No atual ambiente de negócios orientado a dados, as organizações enfrentam o desafio de preparar e transformar com eficiência grandes quantidades de dados para fins de análise e ciência de dados. As empresas precisam construir data warehouses e data lakes com base em dados operacionais. Isso é impulsionado pela necessidade de centralizar e integrar dados provenientes de fontes diferentes.
Ao mesmo tempo, os dados operacionais geralmente se originam de aplicativos respaldados por armazenamentos de dados legados. A modernização de aplicativos requer uma arquitetura de microsserviço que, por sua vez, exige a consolidação de dados de várias fontes para construir um armazenamento de dados operacional. Sem modernização, os aplicativos legados podem incorrer em custos crescentes de manutenção. A modernização de aplicativos envolve a alteração do mecanismo de banco de dados subjacente para um banco de dados moderno baseado em documentos, como o MongoDB.
Essas duas tarefas (construir data lakes ou data warehouses e modernização de aplicativos) envolvem a movimentação de dados, que usa um processo de extração, transformação e carregamento (ETL). O trabalho ETL é uma funcionalidade chave para ter um processo bem estruturado para ter sucesso.
Cola AWS é um serviço de integração de dados sem servidor que simplifica a descoberta, preparação, movimentação e integração de dados de várias fontes para análise, aprendizado de máquina (ML) e desenvolvimento de aplicativos. Atlas MongoDB é um conjunto integrado de banco de dados em nuvem e serviços de dados que combina processamento transacional, pesquisa baseada em relevância, análise em tempo real e sincronização de dados móvel para nuvem em uma arquitetura elegante e integrada.
Ao usar o AWS Glue com o MongoDB Atlas, as organizações podem simplificar seus processos de ETL. Com sua solução de banco de dados totalmente gerenciada, escalável e segura, o MongoDB Atlas fornece um ambiente flexível e confiável para armazenar e gerenciar dados operacionais. Juntos, o AWS Glue ETL e o MongoDB Atlas são uma solução poderosa para organizações que buscam otimizar a forma como criam data lakes e data warehouses e modernizar seus aplicativos para melhorar o desempenho dos negócios, reduzir custos e impulsionar o crescimento e o sucesso.
Neste post, demonstramos como migrar dados de Serviço de armazenamento simples da Amazon (Amazon S3) para o MongoDB Atlas usando AWS Glue ETL e como extrair dados do MongoDB Atlas para um data lake baseado no Amazon S3.
Visão geral da solução
Nesta postagem, exploramos os seguintes casos de uso:
- Extraindo dados do MongoDB – MongoDB é um banco de dados popular usado por milhares de clientes para armazenar dados de aplicativos em escala. Os clientes corporativos podem centralizar e integrar dados provenientes de vários armazenamentos de dados criando data lakes e data warehouses. Esse processo envolve a extração de dados dos armazenamentos de dados operacionais. Quando os dados estão em um só lugar, os clientes podem usá-los rapidamente para necessidades de business intelligence ou ML.
- Ingestão de dados no MongoDB – O MongoDB também serve como um banco de dados não SQL para armazenar dados de aplicativos e criar armazenamentos de dados operacionais. A modernização de aplicativos geralmente envolve a migração do armazenamento operacional para o MongoDB. Os clientes precisariam extrair dados existentes de bancos de dados relacionais ou de arquivos simples. Os aplicativos móveis e da web geralmente exigem que os engenheiros de dados criem pipelines de dados para criar uma única exibição de dados no Atlas enquanto ingerem dados de várias fontes isoladas. Durante essa migração, eles precisariam juntar diferentes bancos de dados para criar documentos. Essa complexa operação de junção precisaria de um poder de computação único e significativo. Os desenvolvedores também precisariam criar isso rapidamente para migrar os dados.
O AWS Glue é útil nesses casos com o modelo de pagamento conforme o uso e sua capacidade de executar transformações complexas em grandes conjuntos de dados. Os desenvolvedores podem usar o AWS Glue Studio para criar esses pipelines de dados com eficiência.
