Bem-vindo à era dos dados. O grande volume de dados capturados diariamente continua a crescer, exigindo que as plataformas e soluções evoluam. Serviços como Serviço de armazenamento simples da Amazon (Amazon S3) oferecem uma solução escalável que se adapta, mas permanece econômica para conjuntos de dados crescentes. O Iniciativa de Dados de Sustentabilidade da Amazônia (ASDI) usa os recursos do Amazon S3 para fornecer uma solução gratuita para você armazenar e compartilhar cargas de trabalho de ciência do clima em todo o mundo. O Programa de Patrocínio de Dados Abertos da Amazon permite que as organizações hospedem gratuitamente na AWS.
Na última década, vimos um aumento nas estruturas de ciência de dados se concretizando, juntamente com a adoção em massa pela comunidade de ciência de dados. Um desses quadros é Painel, que é poderoso por sua capacidade de provisionar uma orquestração de nós de computação do trabalhador, acelerando assim análises complexas em grandes conjuntos de dados.
Nesta postagem, mostramos como implantar um aplicativo personalizado Kit de desenvolvimento em nuvem da AWS (AWS CDK) solução que estende a funcionalidade do Dask para trabalhar inter-regionalmente na rede global da Amazon. A solução AWS CDK implanta uma rede de Dask workers em duas regiões da AWS, conectando-se a uma região cliente. Para mais informações, consulte Orientação para computação distribuída com Cross Regional Dask na AWS e os votos de GitHub repo para código-fonte aberto.
Após a implantação, o usuário terá acesso a um notebook Jupyter, onde poderá interagir com dois datasets da ASDI na AWS: Projeto de Intercomparação de Modelo Acoplado 6 (CMIP6) e Reanálise ECMWF ERA5. O CMIP6 concentra-se na sexta fase do conjunto global de modelos de circulação geral oceano-atmosfera; O ERA5 é a quinta geração de reanálises atmosféricas ECMWF do clima global e a primeira reanálise produzida como um serviço operacional.
Esta solução foi inspirada no trabalho com um cliente-chave da AWS, o UK Met Office. O Met Office foi fundado em 1854 e é o serviço meteorológico nacional do Reino Unido. Eles fornecem previsões meteorológicas e climáticas para ajudá-lo a tomar melhores decisões para se manter seguro e prosperar. Uma colaboração entre o Met Office e a EUMETSAT, detalhada em Computação aproximada de dados em um cluster Dask distribuído entre data centers, destaca a crescente necessidade de desenvolver uma solução de ciência de dados sustentável, eficiente e escalável. Essa solução consegue isso aproximando a computação dos dados, em vez de forçar os dados a se aproximarem dos recursos de computação, o que adiciona custo, latência e energia.
Visão geral da solução
Todos os dias, o UK Met Office produz até 300 TB de dados meteorológicos e climáticos, uma parte dos quais é publicada na ASDI. Esses conjuntos de dados são distribuídos em todo o mundo e hospedados para uso público. O Met Office gostaria de permitir que os consumidores aproveitem ao máximo seus dados para ajudar a informar decisões críticas sobre questões como melhor preparação para incêndios florestais e inundações induzidos por mudanças climáticas e redução da insegurança alimentar por meio de uma melhor análise do rendimento das colheitas.
As soluções tradicionais em uso hoje, particularmente com dados climáticos, são demoradas e insustentáveis, replicando conjuntos de dados entre regiões. A transferência de dados desnecessária na escala de petabytes é cara, lenta e consome energia.
Estimamos que, se essa prática fosse adotada pelos usuários do Met Office, seria possível economizar o equivalente ao consumo diário de energia de 40 residências todos os dias, além de reduzir a transferência de dados entre as regiões.
O diagrama a seguir ilustra a arquitetura da solução.
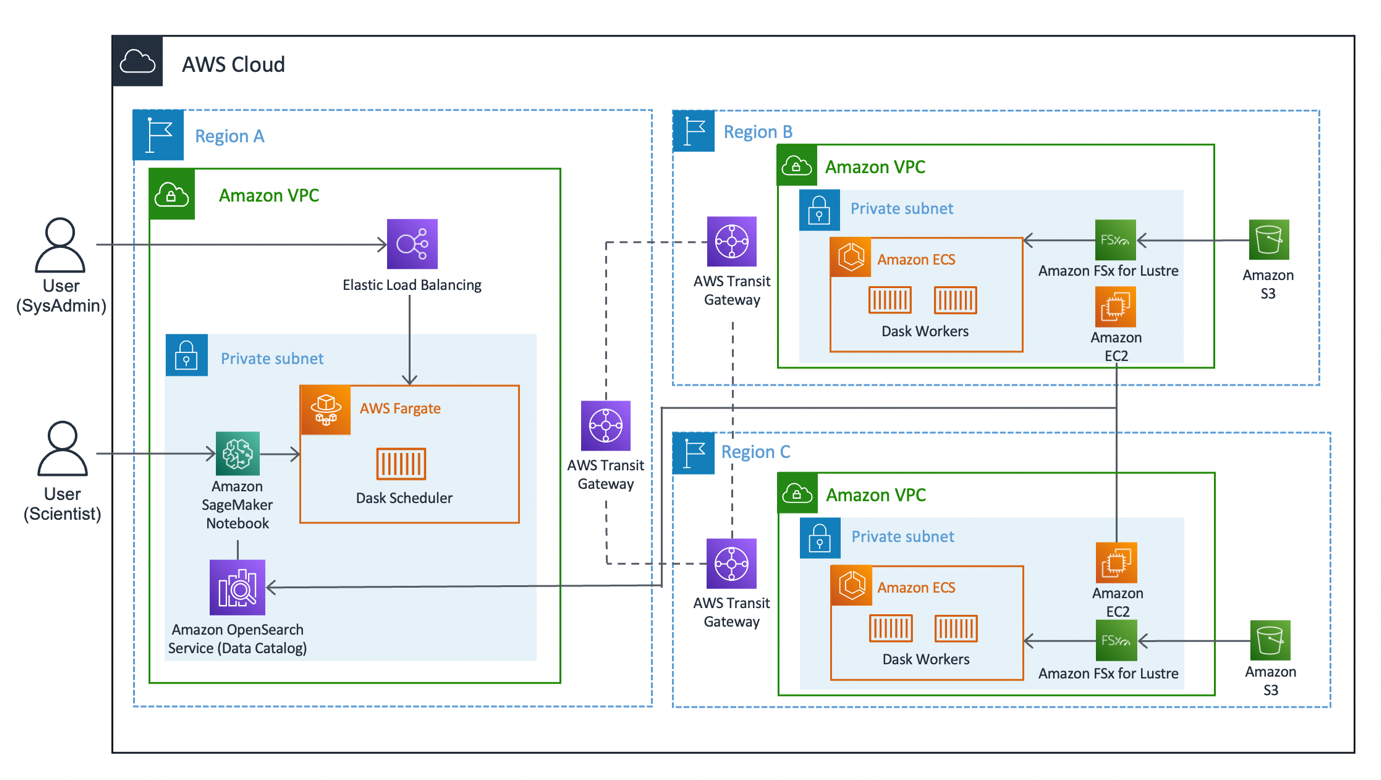
A solução pode ser dividida em três segmentos principais: cliente, trabalhadores e rede. Vamos mergulhar em cada um e ver como eles se juntam.
