Esta é uma postagem conjunta co-escrita por AWS e Voxel51. A Voxel51 é a empresa por trás do FiftyOne, o kit de ferramentas de código aberto para criar conjuntos de dados de alta qualidade e modelos de visão computacional.
Uma empresa de varejo está desenvolvendo um aplicativo móvel para ajudar os clientes a comprar roupas. Para criar este aplicativo, eles precisam de um conjunto de dados de alta qualidade contendo imagens de roupas, rotuladas com diferentes categorias. Nesta postagem, mostramos como redirecionar um conjunto de dados existente por meio de limpeza, pré-processamento e pré-rotulagem de dados com um modelo de classificação zero-shot em Cinquenta e um, e ajustando esses rótulos com Verdade no solo do Amazon SageMaker.
Você pode usar o Ground Truth e o FiftyOne para acelerar seu projeto de rotulagem de dados. Ilustramos como usar perfeitamente os dois aplicativos juntos para criar conjuntos de dados rotulados de alta qualidade. Para nosso exemplo de caso de uso, trabalhamos com o Conjunto de dados Fashion200K, lançado no ICCV 2017.
Visão geral da solução
O Ground Truth é um serviço de rotulagem de dados totalmente autoatendido e gerenciado que capacita cientistas de dados, engenheiros de aprendizado de máquina (ML) e pesquisadores a criar conjuntos de dados de alta qualidade. Cinquenta e um by voxel51 é um kit de ferramentas de código aberto para curadoria, visualização e avaliação de conjuntos de dados de visão computacional para que você possa treinar e analisar melhores modelos acelerando seus casos de uso.
Nas seções a seguir, demonstramos como fazer o seguinte:
- Visualize o conjunto de dados no FiftyOne
- Limpe o conjunto de dados com filtragem e desduplicação de imagens no FiftyOne
- Pré-etiquete os dados limpos com classificação zero-shot no FiftyOne
- Rotule o conjunto de dados com curadoria menor com o Ground Truth
- Injete resultados rotulados do Ground Truth no FiftyOne e revise os resultados rotulados no FiftyOne
Visão geral do caso de uso
Suponha que você possua uma empresa de varejo e queira criar um aplicativo móvel para dar recomendações personalizadas para ajudar os usuários a decidir o que vestir. Seus usuários em potencial estão procurando um aplicativo que diga a eles quais peças de roupa em seu armário funcionam bem juntas. Você vê uma oportunidade aqui: se conseguir identificar boas roupas, pode usar isso para recomendar novas peças de roupa que complementem as roupas que um cliente já possui.
Você quer tornar as coisas o mais fácil possível para o usuário final. Idealmente, alguém que usa seu aplicativo precisa apenas tirar fotos das roupas em seu guarda-roupa, e seus modelos de ML fazem sua mágica nos bastidores. Você pode treinar um modelo de uso geral ou ajustar um modelo para o estilo exclusivo de cada usuário com alguma forma de feedback.
Primeiro, porém, você precisa identificar que tipo de roupa o usuário está capturando. É uma camisa? Um par de calças? Ou alguma outra coisa? Afinal, você provavelmente não quer recomendar uma roupa que tenha vários vestidos ou vários chapéus.
Para enfrentar esse desafio inicial, você deseja gerar um conjunto de dados de treinamento que consiste em imagens de vários artigos de vestuário com vários padrões e estilos. Para prototipar com um orçamento limitado, você deseja inicializar usando um conjunto de dados existente.
Para ilustrar e orientá-lo no processo desta postagem, usamos o conjunto de dados Fashion200K lançado no ICCV 2017. É um conjunto de dados estabelecido e bem citado, mas não é adequado diretamente para o seu caso de uso.
Embora os artigos de vestuário sejam rotulados com categorias (e subcategorias) e contenham uma variedade de tags úteis extraídas das descrições originais do produto, os dados não são sistematicamente rotulados com informações de padrão ou estilo. Seu objetivo é transformar esse conjunto de dados existente em um conjunto de dados de treinamento robusto para seus modelos de classificação de roupas. Você precisa limpar os dados, aumentando o esquema de rotulagem com rótulos de estilo. E você quer fazer isso rapidamente e gastando o mínimo possível.
Baixe os dados localmente
Primeiro, baixe o arquivo zip women.tar e a pasta labels (com todas as suas subpastas) seguindo as instruções fornecidas no Repositório GitHub do conjunto de dados Fashion200K. Depois de descompactar os dois, crie um diretório pai fashion200k e mova as pastas labels e women para ele. Felizmente, essas imagens já foram cortadas nas caixas delimitadoras de detecção de objetos, para que possamos nos concentrar na classificação, em vez de nos preocuparmos com a detecção de objetos.
Apesar do “200K” em seu apelido, o diretório de mulheres que extraímos contém 338,339 imagens. Para gerar o conjunto de dados oficial Fashion200K, os autores do conjunto de dados rastrearam mais de 300,000 produtos online e apenas produtos com descrições contendo mais de quatro palavras foram incluídos. Para nossos propósitos, onde a descrição do produto não é essencial, podemos usar todas as imagens rastreadas.
Vejamos como esses dados são organizados: dentro da pasta mulheres, as imagens são organizadas por tipo de artigo de nível superior (saias, tops, calças, jaquetas e vestidos) e subcategoria de tipo de artigo (blusas, camisetas, mangas compridas topos).
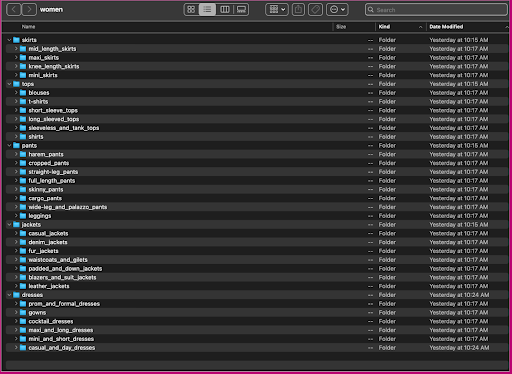
Nos diretórios de subcategorias, há um subdiretório para cada lista de produtos. Cada um deles contém um número variável de imagens. A subcategoria cropped_pants, por exemplo, contém as seguintes listas de produtos e imagens associadas.
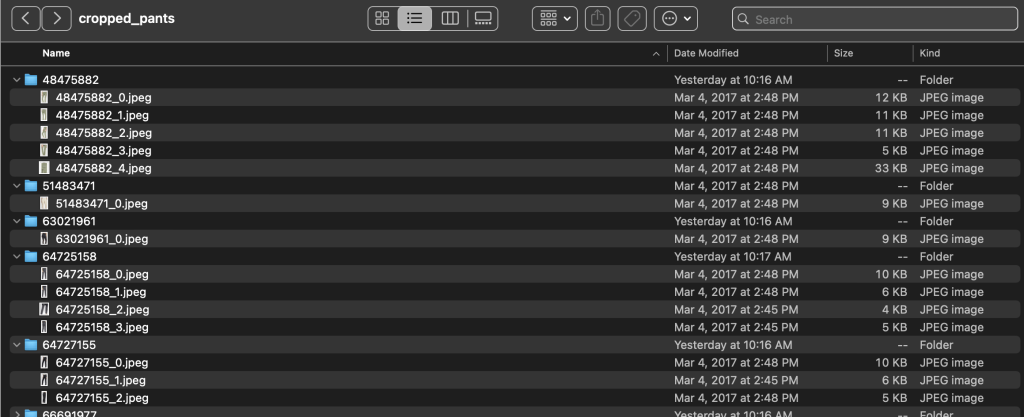
A pasta de rótulos contém um arquivo de texto para cada tipo de artigo de nível superior, para as divisões de treinamento e teste. Dentro de cada um desses arquivos de texto há uma linha separada para cada imagem, especificando o caminho relativo do arquivo, uma pontuação e tags da descrição do produto.
