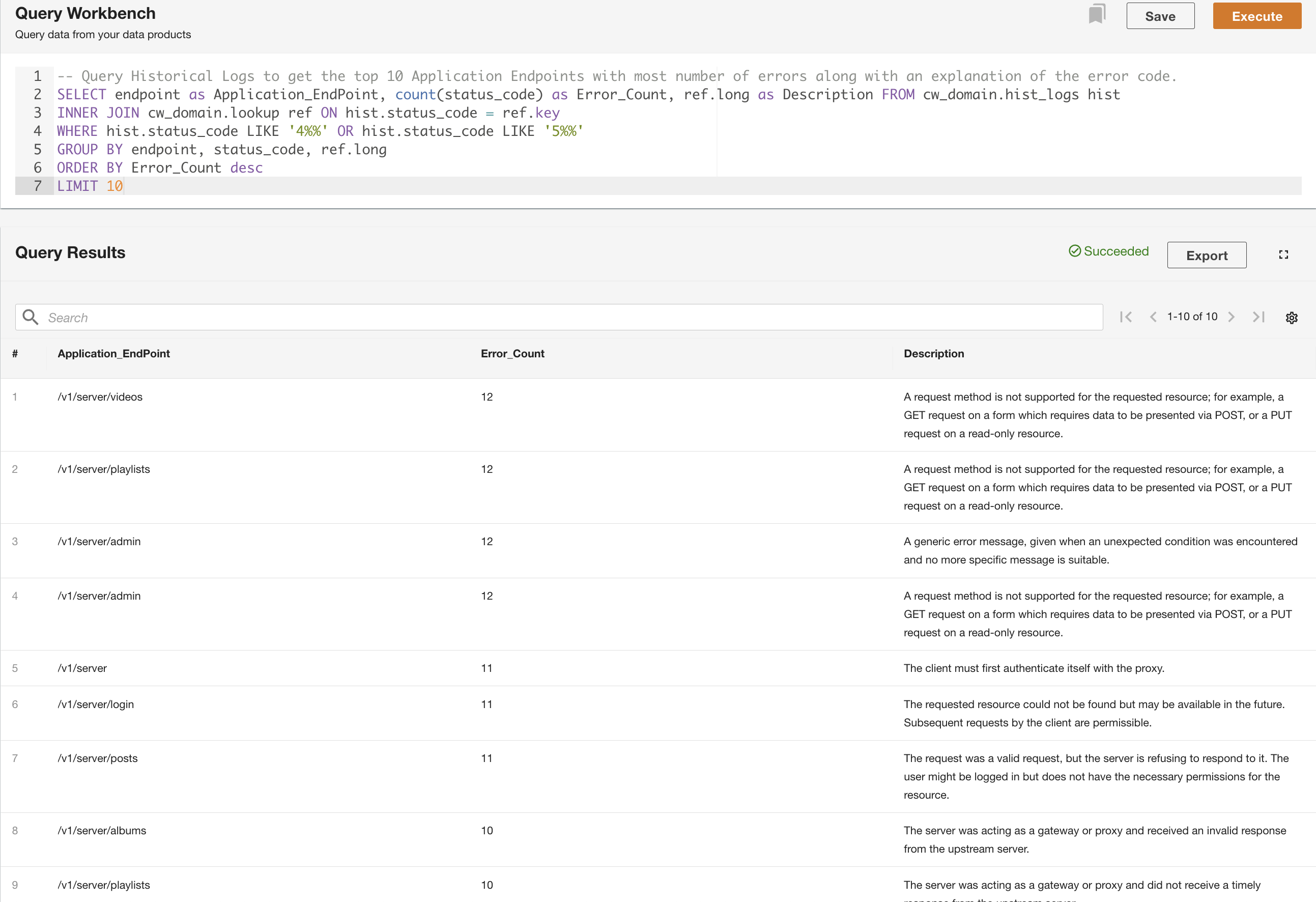
No segundo exemplo, consultamos a tabela de logs históricos para obter os 10 principais endpoints do aplicativo com mais erros para entender o padrão de chamada do endpoint:
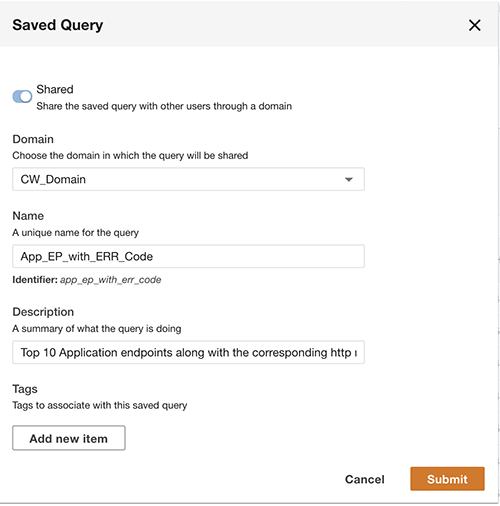
Além de consultar, você pode opcionalmente salvar a consulta e compartilhá-la com outros usuários no mesmo domínio. As consultas compartilhadas podem ser acessadas diretamente no Query Workbench. Os resultados da consulta também podem ser exportados para o formato CSV.