Cliente
O cliente representa a região de origem onde os cientistas de dados se conectam. Esta região (Região A no diagrama) contém um Notebook Amazon SageMaker, um Serviço Amazon OpenSearch domínio e um Dask agendador como componentes chave. Os administradores do sistema têm acesso ao painel interno do Dask exposto por meio de um Balanceador de carga elástico.
Os cientistas de dados têm acesso ao notebook Jupyter hospedado no SageMaker. O notebook é capaz de conectar e executar cargas de trabalho no agendador Dask. O domínio OpenSearch Service armazena metadados nos conjuntos de dados conectados nas Regiões. Os usuários de notebook podem consultar esse serviço para recuperar detalhes, como a região correta dos funcionários do Dask, sem precisar saber a localização regional dos dados de antemão.
Trabalhador
Cada uma das Regiões trabalhadoras (Regiões B e C no diagrama) é composta por um Serviço Amazon Elastic Container (Amazon ECS) cluster de Dask trabalhadores, um Amazon FSx para Lustre sistema de arquivos e um autônomo Amazon Elastic Compute Nuvem (Amazon EC2). O FSx for Lustre permite que os funcionários do Dask acessem e processem dados do Amazon S3 a partir de um sistema de arquivos de alto desempenho, vinculando seus sistemas de arquivos aos buckets do S3. Ele fornece latências abaixo de milissegundos, até centenas de GBs/s de taxa de transferência e milhões de IOPS. Um recurso importante do Lustre é que apenas os metadados do sistema de arquivos são sincronizados. O Lustre gerencia o equilíbrio dos arquivos a serem carregados e mantidos aquecidos, com base na demanda.
Os clusters de trabalho são dimensionados com base no uso da CPU, provisionam trabalhadores adicionais em períodos prolongados de demanda e são reduzidos à medida que os recursos ficam ociosos.
Todas as noites, às 0:00 UTC, um trabalho de sincronização de dados solicita que o sistema de arquivos Lustre sincronize novamente com o bucket S3 conectado e extraia um catálogo de metadados atualizado do bucket. Posteriormente, a instância autônoma do EC2 envia essas atualizações para o serviço OpenSearch correspondente ao índice dessa região. O serviço OpenSearch fornece as informações necessárias ao cliente sobre qual pool de trabalhadores deve ser chamado para um determinado conjunto de dados.
Network
A rede forma o ponto crucial desta solução, utilizando a rede de backbone interna da Amazon. usando AWS Transit Gateway, podemos conectar cada uma das Regiões entre si sem a necessidade de atravessar a Internet pública. Cada um dos trabalhadores pode se conectar dinamicamente ao agendador Dask, permitindo que os cientistas de dados executem consultas inter-regionais por meio do Dask.
Pré-requisitos
O pacote AWS CDK usa a linguagem de programação TypeScript. Siga os passos em Conceitos básicos do AWS CDK para configurar seu ambiente local e inicializar sua conta de desenvolvimento (você precisará inicializar todas as regiões especificadas no GitHub repo).
Para uma implantação bem-sucedida, você precisará Docker instalado e rodando em sua máquina local.
Implante o pacote AWS CDK
A implantação de um pacote do AWS CDK é simples. Depois de instalar os pré-requisitos e inicializar sua conta, você pode prosseguir com o download da base de código.
- Faça o download do Repositório GitHub:
- Instalar módulos de nó:
- Implante o AWS CDK:
A pilha pode levar mais de uma hora e meia para ser implantada.
Passo a passo do código
Nesta seção, inspecionamos alguns dos principais recursos da base de código. Se você gostaria de inspecionar a base de código completa, consulte o Repositório GitHub.
Configure e personalize sua pilha
No arquivo bin/variáveis.ts, você encontrará duas declarações de variáveis: uma para o cliente e outra para trabalhadores. A declaração do cliente é um dicionário com uma referência a uma região e intervalo CIDR. A personalização dessas variáveis alterará a região e o intervalo CIDR de onde os recursos do cliente serão implantados.