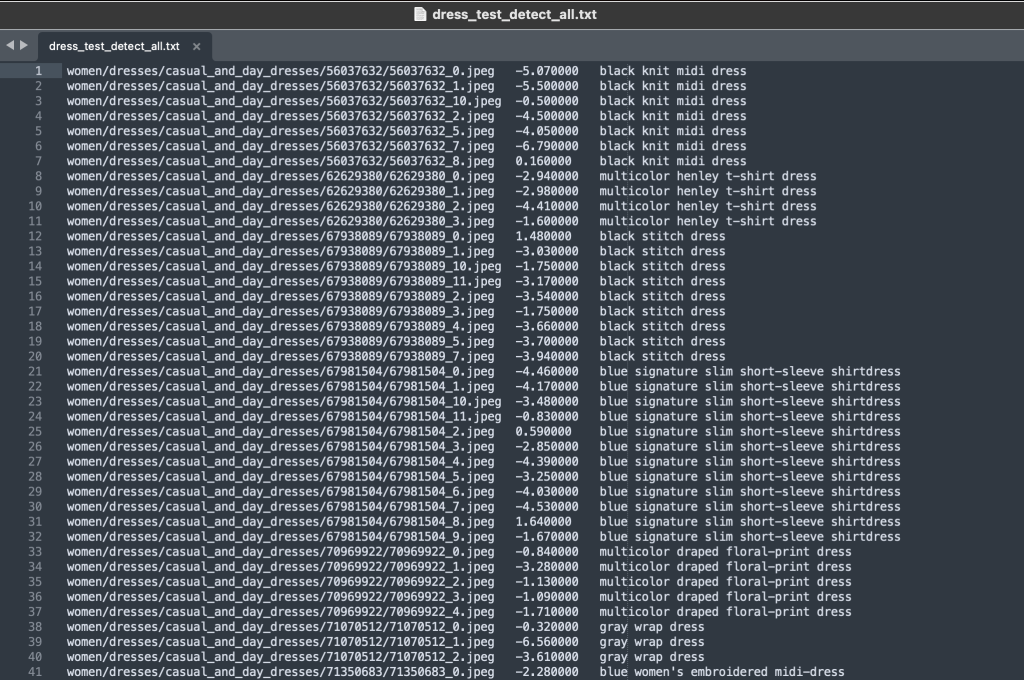
Como estamos redefinindo o objetivo do conjunto de dados, combinamos todas as imagens de treinamento e teste. Nós os usamos para gerar um conjunto de dados específico do aplicativo de alta qualidade. Depois de concluir esse processo, podemos dividir aleatoriamente o conjunto de dados resultante em novas divisões de treinamento e teste.
Injete, visualize e organize um conjunto de dados no FiftyOne
Se ainda não o fez, instale o FiftyOne de código aberto usando o pip:
Uma prática recomendada é fazer isso em um novo ambiente virtual (venv ou conda). Em seguida, importe os módulos relevantes. Importe a biblioteca base, cinquenta e um, o FiftyOne Brain, que possui métodos de ML integrados, o FiftyOne Zoo, do qual carregaremos um modelo que gerará rótulos zero-shot para nós, e o ViewField, que nos permite filtrar com eficiência os dados em nosso conjunto de dados:
Você também deseja importar os módulos glob e os Python, que nos ajudarão a trabalhar com caminhos e correspondência de padrão sobre o conteúdo do diretório:
Agora estamos prontos para carregar o conjunto de dados no FiftyOne. Primeiro, criamos um conjunto de dados chamado fashion200k e o tornamos persistente, o que nos permite salvar os resultados de operações computacionalmente intensivas, portanto, precisamos calcular essas quantidades apenas uma vez.
Agora podemos percorrer todos os diretórios de subcategorias, adicionando todas as imagens nos diretórios de produtos. Adicionamos um rótulo de classificação FiftyOne a cada amostra com o nome de campo article_type, preenchido pela categoria de artigo de nível superior da imagem. Também adicionamos informações de categoria e subcategoria como tags:
Neste ponto, podemos visualizar nosso conjunto de dados no aplicativo FiftyOne iniciando uma sessão:
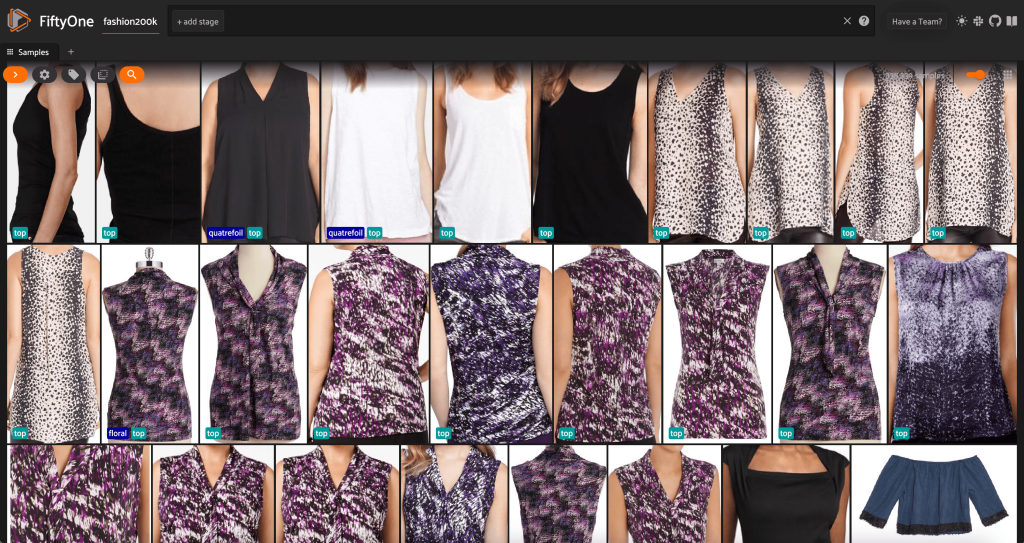
Também podemos imprimir um resumo do conjunto de dados em Python executando print(dataset):
Também podemos adicionar as tags do labels diretório para as amostras em nosso conjunto de dados:
Olhando para os dados, algumas coisas ficam claras:
- Algumas das imagens são bastante granuladas, com baixa resolução. Isso provavelmente ocorre porque essas imagens foram geradas cortando imagens iniciais em caixas delimitadoras de detecção de objetos.
- Algumas roupas são usadas por uma pessoa e outras são fotografadas por conta própria. Esses detalhes são encapsulados pelo
viewpointpropriedade. - Muitas imagens do mesmo produto são muito semelhantes, portanto, pelo menos inicialmente, incluir mais de uma imagem por produto pode não adicionar muito poder preditivo. Na maioria das vezes, a primeira imagem de cada produto (terminando em
_0.jpeg) é o mais limpo.
Inicialmente, podemos querer treinar nosso modelo de classificação de estilo de roupa em um subconjunto controlado dessas imagens. Para isso, usamos imagens de alta resolução de nossos produtos e limitamos nossa visão a uma amostra representativa por produto.
Primeiro, filtramos as imagens de baixa resolução. Nós usamos o compute_metadata() método para calcular e armazenar a largura e a altura da imagem, em pixels, para cada imagem no conjunto de dados. Em seguida, empregamos o FiftyOne ViewField para filtrar imagens com base nos valores mínimos permitidos de largura e altura. Veja o seguinte código:
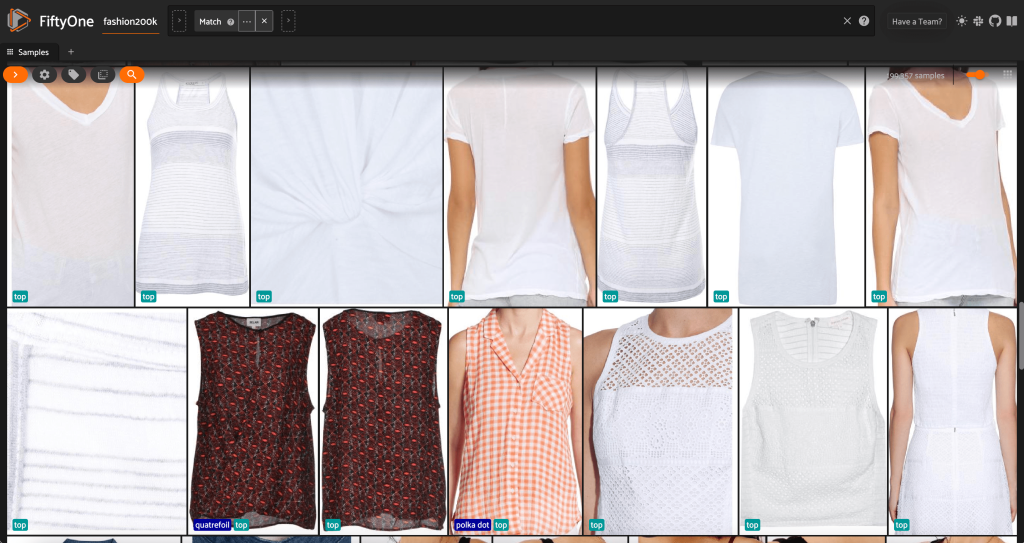
Este subconjunto de alta resolução tem pouco menos de 200,000 amostras.