Visualize produtos de dados ADA no Tableau
ADA oferece a capacidade de connect a ferramentas de BI de terceiros para visualizar dados e criar relatórios a partir dos produtos de dados ADA. Nesta demonstração, usamos a integração nativa do ADA com o Tableau para visualizar os dados dos três produtos de dados que configuramos anteriormente. Usando o conector Athena do Tableau e seguindo as etapas em Configuração do Tableau, você poderá configurar o ADA como fonte de dados no Tableau. Depois que uma conexão bem-sucedida for estabelecida entre o Tableau e o ADA, o Tableau preencherá os três produtos de dados no catálogo do Tableau cw_domain.
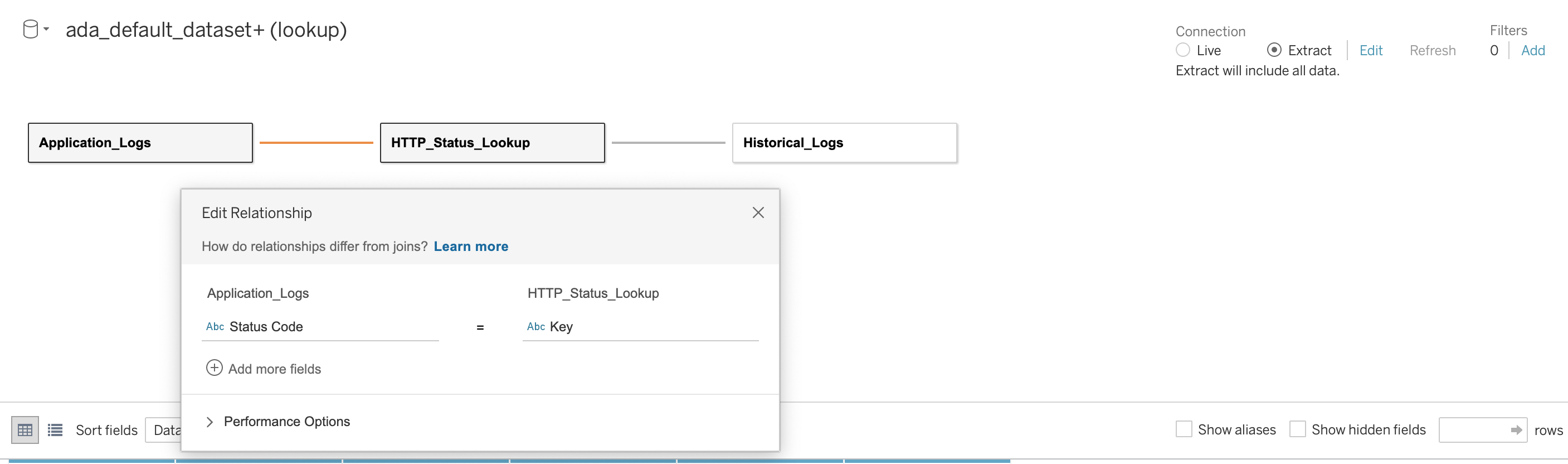
Em seguida, estabelecemos um relacionamento entre os três bancos de dados usando o código de status HTTP como coluna de união, conforme mostrado na captura de tela a seguir. O Tableau nos permite trabalhar online e offline com as fontes de dados. No modo online, o Tableau se conectará ao ADA e consultará os produtos de dados em tempo real. No modo offline, podemos usar o Extrair opção para extrair os dados do ADA e importá-los para o Tableau. Nesta demonstração, importamos os dados para o Tableau para tornar a consulta mais responsiva. Em seguida, salvamos a pasta de trabalho do Tableau. Podemos inspecionar os dados das fontes de dados escolhendo o banco de dados e Actualizar Agora.