A variável de trabalho copia essa mesma funcionalidade; no entanto, é uma lista de dicionários para acomodar a adição ou subtração de conjuntos de dados que o usuário deseja incluir. Além disso, cada dicionário contém os campos adicionados de dataset e lustreFileSystemPath. O conjunto de dados é usado para especificar o URI S3 de conexão para o Luster se conectar. O lustreFileSystemPath A variável é usada como um mapeamento de como o usuário deseja que esse conjunto de dados seja mapeado localmente no sistema de arquivos do trabalhador. Veja o seguinte código:
Publique dinamicamente o IP do agendador
Um desafio inerente à natureza cross-regional deste projeto foi manter uma conexão dinâmica entre os trabalhadores Dask e o agendador. Como poderíamos publicar um endereço IP, que é capaz de mudar, nas regiões da AWS? Conseguimos isso com o uso de Mapa da Nuvem AWS e associar-vpc-com-zona-hospedada. O serviço abstrai permitindo que a AWS gerencie esse namespace DNS de forma privada. Veja o seguinte código:
IU do notebook Jupyter
O notebook Jupyter hospedado no SageMaker fornece aos cientistas um ambiente pronto para implantação para conectar e experimentar facilmente os conjuntos de dados carregados. Nós usamos um script de configuração do ciclo de vida para fornecer ao notebook um ambiente de desenvolvedor pré-configurado e uma base de código de exemplo. Veja o seguinte código:
Nós de trabalho do Dask
Quando se trata dos Dask workers, é fornecida maior personalização, mais especificamente no tipo de instância, threads por contêiner e alarmes de escala. Por padrão, os trabalhadores provisionam no tipo de instância m5d.4xlarge, montam no sistema de arquivos Lustre na inicialização e subdividem seus trabalhadores e encadeamentos dinamicamente nas portas. Tudo isso é opcionalmente personalizável. Veja o seguinte código:
Performance
Para avaliar o desempenho, usamos um cálculo de amostra e plotagem da temperatura do ar a 2 metros com base na diferença entre a previsão CMIP6 para um mês e a temperatura média do ar ERA5 para 10 anos. Definimos uma referência de dois trabalhadores em cada região e avaliamos a diferença na redução de tempo à medida que trabalhadores adicionais foram adicionados. Em teoria, à medida que a solução escala, deve haver uma diferença material produtiva na redução do tempo total.
A tabela a seguir resume os detalhes do nosso conjunto de dados.
| Conjunto de dados | Variáveis | Tamanho do disco | Tamanho do Conjunto de Dados Xarray | Região |
| ERA5 | 2011–2020 (120 arquivos netcdf) | 53.5GB | 364.1 GB | us-leste-1 |
| CMIP6 | 1.13GB | 0.11 GB | nós-oeste-2 |
A tabela a seguir mostra os resultados coletados, mostrando o tempo (em segundos) para cada cálculo e previsão em três estágios na computação de previsão CMIP6, ERA5 e diferença.
| . | . | Número de Trabalhadores | |||
| Computar | Região | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
nós-oeste-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
us-leste-1 | 1512 | 711 | 427 | 202 |
Diferença (propogated pool) |
nós-oeste-2 e nós-leste-1 | 1527 | 906 | 469 | 251 |
O gráfico a seguir visualiza o desempenho e a escala.
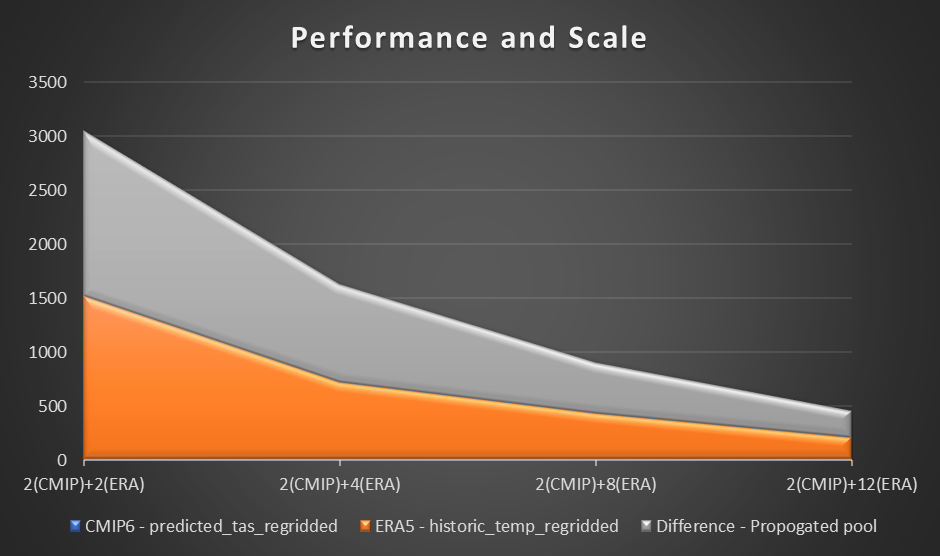
Em nosso experimento, observamos uma melhoria linear na computação para o conjunto de dados ERA5 à medida que o número de trabalhadores aumentava. À medida que o número de trabalhadores aumentava, os tempos de computação às vezes eram reduzidos pela metade.
Caderno Jupyter
Como parte do lançamento da solução, implantamos um notebook Jupyter pré-configurado para ajudar a testar a solução Dask entre regiões. O notebook demonstra a eliminação da preocupação de precisar saber a localização regional dos conjuntos de dados, em vez de consultar um catálogo por meio de uma série de notebooks Jupyter executados em segundo plano.
Para começar, siga as instruções nesta seção.
O código para os notebooks pode ser encontrado em lib/SagemakerCode com o notebook principal sendo ux_notebook.ipynb. Este notebook chama outros notebooks, acionando scripts auxiliares. ux_notebook é projetado para ser o ponto de entrada para cientistas, sem a necessidade de ir a outro lugar.
Para começar, abra este notebook no SageMaker depois de implantar o AWS CDK. O AWS CDK cria uma instância de notebook com todos os arquivos no repositório carregados e com backup em um AWS CodeCommit repositório.
Para executar o aplicativo, abra e execute a primeira célula do ux_notebook. Esta célula executa o get_variables notebook em segundo plano, que solicita uma entrada para os dados que você gostaria de selecionar. Incluímos um exemplo; no entanto, observe que as perguntas só aparecerão depois que a opção anterior for selecionada. Isso é intencional para limitar as opções suspensas e é opcionalmente configurável editando o get_variables notebook.