A partir dessa visualização, podemos criar uma nova visualização em nosso conjunto de dados contendo apenas uma amostra representativa (no máximo) para cada produto. Nós usamos o ViewField mais uma vez, correspondência de padrões para caminhos de arquivo que terminam com _0.jpeg:
Vamos ver uma ordem aleatoriamente embaralhada de imagens neste subconjunto:
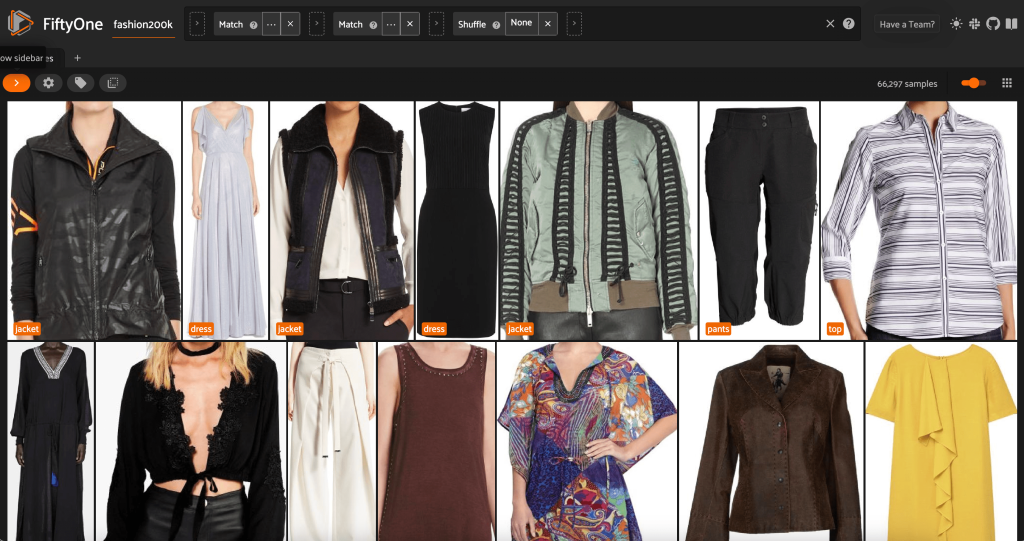
Remova imagens redundantes no conjunto de dados
Esta visualização contém 66,297 imagens, ou pouco mais de 19% do conjunto de dados original. Quando olhamos para a vista, no entanto, vemos que existem muitos produtos muito semelhantes. Manter todas essas cópias provavelmente apenas aumentará o custo de nossa rotulagem e treinamento de modelo, sem melhorar significativamente o desempenho. Em vez disso, vamos nos livrar das quase duplicatas para criar um conjunto de dados menor que ainda tenha o mesmo impacto.
Como essas imagens não são duplicatas exatas, não podemos verificar a igualdade em pixels. Felizmente, podemos usar o FiftyOne Brain para nos ajudar a limpar nosso conjunto de dados. Em particular, calcularemos uma incorporação para cada imagem — um vetor de menor dimensão que representa a imagem — e, em seguida, procuraremos imagens cujos vetores de incorporação estejam próximos uns dos outros. Quanto mais próximos os vetores, mais semelhantes as imagens.
Usamos um modelo CLIP para gerar um vetor de incorporação de 512 dimensões para cada imagem e armazenamos essas incorporações no campo incorporações nas amostras em nosso conjunto de dados:
Em seguida, calculamos a proximidade entre os embeddings, usando similaridade de cosseno, e afirme que quaisquer dois vetores cuja similaridade é maior do que algum limite provavelmente serão quase duplicados. As pontuações de similaridade de cosseno estão no intervalo [0, 1] e, olhando para os dados, uma pontuação limite de thresh = 0.5 parece estar certa. Novamente, isso não precisa ser perfeito. Algumas imagens quase duplicadas provavelmente não arruinarão nosso poder preditivo, e descartar algumas imagens não duplicadas não afeta materialmente o desempenho do modelo.
Podemos visualizar as supostas duplicatas para verificar se elas são realmente redundantes:
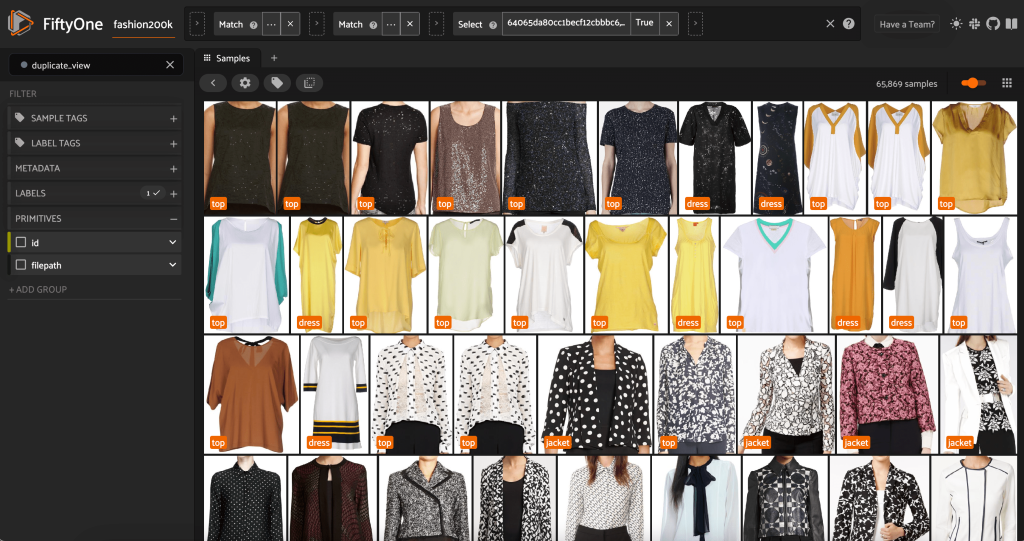
Quando estivermos satisfeitos com o resultado e acreditarmos que essas imagens estão quase duplicadas, podemos escolher uma amostra de cada conjunto de amostras semelhantes para manter e ignorar as outras:
Agora, esta exibição tem 3,729 imagens. Ao limpar os dados e identificar um subconjunto de alta qualidade do conjunto de dados Fashion200K, o FiftyOne nos permite restringir nosso foco de mais de 300,000 imagens para pouco menos de 4,000, representando uma redução de 98%. O uso de incorporações apenas para remover imagens quase duplicadas reduziu nosso número total de imagens em consideração em mais de 90%, com pouco ou nenhum efeito em quaisquer modelos a serem treinados nesses dados.