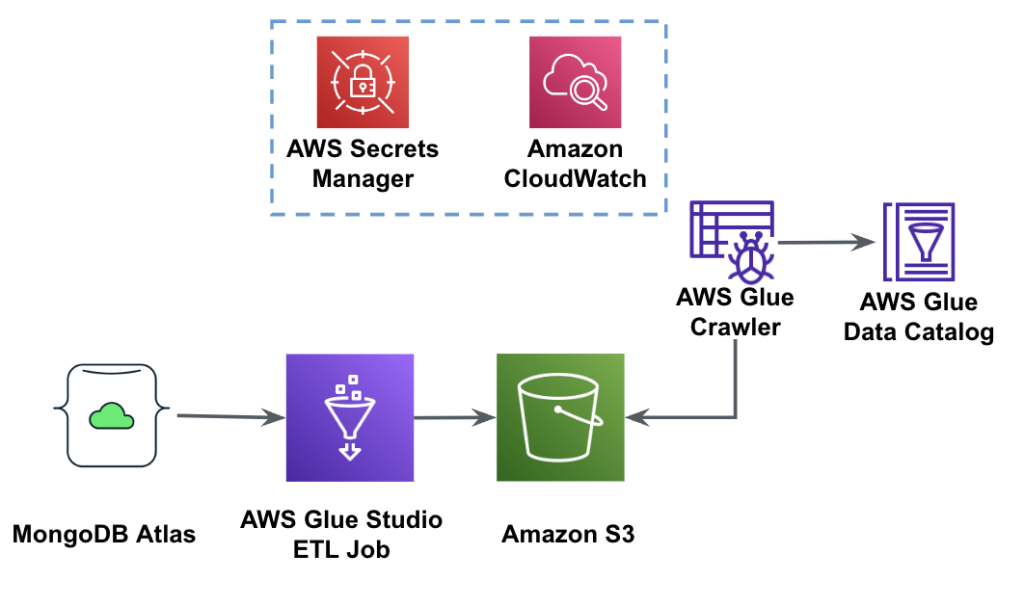
O diagrama a seguir mostra o fluxo de trabalho de extração de dados do MongoDB Atlas em um bucket S3 usando o AWS Glue Studio.
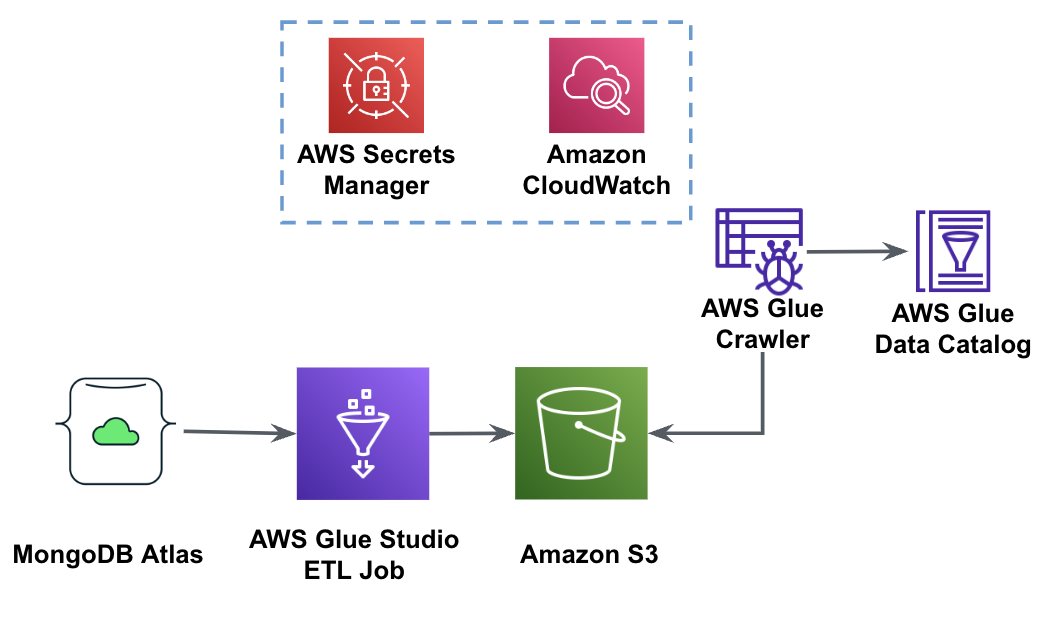
Para implementar essa arquitetura, você precisará de um cluster MongoDB Atlas, um balde S3 e um Gerenciamento de acesso e identidade da AWS (IAM) para AWS Glue. Para configurar esses recursos, consulte as etapas de pré-requisito no seguinte GitHub repo.