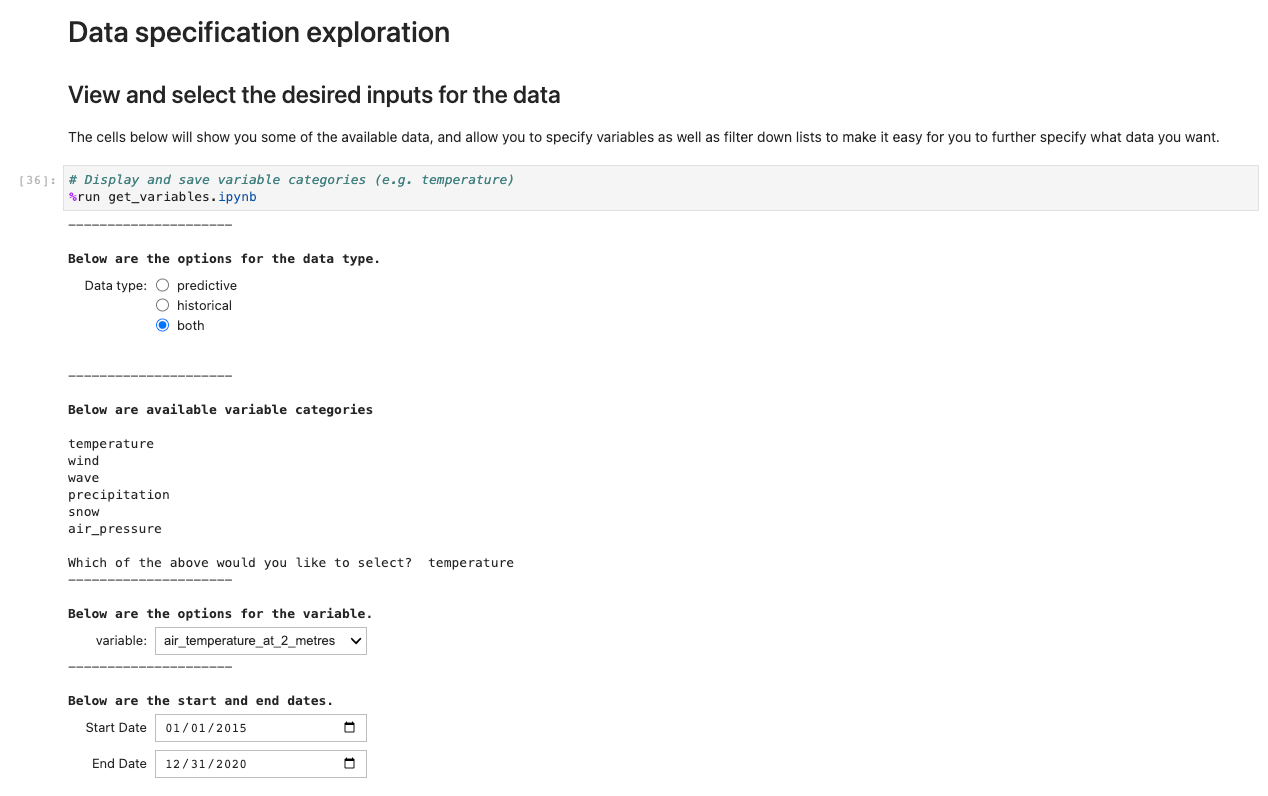
O código anterior armazena variáveis globalmente para que outros notebooks possam recuperar e carregar sua seleção de opções. Para demonstração, a próxima célula deve gerar as variáveis salvas de antes.
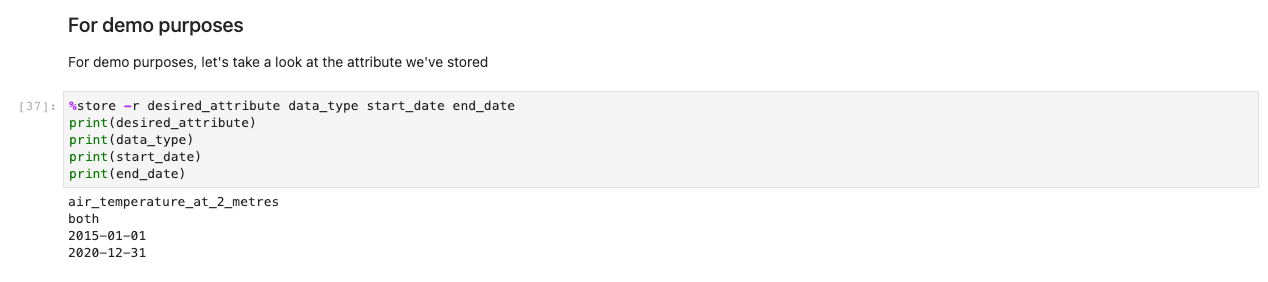
Em seguida, aparece um prompt para mais especificações de dados. Essa célula refina os dados que você procura apresentando os IDs das tabelas em formato legível por humanos. Os usuários selecionam como se fosse um formulário, mas os títulos são mapeados para tabelas em segundo plano que ajudam o sistema a recuperar os conjuntos de dados apropriados.