Com as configurações de fonte de dados implementadas no Tableau, podemos criar relatórios, gráficos e visualizações personalizados nos produtos de dados ADA. Vamos considerar dois casos de uso para visualizações.
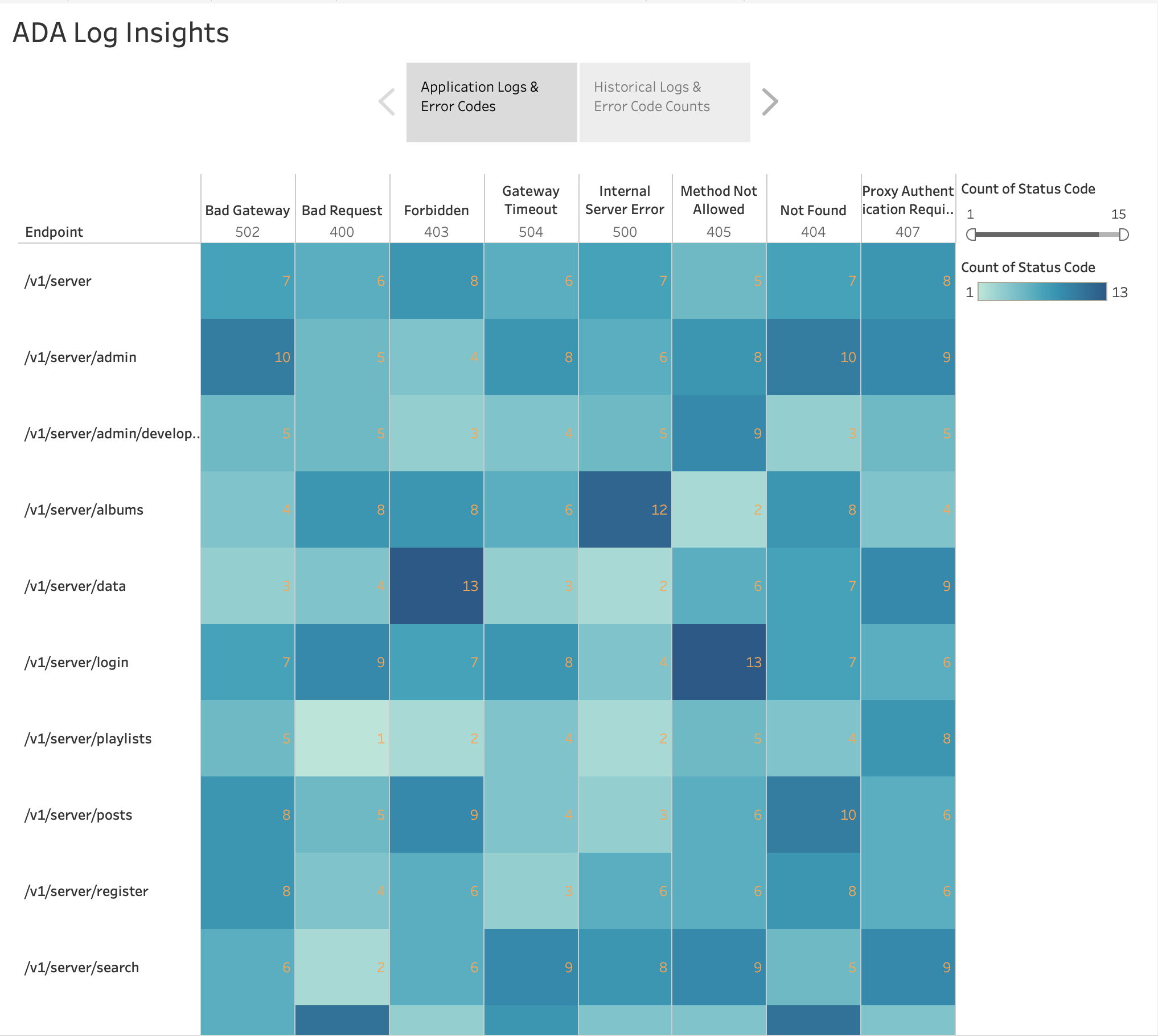
Conforme mostrado na figura a seguir, visualizamos a frequência dos erros HTTP por endpoints do aplicativo usando o recurso integrado do Tableau. mapa de calor gráfico. Filtramos os códigos de status HTTP para incluir apenas códigos de erro no intervalo 4xx e 5xx.