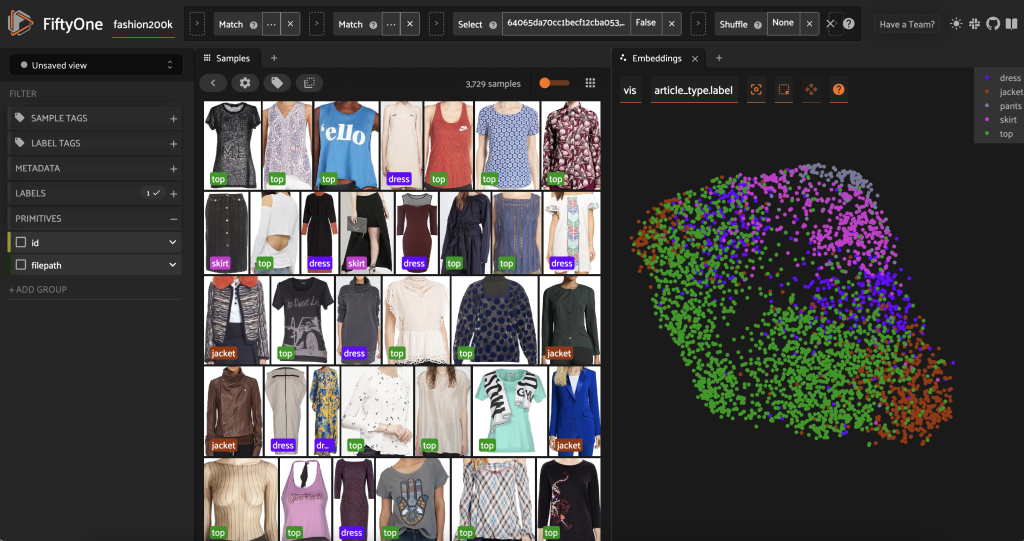
Antes de pré-rotular esse subconjunto, podemos entender melhor os dados visualizando os embeddings que já calculamos. Podemos usar a função integrada do FiftyOne Brain compute_visualization(), que emprega a técnica de aproximação de distribuição uniforme (UMAP) para projetar os vetores de incorporação de 512 dimensões no espaço bidimensional para que possamos visualizá-los:
Abrimos um novo Painel de incorporações no aplicativo FiftyOne e colorir por tipo de artigo, e podemos ver que essas incorporações codificam aproximadamente uma noção de tipo de artigo (entre outras coisas!).
Agora estamos prontos para pré-rotular esses dados.
Ao inspecionar essas imagens altamente exclusivas e de alta resolução, podemos gerar uma lista inicial decente de estilos para usar como classes em nossa classificação zero-shot pré-rotulagem. Nosso objetivo ao pré-rotular essas imagens não é necessariamente rotular cada imagem corretamente. Em vez disso, nosso objetivo é fornecer um bom ponto de partida para anotadores humanos, para que possamos reduzir o tempo e o custo de rotulagem.
Podemos então instanciar um modelo de classificação zero-shot para esta aplicação. Usamos um modelo CLIP, que é um modelo de uso geral treinado em imagens e linguagem natural. Instanciamos um modelo CLIP com o prompt de texto “Roupas no estilo”, para que, dada uma imagem, o modelo gere a classe para a qual “Roupas no estilo [classe]” é o mais adequado. O CLIP não é treinado em dados específicos de varejo ou moda, portanto, isso não será perfeito, mas pode economizar em custos de rotulagem e anotação.
Em seguida, aplicamos esse modelo ao nosso subconjunto reduzido e armazenamos os resultados em um article_style campo:
Iniciando o aplicativo FiftyOne mais uma vez, podemos visualizar as imagens com esses rótulos de estilo previsto. Classificamos por confiança de previsão para visualizarmos primeiro as previsões de estilo mais confiáveis:
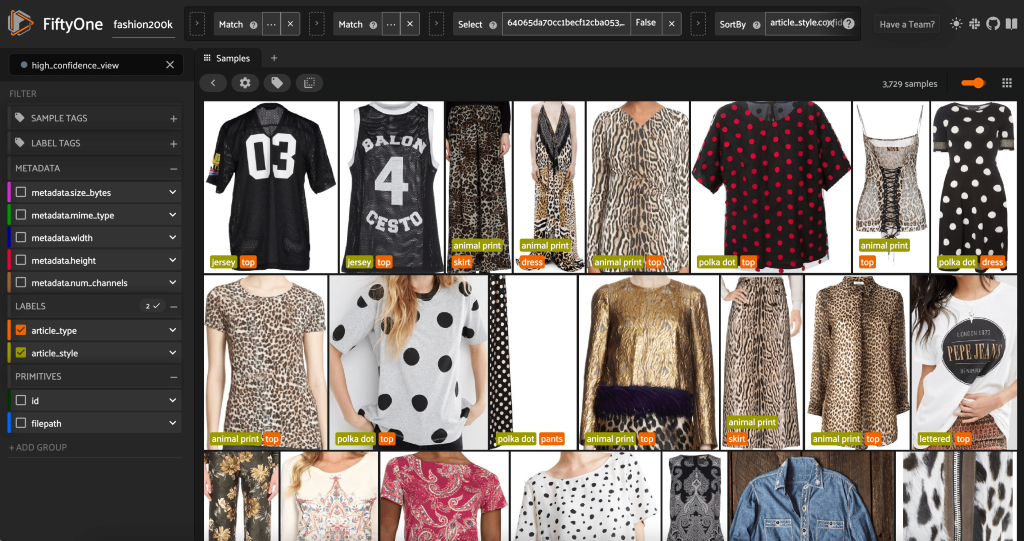
Podemos ver que as previsões de confiança mais altas parecem ser para os estilos “jersey”, “animal print”, “polka dot” e “lettered”. Isso faz sentido, porque esses estilos são relativamente distintos. Também parece que, na maioria das vezes, os rótulos de estilo previstos são precisos.
Também podemos observar as previsões de estilo de confiança mais baixa:
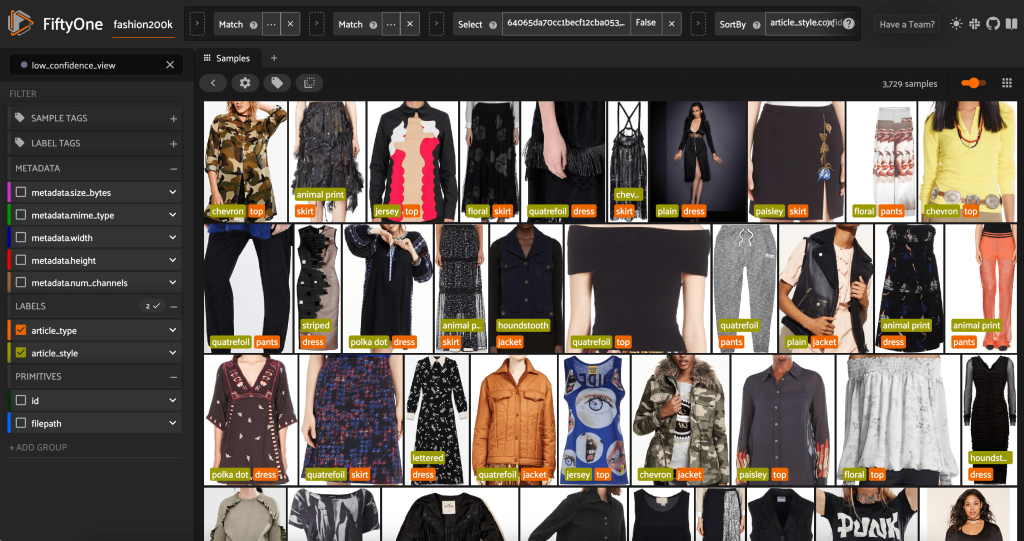
Para algumas dessas imagens, a categoria de estilo apropriada está na lista fornecida e a peça de roupa está rotulada incorretamente. A primeira imagem na grade, por exemplo, deve ser claramente “camuflagem” e não “chevron”. Em outros casos, no entanto, os produtos não se encaixam perfeitamente nas categorias de estilo. O vestido na segunda imagem da segunda linha, por exemplo, não é exatamente “listrado”, mas, dadas as mesmas opções de rotulagem, um anotador humano também pode ter entrado em conflito. À medida que construímos nosso conjunto de dados, precisamos decidir se removemos casos extremos como esses, adicionamos novas categorias de estilo ou aumentamos o conjunto de dados.
