O valor dos dados é sensível ao tempo. O processamento em tempo real torna as decisões baseadas em dados precisas e acionáveis em segundos ou minutos, em vez de horas ou dias. A captura de dados de alteração (CDC) refere-se ao processo de identificação e captura de alterações feitas nos dados em um banco de dados e, em seguida, entrega dessas alterações em tempo real para um sistema downstream. Capturar todas as alterações de transações em um banco de dados de origem e movê-las para o destino em tempo real mantém os sistemas sincronizados e ajuda com casos de uso de análise em tempo real e migrações de banco de dados sem tempo de inatividade. A seguir estão alguns benefícios do CDC:
- Ele elimina a necessidade de atualização de carregamento em massa e janelas de lote inconvenientes, permitindo carregamento incremental ou streaming em tempo real de alterações de dados em seu repositório de destino.
- Ele garante que os dados em vários sistemas permaneçam sincronizados. Isso é especialmente importante se você estiver tomando decisões urgentes em um ambiente de dados de alta velocidade.
Conexão Kafka é um componente de código aberto do Apache Kafka que funciona como um hub de dados centralizado para integração de dados simples entre bancos de dados, armazenamentos de valor-chave, índices de pesquisa e sistemas de arquivos. O Registro de esquema AWS Glue permite que você descubra, controle e evolua centralmente os esquemas de fluxo de dados. Kafka Connect e Schema Registry se integram para capturar informações de esquema de conectores. O Kafka Connect fornece um mecanismo para converter dados dos tipos de dados internos usados pelo Kafka Connect em tipos de dados representados como Avro, Protobuf ou JSON Schema. AvroConverter, ProtobufConverter e JsonSchemaConverter registram automaticamente esquemas gerados por conectores Kafka (origem) que produzem dados para Kafka. Os conectores (sink) que consomem dados do Kafka recebem informações de esquema além dos dados de cada mensagem. Isso permite que os conectores de coletor conheçam a estrutura dos dados para fornecer recursos como manter um esquema de tabela de banco de dados em um catálogo de dados.
A postagem demonstra como criar um CDC de ponta a ponta usando Amazon MSK Conectar, um serviço gerenciado pela AWS para implantar e executar aplicativos Kafka Connect e AWS Glue Schema Registry, que permite descobrir, controlar e desenvolver esquemas de fluxo de dados centralmente.
Visão geral da solução
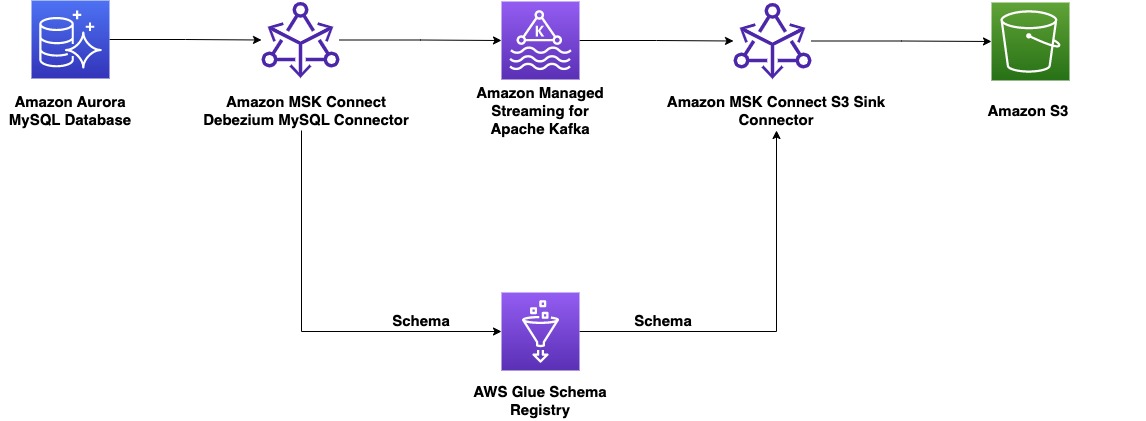
Do lado do produtor, para este exemplo, escolhemos um compatível com MySQL Aurora Amazônica banco de dados como a fonte de dados, e temos um Debézium Conector MySQL para executar CDC. O conector Debezium monitora continuamente os bancos de dados e envia alterações em nível de linha para um tópico Kafka. O conector busca o esquema do banco de dados para serializar os registros em um formato binário. Se o esquema ainda não existir no registro, ele será registrado. Se o esquema existir, mas o serializador estiver usando uma nova versão, o registro do esquema verificará o modo de compatibilidade do esquema antes de atualizar o esquema. Nesta solução, usamos modo de compatibilidade com versões anteriores. O registro do esquema retorna um erro se uma nova versão do esquema não for compatível com versões anteriores e podemos configurar o Kafka Connect para enviar mensagens incompatíveis para a fila de mensagens mortas.