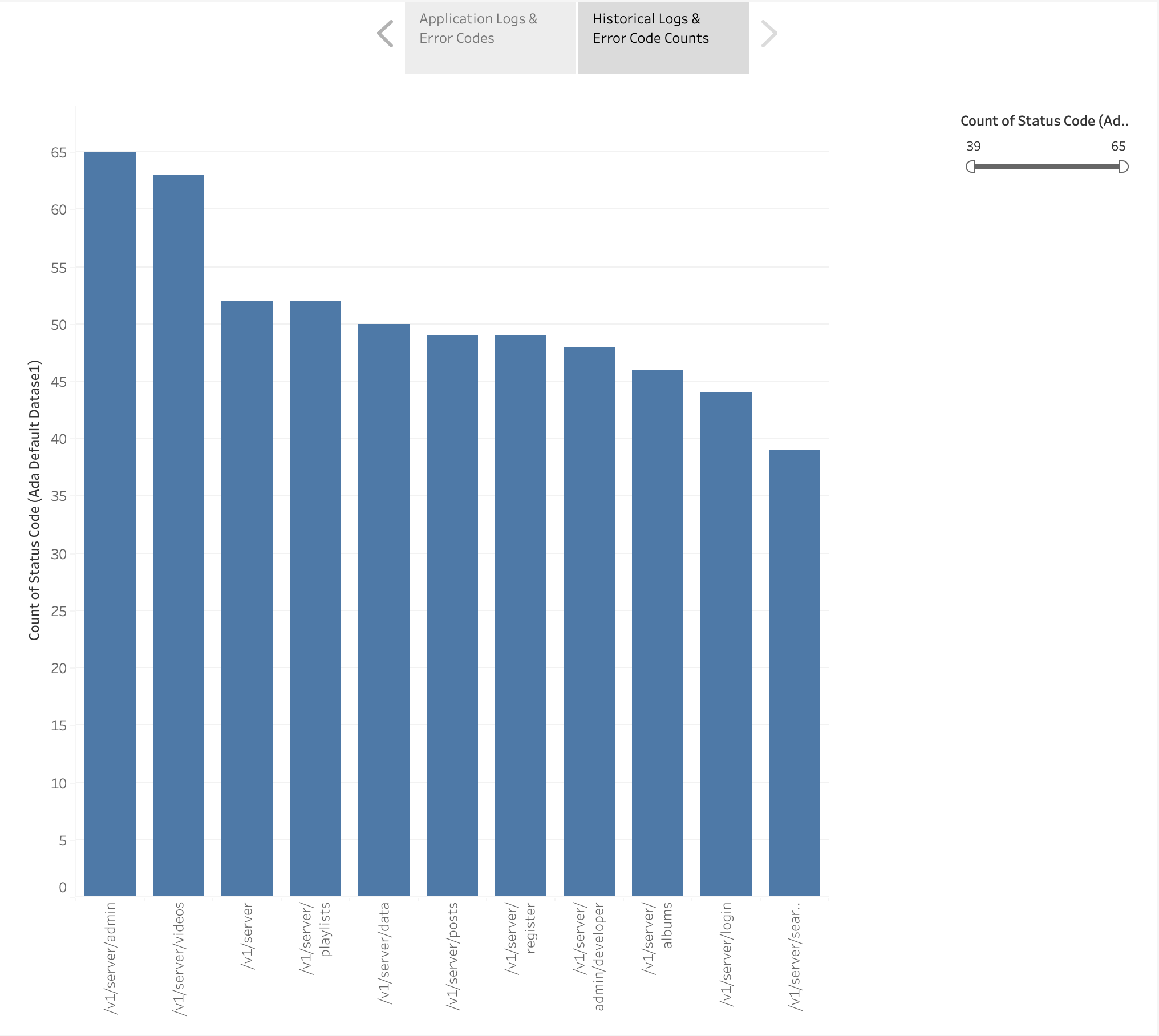
Também criamos um gráfico de barras para representar os endpoints do aplicativo a partir dos logs históricos ordenados pela contagem de códigos de erro HTTP. Neste gráfico, podemos ver que o /v1/server/admin endpoint gerou o maior número de códigos de status de erro HTTP.