Exporte o conjunto de dados final do FiftyOne
Exporte o conjunto de dados final com o seguinte código:
Podemos exportar um conjunto de dados menor, por exemplo, 16 imagens, para a pasta 200kFashionDatasetExportResult-16Images. Criamos um trabalho de ajuste do Ground Truth usando-o:
Carregue o conjunto de dados revisado, converta o formato do rótulo em Ground Truth, carregue no Amazon S3 e crie um arquivo de manifesto para o trabalho de ajuste
Podemos converter os rótulos no conjunto de dados para corresponder ao esquema de manifesto de saída de um trabalho de caixa delimitadora do Ground Truth e carregue as imagens em um Serviço de armazenamento simples da Amazon (Amazon S3) balde para lançar um Trabalho de ajuste do Ground Truth:
Carregue o arquivo de manifesto no Amazon S3 com o seguinte código:
Crie etiquetas com estilo corrigido com o Ground Truth
Para anotar seus dados com rótulos de estilo usando o Ground Truth, conclua as etapas necessárias para iniciar um trabalho de rotulagem de caixa delimitadora seguindo o procedimento descrito no Introdução ao Ground Truth guia com o conjunto de dados no mesmo bucket do S3.
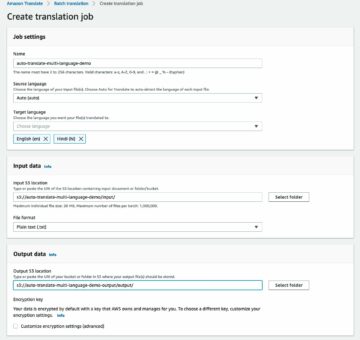
- No console do SageMaker, crie um trabalho de rotulagem do Ground Truth.
- Colocou o Local do conjunto de dados de entrada para ser o manifesto que criamos nas etapas anteriores.
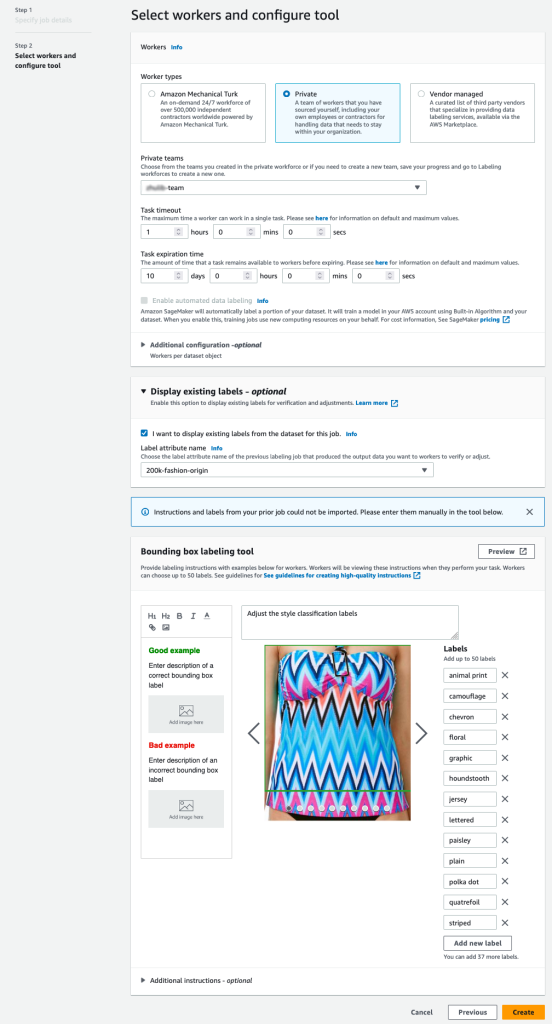
- Especifique um caminho S3 para Localização do conjunto de dados de saída.
- Escolha Papel IAM, escolha Insira uma função IAM personalizada ARN, em seguida, insira o ARN da função.
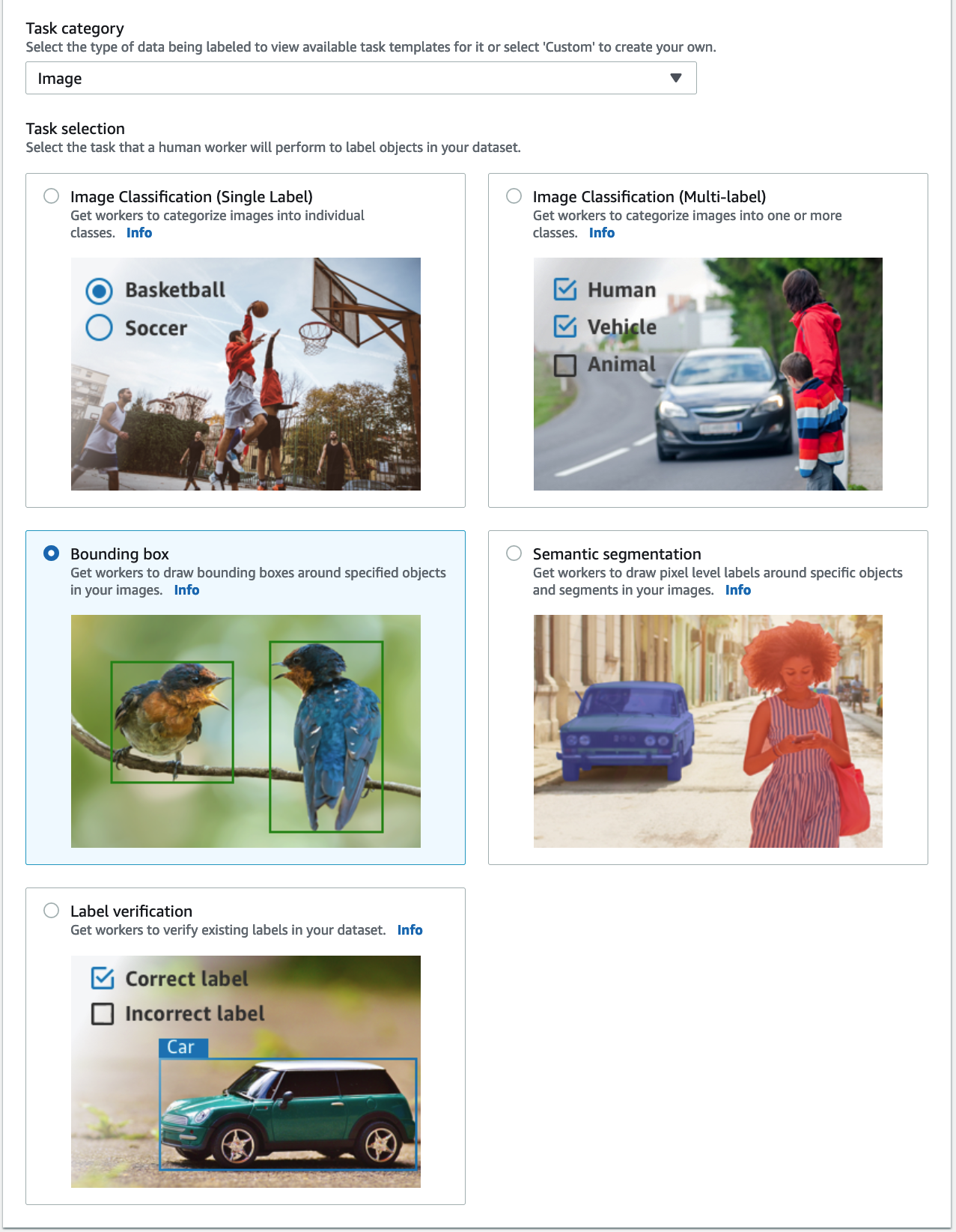
- Escolha Categoria da tarefa, escolha Imagem e selecione Caixa delimitadora.
- Escolha Próximo.
- No Trabalhadores seção, escolha o tipo de força de trabalho que você gostaria de usar.
Você pode selecionar uma força de trabalho por meio de Amazon Mechanical Turk, fornecedores terceirizados ou sua própria força de trabalho privada. Para obter mais detalhes sobre suas opções de força de trabalho, consulte Criar e gerenciar forças de trabalho. - Expandir Opções de exibição de rótulos existentes e selecione Desejo exibir rótulos existentes do conjunto de dados para este trabalho.
- Escolha Atributo de etiqueta name, escolha o nome do seu manifesto que corresponde aos rótulos que deseja exibir para ajuste.