Do lado do consumidor, usamos um Serviço de armazenamento simples da Amazon (Amazon S3) coletor coletor para desserializar o registro e armazenar alterações no Amazon S3. Construímos e implantamos o conector Debezium e o coletor Amazon S3 usando o MSK Connect.
esquema de exemplo
Para este post, usamos o seguinte esquema como primeira versão da tabela:
Pré-requisitos
Antes de configurar os conectores MSK produtor e consumidor, precisamos primeiro configurar uma fonte de dados, um cluster MSK e um novo registro de esquema. Nós fornecemos um Formação da Nuvem AWS modelo para gerar os recursos de suporte necessários para a solução:
- Um banco de dados Aurora compatível com MySQL como fonte de dados. Para executar o CDC, ativamos o log binário no Grupo de parâmetros do cluster de banco de dados.
- Um cluster MSK. Para simplificar a conexão de rede, usamos o mesmo VPC para o banco de dados Aurora e o cluster MSK.
- Dois registros de esquema para manipular esquemas para chave de mensagem e valor de mensagem.
- Um bucket S3 como coletor de dados.
- Plugins do MSK Connect e configuração de trabalho necessários para esta demonstração.
- completa Amazon Elastic Compute Nuvem (Amazon EC2) para executar comandos de banco de dados.
Para configurar recursos em sua conta da AWS, conclua as etapas a seguir em uma região da AWS compatível com Amazon MSK, MSK Connect e AWS Glue Schema Registry:
- Escolha Pilha de Lançamento:
- Escolha Próximo.
- Escolha Nome da pilha, digite o nome adequado.
- Escolha Senha do banco de dados, insira a senha que deseja para o usuário do banco de dados.
- Mantenha outros valores como padrão.
- Escolha Próximo.
- Na próxima página, escolha Próximo.
- Revise os detalhes na página final e selecione Reconheço que o AWS CloudFormation pode criar recursos do IAM.
- Escolha Criar pilha.
Plug-in personalizado para o conector de origem e destino
Um plug-in customizado é um conjunto de arquivos JAR que contém a implementação de um ou mais conectores, transformações ou conversores. O Amazon MSK instalará o plug-in nos trabalhadores do cluster MSK Connect em que o conector está em execução. Como parte desta demonstração, para o conector de origem, usamos código aberto JARs do conector MySQL Debezium, e para o conector de destino, usamos a comunidade Confluent licenciada JARs do conector de coletor do Amazon S3. Ambos os plugins também são adicionados com bibliotecas para Serializadores e desserializadores Avro do registro de esquema do AWS Glue. Esses plug-ins personalizados já foram criados como parte do modelo CloudFormation implantado na etapa anterior.
Use o AWS Glue Schema Registry com o conector Debezium no MSK Connect como o produtor MSK
Primeiro implantamos o conector de origem usando o plug-in Debezium MySQL para transmitir dados de um Edição compatível com o Amazon Aurora MySQL banco de dados para o Amazon MSK. Conclua as seguintes etapas:
- No console do Amazon MSK, no painel de navegação, em Conexão MSK, escolha conectores.
- Escolha Criar conector.
- Escolha Usar plug-in personalizado existente e, em seguida, escolha o plug-in personalizado com o nome começando
msk-blog-debezium-source-plugin. - Escolha Próximo.
- Digite um nome adequado como
debezium-mysql-connectore uma descrição opcional. - Escolha Cluster do Apache Kafka, escolha Cluster MSK e escolha o cluster criado pelo modelo CloudFormation.
- In Configuração do conector, exclua os valores padrão e use os seguintes pares de chave-valor de configuração e com os valores apropriados:
- nome – O nome usado para o conector.
- banco de dados.hostsname – A saída do CloudFormation para Terminal de banco de dados.
- banco de dados.usuário e banco de dados.senha – Os parâmetros passados no modelo CloudFormation.
- banco de dados.history.kafka.bootstrap.servers – A saída do CloudFormation para Kafka Bootstrap.