limpar
Limpar a infraestrutura do aplicativo de amostra é um processo de duas etapas. Primeiro, para remover a infraestrutura provisionada para esta demonstração, execute o seguinte comando no terminal:
Para a pergunta a seguir, insira y e o AWS CDK excluirá os recursos implantados para a demonstração:
Como alternativa, você pode remover os recursos por meio do console do AWS CloudFormation navegando até a pilha CdkStack e escolhendo Apagar.
A segunda etapa é desinstalar o ADA. Para obter instruções, consulte Desinstale a solução.
Conclusão
Nesta postagem, demonstramos como usar a solução ADA para obter insights de logs de aplicativos armazenados em duas fontes de dados diferentes. Demonstramos como instalar o ADA em uma conta da AWS e implantar os componentes de demonstração usando o AWS CDK. Criamos produtos de dados no ADA e configuramos os produtos de dados com as respectivas fontes de dados usando os conectores de dados integrados do ADA. Demonstramos como consultar os produtos de dados usando consultas SQL padrão e gerar insights sobre os dados de log. Também conectamos o cliente Tableau Desktop, um produto de BI de terceiros, ao ADA e demonstramos como criar visualizações com base nos produtos de dados.
ADA automatiza o processo de ingestão, transformação, controle e consulta de diversos conjuntos de dados e simplifica o gerenciamento do ciclo de vida dos dados. Os conectores pré-construídos do ADA permitem ingerir dados de diversas fontes de dados. As equipes de software com conhecimento básico dos produtos e serviços da AWS serão capazes de configurar uma plataforma operacional de análise de dados em poucas horas e fornecer acesso seguro aos dados. Os dados podem então ser consultados de forma fácil e rápida usando uma interface de usuário da web intuitiva e independente.
Experimente o ADA hoje mesmo para gerenciar e obter insights facilmente dos dados.
Sobre os autores
 Aparajithan Vaidyanathan é Arquiteto Principal de Soluções Corporativas da AWS. Ele oferece suporte a clientes corporativos que migram e modernizam suas cargas de trabalho na nuvem AWS. Ele é um arquiteto de nuvem com mais de 23 anos de experiência projetando e desenvolvendo sistemas de software corporativos, de grande escala e distribuídos. Ele é especialista em aprendizado de máquina e análise de dados com foco no domínio de engenharia de dados e recursos. Ele é um aspirante a corredor de maratona e seus hobbies incluem caminhadas, andar de bicicleta e passar o tempo com sua esposa e dois filhos.
Aparajithan Vaidyanathan é Arquiteto Principal de Soluções Corporativas da AWS. Ele oferece suporte a clientes corporativos que migram e modernizam suas cargas de trabalho na nuvem AWS. Ele é um arquiteto de nuvem com mais de 23 anos de experiência projetando e desenvolvendo sistemas de software corporativos, de grande escala e distribuídos. Ele é especialista em aprendizado de máquina e análise de dados com foco no domínio de engenharia de dados e recursos. Ele é um aspirante a corredor de maratona e seus hobbies incluem caminhadas, andar de bicicleta e passar o tempo com sua esposa e dois filhos.
 Rashim Rahman é desenvolvedor de software baseado em Sydney, Austrália, com mais de 10 anos de experiência em desenvolvimento e arquitetura de software. Ele trabalha principalmente na construção de soluções AWS de código aberto em grande escala para casos de uso comuns de clientes e problemas de negócios. Nas horas vagas gosta de praticar esportes e de estar com amigos e familiares.
Rashim Rahman é desenvolvedor de software baseado em Sydney, Austrália, com mais de 10 anos de experiência em desenvolvimento e arquitetura de software. Ele trabalha principalmente na construção de soluções AWS de código aberto em grande escala para casos de uso comuns de clientes e problemas de negócios. Nas horas vagas gosta de praticar esportes e de estar com amigos e familiares.