Você verá apenas nomes de atributo de rótulo para rótulos que correspondam ao tipo de tarefa que você selecionou nas etapas anteriores. - Insira manualmente os rótulos para Ferramenta de rotulagem de caixa delimitadora.
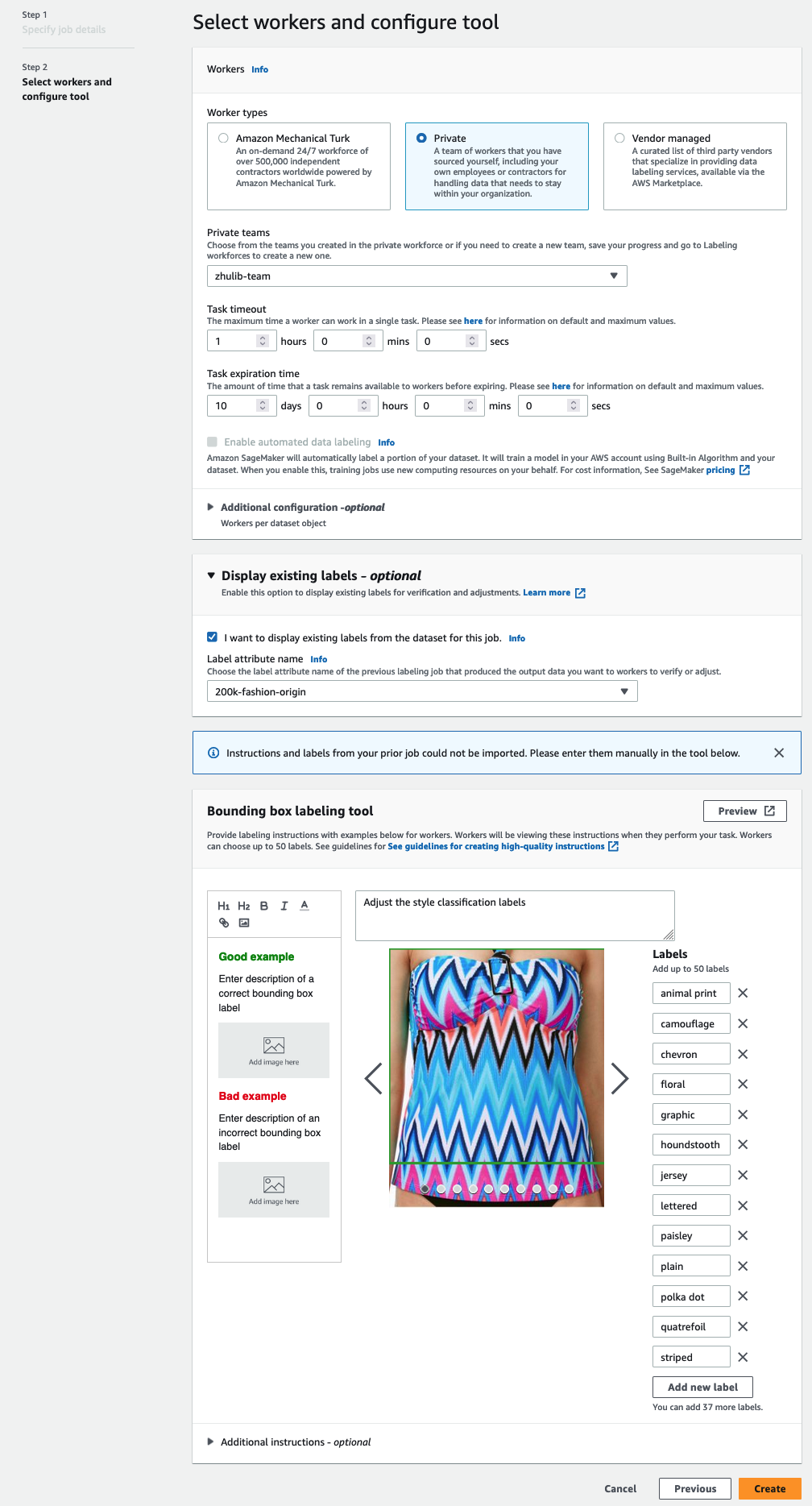 Os rótulos devem conter os mesmos rótulos usados no conjunto de dados público. Você pode adicionar novos rótulos. A captura de tela a seguir mostra como você pode escolher os trabalhadores e configurar a ferramenta para seu trabalho de rotulagem.
Os rótulos devem conter os mesmos rótulos usados no conjunto de dados público. Você pode adicionar novos rótulos. A captura de tela a seguir mostra como você pode escolher os trabalhadores e configurar a ferramenta para seu trabalho de rotulagem.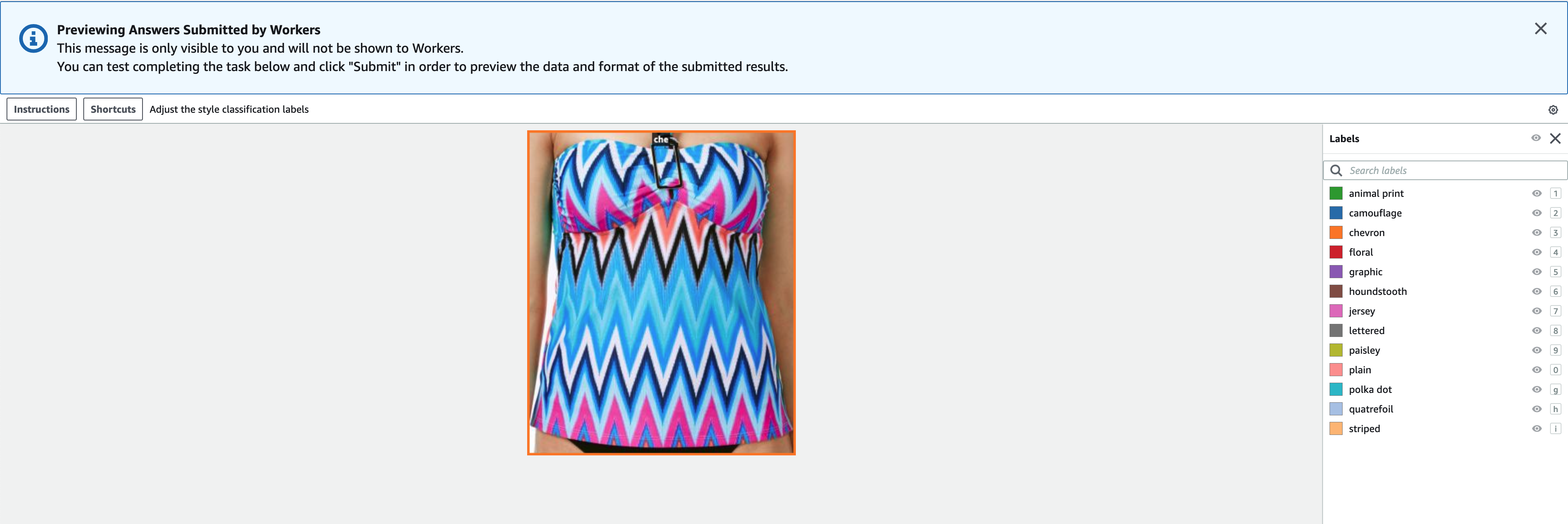
- Escolha visualização para visualizar a imagem e as anotações originais.
Agora criamos um trabalho de rotulagem no Ground Truth. Depois que nosso trabalho estiver concluído, podemos carregar os dados rotulados recém-gerados no FiftyOne. O Ground Truth produz dados de saída em um manifesto de saída do Ground Truth. Para obter mais detalhes sobre o arquivo de manifesto de saída, consulte Saída de trabalho de caixa delimitadora. O código a seguir mostra um exemplo desse formato de manifesto de saída:
Revise os resultados rotulados do Ground Truth no FiftyOne
Após a conclusão do trabalho, baixe o manifesto de saída do trabalho de rotulagem do Amazon S3.
Leia o arquivo de manifesto de saída:
Crie um conjunto de dados FiftyOne e converta as linhas de manifesto em amostras no conjunto de dados:
Agora você pode ver dados rotulados de alta qualidade do Ground Truth no FiftyOne.