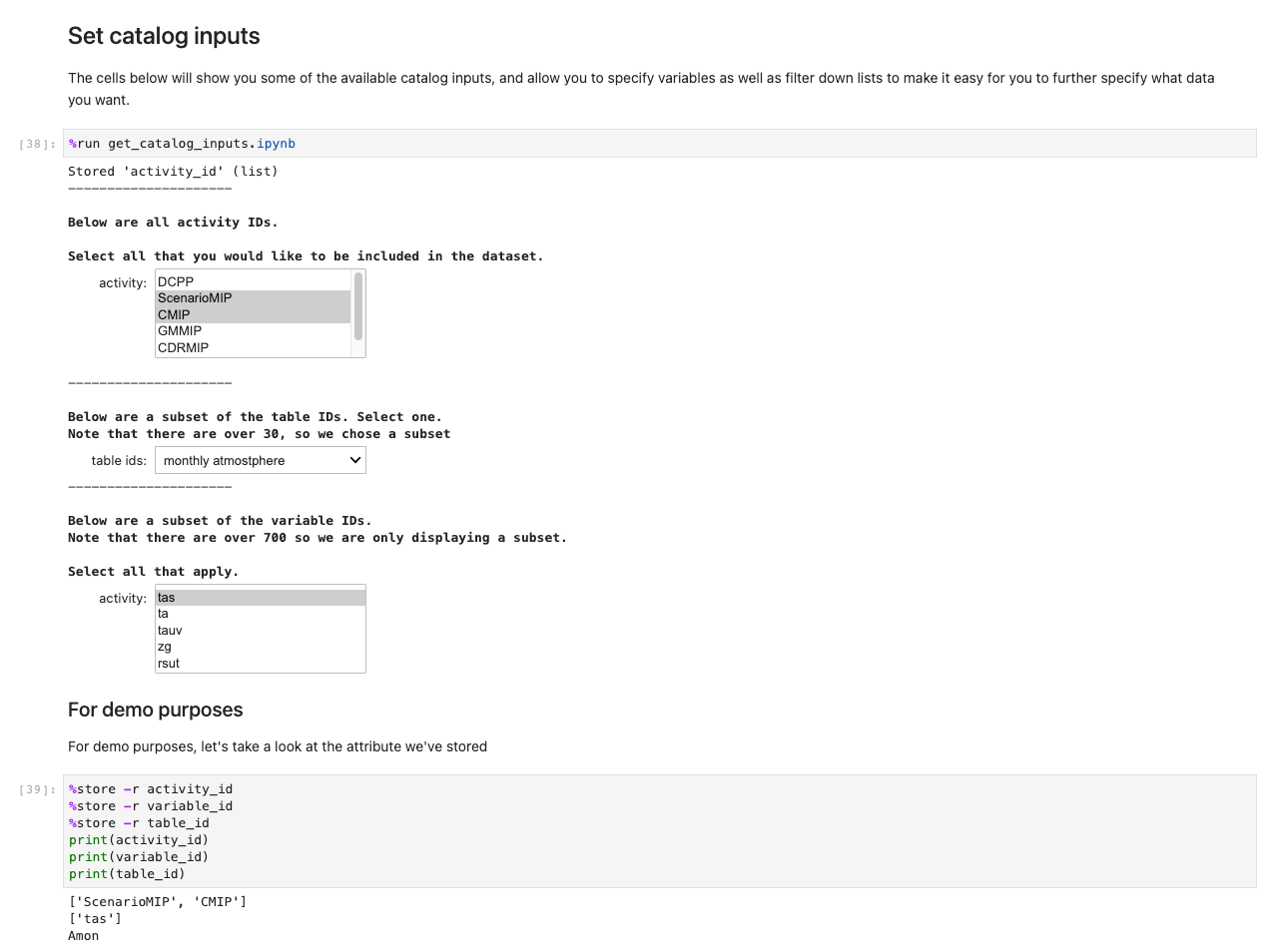
Depois de armazenar todas as suas opções e células de seleção, carregue os dados nas Regiões executando a célula no Obtendo os dados conjunto seção. O comando %%capture suprimirá saídas desnecessárias do get_data caderno. Observe que você pode removê-lo para inspecionar as saídas de outros notebooks. Os dados são então recuperados no back-end.
Enquanto outros notebooks estão sendo executados em segundo plano, o único ponto de contato para o usuário é o ux_notebook. Isso é para abstrair o tedioso processo de importação de dados em um formato que qualquer usuário possa seguir com facilidade.
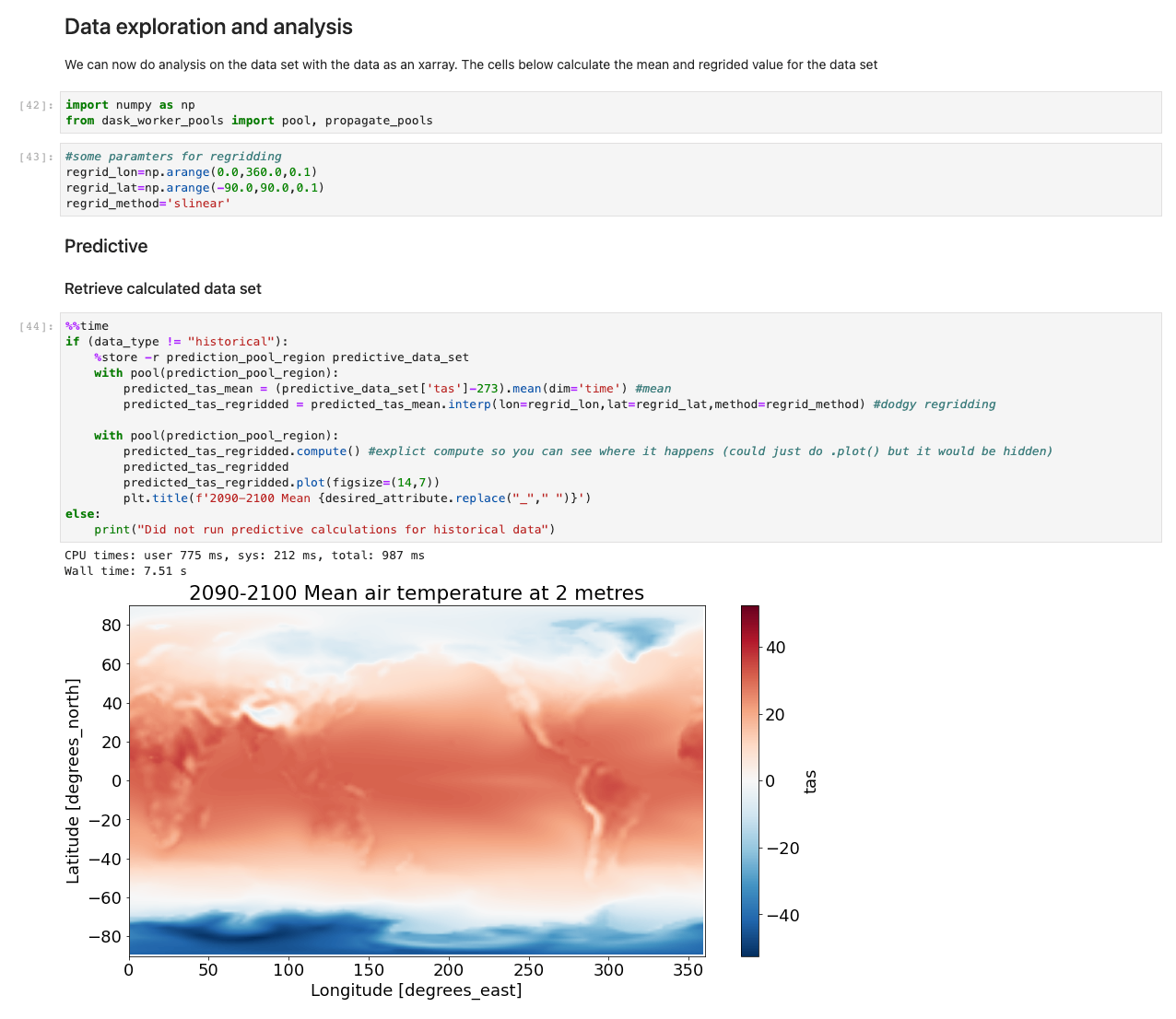
Com os dados agora carregados, podemos começar a interagir com eles. As células a seguir são exemplos de cálculos que você pode executar em dados meteorológicos. Usando matrizes x, importamos, calculamos e plotamos esses conjuntos de dados.
Nosso exemplo ilustra um gráfico de dados preditivos recuperando dados, executando a computação e plotando os resultados em menos de 7.5 segundos - ordens de magnitude mais rápidas do que uma abordagem típica.
Sob o capô
Os cadernos get_catalog_input e get_variables usar a biblioteca ipywidgets para exibir widgets como menus suspensos e seleções de várias caixas. Essas opções são salvas globalmente usando o comando %%store para que possam ser acessadas a partir do ux_notebook. Uma das opções pergunta se você deseja dados históricos, dados preditivos ou ambos. Esta variável é passada para o get_data notebook para determinar quais notebooks subsequentes serão executados.
A get_data notebook primeiro recupera o domínio do OpenSearch Service compartilhado salvo em Armazenamento de parâmetros do AWS Systems Manager. Este domínio permite que nosso notebook execute uma consulta na coleta de informações que indicará onde os conjuntos de dados selecionados estão armazenados Regionalmente. Com esses conjuntos de dados localizados Regionalmente, o notebook fará uma tentativa de conexão com o agendador Dask, passando as informações coletadas do Serviço OpenSearch. O agendador Dask, por sua vez, poderá chamar trabalhadores nas regiões corretas.
Como personalizar e continuar o desenvolvimento
Esses notebooks devem ser um exemplo de como você pode criar uma maneira de os usuários interagirem com os dados. O notebook nesta postagem serve como uma ilustração do que é possível, e convidamos você a continuar desenvolvendo a solução para melhorar ainda mais o envolvimento do usuário. A parte principal dessa solução é a tecnologia de back-end, mas sem algum mecanismo para interagir com esse back-end, os usuários não perceberão todo o potencial da solução.