 Hafiz Saadullah é gerente técnico principal de produto na Amazon Web Services. Hafiz se concentra em soluções AWS, projetadas para ajudar os clientes resolvendo problemas de negócios e casos de uso comuns.
Hafiz Saadullah é gerente técnico principal de produto na Amazon Web Services. Hafiz se concentra em soluções AWS, projetadas para ajudar os clientes resolvendo problemas de negócios e casos de uso comuns.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- ChartPrime. Eleve seu jogo de negociação com ChartPrime. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :tem
- :é
- :não
- :onde
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- habilidade
- Capaz
- Sobre
- Acesso
- acessadas
- acessível
- Conta
- em
- ações
- ADA
- adicionar
- Adição
- Adicional
- endereçando
- admin
- Depois de
- contra
- Todos os Produtos
- permitir
- permite
- juntamente
- tb
- alternativa
- Amazon
- Amazon Web Services
- entre
- an
- análise
- Analistas
- analítica
- analisar
- e
- Outro
- qualquer
- apache
- api
- APIs
- Aplicação
- aplicações
- aplicado
- Aplicar
- Aplicando
- arquitetura
- SOMOS
- AS
- aspirador
- At
- atributos
- Australia
- Autenticação
- autorizado
- Automatizado
- automatiza
- automaticamente
- disponível
- AWS
- Formação da Nuvem AWS
- em caminho duplo
- Backend
- Barra
- baseado
- basic
- BE
- Porque
- sido
- antes
- bespoke
- entre
- ambos
- Caixa
- construir
- Prédio
- construídas em
- negócio
- inteligência de negócios
- mas a
- by
- chamada
- CAN
- capacidade
- casas
- casos
- catálogo
- CD
- alterar
- de cores
- charts
- Escolha
- escolha
- cliente
- Na nuvem
- código
- códigos
- coleção
- Coluna
- colunas
- comum
- completar
- componentes
- Configuração
- configurado
- Contato
- conectado
- da conexão
- conecta
- Considerar
- consistente
- cônsul
- contém
- continuar
- correlacionados
- Correlação
- Correspondente
- corresponde
- Custo
- crio
- criado
- cria
- Criar
- Credenciais
- Atual
- personalizadas
- cliente
- Clientes
- painel de instrumentos
- dados,
- Análise de Dados
- informática
- banco de dados
- bases de dados
- conjuntos de dados
- Padrão
- Demanda
- Demo
- demonstrar
- demonstraram
- Dependendo
- implantar
- implantado
- desenvolvimento
- implanta
- descrição
- projetado
- concepção
- área de trabalho
- detalhado
- detalhes
- Developer
- em desenvolvimento
- Desenvolvimento
- diagnóstico
- diferente
- diretamente
- inválido
- descoberta
- Ecrã
- distribuído
- diferente
- Não faz
- domínio
- domínios
- não
- desistiu
- durante
- cada
- Mais cedo
- facilmente
- edição
- ou
- habilitado
- permite
- Ponto final
- endpoints
- Engenharia
- garantir
- Entrar
- Empreendimento
- clientes corporativos
- Soluções Empresariais
- erro
- erros
- estabelecer
- estabelecido
- Éter (ETH)
- exemplo
- existente
- vasta experiência
- Explicação
- explicação
- extrato
- extrair os dados
- familiar
- família
- Característica
- poucos
- campo
- Campos
- Figura
- Envie o
- Arquivos
- final
- financiar
- Primeiro nome
- flexível
- Foco
- concentra-se
- seguinte
- Escolha
- formato
- quatro
- Frequência
- amigos
- da
- função
- Ganho
- gerar
- gerado
- ter
- obtendo
- governando
- Grupo
- Do grupo
- Ter
- ter
- he
- ajudar
- Destaque
- caminhadas
- sua
- histórico
- Hobbies
- hospedado
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- IAM
- idêntico
- identificar
- Identidade
- if
- importar
- in
- incluir
- inclui
- Incluindo
- INFORMAÇÕES
- Infraestrutura
- do estado inicial,
- insights
- instalar
- instalação
- instruções
- integrado
- integração
- Inteligência
- interativo
- interessado
- Interface
- para dentro
- intuitivo
- invoca
- envolvido
- emitem
- IT
- juntar
- juntando
- Junta
- jpg
- json
- apenas por
- Guarda
- Chave
- Conhecimento
- língua
- grande
- em grande escala
- Sobrenome
- mais tarde
- de lançamento
- aprendizagem
- Biblioteca
- Licenciado
- wifecycwe
- como
- LIMITE
- Line
- Lista
- viver
- log
- logging
- longo
- olhar
- pesquisa
- máquina
- aprendizado de máquina
- fazer
- Fazendo
- gerencia
- de grupos
- Gerente
- muitos
- mapa,
- mapeamento
- Maratona
- Marketing
- Importância
- significativo
- mensagem
- MFA
- poder
- migrado
- minutos
- Moda
- modernizar
- mais
- a maioria
- na maioria das vezes
- Mozilla
- Autenticação multifatorial
- MySQL
- nome
- Nomeado
- nomes
- nativo
- Navegar
- navegação
- Navegação
- você merece...