A figura a seguir mostra o fluxo de trabalho de carregamento de dados de um bucket S3 no MongoDB Atlas usando o AWS Glue.
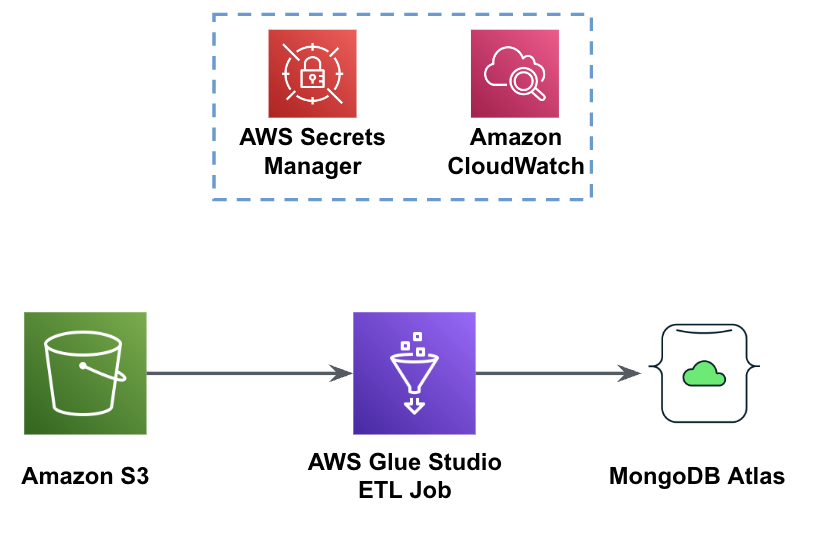
Os mesmos pré-requisitos são necessários aqui: um bucket S3, função IAM e um cluster MongoDB Atlas.
Carregue dados do Amazon S3 para o MongoDB Atlas usando o AWS Glue
As etapas a seguir descrevem como carregar dados do bucket S3 no MongoDB Atlas usando um trabalho do AWS Glue. O processo de extração do MongoDB Atlas para o Amazon S3 é muito semelhante, com exceção do script que está sendo usado. Chamamos a atenção para as diferenças entre os dois processos.
- Criar um cluster gratuito no MongoDB Atlas.
- Nos envie os exemplo de arquivo JSON ao seu balde S3.
- Crie um novo trabalho do AWS Glue Studio com o Editor de scripts do Spark opção.

- Dependendo se você deseja carregar ou extrair dados do cluster MongoDB Atlas, insira o carregar script or extrair script no editor de script do AWS Glue Studio.
A captura de tela a seguir mostra um trecho de código para carregar dados no cluster MongoDB Atlas.

O código usa Gerenciador de segredos da AWS para recuperar o nome do cluster MongoDB Atlas, nome de usuário e senha. Em seguida, ele cria um DynamicFrame para o bucket S3 e o nome do arquivo passado para o script como parâmetros. O código recupera os nomes do banco de dados e da coleção da configuração dos parâmetros do trabalho. Finalmente, o código escreve o DynamicFrame para o cluster MongoDB Atlas usando os parâmetros recuperados.