- key.converter.region e value.converter.region – Sua região.
Algumas dessas configurações são genéricas e devem ser especificadas para qualquer conector. Por exemplo:
- conector.class é a classe Java do conector
- tasks.max é o número máximo de tarefas que devem ser criadas para este conector
Algumas configurações (database.*, transforms.*) são específicos para o conector Debezium MySQL. Referir-se Propriedades de configuração do conector de origem MySQL do Debezium para obter mais informações.
Algumas configurações (key.converter.* e value.converter.*) são específicos para o Schema Registry. Nós usamos o AWSKafkaAvroConverter do Biblioteca de registro de esquema do AWS Glue como o conversor de formato. Para configurar AWSKafkaAvroConverter, usamos o valor das propriedades da string constante no AWSSchemaRegistryConstantes classe:
key.converterevalue.convertercontrolar o formato dos dados que serão gravados no Kafka para conectores de origem ou lidos do Kafka para conectores de coletor. Nós usamosAWSKafkaAvroConverterpara o formato Avro.key.converter.registry.nameevalue.converter.registry.namedefinir qual registro de esquema usar.key.converter.compatibilityevalue.converter.compatibilitydefinir o modelo de compatibilidade.
Consulte Usando o Kafka Connect com o AWS Glue Schema Registry para obter mais informações.
- A seguir, configuramos Capacidade do conector. podemos escolher Provisionado e deixar outras propriedades como padrão
- Escolha configuração do trabalhador, escolha a configuração personalizada do worker com o nome começando
msk-gsr-blogcriado como parte do modelo CloudFormation. - Escolha Permissões de acesso, Utilize o Gerenciamento de acesso e identidade da AWS (IAM) função gerada pelo modelo CloudFormation
MSKConnectRole. - Escolha Próximo.
- Escolha Segurança, escolha os padrões.
- Escolha Próximo.
- Escolha Log de entrega, selecione Entregue no Amazon CloudWatch Logs e procure o grupo de logs criado pelo modelo do CloudFormation (
msk-connector-logs). - Escolha Próximo.
- Revise as configurações e escolha Criar conector.
Após alguns minutos, o conector muda para o status de execução.
Use o AWS Glue Schema Registry com o conector do coletor Confluent S3 em execução no MSK Connect como o consumidor MSK
Implantamos o conector de coletor usando o plug-in de coletor Confluent S3 para transmitir dados do Amazon MSK para o Amazon S3. Conclua as seguintes etapas:
-
- No console do Amazon MSK, no painel de navegação, em Conexão MSK, escolha conectores.
- Escolha Criar conector.
- Escolha Usar plug-in personalizado existente e escolha o plug-in personalizado com o nome começando
msk-blog-S3sink-plugin. - Escolha Próximo.
- Digite um nome adequado como
s3-sink-connectore uma descrição opcional. - Escolha Cluster do Apache Kafka, escolha Cluster MSK e selecione o cluster criado pelo modelo CloudFormation.
- In Configuração do conector, exclua os valores padrão fornecidos e use os seguintes pares de valor-chave de configuração com os valores apropriados:
-
- nome – O mesmo nome usado para o conector.
- s3.bucket.nome – A saída do CloudFormation para Nome do intervalo.
- s3.region, key.converter.region e value.converter.region – Sua região.
-
- A seguir, configuramos Capacidade do conector. podemos escolher Provisionado e deixar outras propriedades como padrão
- Escolha configuração do trabalhador, escolha a configuração personalizada do worker com o nome começando
msk-gsr-blogcriado como parte do modelo CloudFormation. - Escolha Permissões de acesso, use a função IAM gerada pelo modelo CloudFormation
MSKConnectRole. - Escolha Próximo.
- Escolha Segurança, escolha os padrões.
- Escolha Próximo.
- Escolha Log de entrega, selecione Entregue no Amazon CloudWatch Logs e procure o grupo de logs criado pelo modelo CloudFormation
msk-connector-logs. - Escolha Próximo.
- Revise as configurações e escolha Criar conector.
Após alguns minutos, o conector está funcionando.
Testar o fluxo de logs do CDC de ponta a ponta
Agora que os conectores de coletor Debezium e S3 estão funcionando, conclua as etapas a seguir para testar o CDC de ponta a ponta:
- No console do Amazon EC2, navegue até o Grupos de segurança Disputas de Comerciais.