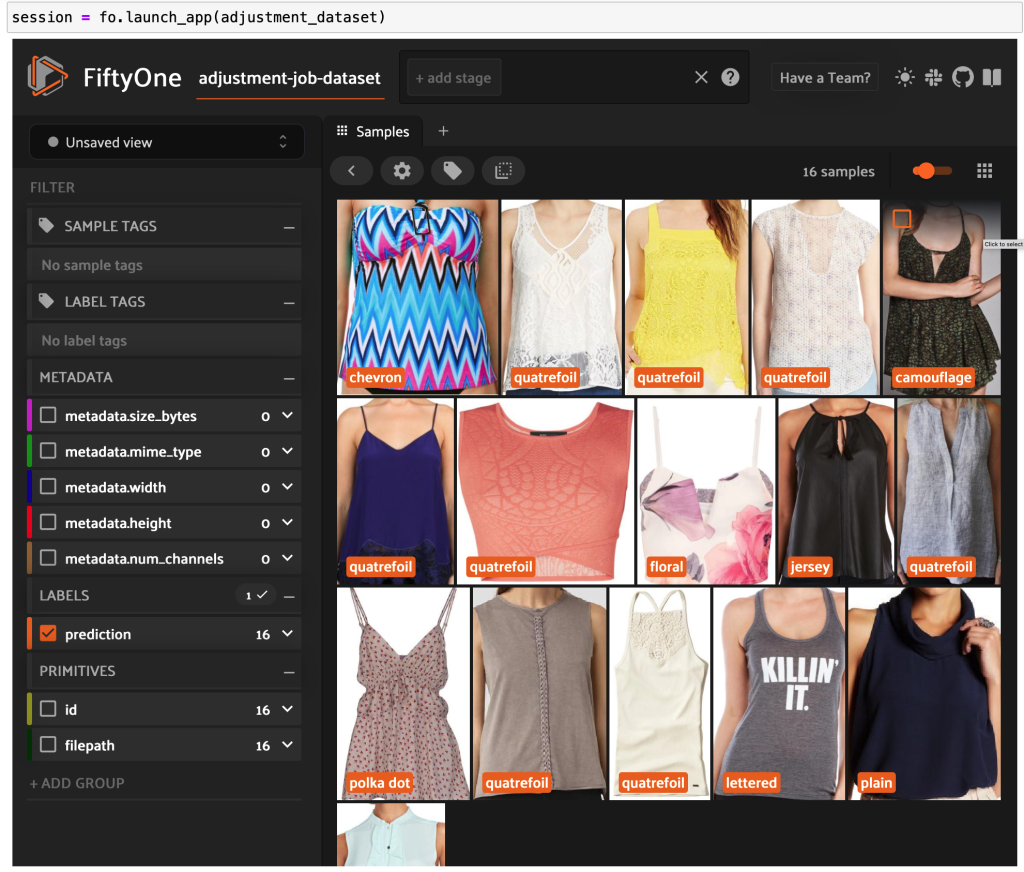
Conclusão
Neste post, mostramos como construir conjuntos de dados de alta qualidade combinando o poder de Cinquenta e um by voxel51, um kit de ferramentas de código aberto que permite gerenciar, rastrear, visualizar e selecionar seu conjunto de dados, e o Ground Truth, um serviço de rotulagem de dados que permite rotular com eficiência e precisão os conjuntos de dados necessários para sistemas de ML de treinamento, fornecendo acesso a vários -in modelos de tarefas e acesso a uma força de trabalho diversificada por meio do Mechanical Turk, fornecedores terceirizados ou sua própria força de trabalho privada.
Incentivamos você a experimentar essa nova funcionalidade instalando uma instância do FiftyOne e usando o console do Ground Truth para começar. Para saber mais sobre o Ground Truth, consulte Dados da etiqueta, Perguntas frequentes sobre rotulagem de dados do Amazon SageMaker, e as Blog do AWS Machine Learning.
Conecte-se com o Comunidade de aprendizado de máquina e IA se você tiver alguma dúvida ou feedback!
Junte-se à comunidade FiftyOne!
Junte-se aos milhares de engenheiros e cientistas de dados que já usam o FiftyOne para resolver alguns dos problemas mais desafiadores da visão computacional atualmente!
Sobre os autores
Shalendra Chabra atualmente é chefe de gerenciamento de produtos dos serviços Amazon SageMaker Human-in-the-Loop (HIL). Anteriormente, Shalendra incubou e liderou o Language and Conversational Intelligence for Microsoft Teams Meetings, foi EIR na Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing na Discussão.io, chefe de produto e marketing da Clipboard (adquirida pela Salesforce) e gerente de produto principal da Swype (adquirida pela Nuance). No total, Shalendra ajudou a construir, enviar e comercializar produtos que tocaram mais de um bilhão de vidas.
Jacó Marcos é engenheiro de aprendizado de máquina e desenvolvedor evangelista na Voxel51, onde ajuda a trazer transparência e clareza aos dados do mundo. Antes de ingressar no Voxel51, Jacob fundou uma startup para ajudar músicos emergentes a se conectar e compartilhar conteúdo criativo com os fãs. Antes disso, ele trabalhou no Google X, Samsung Research e Wolfram Research. Em uma vida passada, Jacob era um físico teórico, concluindo seu doutorado em Stanford, onde investigou as fases quânticas da matéria. Em seu tempo livre, Jacob gosta de escalar, correr e ler romances de ficção científica.
Jason Corso é cofundador e CEO da Voxel51, onde dirige a estratégia para ajudar a trazer transparência e clareza aos dados do mundo por meio de software flexível de última geração. Ele também é professor de robótica, engenharia elétrica e ciência da computação na Universidade de Michigan, onde se concentra em problemas de ponta na interseção de visão computacional, linguagem natural e plataformas físicas. Em seu tempo livre, Jason gosta de passar tempo com sua família, ler, estar na natureza, jogar jogos de tabuleiro e todo tipo de atividades criativas.
Brian Moore é cofundador e CTO da Voxel51, onde lidera estratégia e visão técnica. Ele é PhD em Engenharia Elétrica pela Universidade de Michigan, onde sua pesquisa foi focada em algoritmos eficientes para problemas de aprendizado de máquina em larga escala, com ênfase particular em aplicações de visão computacional. Em seu tempo livre, ele gosta de badminton, golfe, caminhadas e brincar com seus gêmeos Yorkshire Terriers.