Para evitar cobranças futuras, exclua os recursos. Vamos destruir nossa solução implantada com o seguinte comando:
Conclusão
Esta postagem mostra a extensão do Dask inter-regionalmente na AWS e uma possível integração com conjuntos de dados públicos na AWS. A solução foi criada como um padrão genérico e outros conjuntos de dados podem ser carregados para acelerar análises de E/S altas em dados complexos.
Os dados estão transformando todos os campos e todos os negócios. No entanto, com os dados crescendo mais rápido do que a maioria das empresas pode acompanhar, coletar dados e obter valor desses dados é um desafio. Uma estratégia de dados moderna pode ajudá-lo a criar melhores resultados de negócios com dados. A AWS fornece o conjunto mais completo de serviços para a jornada de dados de ponta a ponta para ajudá-lo a extrair valor de seus dados e transformá-los em insights.
Para saber mais sobre as várias formas de usar seus dados na nuvem, acesse o Blog de Big Data da AWS. Além disso, convidamos você a comentar com seus pensamentos sobre esta postagem e se esta é uma solução que você planeja experimentar.
Sobre os autores
 Patrick O'Connor é um engenheiro de prototipagem da WWSO baseado em Londres. Ele é um solucionador de problemas criativo, adaptável em uma ampla gama de tecnologias, como IoT, tecnologia sem servidor, tecnologia espacial 3D e ML/AI, juntamente com uma curiosidade incansável sobre como a tecnologia pode continuar a evoluir nas abordagens cotidianas.
Patrick O'Connor é um engenheiro de prototipagem da WWSO baseado em Londres. Ele é um solucionador de problemas criativo, adaptável em uma ampla gama de tecnologias, como IoT, tecnologia sem servidor, tecnologia espacial 3D e ML/AI, juntamente com uma curiosidade incansável sobre como a tecnologia pode continuar a evoluir nas abordagens cotidianas.
 Chakra Nagarajan é uma Principal SA de prototipagem de aprendizado de máquina com 21 anos de experiência em aprendizado de máquina, big data e computação de alto desempenho. Em sua função atual, ele ajuda os clientes a resolver problemas de negócios complexos do mundo real, criando protótipos com soluções de IA/ML de ponta a ponta em dispositivos de nuvem e periféricos. Sua especialização em ML inclui visão computacional, processamento de linguagem natural, previsão de séries temporais e personalização.