- necessário
- Cria
- Novo
- recentemente
- Próximo
- número
- of
- Oferece
- modo offline
- Velho
- on
- Sob demanda
- ONE
- online
- só
- aberto
- open source
- operacional
- Opção
- or
- ordem
- Outros
- Outros
- Fora
- saída
- Visão geral
- página
- pão
- Senha
- caminho
- padrão
- realizar
- permissões
- Pessoalmente
- telefone
- Pii
- oleoduto
- Lugar
- Avião
- plano
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- políticas
- Portal
- Publique
- Postgresql
- alimentado
- Preparar
- Prepara
- pré-requisitos
- presente
- presentes
- visualização
- anterior
- principalmente
- Diretor
- Prévio
- problemas
- prosseguir
- processo
- processado
- processos
- em processamento
- Produzido
- Produto
- gerente de produto
- Produtos
- Produtos e Serviços
- Programas
- projeto
- fornecer
- fornecido
- provedor
- fornece
- propósito
- fins
- Python
- consultas
- questão
- rapidamente
- alcance
- Leia
- pronto
- receber
- registros
- a que se refere
- região
- relacionamento
- relevante
- remover
- repetir
- Relatórios
- solicitar
- requeridos
- Recursos
- aqueles
- responsivo
- Resultados
- reter
- rever
- equitação
- papéis
- raiz
- Regra
- Execute
- corredor
- corrida
- vendas
- mesmo
- Salvar
- Escala
- cenários
- programado
- escopo
- Pesquisar
- Segundo
- Seção
- seguro
- segurança
- Vejo
- selecionado
- doadores,
- enviar
- enviei
- separado
- servir
- Serverless
- serviço
- Serviços
- conjunto
- contexto
- Partilhar
- compartilhado
- Baixo
- mostrando
- Shows
- simples
- simplificada
- simplificando
- Tamanho
- Habilidades
- So
- Software
- desenvolvimento de software
- solução
- Soluções
- fonte
- Fontes
- especialista
- especializada
- específico
- especificada
- Passar
- Esportes
- SQL
- pilha
- autônoma
- padrão
- começo
- começa
- Status
- Passo
- Passos
- armazenamento
- armazenadas
- Tanga
- estruturada
- bem sucedido
- entraram com sucesso
- tal
- suportes
- certo
- sydney
- sistemas
- mesa
- Quadro
- Tire
- toma
- Profissionais
- equipes
- Dados Técnicos:
- habilidades técnicas
- terminal
- que
- A
- A fonte
- deles
- então
- Lá.
- Este
- De terceiros
- isto
- três
- Através da
- tempo
- para
- hoje
- ferramentas
- topo
- 10 topo
- Total
- Transformar
- Transformação
- transformações
- transformado
- transformando
- transformações
- desencadeado
- dois
- tipo
- tipos
- para
- subjacente
- compreender
- Atualizada
- Atualizações
- sobre
- URI
- us
- usar
- caso de uso
- usava
- Utilizador
- Interface de Usuário
- usuários
- utilização
- Valores
- variável
- variedade
- versão
- via
- Ver
- queremos
- Caminho..
- we
- web
- serviços web
- BEM
- quando
- qual
- enquanto
- Largo
- Ampla variedade
- mulher
- precisarão
- de
- dentro
- sem
- Atividades:
- de gestão de documentos
- trabalho
- seria
- escrever
- anos
- Você
- investimentos
- zefirnet