Zhulingbai é um engenheiro de desenvolvimento de software na Amazon Web Services. Ela trabalha no desenvolvimento de sistemas distribuídos em larga escala para resolver problemas de aprendizado de máquina.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Sobre
- acelerar
- acelerando
- acelerador
- Acesso
- preciso
- exatamente
- adquirido
- atividades
- adicionar
- acrescentando
- endereço
- Ajustado
- Ajustamento
- Depois de
- novamente
- AI
- Alexa
- algoritmos
- Todos os Produtos
- permite
- sozinho
- já
- tb
- Amazon
- amazon alexa
- Amazon Sage Maker
- Verdade no solo do Amazon SageMaker
- Amazon Web Services
- entre
- an
- analisar
- e
- animal
- qualquer
- app
- Aplicação
- aplicações
- Aplicar
- apropriado
- SOMOS
- arranjado
- artigo
- artigos
- AS
- associado
- At
- autores
- longe
- AWS
- base
- baseado
- BE
- Porque
- tornam-se
- sido
- antes
- atrás
- Por trás das cenas
- ser
- Acreditar
- MELHOR
- Melhor
- entre
- bilhão
- borda
- Board Games
- OSSO
- Bootstrap
- ambos
- Caixa
- caixas
- Cérebro
- Break
- trazer
- Trazido
- orçamento
- construir
- Prédio
- construídas em
- mas a
- comprar
- by
- CAN
- Capturar
- casas
- casos
- Categorias
- Categoria
- Chefe executivo
- desafiar
- desafiante
- verificar
- Escolha
- clareza
- classe
- aulas
- classificação
- Limpeza
- remover filtragem
- claramente
- cliente
- Escalada
- Fechar
- mais próximo
- roupas
- Vestuário
- Co-fundador
- código
- combinar
- combinando
- Empresa
- Complemento
- completar
- completando
- Computar
- computador
- Ciência da Computação
- Visão de Computador
- Aplicativos de visão computacional
- confiança
- confiante
- CONTATE-NOS
- consideração
- Consistindo
- cônsul
- contém
- conteúdo
- conteúdo
- controlado
- conversação
- converter
- cópias
- núcleo
- corrigida
- corresponde
- Custo
- custos
- crio
- criado
- Criatividade
- Credenciais
- CTO
- comissariada
- curadoria
- Atualmente
- personalizadas
- cliente
- Clientes
- Cortar
- ponta
- dados,
- conjuntos de dados
- decidir
- demonstrar
- brim
- profundidade
- descrição
- detalhes
- Detecção
- Developer
- em desenvolvimento
- Desenvolvimento
- diferente
- diretamente
- diretórios
- Ecrã
- distinto
- distribuído
- Sistemas distribuídos
- diferente
- do
- Não faz
- Cachorro
- fazer
- feito
- não
- DOT
- down
- download
- duplicatas
- e
- cada
- fácil
- borda
- efeito
- eficiente
- eficientemente
- Engenharia elétrica
- embutindo
- emergente
- ênfase
- emprega
- empodera
- encapsulado
- encorajar
- final
- engenheiro
- Engenharia
- Engenheiros
- Entrar
- Meio Ambiente
- igualdade
- essencial
- estabelecido
- Éter (ETH)
- avaliação
- Evangelista
- exatamente
- exemplo
- existente
- exportar
- bastante
- família
- fãs
- retornos
- poucos
- Ficção
- campo
- Campos
- Envie o
- Arquivos
- filtro
- filtragem
- final
- Primeiro nome
- caber
- flexível
- Foco
- focado
- concentra-se
- seguinte
- Escolha
- formulário
- formato
- Felizmente
- Fundado
- quatro
- Gratuito
- da
- totalmente
- funcionalidade
- Games
- propósito geral
- gerar
- gerado
- ter
- GitHub
- OFERTE
- dado
- meta
- golfe
- Bom estado, com sinais de uso
- maior
- Grade
- Solo
- Grupo
- guia
- feliz
- Ter
- he
- cabeça
- altura
- ajudar
- ajudou
- útil
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- alta qualidade
- de alta resolução
- mais
- altamente
- caminhadas
- sua
- detém
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- humano
- i
- IAM
- ID
- identificar
- identificar
- ids
- if
- imagem
- imagens
- Impacto
- importar
- melhorar
- in
- Em outra
- Incluindo
- incorretamente
- incubado
- INFORMAÇÕES
- do estado inicial,
- inicialmente
- instalar
- instalando
- instância
- em vez disso
- instruções
- Inteligência
- interseção
- para dentro
- IT
- ESTÁ
- camisola
- Trabalho
- juntando
- articulação
- json
- apenas por
- Guarda
- manutenção
- O rótulo
- marcação
- Rótulos
- língua
- em grande escala
- lançamento
- de lançamento
- conduzir
- Leads
- APRENDER
- aprendizagem
- mínimo
- levou
- esquerda
- Permite
- Biblioteca
- vida
- como
- Provável
- LIMITE
- Limitado
- Line
- linhas
- Lista
- listagem
- Anúncios
- pequeno
- Vidas
- carregar
- olhar
- procurando
- lote
- Baixo
- máquina
- aprendizado de máquina
- moldadas
- mágica
- fazer
- FAZ
- gerencia
- gerenciados
- de grupos
- Gerente
- muitos
- mapa,
- mercado
- Marketing
- Match
- correspondente
- materialmente
- Importância
- Posso..
- mecânico
- Mídia
- reuniões
- Meta
- metadados
- método
- métodos
- Michigan
- Microsoft
- equipes da microsoft
- poder
- mínimo
- ML
- Móvel Esteira
- Aplicativo móvel
- modelo
- modelos
- Módulos
- mais
- a maioria
- mover
- muito
- múltiplo
- músicos
- devo
- nome
- Nomeado
- nomes
- natural
- Linguagem Natural
- Natureza
- Perto
- necessariamente
- necessário
- você merece...
- Cria
- Novo
- visivelmente
- Noção
- agora
- Nuança
- número
- objeto
- Detecção de Objetos
- objetos
- of
- oficial
- on
- uma vez
- ONE
- online
- só
- aberto
- open source
- Operações
- Oportunidade
- Opções
- or
- Organizado
- original
- OS
- Outros
- Outros
- A Nossa
- Fora
- delineado
- saída
- Acima de
- próprio
- possui
- Packs
- emparelhado
- parte
- particular
- passado
- caminho
- padrão
- padrões
- perfeita
- atuação
- pessoa
- Personalizado
- Fases da Matéria
- físico
- escolher
- FOTOS
- Xadrez
- Avião
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- ponto
- populosa
- possível
- Publique
- poder
- prática
- previsto
- predição
- Previsões
- visualização
- anterior
- anteriormente
- Impressão
- Prévio
- privado
- provavelmente
- problemas
- processo
- Produto
- gestão de produtos
- gerente de produto
- Produtos
- Professor
- projeto
- propriedade
- em perspectiva
- protótipo
- fornecer
- fornecido
- fornecendo
- público
- soco
- fins
- Python
- Quantum
- Frequentes
- rapidamente
- alcance
- em vez
- Leitura
- pronto
- recomendar
- recomendações
- reduzir
- Reduzido
- redução
- relativamente
- liberado
- relevante
- remover
- representante
- representando
- requeridos
- pesquisa
- pesquisadores
- Resolução
- restringir
- resultar
- resultando
- Resultados
- varejo
- retorno
- rever
- Livrar
- robótica
- uma conta de despesas robusta
- Tipo
- grosseiramente
- LINHA
- arruinar
- corrida
- sábio
- Dito
- Salesforce
- mesmo
- Samsung
- Salvar
- Cenas
- Ciência
- Ficção científica
- cientistas
- Ponto
- sem problemas
- Segundo
- Seção
- seções
- Vejo
- parecem
- parece
- selecionado
- sentido
- separado
- serviço
- Serviços
- Sessão
- conjunto
- Partilhar
- ela
- rede de apoio social
- mostrar
- Shows
- SIM
- semelhante
- simples
- menor
- So
- Software
- desenvolvimento de software
- RESOLVER
- alguns
- Alguém
- algo
- Espaço
- gastar
- Passar
- divisão
- splits
- Stanford
- começo
- começado
- Comece
- inicialização
- acelerador de inicialização
- estado-da-arte
- Passos
- Ainda
- armazenamento
- loja
- Estratégia
- estilo
- estilos
- RESUMO
- Suportado
- sistemas
- Tire
- Tarefa
- equipes
- Dados Técnicos:
- TechStars
- conta
- modelos
- teste
- do que
- que
- A
- deles
- Eles
- então
- teórico
- Lá.
- Este
- deles
- coisas
- think
- De terceiros
- isto
- milhares
- limiar
- Através da
- Jogando
- tempo
- para
- juntos
- ferramenta
- kit de ferramentas
- topo
- nível superior
- Tops
- Total
- tocou
- pista
- Trem
- treinado
- Training
- Transformar
- Transparência
- verdadeiro
- Verdade
- VIRAR
- dois
- tipo
- tipos
- para
- compreender
- único
- universidade
- Universidade de Michigan
- Atualizar
- us
- usar
- caso de uso
- usava
- Utilizador
- usuários
- utilização
- Valores
- variedade
- vário
- fornecedores
- verificar
- muito
- via
- Ver
- Virtual
- visão
- queremos
- foi
- we
- web
- serviços web
- BEM
- foram
- O Quê
- quando
- se
- qual
- Wikipedia
- precisarão
- com
- dentro
- sem
- Mulher
- palavras
- Atividades:
- trabalhou
- trabalhadores
- Força de trabalho
- trabalho
- do mundo
- preocupar-se
- seria
- escrever
- X
- Você
- investimentos
- zefirnet
- Zip
- ZOO