Chakra Nagarajan é uma Principal SA de prototipagem de aprendizado de máquina com 21 anos de experiência em aprendizado de máquina, big data e computação de alto desempenho. Em sua função atual, ele ajuda os clientes a resolver problemas de negócios complexos do mundo real, criando protótipos com soluções de IA/ML de ponta a ponta em dispositivos de nuvem e periféricos. Sua especialização em ML inclui visão computacional, processamento de linguagem natural, previsão de séries temporais e personalização.
 Val Cohen é um engenheiro sênior de prototipagem da WWSO baseado em Londres. Solucionadora de problemas por natureza, Val gosta de escrever código para automatizar processos, criar ferramentas obcecadas pelo cliente e criar infraestrutura para vários aplicativos para sua base global de clientes. Val tem experiência em uma ampla variedade de tecnologias, como desenvolvimento web front-end, trabalho back-end e AI/ML.
Val Cohen é um engenheiro sênior de prototipagem da WWSO baseado em Londres. Solucionadora de problemas por natureza, Val gosta de escrever código para automatizar processos, criar ferramentas obcecadas pelo cliente e criar infraestrutura para vários aplicativos para sua base global de clientes. Val tem experiência em uma ampla variedade de tecnologias, como desenvolvimento web front-end, trabalho back-end e AI/ML.
 Niall Robinson é chefe de futuros de produtos no UK Met Office. Ele e sua equipe exploram novas maneiras de o Met Office agregar valor por meio da inovação de produtos e parcerias estratégicas. Ele teve uma carreira variada, liderando uma equipe multidisciplinar de P&D em informática, pesquisa acadêmica em ciência de dados e cientista de campo, além de experiência em modelagem climática.
Niall Robinson é chefe de futuros de produtos no UK Met Office. Ele e sua equipe exploram novas maneiras de o Met Office agregar valor por meio da inovação de produtos e parcerias estratégicas. Ele teve uma carreira variada, liderando uma equipe multidisciplinar de P&D em informática, pesquisa acadêmica em ciência de dados e cientista de campo, além de experiência em modelagem climática.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :tem
- :é
- :onde
- $UP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- habilidade
- Capaz
- Sobre
- acima
- RESUMO
- resumos
- acadêmico
- pesquisa acadêmica
- acelerar
- acelerando
- Acesso
- acessadas
- acomodar
- realizar
- Conta
- Alcança
- em
- adapta
- adicionado
- acrescentando
- Adicional
- Adicionalmente
- endereço
- endereçando
- Adiciona
- administradores
- adotado
- Adoção
- Depois de
- AI / ML
- AR
- Todos os Produtos
- Permitindo
- permite
- juntamente
- tb
- Amazon
- Amazon EC2
- an
- análise
- e
- qualquer
- aparecer
- Aplicação
- aplicações
- abordagem
- se aproxima
- apropriado
- arquitetura
- SOMOS
- AS
- At
- Atmosfera
- atmosférico
- automatizar
- evitar
- AWS
- Cliente AWS
- Espinha dorsal
- Apoiado
- Backend
- fundo
- Equilíbrio
- base
- baseado
- BE
- tornam-se
- sido
- antes
- ser
- abaixo
- referência
- Melhor
- entre
- Grande
- Big Data
- Bootstrap
- ambos
- Trazendo
- Quebrado
- construir
- Prédio
- construído
- construídas em
- negócio
- mas a
- by
- calcular
- chamada
- chamado
- chamada
- chamadas
- CAN
- capacidades
- capaz
- Oportunidades
- catálogo
- CD
- Células
- desafiar
- desafiante
- alterar
- mudança
- carregar
- acusações
- escolhas
- Circulação
- cliente
- Clima
- mais próximo
- Na nuvem
- Agrupar
- CO
- código
- base de código
- colaboração
- Coleta
- como
- vem
- vinda
- comentar
- comunidade
- Empresas
- completar
- integrações
- componentes
- Composto
- computação
- Computar
- computador
- Visão de Computador
- computação
- Configuração
- Contato
- conectado
- Conexão de
- da conexão
- Consumidores
- consumo
- Recipiente
- contém
- continuar
- continua
- cópias
- núcleo
- correta
- Custo
- relação custo-benefício
- poderia
- acoplado
- CPU
- crio
- cria
- Criatividade
- crítico
- colheita
- Atravessar
- curiosidade
- Atual
- personalizadas
- cliente
- Clientes
- personalizável
- personalizar
- diariamente
- painel de instrumentos
- dados,
- ciência de dados
- estratégia de dados
- conjuntos de dados
- dia
- década
- decisões
- Padrão
- Demanda
- demonstra
- implantar
- implantado
- desenvolvimento
- implanta
- projetado
- destruir
- detalhado
- detalhes
- Determinar
- desenvolver
- Developer
- Desenvolvimento
- Dispositivos/Instrumentos
- diferença
- inválido
- descoberta
- Ecrã
- distribuído
- computação distribuída
- dns
- Estivador
- domínio
- down
- dinâmico
- dinamicamente
- cada
- facilidade
- facilmente
- borda
- edição
- eficiente
- em outro lugar
- permitir
- end-to-end
- energia
- COMPROMETIMENTO
- engenheiro
- entrada
- Meio Ambiente
- Equivalente
- Era
- estimado
- Éter (ETH)
- Cada
- todo dia
- cotidiano
- evolui
- exemplo
- exemplos
- vasta experiência
- experimentar
- experiência
- explorar
- exportar
- exposto
- extensão
- mais rápido
- Característica
- Funcionalidades
- campo
- Campos