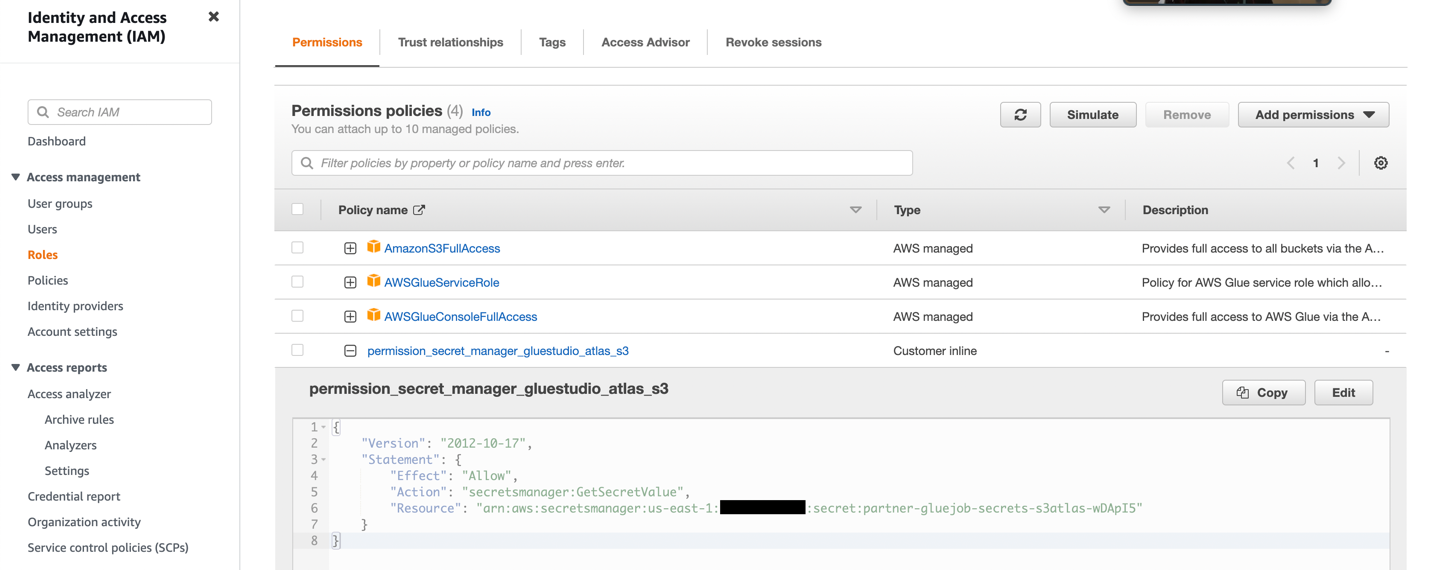
- Crie uma função do IAM com as permissões mostradas na captura de tela a seguir.
Para mais detalhes, consulte Configure uma função IAM para seu trabalho ETL.
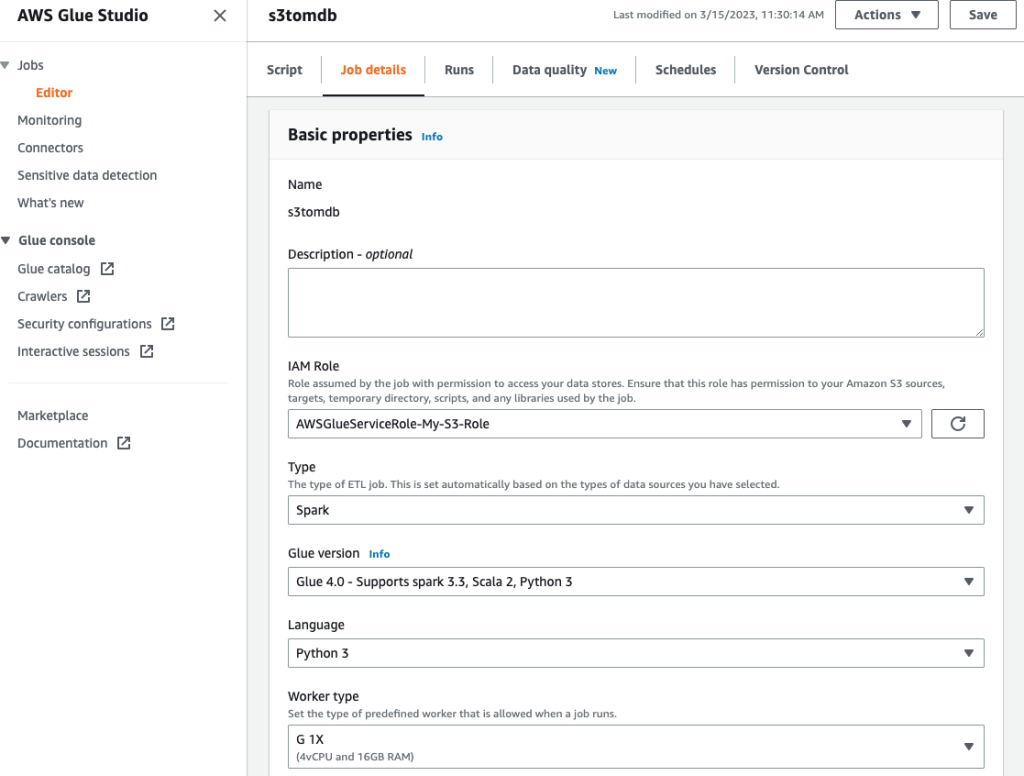
- Dê um nome ao trabalho e forneça a função IAM criada na etapa anterior no Detalhes do trabalho aba.
