Encontrar colunas semelhantes em um lago de dados tem aplicações importantes em limpeza e anotação de dados, correspondência de esquema, descoberta de dados e análise em várias fontes de dados. A incapacidade de localizar e analisar com precisão dados de fontes diferentes representa um potencial matador de eficiência para todos, desde cientistas de dados, pesquisadores médicos, acadêmicos até analistas financeiros e governamentais.
As soluções convencionais envolvem pesquisa de palavra-chave lexical ou correspondência de expressão regular, que são suscetíveis a problemas de qualidade de dados, como nomes de coluna ausentes ou diferentes convenções de nomenclatura de coluna em diversos conjuntos de dados (por exemplo, zip_code, zcode, postalcode).
Nesta postagem, demonstramos uma solução para pesquisar colunas semelhantes com base no nome da coluna, no conteúdo da coluna ou em ambos. A solução usa algoritmos aproximados de vizinhos mais próximos disponível em Serviço Amazon OpenSearch para pesquisar colunas semanticamente semelhantes. Para facilitar a pesquisa, criamos representações de recursos (embeddings) para colunas individuais no data lake usando modelos Transformer pré-treinados do biblioteca de transformadores de frases in Amazon Sage Maker. Por fim, para interagir e visualizar os resultados de nossa solução, construímos um Iluminado aplicativo da web em execução AWS Fargate.
Nós incluímos um tutorial de código para você implantar os recursos para executar a solução em dados de amostra ou em seus próprios dados.
Visão geral da solução
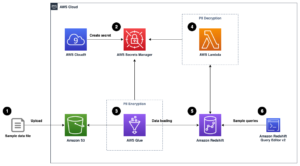
O diagrama de arquitetura a seguir ilustra o fluxo de trabalho em dois estágios para localizar colunas semanticamente semelhantes. A primeira fase executa um Funções de etapa da AWS fluxo de trabalho que cria incorporações de colunas tabulares e cria o índice de pesquisa do serviço OpenSearch. O segundo estágio, ou estágio de inferência online, executa um aplicativo Streamlit por meio do Fargate. O aplicativo da web coleta consultas de pesquisa de entrada e recupera do índice do serviço OpenSearch as k colunas mais semelhantes aproximadas à consulta.

Figura 1. Arquitetura da solução
O fluxo de trabalho automatizado prossegue nas seguintes etapas:
- O usuário carrega conjuntos de dados tabulares em um Serviço de armazenamento simples da Amazon (Amazon S3), que invoca um AWS Lambda função que inicia o fluxo de trabalho do Step Functions.
- O fluxo de trabalho começa com um Cola AWS trabalho que converte os arquivos CSV em Parquet Apache formato de dados.
- Um trabalho de processamento do SageMaker cria incorporações para cada coluna usando modelos pré-treinados ou modelos de incorporação de coluna personalizados. O trabalho de processamento do SageMaker salva as incorporações de coluna para cada tabela no Amazon S3.
- Uma função do Lambda cria o domínio e o cluster do OpenSearch Service para indexar as incorporações de colunas produzidas na etapa anterior.
- Por fim, um aplicativo da Web Streamlit interativo é implantado com o Fargate. O aplicativo da web fornece uma interface para o usuário inserir consultas para pesquisar o domínio do Serviço OpenSearch em busca de colunas semelhantes.
Você pode baixar o tutorial de código em GitHub para experimentar esta solução em dados de amostra ou em seus próprios dados. As instruções sobre como implantar os recursos necessários para este tutorial estão disponíveis em Github.
Pré-requisitos
Para implementar esta solução, você precisa do seguinte:
- An Conta da AWS.
- Familiaridade básica com os serviços da AWS, como o Kit de desenvolvimento em nuvem da AWS (AWS CDK), Lambda, serviço OpenSearch e processamento SageMaker.
- Um conjunto de dados tabular para criar o índice de pesquisa. Você pode trazer seus próprios dados tabulares ou baixar os conjuntos de dados de amostra em GitHub.
Crie um índice de pesquisa
O primeiro estágio cria o índice do mecanismo de pesquisa da coluna. A figura a seguir ilustra o fluxo de trabalho do Step Functions que executa este estágio.

Figura 2 – Fluxo de trabalho de funções de etapa – vários modelos de incorporação
Conjuntos de dados
Nesta postagem, criamos um índice de pesquisa para incluir mais de 400 colunas de mais de 25 conjuntos de dados tabulares. Os conjuntos de dados são originários das seguintes fontes públicas:
Para obter a lista completa das tabelas incluídas no índice, consulte o tutorial de código em GitHub.
Você pode trazer seu próprio conjunto de dados tabulares para aumentar os dados de amostra ou criar seu próprio índice de pesquisa. Incluímos duas funções do Lambda que iniciam o fluxo de trabalho do Step Functions para criar o índice de pesquisa para arquivos CSV individuais ou um lote de arquivos CSV, respectivamente.