- Envie o
- Arquivos
- Encontre
- Primeiro nome
- concentra-se
- seguir
- seguinte
- comida
- Escolha
- formulário
- formato
- formas
- encontrado
- Fundado
- Quadro
- enquadramentos
- Gratuito
- da
- fruição
- cheio
- funcionalidade
- mais distante
- futuro
- futuros
- Geral
- geração
- ter
- obtendo
- Git
- Global
- rede global
- Globalmente
- globo
- vai
- gráfico
- maior
- Grade
- Cresça:
- Crescente
- tinha
- Metade
- reduziu para metade
- Ter
- he
- cabeça
- ajudar
- ajuda
- sua experiência
- Alta
- alta performance
- destaques
- sua
- histórico
- hospedeiro
- hospedado
- hora
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- legível para humanos
- Centenas
- inativo
- ids
- if
- ilustra
- importar
- importador
- melhorar
- melhoria
- in
- incluir
- inclui
- aumentou
- índice
- indicam
- informar
- INFORMAÇÕES
- Infraestrutura
- inerente
- Inovação
- entrada
- insegurança
- introspecção
- inspirado
- instalar
- instância
- em vez disso
- instruções
- integração
- Intencional
- interagir
- interagindo
- Interface
- interno
- Internet
- para dentro
- convidar
- iot
- IP
- Endereço IP
- questões
- IT
- ESTÁ
- Trabalho
- viagem
- jpg
- Caderno Jupyter
- Guarda
- Chave
- Saber
- língua
- grande
- Sobrenome
- Latência
- lançamento
- principal
- APRENDER
- aprendizagem
- Biblioteca
- wifecycwe
- como
- vinculação
- Lista
- carregar
- local
- localmente
- localizado
- localização
- London
- máquina
- aprendizado de máquina
- principal
- fazer
- gerencia
- Gerente
- gestão
- mapa,
- mapeamento
- Massa
- Adoção em massa
- material
- Posso..
- significar
- mecanismo
- metadados
- milhões
- ML
- modelo
- EQUIPAMENTOS
- Módulos
- Mês
- mensal
- dados mensais
- mais
- a maioria
- MONTE
- multidisciplinar
- nome
- Nacional
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Natureza
- necessário
- você merece...
- necessitando
- rede
- Novo
- Próximo
- noite
- nó
- nós
- caderno
- laptops
- agora
- número
- números
- of
- oferecer
- Office
- on
- ONE
- só
- aberto
- dados abertos
- open source
- código-fonte aberto
- operacional
- Opção
- Opções
- or
- orquestração
- organizações
- Outros
- A Nossa
- Fora
- resultados
- saída
- Acima de
- global
- pacote
- parâmetro
- parte
- particular
- particularmente
- parcerias
- passou
- Passagem
- padrão
- atuação
- períodos
- Personalização
- petabyte
- fase
- plano
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- piscina
- portas
- possível
- Publique
- potencial
- poder
- poderoso
- prática
- predição
- Previsões
- pré-requisitos
- anterior
- primário
- Diretor
- privado
- Problema
- problemas
- processo
- processos
- em processamento
- Produzido
- Produto
- Inovação de Produto
- produtivo
- Agenda
- Programação
- projeto
- protótipos
- prototipagem
- fornecer
- fornecido
- fornece
- provisão
- público
- publicar
- publicado
- Pullover
- consultas
- Frequentes
- R & D
- alcance
- em vez
- ready-made
- mundo real
- perceber
- reduzir
- redução
- redução
- região
- regional
- regiões
- implacável
- permanece
- remover
- Removido
- repositório
- representa
- pesquisa
- Recursos
- aqueles
- Resultados
- Tipo
- Execute
- corrida
- SA
- seguro
- sábio
- mesmo
- Salvar
- escalável
- Escala
- Escalas
- dimensionamento
- Ciência
- Cientista
- cientistas
- Scripts
- segundo
- Seção
- Vejo
- visto
- segmentos
- selecionado
- doadores,
- senior
- Série
- Serverless
- serve
- serviço
- Serviços
- conjunto
- Partilhar
- compartilhado
- rede de apoio social
- mostrar
- apresentando
- Shows
- simples
- simplesmente
- sexto
- lento
- So
- solução
- Soluções
- RESOLVER
- alguns
- fonte
- Espacial
- especificamente
- especificações
- especificada
- de patrocínio
- pilha
- Estágio
- autônoma
- começo
- começado
- ficar
- Passos
- armazenamento
- loja
- armazenadas
- lojas
- franco
- Estratégico
- Parcerias estratégicas
- Estratégia
- subseqüente
- Subseqüentemente
- bem sucedido
- tal
- superfície
- surge
- Sustentabilidade
- sustentável
- .
- sistemas
- mesa
- Tire
- Profissionais
- tecnologia
- Tecnologias
- Tecnologia
- teste
- do que
- que
- A
- as informações
- A fonte
- do Reino Unido
- o mundo
- deles
- então
- Lá.
- assim
- Este
- deles
- isto
- aqueles
- três
- Prosperar
- Através da
- Taxa de transferência
- tempo
- Séries temporais
- vezes
- títulos
- para
- hoje
- juntos
- ferramentas
- pista
- Rastreamento
- transferência
- transformando
- trânsito
- desencadeando
- VIRAR
- dois
- tipo
- Datilografado
- típico
- Uk
- para
- destravar
- insustentável
- que vai mais à frente
- Atualizações
- sobre
- URI
- Uso
- usar
- usava
- Utilizador
- usuários
- utilização
- UTC
- Utilizando
- VAL
- valor
- variedade
- vário
- via
- visão
- Visite a
- volume
- queremos
- quer
- quente
- foi
- Caminho..
- maneiras
- we
- Clima
- web
- Desenvolvimento web
- foram
- se
- qual
- Largo
- Ampla variedade
- precisarão
- desejos
- de
- sem
- Atividades:
- trabalhador
- trabalhadores
- mundo
- preocupar-se
- seria
- escrita
- anos
- ainda
- Produção
- Você
- investimentos
- zefirnet