- Você pode deixar o restante dos parâmetros como padrão, conforme mostrado nas capturas de tela a seguir.
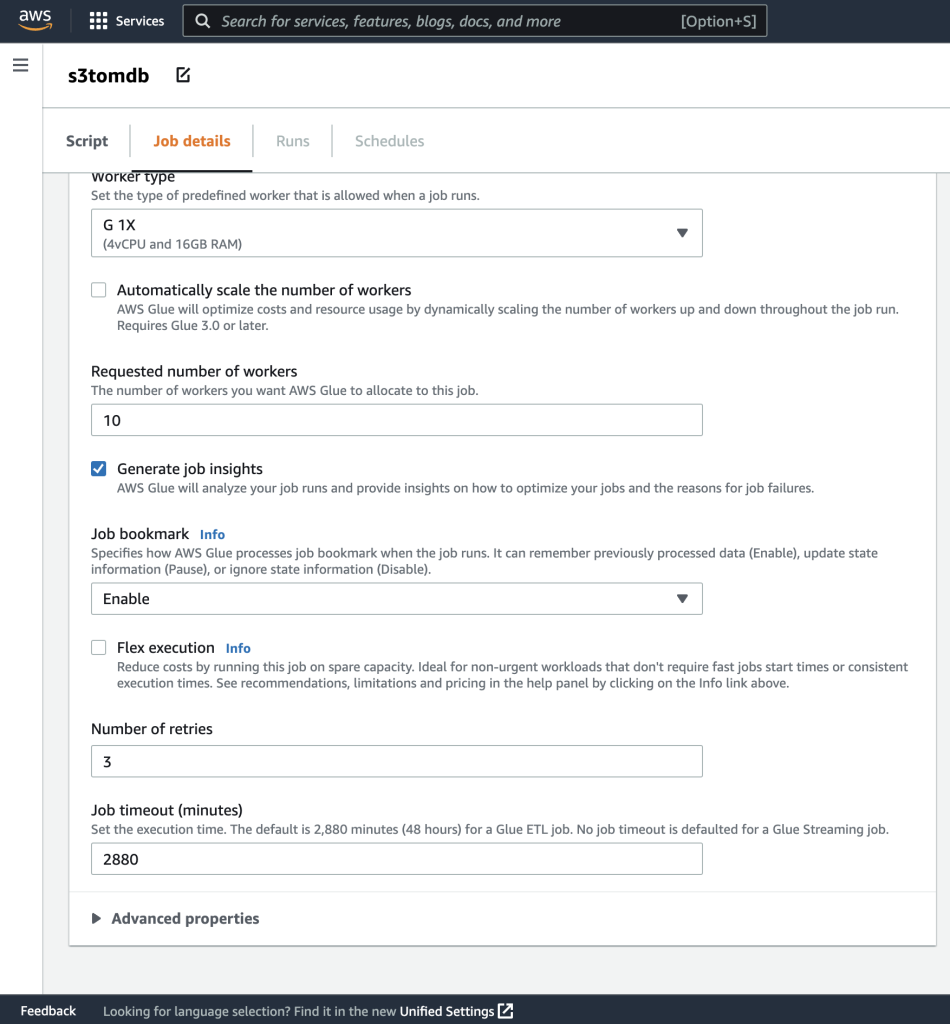
- Em seguida, defina os parâmetros da tarefa que o script usa e forneça os valores padrão.