Transformar CSV em Parquet
Arquivos CSV brutos são convertidos em formato de dados Parquet com o AWS Glue. Parquet é um formato de arquivo de formato orientado a coluna preferido em análise de big data que fornece compactação e codificação eficientes. Em nossos experimentos, o formato de dados Parquet ofereceu uma redução significativa no tamanho do armazenamento em comparação com os arquivos CSV brutos. Também usamos o Parquet como um formato de dados comum para converter outros formatos de dados (por exemplo, JSON e NDJSON), pois oferece suporte a estruturas de dados aninhadas avançadas.
Criar incorporações de colunas tabulares
Para extrair incorporações para colunas de tabela individuais nos conjuntos de dados tabulares de exemplo nesta postagem, usamos os seguintes modelos pré-treinados do sentence-transformers biblioteca. Para modelos adicionais, consulte Modelos pré-treinados.
O trabalho de processamento do SageMaker é executado create_embeddings.py(código) para um único modelo. Para extrair incorporações de vários modelos, o fluxo de trabalho executa tarefas paralelas do SageMaker Processing, conforme mostrado no fluxo de trabalho do Step Functions. Usamos o modelo para criar dois conjuntos de embeddings:
- nome_coluna_embeddings – Incorporações de nomes de colunas (cabeçalhos)
- coluna_content_embeddings – Incorporação média de todas as linhas na coluna
Para obter mais informações sobre o processo de incorporação de colunas, consulte o tutorial de código em GitHub.
Uma alternativa para a etapa de processamento do SageMaker é criar uma transformação em lote do SageMaker para obter incorporações de coluna em grandes conjuntos de dados. Isso exigiria a implantação do modelo em um endpoint do SageMaker. Para mais informações, veja Usar transformação em lote.
Incorporações de índice com serviço OpenSearch
Na etapa final deste estágio, uma função Lambda adiciona as incorporações de coluna a um k-Nearest-Neighbor aproximado do OpenSearch Service (kNN) índice de pesquisa. Cada modelo recebe seu próprio índice de pesquisa. Para obter mais informações sobre os parâmetros de índice de pesquisa kNN aproximados, consulte k-NN.
Inferência online e pesquisa semântica com um aplicativo da web
A segunda etapa do fluxo de trabalho executa um Iluminado aplicativo da web onde você pode fornecer entradas e procurar colunas semanticamente semelhantes indexadas no OpenSearch Service. A camada de aplicação usa um Balanceador de carga de aplicativo, Fargate e Lambda. A infraestrutura do aplicativo é implantada automaticamente como parte da solução.
O aplicativo permite que você forneça uma entrada e pesquise nomes de coluna semanticamente semelhantes, conteúdo de coluna ou ambos. Além disso, você pode selecionar o modelo de incorporação e o número de vizinhos mais próximos para retornar da pesquisa. O aplicativo recebe entradas, incorpora a entrada com o modelo especificado e usa pesquisa kNN no serviço OpenSearch para pesquisar incorporações de colunas indexadas e localizar as colunas mais semelhantes à entrada fornecida. Os resultados da pesquisa exibidos incluem nomes de tabelas, nomes de colunas e pontuações de similaridade para as colunas identificadas, bem como os locais dos dados no Amazon S3 para exploração adicional.
A figura a seguir mostra um exemplo do aplicativo da web. Neste exemplo, procuramos colunas em nosso data lake que tenham Column Names (tipo de carga útil) A district (carga paga). O aplicativo usado all-MiniLM-L6-v2 como o modelo de incorporação e retornou 10 (k) vizinhos mais próximos de nosso índice de serviço OpenSearch.
O aplicativo retornou transit_district, city, borough e location como as quatro colunas mais semelhantes com base nos dados indexados no OpenSearch Service. Este exemplo demonstra a capacidade da abordagem de pesquisa para identificar colunas semanticamente semelhantes em conjuntos de dados.

Figura 3: Interface de usuário do aplicativo da Web
limpar
Para excluir os recursos criados pelo AWS CDK neste tutorial, execute o seguinte comando:
cdk destroy --allConclusão
Nesta postagem, apresentamos um fluxo de trabalho de ponta a ponta para criar um mecanismo de pesquisa semântica para colunas tabulares.
Comece hoje mesmo com seus próprios dados com nosso tutorial de código disponível em GitHub. Se você quiser ajuda para acelerar o uso de ML em seus produtos e processos, entre em contato com o Laboratório de soluções de aprendizado de máquina da Amazon.
Sobre os autores
![]() Kachi Odoemene é um cientista aplicado na AWS AI. Ele cria soluções de IA/ML para resolver problemas de negócios para clientes da AWS.
Kachi Odoemene é um cientista aplicado na AWS AI. Ele cria soluções de IA/ML para resolver problemas de negócios para clientes da AWS.
![]() Taylor McNally é arquiteto de Deep Learning no Amazon Machine Learning Solutions Lab. Ele ajuda clientes de vários setores a criar soluções aproveitando AI/ML na AWS. Ele gosta de uma boa xícara de café, do ar livre e do tempo com sua família e seu cachorro enérgico.