- Selecione o grupo de segurança
ClientInstanceSecurityGroupe escolha Editar regras de entrada. - Adicione uma regra de entrada que permita a conexão SSH de sua rede local.
- No Instâncias página, selecione a instância
ClientInstancee escolha Contato. - No Conexão de instância EC2 guia, escolha Contato.
- Certifique-se de que seu diretório de trabalho atual seja
/home/ec2-usere tem os arquivoscreate_table.sql,alter_table.sql,initial_insert.sqleinsert_data_with_new_column.sql. - Crie uma tabela em seu banco de dados MySQL executando o seguinte comando (forneça o nome do host do banco de dados nas saídas do modelo CloudFormation):
- Quando uma senha for solicitada, insira-a nos parâmetros de modelo do CloudFormation.
- Insira alguns dados de amostra na tabela com o seguinte comando:
- Quando uma senha for solicitada, insira-a nos parâmetros de modelo do CloudFormation.
- No console AWS Glue, escolha Registros de esquema no painel de navegação e escolha Esquemas.
- Navegar para
db1.sampledatabase.moviesversão 1 para verificar o novo esquema criado para a tabela de filmes:
Uma pasta separada do S3 é criada para cada partição do tópico Kafka e os dados do tópico são gravados nessa pasta.
- No console do Amazon S3, verifique os dados gravados no formato Parquet na pasta do seu tópico Kafka.
Evolução do esquema
Depois que o esquema inicial é definido, os aplicativos podem precisar evoluí-lo ao longo do tempo. Quando isso acontece, é fundamental que os consumidores downstream sejam capazes de manipular os dados codificados com o esquema antigo e o novo perfeitamente. Os modos de compatibilidade permitem que você controle como os esquemas podem ou não evoluir ao longo do tempo. Esses modos formam o contrato entre os aplicativos que produzem e consomem dados. Para obter informações detalhadas sobre os diferentes modos de compatibilidade disponíveis no AWS Glue Schema Registry, consulte Registro de esquema AWS Glue. Em nosso exemplo, usamos a combinação reversa para garantir que os consumidores possam ler as versões de esquema atual e anterior. Conclua as seguintes etapas:
- Adicione uma nova coluna à tabela executando o seguinte comando:
- Insira novos dados na tabela executando o seguinte comando:
- No console AWS Glue, escolha Registros de esquema no painel de navegação e escolha Esquemas.
- Navegue até o esquema
db1.sampledatabase.moviesversão 2 para verificar a nova versão do esquema criado para a tabela de filmes filmes incluindo a coluna de país que você adicionou:
- No console do Amazon S3, verifique os dados gravados no formato Parquet na pasta do tópico Kafka.
limpar
Para ajudar a evitar cobranças indesejadas em sua conta da AWS, exclua os recursos da AWS que você usou nesta postagem:
- No console do Amazon S3, navegue até o bucket S3 criado pelo modelo CloudFormation.
- Selecione todos os arquivos e pastas e escolha Apagar.
- Insira excluir permanentemente conforme as instruções e escolha Excluir objetos.
- No console do AWS CloudFormation, exclua a pilha que você criou.
- Aguarde até que o status da pilha mude para DELETE_COMPLETE.
Conclusão
Esta postagem demonstrou como usar o Amazon MSK, o MSK Connect e o AWS Glue Schema Registry para criar um fluxo de log do CDC e desenvolver esquemas para fluxos de dados conforme as necessidades de negócios mudam. Você pode aplicar esse padrão de arquitetura a outras fontes de dados com diferentes conectores Kafka. Para mais informações, consulte o Exemplos do MSK Connect.
Sobre o autor
 Kalyan Janaki é Especialista Sênior em Big Data & Analytics na Amazon Web Services. Ele ajuda os clientes a arquitetar e criar soluções baseadas em nuvem altamente escaláveis, de alto desempenho e seguras na AWS.