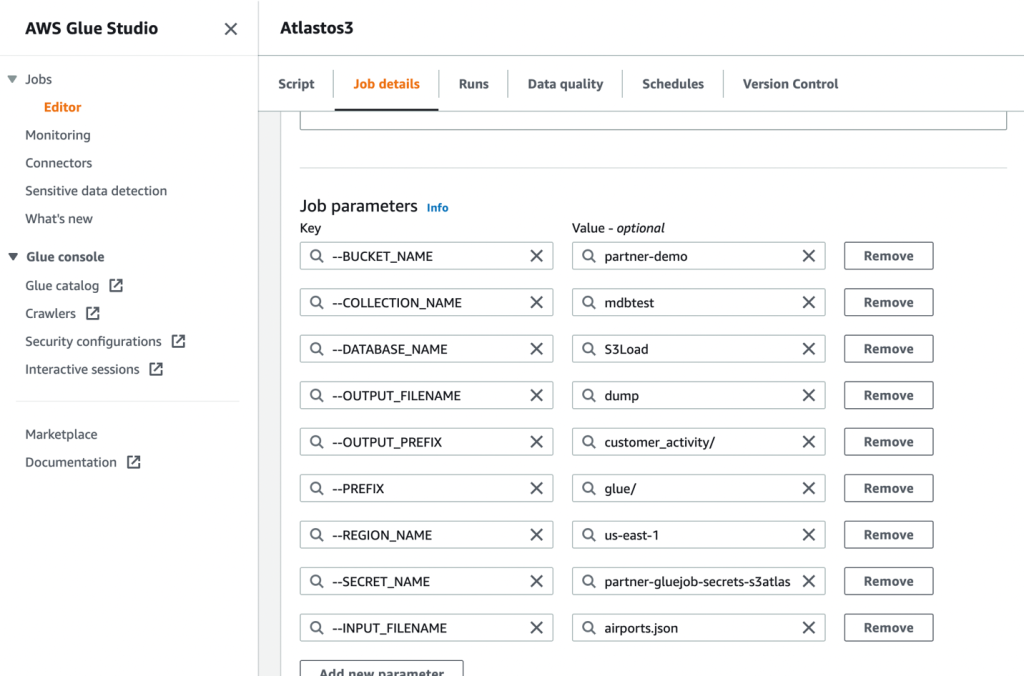
- Salve o trabalho e execute-o.
- Para confirmar uma execução bem-sucedida, observe o conteúdo da coleção de banco de dados MongoDB Atlas se estiver carregando os dados ou o bucket S3 se estiver executando uma extração.



A captura de tela a seguir mostra os resultados de um carregamento de dados bem-sucedido de um bucket do Amazon S3 para o cluster do MongoDB Atlas. Os dados agora estão disponíveis para consultas na IU do MongoDB Atlas.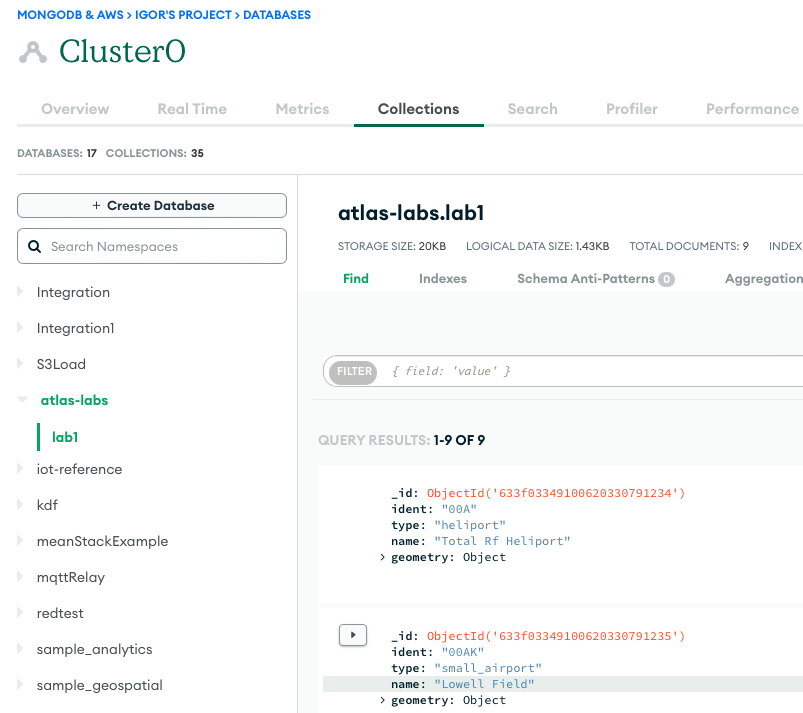
- Para solucionar problemas de suas execuções, revise o Amazon CloudWatch logs usando o link no job's Execute aba.