Taylor McNally é arquiteto de Deep Learning no Amazon Machine Learning Solutions Lab. Ele ajuda clientes de vários setores a criar soluções aproveitando AI/ML na AWS. Ele gosta de uma boa xícara de café, do ar livre e do tempo com sua família e seu cachorro enérgico.
![]() Austin Welch é cientista de dados no laboratório de soluções do Amazon ML. Ele desenvolve modelos personalizados de aprendizado profundo para ajudar os clientes do setor público da AWS a acelerar sua adoção de IA e nuvem. Nas horas vagas, gosta de ler, viajar e praticar jiu-jitsu.
Austin Welch é cientista de dados no laboratório de soluções do Amazon ML. Ele desenvolve modelos personalizados de aprendizado profundo para ajudar os clientes do setor público da AWS a acelerar sua adoção de IA e nuvem. Nas horas vagas, gosta de ler, viajar e praticar jiu-jitsu.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- habilidade
- Sobre
- ausente
- acelerar
- acelerando
- exatamente
- em
- Adicional
- Adicionalmente
- Adiciona
- Adoção
- avançado
- AI
- AI / ML
- Todos os Produtos
- permite
- alternativa
- Amazon
- Aprendizado de máquina da Amazon
- Laboratório de soluções de ML da Amazon
- Analistas
- analítica
- analisar
- e
- apache
- Aplicação
- aplicações
- aplicado
- abordagem
- arquitetura
- atribuído
- Automatizado
- automaticamente
- disponível
- média
- AWS
- Cola AWS
- baseado
- Porque
- Grande
- Big Data
- trazer
- construir
- Prédio
- Constrói
- negócio
- Limpeza
- Na nuvem
- adoção de nuvem
- Agrupar
- código
- Café
- coleta
- Coluna
- colunas
- comum
- comparado
- Contacto
- conteúdo
- Convenções
- converter
- convertido
- crio
- criado
- cria
- copo
- personalizadas
- Clientes
- dados,
- Análise de Dados
- lago data
- qualidade de dados
- cientista de dados
- conjuntos de dados
- profundo
- deep learning
- demonstrar
- demonstra
- implantar
- implantado
- Implantação
- destruir
- Desenvolvimento
- desenvolve
- diferente
- descoberta
- díspar
- diferente
- Cachorro
- domínio
- download
- cada
- eficiência
- eficiente
- end-to-end
- Ponto final
- Motor
- Éter (ETH)
- todos
- exemplo
- exploração
- extrato
- facilitar
- Familiaridade
- família
- Funcionalidades
- Figura
- Envie o
- Arquivos
- final
- Finalmente
- financeiro
- Encontre
- descoberta
- Primeiro nome
- seguinte
- formato
- da
- cheio
- função
- funções
- mais distante
- ter
- dado
- Bom estado, com sinais de uso
- Governo
- cabeçalhos
- ajudar
- ajuda
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- identificado
- identificar
- executar
- importante
- in
- incapacidade
- incluir
- incluído
- índice
- Individual
- indústrias
- INFORMAÇÕES
- Infraestrutura
- iniciar
- Inicia
- entrada
- instruções
- interagir
- interativo
- Interface
- invoca
- envolver
- questões
- IT
- Trabalho
- Empregos
- json
- laboratório
- lago
- grande
- camada
- aprendizagem
- aproveitando
- Biblioteca
- Lista
- carregar
- locais
- máquina
- aprendizado de máquina
- correspondente
- médico
- ML
- modelo
- modelos
- mais
- a maioria
- múltiplo
- nome
- nomes
- nomeando
- você merece...
- vizinhos
- número
- oferecido
- online
- Outros
- ao ar livre
- próprio
- Paralelo
- parâmetros
- parte
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- Publique
- potencial
- preferido
- apresentado
- anterior
- problemas
- prossegue
- processo
- processos
- em processamento
- Produzido
- Produtos
- fornecer
- fornece
- público
- qualidade
- Cru
- Leitura
- recebe
- regular
- representa
- requerer
- requeridos
- pesquisadores
- Recursos
- respectivamente
- Resultados
- retorno
- Execute
- corrida
- sábio
- Cientista
- cientistas
- Pesquisar
- motor de busca
- pesquisar
- Segundo
- setor
- serviço
- Serviços
- Conjuntos
- mostrando
- Shows
- periodo
- semelhante
- simples
- solteiro
- Tamanho
- solução
- Soluções
- RESOLVER
- Fontes
- especificada
- Etapa
- começado
- Passo
- Passos
- armazenamento
- tal
- suportes
- suscetível
- mesa
- A
- deles
- Através da
- tempo
- para
- hoje
- Transformar
- transformadores
- Viagens
- tutorial
- usar
- Utilizador
- Interface de Usuário
- vário
- web
- Aplicativo da Web
- qual
- de gestão de documentos
- seria
- investimentos
- zefirnet