Kalyan Janaki é Especialista Sênior em Big Data & Analytics na Amazon Web Services. Ele ajuda os clientes a arquitetar e criar soluções baseadas em nuvem altamente escaláveis, de alto desempenho e seguras na AWS.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :é
- $UP
- 1
- 10
- 11
- 7
- 8
- a
- Capaz
- Sobre
- Acesso
- Conta
- preciso
- reconhecer
- adicionado
- Adição
- Todos os Produtos
- Permitindo
- permite
- já
- Amazon
- Amazon EC2
- Amazon Web Services
- analítica
- e
- apache
- Apache Kafka
- aplicações
- Aplicar
- apropriado
- arquitetura
- SOMOS
- AS
- aurora
- automaticamente
- disponível
- AWS
- Formação da Nuvem AWS
- Cola AWS
- BE
- antes
- Benefícios
- entre
- Grande
- Big Data
- Bootstrap
- construir
- negócio
- by
- CAN
- capacidades
- capturar
- Capturar
- casos
- catálogo
- CDC
- centralizada
- alterar
- Alterações
- acusações
- verificar
- Cheques
- Escolha
- classe
- Agrupar
- Coluna
- comunidade
- compatibilidade
- compatível
- completar
- componente
- Computar
- Configuração
- Junção
- Contato
- da conexão
- cônsul
- constante
- consumir
- consumidor
- Consumidores
- continuamente
- contract
- ao controle
- país
- crio
- criado
- crítico
- Atual
- personalizadas
- Clientes
- dados,
- integração de dados
- orientado por dados
- banco de dados
- bases de dados
- dias
- decisões
- Padrão
- defaults
- definido
- entregando
- Demo
- demonstraram
- demonstra
- implantar
- implantado
- descrição
- destino
- detalhado
- detalhes
- diferente
- descobrir
- Não faz
- Cair
- cada
- elimina
- permitindo
- end-to-end
- garantir
- garante
- Entrar
- Meio Ambiente
- erro
- especialmente
- Éter (ETH)
- Cada
- evolui
- exemplo
- existente
- existe
- poucos
- Campos
- Envie o
- Arquivos
- final
- Primeiro nome
- seguinte
- Escolha
- formulário
- formato
- da
- gerar
- gerado
- Grupo
- Do grupo
- manipular
- Manipulação
- acontece
- Ter
- ajudar
- ajuda
- altamente
- história
- hospedeiro
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- Hub
- IAM
- identificar
- Dados de identificação:
- implementação
- importante
- in
- Incluindo
- índices
- INFORMAÇÕES
- do estado inicial,
- instalar
- instância
- em vez disso
- integrar
- integração
- interno
- IT
- Java
- jpg
- json
- Kafka
- Chave
- Saber
- Deixar
- bibliotecas
- Licenciado
- como
- carregar
- carregamento
- local
- longo
- moldadas
- FAZ
- Fazendo
- gerenciados
- dominar
- max
- máximo
- mecanismo
- mensagem
- mensagens
- poder
- minutos
- modelo
- modos
- monitores
- mais
- Filmes
- em movimento
- múltiplo
- MySQL
- nome
- Navegar
- Navegação
- você merece...
- necessário
- Cria
- rede
- Novo
- Próximo
- número
- of
- Velho
- on
- ONE
- open source
- Outros
- saída
- página
- pares
- pão
- parâmetro
- parâmetros
- parte
- passou
- Senha
- padrão
- realizar
- permanentemente
- escolher
- platão
- Inteligência de Dados Platão
- PlatãoData
- plug-in
- plugins
- Publique
- evitar
- anterior
- processo
- em processamento
- produzir
- produtor
- Propriedades
- fornecer
- fornecido
- fornece
- Leia
- reais
- em tempo real
- receber
- registro
- registros
- refere-se
- região
- cadastre-se
- registrado
- registro
- repositório
- representado
- Recursos
- Retorna
- Tipo
- Regra
- Execute
- corrida
- mesmo
- escalável
- sem problemas
- Pesquisar
- segundo
- seguro
- segurança
- senior
- sensível
- separado
- serviço
- Serviços
- conjunto
- Configurações
- rede de apoio social
- simples
- simplificar
- solução
- Soluções
- alguns
- fonte
- Fontes
- especialista
- específico
- especificada
- pilha
- Comece
- Status
- Passo
- Passos
- armazenamento
- loja
- lojas
- transmitir canais
- de streaming
- córregos
- estrutura
- adequado
- Apoiar
- suportes
- sincronizar.
- .
- sistemas
- mesa
- Target
- tarefas
- modelo
- teste
- que
- A
- A fonte
- Eles
- Este
- tempo
- sensível ao tempo
- Título
- para
- tópico
- Transações
- VIRAR
- tipos
- para
- não desejado
- atualização
- usar
- Utilizador
- valor
- Valores
- versão
- web
- serviços web
- qual
- precisarão
- Windows
- de
- trabalhador
- trabalhadores
- trabalhar
- trabalho
- escrito
- investimentos
- zefirnet