A captura de tela a seguir mostra que o trabalho foi executado com êxito, com detalhes adicionais, como links para os logs do CloudWatch.

Conclusão
Nesta postagem, descrevemos como extrair e ingerir dados para o MongoDB Atlas usando o AWS Glue.
Com os trabalhos ETL do AWS Glue, agora podemos transferir os dados do MongoDB Atlas para fontes compatíveis com o AWS Glue e vice-versa. Você também pode estender a solução para criar análises usando os serviços AWS AI e ML.
Para saber mais, consulte o Repositório GitHub para obter instruções passo a passo e código de amostra. você pode adquirir Atlas MongoDB no AWS Marketplace.
Sobre os autores

Igor Alekseev é Arquiteto de Soluções de Parceiro Sênior na AWS no domínio de Dados e Análise. Em sua função, Igor está trabalhando com parceiros estratégicos, ajudando-os a criar arquiteturas complexas e otimizadas para AWS. Antes de ingressar na AWS, como Arquiteto de Dados/Soluções, ele implementou muitos projetos no domínio de Big Data, incluindo vários data lakes no ecossistema Hadoop. Como Engenheiro de Dados, ele esteve envolvido na aplicação de IA/ML para detecção de fraudes e automação de escritórios.
 Babu Srinivasan é Arquiteto de Soluções de Parceiro Sênior no MongoDB. Em sua função atual, ele está trabalhando com a AWS para criar as integrações técnicas e arquiteturas de referência para as soluções AWS e MongoDB. Ele tem mais de duas décadas de experiência em tecnologias de banco de dados e nuvem. Ele é apaixonado por fornecer soluções técnicas para clientes que trabalham com vários integradores de sistemas globais (GSIs) em várias regiões geográficas.
Babu Srinivasan é Arquiteto de Soluções de Parceiro Sênior no MongoDB. Em sua função atual, ele está trabalhando com a AWS para criar as integrações técnicas e arquiteturas de referência para as soluções AWS e MongoDB. Ele tem mais de duas décadas de experiência em tecnologias de banco de dados e nuvem. Ele é apaixonado por fornecer soluções técnicas para clientes que trabalham com vários integradores de sistemas globais (GSIs) em várias regiões geográficas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :tem
- :é
- 100
- 11
- a
- habilidade
- Sobre
- Acesso
- em
- Adicional
- AI
- AI / ML
- tb
- Amazon
- quantidades
- an
- analítica
- e
- Aplicação
- Desenvolvimento de Aplicações
- aplicações
- Aplicando
- Aplicativos
- arquitetura
- SOMOS
- AS
- At
- atlas
- Automação
- disponível
- AWS
- Cola AWS
- Mercado da AWS
- Apoiado
- baseado
- ser
- entre
- Grande
- Big Data
- construir
- Prédio
- negócio
- inteligência de negócios
- desempenho dos negócios
- negócios
- by
- chamada
- CAN
- casos
- desafiar
- mudança
- Na nuvem
- Agrupar
- código
- coleção
- combina
- vem
- vinda
- integrações
- Computar
- Configuração
- Confirmar
- consolidação
- construir
- conteúdo
- continuou
- custos
- crio
- criado
- cria
- criação
- Atual
- Clientes
- dados,
- engenheiro de dados
- integração de dados
- lago data
- ciência de dados
- armazéns de dados
- orientado por dados
- banco de dados
- bases de dados
- conjuntos de dados
- décadas
- Padrão
- demonstrar
- descreve
- descrito
- detalhes
- Detecção
- desenvolvedores
- Desenvolvimento
- diferenças
- diferente
- descobrir
- díspar
- INSTITUCIONAIS
- domínio
- distância
- dirigido
- durante
- ecossistema
- editor
- eficientemente
- Motor
- engenheiro
- Engenheiros
- Entrar
- Empreendimento
- clientes corporativos
- Meio Ambiente
- Éter (ETH)
- exceção
- existente
- vasta experiência
- explorar
- estender
- extrato
- Extração
- Rosto
- Figura
- Envie o
- Arquivos
- Finalmente
- plano
- flexível
- seguinte
- Escolha
- fraude
- detecção de fraude
- Gratuito
- da
- totalmente
- funcionalidade
- geografias
- Global
- Growth
- Hadoop
- acessível
- ter
- he
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- sua
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- enorme
- IAM
- Dados de identificação:
- if
- executar
- implementado
- melhorar
- in
- Incluindo
- aumentando
- entrada
- instruções
- integrar
- integrado
- integração
- integrações
- Inteligência
- para dentro
- envolver
- envolvido
- IT
- ESTÁ
- Trabalho
- Empregos
- juntar
- juntando
- json
- Chave
- lago
- grande
- APRENDER
- aprendizagem
- Deixar
- Legado
- como
- LINK
- Links
- carregar
- carregamento
- procurando
- máquina
- aprendizado de máquina
- manutenção
- FAZ
- gerenciados
- gestão
- muitos
- marketplace
- Posso..
- migrado
- migração
- ML
- Móvel Esteira
- modelo
- EQUIPAMENTOS
- modernização
- modernizar
- MongoDB
- mais
- mover
- movimento
- múltiplo
- nome
- nomes
- você merece...
- necessário
- Cria
- Novo
- agora
- observar
- of
- Office
- frequentemente
- on
- ONE
- operação
- operacional
- Otimize
- Opção
- or
- ordem
- organizações
- Fora
- parâmetros
- parceiro
- Parceiros
- passou
- apaixonado
- Senha
- atuação
- realização
- permissões
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- Popular
- Publique
- poder
- poderoso
- Preparar
- preparação
- pré-requisitos
- anterior
- Prévio
- processo
- processos
- em processamento
- projetos
- fornece
- fornecendo
- fins
- consultas
- rapidamente
- em tempo real
- reduzir
- confiável
- requerer
- exige
- Recursos
- DESCANSO
- Resultados
- rever
- Tipo
- Execute
- mesmo
- escalável
- Escala
- Ciência
- screenshots
- Pesquisar
- seguro
- senior
- Serverless
- serve
- serviço
- Serviços
- vários
- mostrando
- Shows
- periodo
- semelhante
- simples
- solteiro
- solução
- Soluções
- Fontes
- Passo
- Passos
- armazenamento
- loja
- lojas
- franco
- Estratégico
- parceiros estratégicos
- simplificar
- estudo
- suceder
- sucesso
- bem sucedido
- entraram com sucesso
- tal
- suíte
- supply
- Sincronização
- .
- tarefas
- Dados Técnicos:
- Tecnologias
- do que
- que
- A
- deles
- Eles
- então
- Este
- deles
- isto
- milhares
- tempo
- para
- hoje
- juntos
- transacional
- transferência
- Transformar
- transformações
- transformando
- VIRAR
- dois
- ui
- subjacente
- usar
- usava
- Utilizador
- utilização
- Valores
- muito
- Ver
- queremos
- foi
- we
- web
- foram
- quando
- se
- qual
- enquanto
- precisarão
- de
- sem
- de gestão de documentos
- trabalhar
- seria
- Você
- investimentos
- zefirnet